網路上的數據就像現代的黑金,但這些寶貴資訊分散在各種網站、藏在亂七八糟的 HTML 裡,還有一堆 CAPTCHA 跟反爬蟲機制在把關。如果你曾經手動複製貼上產品價格、競爭對手資料或潛在客戶名單,肯定知道這種方式不只超級耗時,還很容易錯過商機。這也是為什麼網頁爬蟲成為現代企業的必備技能。事實上,替代數據市場(包含網頁爬蟲)在 ,而且還在持續飆升。

有趣的是,雖然 Python 是新手最愛,但 Go(Golang)其實默默支撐著全球最快、最穩定的爬蟲。Go 的優勢在於超強的並發能力、強大的標準函式庫,以及讓後端工程師愛不釋手的效能。我親眼看過團隊只因為改用 Go,爬蟲速度直接翻倍——而且只要選對工具,入門一點都不難。
想讓 Go 變成你的網頁爬蟲神兵利器嗎?這篇文章會帶你從環境建置到進階技巧,實戰範例、實用建議,還有怎麼結合 這類 AI 工具,讓你的數據流程更上一層樓。
為什麼選 Go 來做網頁爬蟲?商業價值大解析
老實說,當你要抓數千甚至上百萬頁面時,每一秒都很關鍵。Go 天生就適合這種高強度的任務。以下是越來越多企業選擇 Go 來做網頁爬蟲的原因:
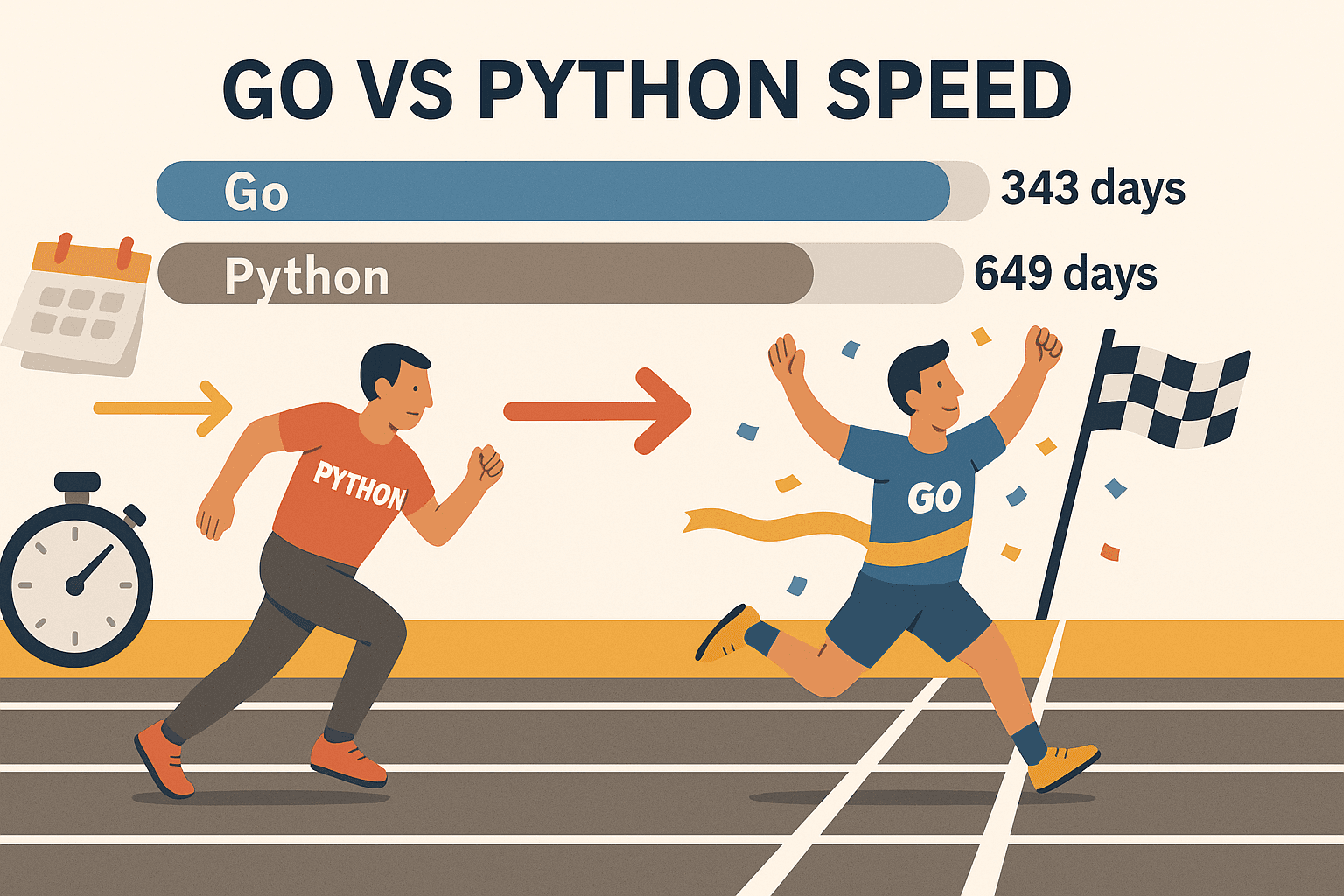
- 超強並發能力: Go 的 goroutine(超輕量執行緒)讓你同時抓上百頁面,電腦完全不會卡。在某次測試中,Go 能在 343 天內抓完 ,而 Python 則需要 649 天。這速度根本不同級別。
- 穩定又可靠: Go 的強型別和高效記憶體管理,讓它成為長時間、大規模爬蟲的首選。再也不用擔心半夜爬蟲掛掉。
- 一流網路支援: Go 標準函式庫內建 HTTP 請求、HTML 解析、JSON 處理,開箱即用,完全不用額外裝一堆套件。
- 部署超簡單: Go 會編譯成單一執行檔,無論哪個平台都能直接跑,不用煩惱虛擬環境或相依套件。
