
網路上資料多到爆,說真的——沒有人有時間一筆一筆複製貼上上千筆產品列表,或競爭對手的價格頁面。如果您像我一樣,平常常用 Linux 來做自動化與開發,那您一定知道這個平台對資料驅動團隊有多好用。事實上,,而且。但問題是:要找到一款真的符合您工作流程的 Linux 網頁爬蟲——不管您是非技術型商務使用者,還是硬派工程師——都像在茫茫草堆裡找針一樣難。
所以我整理了這篇深入指南,介紹 2026 年最值得關注的 18 款 Linux 網頁爬蟲工具。從像 這類由 AI 驅動、免程式碼的解決方案(沒錯,就是我和團隊打造的那款),到像 Scrapy 和 Beautiful Soup 這類經典開發者框架,這份清單能幫您快速挑到最適合的 Linux 網頁爬蟲,省去反覆試錯的麻煩。
為什麼 Linux 網頁爬蟲工具對商務使用者很重要
說實話:人工蒐集資料就是效率殺手。研究顯示,依賴複製貼上方法的團隊每週會浪費好幾個小時,而且錯誤率接近 5%——這種做法很容易導致昂貴失誤與錯失機會()。Linux 以穩定性、安全性與彈性著稱,是執行需要 24/7 運作爬蟲的首選平台——不管您是在桌機、伺服器,還是雲端上操作都一樣合適。
Linux 網頁爬蟲工具的常見商務應用:
- 開發潛在客戶: 業務團隊會從名錄、社群媒體或評論網站抓取最新聯絡人,省去大量手動整理的時間()。
- 價格監控: 電商團隊可自動擷取競爭對手價格與庫存資料,讓自家定價保持精準且即時。
- 競爭對手研究: 行銷與營運團隊追蹤新品上市、評論與 SEO 關鍵字,不再「摸黑前進」。
- 市場情報: 分析師彙整新聞、論壇與社群資料,及早捕捉趨勢。
- 工作流程自動化: 有些工具(尤其是 AI 驅動工具)甚至能直接從您的 Linux 機器自動化網頁流程,例如填表或操作儀表板。
最棒的是,選對 Linux 網頁爬蟲工具,不只工程師,非技術使用者也能被賦能,更快、更聰明地運用網路資料做決策。
我們如何挑選最適合 Linux 的網頁爬蟲
不是每款爬蟲都一樣,尤其是在 Linux 上。以下是我評估的重點:
- Linux 相容性: 這裡列出的每款工具,都能原生在 Linux 上執行,或透過瀏覽器、簡單替代方案(像 Wine 或雲端存取)使用。
- 易用性: 從自然語言 AI 指令到視覺化點選介面,我優先挑選能讓非工程師快速上手的工具;但也沒有忽略那些想要完全掌控的進階使用者。
- 資料擷取能力: 能不能處理動態內容、分頁、子頁面與各種資料型態?能不能扛住反爬蟲機制?
- 擴展性與自動化: 排程、雲端爬取、分散式爬行——這些都是嚴肅資料專案的必備功能。
- 整合與匯出: CSV、Excel、Google 試算表、API——資料出不來,再強也沒用。
- 價格與授權: 免費、開源或付費——從個人創業者到企業團隊,各種預算都能找到合適選項。
- 社群與支援: 活躍的使用者社群、完善文件與即時支援,遇到卡關時差很多。
我也把真實使用者回饋、業界評測,以及我親自上手這些工具的經驗一起納入考量。現在就來看清單。
1. Thunderbit
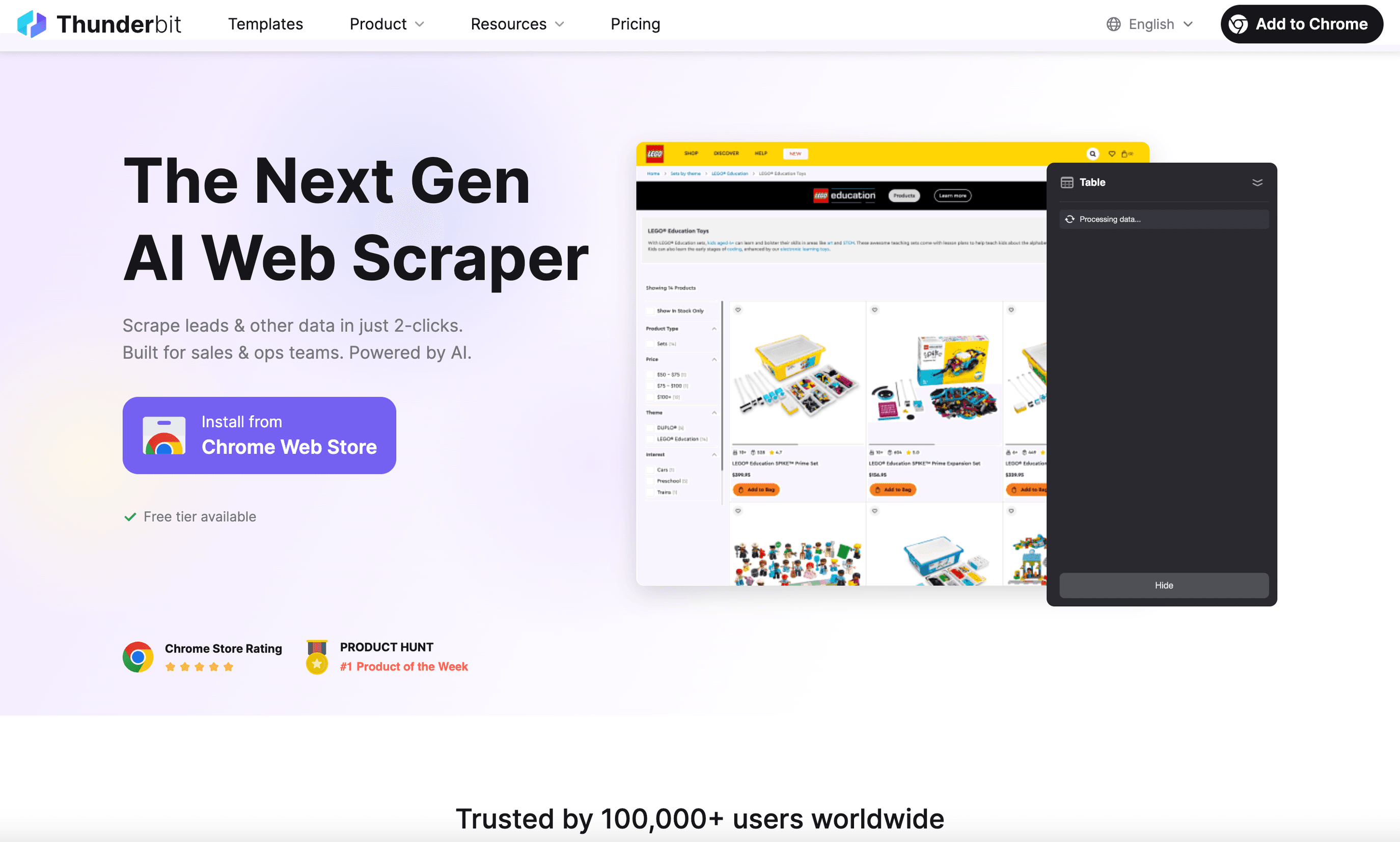 是我最推薦給商務使用者的選擇,因為它是一款真正好上手的 Linux 網頁爬蟲。身為一個,它在 Linux 上運作非常順暢(只要打開 Chrome 或 Chromium 即可),還能讓您只用兩次點擊就從任何網站抓取資料。
是我最推薦給商務使用者的選擇,因為它是一款真正好上手的 Linux 網頁爬蟲。身為一個,它在 Linux 上運作非常順暢(只要打開 Chrome 或 Chromium 即可),還能讓您只用兩次點擊就從任何網站抓取資料。
