電子郵件之所以到現在還有效,是因為它直接、可衡量,而且只要底層資料夠好,就很容易做個人化。真正難的不是發外聯,而是不花好幾個小時,從網站、名錄、PDF 和 LinkedIn 頁面一筆一筆複製電子郵件,同時還能拿到乾淨的公開聯絡資料。
這也是為什麼現在的「email scraper」早就不只是一種工具。有些工具會從開放網路抓取電子郵件;有些則是根據姓名、公司或網域找出並驗證工作信箱;還有一些更像 B2B 聯絡人資料庫,再加上資料補全與外聯層。這一頁要回答的其實是採購上最實際的問題:哪一種模式最適合你的工作流程?
依工作流程快速推薦
- 需要直接從網站、名錄、PDF 或圖片抓取電子郵件? 先看 。
- 需要尋找器、驗證器與多通路外聯整合在同一套系統? 可優先考慮 。
- 需要大型 B2B 聯絡人資料庫,還有銷售工作流程層? 看看 。
- 需要以 LinkedIn 為主的電子郵件查找與輕量資料補全? 比較 。
- 需要最乾淨的網域搜尋與電子郵件驗證流程? 先從 開始。
- 需要可重複使用、免寫程式的爬蟲,處理更複雜的網站? 可以看看 。
- 需要已驗證的 B2B 聯絡人資料,以及適合 CRM 的資料補全? 看看 。
2026 年的 Email Scraper 到底算什麼
舊定義很簡單:一個抓取頁面,並擷取任何看起來像 name@company.com 的工具。這件事現在仍然重要,但多數團隊如今買的其實是以下四類之一:
- 開放網路抓取: 從公開頁面、名錄、清單、PDF、圖片或搜尋結果流程中擷取電子郵件與背景資訊。
- 查找器加驗證器: 先輸入人名、公司或網域,再比對可能的工作信箱,接著驗證是否可投遞。
- 免寫程式抓取: 為需要比一鍵式爬蟲更多控制的網站建立可重複使用的擷取任務。
- 銷售資料庫開發: 以商業聯絡網路為基礎,再搭配資料補全、篩選與 GTM 工作流程層來運作。
