

網路世界的發展速度,早就快到讓人跟不上腳步——比我對咖啡的熱情還要誇張。到了 2026 年,網頁資料擷取早已不是資料工程師的專利,而是商業情報、AI 訓練、流程自動化的核心工具。無論你是要追蹤市場動態、訓練新一代 LLM,還是想掌握競爭對手的價格策略,對即時、結構化網頁資料的需求只會越來越高。而這場資料淘金熱的主角,就是 Python。靠著龐大的生態圈和超直覺的語法,Python 依然是網頁爬蟲的首選語言,從簡單腳本到企業級爬蟲都能輕鬆搞定。
但重點來了:選對 python 網頁爬蟲套件,往往決定你的專案成敗。我看過不少團隊因為選錯工具,卡在反爬牆、或是花大把時間處理亂七八糟的 HTML,明明換個更聰明的函式庫,幾分鐘就能解決。身為長年投入 SaaS、自動化、AI 領域的開發者(同時也是 Thunderbit 的創辦人,專注讓爬蟲變得更簡單),我特別整理出 2026 年最值得推薦的 12 款 python 網頁爬蟲套件,每一款都有自己的特色、適用場景和優缺點。現在就帶你找到最適合你的資料擷取神器。
為什麼選對 python 網頁爬蟲套件這麼重要?
用 AI 從任何網站抓取資料 Get Started Free
說真的,每個爬蟲專案的需求都不一樣。有時你只需要從靜態頁面抓幾個商品價格,有時卻得面對 JavaScript 滿天飛、比貓洗澡還難搞的網站。選對套件能幫你省下大把時間、減少錯誤,還能避開反爬封鎖或 HTML 結構混亂等常見陷阱。
Python 在網頁爬蟲領域的熱門不是假的。像 requests、urllib3 這類函式庫,每月下載量都超過 10 億次,幾乎所有主流爬蟲工具都以 Python 為主。但能力越大,責任越大:選錯工具,你的專案可能慢得像撥接網路;選對工具,還沒喝完咖啡就能拿到乾淨的結構化資料。
我們如何挑選最佳 python 網頁爬蟲套件?
我不是隨便從 PyPI 排行榜亂挑。每個套件我都從以下幾個面向評估:
- 效能與併發能力: 能不能快速抓取數百、數千頁?
- 易用性: 新手友善嗎?還是要有資工博士才能上手?
- HTML 解析能力: 能處理破碎標記、支援 XPath/CSS 選擇器、資料擷取是否順暢?
- 動態內容支援: 能不能搞定 JavaScript 網站?還是只能抓靜態頁?
- 社群與文件: 有沒有活躍的用戶、完整的教學?還是只能在 Stack Overflow 求救?
- 最佳應用場景: 適合快速腳本、大型爬蟲,還是介於兩者之間?
此外,我也參考了開發者實戰回饋、最新效能測試,以及自己多年踩坑的經驗。現在,就來認識這些強者吧。
1. Thunderbit
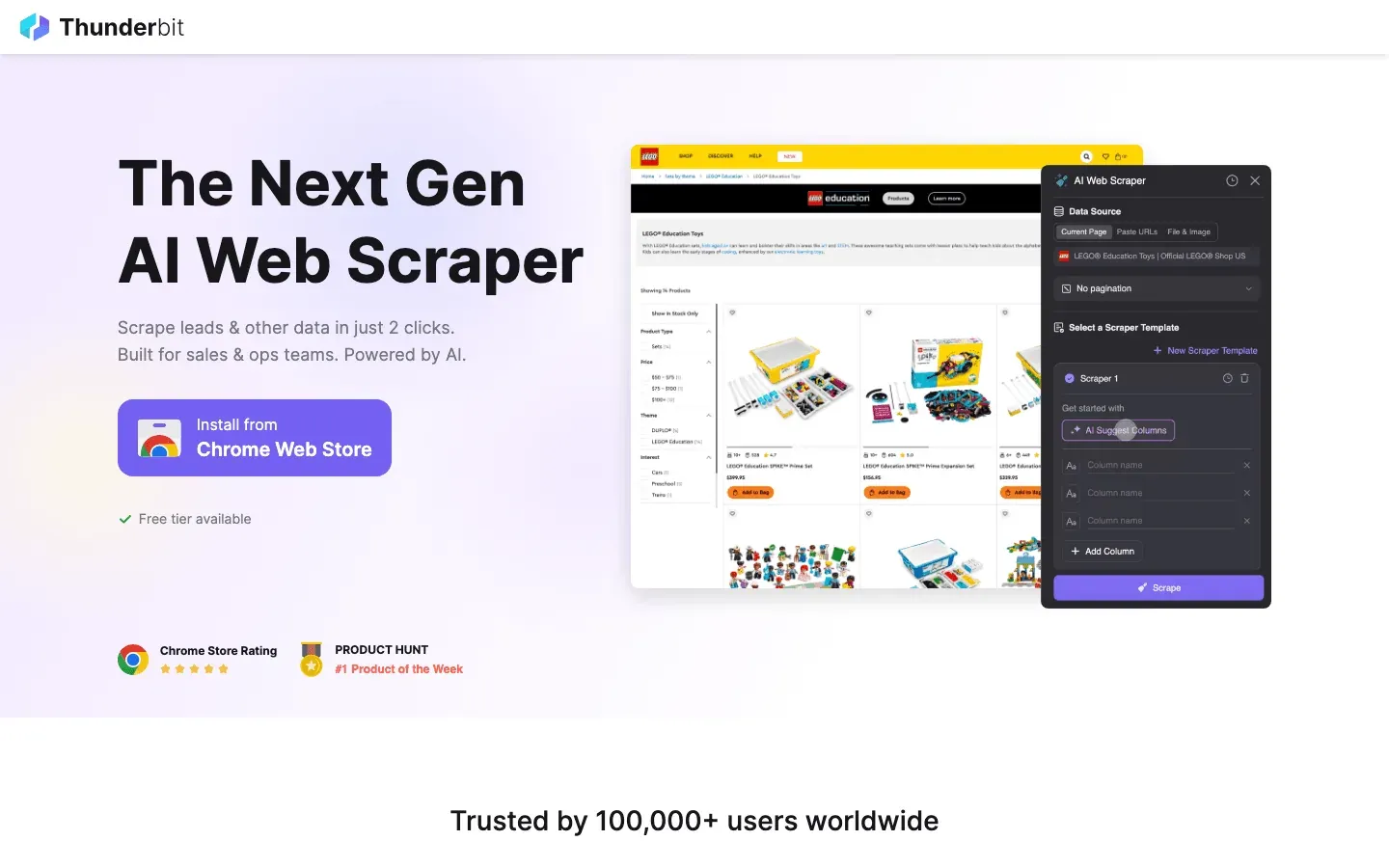 Thunderbit 並不是傳統的 Python 函式庫,而是一款 AI 驅動的 Chrome 擴充功能,徹底改變了網頁爬蟲的玩法。對於追求速度、精準度與 AI 智能的 Python 開發者來說,Thunderbit 是不可多得的利器。它最大特色是支援自然語言指令,你只要用中文或英文描述想抓什麼資料,AI 就會自動判斷欄位、處理分頁、子頁面、甚至直接匯出到 Excel、Google Sheets、Notion 或 Airtable。
