讓我跟你分享一個小秘密:網路其實就像全世界最大的圖書館,只是大部分的書都被「黏」在架上。每天我都會遇到企業主、行銷人員、業務團隊,他們都知道網頁裡藏著寶——產品規格、競爭對手價格、顧客評論、聯絡方式——但要把這些文字撈出來?這才是真正的難題。我在 SaaS 和自動化圈子混了好幾年,見過太多「複製貼上馬拉松」和「自己寫 Python 抓資料」的血淚史。好消息是,現在有新一代的人工智慧網頁爬蟲和更聰明的瀏覽器擴充功能,從網站提取文字變得前所未有的簡單又輕鬆。
這篇教學會帶你從最基本的複製貼上,到進階的 AI 工具(像 ,沒錯,這是我們團隊的產品,但我會誠實分析優缺點),每一種實用方法都會詳細拆解。不管你是 Excel 達人、程式高手,還是只想省下盯著網頁抄資料的時間,都能找到適合你的解法。現在,就讓我們一起打開這些數位書本,把你需要的文字帶回家。
什麼是「從網站提取文字」?
「從網站提取文字」其實就是把你在網頁上看到(有時甚至沒看到)的資訊,轉成你能用的格式——像 Excel、資料庫,或乾淨的 Word 文件。但網站上的文字類型其實很多:
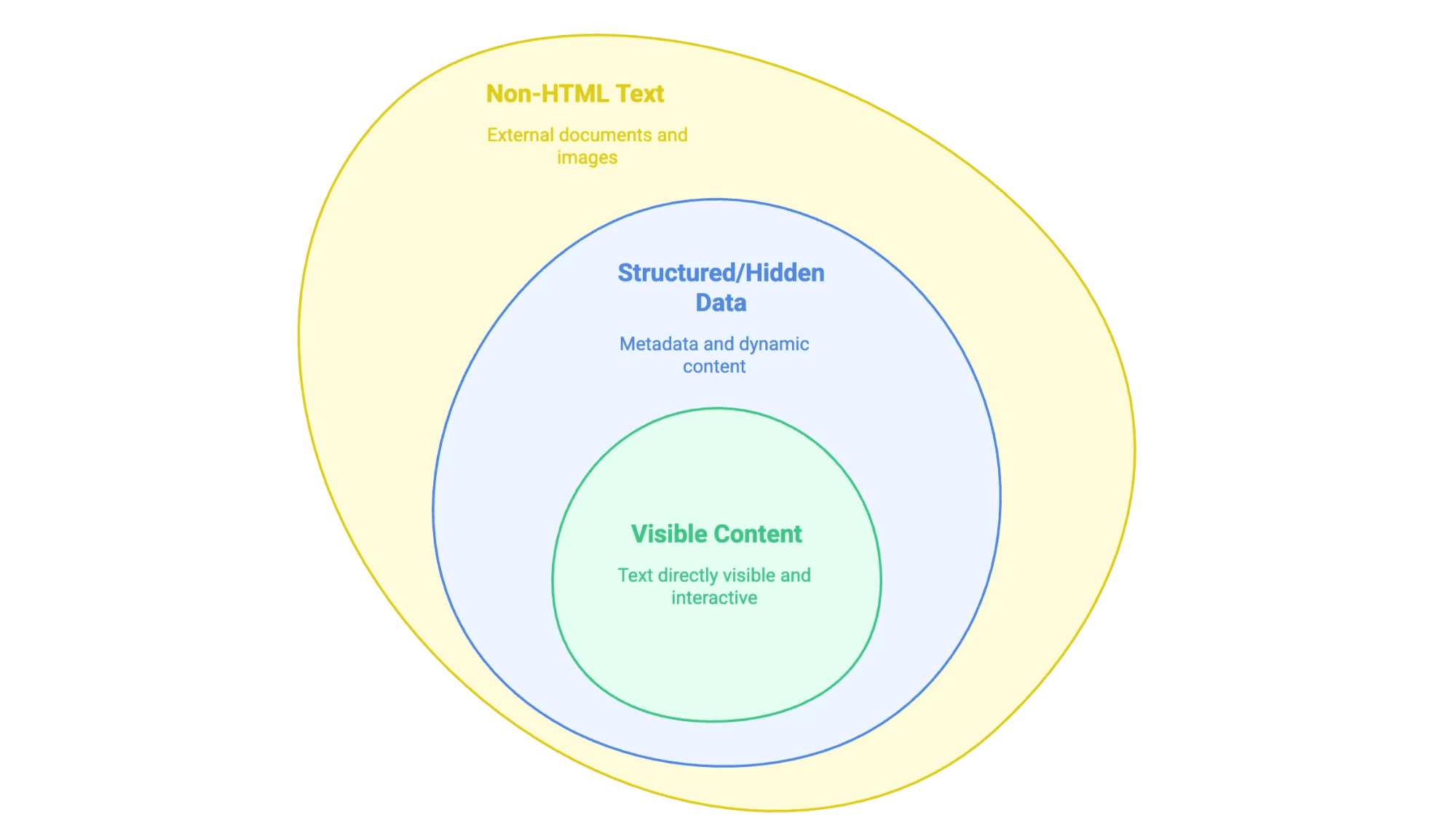
- 可見內容: 你可以用滑鼠反白的文字——像正文、標題、清單、表格、產品描述、部落格文章等。
- 結構化或隱藏資料: 例如
<meta>標籤裡的資訊、JSON-LD 腳本,或是要點擊、捲動才會出現的 JavaScript 動態資料。 - 非 HTML 文字: 像 PDF、Word 文件,甚至圖片上的文字(例如掃描合約、資訊圖表)也常常藏在網站裡。
重點是,你要先搞清楚自己要哪一種資料,因為不同類型需要不同的提取方式。
為什麼要從網站提取文字?商業應用與效益
說真的,沒有人會閒到純粹為了好玩去抓網站資料(除非你真的很愛這種挑戰)。企業會這麼做,是因為回報率超高。根據統計,網頁爬蟲軟體市場在 ,而且還在持續成長。原因如下:
