

Temu 現已遍及 50 多個市場,每月活躍用戶超過 4.16 億。它的商品目錄涵蓋從廚房小物、寵物配件到 LED 燈條等各種品類。如果您在做電商、Dropshipping 或競爭情報,您大概曾想把 Temu 資料匯入試算表,接著又發現 Temu 非常、非常不希望您這麼做。
我花了很多時間研究並測試受保護電商網站的抓取工具。Temu 是最棘手的目標之一。大多數線上指南不是丟給您一份幾週內就會失效的 Python 教學,就是推薦價格高到超過您每月廣告預算的企業級 API。
現實情況是,大多數商務使用者——Dropshipper、獨立營運者、行銷團隊——只想要一份乾淨的試算表,裡面有商品名稱、價格、圖片、評分和賣家資訊。他們不想在凌晨兩點除錯 Playwright 腳本。
這份指南正是為了補上這個缺口:以實用、按技能分級的方式,整理出 2026 年真正能用的最佳 Temu 爬蟲,並搭配能把原始抓取轉化為持續競爭情報的最佳實務。不論您是完全新手,還是正在打造資料管線的開發者,這裡都有適合您的內容。
為什麼要抓取 Temu?商務團隊的頂級使用情境
Temu 資料不只是有趣——它還非常有策略價值。
這個平台已成為低價與中低價商品類別中的定價風向球。即使您沒有在 Temu 上銷售,您的客戶也會拿您的價格和那裡看到的價格比較。以下是不同團隊如何使用 Temu 資料:
| 使用情境 | 所需資料 | 重要原因 |
|---|---|---|
| Dropshipping 商品研究 | 標題、價格、圖片、評分、評論數、銷量、變體 | 找出有需求訊號的低成本商品,並與 Amazon、Shopify、AliExpress、TikTok Shop 做比較 |
| 競爭性定價 | 目前價格、原價、折扣%、幣別、運費、時間戳記 | 建立定價策略與促銷規劃的基準 |
| 商品採購 | 規格、圖片、變體、賣家/商店、商品 ID、分類 | 找出值得進一步驗證的商品類型與供應商式刊登 |
| 市場趨勢分析 | 搜尋關鍵字、分類、銷量、評論數、評分 | 看出哪些商品正在各分類中快速升溫 |
| 行銷與創意研究 | 標題、圖片、評論數、評分、描述、分類標籤 | 挖掘高流量刊登使用的訊息訴求、視覺鉤子、組合包與主張 |
| 庫存與可用性監控 | 商品網址、可用性、運送預估、價格、時間戳記 | 掌握缺貨、地區倉庫變化與價格變動 |
搜尋「最佳 Temu 爬蟲」的人,通常會分成三類。非技術使用者想要的是可以輸出試算表的 Chrome 擴充功能。半技術營運者想要的是有範本和排程的視覺化工具。開發者想要的是 API、Playwright 腳本和代理策略。
這篇文章會涵蓋這三類——但會先從最大的一群開始:需要資料,不需要程式碼的人。
2026 年最佳 Temu 爬蟲的關鍵差異是什麼
能抓 Amazon 或 Shopify 的爬蟲,不代表一定能在 Temu 撐得住。本文的評估標準如下:
- Temu 上的可靠性——它真的能回傳乾淨資料,還是會被封鎖、回傳空白列,或在版面改版後失效?
- 易用性——非技術商務使用者能不能不用寫程式就上手?
- 資料完整度——是否支援子頁面補強(逐一造訪每個商品詳情頁以取得規格、變體、賣家資訊)?
- 維護負擔——Temu 改變頁面結構時,它能不能自動適應?