Thunderbit 並不是傳統的 Python 函式庫,而是一款 AI 驅動的 Chrome 擴充功能,徹底改變了網頁爬蟲的玩法。對於追求速度、精準度與 AI 智能的 Python 開發者來說,Thunderbit 是不可多得的利器。它最大特色是支援自然語言指令,你只要用中文或英文描述想抓什麼資料,AI 就會自動判斷欄位、處理分頁、子頁面、甚至直接匯出到 Excel、Google Sheets、Notion 或 Airtable。
Thunderbit 對於結構混亂、難以解析的網站特別有用——像是雜亂的目錄、商品列表、或 HTML 結構像抽象畫一樣的頁面。AI 智能欄位建議功能會自動分析頁面,推薦最適合的資料欄位;子頁面爬取則能自動點擊連結,補充更多細節。遇到反爬封鎖也不怕,Thunderbit 提供瀏覽器端與雲端爬取雙模式。
Python 開發者常用 Thunderbit 來做快速原型、名單蒐集、市場調查。你可以直接把結果接到 Python 資料流程,甚至用 API 自動化整個爬蟲任務。雖然不是傳統的程式庫,但已成為想省下寫程式時間、專注資料分析的開發者新寵。
主要特色:
- AI 智能欄位建議與資料擷取
- 支援子頁面、分頁、PDF/圖片擷取
- 一鍵匯出 CSV、Excel、Google Sheets、Notion、Airtable
- 完全免寫程式,適合新手與專業開發者
- 免費方案可用,付費彈性升級
最適合: 名單蒐集、市場調查、快速原型、結構混亂或複雜網頁資料擷取。
2. Beautiful Soup
 Beautiful Soup 是 Python HTML 解析界的元老。新手入門、靜態頁面資料擷取的首選。它特別擅長處理結構雜亂的 HTML(俗稱「標籤湯」),對於不按牌理出牌的網站非常實用。
Beautiful Soup 是 Python HTML 解析界的元老。新手入門、靜態頁面資料擷取的首選。它特別擅長處理結構雜亂的 HTML(俗稱「標籤湯」),對於不按牌理出牌的網站非常實用。
API 設計直觀易懂,像 .find()、.select()、.text 等方法,搭配 requests 抓取網頁超順手。底層可選不同解析器(如 lxml 速度快、html5lib 相容性高)。文件齊全、社群龐大。
主要特色:
- 直覺、Python 風格的 HTML/XML 解析 API
- 能優雅處理破碎或不規則標記
- 支援多種解析器,速度與相容性兼顧
- 社群活躍、教學資源豐富
最適合: 快速腳本、靜態頁面爬取、新手入門。
3. Scrapy
 Scrapy 是大型自動化爬蟲的王者。需要抓數百、數千頁、管理資料流程、定時任務?Scrapy 就是你的框架。基於 Twisted 引擎,支援非同步高效爬取、資料清洗流程、內建多種匯出格式(JSON、CSV、資料庫)。
Scrapy 是大型自動化爬蟲的王者。需要抓數百、數千頁、管理資料流程、定時任務?Scrapy 就是你的框架。基於 Twisted 引擎,支援非同步高效爬取、資料清洗流程、內建多種匯出格式(JSON、CSV、資料庫)。
Scrapy 可擴充性強,有代理、快取、甚至有限度的 JavaScript 處理(可整合 Splash 或 Selenium)。學習曲線比 Beautiful Soup 陡峭,但想玩大規模爬蟲,Scrapy 絕對值得投入。
主要特色:
- 非同步高效爬取
- 內建資料清洗、儲存流程
- 多種匯出格式(JSON、CSV、DB)
- 社群龐大、外掛豐富