最常見的採購錯誤,就是把這四種當成可以互換。如果你的最佳潛在客戶散落在利基型公開來源中,單靠聯絡人資料庫一定會有缺口;如果你的團隊已經知道公司,只需要一個已驗證的工作信箱,那麼一般的網頁爬蟲就太繞了。
如果你想先看看這個類別中的開放網路端,再比較以資料庫為主的工具,這支 Thunderbit 官方短片會是最快、最實用的例子。它展示了傳統電子郵件尋找器不太擅長處理的流程:從 PDF 擷取聯絡資料,而不只是從已知公司網域抓取。
抓取電子郵件合法嗎?
通常,答案不是「一定可以」或「一定不行」。公開可存取的聯絡資料,不代表可以不受限制地大量外聯。法律風險取決於聯絡資料所在位置、你如何蒐集、如何儲存,以及如何使用。
至少,團隊應該參考 上關於歐盟資料處理的 GDPR 指引,以及 FTC 的 ,了解美國商業電子郵件規範。好的工具可以減少人工作業,但無法取代相關性足夠的外聯、退出訂閱處理,以及合理的資料治理。
前一版文章中的真實工作流程示例
這篇文章的舊版本,比一般工具清單頁更強調實作教學,所以這些實際示範與操作截圖特地保留下來。它們依然有用,因為能展示在搜尋結果、PDF、名錄、供應商資料庫與 LinkedIn 補全流程中,「電子郵件抓取」在實務上的樣子。
一般 AI 抓取操作示範
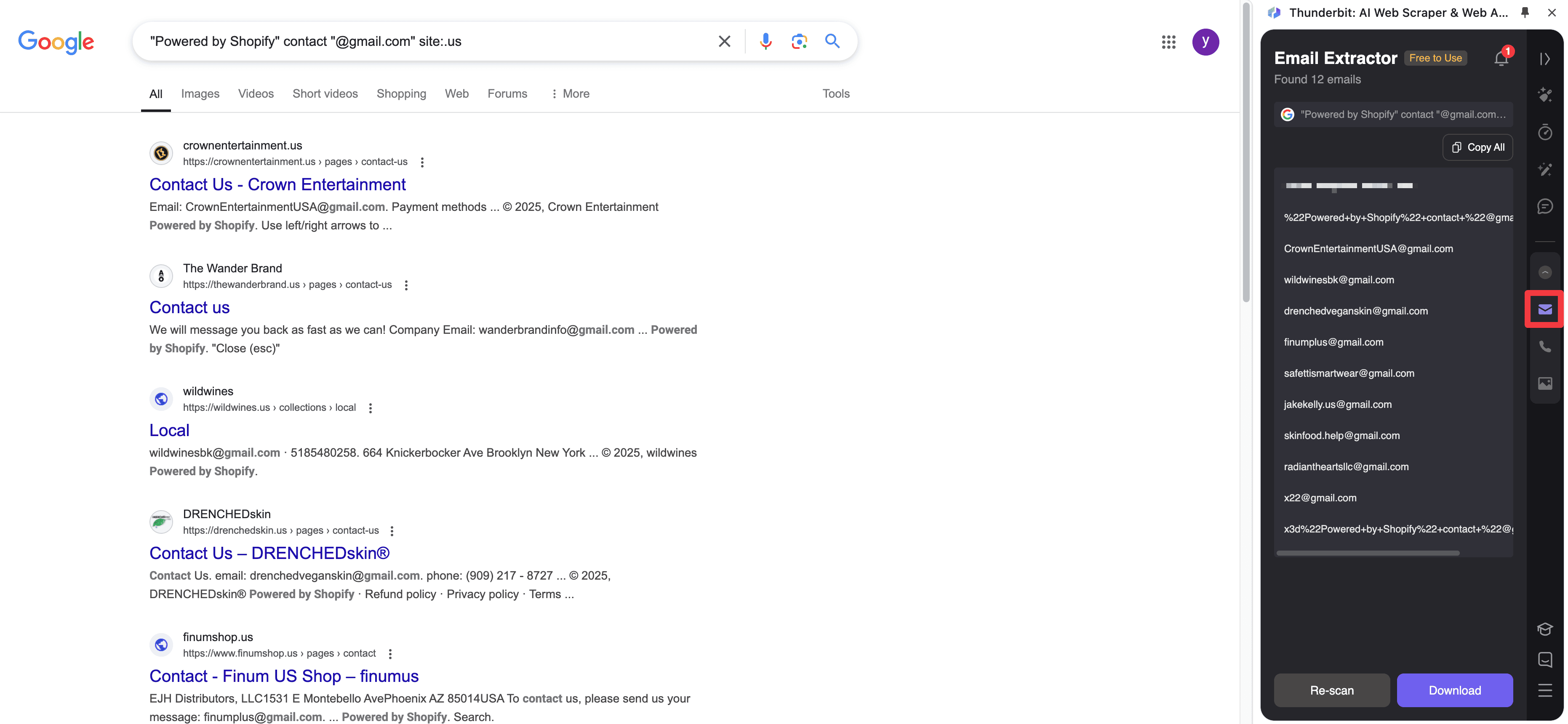
Google 搜尋流程
如果你的潛在客戶來源是從搜尋開始,這個舊示範仍然展示了最快且實用的模式:先搜尋,再從結果集與連結頁面中擷取結構化聯絡欄位。
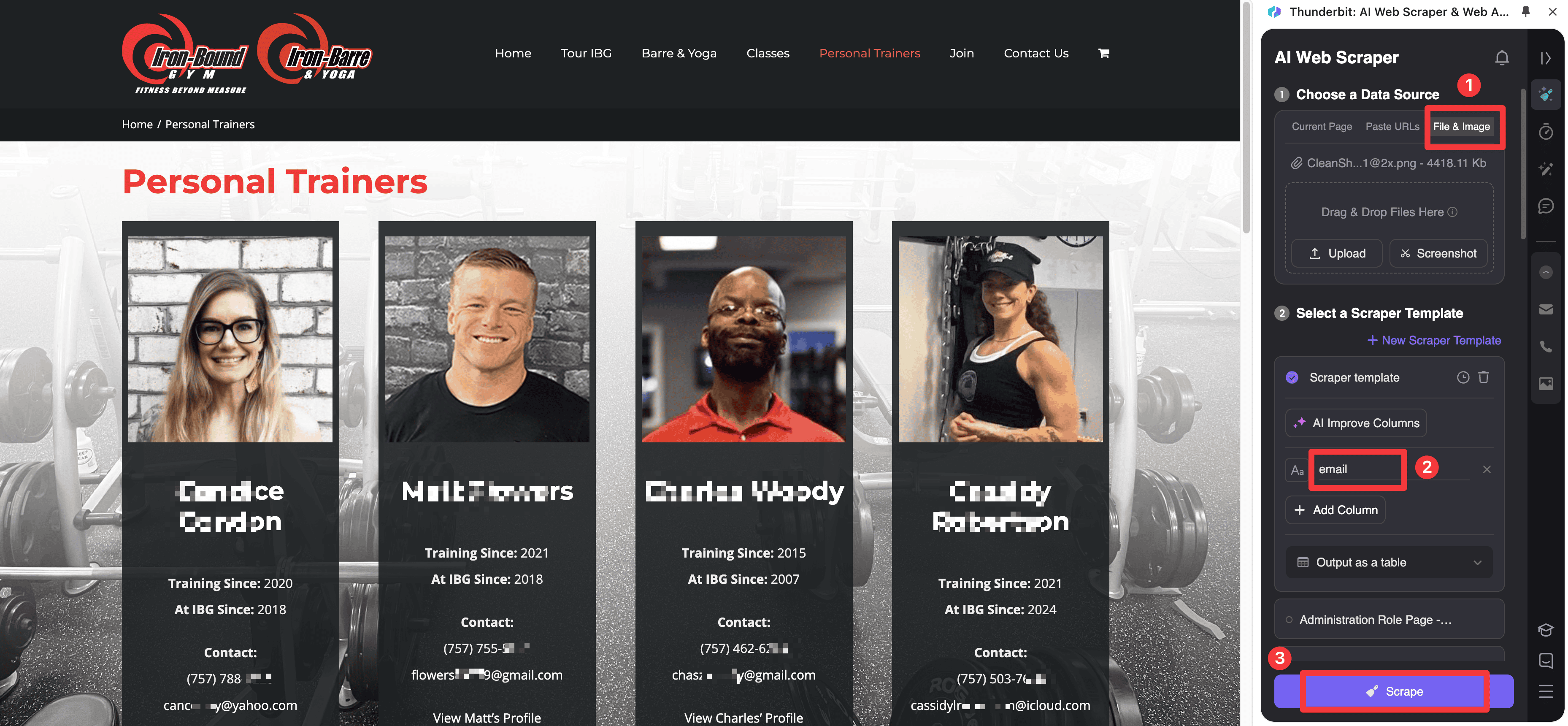
PDF 與圖片擷取
有些最有價值的聯絡資料仍然藏在檔案裡,而不是乾淨的 HTML 頁面。這張截圖值得保留,因為它展示了從文件型來源擷取電子郵件時的實際輸出樣式。
網站名錄流程