Thunderbit 的亮點:
- 自然語言提示: 只要描述您要什麼(例如「擷取這個頁面上的所有產品名稱與價格」),Thunderbit 的 AI 就會替您處理剩下的事。
- AI 建議欄位: 點一下,Thunderbit 就會掃描頁面並建議欄位與資料類型,不必手動選欄位。
- 子頁面與分頁爬取: 需要更多細節?Thunderbit 可以自動造訪每個子頁面(例如產品詳情頁),並自動補強您的表格。
- 雲端或本機爬取: 在雲端一次最多可抓取 50 個頁面;如果網站需要登入,也可以使用瀏覽器模式。
- 即時匯出: 一鍵匯出到 Excel、Google 試算表、Airtable、Notion、CSV 或 JSON——永遠免費。
- 加值工具: 只要點一下,就能擷取電子郵件、電話號碼與圖片。AI 自動填表也能幫您自動化表單輸入。
價格: 有免費方案(可抓取 6–10 個頁面),付費方案從 每月 15 美元、500 列 起()。使用者很喜歡它「幾乎不用學習成本」,也喜歡它能把「幾小時的工作縮短成幾分鐘」()。如果是大規模任務,可能需要拆成較小批次執行;但對多數商務情境來說,它能節省大量時間。
Linux 相容性: 100%。只要在您的 Linux 桌機或伺服器上執行 Chrome/Chromium 即可。
最適合: 想要最快、最簡單上手的非技術商務使用者(業務、行銷、營運)。
2. Scrapy
 是 Python 開發者的黃金標準,適合想要 彈性高、可擴展的 Linux 網頁爬蟲。它是開源、速度極快(非同步爬取),從簡單抓取到大規模分散式爬行都能處理。
是 Python 開發者的黃金標準,適合想要 彈性高、可擴展的 Linux 網頁爬蟲。它是開源、速度極快(非同步爬取),從簡單抓取到大規模分散式爬行都能處理。
主要功能:
- 非同步、高速爬行——非常適合抓取成千上萬個頁面。
- 高度可擴充: 可加入代理、CAPTCHA 等外掛。
- 可與 Python 資料生態整合: 可輸出到 JSON、CSV、資料庫或 pandas。
- 可處理 cookie、session 與自動節流。
價格: 100% 免費且開源。
Linux 相容性: 原生支援(可透過 pip 安裝)。在伺服器與容器中都能順暢運作。
最適合: 建立客製化、大規模爬蟲的開發者。
提醒: 對非工程師來說學習曲線比較陡,但如果您會 Python,Scrapy 幾乎無可匹敵。
3. Beautiful Soup
 是一個輕量級 Python 函式庫,專門用來 解析 HTML 與 XML。它非常適合快速、臨時性的抓取,或清理雜亂的網頁內容。
是一個輕量級 Python 函式庫,專門用來 解析 HTML 與 XML。它非常適合快速、臨時性的抓取,或清理雜亂的網頁內容。
主要功能:
- 簡單、友善的人類可讀 API——很適合初學者。
- 可搭配 requests 來抓取頁面。
- 能優雅處理損壞的 HTML。
價格: 免費且開源。
Linux 相容性: 100%(純 Python)。
最適合: 進行小到中型抓取或解析工作的開發者與資料科學家。
限制: 無法直接處理 JavaScript 或動態內容——如果需要這些功能,可以搭配 Selenium 或 Puppeteer。
4. Selenium
 是經典的 瀏覽器自動化框架。它可以讓您控制 Chrome、Firefox 或其他瀏覽器,抓取動態、JavaScript 密集型網站。