| 團隊 | 應用範例 | 效益 |
|---|---|---|
| 業務 | 從名錄抓取潛在客戶與聯絡方式 | 更快、更豐富的名單開發 |
| 行銷 | 擷取競爭對手部落格與 SEO 資料 | 分析內容缺口、掌握趨勢 |
| 營運 | 監控各大電商網站商品價格 | 動態定價、庫存追蹤 |
| 房地產 | 匯整物件列表與詳細資訊 | 市場分析、潛在客戶開發 |
| 客服 | 收集顧客評論與論壇問答 | 情緒分析、早期問題偵測 |
幾個真實案例:

- 名單開發: 某餐飲設備公司 ,省下過去幾天的人工作業。
- 競爭對手監控: 零售商 John Lewis 利用爬蟲抓取價格資訊,。
- SEO 分析: 團隊會擷取 meta 標籤與關鍵字,來 。
而且有了 AI 工具,企業在資料收集上能比傳統方法 。
手動方法:最基本的複製貼上
先從最簡單的開始。有時候你只需要一小段資料,其實不用任何工具。
如何手動提取網站文字
- 複製貼上: 開啟網頁,反白你要的文字,按 Ctrl+C(或右鍵 > 複製),再貼到文件或試算表。
- 另存網頁: 在瀏覽器選單點「檔案 > 另存新檔」,選「僅 HTML」可取得原始碼,有些瀏覽器也能存成 .txt 純文字。
- 列印成 PDF: 用瀏覽器的列印功能選「另存為 PDF」,再從 PDF 複製文字(或用 PDF 閱讀器的「另存為文字」功能)。
- 開發者工具: 右鍵 > 檢查元素,或按 F12 開啟 DevTools,直接查看 HTML 原始碼、meta 標籤或隱藏的 JSON,複製你需要的內容。
侷限與缺點
手動提取適合偶爾用用,但只要量一大就會變成惡夢。這種方式 。我看過實習生一行一行抄表格抄好幾天——沒有人想做這種苦工。
用瀏覽器擴充功能和線上工具提取網站文字
想更有效率?瀏覽器擴充功能和線上工具是大多數商務用戶的首選:不用寫程式、不用搞技術,只要點一點就能搞定。
為什麼要用這些工具?