名錄頁通常是 AI 輔助擷取比傳統電子郵件尋找器更實用的場景,尤其當每個結果版面略有不同,或把聯絡資訊放到子頁面時更是如此。
供應商資料庫與 LinkedIn 工作流程
舊文章也展示了兩個至今仍然重要的邊界案例:在匯出權限受限時,從供應商式搜尋頁抓取資料,以及在你需要的不只是單一電子郵件地址時,使用以 LinkedIn 為主的資料補全。
2026 年最佳電子郵件抓取工具快速比較表
| 工具 | 價格 संकेत | 核心模式 | 最適合 |
|---|---|---|---|
| Thunderbit | 提供免費方案與付費方案;另有企業定價 | 人工智慧網頁爬蟲與聯絡資訊提取器 | 從網站、PDF 與名錄抓取電子郵件與潛在客戶背景資訊 |
| Snov.io | 年繳方案起價為每月 $29.25 | 尋找器、驗證器與多通路外聯平台 | 適合精簡團隊的一體化外聯 |
| ZoomInfo | 客製化定價 | 企業級聯絡人資料庫與 GTM 工作流程平台 | 大規模、以銷售情報為主的開發 |
| Skrapp.io | 提供免費方案;Professional 年繳起價為每月 $29 | 以 LinkedIn 為主的電子郵件查找器與資料補全 | 以 LinkedIn 為主的潛在客戶開發 |
| Hunter | 提供免費方案;Starter 年繳起價為每月 $34 | 網域搜尋、電子郵件查找器、驗證器與外聯 | 以查找為先、且重視驗證的工作流程 |
| Octoparse | 提供免費方案;Standard 起價為每月 $69 | 免寫程式的網頁抓取平台 | 可重複執行的客製化抓取任務 |
| Lusha | 提供免費方案;付費方案年繳起價為每月 $37.45 | B2B 聯絡資料與資料補全平台 | 已驗證的聯絡資料,以及適合 CRM 的資料補全 |
2026 年 7 款最佳電子郵件抓取工具
1.