- 排程與監控——能不能定期執行抓取,並匯出到持續更新的資料目的地?
- 匯出目的地——CSV、Excel、Google Sheets、Airtable、Notion、JSON?
- 成本透明度——實際的 Temu 抓取流程每月大概要花多少錢?
Reddit 的 r/webscraping 社群回報一再把 Temu 描述成最難抓取的電商網站之一。有位使用者寫道他「連當買家都看不到價格」,另一位則指出 Temu 和 Shopee 都有團隊持續強化反機器人機制。雖然沒有公開的 Temu 專屬失敗率基準,但 2025 Imperva Bad Bot Report 顯示,自動化流量已超越人類流量,機器人占了整體網路流量的 51%。這就是 Temu 所面對的防禦環境。
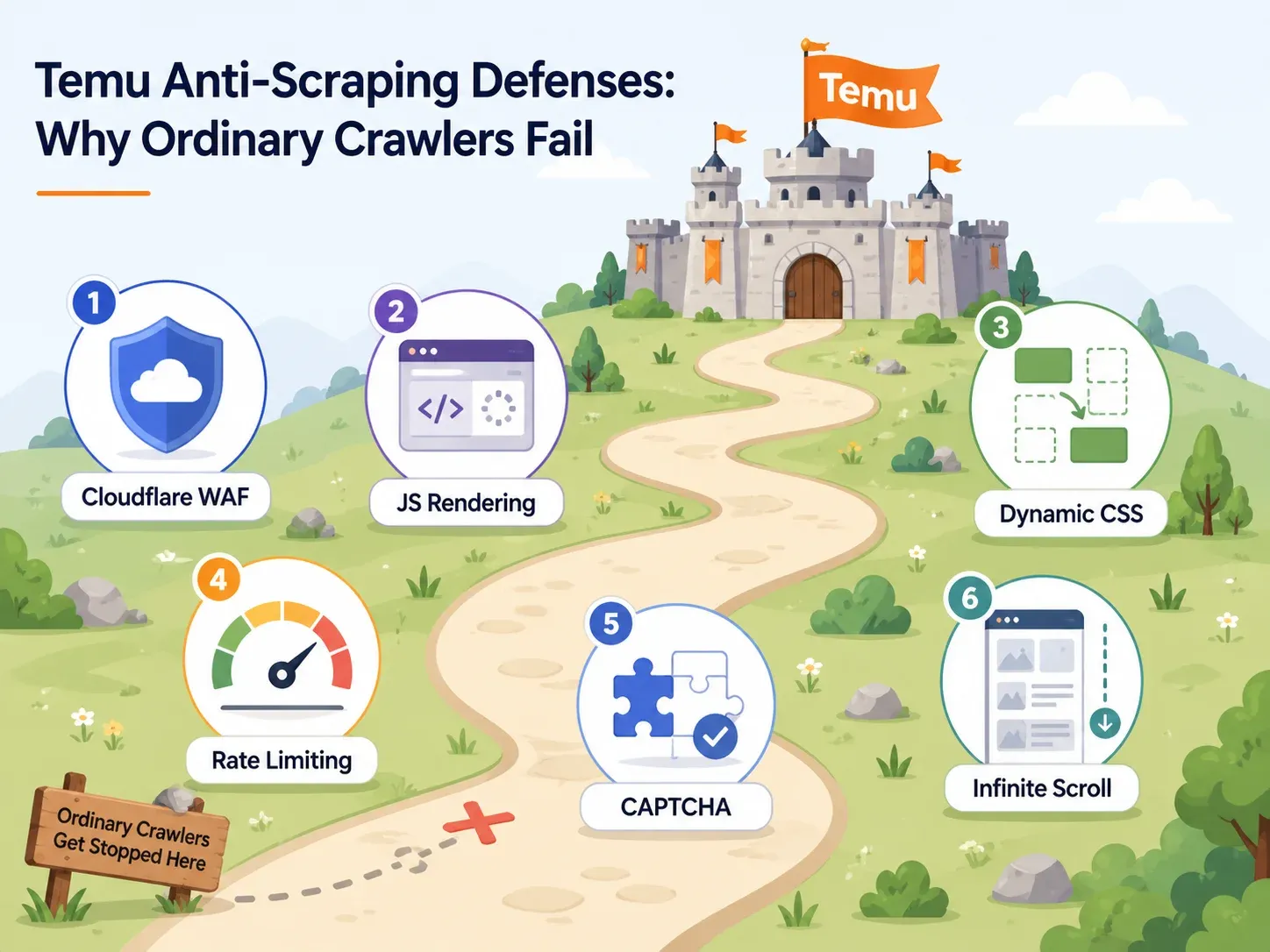
Temu 的反機器人防線:為什麼多數爬蟲會失敗
大多數談 Temu 抓取的文章,只會用一句話帶過反機器人措施:「Temu 有反機器人。」這沒有幫助。
如果您正在選工具,您需要知道 Temu 用的是哪些防禦,以及哪種工具能力能破解它們。下面是實用對照:
| Temu 防禦 | 作用 | 所需工具能力 | 範例工具 |
|---|---|---|---|
| Cloudflare WAF/瀏覽器檢查 | 封鎖自動化 user-agent、識別機器人指紋、回傳驗證頁 | 具備輪換住宅 IP 與真實瀏覽器指紋的雲端基礎設施 | Thunderbit(雲端抓取)、Bright Data、Oxylabs、ScraperAPI |
| 大量 JavaScript 渲染 | 商品資料透過 JS 載入;原始 HTML 是空的 | 無頭瀏覽器或完整瀏覽器渲染 | Thunderbit(瀏覽器抓取模式)、Playwright、Selenium、ParseHub、Apify 瀏覽器 actors |
| 動態 CSS 選擇器 | 類別名稱在每次部署間都會變,CSS 型爬蟲容易失效 | 以 AI 為基礎的欄位偵測(不依賴固定選擇器) | Thunderbit(AI 每次重新讀取頁面)、Bright Data AI scraper builder |
| 速率限制 | 限制快速連續請求 | 具智慧節流的並行雲端請求 | Thunderbit(雲端最多可同時處理 50 頁)、ScraperAPI、Bright Data |
| CAPTCHA 驗證 | 在出現可疑行為後中斷工作階段 | 內建 CAPTCHA 解決或較低觸發策略 | Bright Data、Oxylabs、ScraperAPI premium/ultra-premium |
| 無限捲動/延遲載入 | 若不互動,只會看到第一批商品 | 智慧捲動、分頁偵測、互動自動化 | Thunderbit 分頁、Apify 智慧捲動、Octoparse 工作流程建構器 |
Cloudflare WAF 與 IP 封鎖
Temu 的前門由類似 Cloudflare 的瀏覽器完整性檢查把守。像簡單 Python requests.get() 這種基本 HTTP 請求,通常會被挑戰、回傳 403,或只給不完整資料。
