在 GitHub 搜尋「tiktok scraper」會找到 。大約有 已經一年多沒有更新,而且至少有 。
如果你曾經複製過一個熱門的 TikTok 爬蟲 repo,花了一個小時跟依賴套件搏鬥,最後卻完全沒有輸出——你並不孤單。GitHub 上星標最高的 TikTok 爬蟲 drawrowfly/tiktok-scraper,至今仍有超過 5,000 顆星。但它的 issue 區裡滿是像 與 這類討論,而且兩個都回報沒有任何輸出。我在 Thunderbit 已經追蹤 TikTok 爬蟲 repo 的狀態好幾個月,模式非常明顯:這些工具壞得很快,而且大多數永遠不會修好。這篇文章就是我當初開始評估這些 repo 時,希望能存在的實戰生存指南。我們會談哪些還活著、哪些已經死了、接下來該怎麼做,以及如何停止把時間浪費在早在你找到它之前就已失效的程式碼上。
為什麼 GitHub 上大多數 TikTok 爬蟲都會壞掉(而且一直壞)
TikTok 不是一般的爬取目標。它的網頁結構一直在變。不同於靜態的電商商品頁或目錄清單,TikTok 會輪替端點、更新反機器人指紋辨識、改變頁面渲染方式,還會新增新的 session/token 要求——有時甚至在上次變動後幾週內就又改了。
開源維護者都是志工。當 TikTok 推出更新而打壞爬蟲的請求路徑時,repo 可能會壞上好幾天、好幾週,甚至永久失修。這不是在批評維護者——而是快速變動、資金充足的平台,和有正職工作、沒有報酬的開發者之間的結構性落差。
就算是最好的 TikTok 爬蟲 repo,也是在修修補補的循環裡打轉。如果你要用,至少得有一套評估、排錯,以及備援方案的策略。
TikTok 的反機器人防護:你正在對抗什麼
- 速率限制。 TikTok 的 甚至對已核准的整合都明確記載了請求配額。不明來源的爬蟲會更快撞上這些限制。
- Cookie 與 session 閘門。 像 這類較新的 repo 需要
ms_token;像 這類較舊的 repo 在範例中會出現tt_webid_v2; 則記錄了msToken、ttwid、X-Bogus和A_Bogus。TikTok 會檢查你的請求看起來是否像來自真實瀏覽 session。 - 瀏覽器指紋辨識。 解釋了網站如何把標頭、Cookie、TLS 簽章與 JavaScript 可讀取的瀏覽器特徵,和真實使用者流量做比對。他們的 涵蓋 Canvas、WebGL、WebRTC、字型與執行環境訊號。指紋辨識就像 TikTok 在檢查你瀏覽器的身分證——如果瀏覽器、Cookie、時間與網路簽章對不上,還沒回傳任何內容,請求就已經看起來很可疑了。
- 行為偵測。 中常提到,新的 Playwright session 會觸發 CAPTCHA 提示。來自 的社群貼文也越來越常描述:偵測不只看 IP 重用,還會看操作時間與互動品質。
- 加密/簽章請求參數。 Evil0ctal 文件化了
X-Bogus與A_Bogus;更早的社群 gist 則圍繞 URL 簽章與 token 產生。TikTok 越來越期待收到的請求,帶著和它自家瀏覽器/App 流量相同的「印記」。 - CAPTCHA 與驗證流程。 與 的存在,證實 CAPTCHA 仍然是反機器人防線的一部分。
為什麼開源維護者追不上
生命週期總是這樣:某位開發者做出一個 TikTok 爬蟲,上 GitHub 後爆紅,TikTok 補上漏洞,維護者要嘛修好,要嘛就走人。
有兩個 repo 很典型地展現了這個模式:
- drawrowfly/tiktok-scraper 仍有 5,052 顆星和 889 個 fork,但它的 。它是 GitHub 上以精確片語搜尋到、星標最高的 TikTok 爬蟲,但現在看起來就像一份歷史文物:曝光度高、信任度高,卻已經沒有持續維護。
- davidteather/TikTok-Api 顯示 。它的 顯示 2025 年 4 月、7 月、10 月,以及 2026 年 4 月都有實質維護——包含修正使用者影片抓取與新的 proxy/session 控制。但即使是這個較健康的專案,也公開警告 TikTok 會阻擋請求,使用者可能需要 proxy、Playwright,以及自訂 session 邏輯。