- 產業廣泛採用: Go 已經是 (甚至超越 Node.js),Google、Uber、Netflix 等大公司都在用。
當然,Python 適合快速原型或需要機器學習時用。但如果你重視速度、規模與穩定性,Go 幾乎無可取代——尤其搭配 Colly、Goquery 這些強大函式庫。
步驟一:建立 Go 網頁爬蟲開發環境
在開始寫爬蟲前,先把 Go 環境裝好。好消息是,這個過程超簡單。
1. 安裝 Go
- 前往 ,選擇你作業系統的安裝檔(Windows、macOS、Linux)。
- 執行安裝程式並照指示完成。Linux 也可以用套件管理器安裝。
- 開啟終端機,輸入:
如果看到像1go versiongo version go1.21.0 darwin/amd64這樣的訊息,就代表安裝成功。
疑難排解: 如果找不到 go 指令,請確認 PATH 設定正確。Linux/macOS 可能要在 ~/.bash_profile 或 ~/.zshrc 加上 export PATH=$PATH:/usr/local/go/bin。
2. 初始化新專案
- 建立一個新資料夾:
1mkdir my-scraper && cd my-scraper - 初始化 Go 模組:
這會產生1go mod init github.com/yourname/my-scrapergo.mod檔案,幫你管理相依套件。
3. 選擇編輯器
- 搭配 Go 擴充套件,支援自動補全、語法檢查、除錯。
- JetBrains GoLand 也是 Go 開發者很愛用的專業工具。
- 如果你偏好經典風格,Vim/Neovim 加 Go 外掛也很不錯。
4. 測試環境是否正常
建立一個簡單的 main.go:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go is installed and working!")
