
執行摘要
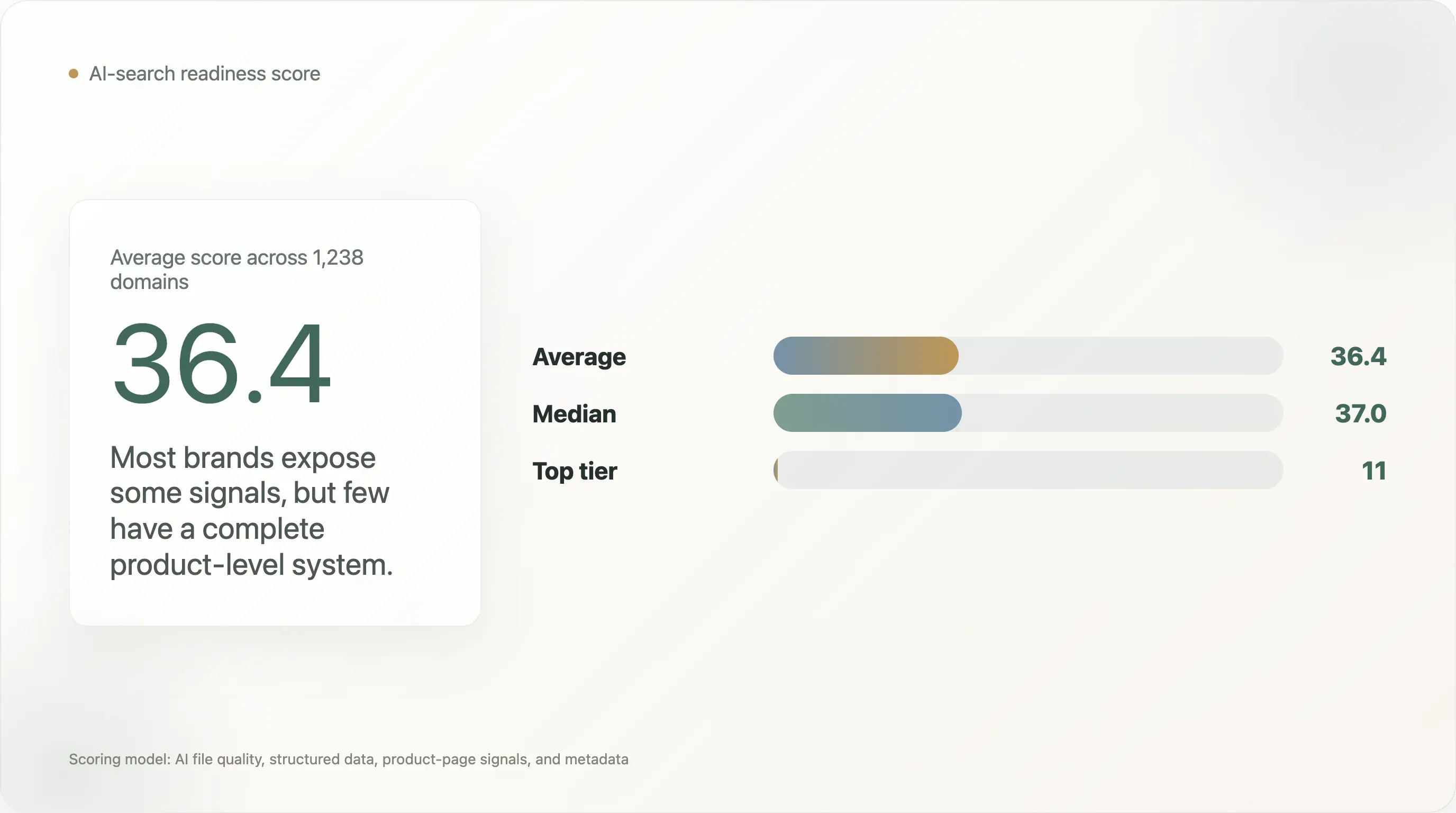
本研究從四個面向評分 1,238 個 DTC 網域 的 AI 搜尋就緒程度:AI 檔案品質、一般結構化資料、產品頁結構化訊號,以及中繼資料。平均分數為 36.4 分(滿分 100),中位數為 37.0。依照這套評分模型,只有 11 個網域 達到 ai_ready 等級。
最重要的發現是:表面上能被搜尋到,和產品層級真的能被理解,兩者之間有明顯落差。規模最大的 llms.txt 品質分組是 platform_default,共有 629 個網域。這表示很多品牌只是因為平台自動產生,就先有了一份基本可供 AI 讀取的檔案。但在被評分的網域中,首頁的 Product schema 只出現在 0.9% 的網域;而在曾嘗試抓取產品頁的網域中,產品頁 Product schema 只出現在 39.2%。產品頁價格訊號出現在 48.1%,評論或評分訊號則出現在 43.5%。
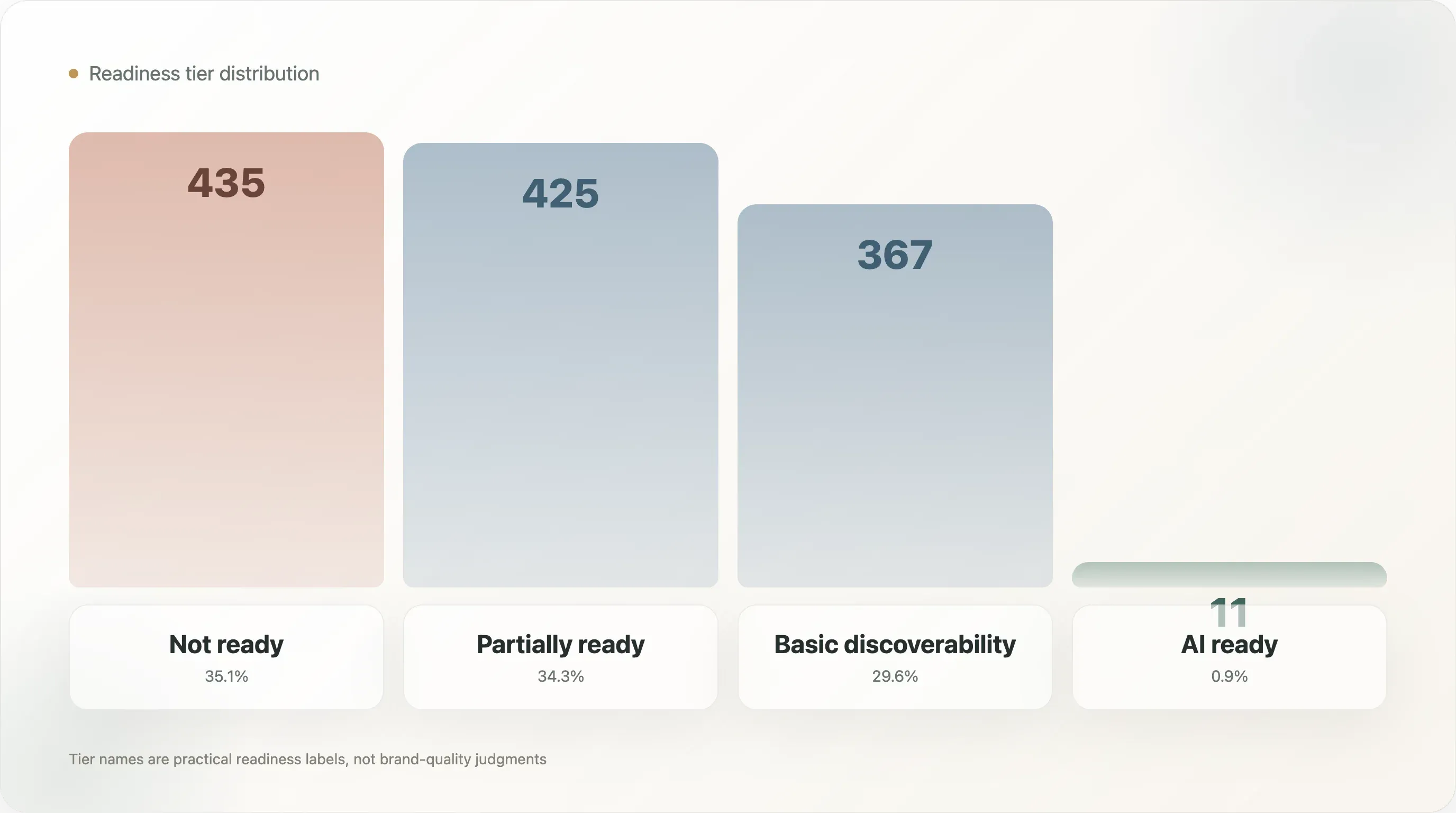
等級分布也顯示市場仍處於非常早期:
| AI 就緒等級 | 網域數 |
|---|---|
| 尚未就緒 | 435 |
| 部分就緒 | 425 |
| 基礎可發現性 | 367 |