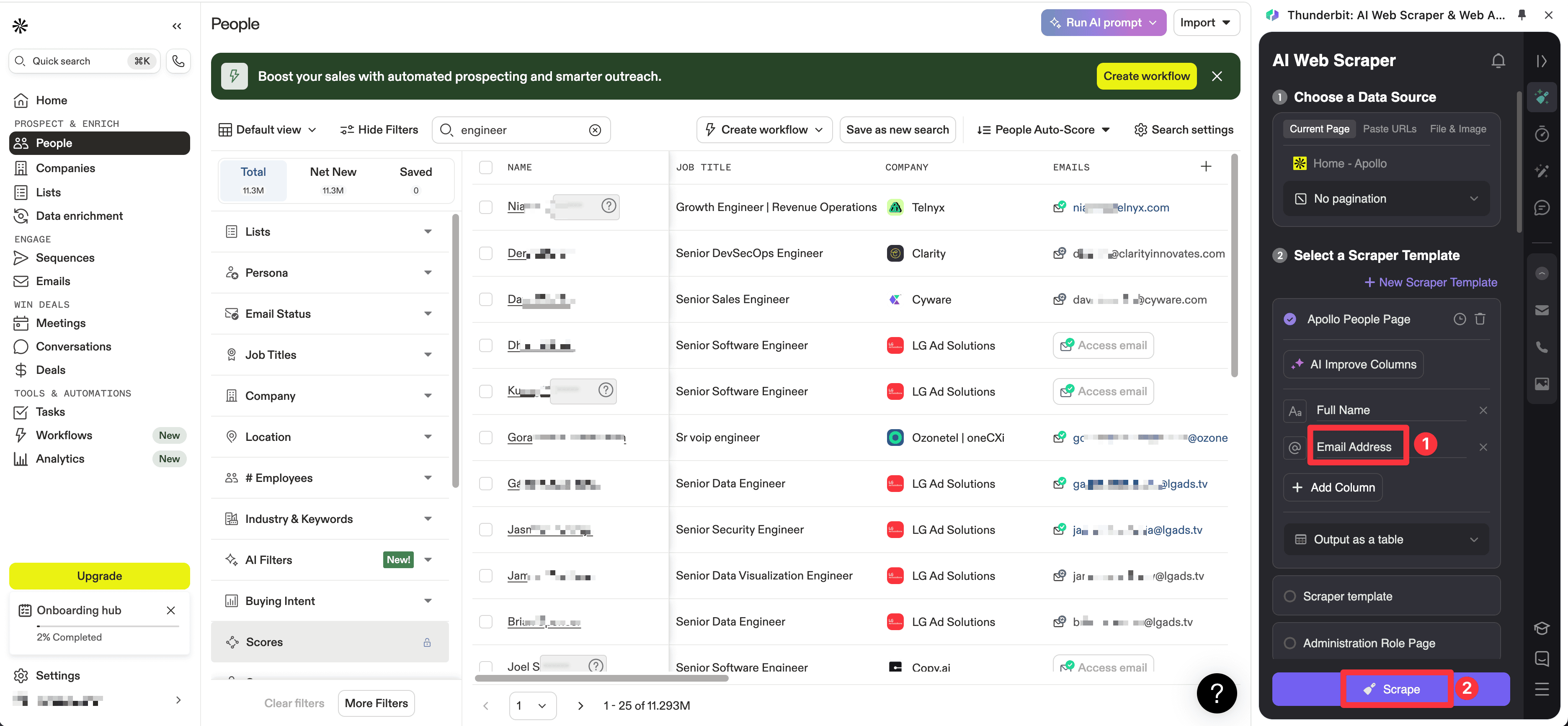
當工作起點在開放網路,而不是商業聯絡人資料庫裡時,Thunderbit 是最強的選擇。它目前的定位簡單而實用:只要點幾下就能抓取網站,用 AI 建議欄位,並在不建立 selector 的情況下匯出結構化結果。
因此,當你的來源是名錄頁、市集清單、在地商家頁、PDF、圖片,或是大型 B2B 資料庫覆蓋不佳的長尾潛在客戶來源時,它會比傳統電子郵件尋找器更適合。
它能入選的原因:
- AI 優先的抓取流程: 很適合不想建立或維護 selector 的非技術團隊。
- 超越標準頁面的電子郵件擷取: 可處理 PDF、圖片與混合版面頁面。
- 不只抓電子郵件,也抓背景脈絡: 可同時擷取姓名、公司資訊、職稱、URL 與備註。
- 快速匯出: 適合 Sheets、Airtable、Notion 與後續的資料補全流程。
價格 संकेत: Thunderbit 目前提供免費方案、付費方案與企業定價。
2.
Snov.io 仍是這個類別中最實用的混合型工具之一,因為它把小團隊常想要的三件事整合在一起:潛在客戶開發、電子郵件驗證,以及多通路外聯。它目前的網站依然把產品定位成潛在客戶開發與外聯自動化平台,而不是單一用途的狹義查找器。
這個定位很重要。如果你的團隊不想分別使用找信箱、驗證信箱、信箱暖機與首封外聯等不同工具,Snov.io 會比拼湊多個小產品更俐落。