- 比手動快超多
- 完全不需要寫程式
- 能處理表格、清單,甚至有些能抓檔案
- 可匯出到 Excel、Google Sheets、CSV 等格式
來看看目前最受歡迎的幾種選擇。
Thunderbit:AI 網頁爬蟲,快速精準提取文字
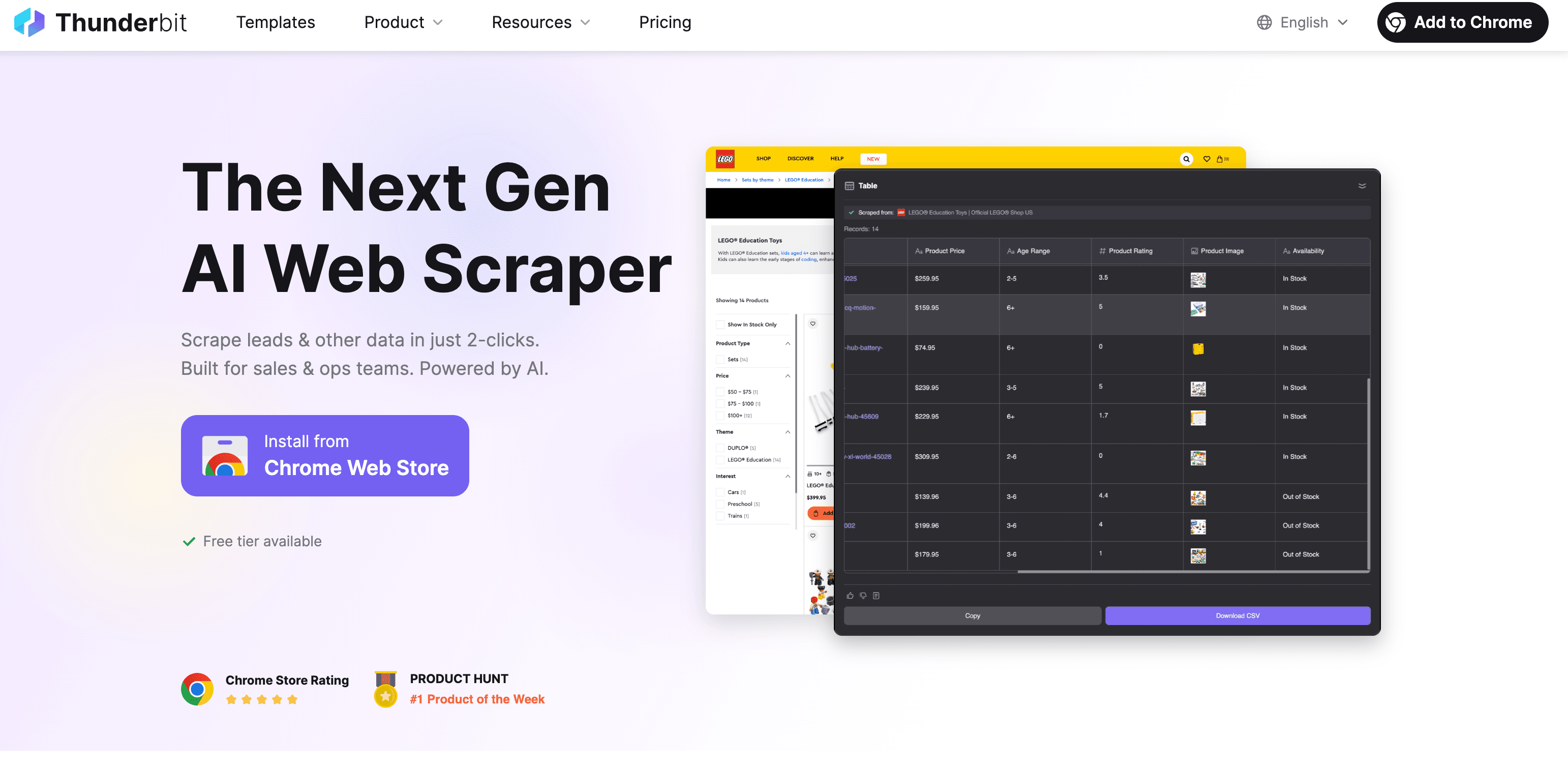
雖然我有點私心,但 真的就是為了讓網頁文字提取變得像點外送一樣簡單。操作方式如下:
步驟教學:用 Thunderbit 提取網站文字
- 安裝 Chrome 擴充功能: 從 Chrome Web Store 。
- 打開目標網站: 前往你想提取資料的網頁。
- 點選「AI 建議欄位」: Thunderbit 的 AI 會自動掃描頁面,推薦哪些欄位(像產品名稱、價格、描述等)可以提取。
- 檢查與調整: 你可以修改 AI 建議的欄位,或自行新增。
- 點擊「開始爬取」: Thunderbit 會自動抓取資料,連分頁或子頁面都能一併處理。
- 匯出資料: 可直接下載到 Excel、Google Sheets、Airtable、Notion,或存成 CSV/JSON。匯出完全免費。
Thunderbit 有哪些獨特優勢?
- AI 智慧欄位建議: 不用自己設定選擇器或寫程式,AI 會自動判斷頁面重點。
- 自動處理分頁與子頁面: 需要每個產品頁的詳細資料?Thunderbit 會自動點擊、翻頁。
- 支援 PDF、圖片、文件提取: 有 PDF 手冊或產品規格圖?Thunderbit 內建 OCR,連圖片上的文字都能抓。
- 多語言支援: 支援 34 種語言(我還在等克林貢語,有朝一日會有的)。
- 資料匯出完全免費: 不會因為匯出資料被收費。