| AI 就緒 | 11 |
這樣的分布很有參考價值,因為它把三件常被混為一談的事分開了。品牌可以被找到。品牌可以有中繼資料。品牌也可以有 llms.txt。但「可被發現」不等於「在產品層級可被理解」。
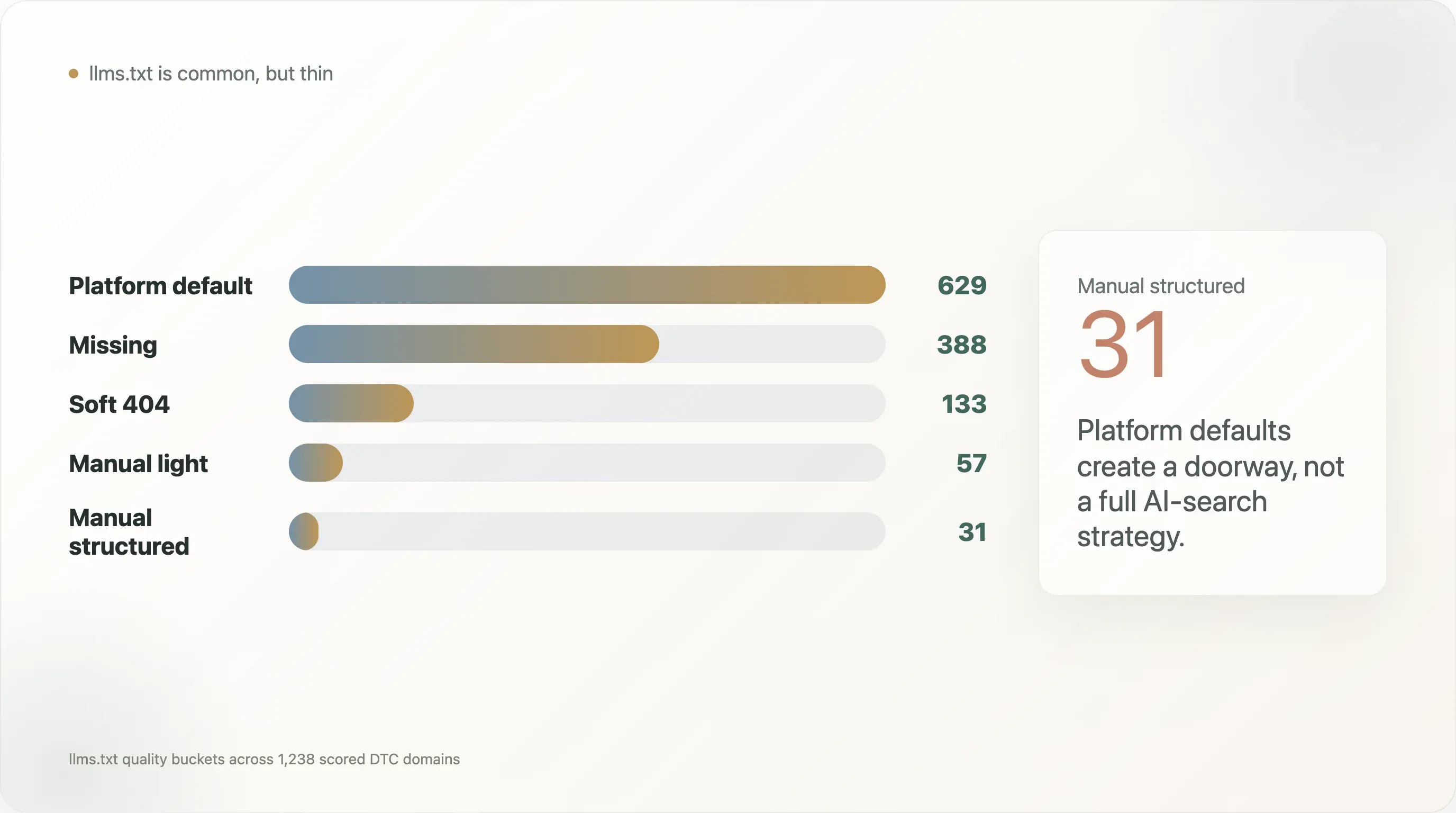
llms.txt 品質分布讓這點更明顯:
| llms.txt 品質分組 | 網域數 |
|---|---|
| 平台預設 | 629 |
| 缺失 | 388 |
| 軟性 404 | 133 |
| 人工簡版 | 57 |
| 人工結構化 | 31 |
因此,這份報告最有力的切入點不是「DTC 品牌有 llms.txt 了」。那個標題太淺。更好的結論是:平台預設檔案為 AI 可發現性打下了薄薄一層基礎,但多數 DTC 品牌還沒建立 AI 購物與答案引擎真正需要的產品層結構化資料。
正面的案例則說明了更好的就緒狀態可能長什麼樣子。ai_ready 等級中的品牌包括 Mokobara、Magic Mind、Le Petit Ballon、Maine Lobster Now、Yo Mama's Foods、La Maison Convertible、Unbloat、NuRange Coffee、Three Ships Beauty 和 Manukora。這些例子很重要,因為它們證明 AI 就緒並不只屬於某一類別或某一種品牌。食品、美妝、保健、家具、服飾與特殊商品電商,都可以把可供機器讀取的產品層做得更完整。
最值得分享的發現
-
DTC 的平均 AI 就緒分數只有 36.4/100。
-
在 1,238 個被評分的網域中,只有 11 個達到
ai_ready等級。 -
llms.txt 很常見,但多半是平台自動生成。 最大的品質分組是平台預設,共有 629 個網域。
-
人工結構化的 llms.txt 很少見。 只有 31 個網域落在人工結構化分組。
-
首頁 Product schema 幾乎缺席。 只出現在 0.9% 的被評分網域中。
-
產品頁 Product schema 表現較好,但仍不完整。 在曾嘗試產品頁抓取的網域中,只有 39.2% 有產品頁 Product schema。
-
AI 購物就緒需要的是產品事實,而不只是爬蟲能進得去。 價格、商品資訊、評論、可用性與產品 schema 訊號,比單一薄檔案更重要。
1. 為什麼 AI 搜尋就緒與 SEO 基礎不同
傳統 SEO 關注的是頁面能不能被抓取、索引、排序與點擊。AI 搜尋則多了一層:系統是否能充分理解品牌、產品、商品資訊、價格、評論、供應情況、政策與實體之間的關係,以便回答問題或推薦商品?