在這種情況下可運作的工具,需要輪換住宅或行動 IP,以及真實的瀏覽器指紋。Cloudflare 2025 Radar 回顧指出,非 AI 機器人在 2025 年初就已佔據約一半的 HTML 頁面請求。這就是 Temu 需要防守的自動化規模。
JavaScript 渲染與動態選擇器
這正是大多數新手爬蟲悄悄失敗的地方。
如果您檢視 Temu 的頁面原始碼,常常會看到一個空殼——真正的商品卡片、價格和圖片是頁面載入後才由 JavaScript 注入的。只讀取原始 HTML 的爬蟲,會什麼都抓不到。再加上 Temu 的 CSS 類別名稱和 DOM 結構會在不同部署間變動。依賴像 .product-card__price 這種固定 CSS 選擇器的爬蟲,今天可用,明天就可能回傳空欄位。
以 AI 為基礎的爬蟲(像 Thunderbit)會每次語意化地讀取頁面,因此不依賴特定類別名稱保持不變。
速率限制與 CAPTCHA 驗證
如果從同一個 IP 太快或太頻繁地打 Temu,就會觸發速率限制或 CAPTCHA 驗證。有些工具透過智慧節流與內建 CAPTCHA 解決來處理;有些則把問題丟給您——對非技術使用者來說,這基本上等於死路一條。
對於雲端抓取,關鍵是把請求分散到乾淨 IP 上,並搭配自動重試邏輯。
依技能等級劃分的最佳 Temu 爬蟲:完整解析
找到您的等級,直接跳到符合的章節:
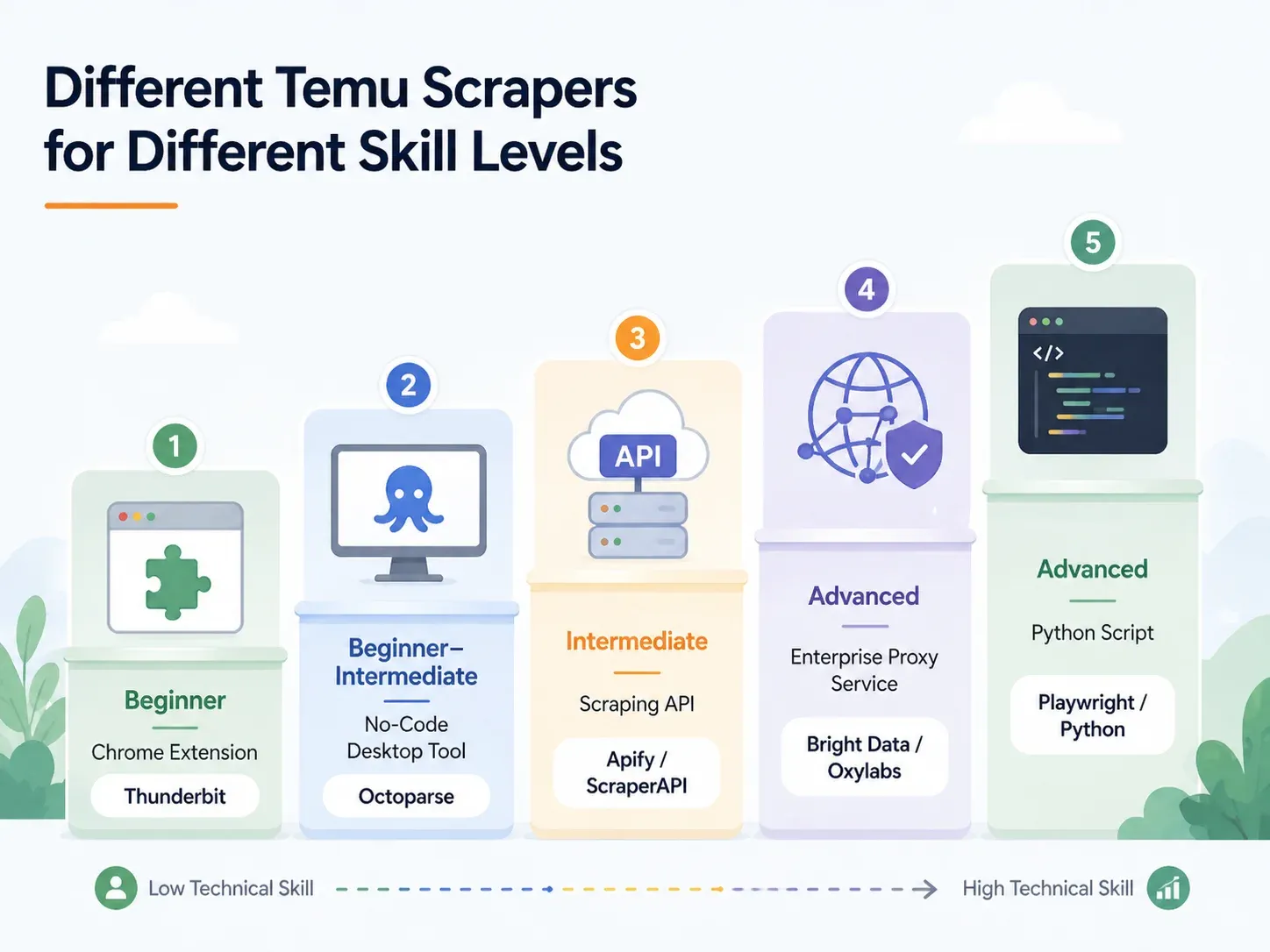
| 方法 | 技能等級 | 設定時間 | 反機器人處理 | 最適合 |
|---|---|---|---|---|
| AI Chrome 擴充功能(例如 Thunderbit) | 新手 | < 2 分鐘 | 已處理(雲端或瀏覽器) | Dropshipper、行銷人員、電商營運 |
| 無程式碼桌面工具(例如 Octoparse、ParseHub) | 新手-中階 | 10–60 分鐘 | 部分處理(需要代理設定) | 需要範本的定期抓取 |
| 抓取 API/服務(例如 ScraperAPI、Apify) | 中階 | 15–45 分鐘 | 內建 | 將資料整合進管線的開發者 |
| 代管代理/企業級(例如 Bright Data、Oxylabs) | 進階/企業級 | 數小時-數天 | 完整基礎設施 | 大量、高吞吐、倉儲交付 |
| 自訂 Python 腳本(Playwright/Selenium) | 進階 | 1–4 小時以上 | 手動(代理 + CAPTCHA 設定) | 完整控制、邊緣情境客製化 |
Thunderbit:最適合非技術使用者的 Temu 爬蟲
Thunderbit 是一款以 AI 驅動的 Chrome 擴充功能,專為商務使用者——銷售團隊、電商營運、Dropshipper、行銷人員——設計,讓他們無需寫程式也能從網站取得結構化資料。我在 Thunderbit 團隊工作,因此對這個產品很熟。以下我會直接說明它能做什麼,以及適合放在哪裡。
核心流程只要兩步:打開 Temu 頁面,點 AI Suggest Fields,檢視系統建議的欄位(商品名稱、價格、圖片、評分等),然後點 Scrape。
Thunderbit 的 AI 會讀取頁面結構並自動提出欄位名稱與資料類型。它不依賴固定的 CSS 選擇器,因此當 Temu 變更類別名稱或卡片版面時,爬蟲可以自動適應。
