網路上充滿了各式各樣的寶貴數據,但多數網站並不會直接開放下載。到了 2025 年,網頁爬蟲早已從冷門技能,變成各行各業(像是價格監控、職缺搜尋、不動產、競品分析)不可或缺的利器。問題來了,Github 上的爬蟲專案多到讓人眼花撩亂,有些穩定又好用,有些則早已沒人維護、難以上手。那對於非工程師來說,該怎麼挑選適合自己的 github 網頁爬蟲專案?
這篇懶人包會帶你一次看懂 2025 年最值得一試的 15 個 Github 網頁爬蟲專案。不是單純列清單,而是從安裝難易度、適用場景、動態內容支援、維護狀態、資料匯出方式、適合族群等多個面向,幫你快速找到最合適的工具。如果你已經不想再寫程式碼,還會介紹像 這種無程式碼、AI 驅動的工具,讓商業用戶和非技術人員也能輕鬆搞定。
我們怎麼挑出這 15 個 Github 網頁爬蟲專案?
老實說,Github 上的專案品質參差不齊。有些經過大量用戶驗證,有些只是週末玩票性質。這次精選的標準如下:
- Github 星數與社群活躍度: 從幾千到九萬多星,且有活躍貢獻者的專案。
- 近期有更新: 2025 年還有維護,不是被遺忘的「化石」。
- 文件與易用性: 文件清楚、範例齊全、學習曲線合理。
- 實際應用: 有被企業或學術界實際採用,而不是只有「Hello World」等級。
另外,因為每個人需求不同,我們還會從這些角度比較:
- 安裝與設定難度: 幾分鐘就能上手,還是要搞一堆依賴和驅動?
- 適用場景: 適合電商、新聞、研究還是其他領域?
- 動態網頁支援: 能不能處理現代 JavaScript 網站?
- 專案活躍度: 是否持續維護,還是早就停更?
- 資料匯出方式: 能不能直接產出可用的結構化資料?
- 適合族群: 適合 Python 新手、數據工程師,還是非技術團隊?
每個專案都會有快速標籤,讓你一眼就能找到最適合自己的選擇——不管你是程式高手,還是只想把資料丟進 Google Sheet。