這個差異對 DTC 特別重要,因為電商頁面充滿了人類很容易看懂、但機器卻可能一頭霧水的細節。消費者可以直接看產品頁,理解產品名稱、價格、尺寸、訂閱選項、折扣、評論、庫存狀態與退貨政策。爬蟲或 AI 助理則需要這些事實以一致的方式被表達出來。
中繼資料有幫助。Open Graph 有幫助。canonical 標籤有幫助。llms.txt 也可能幫助爬蟲找到重要內容。但真正的考驗是產品層結構。若 AI 購物助理正在比較五款蛋白粉、保養品、蠟燭、洋裝或咖啡訂閱服務,它需要的是結構化事實。若缺少這些事實,品牌也許看得到,卻無法被可靠理解。
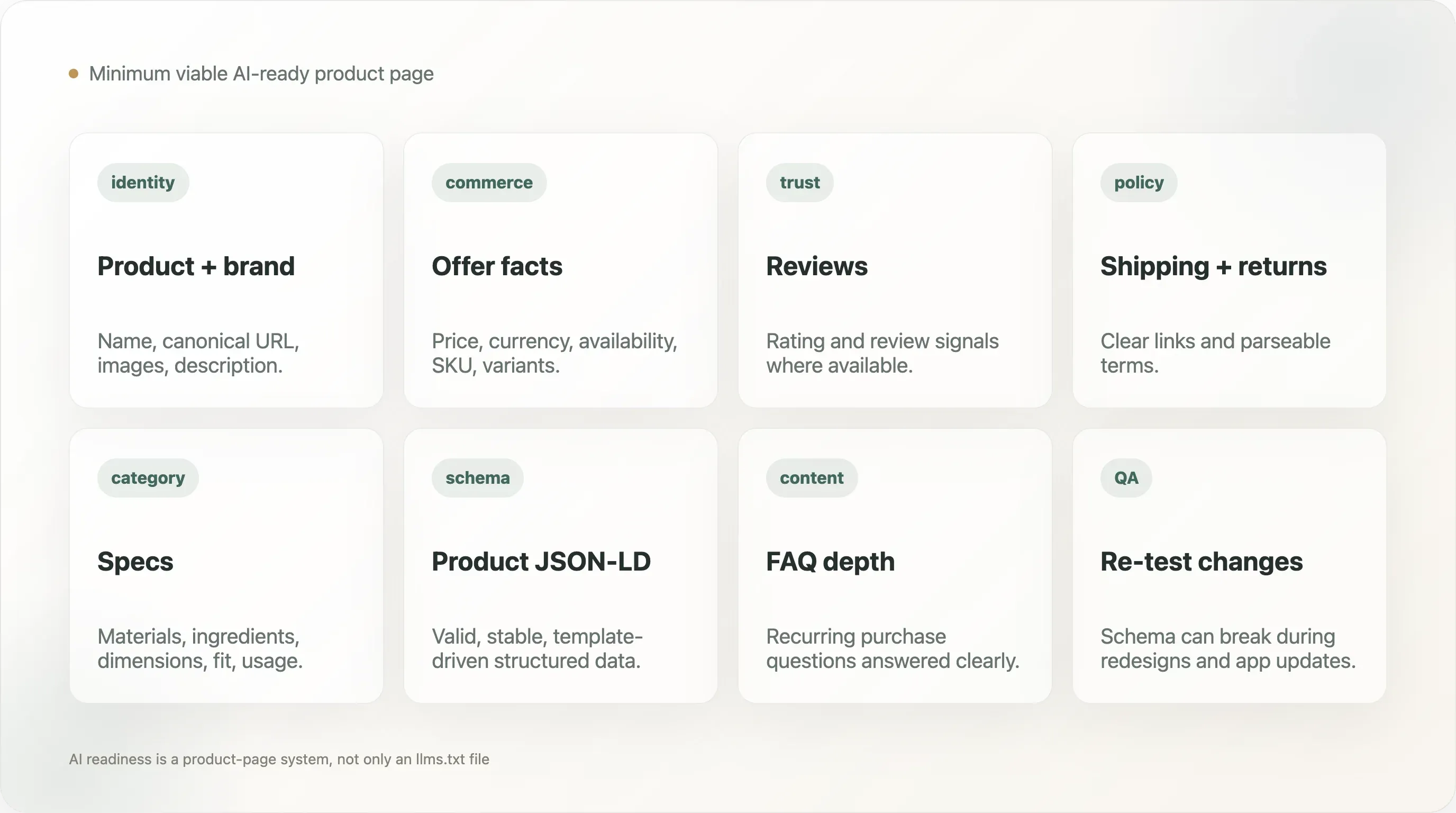
本報告把就緒程度拆成四個層次:
- AI 檔案層: 是否存在 llms.txt,以及它是缺失、軟性 404、平台預設、人工簡版還是人工結構化。
- 一般結構化資料層: JSON-LD、Organization、WebSite、BreadcrumbList 與 Product schema。
- 產品頁層: Product schema、商品資訊或價格訊號、評論或評分訊號,以及可用性訊號。
- 中繼資料層: canonical、meta description、Open Graph 圖片、Twitter card、hreflang 及其他類似的機器可讀上下文。
分層模型之所以重要,是因為它避免了膚淺結論。只有 llms.txt、卻沒有產品事實的品牌,並沒有看起來那麼就緒。沒有 llms.txt、但產品頁 schema 很完整的品牌,可能比檔案層看起來更容易被理解。
2. llms.txt 故事:多半由平台建立的薄薄一層
llms.txt 稽核得到五個品質分組:
| 品質分組 | 網域數 | 解讀 |
|---|---|---|
| 平台預設 | 629 | 標準的平台自動檔案,通常內容薄但有效 |
| 缺失 | 388 | 找不到可用檔案 |
| 軟性 404 | 133 | 回應存在,但內容誤導或沒有實際用途 |
| 人工簡版 | 57 | 人工建立或自訂檔案,但結構有限 |
| 人工結構化 | 31 | 內容較完整的人工檔案,含標題、連結、產品或政策詞彙 |
這是本報告最重要的細節之一。表面上看,llms.txt 的採用率似乎很高,因為平台預設檔案很常見。但平台預設並不等於深思熟慮的 AI 搜尋策略。它往往只是基本的導引層。
這不代表平台預設檔案沒價值。它們可能幫助爬蟲找到重要路徑,也顯示平台層面的決策能多快改變市場。某個平台可以在許多店家還沒正式討論 AI 搜尋營運前,就先替數百個商店新增一份機器可讀檔案。
但人工結構化分組小得多:只有 31 個網域。稽核中可見的人工結構化檔案範例包括來自 Dermalogica、Ad Hoc Atelier、DKNY 等品牌,以及像 Magic Mind、Le Petit Ballon、Maine Lobster Now、Yo Mama's Foods 與 Three Ships Beauty 這些 ai_ready 例子。這些都是很好的正面案例,因為它們展示了如何超越預設檔案:更多連結、更多標題、更多產品詞彙、更多政策詞彙,以及更有意圖的結構。
軟性 404 分組也同樣重要。軟性 404 表示請求有回應,但不是有用的 llms.txt 檔案。這可能誤導簡單的稽核流程。對 AI 搜尋就緒來說,只檢查「有沒有」是不夠的,還要看「好不好」。
3. 產品層結構才是真正的落差
資料中最明顯的缺口是 Product schema。
首頁 Product schema 只出現在 0.9% 的被評分網域。產品頁 Product schema 只出現在 39.2% 的被評分網域中,而且這還是只計入曾嘗試產品頁抓取的情況。產品頁價格訊號出現在 48.1%,評論或評分訊號出現在 43.5%。