模式很簡單:
- 一個久未更新的 TikTok 爬蟲 repo,大概率已死。
- 一個仍在更新的 TikTok 爬蟲 repo,大概率還是很脆弱。
- 真正的差別,只在於這個月是否還有人願意幫你修補壞掉的部分。
60 秒 repo 健檢清單:如何評估 GitHub 上任何 TikTok 爬蟲
在你複製任何東西之前,先跑一次這份清單。不到一分鐘,卻能省下好幾個小時的挫折。
| 訊號 | 🟢 健康 | 🟡 有風險 | 🔴 已死亡 |
|---|---|---|---|
| 最後一次有意義的更新 | 3 個月內 | 3–12 個月前 | 12 個月以上 |
| 開放 issue 數量 | 少,而且新 issue 會被回覆 | 數量增加,維護者仍偶爾活動 | 很多「壞了/被擋/無法運作」但沒人回覆的回報 |
| 最近使用者抱怨 | 主要是安裝問題 | 安裝問題與故障問題混在一起 | 一再出現「沒有輸出」、「403」、「還能用嗎?」 |
| 目前的 auth/session 模型 | 有文件化的 session/cookie 路徑 | token 很多,但有說明 | 依賴舊版網頁端點,沒有現代 auth 指引 |
| 安裝面 | 可重現、已測試的安裝流程 | 有些手動步驟 | 舊依賴、沒有現代化安裝說明 |
| CI/測試 | 有測試,而且是最新的 | 有測試,但覆蓋範圍不明 | 沒有測試或 actions 已過期 |
| 資料範圍是否符合需求 | 和你的實際用途相符 | 只支援部分用途 | 根本解決的是別的問題 |
如何在 60 秒內檢查每個訊號
- 最後更新日期: 看 GitHub 上 repo 標頭。如果寫著「last pushed 2 years ago」,可以直接跳過。
- Open issues: 點進 Issues 分頁,快速掃過最新標題。搜尋
not working、403、blocked、captcha或zero output。 - 使用者抱怨: 如果前 5 個 open issues 全都在說「這個現在不能用了」,答案就很明顯。
- Auth/session 模型: 打開 README,找像
ms_token、Playwright 設定,或 proxy 提示這類最新指引。如果 README 還在引用 2023 年的端點,就可以放棄了。 - 安裝面: 看有沒有 requirements 檔、Docker 支援,或清楚的安裝說明。如果 README 只寫「npm install」,而最後測試的 Node 版本還是 14,那就等著出事吧。
- CI/測試: 看 Actions 分頁。如果測試失敗或根本不存在,壞掉的機率只能靠猜。
- 資料範圍: repo 是否真的描述了你要的資料類型(個人檔案、影片中繼資料、留言、標籤)?很多 repo 只支援影片下載,不支援結構化資料擷取。
這些紅旗代表「直接離開」
- repo 已封存。
- README 寫著「no longer maintained」。
- 最後一次 commit 引用的是 2 年前的 TikTok API 版本。
- issue 充滿「不能用」回報,而且維護者幾個月都沒回應。
- repo 星標很多,但最近幾乎沒有 fork 或 pull request。
小技巧:在 Issues 分頁搜尋 is:issue is:open "not working" 或 is:issue is:open "403"。如果結果很多而且很新,那這個 repo 大概率已經壞了。
熱門 TikTok 爬蟲 GitHub repo:誠實的狀態檢查(2026)
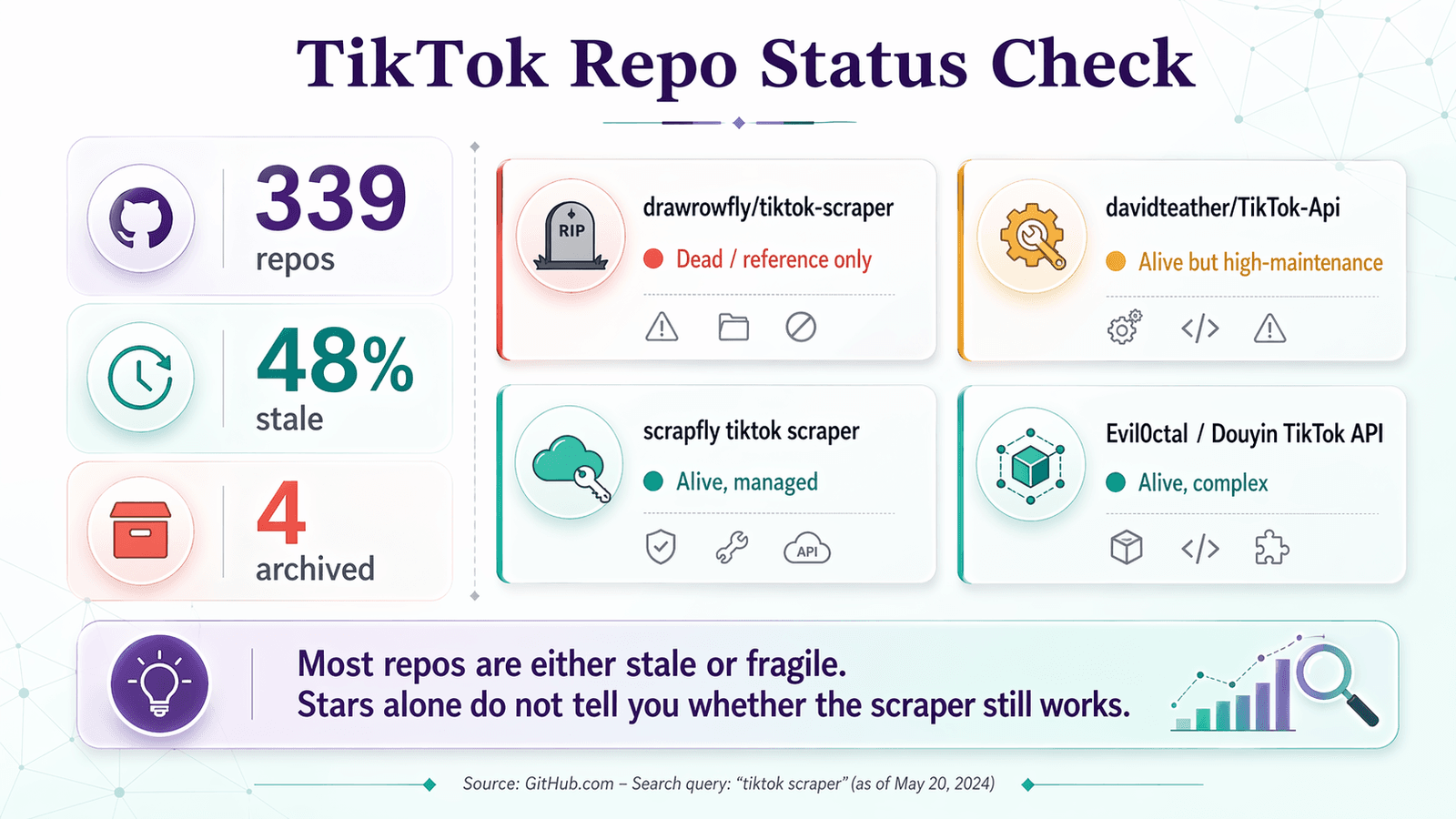
以下是將「Repo 健檢清單」套用到你在 GitHub 搜尋「tiktok scraper」時實際會找到的 repo:
| Repo | 最後更新 | 星標 | 開放 issue | 判定 | 備註 |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 已死亡/僅供參考 | 仍然有名,但對 2026 年的正式用途來說已經太舊 |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 還活著,但維護成本高 | 最強的 OSS 選擇;預期需要 Playwright、token,常常還要 proxy |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938(父 repo) | 約 0(monorepo) | 🟡 還活著,但不是純 OSS | 目前仍有用,但需要 ScrapFly API key |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 還活著、範圍廣、也複雜 | 功能豐富的多平台專案;更接近進階使用者平台 |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 有風險 | 較小的 repo,且有關於使用者資訊與 hashtag 流程的未解抱怨 |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 太新,不值得信任 | 示範型 repo,不是經社群驗證的專案 |
drawrowfly/tiktok-scraper
多年來,這個 TypeScript scraper/downloader 一直是「tiktok scraper github」的預設答案——可抓使用者、趨勢、hashtag 和音樂 feed。到了 2026 年,最好把它當成歷史文件來看待。它的 ,而 issue 佇列裡到現在還有 2023–2025 年留下、未解決的 和 回報。如果你是因為複製了這個 repo 卻什麼都抓不到才看到這篇文章,那你不是唯一一個。
davidteather/TikTok-Api
這仍是 2026 年最可信的開源 TikTok 資料包裝器,而且還活著。它持續更新、,並且清楚文件化 Playwright 設定、非同步用法、token 處理、proxy 支援與 session 復原功能。但它不是「複製即用」的工具。它自己的 README 就說,EmptyResponseException 通常代表 TikTok 正在阻擋請求,而且 也顯示使用者反覆碰到 ms_token、留言抓取壞掉、KeyError: 'ItemModule',以及特定端點失敗等問題。結論:還活著、很有用、只適合開發者,而且維護成本高。
其他值得注意的 repo
- : 目前仍可用,技術上也有參考價值,但 README 要求
SCRAPFLY_KEY。這是託管式爬取平台的程式範例,不是免費的獨立工具。 - : 同時涵蓋 TikTok 和抖音,文件化簽章邏輯(
X-Bogus、A_Bogus、msToken),並支援留言、追蹤者、播放清單等功能。技術門檻高,而且越來越和付費 API 參考綁在一起。issue tracker 在 2026 年仍有關於影片連結與使用者資訊端點的 bug 回報。還活著、功能豐富,但很複雜。 - : 規模較小,且有未解抱怨。正式用途風險高。
- : 4 顆星、0 個 issue、太新,不值得信任。宣傳它的 Medium 文章也沒有批判性地檢視。
TikTok 官方 API vs. GitHub 爬蟲 vs. 無程式碼工具:決策框架

大多數競品文章不是忽略 TikTok 的官方存取路徑,就是直接從「用 GitHub」跳到「買我們的服務」。以下是這三種路徑的中立比較:
| 因素 | TikTok Research API | GitHub 爬蟲 | 無程式碼工具(例如 Thunderbit) |
|---|---|---|---|
| 存取門檻 | 需要學術/商業申請;核准約 4 週 | Git clone + 安裝設定 | 安裝瀏覽器擴充功能 |
| 資料範圍 | 僅限核准端點(帳號、影片、留言、商店) | 廣泛(個人檔案、影片、留言、hashtag、商店) | 可見頁面資料(個人檔案、影片、互動數據、hashtag) |