- 應用場景多元: 產品描述、聯絡資訊、部落格內容、名單收集等都適用。
想看實際操作?歡迎到 看更多教學,例如 。
其他瀏覽器擴充功能與線上工具
也來介紹幾個你可能會遇到的其他工具:
- 網頁爬蟲 (): 免費、可視化操作,但學習曲線較高。適合懂技術的分析師,需要自己設定「網站地圖」和選擇器。能處理分頁,但不支援 PDF 或圖片。 。
- CopyTables: 超簡單,直接把 HTML 表格複製到剪貼簿或 Excel。適合臨時抓表格,但只能一頁一頁抓,且僅限表格。 。
- ScraperAPI (): 給開發者用的。你傳網址給它,它回傳 HTML(自動處理代理、反爬蟲等),但你還是要自己解析文字。 。
什麼時候該用哪個工具?
- Thunderbit: 追求速度、AI 輔助、多格式支援(含 PDF/圖片)時。
- 網頁爬蟲: 喜歡自己調整、需要高度自訂時。
- CopyTables: 只想快速抓表格時。
- ScraperAPI: 需要自己寫程式打造專屬爬蟲時。
自動化網頁爬蟲:用程式提取網站文字
如果你是開發者(或有工程師幫忙),自己寫爬蟲能達到最高自由度。基本流程如下:
- 發送 HTTP 請求: 用 Python 的
requests或類似工具抓取網頁。 - 解析 HTML: 用
BeautifulSoup、lxml或Scrapy找到你要的文字。 - 提取與匯出: 把資料撈出來、清理好,存成 CSV、JSON 或資料庫。
範例:Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)優缺點分析
- 優點: 彈性最高,任何網站、任何資料型態都能處理,能整合到自家系統。
- 缺點: 需要程式能力、後續維護,還要處理反爬蟲機制。
適合什麼情境?