這些數字說明得很清楚:即使品牌已經有電商商店,基本產品事實也未必能被機器穩定讀懂。
這一點很重要,因為 AI 搜尋與 AI 購物很可能會獎勵清楚度。若產品頁提供 Product schema、商品資訊、價格、可用性、評論訊號與政策連結,就能讓機器拿到更可靠的事實。若這些事實藏在 JavaScript、格式不一致的模板、圖片或動態元件裡,機器就可能誤解或忽略。
這個就緒落差不只是關於排名,也關於表達。當 AI 系統在摘要某個產品類別、比較選項、回答「最適合什麼」的問題,或產生購物推薦時,產品事實越乾淨的品牌,越容易被準確納入。
ai_ready 群組中的正面例子證明了這點:
- Mokobara 以 83 分拿下輸出中的最高分。
- Magic Mind、Le Petit Ballon 和 Maine Lobster Now 都是 81 分。
- Yo Mama's Foods 為 80 分。
- La Maison Convertible、Unbloat、Vinocheepo 和 NuRange Coffee 都是 79 分。
- Three Ships Beauty 為 77 分。
- Manukora 為 75 分。
這些例子橫跨不同類別。AI 就緒不是只有美妝類或科技類才需要的事。對食品、保健、家具、服飾、特殊商品,以及任何可能有人詢問 AI 系統推薦、比較或解釋的類別,都很重要。
4. AI 就緒等級:多數品牌仍在及格線以下
等級分布如下:
| 等級 | 網域數 | 樣本占比 |
|---|---|---|
| 尚未就緒 | 435 | 35.1% |
| 部分就緒 | 425 | 34.3% |
| 基礎可發現性 | 367 | 29.6% |
| AI 就緒 | 11 | 0.9% |
這些名稱是刻意設計得務實。尚未就緒 不代表品牌不好,只代表這個模型所使用的公開訊號不足以顯示足夠的 AI 搜尋就緒程度。部分就緒 表示已有一些元素,但重要層次仍然缺失。基礎可發現性 表示品牌更容易被機器看見,但可能仍欠缺產品層完整性。AI 就緒 則表示該網域在檔案品質、結構化資料、產品事實與中繼資料的組合上更強。
只有 11 個網域進入最高等級。這是最醒目的標題,但更有用的洞見是中間層的形狀。樣本在尚未就緒、部分就緒與基礎可發現性之間幾乎平均分布。市場並不空白,而是正在過渡。很多品牌已有一些訊號,但很少品牌擁有完整系統。
這代表近程機會很大。AI 搜尋就緒仍在早期,因此品牌只要做些相對實際的工作,就能從一般提升到更強:改善 llms.txt、驗證 schema、曝光產品事實、整理中繼資料,並讓產品頁更容易被機器解析。
5. 類別模式:美妝與服飾領先,但沒有任何類別已完成
類別分類是方向性的,不是絕對精準的。不過,類別表仍然揭示了有用的模式:
| 類別 | 樣本數 | 平均 AI 就緒分數 | 人工或結構化 llms | 產品頁 schema | 產品頁 schema 比率 |
|---|---|---|---|---|---|
| 美妝與保養 | 98 | 46.2 | 3 | 56 | 57.1% |
| 服飾與鞋履 | 149 | 45.7 | 6 | 79 | 53.0% |
| 珠寶與配件 | 34 | 44.5 | 0 | 20 | 58.8% |
| 寵物 | 15 | 43.5 | 0 | 8 | 53.3% |
| 嬰幼兒與兒童 | 27 | 42.6 | 1 | 15 | 55.6% |
| 食品與飲料 | 118 | 42.5 | 5 | 58 | 49.2% |
| 居家與家具 | 48 | 42.3 | 0 | 23 | 47.9% |