是經典的 瀏覽器自動化框架。它可以讓您控制 Chrome、Firefox 或其他瀏覽器,抓取動態、JavaScript 密集型網站。
主要功能:
- 自動化真實瀏覽器——可登入、點擊、捲動,像真人一樣互動。
- 支援 Python、Java、C# 等多種語言。
- 有無頭模式,可在 Linux 伺服器上執行。
價格: 免費且開源。
Linux 相容性: 完整支援(只需安裝對應的瀏覽器驅動程式)。
最適合: QA 工程師、爬蟲開發者,以及任何需要模擬使用者行為的人。
提醒: 這類工具資源消耗較大,也比純 HTTP 爬蟲慢,但有時候它是唯一能拿到資料的方法。
5. Puppeteer
 是 Google 出品的 Node.js 函式庫,用來 控制無頭 Chrome/Chromium。它有點像 Selenium,但提供更現代化的 JavaScript API,並與 Chrome 功能緊密整合。
是 Google 出品的 Node.js 函式庫,用來 控制無頭 Chrome/Chromium。它有點像 Selenium,但提供更現代化的 JavaScript API,並與 Chrome 功能緊密整合。
主要功能:
- 可執行 JavaScript、處理動態內容,還能截圖。
- 速度快、穩定,對 Node.js 開發者來說很好上手。
- 可攔截網路請求並封鎖不需要的資源。
價格: 免費且開源。
Linux 相容性: 會自動安裝 Chromium;預設以無頭模式運作。
最適合: 抓取現代網頁應用或單頁網站的開發者。
6. Octoparse
 是一款 免程式碼網頁爬蟲,具有拖放式介面與大量預先建立的範本。雖然桌面程式只有 Windows/Mac 版本,但 Linux 使用者可以透過瀏覽器使用 Octoparse 的 雲端平台,或用 Wine 執行 Windows 程式。
是一款 免程式碼網頁爬蟲,具有拖放式介面與大量預先建立的範本。雖然桌面程式只有 Windows/Mac 版本,但 Linux 使用者可以透過瀏覽器使用 Octoparse 的 雲端平台,或用 Wine 執行 Windows 程式。
主要功能:
- 100+ 現成爬取範本,可用於 Amazon、eBay、Zillow 等網站。
- 視覺化流程設計器——用點選方式建立爬蟲。
- 雲端爬取與排程——讓 Octoparse 的伺服器代勞重工。
- 可匯出到 Excel、CSV、JSON 與資料庫。
價格: 有免費方案(功能受限),付費方案從 每月 75–89 美元 起。
Linux 相容性: 可透過雲端/網頁存取;桌面版可經由 Wine 使用。
最適合: 需要快速取得電商或市場平台資料的非工程師。
7. PhantomJS
 是一個 無頭 WebKit 瀏覽器,曾經是輕量級瀏覽器自動化的首選。它現在已經停止維護,但仍可在 Linux 上用於舊專案或簡單任務。
是一個 無頭 WebKit 瀏覽器,曾經是輕量級瀏覽器自動化的首選。它現在已經停止維護,但仍可在 Linux 上用於舊專案或簡單任務。
主要功能:
- 可用 JavaScript 撰寫腳本。
- 可處理中等程度的 JavaScript,並支援截圖/PDF。
- 不需要 GUI。
價格: 免費且開源。
Linux 相容性: 原生二進位檔。
最適合: 舊有專案,或無法安裝 Chrome 的環境。
注意: 已不再持續維護——現代網站可能無法順利運作。
8. ParseHub
 是一款 視覺化、跨平台的網頁爬蟲,並提供原生 Linux 應用程式。它非常適合想抓取複雜、動態網站的非工程師。