Temu 相關的重點功能:
- **雲端抓取模式:**對公開頁面更快,最多可同時處理 50 頁。最適合不需要登入的分類頁、搜尋結果與商品列表。
- **瀏覽器抓取模式:**使用您目前的 Chrome 工作階段,包括 cookies、地區設定與登入狀態。當地區、彈窗或登入內容會影響頁面顯示時,這個模式最合適。
- **抓取子頁面:**完成列表頁抓取後,點「抓取子頁面」即可逐一拜訪每個商品詳情頁,並自動追加完整描述、變體、賣家資訊、運送預估和規格等欄位,完全不需額外設定。
- **欄位 AI 提示詞:**在抓取時分類、翻譯或重新格式化資料。例如:「將此商品分類為 Kitchen Utensils、Small Appliances、Storage 或 Other。」
- **排程抓取:**設定自然語言排程(例如「每週一上午 9 點」),輸入網址,Thunderbit 就會在雲端執行抓取,並匯出到 Google Sheets、Airtable 或其他目的地。
- **免費匯出:**Excel、CSV、Google Sheets、Airtable、Notion、JSON——匯出沒有付費牆。圖片在 Airtable 和 Notion 中會以實際附件形式匯出。
價格:免費方案最多 6 頁(試用加碼可到 10 頁);付費方案約從 $15/月(按月)或 $9/月(按年) 起,含 500 點數,1 點數 = 1 筆輸出列。
用 AI 抓取 Temu 資料 Get Started Free
並排比較:Thunderbit 與 Python 腳本在同一個 Temu 頁面上的差異
差距非常明顯:
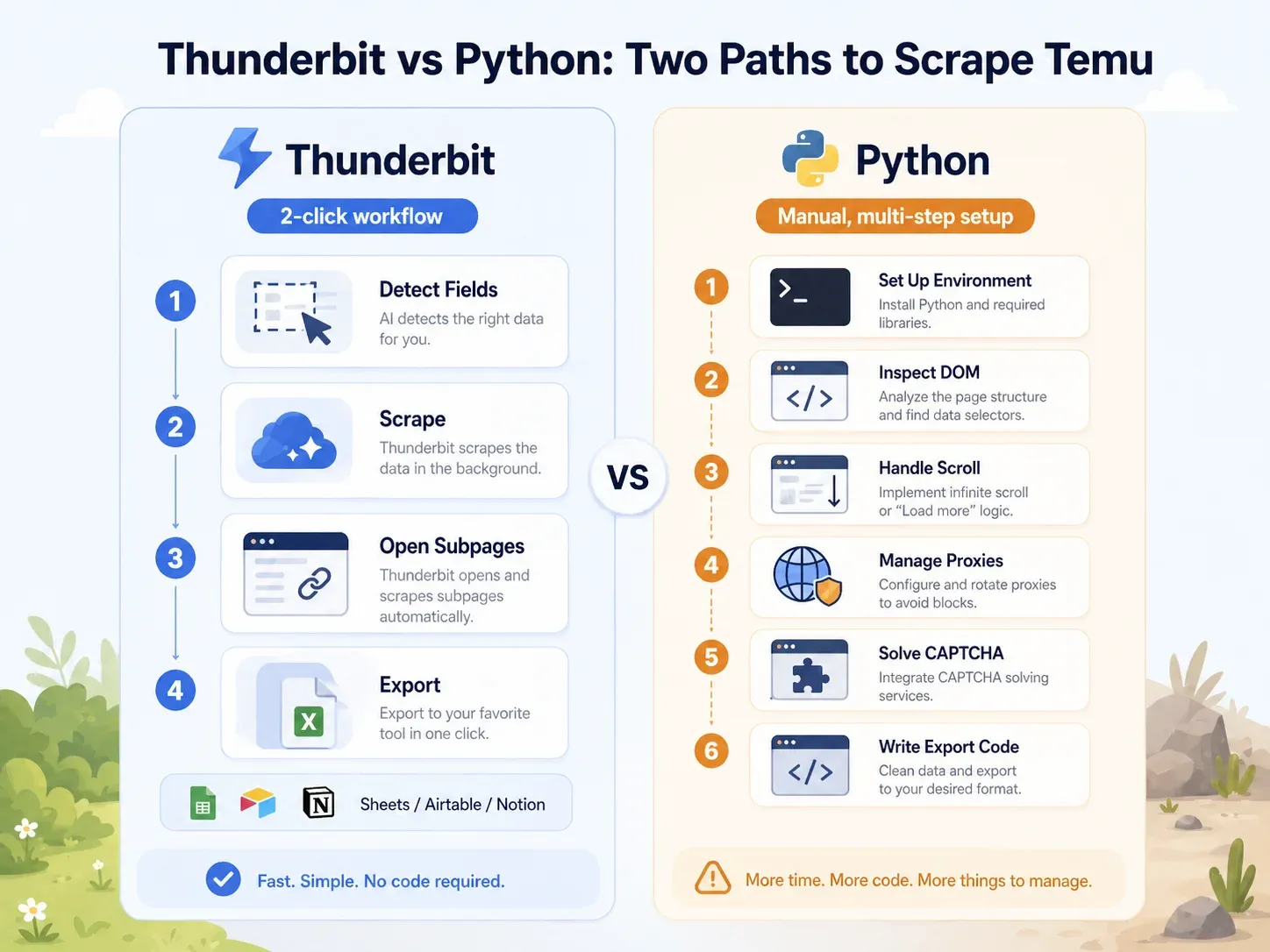
| 任務 | Thunderbit | Python(Playwright) |
|---|---|---|
| 開啟 Temu 分類頁 | 在 Chrome 中開啟頁面 | 設定 Python 環境、安裝 Playwright、安裝瀏覽器 |
| 辨識欄位 | 點選「AI Suggest Fields」 | 檢查 DOM、網路呼叫、JSON 載荷 |
| 處理動態載入 | 瀏覽器/雲端模式 + 分頁 | 撰寫捲動/等待邏輯、攔截請求 |
| 處理封鎖 | 嘗試雲端模式或瀏覽器模式 | 加入代理、標頭、指紋偽裝、重試、CAPTCHA |
| 擷取列表欄位 | 點選「Scrape」 | 撰寫選擇器或 API 解析邏輯 |
| 補強商品頁 | 點選「抓取子頁面」 | 建立獨立的 PDP 爬蟲 |
| 匯出 | 點選 Sheets/Airtable/Notion/Excel | 撰寫 CSV/JSON/Sheets 整合程式碼 |
| 商務使用者的典型設定 | 2 分鐘內完成 | 至少 1–4 小時;且需持續維護 |
一個最小化的 Playwright Temu 原型可能像這樣(偽程式碼——不是可直接上線的版本):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# Production code still needs selectors, proxies, retries,