| 健康與保健 | 58 | 40.7 | 6 | 27 | 46.6% |
| 戶外與運動 | 49 | 39.8 | 1 | 23 | 46.9% |
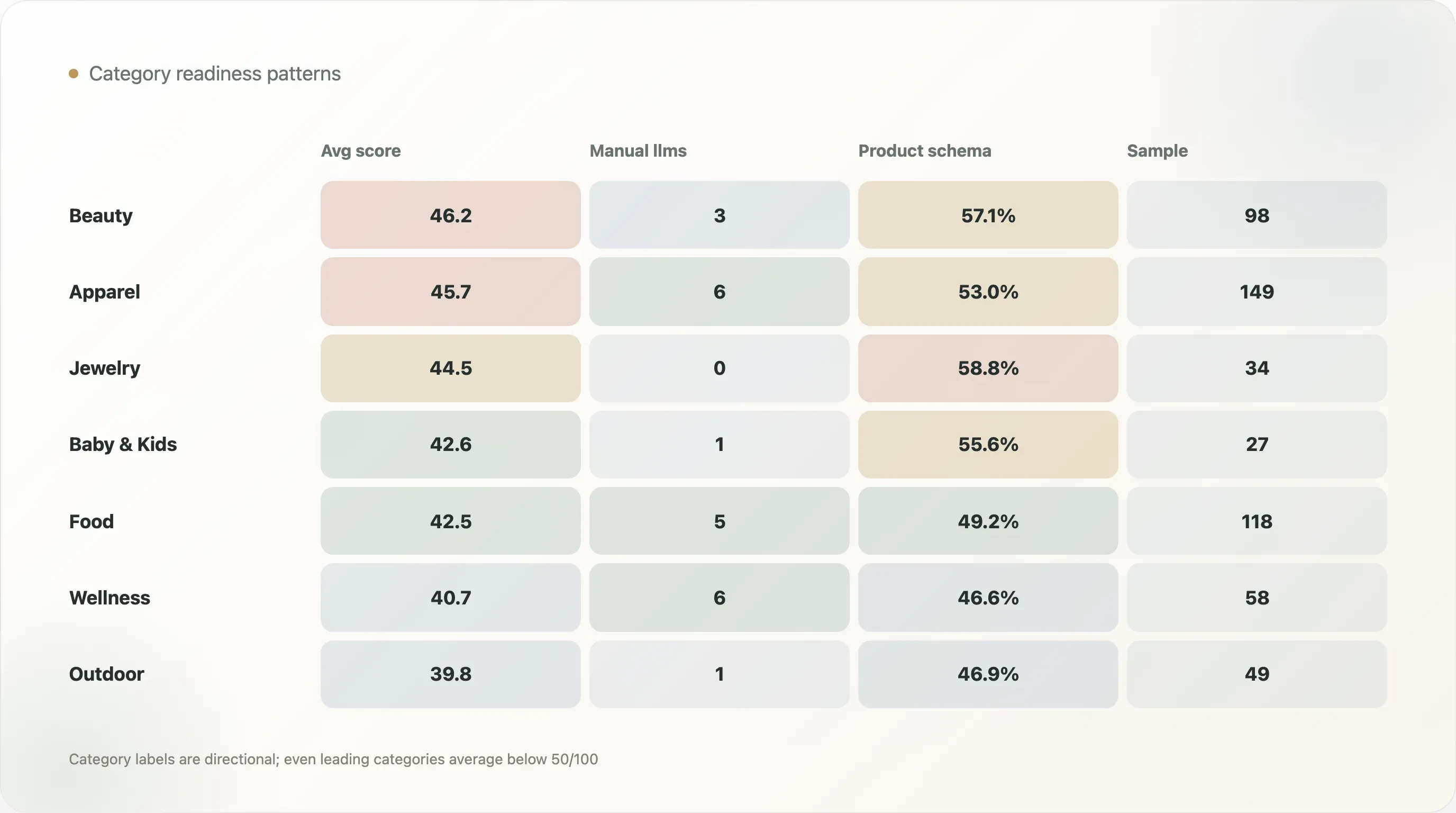
美妝與保養的平均 AI 就緒分數最高,為 46.2。服飾與鞋履緊接在後,為 45.7。這些類別通常擁有更成熟的電商模板、豐富的商品目錄、評論、變體、視覺素材與內容需求,因此也更容易快速受益於結構化產品工作。
珠寶與配件的產品頁 schema 比率高達 58.8%,但在類別表中沒有任何人工或結構化 llms.txt 偵測結果。這正好說明為什麼就緒程度必須分層看待:某個類別可以在產品 schema 上很強,但在 AI 檔案品質上仍然很弱。
食品與飲料包含幾個很強的正面案例,包括 Maine Lobster Now、Yo Mama's Foods、NuRange Coffee 與 Manukora。這很重要,因為食品與飲料產品通常需要非常清楚的事實:成分、營養、份量、訂閱、產地、運送、保存、評論與可用性。只有網站把這些內容清楚曝光,AI 系統才能準確表達。
健康與保健的人工或結構化 llms 比率為 10.3%,是表中主要類別裡最高的,但平均分數只有 40.7。這顯示該類別有些品牌正在積極嘗試 AI 可讀檔案,但產品頁結構仍有不少改善空間。考量到保健領域對信任與教育的要求,這應該是最該積極採用結構化事實的類別之一。
沒有任何類別已經完成。即便領先類別的平均分數也都低於 50/100。這讓針對類別撰寫 AI 就緒內容,成為 SEO 寫手與顧問的一大機會。
6. 好的樣子:來自 AI 就緒品牌的正面模式
ai_ready 群組很小,但很有價值,因為它展示了值得複製的模式。
Mokobara 以 83 分拿下輸出中的最高分。它更像是整體就緒度很高的例子,而不是單一訊號取勝。
Magic Mind、Le Petit Ballon 和 Maine Lobster Now 都拿到 81 分,且落在人工結構化 llms 分組。這很重要,因為它們展示的是有意識的檔案層工作,而不只是平台預設。
Yo Mama's Foods 拿到 80 分,同樣擁有人工結構化 llms。食品品牌特別能從 AI 可讀結構中受益,因為 AI 系統可能被問到成分、口味、使用情境、食譜、飲食相容性與比較。
Three Ships Beauty 拿到 77 分,同樣擁有人工結構化 llms。美妝是很適合結構化 AI 就緒的類別,因為消費者會問膚質、成分、保養步驟、質地、評論與替代品。
Manukora 拿到 75 分。蜂蜜與與保健相關的食品通常需要針對產地、品質、效益、認證與用法進行說明,因此結構化產品與政策訊號特別有價值。
重點不是每個品牌都要長得一模一樣。重點是 AI 就緒是一套系統:
- 有用的 llms.txt 檔案
- 乾淨的中繼資料
- 結構化的 Organization 與 WebSite 資料
- 產品頁 schema
- 價格與商品資訊訊號
- 評論或評分訊號
- 可用性訊號
- 政策與支援說明清楚
任何一層都會有幫助;但把它們組合起來,才真正形成就緒。
7. 為什麼只有 llms.txt 還不夠
llms.txt 已經變成 AI 就緒的便利代稱。這可以理解,因為它看得見、容易檢查,而且夠新,會讓人覺得很有策略性。但這份研究顯示,不能把它當成全部故事。
平台預設的 llms.txt 可以建立一個基本入口。它也許能引導爬蟲找到重要頁面,也可能告訴機器這個網站有一個 AI 可讀入口。但如果產品頁沒有清楚曝光產品事實,那麼入口通往的只是亂糟糟的房間。
AI 搜尋的問題不只是「爬蟲找不找得到網站」,而是:
- 爬蟲能辨識這是什麼產品嗎?