最適合: 大型、定期爬蟲專案、資料流程自動化、追求速度與穩定性者。
4. Selenium
 Selenium 是處理 JavaScript 動態網站、互動式頁面的首選。它能自動操作真實瀏覽器(Chrome、Firefox 等),模擬點擊、滾動、表單填寫等行為。只要資料是 JS 動態產生的,Selenium 幾乎都能搞定。
Selenium 是處理 JavaScript 動態網站、互動式頁面的首選。它能自動操作真實瀏覽器(Chrome、Firefox 等),模擬點擊、滾動、表單填寫等行為。只要資料是 JS 動態產生的,Selenium 幾乎都能搞定。
缺點是速度慢、資源消耗大——每次爬取都要開一個完整瀏覽器,不適合大規模批次處理。但遇到其他工具無法突破的動態網頁,Selenium 就是救星。
主要特色:
- 完整瀏覽器自動化(支援 Chrome、Firefox、Edge 等)
- 處理 JavaScript 動態內容、互動元素
- 支援無頭模式(無 UI 更快)
- 社群成熟、文件齊全
最適合: 動態 JS 網站、登入流程自動化、處理 CAPTCHA 或複雜互動。
5. PyQuery
 PyQuery 把 jQuery 的語法帶進 Python,對有前端經驗的開發者特別友善。底層用
PyQuery 把 jQuery 的語法帶進 Python,對有前端經驗的開發者特別友善。底層用 lxml 解析,支援 CSS 選擇器,像 $('div.classname') 一樣選取元素。
PyQuery 適合快速原型、追求簡潔程式碼的開發者。複雜查詢比 Beautiful Soup 更快,也能與 async 工具或 Selenium 結合。
主要特色:
- jQuery 風格選擇器與語法
- 以 lxml 為後端,解析速度快
- 前端轉後端開發者上手無痛
- 支援鏈式查詢、語法簡潔
最適合: 快速原型、jQuery 愛好者、追求簡潔 HTML 解析。
6. LXML
 LXML 是 Python 解析 HTML/XML 的效能怪獸。基於 C 語言的
LXML 是 Python 解析 HTML/XML 的效能怪獸。基於 C 語言的 libxml2 與 libxslt,速度極快,支援 XPath、CSS 選擇器。處理大型文件或複雜查詢時,lxml 是首選。
可單獨使用,也能作為 Beautiful Soup、PyQuery 的解析器。API 稍進階,但效能與彈性值得投入。
主要特色:
- Python 最快的 HTML/XML 解析
- 完整支援 XPath、CSS 選擇器
- 高效處理大型、複雜文件
- 可獨立或作為其他函式庫解析器
最適合: 高效能解析、大型爬蟲、進階查詢需求。
7. Requests
 Requests 是 Python HTTP 請求的標準配備。API 直觀,
Requests 是 Python HTTP 請求的標準配備。API 直觀,requests.get(url) 就能抓網頁,支援 cookies、session、JSON 解碼。
雖然是同步(每次請求需等待),但對於小型腳本、靜態頁面爬取非常夠用。搭配 Beautiful Soup 或 lxml,經典爬蟲組合。
主要特色:
- 簡單、Python 風格的 HTTP 請求 API
- 支援 cookies、session、重導向
- 與解析函式庫無縫整合
- 社群龐大、文件豐富