安裝與設定難度:最快多久能開始爬?
對大多數人來說,最大門檻就是「怎麼讓爬蟲跑起來」。這裡把難度分成三種:
- 即裝即用(零設定): 安裝就能用,超適合新手。
- 中等(指令列、簡單程式碼): 需要寫點程式或用 CLI,但有經驗者很快就能上手。
- 進階(驅動、反爬、深度開發): 需要設定環境、瀏覽器驅動,或有較高程式能力。
主要專案分類如下:
- 即裝即用: MechanicalSoup(Python)、Nokogiri(Ruby)、Maxun(部署後給終端用戶)
- 中等: Scrapy、Crawlee、Node Crawler、Selenium、Playwright、Colly、Puppeteer、Katana、Scrapling、WebMagic
- 進階: Heritrix、Apache Nutch(需 Java、設定檔或大數據環境)
如果你不是工程師,建議選「即裝即用」或無程式碼工具。其他人則可依需求選「中等」難度,基本不會太難——除非你真的很怕大括號。
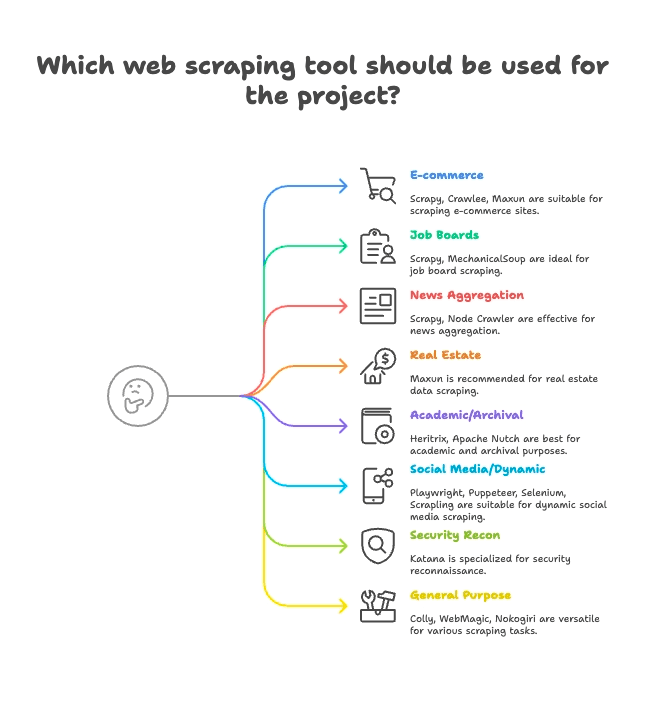
依產業場景分組:找對你的爬蟲
不同爬蟲適合不同任務,以下依最佳應用場景分組:
電商與價格監控
- Scrapy: 適合大規模、多頁商品爬取
- Crawlee: 靜態、動態電商網站都能搞定
- Maxun: 無程式碼,快速抓商品清單
職缺網站與招募
- Scrapy: 支援分頁、結構化職缺列表
- MechanicalSoup: 適合需要登入的職缺網站
新聞與內容聚合
- Scrapy: 大型新聞網站爬取
- Node Crawler: 靜態新聞聚合超快
不動產
- Thunderbit: AI 智能抓取列表與詳情頁
- Maxun: 視覺化選取房產資料
學術研究與網頁存檔
- Heritrix: 全站存檔(WARC 格式)
- Apache Nutch: 分散式爬取研究數據
社群媒體與動態內容
- Playwright、Puppeteer、Selenium: 動態內容、模擬登入
- Scrapling: 反爬蟲、隱身爬取
資安與偵查
- Katana: 快速發現 URL、資安爬取
通用型爬蟲
- Colly: Go 語言高效能爬蟲
- WebMagic: Java 彈性框架
- Nokogiri: Ruby 解析器
動態網頁支援:這些 Github 專案能抓現代網站嗎?
現在的網站大量用 JavaScript(像 React、Vue、無限滾動、AJAX),如果你曾經爬到一片空白就知道有多崩潰。
各專案對動態內容的支援如下:
- 完整 JS 支援(無頭瀏覽器):
- Selenium: 控制真實瀏覽器,完整執行 JS
- Playwright: 多瀏覽器、多語言,JS 支援超強
- Puppeteer: 無頭 Chrome/Firefox,完整渲染 JS
- Crawlee: 可切換 HTTP/瀏覽器模式(整合 Puppeteer/Playwright)
- Katana: 可選無頭模式解析 JS
- Scrapling: 整合 Playwright,隱身 JS 爬取
- Maxun: 內建瀏覽器,支援動態內容
- 無原生 JS 支援(只抓靜態 HTML):
- Scrapy: 需搭配 Selenium/Playwright 外掛
- MechanicalSoup、Node Crawler、Colly、WebMagic、Nokogiri、Heritrix、Apache Nutch: 只抓 HTML,無法直接處理 JS
Thunderbit 的 AI 在這方面特別強大:自動偵測並抓取動態內容,完全不用手動設定、外掛或選擇器。只要點「AI 建議欄位」,就算是 React 網站也能輕鬆搞定。想知道更多,請參考 。
專案活躍度與穩定性:明年還能用嗎?
最怕就是好不容易建好流程,結果工具被棄坑。各大專案維護狀況如下:
- 持續活躍(頻繁更新):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- 穩定但更新較慢:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- 維護模式(專用型、更新慢):
- Heritrix:
- Apache Nutch:
Thunderbit 屬於雲端託管服務,完全不用擔心專案被棄坑。我們團隊會持續更新 AI、範本與整合,還有新手教學和專屬客服協助。
資料處理與匯出:從原始 HTML 到商業可用數據
抓到資料只是第一步,還要能方便地匯出成團隊可用的格式(像 CSV、Excel、Google Sheets、Airtable、Notion,甚至 API)。
- 內建結構化匯出:
- Scrapy: 支援 CSV、JSON、XML
- Crawlee: 彈性資料集與儲存
- Maxun: CSV、Excel、Google Sheets、JSON API
- Thunderbit:
- 手動處理(需自己寫程式):
- MechanicalSoup、Node Crawler、Selenium、Playwright、Puppeteer、Colly、WebMagic、Nokogiri、Scrapling: 需自己寫程式儲存/匯出
- 專用格式匯出:
- Heritrix: WARC(網頁存檔格式)
- Apache Nutch: 原始內容存入儲存/索引
Thunderbit 的結構化匯出和多平台整合,對商業用戶來說超級省時。再也不用手動處理 CSV 或寫「膠水程式」,一鍵就能直接用。
適合族群:每個 Github 爬蟲專案適合誰?
不是每個工具都適合所有人,以下是建議對象:
- Python 新手: MechanicalSoup、Scrapling(進階者)
- 數據工程師: Scrapy、Crawlee、Colly、WebMagic、Node Crawler
- 測試/自動化專家: Selenium、Playwright、Puppeteer
- 資安研究員: Katana
- Ruby 開發者: Nokogiri
- Java 開發者: WebMagic、Heritrix、Apache Nutch
- 非技術/商業團隊: Maxun、Thunderbit
- 成長駭客、分析師: Maxun、Thunderbit
如果你不想寫程式,只想快速拿到結果,Thunderbit 和 Maxun 絕對是首選。其他人則可依語言和需求挑選。
15 大 Github 網頁爬蟲專案詳細比較
以下依應用場景分組,並附上重點標籤:
電商、價格監控與通用爬取
— 57.1k 星,2025/6 更新