# CAPTCHA handling, PDP crawling, and export logic.
print(cards.count())
在您抓到任何一個欄位之前,這就已經是 10 行以上,而且還沒碰代理、CAPTCHA、PDP 補強或匯出。對非技術使用者來說,Thunderbit 把整個流程壓縮成幾次點擊。對開發者來說,Python 路線可提供更高控制度——但維護成本也高得多。
Octoparse 與 ParseHub:無程式碼桌面版 Temu 爬蟲
如果您想要比 Chrome 擴充功能更多的控制,但又不想寫程式,Octoparse 和 ParseHub 是主要選項。
Octoparse 有公開的 Temu Details Scraper 範本。它的範例輸出包含商品 ID、標題、價格、賣家/商店資料、圖片網址、折扣、商店網址和詳細規格。這是很大的優勢——您可以直接從範本開始,而不是從零打造工作流程。Octoparse 也支援雲端擷取、排程和視覺化工作流程建構。
Temu 相關的注意事項:
- 反機器人附加項目(住宅代理每 3 美元/GB、CAPTCHA 解決每千次 1~1.50 美元)加起來成本可能不低。
- 當 Temu 變更版面時,範本可能失效。您可能需要更新選擇器,或等待 Octoparse 維護範本。
- 依頁面複雜度不同,設定時間約 10–60 分鐘。
Octoparse 定價:免費方案含 10 個任務與每月 50K 資料匯出;Standard 年繳約 75 美元/月;Professional 年繳約 108 美元/月。代理、CAPTCHA 和代管服務為額外費用。
ParseHub 是一款視覺化桌面/網頁爬蟲,對動態頁面處理得不錯(它會執行完整的 Chromium 瀏覽器)。不過,付費方案從 189 美元/月起跳,對單人營運者來說門檻偏高。我在研究中沒有找到明確的公開 Temu 專屬範本。ParseHub 比較適合已經習慣建構視覺化抓取專案的團隊。
| 工具 | Temu 上的優勢 | Temu 上的弱點 | 價格 |
|---|---|---|---|
| Octoparse | 公開 Temu 範本、視覺化工作流程、雲端擷取、排程 | 範本需要維護,反機器人附加項目增加成本 | 免費;年繳 Standard 約 $75/月;年繳 Pro 約 $108/月;附加項目另計 |
| ParseHub | 動態頁面處理、專案工作流程建構器、付費方案支援 IP 輪換 | 入門價格較高,未找到公開 Temu 範本 | 付費方案自 $189/月起 |
抓取 API:ScraperAPI、Apify 與 Bright Data 用於 Temu
以 API 為基礎的抓取服務會處理代理、渲染與反機器人邏輯,讓開發者專注於解析和儲存資料。當您是在打造管線,而不是跑一次性試算表匯出時,這類工具最合適。
ScraperAPI 是一個提供代理輪換與渲染的開發者 API。其定價頁列出 7 天試用含 5,000 點數、Hobby 方案每月 49 美元含 100,000 點數,之後還有更高階方案。Temu 的難點在於:JavaScript 渲染與高級代理池會依方案每次請求消耗 10–75 點數。這種點數倍率意味著,您每列的實際成本可能遠高於表面價格。
Apify 是一個擁有預建「actors」(爬蟲)的平台。平台上有多個 Temu actor。某個由社群維護的 Temu Scraper 列出在免費方案下約每 1,000 個商品 5 美元的按事件計費;另一個 Temu Products Scraper 則列出每 1,000 筆結果 4 美元。風險在於:actor 品質不一,維護依賴社群,而且有些 actor 可能已停用,或在 Temu 更新後失效。請務必先查看「最後修改」日期與使用者評分,再決定是否採用。
Bright Data 是企業級選項。它的 Temu scraper 頁面表示,工作會在 Bright Data 基礎設施上執行,並具備代理輪換、地理定位、CAPTCHA/解封邏輯與自動擴充。輸出格式包括 JSON、CSV、Parquet,以及直接送到 S3、GCS、Azure Blob、BigQuery 和 Snowflake。業界評測顯示,Web Scraper API 按量計費約每 1,000 筆資料 2.5 美元,承諾方案約從 499 美元/月起。功能很強,但定價是給有實際預算的團隊。
Oxylabs 也有專屬的 Temu Scraper API 頁面。方案從 49 美元/月起,並提供最多 2,000 筆結果的免費試用。對想透過 API 取得結構化 Temu 資料的開發團隊來說,它是 Bright Data 的有力替代方案。
| API/平台 | Temu 專屬證據 | 優勢 | 弱點 | 最適合 |
|---|---|---|---|---|
| ScraperAPI | 未找到 Temu 專頁,但有電商反機器人功能說明 | 簡單端點、JS 渲染、高級代理 | 高級功能有點數倍率;需自行解析資料 | 開發者管線 |