是一款 視覺化、跨平台的網頁爬蟲,並提供原生 Linux 應用程式。它非常適合想抓取複雜、動態網站的非工程師。
主要功能:
- 點選式介面——選取元素,視覺化建立工作流程。
- 可處理動態內容、地圖、無限捲動等情境。
- 支援雲端執行與排程。
- 可匯出到 CSV、JSON,或透過 API 使用。
價格: 免費方案(5 個專案),付費方案從 每月 189 美元 起。
Linux 相容性: 提供 Linux、Windows、Mac 原生應用程式。
最適合: 想要在不寫程式的前提下保有控制力的分析師與半技術使用者。
9. Kimurai
 是一個 Ruby 網頁爬蟲框架,原生支援 Linux。對 Ruby 開發者來說,它就像 Scrapy 的 Ruby 版本。
是一個 Ruby 網頁爬蟲框架,原生支援 Linux。對 Ruby 開發者來說,它就像 Scrapy 的 Ruby 版本。
主要功能:
- 支援多種瀏覽器: 無頭 Chrome、Firefox、PhantomJS 或純 HTTP。
- 非同步處理,支援高併發。
- 簡潔的 Ruby DSL,用來撰寫 spider。
價格: 免費且開源。
Linux 相容性: 100%(Ruby)。
最適合: Ruby 開發者,或需要客製化、高併發爬取的 Rails 團隊。
10. Apify
 是一個 雲端網頁爬取平台,提供開源 SDK 與現成「actor」市集。您可以在 Linux 機器上執行爬蟲,也可以直接在雲端使用。
是一個 雲端網頁爬取平台,提供開源 SDK 與現成「actor」市集。您可以在 Linux 機器上執行爬蟲,也可以直接在雲端使用。
主要功能:
- 提供 Node.js、Python 等 SDK。
- 有預先建好的爬蟲市集。
- 支援雲端執行、排程與 API 整合。
價格: 有免費方案,雲端用量按使用付費。
Linux 相容性: CLI/SDK 可在 Linux 上執行;雲端平台可透過瀏覽器存取。
最適合: 想同時兼顧客製程式與雲端基礎設施的開發者。
11. Colly
 是一個以 Go 為基礎的 網頁爬蟲框架,強調速度與效率。如果您是 Go 開發者,這就是您的工具。
是一個以 Go 為基礎的 網頁爬蟲框架,強調速度與效率。如果您是 Go 開發者,這就是您的工具。
主要功能:
- 超高速、可並行爬取——單核心每秒超過 1,000 個請求也沒問題。
- 禮貌性爬行(遵守 robots.txt)、session/cookie 管理。
- 記憶體占用低。
價格: 免費且開源。
Linux 相容性: 原生 Go 二進位檔。
最適合: 需要高效能抓取的 Go 開發者。
12. PySpider
 是一個 附有網頁介面的 Python 網頁爬蟲系統。您可以直接從瀏覽器管理、排程與監控爬行任務。
是一個 附有網頁介面的 Python 網頁爬蟲系統。您可以直接從瀏覽器管理、排程與監控爬行任務。
主要功能:
- 基於網頁的介面,可用於撰寫腳本與監控。
- 支援分散式爬行、排程與重試。
- 可與資料庫和訊息佇列整合。
價格: 免費且開源。
Linux 相容性: 為 Linux 部署而設計。
最適合: 透過網頁介面管理多個抓取專案的團隊。
13. WebHarvy
 是一款適用於 Windows 的 視覺化點選式爬蟲,但 Linux 使用者可以透過 Wine 執行。它以模式偵測與一次性購買授權模式聞名。