- 簡介: 高階、非同步 Python 框架,適合大規模爬取。
- 安裝: 中等(需 Python 程式、非同步框架)
- 應用: 電商、新聞、研究、多頁爬蟲
- JS 支援: 無(需外掛 Selenium/Playwright)
- 維護: 積極維護
- 匯出: 內建 CSV、JSON、XML
- 適合: 開發者、數據工程師
- 亮點: 可擴展性高、外掛豐富,新手學習曲線較陡。
— 17.9k 星,2025

- 簡介: 功能完整的 Node.js 靜態/動態網頁爬蟲庫。
- 安裝: 中等(Node/TS 程式)
- 應用: 電商、社群、流程自動化
- JS 支援: 有(整合 Puppeteer/Playwright)
- 維護: 非常活躍
- 匯出: 彈性資料集、儲存
- 適合: JS/TS 團隊
- 亮點: 反封鎖工具包,HTTP/瀏覽器模式切換方便。
— 13k 星,2025/6

- 簡介: 開源無程式碼網頁資料擷取平台,視覺化操作。
- 安裝: 中等(需伺服器部署),終端用戶簡單
- 應用: 通用、電商、商業數據
- JS 支援: 有(內建瀏覽器)
- 維護: 積極成長
- 匯出: CSV、Excel、Google Sheets、JSON API
- 適合: 非技術用戶、分析師、團隊
- 亮點: 點選式爬取、多層級導航、自架部署。
職缺網站、招募與簡單互動
— 4.8k 星,2024

- 簡介: Python 函式庫,適合自動填表與簡單瀏覽。
- 安裝: 即裝即用(Python,程式碼極少)
- 應用: 需登入的職缺網站、靜態頁面
- JS 支援: 無
- 維護: 穩定、偶有更新
- 匯出: 無內建(需手動)
- 適合: Python 新手、快速腳本
- 亮點: 幾行程式就能模擬瀏覽器,不適合動態網站。
新聞聚合與靜態內容
— 6.8k 星,2024

- 簡介: 伺服器端高併發爬蟲,整合 Cheerio 解析。
- 安裝: 中等(Node 回呼/非同步)
- 應用: 新聞、靜態內容高速爬取
- JS 支援: 無(僅 HTML)
- 維護: 中度活躍(v2 beta)
- 匯出: 無內建(需自訂)
- 適合: Node.js 開發者、高併發需求
- 亮點: 非同步爬取、速率限制、jQuery 風格 API。
不動產、列表與子頁爬取

- 簡介: AI 驅動、無程式碼網頁爬蟲,專為商業用戶設計。
- 安裝: 即裝即用(Chrome 擴充,2 步驟完成)
- 應用: 不動產、電商、銷售、行銷、任何網站
- JS 支援: 有(AI 自動偵測動態內容)
- 維護: 持續更新、雲端託管
- 匯出: 一鍵匯出 Sheets、Airtable、Notion、CSV、JSON
- 適合: 非技術用戶、商業團隊、銷售、行銷
- 亮點: AI「建議欄位」、子頁爬取、即時匯出、完整教學、範本、。
學術研究與網頁存檔
— 3k 星,2023

- 簡介: Internet Archive 官方網頁存檔爬蟲。
- 安裝: 進階(Java 應用、設定檔)
- 應用: 網頁存檔、全域爬取
- JS 支援: 無(僅抓取)
- 維護: 穩定維護(更新較慢)
- 匯出: WARC(網頁存檔格式)
- 適合: 檔案館、圖書館、機構
- 亮點: 可擴展、穩定、標準合規。不適合目標式爬取。
— 3k 星,2024