| Apify | Marketplace 中有多個 Temu actors | 若 actor 符合需求且維護良好,是最快的開發路徑 | actor 品質不一;部分已停用 | 想要 actor marketplace + 排程的開發者 |
| Bright Data | 專屬 Temu scraper 頁面 | 企業級基礎設施、解封、倉儲交付 | 昂貴;仍需了解網頁抓取概念 | 企業級資料團隊 |
| Oxylabs | 專屬 Temu Scraper API 頁面 | 每筆清楚計價、JS 處理、IP/CAPTCHA 主張 | 需要開發者 API 工作流程 | 需要 Temu API 存取的開發團隊 |
自訂 Python 腳本(Playwright/Selenium):完整控制,高投入
自訂 Python 爬蟲提供最大的彈性——這是優點。對 Temu 來說,Playwright 通常比 Selenium 更適合作為起點,因為它有自動等待機制,且對大量 JavaScript 的頁面處理更好。
但代價也很高。
原型需要 1–4 小時。生產級爬蟲則需要代理輪換、逼真的瀏覽器指紋、CAPTCHA 策略、重試、資料結構驗證、輸出儲存、監控、告警,以及法務審查。
而且它會壞。Reddit 抓取社群一再提到,當網站使用 Cloudflare、JavaScript 渲染與反機器人指紋時,現代電商抓取非常不穩定。
| 失敗模式 | 典型原因 | 緩解方式 |
|---|---|---|
| 空白 HTML/缺少商品 | 初始 HTML 之後才由 JS 載入商品卡片 | 使用 Playwright,等待網路與 DOM |
| 只有前幾個商品 | 無限捲動/延遲載入 | 捲動迴圈、network idle 等待、卡片數閾值 |
| 價格缺失或不一致 | 地區/工作階段/幣別狀態或反機器人回應 | 設定 locale、cookies、地理定位代理 |
| 403/驗證頁/CAPTCHA | IP 信譽、無頭指紋、請求頻率 | 住宅代理、隱身瀏覽器、降低速率 |
| 選擇器失效 | DOM/類別變更、A/B 測試 | 若可行,改用語意擷取或 API 解析 |
自訂腳本不是「免費」方案。它只是把成本從訂閱費轉移到開發人力、代理帳單、CAPTCHA 成本和維護風險。如果您團隊裡有抓取工程師,且需要特殊邏輯,這是正確路線。對其他人來說,實務上它通常是最昂貴的選擇。
最佳實務:用子頁面抓取取得完整 Temu 商品資料
這是本文中最有影響力的最佳實務——而且幾乎沒有其他指南會提到它。
Temu 的分類頁或搜尋頁只能看到基本資訊:標題、縮圖、價格、大略評分。但真正能讓資料列可執行的欄位——詳細描述、變體列表、完整評論數、運送預估、賣家名稱、規格表——都在商品詳情頁(PDP)裡。
如果您只抓列表頁,就只拿到部分資料集。
兩步驟工作流程:
- 步驟 1 — 抓取列表頁(PLP): 從 Temu 搜尋或分類頁擷取商品名稱、價格、縮圖、評分。
- 步驟 2 — 透過子頁面抓取補強: 逐一造訪每個商品的 PDP,並追加完整描述、評論數、變體選項、運送時間、賣家資訊等欄位。
以下是前後資料差異:
| 欄位 | 來自 PLP(步驟 1) | 從 PDP 新增(步驟 2) |
|---|---|---|
| 商品標題 | ✅ | — |
| 價格 | ✅ | ✅(驗證/折扣%) |
| 縮圖 | ✅ | — |
| 星等評分 | ✅ | ✅(含評論數) |
| 完整描述 | ❌ | ✅ |
| 變體(尺寸、顏色) | ❌ | ✅ |
| 賣家名稱 | ❌ | ✅ |
| 運送預估 | ❌ | ✅ |
| 詳細規格 | ❌ | ✅ |
在 Thunderbit 裡,這只要一個動作:完成第一次抓取後,點「抓取子頁面」。AI 會逐一造訪每個商品網址並追加欄位——不需要額外設定、不需要獨立 spider、不需要維護選擇器。Octoparse 的 Temu Details 範本和 Apify 的 Temu actor 也支援 PDP 層級欄位,但需要更多設定與維護。在 Python 中,您必須另外建立 PDP 爬蟲、維護其選擇器,並處理詳情頁內的分頁——這是相當大的額外投入。
最佳實務:定期抓取 Temu,持續監控價格與庫存
一次性抓取對商品發掘很有用,但競爭情報需要反覆觀察。
價格會變、商品會缺貨、新商品每天都在上架、促銷也會改變折扣深度。每週或每日抓取,能建立一份團隊真正可以採取行動的歷史表格。
值得自動化的三種用途:
- **價格監控:**每週追蹤競品前 50 個 Temu SKU。更新後的價格自動匯出到 Google Sheets,方便和自家定價即時比較。
- **庫存與可用性監控:**偵測熱門商品何時缺貨、何時出現新變體,或運送預估何時變動。
- **新商品/趨勢偵測:**排程每天抓取 Temu 的「新品上架」或優先分類頁。依銷量或評論數排序,及早發現正在升溫的商品。