是一款適用於 Windows 的 視覺化點選式爬蟲,但 Linux 使用者可以透過 Wine 執行。它以模式偵測與一次性購買授權模式聞名。
主要功能:
- 瀏覽並點選即可選取資料,不用寫程式。
- 可自動偵測清單模式。
- 支援匯出到 CSV、JSON、XML、SQL。
價格: 約 139 美元一次性授權。
Linux 相容性: 可透過 Wine 或虛擬機器執行。
最適合: 想要快速、視覺化爬蟲的初學者或個人專業工作者。
14. OutWit Hub
 是一款 原生 Linux GUI 應用程式,專為網頁爬取設計。它能自動辨識資料模式,並提供強大的擷取與自動化功能。
是一款 原生 Linux GUI 應用程式,專為網頁爬取設計。它能自動辨識資料模式,並提供強大的擷取與自動化功能。
主要功能:
- 可自動偵測連結、圖片、表格、電子郵件等。
- 提供腳本編輯器,可做客製化擷取。
- 支援巨集自動化與排程。
價格: 免費版(功能有限),Pro 授權約 50–100 美元。
Linux 相容性: 提供 Linux、Windows、Mac 原生應用程式。
最適合: 有些技術背景、想要桌面 GUI 爬蟲的非工程師。
15. Portia
 是 Scrapinghub 推出的 開源視覺化網頁爬蟲。它在瀏覽器中執行,讓您可以透過標註網頁來訓練爬蟲。
是 Scrapinghub 推出的 開源視覺化網頁爬蟲。它在瀏覽器中執行,讓您可以透過標註網頁來訓練爬蟲。
主要功能:
- 基於瀏覽器的視覺化擷取介面。
- 可與 Scrapy 整合,用於客製化專案。
- 開源且可擴充。
價格: 免費且開源。
Linux 相容性: 基於瀏覽器;可在任何作業系統上使用。
最適合: 想要結合 Scrapy 整合功能的開源視覺化抓取使用者。
16. Content Grabber
 是一款 企業級視覺化爬蟲,主要面向 Windows,但可透過 Wine 或虛擬化在 Linux 上執行。
是一款 企業級視覺化爬蟲,主要面向 Windows,但可透過 Wine 或虛擬化在 Linux 上執行。
主要功能:
- 視覺化編輯器加上 C# 腳本,適合進階邏輯。
- 多代理管理與排程。
- 可與資料庫、API 等整合。
價格: 授權費高達數千美元;伺服器版從每月 69 美元起。
Linux 相容性: 透過 Wine 或 VM 使用。
最適合: 管理大量爬取專案的代理商與大型團隊。
17. Helium
 是一個 簡化 Selenium 自動化的 Python 函式庫。它的目標是讓瀏覽器腳本更像人類操作。
是一個 簡化 Selenium 自動化的 Python 函式庫。它的目標是讓瀏覽器腳本更像人類操作。
主要功能:
- 直覺式命令,例如
click("Login")或write("email")。 - 可自動化 Chrome 與 Firefox。
- 很適合快速腳本與自動化任務。
價格: 免費且開源。
Linux 相容性: 可在 Linux 上運作(建立於 Selenium 之上)。
最適合: 覺得 Selenium 太繁瑣的 Python 使用者。
18. Dexi.io
 是一個 雲端資料擷取與自動化平台。它可直接透過瀏覽器使用,因此 Linux 使用者不用安裝任何東西就能上手。
是一個 雲端資料擷取與自動化平台。它可直接透過瀏覽器使用,因此 Linux 使用者不用安裝任何東西就能上手。
主要功能:
- 視覺化工作流程設計器,用於爬取與自動化。
- 支援排程、資料轉換與 API 整合。
- 具備企業級擴展性與支援。
價格: 每月 119 美元起(Standard);更大規模則有更高階方案。