- 簡介: 開源大數據、搜尋引擎爬蟲。
- 安裝: 進階(需 Java+Hadoop)
- 應用: 搜尋引擎爬取、大數據
- JS 支援: 無(僅 HTTP)
- 維護: Apache 持續維護
- 匯出: 原始內容存入儲存/索引
- 適合: 企業、大數據、學術研究
- 亮點: 外掛架構、分散式爬取。
社群媒體、動態內容與自動化
— 約 30k 星,2025

- 簡介: 瀏覽器自動化,支援所有主流瀏覽器。
- 安裝: 中等(需驅動、多語言)
- 應用: JS 重度網站、流程測試、社群媒體
- JS 支援: 有(完整瀏覽器自動化)
- 維護: 穩定活躍
- 匯出: 無(需手動)
- 適合: 測試工程師、開發者
- 亮點: 多語言、模擬真實用戶行為。
— 73.5k 星,2025

- 簡介: 現代瀏覽器自動化,適合爬蟲與 E2E 測試。
- 安裝: 中等(多語言腳本)
- 應用: 現代網頁、社群、流程自動化
- JS 支援: 有(無頭或真實瀏覽器)
- 維護: 非常活躍
- 匯出: 無(需自訂)
- 適合: 需強大瀏覽器控制的開發者
- 亮點: 跨瀏覽器、自動等待、網路攔截。
— 90.9k 星,2025

- 簡介: Chrome/Firefox 自動化高階 API。
- 安裝: 中等(Node 腳本)
- 應用: 無頭 Chrome 爬取、動態內容
- JS 支援: 有(Chrome/Firefox)
- 維護: Chrome 團隊維護
- 匯出: 無(需自訂)
- 適合: Node.js、前端開發者
- 亮點: 瀏覽器控制豐富、截圖、PDF、網路攔截。
— 5.4k 星,2025/6

- 簡介: 具備反爬蟲功能的高效能隱身爬蟲。
- 安裝: 中等(Python 程式)
- 應用: 隱身爬取、反封鎖、動態網站
- JS 支援: 有(整合 Playwright)
- 維護: 積極、前沿
- 匯出: 無內建(需手動)
- 適合: Python 開發者、駭客、數據工程師
- 亮點: 隱身、代理、反封鎖、非同步。
資安偵查
— 13.8k 星,2025

- 簡介: 快速網頁爬蟲,適合資安、連結發現。
- 安裝: 中等(CLI 工具或 Go 函式庫)
- 應用: 資安爬取、端點發現
- JS 支援: 有(可選無頭模式)
- 維護: ProjectDiscovery 積極維護
- 匯出: 純文字(URL 清單)
- 適合: 資安研究員、Go 開發者
- 亮點: 速度快、高併發、JS 解析。
通用型爬蟲
— 24.3k 星,2025

- 簡介: Go 語言高效能爬蟲框架。
- 安裝: 中等(Go 程式)
- 應用: 高效能、通用型爬取
- JS 支援: 無(僅 HTML)
- 維護: 積極、近期提交
- 匯出: 無內建(需自訂)
- 適合: Go 開發者、效能導向
- 亮點: 非同步、速率限制、分散式爬取。
— 11.6k 星,2023

- 簡介: 彈性 Java 爬蟲框架,類似 Scrapy。
- 安裝: 中等(Java,API 簡單)
- 應用: Java 通用型爬取
- JS 支援: 無(可擴充 Selenium)
- 維護: 社群活躍
- 匯出: 可插拔管線
- 適合: Java 開發者
- 亮點: 執行緒池、排程、反封鎖。
— 6.2k 星,2025