5}執行:
1go run main.go看到訊息就代表一切 OK。
步驟二:用 Go 發送第一個 HTTP 請求
現在來抓第一個網頁!Go 的 net/http 套件讓這件事變得超簡單。
基本 HTTP GET 範例:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Error fetching the URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Error reading the response body:", err)
17 return
18 }
19 fmt.Println(string(body))
20}重點提示:
- 每次呼叫
http.Get後都要檢查錯誤。 - 用
defer resp.Body.Close()避免資源外洩。 - 用
io.ReadAll讀取完整回應內容。
進階技巧:
- 想自訂標頭(像瀏覽器 User-Agent),可以用
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - 記得檢查
resp.StatusCode,200 代表成功,403 或 404 可能被擋或頁面不存在。
步驟三:用 Go 解析 HTML 並提取資料
抓到 HTML 只是第一步,接下來要把有用的資訊(像產品名稱、價格、連結等)萃取出來。
Goquery 登場: 這是 Go 的 HTML 解析套件,語法跟 jQuery 很像,操作起來超直覺。
安裝 Goquery:
1go get github.com/PuerkitoBio/goquery範例:抓取產品名稱與價格
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Product %d: %s - %s\n", i+1, name, price)
21 })
22}運作原理:
doc.Find("div.product")會選出所有產品區塊。s.Find("h2").Text()取得產品名稱,s.Find(".price").Text()取得價格。
正則表達式: 想抓 email 這種簡單模式,可以用 Go 的 regexp 套件。複雜結構還是建議用 Goquery。
步驟四:用 Go 函式庫(Colly & Gocolly)強化你的爬蟲
想再升級? 是 Go 最熱門的網頁爬蟲框架。它幫你處理爬蟲流程、並發、Cookie 等細節,讓你專心在資料本身。
Colly 的優點:
- 簡單 API: 只要註冊 callback 就能抓取目標元素。
- 高效並發: 用
colly.Async(true)輕鬆同時抓大量頁面。 - 自動爬行: 能自動追蹤連結、處理分頁。
- 反爬蟲功能: 可自訂標頭、輪換 User-Agent、管理 Cookie。
- 錯誤處理: 內建失敗請求的處理機制。
安裝 Colly:
1go get github.com/gocolly/colly/v2Colly 基本爬蟲範例:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Product: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Request failed:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}功能比較:Goquery vs. Colly
| 功能 | Goquery | Colly |
|---|---|---|
| HTML 解析 | 有 | 有(內部用 Goquery) |
| HTTP 請求 | 需自行處理 | 內建 |
| 並發處理 | 需手動(goroutine) | 簡單(Async(true)) |
| 爬行/連結追蹤 | 需手動 | 自動 |
| 反爬蟲功能 | 需手動 | 內建 |
| 錯誤處理 | 需手動 | 內建 |
Colly 對於複雜一點的爬蟲專案,真的能大幅省下開發時間。
步驟五:Go 網頁爬蟲實戰挑戰與解法
現實世界的網頁爬蟲不會永遠順利,這裡教你怎麼解決常見難題:
1. IP 被封鎖
- 用 Go 的
http.Transport或 Colly 的 proxy 支援輪換代理。 - 隨機延遲請求速度,降低被偵測風險。
2. User-Agent 與標頭
- 一定要設置像 Chrome、Firefox 的真實 User-Agent。
- 模擬真實瀏覽器的標頭(像 Accept-Language 等)。
3. CAPTCHA 驗證
- 遇到 CAPTCHA,通常是抓太快或太明顯。
- 可以用 這類 headless browser 處理需要 JS 或互動的網站。
- 如果遇到高強度反爬蟲,可以考慮整合自動解 CAPTCHA 服務。
4. 分頁處理
- 用 Colly 可自動追蹤「下一頁」連結:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. 動態內容(JavaScript)