團隊仍然會把它列入候選的原因:
- 查找與外聯整合在同一訂閱: 很適合想減少工具分散的新創與代理商。
- 內建驗證: 在活動上線前更能控制退信率。
- 類 CRM 工作流程層: 適合在同一環境中管理潛在客戶與活動。
- 延伸功能與 LinkedIn 流程: 適合以瀏覽器為主的開發模式。
價格 संकेत: Snov.io 的 Starter 方案目前標示為年繳每月 $29.25。
3.
ZoomInfo 會出現在這份清單上,是因為很多聲稱需要「email scraper」的買家,實際上需要的是一個大型 B2B 聯絡人資料庫,再加上層層堆疊的開發工作流程。它目前的 Sales 產品頁主打公司與聯絡人搜尋、潛在客戶開發、買家意圖、工作流程自動化,以及跨更大 GTM 堆疊的資料啟動。
這與純粹的網頁抓取本質上不同。當你的團隊更重視規模、篩選深度與整合式開發營運,而不是來源層級的彈性時,ZoomInfo 就很合理。
企業團隊把它列入候選的原因:
- 大型結構化聯絡人資料庫: 比起單次頁面擷取,更適合帳戶式開發。
- GTM 工作流程層: 當聯絡資料需要流向路由、資料補全或協調流程時特別有用。
- 銷售情報導向: 對大型外聯組織的適配度高於簡單電子郵件工具。
- 平台深度廣: 如果採購本質上是為了開發管道,而不只是查找信箱,它會很有吸引力。
價格 संकेत: ZoomInfo 仍採客製化定價,依產品組合、席次與使用量而定。
4.