最適合: 簡單腳本、靜態頁面爬取、新手快速上手。
8. MechanicalSoup
 MechanicalSoup 是輕量級自動化瀏覽器互動工具,能自動填表、處理多步驟登入流程,但不需啟動完整瀏覽器。它結合了
MechanicalSoup 是輕量級自動化瀏覽器互動工具,能自動填表、處理多步驟登入流程,但不需啟動完整瀏覽器。它結合了 requests 與 Beautiful Soup,速度比 Selenium 快,適合不依賴 JS 的網站。
需要登入、送出表單、點擊幾個頁面(網站不太動態)時,MechanicalSoup 是很好的折衷方案。
主要特色:
- 自動化表單填寫、頁面導航
- 基於 Requests 與 Beautiful Soup
- 輕量快速(無瀏覽器負擔)
- 適合中度互動需求
最適合: 需登入或表單提交、簡單自動化、想避開 Selenium 負擔者。
9. Aiohttp
 Aiohttp 是高效非同步 HTTP 請求利器。需要同時抓取數百頁?aiohttp 可並行發送請求,大幅縮短總執行時間。實測 50 頁只需 3 秒,傳統同步 requests 則要 16 秒(效能比較)。
Aiohttp 是高效非同步 HTTP 請求利器。需要同時抓取數百頁?aiohttp 可並行發送請求,大幅縮短總執行時間。實測 50 頁只需 3 秒,傳統同步 requests 則要 16 秒(效能比較)。
需撰寫 async def、await,但大規模爬蟲值得投入。
主要特色:
- 非同步 HTTP 客戶端/伺服器框架
- 支援 session、cookies、HTTP/2
- 併發請求大幅提速
- 可與 async 解析函式庫整合
最適合: 高速、大規模爬蟲、API 批次抓取、熟悉 async 的開發者。
10. Twisted
 Twisted 是 Scrapy 背後的事件驅動網路引擎。雖然不是專門的爬蟲函式庫,但進階用戶可直接用 Twisted 寫自訂爬蟲、處理非 HTTP 協議、打造超高併發爬蟲。
Twisted 是 Scrapy 背後的事件驅動網路引擎。雖然不是專門的爬蟲函式庫,但進階用戶可直接用 Twisted 寫自訂爬蟲、處理非 HTTP 協議、打造超高併發爬蟲。
功能強大但學習曲線陡峭,適合高度自訂需求或自行開發框架者。
主要特色:
- 事件驅動網路(HTTP、WebSocket、SSH 等)
- 支援 SSL、併發、自訂協議
- Scrapy 非同步引擎基礎
- 彈性高,適合進階應用
最適合: 自訂協議、打造爬蟲框架、進階開發者。
11. Grab
 Grab 是一站式爬蟲工具包,結合 HTTP 請求、解析、自動化、代理輪換、CAPTCHA 處理。類似 Scrapy,但更易學易用,內建代理、快取、非同步爬蟲。
Grab 是一站式爬蟲工具包,結合 HTTP 請求、解析、自動化、代理輪換、CAPTCHA 處理。類似 Scrapy,但更易學易用,內建代理、快取、非同步爬蟲。
最大亮點是 Grab:Spider 系統,能用 multicurl 同時發送數千請求。想要一站式解決方案、又不想學 Scrapy,Grab 值得一試。
主要特色:
- 內建代理、User-Agent 輪換、快取
- 非同步爬蟲系統,高併發
- XPath 解析、模組化架構
- 已用於大型專案
最適合: 一站式爬蟲、代理/驗證碼密集任務、想要 Scrapy 功能但更簡單者。