Linux 相容性: 網頁應用程式——任何作業系統都能使用。
最適合: 需要可擴展、整合式網頁資料擷取的專業人士與企業。
Linux 網頁爬蟲工具快速比較表
| 工具 | 類型/主要功能 | 最適合 | 價格 | Linux 相容性 |
|---|---|---|---|---|
| Thunderbit | AI Chrome 擴充功能、兩步驟、子頁面、雲端/本機 | 非技術型商務使用者 | 免費,起價每月 15 美元 | ✔ Linux 上的 Chrome |
| Scrapy | Python 框架、非同步、CLI、高度可擴充 | 開發者、大規模客製爬蟲 | 免費 | ✔ 原生 |
| Beautiful Soup | Python 函式庫、簡單 HTML/XML 解析 | 開發者、資料科學家、小型任務 | 免費 | ✔ 原生 |
| Selenium | 瀏覽器自動化、JavaScript 密集網站 | QA、開發者、動態內容 | 免費 | ✔ 原生 |
| Puppeteer | Node.js、無頭 Chrome、JavaScript 渲染 | Node 開發者、現代網頁應用 | 免費 | ✔ 原生 |
| Octoparse | 免程式碼、拖放式、雲端範本 | 非工程師、電商 | 免費,起價每月 75 美元 | ◐ 雲端/Wine |
| PhantomJS | 無頭 WebKit、可用 JS 撰寫腳本 | 舊系統、輕量化、無需 Chrome | 免費 | ✔ 原生 |
| ParseHub | 視覺化、跨平台、點選式 | 分析師、半技術使用者 | 免費,起價每月 189 美元 | ✔ 原生 |
| Kimurai | Ruby 框架、多瀏覽器、非同步 | Ruby 開發者、高併發 | 免費 | ✔ 原生 |
| Apify | 雲端平台、SDK、市集 | 開發者、混合式客製/雲端 | 免費方案、按用量計費 | ✔ 原生/雲端 |
| Colly | Go 框架、快速、並行 | Go 開發者、高效能 | 免費 | ✔ 原生 |
| PySpider | Python、網頁介面、排程、分散式 | 團隊、多專案 | 免費 | ✔ 原生 |
| WebHarvy | 視覺化、模式偵測、一次性授權 | 初學者、個人專業人士 | 約 139 美元一次性 | ◐ Wine/VM |
| OutWit Hub | 原生 GUI、自動偵測資料、腳本 | 非工程師、桌面 GUI | 免費版、Pro 50–100 美元 | ✔ 原生 |
| Portia | 開源、視覺化、基於瀏覽器 | 開源、Scrapy 整合 | 免費 | ✔ 瀏覽器 |
| Content Grabber | 企業級、視覺化、腳本、多代理 | 代理商、大型團隊 | $$$,起價每月 69 美元 | ◐ Wine/VM |
| Helium | Python、簡化版 Selenium、直覺 API | Python 使用者、快速自動化 | 免費 | ✔ 原生 |
| Dexi.io | 雲端、視覺化工作流程、排程、API | 企業、可擴展自動化 | 起價每月 119 美元 | ✔ 瀏覽器 |
如何為 Linux 選擇合適的網頁爬蟲:關鍵考量
挑選合適的工具,重點就是要和您的需求與技能匹配:
- 技術能力: 非工程師應優先考慮 Thunderbit、ParseHub、Octoparse 或 OutWit Hub。開發者則可透過 Scrapy、Puppeteer、Colly 或 Kimurai 發揮更多威力。