| 維護負擔 | 低(官方、穩定) | 高(TikTok 一更新,repo 就可能壞) | 無(AI 會適應版面變化) |
| 被封鎖風險 | 無(已授權) | 高 | 低(基於瀏覽器,模擬真實使用者) |
| 成本 | 免費(若獲核准) | 免費(但很耗時間) | 有免費方案;付費方案自每月 15 美元起 |
| 需要寫程式嗎 | 需要(Python/R) | 需要(Python/Node.js) | 不需要 |
| 最適合 | 研究人員、學術界、獲核准的組織 | 能接受維護成本的開發者 | 行銷、銷售、營運、非工程背景使用者 |
什麼時候該用 TikTok Research API
如果你符合資格,TikTok 的 是最乾淨的官方路徑。符合資格的研究者在 可以申請研究公開內容與帳號資料。可用的資料類別包括帳號、追蹤者/被追蹤者、喜歡的影片、置頂影片、轉發影片、內容、留言與商店。 會提供像 video_description、view_count、like_count、comment_count、share_count 這類欄位,以及留言層級的 text、reply_count、create_time 等欄位。
缺點是:資格只限學術機構,以及特定地區內符合條件的非營利/獨立研究者,另外還包括 。如果你是成長團隊或代理商,需要的是快速的營運數據,這不是你的路。
TikTok 也提供給廣告與廣告主內容資料用的 ,這對透明度研究很有用,但不適合一般爬取需求。
什麼時候 GitHub 爬蟲仍然合理
如果你是開發者,想取得官方 API 核准門檻之外的公開資料,而且願意維護整個堆疊,GitHub 爬蟲仍然有用途。像是抓取可見的個人檔案格狀頁、hashtag、留言、播放清單,或在自訂資料流程中擷取影片中繼資料,並且能接受 fork repo 再自行修補的情境。
但要誠實說明:這不是一次設定就結束的事情。即使是 2026 年最可靠的 repo,,仍然會告訴使用者可能需要 Playwright、cookies/tokens、proxy,以及自訂 page/session factory。
什麼時候像 Thunderbit 這樣的無程式碼工具最合適
不是開發者?或者你已經厭倦修修補補的循環?基於瀏覽器的 AI 工具,是取得結構化 TikTok 資料最快的方法。
我們打造的 是一個以 Chrome 擴充功能形式運作的 AI 網頁爬蟲。在 TikTok 上,它可以讀取任何可見頁面(個人檔案、影片、hashtag、搜尋結果),透過「AI 建議欄位」自動建議欄位,然後你只要按下「Scrape」就能擷取結構化資料。 會列出像發佈日期、影片長度、按讚數、分享數、收藏數、留言數、觀看數與 hashtag 等欄位。 示範如何從個人檔案頁收集貼文縮圖、URL、說明文字、創作者帳號名稱與互動訊號。 則涵蓋影片 URL、創作者使用者名稱、說明、發佈時間、觀看數、按讚數、留言數、分享數、音效/音訊與封面圖片 URL。
透過子頁面爬取,你可以從個人檔案清單進入每支影片頁,補充互動數據、說明文字與 hashtag——這對建立 influencer 資料庫或做競品內容稽核的行銷人員特別有用。
不用維護、不用處理安裝問題、不用設定反封鎖配置。AI 會自動適應版面變更。匯出到 Google Sheets、Excel、Airtable、Notion、CSV 或 JSON 都免費。
如果你已經在壞掉的 GitHub repo 上耗掉好幾個小時,這是一個真正可行的替代方案——不是硬推產品。
安裝排錯:修復 TikTok 爬蟲 GitHub 最常見的 5 種安裝失敗
在 TikTok 爬取論壇裡,安裝失敗是第三常被提到的痛點,而且沒有任何一份主流指南真的幫你解決。以下是常見問題。
Node.js 版本衝突
問題: 許多較舊的 TikTok 爬蟲 repo(尤其是 drawrowfly/tiktok-scraper)是為 Node.js 14–16 打造的。如果你跑的是 Node 20 以上,npm install 可能會無聲失敗,或產生不相容的二進位檔。