在 Thunderbit 中,您只要用自然語言描述間隔(例如「每週一上午 9 點」)、輸入目標網址,然後點「排程」。抓取會在雲端執行,並匯出到您選擇的目的地。由於 AI 每次都會重新讀取頁面,排程抓取會自動適應 Temu 的版面變化——Temu 重新設計商品卡片時,您不需要更新選擇器。
替代方案是:設置 cron job、維護 Python 腳本、配置代理輪換、建立輸出管線,並且每次 Temu 改版都要修選擇器。對非技術團隊來說,這根本不可行;對開發者而言,則是持續性的額外負擔。Apify 與 Bright Data 也支援排程執行,但需要更多技術設定與更高的成本底線。
最佳實務:端到端 Temu 資料流程(抓取 → 清理 → 匯出 → 行動)
大多數抓取指南都停在「下載 CSV」。
但商務使用者需要的是能真正放進工作工具中的資料——用 Google Sheets 協作、用 Airtable 建商品資料庫、用 Notion 做團隊儀表板。真正的最佳實務是一套端到端工作流程:
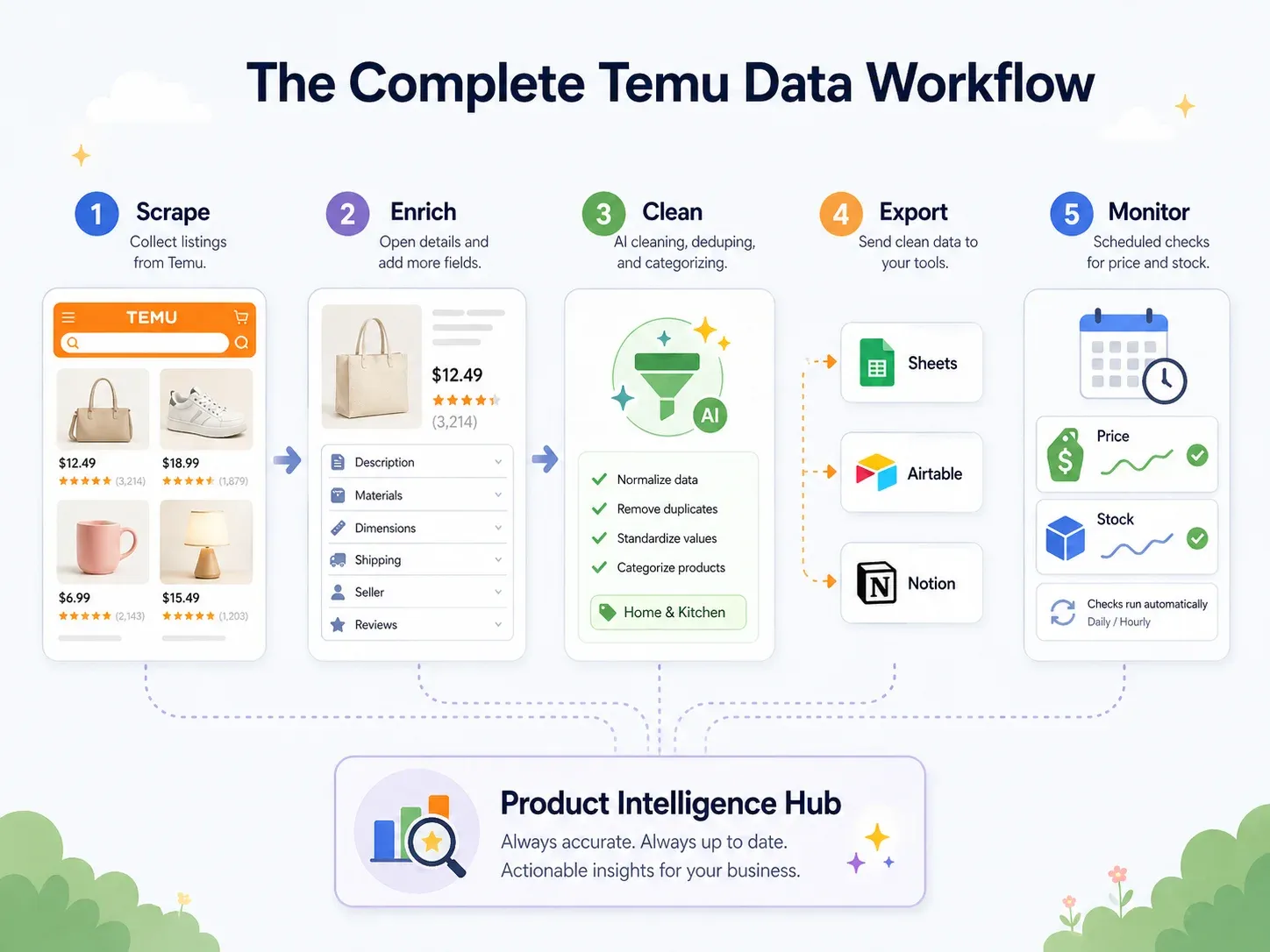
| 流程步驟 | 發生什麼事 | Thunderbit 能力 |
|---|---|---|
| 抓取 | 從 Temu 頁面擷取資料 | AI Suggest Fields → Scrape(2 次點擊) |
| 補強 | 造訪每個商品的詳情頁 | Scrape Subpages(1 次點擊) |
| 清理與標記 | 分類商品、標準化價格、翻譯標題 | 欄位 AI 提示詞——在抓取時標記、格式化、翻譯 |
| 匯出 | 推送到商務工具 | 免費匯出到 Excel、Google Sheets、Airtable、Notion;下載 CSV/JSON |
| 監控 | 追蹤隨時間的變化 | 具自然語言間隔的排程爬蟲 |
舉個具體例子:您抓取 200 個 Temu 廚房商品。抓取過程中,欄位 AI 提示詞會自動把每個商品分類成「Utensils/Small Appliances/Storage/Cleaning/Decor」。價格會標準化成數字化的美元值。中文商品標題會翻譯成英文。資料會直接匯出到 Airtable base,並保留商品圖片(不只是網址,而是實際圖片附件,正如 Thunderbit 的圖片抓取指南 所說)。再透過排程抓取每週更新一次資料。
以下是幾個適用於 Temu 資料的欄位 AI 提示詞範例:
- 「將此商品分類為以下其中之一:Kitchen Utensils、Small Appliances、Storage、Cleaning、Decor、Other。只回傳分類名稱。」
- 「將商品標題翻譯成精簡英文,同時保留品牌名、數量、尺寸與型號。」
- 「將價格標準化為不含貨幣符號的數字。」
- 「根據評分、評論數與銷量,將需求標示為 High、Medium 或 Low。若資料缺失,回傳 Unknown。」
這個流程能把原始抓取轉化成一個持續運作的商品情報資料庫——而不需要開發者另外建立 ETL 管線。
最佳 Temu 爬蟲比較:並排表格
| 工具 | 技能等級 | 設定時間 | 反機器人處理 | 子頁面抓取 | 排程 | 匯出選項 | 價格級距 | 最適合 |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | 新手 | 幾分鐘 | 瀏覽器模式、雲端模式、AI 欄位偵測 | 有(抓取子頁面) | 有(自然語言排程) | Excel、CSV、Google Sheets、Airtable、Notion、JSON | 免費 6 頁;付費約自 $9–15/月起,含 500 點數 | 非技術電商團隊、Dropshipper |
| Octoparse | 新手-中階 | 10–60 分鐘 | 雲端擷取、代理/CAPTCHA 附加項 | 有(範本工作流程) | 有(付費/雲端方案) | Excel、CSV、JSON、HTML、XML、資料庫、Google Sheets | 免費;年繳 Standard 約 $75/月;附加項另計 | 想要視覺化流程 + Temu 範本的營運者 |
| ParseHub | 新手-中階 | 30–60 分鐘 | 動態渲染、付費 IP 輪換 | 有(專案流程) | 付費方案 | CSV/JSON,付費方案支援 Dropbox/S3 | 付費自 $189/月起 | 為動態網站打造視覺化專案的團隊 |
| ScraperAPI | 開發者 | 數小時 | 代理輪換、JS 渲染、高級代理池 | 需自行程式化 | DataPipeline/排程器 | HTML/JSON/CSV | 試用 5K 點數;Hobby $49/月;另有更高方案 | 建立自訂 Temu 管線的開發者 |
| Apify | 中階 | 若 actor 合適,10–30 分鐘 | actor 專屬瀏覽器/代理邏輯 | 依 actor 而定 | 有 | JSON、CSV、Excel、API/datasets | 平台免費;Temu actors 約每 1K 商品 $4–5 | 能評估 actor 品質的開發者/營運者 |