- 資料複雜度: 靜態頁面可用 Beautiful Soup 或 Colly,速度快且簡單;如果是動態、JavaScript 很重的網站,您會需要 Selenium、Puppeteer,或支援 JS 的視覺化工具。
- 規模與頻率: 一次性任務可用免程式碼工具或雲端爬蟲;若是排程化、大規模爬取,建議選 Scrapy、PySpider 或 Apify。
- 整合需求: 若您需要匯出到 Excel、Sheets 或資料庫,請確認工具支援您的工作流程。
- 預算: 對工程師來說,免費與開源選項很多;對商務使用者而言,Thunderbit 與 ParseHub 提供相對親民的入門方案,而企業團隊則可能投資 Dexi.io 或 Content Grabber。
- 支援與社群: 開源工具通常有龐大社群;商業工具則提供專屬支援。
專業建議: 不要害怕混搭工具。您可以先用 Thunderbit 做原型驗證與資料模式辨識,再切換到 Scrapy 進行正式規模爬取。或者先用 Selenium 登入並取得 session cookie,再交給 Colly 或 Scrapy 做高速抓取。
結語:在 2026 年找到最適合您的 Linux 網頁爬蟲工具
到 2026 年,Linux 使用者在網頁爬蟲工具的選擇上可說非常幸福。不管您要的是能在幾分鐘內完成任務的免程式碼 AI 工具(Thunderbit)、穩健的開發者框架(Scrapy、Colly),還是企業級平台(Dexi.io),都能找到符合您需求與工作流程的 Linux 網頁爬蟲。
重點整理:
- Linux 是現代資料基礎架構的核心——大多數頂級爬蟲都能原生執行,或透過瀏覽器運作。
- AI 與免程式碼工具正在讓商務使用者也能輕鬆進行網頁爬取。
- 開發者框架在彈性、速度與規模方面仍然是主力。
- 先試用再購買——多數工具都提供免費方案或試用。
準備開始了嗎? 或前往 參考更多關於網頁爬取、自動化與資料驅動成長的指南。
常見問題
1. 如果我不會寫程式,Linux 上最好上手的網頁爬蟲是哪一款?
是非技術使用者的首選。它可作為 Linux 上的 Chrome 擴充功能執行,並使用 AI 自動化所有流程,只要兩次點擊就能擷取資料。
2. 哪一款 Linux 網頁爬蟲最適合大規模客製專案?
是開發者的首選。它快速、可擴展、而且高度可客製化——非常適合大型、重複性的爬取任務。
3. 在 Linux 上可以抓取 JavaScript 很重或動態的網站嗎?
可以!您可以使用 或 來控制真實瀏覽器並擷取動態內容。ParseHub 和 Thunderbit 這類視覺化工具也支援動態網站。
4. 有適合商務用途的免費 Linux 網頁爬蟲工具嗎?
當然有。Scrapy、Beautiful Soup、Selenium、Colly、PySpider 與 Kimurai 都是免費且開源的。Thunderbit 與 ParseHub 也提供免費方案,適合小型任務。
5. 我該怎麼在免程式碼與程式碼型 Linux 爬蟲之間做選擇?
如果您要的是速度與簡單性,就選免程式碼工具(Thunderbit、ParseHub、Octoparse)。如果您需要彈性、自動化或與其他系統整合,程式碼型工具(Scrapy、Puppeteer、Colly)會是更好的選擇。
祝您爬取順利——也祝您的 Linux 驅動資料專案跑得比全新安裝的 Ubuntu 還順。若您想看更多網頁爬取技巧,歡迎前往 或訂閱我們的 觀看實作教學。
了解更多