解法: 使用 nvm(Node Version Manager)安裝並切換到正確版本:
1nvm install 16
2nvm use 16
3npm install如果 repo 沒有指定 Node 版本,請查看 package.json 裡的 engines 欄位,或看 CI 設定。
Python 依賴問題與 Playwright 設定
問題: 需要 和特定瀏覽器二進位檔的 Playwright。使用者會遇到像「browser not found」或依賴衝突這類錯誤。
解法: 一律先使用虛擬環境,然後明確安裝 Playwright 瀏覽器:
1python -m venv .venv
2source .venv/bin/activate # Windows:.venv\Scripts\activate
3pip install TikTokApi
4python -m playwright install如果 playwright install 失敗,請檢查系統套件管理員是否缺少系統依賴(例如 Ubuntu 上的 libnss3)。
Linux/Ubuntu 權限錯誤
問題: 使用 sudo pip install 會破壞系統 Python 環境,進而引發連鎖依賴問題。
解法: 絕對不要用 sudo pip install。務必先建立虛擬環境:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txt這樣可以把爬蟲的依賴與你的系統 Python 隔離開來。
Windows 路徑與編碼問題
問題: Windows CMD 常有編碼問題與路徑長度限制,會破壞爬蟲安裝,尤其當 Playwright 把瀏覽器二進位檔下載到很深的巢狀目錄時。
解法: 改用 WSL(Windows Subsystem for Linux)或 Git Bash,不要用 CMD。WSL 會在 Windows 裡提供完整的 Linux 環境:
1wsl --install
2# 接著開啟 WSL 終端機,照 Linux 的設定步驟進行Docker 快捷法:直接跳過所有依賴問題
問題: 上面那些全部。
解法: 如果你熟悉 Docker,就把爬蟲環境容器化。Python 版 TikTok 爬蟲的基本 Dockerfile 看起來像這樣:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]這能確保不管主機作業系統是什麼,都有可重現的環境。如果爬蟲在 Docker 裡能跑,Docker 外出錯通常就是環境問題,而不是程式碼問題。
排錯流程圖:
- repo 能不能成功執行自己的範例?→ 如果不能,先檢查執行環境版本。
- 執行環境版本正確嗎?→ 檢查瀏覽器/Playwright 安裝。
- 瀏覽器有安裝嗎?→ 檢查 token/cookie。
- token/cookie 有效嗎?→ 檢查 TikTok 是否正在阻擋這個 session。
- 以上都失敗?→ 先假設是 repo 壞了,不是使用者錯。換工具吧。
TikTok 爬取的反封鎖最佳實踐(不用付 proxy 費)
論壇使用者經常抱怨封鎖與偵測:「它們會害你的帳號被封,這又是一筆額外支出」以及「不用 Apify 或昂貴的付費 API」。以下是一些不需要付費 proxy 訂閱的免費實用 workaround。

| 做法 | 難度 | 成本 | 效果 |
|---|---|---|---|
| 隨機請求延遲(2–8 秒抖動) | 容易 | 免費 | 中等 |
| Session/Cookie 輪替 | 中等 | 免費 | 中等 |
| 只抓已登出狀態可見的公開頁面 | 容易 | 免費 | 中等 |
遵守 robots.txt + 速率限制標頭 | 容易 | 免費 | 基準 |
| Headless 瀏覽器指紋隨機化(Playwright) | 中等 | 免費 | 高 |
| 使用 TikTok 的 mobile API 端點(較不易被偵測) | 困難 | 免費 | 高 |
| Residential proxy 輪替 | 中等 | 每月 20–100 美元 | 高 |