Skrapp.io 之所以仍然重要,是因為它把工作流程維持在許多現代開發仍從這裡開始的地方:LinkedIn、Sales Navigator,以及以公司名稱為基礎的搜尋。它目前的產品與價格頁仍強調已驗證的商務電子郵件、公司搜尋、LinkedIn 擷取與輕量資料補全。
這讓它比更大的 GTM 套件更容易評估。如果你的業務代表大多在以個人檔案為起點的開發情境中工作,且主要需求是聯絡資訊發現,那麼 Skrapp 仍然把焦點放在這件事上。
最適合的情境:
- 以 LinkedIn 為主的潛在客戶開發: 很適合從個人檔案與公司頁開始的情境。
- 輕量資料補全: 不必支付大型平台費用也能使用。
- 簡單匯出與 CRM 同步: 方便把潛在客戶名單轉成可執行的外聯資產。
- 營運負擔較低: 對小團隊來說更容易導入。
價格 संकेत: Skrapp.io 目前提供免費方案,Professional 年繳起價為每月 $29。
5.
如果你想要的是以查找為先的產品,而不是更廣泛的銷售平台,Hunter 仍然是最乾淨的答案。它目前的產品與價格頁持續強調 Domain Search、Email Finder、Email Verifier、Discover 與 Sequences。這種清楚很重要。很多團隊其實只需要一種快速方式,把「人名+公司」轉成一個很可能正確、而且有來源依據的工作信箱。
Hunter 仍值得入選的原因:
- 強大的網域搜尋流程: 對理解公司信箱格式特別有用。
- 內建驗證: 在寄信前能更好地維持投遞健康。
- 批次工作流程: 很適合以試算表為基礎的外聯準備。
- 冷郵件後續處理: 如果你希望查找與發送都在同一系統,會很方便。
價格 संकेत: Hunter 的 Starter 方案目前標示為年繳每月 $34,另有免費方案。
如果你想把以查找為主的流程與開放網路抓取做比較,這支 Hunter 官方教學是最清楚的中間點。它展示了資料庫與驗證工具最擅長的流程:先依人名與公司搜尋,再把結果轉成已驗證的工作信箱。
6.
Octoparse 仍在這場討論中,因為有些團隊確實需要的是可設定的爬蟲,而不只是電子郵件尋找器。它目前的價格頁仍以免寫程式的任務設定、雲端擷取、排程、反封鎖附加功能與重複執行任務為主軸。
這讓它在來源網站複雜、分頁很多或經常變動時,比輕量電子郵件提取器更有能力。它的思路不是「打開頁面,按一下匯出」。如果你需要控制力與可重複性,這反而是優勢,而不是缺點。
它的重要性在於:
- 免寫程式任務建立器: 當重複擷取比首次抓取速度更重要時很有用。
- 雲端執行與排程: 適合週期性收集任務。
- 更高的客製化上限: 當電子郵件收集只是更大資料作業的一步時很合適。
- 更廣泛的抓取用途: 比狹義電子郵件尋找工具更適合結構化網站收集。