- 它能辨識品牌嗎?
- 它能解析價格嗎?
- 它能解析可用性嗎?
- 它能辨識評論或評分嗎?
- 它能區分產品內容與行銷內容嗎?
- 它能理解政策嗎?
- 它能比較變體嗎?
- 它能引用正確的 canonical 頁面嗎?
llms.txt 有助於導覽與優先排序。結構化產品資料有助於理解。AI 就緒需要兩者兼具。
8. 營運實戰手冊:如何提升 AI 搜尋就緒程度
對 DTC 與電商團隊來說,實際流程其實很直觀。
步驟 1:檢查 AI 檔案層。 網域有沒有 llms.txt?它是真的還是軟性 404?它是平台預設、人工簡版還是結構化?是否有指向有用的頁面?
步驟 2:稽核中繼資料。 確認 canonical 標籤、meta description、Open Graph 圖片、Twitter card、相關的 hreflang,以及行動版 viewport。這些不花俏,但有助於機器建立上下文。
步驟 3:驗證 JSON-LD。 檢查 Organization、WebSite、BreadcrumbList 與 Product schema。Product schema 是電商最重要的缺口。
步驟 4:稽核產品頁,不只是首頁。 AI 購物會重視產品頁。確認產品名稱、描述、圖片、價格、商品資訊、可用性、SKU、評論、評分、變體與退貨政策。
步驟 5:讓產品事實保持穩定。 避免把關鍵產品事實只放在圖片、不易完整渲染的分頁,或爬蟲可能解析不到的 JavaScript 元件裡。
步驟 6:提升政策清晰度。 運送、退貨、訂閱條款、保固、認證與安全聲明,都應該容易找到,也容易解析。
步驟 7:模板變更後重新測試。 schema 常會在重新設計、主題更換、應用程式變更與 headless 遷移時失效。請把結構化資料視為 QA 的一部分。
步驟 8:建立負責機制。 AI 就緒不應只屬於 SEO。它牽涉電商、產品、內容、工程、法務與客服。
9. SEO 與內容團隊可以引用什麼
這份研究提供了幾個很強的引用角度:
「在 1,238 個被評分的 DTC 網域中,只有 11 個達到 AI 就緒等級。」 這是最廣泛的就緒切入點。
「llms.txt 很常見,但多半是平台自動生成。」 平台預設分組有 629 個網域,而人工結構化檔案只有 31 個。
「首頁 Product schema 只出現在 0.9% 的被評分網域。」 這是最尖銳的結構化資料缺口。
「在曾嘗試產品頁抓取的網域中,產品頁 Product schema 只出現在 39.2%。」 這提供了更細緻的觀點:產品頁比首頁好,但仍不完整。
「美妝與服飾領先類別表,但平均仍低於 50/100。」 這能形成具體類別角度。
「AI 就緒是分層的。」 這是最重要的教育重點,讓原本可能把 llms.txt 等同於就緒的讀者重新理解。
但也有一個必須保留的前提:這些資料反映的是本樣本中的公開網站訊號,而不是整個產業的總採用率,也不是內部搜尋表現。
10. AI 購物對 DTC 團隊帶來什麼改變
傳統電商發現方式建立在頁面、排名、廣告與點擊之上。消費者搜尋、比較結果、打開頁面、閱讀評論,再做決定。AI 購物與答案引擎把這段旅程壓縮了。消費者可能直接問「適合平日義大利麵的低糖醬汁」、「200 美元以下、評價好的登機背包」,或「沒有香精、適合敏感肌的溫和潔面乳」。AI 系統甚至可能在消費者看到品牌頁面之前,就先總結選項。
這改變了產品頁的工作。產品頁仍然要說服人,但它也必須把產品描述得夠清楚,讓機器能拿來比較。品牌語氣不夠。漂亮圖片不夠。巧妙的產品名稱也不夠。機器需要的是事實:它是什麼、適合誰、價格多少、是否有貨、有哪些變體、評論怎麼說、哪些主張有支撐、哪些成分或材質重要,以及適用哪些政策。
這就是為什麼產品層結構比一般 AI 檔案更重要。llms.txt 可以幫助爬蟲知道去哪裡找;產品 schema 與乾淨的產品頁事實則幫助它理解找到的是什麼。
對 DTC 品牌來說,風險不只是被排除,而是被錯誤表述。如果產品頁不夠清楚,AI 回答可能會總結錯誤功能、漏掉關鍵差異、忽略重要政策,或拿它和結構更完整的競品做不公平比較。從這個角度看,AI 就緒其實也包含品牌保護。
對考慮路徑較複雜的類別,影響更大。美妝消費者會問膚質、成分、保養步驟、敏感性與效果。食品消費者會問營養、過敏原、產地、口味、食譜與飲食相容性。服飾消費者會問版型、尺寸、材質、退貨與穿搭。保健消費者會問證據、用法、安全與信任。居家消費者會問尺寸、材質、配送、組裝與耐用度。這些本質上都是機器可讀內容問題,不只是行銷問題。
機會在於,多數品牌仍處於早期。平均就緒分數只有 36.4/100,而且只有 11 個網域達到 ai_ready 等級。品牌不需要等到整站重建才開始。可以先從模板、schema、政策清晰度與產品事實著手。
11. 依部門劃分的 AI 就緒計畫
AI 就緒不該只屬於 SEO。它會碰到好幾個團隊。
SEO 負責可發現性與 schema 驗證。 SEO 團隊應稽核 canonical 標籤、中繼資料、結構化資料、Product schema、麵包屑、hreflang 與可抓取性,也要監控產品 schema 是否在主題變更與應用更新後仍然存在。