12. Urllib3
 Urllib3 是許多 Python HTTP 客戶端(如 Requests)的底層引擎。支援連線池、執行緒安全、重試、細緻控制 HTTP 連線。多數開發者間接使用,但需要極致效能或自建高階函式庫時,urllib3 是首選。
Urllib3 是許多 Python HTTP 客戶端(如 Requests)的底層引擎。支援連線池、執行緒安全、重試、細緻控制 HTTP 連線。多數開發者間接使用,但需要極致效能或自建高階函式庫時,urllib3 是首選。
新手不如用 Requests,但 urllib3 經過大量實戰驗證,穩定可靠。
主要特色:
- 連線池、執行緒安全
- 精細控制 HTTP 連線
- 許多函式庫的基礎
- 重複請求效能高
最適合: 自訂 HTTP 客戶端、多執行緒爬蟲、開發高階函式庫。
一覽表:python 網頁爬蟲套件比較
| 套件 | 易用性 | 效能 | 動態內容 | 解析能力 | 社群/文件 | 最適合 |
|---|---|---|---|---|---|---|
| Thunderbit | ★★★★☆ (GUI/AI) | 快速 (雲端/本地) | 有 (AI 支援) | 自動欄位、子頁面 | 新興 (AI 熱潮) | 名單蒐集、市場調查、免寫程式用戶 |
| Beautiful Soup | ★★★★★ (超易用) | 中等 | 無 | HTML/XML,容錯高 | 超大 | 靜態頁面、新手 |
| Scrapy | ★★☆☆☆ (進階) | ★★★★★ (極快) | 僅外掛支援 | CSS/XPath、流程 | 大型、活躍 | 大型、定期爬蟲 |
| Selenium | ★★☆☆☆ (中等) | ★☆☆☆☆ (慢) | 有 (完整) | DOM、JS | 成熟 | JS 動態、互動網站 |
| PyQuery | ★★★★☆ (jQuery) | 快速 (lxml) | 無* | jQuery 選擇器 | 中等 | 快速原型、jQuery 開發者 |
| LXML | ★★★☆☆ (進階) | ★★★★★ (最快) | 無 | XPath/CSS, XML | 中等 | 大型文件、進階查詢 |
| Requests | ★★★★★ (超易用) | ★★☆☆☆ (同步) | 無 | HTTP, JSON | 超大 | 簡單腳本、靜態頁 |
| MechanicalSoup | ★★★★☆ (易用) | ★★☆☆☆ (同步) | 無 | 表單、自動導航 | 小型 | 登入流程、自動化 |
| Aiohttp | ★★☆☆☆ (async) | ★★★★★ (併發) | 無 | 非同步 HTTP | 大型 (async) | 高速、大規模爬蟲 |
| Twisted | ★☆☆☆☆ (複雜) | ★★★★★ (自訂) | 無 | 網路協議 | 小眾 | 自訂框架、進階用戶 |
| Grab | ★★★☆☆ (模組化) | ★★★★☆ (非同步) | 無 | 代理、XPath | 小型 | 一站式、代理/驗證碼密集 |
| Urllib3 | ★★★★☆ (底層) | ★★★★☆ (連線池) | 無 | HTTP、連線池 | 超大 | 自訂客戶端、多執行緒爬蟲 |
*PyQuery 可搭配 Selenium 處理動態網站。
如何選擇最適合你的 python 網頁爬蟲套件?
