
網頁爬取該用哪種程式語言?答案其實要看你的專案——而我看過不少開發者因為選錯語言,最後直接卡死。
網頁爬取軟體市場在 。選對語言,代表你可以更快做完、少花時間維護;選錯了,最後只會換來壞掉的爬蟲和被白白浪費的週末。
我做自動化工具已經很多年了。以下是我用過的七種爬取語言——包含程式碼範例、實際取捨,以及什麼情況下你其實該直接跳過寫程式,改用 。
我們如何選出最佳的網頁爬取語言
談到網頁爬取,不是每種程式語言都一樣好用。我看過專案因為幾個關鍵因素一飛沖天,也看過它們因此翻車:
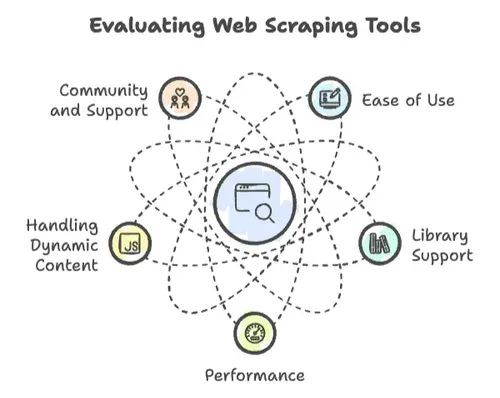
- 易用性: 上手有多快?語法是不是夠友善,還是你得先拿到電腦科學博士學位才印得出「Hello, World」?
- 函式庫支援: 有沒有穩定的 HTTP 請求、HTML 解析與動態內容處理函式庫?還是你得自己從零造輪子?
- 效能: 能不能處理數百萬頁的爬取,還是跑幾百頁就撐不住了?
- 動態內容處理: 現代網站很愛 JavaScript,你的語言跟得上嗎?
- 社群與支援: 當你卡關時——而且你一定會卡——有沒有社群能幫你一把?
根據這些標準,再加上大量熬夜測試,以下是我會介紹的七種語言:
- Python:初學者與專業人士都愛用的首選。
- JavaScript 與 Node.js:動態內容之王。
- Ruby:語法乾淨,腳本寫得快。
- PHP:伺服器端的簡單利器。
- C++:需要極致速度時的選擇。
- Java:企業級、可擴展。
- Go(Golang):快速而且具備並行能力。
如果你正在想:「Shuai,我根本不想寫程式。」那就先別走,文章最後會介紹 Thunderbit。
Python 網頁爬取:最適合新手的強大方案
先從大家最愛的 Python 開始。如果你問一屋子的資料人員:「網頁爬取最好的程式語言是什麼?」你大概會像在 Taylor Swift 演唱會聽到萬人齊聲一樣,聽到大家一起喊 Python。
為什麼選 Python?
- 語法對新手友善: 你幾乎可以把 Python 程式直接唸出來,而且聽起來還很像英文。
- 無可匹敵的函式庫支援: 從用來解析 HTML 的 、用於大規模爬取的 、負責 HTTP 的 ,到瀏覽器自動化的 ——Python 幾乎什麼都有。
- 超大社群: 光是網頁爬取相關的 。
Python 範例程式:抓取頁面標題
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: \{title\}")優勢:
- 開發與原型製作速度快。
- 教學與問答資源非常多。
- 很適合資料分析——先用 Python 抓資料,再用 pandas 分析、matplotlib 視覺化。
- 函式庫也一直在進化:Scrapy 2.14 版本(2026 年 1 月)已在整個框架中原生加入
async/await,所以非同步不再只是 Selenium/Playwright 的專利。
限制:
- 跟編譯型語言相比,大量任務時速度較慢。
- 面對超動態網站時可能有點笨重(不過 Selenium 和 Playwright 可以幫上忙)。
- 不適合以閃電速度爬取數百萬頁。
結論:
如果你是爬取新手,或只是想趕快把事情做完,Python 就是最好的網頁爬取語言——沒有之一。 。
JavaScript 與 Node.js:輕鬆爬取動態網站
如果 Python 是瑞士刀,那 JavaScript(以及 Node.js) 就是電鑽——特別適合爬取現代、JavaScript 密集型網站。
為什麼選 JavaScript/Node.js?
- 動態內容原生支援: 它在瀏覽器裡執行,所以能看到使用者看見的內容——即使網站是用 React、Angular 或 Vue 建的。
- 預設支援非同步: Node.js 可以同時處理數百個請求。
- 對網頁開發者很熟悉: 如果你做過網站,本來就已經會一些 JavaScript。
核心函式庫:
- :支援多瀏覽器(Chromium、Firefox、WebKit),具備自動等待與每個 context 的代理設定。如果你在 2026 年要開始新的 Node 爬蟲,這是預設首選。
- :透過 Chrome DevTools Protocol 控制無頭 Chrome。對只跑 Chrome 的工作,以及需要較輕依賴的情境,仍然很穩。
- :Node 端類似 jQuery 的 HTML 解析工具,當你不需要真實瀏覽器時很好用。
Node.js 範例程式:使用 Puppeteer 抓取頁面標題
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: $\{title\}`);
8 await browser.close();
9})();優勢:
- 原生處理 JavaScript 渲染內容。
- 很適合爬取無限捲動、彈出視窗與互動式網站。
- 適合大規模、並行爬取。
限制:
- 非同步程式設計對新手來說可能不太直覺。
- 無頭瀏覽器如果同時跑太多,會很吃記憶體。
- 相較 Python,資料分析工具較少。
什麼時候 JavaScript/Node.js 是最好的網頁爬取語言?