真正有幫助的免費技巧
隨機請求延遲。 不要用緊密迴圈狂打請求。每次請求之間加上 2–8 秒的隨機抖動。這是你能做的最簡單一件事:
1import time, random
2time.sleep(random.uniform(2, 8))Session 與 cookie 重用。 不要每個請求都建立全新 session。改為在一批請求之間重用 cookies 與 session 狀態,然後再輪替。這也是為什麼現代 repo 會要求你提供 ms_token,而不是假裝能做無狀態爬取。
只抓已登出狀態下的公開頁面。 它不支援需要使用者登入的路由,只能處理登出後可見的資料。與已登入 session 相比,登出狀態的爬取較不容易被偵測。
遵守 robots.txt。 TikTok 目前的 會直接封鎖許多 agent,只允許一般爬取使用少數公開路徑。這不是讓你可以猛烈爬取的綠燈,但尊重它可以降低立刻被封 IP 的機率。
提高成功率的進階技巧
Headless 瀏覽器指紋隨機化。 如果你用的是 Playwright,請為每個 session 隨機化 viewport 大小、user-agent 字串、時區與 locale。這會讓你的爬蟲每次看起來都像不同的真實使用者,而不是一個換了新 IP 的同一隻機器人。
使用 TikTok 的 mobile API 端點。 有些社群成員回報,鎖定 mobile 風格端點時,被偵測的機率比 web 前端更低。這比較難實作、文件也比較少,但對進階使用者來說,這確實是一種技巧。
什麼時候你真的需要 proxy(以及較實惠的選項)
當規模變大時,免費技巧不夠用。Residential proxy 輪替是大量 TikTok 爬取的標準作法。這裡我不會特別推薦某家付費 proxy 服務,但一般建議是:避免 datacenter proxy(TikTok 會積極標記),並找每次請求可輪替的 residential 或 mobile proxy 池。
或者,像 這類以瀏覽器為基礎的工具,可以完全避開 proxy 問題,因為它直接在你自己的瀏覽器 session 中執行,模擬真實使用者。這不代表它在大規模下完全不會被偵測,但對典型的行銷或研究用途(數十到數百頁,而不是數百萬頁)來說,路徑簡單得多。
你到底會拿到什麼資料?TikTok 爬蟲的真實輸出範例
使用者想在決定工具前先知道實際能抓到什麼資料——但大多數指南完全跳過這部分。以下是根據來源文件整理出的代表性欄位結構。
個人檔案資料
| 使用者名稱 | 顯示名稱 | 追蹤者 | 追蹤中 | 總按讚數 | 簡介 | 已驗證 | 個人檔案 URL |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1,240,000 | 312 | 48,700,000 | "料理+喜劇 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890,000 | 150 | 22,100,000 | "旅遊 Vlogger 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2,100,000 | 88 | 91,300,000 | "運動與健康" | ✅ | tiktok.com/@fitnessmaya |
可取得來源: GitHub 爬蟲(TikTok-Api、Evil0ctal)、Research API、Thunderbit(從可見的個人檔案頁)。
影片中繼資料
| 影片 URL | 說明 | 觀看數 | 按讚數 | 留言數 | 分享數 | 音樂 | Hashtags | 發佈日期 | 長度 |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "史上最棒的義大利麵技巧 🍝" | 4,200,000 | 312,000 | 8,400 | 21,000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV:你的貓正在評分你" | 9,100,000 | 1,100,000 | 23,000 | 55,000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "沒人問但我還是要分享的晨間例行公事" | 1,800,000 | 98,000 | 3,200 | 7,500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