價格 संकेत: Octoparse 目前提供免費方案,Standard 起價為每月 $69。
7.
Lusha 依然很吸引重視已驗證 B2B 聯絡資料、簡單資料補全與適合 CRM 的工作流程的團隊。它目前的產品與價格頁,把重點放在工作區搜尋、以延伸功能驅動的開發、API 工作流程,以及能餵給外聯系統的準確聯絡資料。
這讓它更接近這個市場中「適合業務代表使用的資料層」,而不是原始抓取層。如果你的團隊更需要經過驗證的聯絡人與資料補全,而不是頁面層級的擷取彈性,Lusha 會比一般爬蟲更合理。
團隊仍在使用它的原因:
- 已驗證的聯絡資料: 當準確性比抓取彈性更重要時特別適合。
- 多種操作介面: 工作區、瀏覽器延伸功能與 API 工作流程。
- CRM 與資料補全導向: 對 RevOps 與外聯團隊很有幫助。
- 商業導入較簡單: 比大型企業平台更容易落地。
價格 संकेत: Lusha 目前提供免費方案,付費方案年繳起價為每月 $37.45。
真正的選擇:抓取彈性 vs 資料庫規模 vs 工作流程簡潔
多數買家不是在抽象地選「最好的工具」,而是在選自己能接受哪種取捨:
- 如果你需要開放網路彈性,Thunderbit 和 Octoparse 通常比資料庫型產品更適合作為起點。
- 如果你需要查找加驗證,Hunter 通常比大型套件更俐落。
- 如果你需要查找加外聯,Snov.io 能提供更完整的輕量堆疊。
- 如果你需要企業級規模的聯絡覆蓋,ZoomInfo 是這裡資料庫導向最強的選項。
- 如果你需要適合業務代表的資料補全與 CRM 工作流程,Lusha 和 Skrapp 的實務操作通常比重型企業平台更容易。
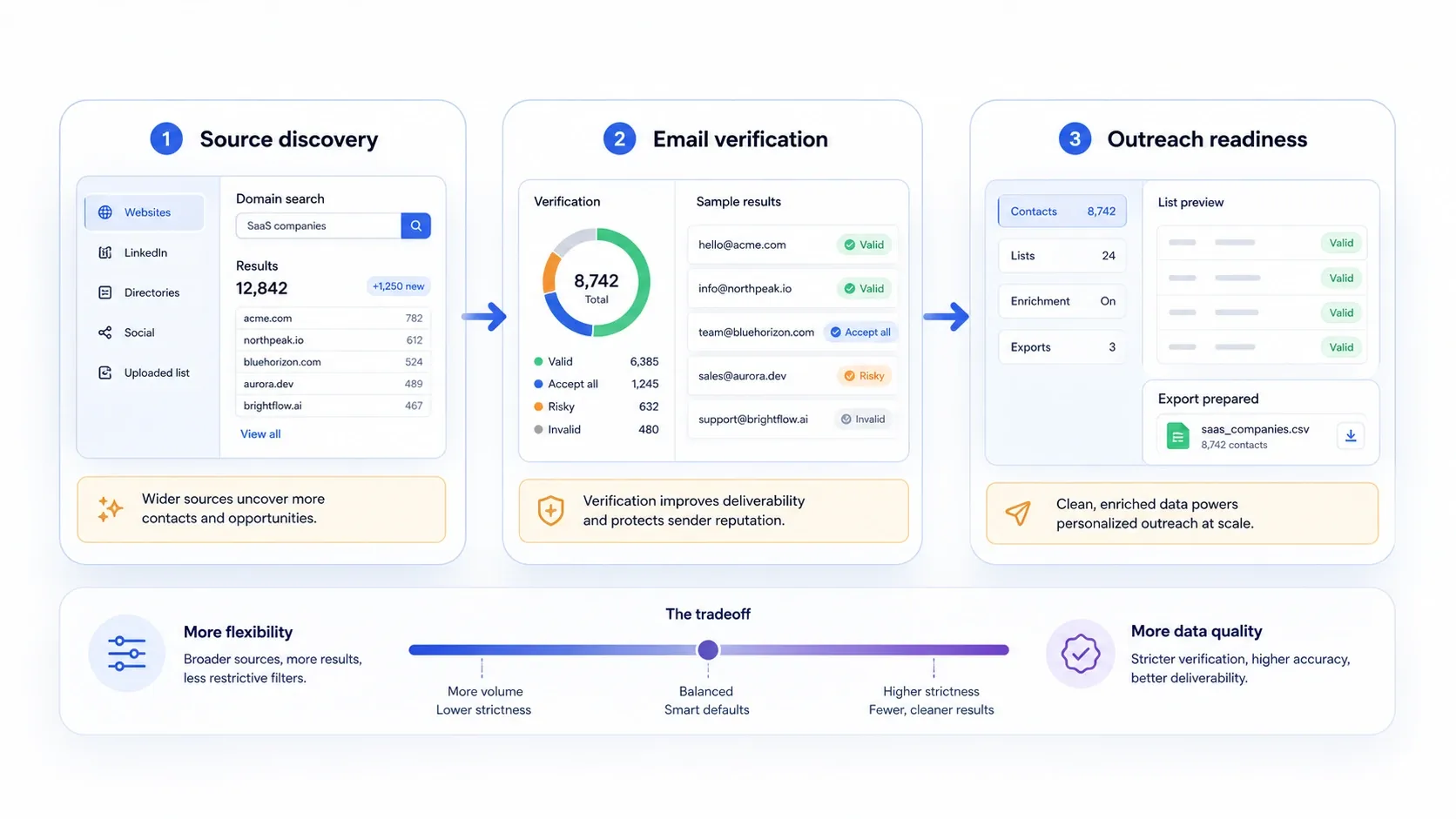
這個區分很重要,因為許多有價值的潛在客戶來源仍然不在精緻的 B2B 資料庫裡:名錄、市集、協會網站、公開 PDF、在地清單、展商頁面,以及搜尋結果流程。如果你的最佳客戶就在這些地方,單靠資料庫一定會有缺口。
Thunderbit 如何融入現代電子郵件抓取堆疊
這正是 Thunderbit 與這個類別中其他工具互補的地方。像 Hunter、Snov.io、Lusha、Skrapp 和 ZoomInfo,在你已經知道要接觸的人、公司或帳戶集合時很有用。Thunderbit 則是在更前面的流程中有用,當問題是先把潛在客戶來源本身蒐集起來時。
你可以這樣使用這套堆疊:
- 用 收集姓名、公司頁、名錄、活動頁、賣家頁、PDF 或清單。
- 將資料列匯出到 Sheets、Excel、Airtable 或 Notion。
- 再用 Hunter、Snov.io、Skrapp、Lusha 或 ZoomInfo 這類查找平台驗證或補上工作信箱。