| Bright Data | 進階/企業級 | 數小時-數天 | 完整代理、CAPTCHA、解封、自動擴充 | 透過 scraper/API 自訂 | 有 | JSON、CSV、Parquet、S3、GCS、Azure、BigQuery、Snowflake | 約每 1K 記錄 $2.5 按量計費;承諾方案約自 $499/月 | 企業級資料團隊、大量擷取 |
| Oxylabs | 進階 | 數小時 | JS 處理、IP/CAPTCHA 主張 | 透過 API 自訂 | 有 | JSON/API 輸出 | 自 $49/月起;試用最多 2K 結果 | 需要 Temu API 存取的開發團隊 |
| 自訂 Python(Playwright) | 進階 | 1–4 小時以上;且需持續維護 | 手動代理、CAPTCHA、指紋偽裝 | 完全自訂 | cron/佇列/手動 | 自訂 | 開發時間 + 代理/CAPTCHA/主機成本 | 邊緣案例、擁有抓取工程師的團隊 |
您該選哪一個 Temu 爬蟲?快速建議
- 需要快速做商品研究的 Dropshipper? 先從 Thunderbit 的免費方案 開始。這是把「我想要 Temu 資料」變成「我已經有試算表」最快的方法。如果它能在您的目標頁面上運作(而且對大多數公開分類頁與商品頁都應該可以),就完成了。
- 想要視覺化控制與可重複範本的營運者? Octoparse 有公開的 Temu Details 範本與視覺化工作流程建構器。請預期需要 10–30 分鐘設定,以及一些代理/CAPTCHA 配置。
- 正在打造資料管線或內部工具的開發者? ScraperAPI 或 Apify 可提供能與程式碼及排程工作整合的 API/actor 工作流程。請仔細檢查 Apify actors——確認維護狀態與使用者評分。
- 需要大量 Temu 資料與倉儲交付的企業團隊? Bright Data 是基礎設施路線。雖然昂貴,但它能處理規模、解封,以及送往 S3/BigQuery/Snowflake。
- 需要特殊邏輯的抓取工程師? 自訂 Playwright/Selenium 可提供完全控制。只要預留持續維護、代理成本與 CAPTCHA 處理的預算即可。
對大多數非技術商務使用者來說,我會建議先測試 Thunderbit 的免費方案。最直接的問題永遠是「我能不能從這個特定的 Temu 頁面拿到我需要的列?」——而您可以在兩分鐘內、花不到任何成本回答這個問題。對開發者而言,在正式投入預算之前,請先對 Apify、ScraperAPI 和一個小型 Playwright 原型做每筆成功資料的成本基準測試。
關於抓取 Temu 的常見問題
抓取 Temu 合法嗎?
這取決於司法管轄區、您收集的資料、存取方式,以及您如何使用這些資料。Temu 的 使用條款 明確限制自動化存取,包括爬行、抓取或 spidering 頁面或資料。美國法院對存取公開可得資料曾有較有利的先例(第九巡迴法院的 hiQ v. LinkedIn 判決),但後續裁決也維持了違約與侵入的主張。簡短答案:為研究而抓取公開可得的商品資料,在某些情境下或許站得住腳,但服務條款、隱私法、著作權,以及您如何使用資料都很重要。這不是法律意見——商業用途請諮詢律師。
Temu 多久會改一次網站版面?
沒有公開的固定週期。社群回報與工具生態都把 Temu 視為一個變動頻繁的目標。請假設 CSS 選擇器隨時可能失效,並優先使用 AI/語意化擷取,或採用持續維護中的範本,而不是硬編碼選擇器。
我可以在不被封鎖的情況下抓取 Temu 嗎?
對少量公開頁面,只要節奏得當,是可以的——尤其是使用具備真實瀏覽器渲染、工作階段支援與節流機制的工具。沒有任何工具能保證百分之百不被封鎖。對公開目錄頁而言,搭配輪換 IP 的雲端抓取效果很好;若地區、登入或彈窗會影響資料,使用目前工作階段的瀏覽器抓取通常更有效。
我可以從 Temu 商品頁擷取哪些資料?
常見公開欄位包括商品標題、網址、目前價格、原價、折扣百分比、圖片網址、星等評分、評論數、銷量、賣家/商店名稱、運送資訊、分類、商品規格、變體(顏色、尺寸)以及抓取時間戳記。實際可得欄位取決於頁面類型(列表頁 vs. 詳情頁)與地區。
抓取 Temu 需要代理嗎?
如果是小規模、瀏覽器模式、手動式的擷取(一次幾頁),也許不需要。但若是雲端、排程或高流量收集,通常就需要代理或代管式的防封鎖基礎設施。Thunderbit、Bright Data 和 ScraperAPI 這類工具會把代理管理整合進平台中,您不必另外配置。
如果您想深入了解相關主題,可以參考我們的指南:價格比較的網頁抓取、最佳電商網頁爬蟲、將網站資料抓取到 Excel、以及如何抓取到 Google Sheets。您也可以到 Thunderbit YouTube 頻道 觀看操作示範。
使用 Thunderbit 抓取 Temu Get Started Free
延伸閱讀