2026 年資料擷取是什麼?怎麼做? Get Started Free
到底該選哪一套?這裡有一張快速對照表:
- 靜態頁面、小型專案、新手入門: 先用 Requests + Beautiful Soup。
- 大規模、定期、商業級爬蟲: Scrapy 或 Grab(想要一站式)。
- JavaScript 動態、互動網站: Selenium(或想免寫程式、AI 智能就選 Thunderbit)。
- 高速、大量併發: Aiohttp(熟悉 async 的話)。
- 表單自動化、登入流程: MechanicalSoup(簡單)、Selenium(複雜 JS)。
- 進階解析、大型文件: LXML 或 PyQuery。
- 自訂網路協議: Twisted。
- 快速原型、名單蒐集、結構雜亂資料: Thunderbit。
其實很多專案會混用多種工具,發揮最大效率。例如用 Selenium 渲染頁面,再交給 Beautiful Soup 或 PyQuery 解析。
結語:用對 Python 工具,讓網頁爬蟲如虎添翼
2026 年的網頁爬蟲,比以往更強大、更不可或缺。選對 Python 套件,你就能把網路的混亂資訊,轉化為乾淨、可用的資料,無論是商業決策、學術研究,還是你的下一個創新專案。無論你是資深開發者,還是剛踏入資料世界的新手,這份清單裡一定有適合你的工具。
想體驗 AI 智能、免寫程式的爬蟲?Thunderbit 絕對值得一試。想學更多技巧、深度教學,歡迎追蹤 Thunderbit Blog,掌握最新網頁爬蟲、自動化、資料應用趨勢。
祝你爬蟲順利——願你的選擇器永遠精準,代理永不失效,資料乾淨如你的程式碼。
常見問題
1. 新手最推薦哪個 python 網頁爬蟲套件?
對大多數新手來說,Requests 搭配 Beautiful Soup 是最容易上手的組合。API 直觀、教學多,靜態頁面爬取綽綽有餘。
2. Python 如何抓取 JavaScript 動態網站?
用 Selenium 自動操作瀏覽器,或試試 Thunderbit,AI 智能、免寫程式也能搞定動態內容。大規模需求可用 Scrapy 搭配 Splash 或 Selenium。
3. 大型、高速爬蟲推薦哪個套件?
Scrapy 專為大規模、非同步爬取設計。如果追求極速、熟悉 async,aiohttp 也是高併發首選。
4. 這些套件可以混合使用嗎?
當然!很多開發者會用 Requests 或 Selenium 抓頁面,再交給 Beautiful Soup、lxml、PyQuery 解析。Thunderbit 匯出的資料也能直接進 Python 做進一步分析。
5. Thunderbit 是 Python 函式庫還是獨立工具?
Thunderbit 是 AI 驅動的 Chrome 擴充功能與平台,不是傳統 Python 函式庫。但它的輸出(CSV、Excel、Sheets、Notion、Airtable)可無縫接入 Python 資料流程,是 Python 開發者的強力助手。
想在網頁爬蟲領域搶先一步?歡迎訂閱 Thunderbit YouTube 頻道,並持續關注 Thunderbit Blog,獲取更多教學、比較與自動化技巧。
免費體驗 Thunderbit 人工智慧網頁爬蟲 Get Started Free
延伸閱讀