- 保留來源頁面的脈絡,讓最後的外聯具備真正可用的個人化素材。
這種組合通常比期待單一平台什麼都做好來得更強。

使用任何 Email Scraper 之前的最佳做法
- 先看來源品質,不只看數量。 來自相關公開來源的小名單,通常比大型通用匯出更有價值。
- 每次活動前都先驗證。 職位會變、網域會變,過時資料會傷害寄件者聲譽。
- 保留來源脈絡。 把產生潛在客戶的頁面、清單或 PDF 存下來,讓外聯可以引用真實內容。
- 把擷取與發送分開。 收集品質與投遞品質是不同問題,應分別檢查。
- 尊重合規與相關性。 即使是準確的公開商務聯絡資料,也不代表可以任意發垃圾郵件。
最後這支 Hunter 官方影片很有用,因為它涵蓋了許多團隊在候選清單比較時會跳過的最後一步:當你拿到聯絡資料後,如何在不犧牲名單品質或營運紀律的情況下,把它變成外聯流程?
結論
2026 年最好的電子郵件抓取工具,取決於你真正需要完成的是什麼:
- 如果你的潛在客戶來源在開放網路上,而且你需要快速的 AI 輔助擷取,選 Thunderbit。
- 如果你想要查找、驗證與外聯整合在同一套系統,選 Snov.io。
- 如果你需要資料庫深度與 GTM 工作流程規模,選 ZoomInfo。
- 如果你的團隊高度依賴 LinkedIn 開發,選 Skrapp.io。
- 如果你想要最乾淨的查找加驗證流程,選 Hunter。
- 如果你需要可設定的免寫程式爬蟲來處理更複雜的網站,選 Octoparse。
- 如果你最重視已驗證的 B2B 聯絡資料與適合 CRM 的資料補全,選 Lusha。
如果你的團隊在查找電子郵件之前,還需要先從名錄、市集、在地清單、展商頁面、PDF 或其他長尾公開來源建立潛在客戶名單,先從 開始,再在上層疊加驗證器或查找器。
常見問題
Q1:電子郵件爬蟲和電子郵件尋找器有什麼差別?
A: 電子郵件爬蟲會從公開頁面或檔案中擷取聯絡資料。電子郵件尋找器通常先從人名、公司或網域開始,再把這個輸入比對到可能的工作信箱,通常還會附帶驗證。
Q2:哪個工具最適合直接從網站抓取電子郵件?
A: 在這份清單中,如果來源是即時網站、PDF、圖片或名錄頁,而不是專有的 B2B 資料庫,Thunderbit 是最合適的選擇。
Q3:哪個工具最適合網域搜尋與電子郵件驗證?
A: 如果你想要網域搜尋、電子郵件查找與驗證,而且不想承擔大型外聯平台的額外負擔,Hunter 仍然是最專注的選項。
Q4:ZoomInfo 真的是電子郵件爬蟲嗎?
A: 不是純粹的網頁抓取意義上的爬蟲。它更適合被理解為銷售情報資料庫與開發平台;許多買家會拿它與電子郵件爬蟲比較,是因為最終目標仍然是取得可用的聯絡資料。