電商團隊負責產品頁事實。 產品名稱、價格、變體、可用性、組合包、訂閱、評論、運送條件與退貨細節都必須清楚且一致。若這些事實分散在元件、分頁、圖片與腳本中,機器就會難以處理。
內容團隊負責說明深度。 AI 系統偏好能清楚回答問題的頁面。購買指南、比較表、成分說明、使用情境頁、尺寸建議與 FAQ,都能幫助人與機器。
工程團隊負責實作品質。 schema 必須有效、穩定且由模板驅動。產品事實不應完全依賴脆弱的前端渲染。產品頁模板在每次發版後都應測試。
法務與合規團隊負責主張。 若產品涉及健康、永續、安全、成分或效能主張,這些說法必須正確、可支持且容易理解。AI 系統可能會放大不清楚的主張。
客服團隊負責常見問題。 服務單能揭露消費者與 AI 系統可能會問什麼:出貨時間、版型、成分、相容性、退貨、訂閱取消、保養說明與產品比較。這些問題應回流到產品頁內容。
高層負責優先順序。 AI 就緒會和許多其他專案競爭。高層應該理解的是:結構化產品事實不只支援 SEO,也支援 AI 搜尋、產品資料流、付費購物、站內搜尋、客服與轉換率。這不只是 AI 專案。
12. 最小可行的 AI 就緒產品頁
實際可行的 DTC 產品頁應曝光:
- 產品名稱
- 品牌名稱
- canonical URL
- 產品描述
- 產品圖片
- 價格
- 幣別
- 可用性
- 變體資訊
- SKU 或產品識別碼(如適用)
- 評論或評分訊號(如有)
- 商品資訊細節
- 運送與退貨政策連結
- 與類別相關的材質、成分或規格事實
- 針對常見購買問題的 FAQ 或支援內容
頁面也應包含有效的 Product schema,並避免只把關鍵事實藏在圖片或爬蟲可能無法解析的腳本中。這不代表產品頁要無聊;而是要把有說服力的設計,和可靠的結構化事實分開。
對很多品牌來說,最快的勝利不是寫一份很長的 AI 策略文件,而是驗證十個重要產品頁、修好 schema,並確保最重要的產品事實在 HTML 與結構化資料中清楚可見。
方法
本研究使用於 2026 年 5 月 11 日 蒐集的 DTC 雙報表資料集。它透過 master.csv、detection.csv、seo_signals.csv、原始 llms.txt 檔案,以及可取得的原始產品頁 HTML,評分 1,238 個網域。
評分模型分成四個層次:
- AI 檔案層: llms.txt 是否存在與其品質。
- 一般結構化資料層: JSON-LD、Organization、WebSite、BreadcrumbList、Product 與相關結構化訊號。
- 產品頁層: Product schema、商品資訊或價格訊號、評論或評分訊號,以及可用性訊號。
- 中繼資料層: canonical、meta description、Open Graph 圖片、Twitter card、hreflang 與相關頁面上下文。
模型會產生 0 到 100 的 AI 就緒分數,並將網域分到四個等級之一:尚未就緒、部分就緒、基礎可發現性與 ai_ready。
限制與注意事項
-
AI 就緒不等於 AI 流量。 分數不代表實際來自 AI 搜尋系統或購物助理的推薦流量。
-
公開訊號是下限。 有些結構化資料可能是動態載入,或以爬取未捕捉到的方式呈現。
-
llms.txt 品質是推定判斷。 人工結構化檔案是透過可觀察到的檔案特徵來識別,例如標題、連結、產品詞彙與政策詞彙。
-
產品頁偵測取決於已嘗試抓取的產品頁。 產品頁 schema 百分比只適用於曾被嘗試且可取得的產品頁。
-
樣本不是完整的 DTC 普查。 它偏向電商工具生態系與公開 DTC 名單中較可見的品牌。
-
類別標籤是方向性的。 它們適合做大方向比較,但不是精準分類法。
-
AI 搜尋標準仍在演變。 這套評分模型被設計為 2026 年的實用基準,而非永久定義。
可重現性說明
交付資料夾包含:
analyze_ai_search_readiness.py— 用於評估 DTC 網域在llms.txt、結構化資料、產品頁訊號與中繼資料訊號上的評分腳本。ai_search_readiness_scores.csv— 網域層級的 AI 就緒分數、等級與組成訊號。llms_quality_audit.csv— 網域層級的llms.txt品質稽核,包括平台預設、軟性 404、缺失、人工簡版與人工結構化分類。category_ai_readiness.csv— 類別層級的 AI 就緒比較。top_ai_ready_brands.csv— 供編輯審閱與範例選取的高分網域。lowest_ai_ready_brands.csv— 供缺口分析與編輯審閱的低分網域。summary.json— 本報告引用的標題級總體指標,包括樣本數、等級數、平均分數、中位數與產品頁訊號比率。
方法修正、資料集問題與後續分析歡迎來信至 support@thunderbit.com。本報告獨立於 Thunderbit 所持有的任何商業立場發布;我們打造的是 AI 驅動的網頁爬蟲,而我們在結構上也關注公開電商網站能否更容易被人類、搜尋引擎與 AI 助理準確理解。本基準建立於 2026 年 5 月 11 日蒐集的 1,238 個公開網站訊號之 DTC 網域評分。此報告中的資料自成一體。— Thunderbit 研究團隊,2026 年 5 月。