- 簡介: Ruby 原生 HTML/XML 解析器。
- 安裝: 即裝即用(Ruby gem)
- 應用: Ruby 應用中的 HTML/XML 解析
- JS 支援: 無(僅解析)
- 維護: 積極,緊跟 Ruby
- 匯出: 無(用 Ruby 處理)
- 適合: Ruby 開發者、Rails 團隊
- 亮點: 速度快、合規、安全預設。
一覽表:功能比較
這裡有一張快速比較表,並加上 Thunderbit 供你參考:
| 專案 | 安裝難度 | 應用場景 | JS 支援 | 維護狀態 | 資料匯出 | 適合族群 | Github 星數 |
|---|---|---|---|---|---|---|---|
| Scrapy | 中等 | 電商、新聞 | 無 | 積極 | CSV、JSON、XML | 開發者、數據工程師 | 57.1k |
| Crawlee | 中等 | 多元、流程自動化 | 有 | 非常活躍 | 彈性資料集 | JS/TS 團隊 | 17.9k |
| MechanicalSoup | 即裝即用 | 靜態、表單 | 無 | 穩定 | 無(手動) | Python 新手 | 4.8k |
| Node Crawler | 中等 | 新聞、靜態 | 無 | 中度活躍 | 無(手動) | Node.js 開發者 | 6.8k |
| Selenium | 中等 | JS 重度、測試 | 有 | 穩定 | 無(手動) | 測試工程師、開發者 | ~30k |
| Heritrix | 進階 | 存檔、研究 | 無 | 穩定 | WARC | 檔案館、機構 | 3k |
| Apache Nutch | 進階 | 大數據、搜尋 | 無 | 積極 | 原始內容 | 企業、研究 | 3k |
| WebMagic | 中等 | Java、通用 | 無 | 社群活躍 | 可插拔管線 | Java 開發者 | 11.6k |
| Nokogiri | 即裝即用 | Ruby 解析 | 無 | 積極 | 無(手動) | Ruby 開發者 | 6.2k |
| Playwright | 中等 | 動態、自動化 | 有 | 非常活躍 | 無(手動) | 開發者、QA | 73.5k |
| Katana | 中等 | 資安、發現 | 有 | 積極 | 純文字 | 資安、Go 開發者 | 13.8k |
| Colly | 中等 | 高效能、通用 | 無 | 積極 | 無(手動) | Go 開發者 | 24.3k |
| Puppeteer | 中等 | 動態、自動化 | 有 | 穩定 | 無(手動) | Node.js 開發者 | 90.9k |
| Maxun | 簡單(用戶) | 無程式碼、商業 | 有 | 積極 | CSV、Excel、Sheets、API | 非技術、分析師 | 13k |
| Scrapling | 中等 | 隱身、反爬 | 有 | 積極 | 無(手動) | Python 開發者、駭客 | 5.4k |
| Thunderbit | 即裝即用 | 無程式碼、商業 | 有 | 雲端託管、持續更新 | Sheets、Airtable、Notion | 非技術、商業用戶 | N/A |
為什麼 Thunderbit 是非技術與商業用戶的最佳選擇?
說真的,大多數 Github 開源專案都是「工程師寫給工程師」用的,安裝、維護、除錯都要自己來。如果你是商業用戶、行銷、業務,或只想要結果、不想被正則表達式搞瘋,Thunderbit 就是為你量身打造。
Thunderbit 的優勢:
- 無程式碼、AI 智能操作: 安裝 ,點「AI 建議欄位」就能開始爬取,完全不用寫程式、選擇器或安裝套件。
- 動態網頁支援: Thunderbit AI 能自動讀取並擷取現代 JS 網站(像 React、Vue、AJAX),完全不用手動設定。
- 子頁爬取: 需要抓每個商品或列表詳情?Thunderbit AI 可自動點擊子頁並合併資料,完全不用自訂程式。
- 商業級匯出: 一鍵匯出 Google Sheets、Airtable、Notion、CSV、JSON,超適合銷售名單、價格監控、內容聚合。
- 持續更新與支援: Thunderbit 是雲端託管服務,完全不用擔心「棄坑」,還有新手教學、範本庫和專屬客服。
- 適合族群: Thunderbit 專為非技術用戶、商業團隊,以及重視效率與穩定性的用戶設計。
不只我們這麼說——全球超過 3 萬用戶信賴 Thunderbit,包括 Accenture、Grammarly、Puma 等知名團隊。我們也曾獲得 Product Hunt「本週最佳產品」殊榮。
想體驗爬蟲有多簡單,。
結語:2025 年如何選對網頁爬蟲方案?
總結來說,Github 上有一堆強大的爬蟲工具,但大多數都是為工程師設計。如果你熱愛寫程式,Scrapy、Crawlee、Playwright、Colly 這些框架能給你最大彈性。如果你在學術或資安領域,Heritrix、Nutch、Katana 會是首選。
但如果你是商業用戶、分析師,或只想快速拿到結構化、可用的資料,Thunderbit 絕對是最佳解。無需安裝、無需維護、無需寫程式,直接拿到結果。
下一步?你可以根據自己的技能和需求,試試看合適的 Github 專案;或者,想省下學習曲線、馬上見效,,立刻開始爬取。
想更深入了解網頁爬蟲,歡迎瀏覽 ,像是 或 。
祝你爬蟲順利,資料永遠乾淨、結構化、好用!如果遇到困難,記得:Github 上一定有解法……或者,直接交給 Thunderbit AI 幫你搞定。