- Go 的 HTTP 套件沒辦法執行 JS。可以用 headless browser(Rod、chromedp),或直接抓 API 端點。
6. 當遇到瓶頸時……用 Thunderbit
有時候網站太動態、反爬蟲太強,或你急需資料又不想寫程式,這時 就超好用。Thunderbit 是一款 AI 驅動的網頁爬蟲 Chrome 擴充功能,特色包括:
- AI 自動偵測並提取欄位,只要點「AI 建議欄位」就搞定。
- 自動處理子頁面、分頁等複雜流程。
- 在真實瀏覽器(或雲端)執行,能應對大量 JS 跟反爬蟲機制。
- 一鍵匯出到 Excel、Google Sheets、Airtable、Notion,完全免寫程式。
- 支援排程自動抓取,團隊協作也很方便。
Thunderbit 對於業務、銷售、需要結構化資料的用戶來說,真的是省時又省力的好幫手。沒錯,我自己和團隊就是為了解決這些痛點才開發它。
Go + Thunderbit:效率最大化的組合
其實你不用在 Go 和 Thunderbit 之間二選一,最強的團隊往往兩者一起用。
範例流程:
- 先用 Go(搭配 Colly)大規模爬取網址或基礎資料。
- 把網址清單交給 Thunderbit,針對子頁面、動態內容或複雜反爬蟲網站進行詳細結構化提取。
- 從 Thunderbit 匯出資料到 Google Sheets 或 CSV。
- 再用 Go 處理、整合或分析這些資料。
這種混合策略,既有 Go 的速度與彈性,又能享受 Thunderbit 的 AI 智慧與便利,等於同時擁有瑞士刀和電動工具。
Go 網頁爬蟲方案比較:原生 Go vs. Colly vs. Thunderbit
以下快速比較,幫你選出最適合的工具:
| 面向 | 純 Go(net/http + html) | Go + Colly(函式庫) | Thunderbit(AI 無程式碼) |
|---|---|---|---|
| 安裝與學習曲線 | 陡峭(需寫程式) | 適中(API 較簡單) | 最簡單(無程式碼,AI 驅動) |
| 並發處理 | 手動(goroutine) | 內建(Async(true)) | 雲端/瀏覽器自動並行 |
| 動態內容(JS) | 需 headless browser | 部分支援 JS,或用 Rod | 完整瀏覽器,原生支援 JS |
| 反爬蟲處理 | 手動(代理、標頭) | 內建多種功能 | 大多自動處理,雲端 IP |
| 資料結構化 | 自行撰寫 | callback、自訂 struct | AI 建議、自動格式化 |
| 匯出選項 | 自訂(CSV、資料庫等) | 自訂 | Excel、Sheets、Notion、Airtable |
| 維護成本 | 高(常需改程式) | 適中 | 低(AI 自動適應網站變化) |
| 適合對象 | 開發者、自訂流程 | 開發者、快速原型 | 非程式人員、商業用戶 |
小建議: 大型、需自訂或後端整合專案用 Go/Colly,想快速、簡單或需處理複雜前端網站時用 Thunderbit。
重點整理:Go 網頁爬蟲入門
- Go 是網頁爬蟲的強力工具——特別適合追求速度、並發與穩定性的需求。
- 從基礎做起: 建好 Go 環境,學會發送 HTTP 請求、用 Goquery 解析 HTML。
- 進階用 Colly: 需要爬行、並發、反爬蟲時,Colly 是你的好夥伴。
- 面對現實挑戰: 輪換代理、設置標頭,遇到難搞網站就用 headless browser 或 Thunderbit。
- 工具混搭最強大: Go 與 Thunderbit 結合,效率與彈性兼得。
網頁爬蟲能大幅提升銷售、營運、研究團隊的效率。有了 Go 及相關函式庫(再加點 AI),你就能自動化繁瑣流程,把時間花在真正有價值的洞察上。
Go 網頁爬蟲進階資源
想更深入?這裡推薦幾個超實用資源:
祝你爬蟲順利,資料結構清楚、速度飛快、咖啡永遠夠濃!
常見問答
1. 為什麼用 Go 做網頁爬蟲,而不是 Python 或 JavaScript?
Go 在並發、速度與穩定性上表現超強,特別適合大規模或長時間運行的爬蟲專案。當你需要快速抓大量頁面、又想要可攜式執行檔時,Go 絕對是理想選擇。
2. Go 最簡單的 HTML 解析方式是什麼?
推薦用 套件,語法跟 jQuery 很像,DOM 操作和資料提取都很方便。
3. Go 如何處理 JavaScript 動態渲染的網站?
你需要用像 或 這類 headless browser。或者直接用 ,完全不用寫程式也能搞定 JS 網站。
4. 如何避免爬蟲被封鎖?
輪換 User-Agent、使用代理、加上請求延遲、模擬真實瀏覽器行為。Colly 讓這些技巧更容易實現,Thunderbit 則大多自動處理反爬蟲。
5. 可以把 Go 和 Thunderbit 結合在同一流程嗎?
當然可以!用 Go 處理大規模爬取或後端整合,Thunderbit 負責 AI 智慧提取、子頁面抓取與資料匯出,開發者和商業用戶都能受益。
想提升你的網頁爬蟲技能?歡迎免費試用 ,或到 看更多教學、技巧與 AI 自動化深度解析。