可取得來源: GitHub 爬蟲(TikTok-Api、Evil0ctal)、(欄位包括 video_description、view_count、like_count、comment_count、share_count、music_id、hashtag_names、video_duration)、Thunderbit()。
留言資料
| 留言者 | 留言內容 | 按讚數 | 時間戳 | 回覆數 |
|---|---|---|---|---|
| @user_abc | "我試了這個,真的能用 😂" | 1,200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "下次加點蒜,信我" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "這就是我想看的內容" | 340 | 2026-03-16T11:30:00Z | 2 |
可取得來源: GitHub 爬蟲(TikTok-Api、Evil0ctal)、(欄位包括 text、like_count、reply_count、create_time)、Thunderbit(從可見的留言區)。
Hashtag 與搜尋資料
| Hashtag | 熱門影片 URL | 總觀看數 | 趨勢中 |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4,200,000 | 是 |
| #cooking | tiktok.com/@chef/video/321 | 11,000,000 | 是 |
| #hack | tiktok.com/@tips/video/654 | 2,900,000 | 否 |
可取得來源: GitHub 爬蟲(依 repo 而異)、Thunderbit()。
注意:沒有任何單一 repo 能保證永遠拿到所有欄位。TikTok 的回應結構會變動,而且連維護者都會提醒這件事。請把這些內容視為代表性樣本,而不是保證輸出。
用 Thunderbit 在 2 次點擊內抓取 TikTok 資料(逐步教學)
厭倦修修補補的循環了嗎?以下是無程式碼的路徑——給那些試過 GitHub repo 但失敗的人一個逃生出口。
- 安裝 。
- 前往你要爬取的 TikTok 頁面——個人檔案、搜尋結果頁、hashtag 頁或單支影片頁。
- 點擊「AI Suggest Fields」。 Thunderbit 的 AI 會讀取頁面並建議欄位:使用者名稱、追蹤者、影片說明、按讚數、hashtag 等。
- 需要的話調整欄位,然後點擊「Scrape」。 資料會填入結構化表格中。
- 使用子頁面爬取來豐富資料。 從個人檔案清單點進每支影片,擷取更多欄位:完整說明、音樂資訊、留言數、分享數。
- 匯出到 Google Sheets、Excel、Airtable 或 Notion——完全免費。
不用維護、不用處理安裝問題、不用設定反封鎖。AI 會自動適應 TikTok 的版面變化。
用子頁面爬取豐富 TikTok 資料
從個人檔案或 hashtag 頁抓到影片清單後,點擊「Scrape Subpages」,讓 AI 逐一造訪每支影片頁並擷取更多欄位。這對建立 influencer 資料庫或進行競品內容稽核特別有幫助——你可以不用手動點進數十個頁面,就拿到完整的影片層級互動資料表。
匯出並運用你的 TikTok 資料
Thunderbit 可免費匯出到 Google Sheets、Excel、Airtable、Notion、CSV 或 JSON。常見用途包括:
- 把資料丟進試算表做互動分析。
- 傳到 Airtable,做成類 CRM 的 influencer 追蹤表。
- 推到 Notion,供團隊協作進行內容研究。
如果你想更深入了解 Thunderbit 如何處理網頁資料擷取,可以看看我們的 ,或到 觀看教學影片。
保持合法:TikTok 服務條款與爬取合規
TikTok 的法律立場很清楚。平台的 表示,服務條款禁止自動化腳本在未授權的方式下收集資訊或與服務互動,並明確提到繞過存取限制。TikTok 的 也禁止使用自動化腳本或網路爬行,以欺騙方式取得資訊。
實務建議:
- 只抓公開可用的資料。 不要爬私密內容或需要登入才能看的內容。
- 尊重速率限制。 不要狂打 TikTok 的伺服器。
- 遵守資料隱私法。 如果你在收集、儲存或分析個人資料,GDPR 與 CCPA 仍然適用。
- 符合資格時使用 Research API。 從合規角度來看,這是最安全的路。
- 這不是法律建議。 請針對你的具體情況諮詢專業人士。
想更了解法律面,請參考我們的 指南。
當你的 TikTok 爬蟲 GitHub repo 死掉時,該怎麼辦
簡短版本如下:
- 在複製任何 GitHub 上的 TikTok 爬蟲之前,先跑 60 秒 repo 健檢清單。 大多數 repo 其實早就死了。
- 了解你的選項。 官方 API、GitHub 爬蟲與無程式碼工具,各自適合不同使用者與用途。
- 如果你選 GitHub 路線, 請預留時間處理安裝排錯與反封鎖設定。要有持續維護的心理準備。
- 先確認你實際會拿到什麼資料, 再決定要不要用這個工具。看輸出欄位,不要只看星標數。
- 如果你不是開發者(或者你已經受夠壞掉的 repo),試試像 這樣的無程式碼工具——兩次點擊、結構化資料、免費匯出。
你需要的 TikTok 資料其實是拿得到的。真正的問題是:你想把時間花在維護爬蟲,還是實際使用資料。選擇適合你技能等級與使用情境的方法,別再讓一個已經失效的 GitHub repo 白白浪費你下午的時間。
常見問題
2026 年 GitHub 上還有能用的 TikTok 爬蟲嗎?
有,但名單很短。 是截至 2026 年 4 月仍有積極維護、最可信的開源選項。 也還活著,但更複雜。星標最高的 repo drawrowfly/tiktok-scraper 自 2023 年 5 月後就沒再更新,實際上已經死了。在投入任何 repo 前,務必先跑一次 Repo 健檢清單。
爬取 TikTok 合法嗎?
TikTok 的服務條款明確禁止自動化爬取。公開可見的資料在法律上屬於灰色地帶,會依司法管轄區而異。最安全的方式是讓符合資格的研究者使用官方 。如果你要爬公開資料,請只抓公開可存取內容、尊重速率限制,並遵守 GDPR/CCPA。這不是法律建議——請就你的情況諮詢專業人士。
我可以不用寫程式抓 TikTok 嗎?
可以。像 這類基於瀏覽器的 AI 工具,能讓你不寫任何程式就擷取結構化 TikTok 資料(個人檔案、影片中繼資料、hashtag、互動數據)。TikTok Research API 對獲核准的申請者也只需要少量程式碼。對非開發者來說,無程式碼工具是最快、也最可靠的路徑。
TikTok 爬蟲可以抓到哪些資料?
常見資料類型包括個人檔案資訊(使用者名稱、追蹤者、簡介、驗證狀態)、影片中繼資料(說明、觀看數、按讚數、留言數、分享數、音樂、hashtag、長度、發佈日期)、留言(文字、按讚數、時間戳、回覆)以及 hashtag/搜尋資料(熱門影片、總觀看數、趨勢狀態)。實際欄位會依工具和方法而異——詳情請見上方的輸出範例區塊。
為什麼我的 TikTok 爬蟲一直被阻擋?
TikTok 採用多層反機器人防護:速率限制、cookie/session 閘門、瀏覽器指紋辨識、行為偵測、加密請求參數,以及 CAPTCHA 流程。常見的被阻擋原因包括請求太快、每次都用全新乾淨 session、以預設指紋執行 headless 瀏覽器,或使用 datacenter proxy。請參考上方的反封鎖最佳實踐章節,了解免費與付費的 workaround。