- 需要抓取大量(數千、數萬頁)資料時。
- 網站結構複雜(需登入、多步驟表單)。
- 想把爬蟲直接整合到自家應用或自動化流程。
提取非 HTML 格式的文字:PDF、Word、圖片
網站內容不只 HTML,還常有 PDF、Word 文件、圖片等重要資料。該怎麼抓?
- 純文字 PDF: 可用 Adobe Acrobat,或 Python 的
PDFMiner、PyPDF2等工具提取。 - 掃描 PDF: 需用 OCR(光學文字辨識)工具,如 Tesseract、、。
Word/Excel 文件
- Word: 用
python-docx讀取 .docx 檔案。 - Excel: 用
openpyxl或pandas處理 .xlsx 檔案。
圖片
- OCR 工具: 開源可用 Tesseract,或用雲端服務提升準確率。建議圖片解析度 150–300 DPI 效果最佳。
Thunderbit 的做法
「圖片/文件解析器」功能讓你直接上傳或貼連結(PDF、圖片、文件),AI 會自動提取文字(如果有表格還會自動建議欄位)。不用切換多個工具,檔案就像網頁一樣輕鬆處理。
各種方法比較:哪種提取方案最適合你?
這裡幫你快速比較各種方法:
| 方法 | 易用性 | 可擴展性 | 技術門檻 | 支援資料型態 | 適合對象 |
|---|---|---|---|---|---|
| 手動(複製貼上) | 非常簡單 | 低 | 無 | 只限可見文字 | 臨時、小量需求 |
| 瀏覽器擴充/線上工具 | 簡單~中等 | 中 | 低~中 | HTML、部分表格 | 非技術用戶、中小型需求 |
| AI 工具(Thunderbit) | 非常簡單 | 高 | 無 | HTML、PDF、圖片等 | 商務用戶、混合內容 |
| 程式開發 | 困難 | 非常高 | 高 | 任何(有對應函式庫即可) | 開發者、大型專案 |
| 非 HTML 提取(OCR) | 中等 | 低~中 | 中 | PDF、圖片、文件 | 需處理檔案/圖片時 |
如果你想要最快、最彈性、最省力的方式——尤其是商業應用——AI 工具如 Thunderbit 幾乎是首選。但如果你需要完全自訂或大規模抓取,自己寫程式會更合適。
重點整理:現在就開始提取網站文字
- 網路上充滿有價值的文字資料,但取得並不容易。
- 手動方法適合小量需求,但無法規模化。
- 瀏覽器擴充與人工智慧網頁爬蟲(如 )讓提取文字變得快速、精準、人人可用——完全不需寫程式。
- 處理非 HTML 內容(PDF、圖片)時,請選擇有內建 OCR 與文件解析功能的工具。
- 請根據團隊技能、專案規模與資料型態,選擇最適合的方法。
祝你抓資料順利——也希望你再也不用瘋狂 Ctrl+C。只要選對工具,網站資料提取就能變成自動化、省時又高效的流程,讓你把時間花在更有價值的事情上。告別無止盡的複製貼上,迎接更聰明、更高效的未來!
常見問題
Q1:我可以抓取任何網站的資料嗎?
A1:不一定。有些網站會封鎖爬蟲,或在服務條款中禁止抓取。請務必先確認網站政策。
Q2:人工智慧網頁爬蟲的準確度高嗎?
A2:像 Thunderbit 這類 AI 爬蟲通常非常準確,但遇到結構複雜或高度動態的頁面時,可能需要手動微調。
Q3:使用網頁爬蟲工具需要會寫程式嗎?
A3:不用,Thunderbit 及多數瀏覽器擴充功能都為非技術用戶設計,完全不需程式能力。
Q4:我可以從 PDF 或圖片中提取哪些資料?
A4:OCR 工具能從掃描 PDF 和圖片中提取文字、表格,甚至隱藏資訊,讓資料提取更有彈性。
延伸閱讀