當你的目標網站是動態的,或你想自動化瀏覽器操作時。 。
Ruby:適合快速網頁爬取腳本的乾淨語法
Ruby 不只是給 Rails 應用和優雅程式散文用的。它也是網頁爬取的好選擇——尤其是如果你喜歡程式碼讀起來像俳句。
為什麼選 Ruby?
- 可讀性高、表達力強: 你可以寫出一個 Ruby 爬蟲,讀起來幾乎跟你的購物清單一樣簡單。
- 很適合原型製作: 寫得快,也容易調整。
- 核心函式庫: 用於解析的 ,以及用於自動化導覽的 。
Ruby 範例程式:抓取頁面標題
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #\{title\}"優勢:
- 非常易讀又簡潔。
- 很適合小型專案、一次性腳本,或你本來就已經在用 Ruby 的情況。
限制:
- 大型任務時,速度比 Python 或 Node.js 慢。
- 用於爬取的函式庫較少,社群支援也較弱。
- 不太適合爬取 JavaScript 密集型網站(雖然可以用 Watir 或 Selenium)。
最適合:
如果你本來就是 Ruby 開發者,或只是想快速寫個腳本,Ruby 會讓人很愉快;但若要做大規模、動態爬取,還是另尋他法。
PHP:伺服器端網頁資料擷取的簡單方案
PHP 看起來像是早期網路的遺物,但它其實還活得很好——尤其當你想直接在伺服器上抓資料時。
為什麼選 PHP?
- 到處都能跑: 大多數網站伺服器本來就有 PHP。
- 容易與網頁應用整合: 一次完成抓取與網站顯示。
- 核心函式庫: 用於 HTTP 的 、用於請求的 、以及無頭瀏覽器自動化的 。
PHP 範例程式:抓取頁面標題
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>優勢:
- 很容易部署到網站伺服器上。
- 很適合當作網頁工作流程的一部分來爬取。
- 對簡單的伺服器端爬取任務來說速度快。
限制:
- 進階爬取的函式庫支援有限。
- 不適合高併發或大規模爬取。
- 處理 JavaScript 密集型網站比較麻煩(不過 Panther 有幫助)。
最適合:
如果你的技術棧本來就是 PHP,或你想在網站上抓資料並直接顯示,PHP 是實用的選擇。 。
C++:適合大規模專案的高效能網頁爬取
C++ 就像程式語言裡的肌肉車。如果你需要原始速度與控制力,而且不怕動手做一點苦工,C++ 可以帶你很遠。
為什麼選 C++?
- 快到飛起: 在 CPU 密集型任務上,速度勝過多數語言。
- 細粒度控制: 可以管理記憶體、執行緒與各種效能調校。
- 核心函式庫: 用於 HTTP 的 、用於解析的 。
C++ 範例程式:抓取頁面標題
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}優勢:
- 大型爬取任務的速度無可匹敵。
- 很適合把爬取功能整合進高效能系統。
限制:
- 學習曲線很陡(咖啡請先備好)。
- 需要手動管理記憶體。
- 高階函式庫較少;不太適合動態內容。
最適合:
當你需要爬取數百萬頁,或效能是絕對關鍵時。否則,你可能花在除錯的時間比爬資料還多。
Java:企業級網頁爬取解決方案
Java 是企業世界的主力工作馬。如果你要打造的是能長期運作、處理大量資料,還能在殭屍末日活下來的系統,那 Java 就是你的朋友。
為什麼選 Java?
- 穩健且可擴展: 很適合大型、長期運作的爬取專案。
- 強型別與錯誤處理: 上線後驚喜更少。
- 核心函式庫: 用於解析的 、用於瀏覽器自動化的 、以及用於 HTTP 的 。
Java 範例程式:抓取頁面標題
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}優勢:
- 高效能且支援並行。
- 很適合大型、需要長期維護的程式碼庫。
- 對動態內容也有不錯的支援(透過 Selenium 或 HtmlUnit)。
限制:
- 語法較冗長;比起腳本語言,需要更多前置設定。
- 對小型、一次性腳本來說有點大材小用。
最適合:
企業級爬取,或你需要非常穩定、可擴展的系統時。
Go(Golang):快速且具並行能力的網頁爬取
Go 是後起之秀,但已經開始引起關注——尤其是在高速、並行爬取方面。
為什麼選 Go?
- 編譯型速度: 幾乎跟 C++ 一樣快。
- 內建並行: Goroutines 讓平行爬取變得很輕鬆。
- 核心函式庫: 用於爬取的 ,以及用於解析的 。
Go 範例程式:抓取頁面標題
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}優勢:
- 速度驚人,且適合大規模爬取。
- 部署容易(單一二進位檔)。
- 很適合並行爬取。
限制:
- 社群規模比 Python 或 Node.js 小。
- 高階爬取函式庫較少。
- 處理 JavaScript 密集型網站需要額外設定(Chromedp 或 Selenium)。
最適合:
當你需要大規模爬取,或 Python 的速度就是不夠時。 。
比較最佳網頁爬取程式語言
把前面的內容整合起來。以下是 2026 年選擇最佳網頁爬取語言時的並列比較:
| 語言/工具 | 易用性 | 效能 | 函式庫支援 | 動態內容處理 | 最佳使用情境 |
|---|---|---|---|---|---|
| Python | 非常高 | 中等 | 優秀 | 良好(Selenium/Playwright) | 通用、初學者、資料分析 |
| JavaScript/Node.js | 中等 | 高 | 強 | 優秀(原生) | 動態網站、非同步爬取、網頁開發者 |
| Ruby | 高 | 中等 | 尚可 | 有限(Watir) | 快速腳本、原型製作 |
| PHP | 中等 | 中等 | 普通 | 有限(Panther) | 伺服器端、網頁應用整合 |
| C++ | 低 | 非常高 | 有限 | 非常有限 | 效能關鍵、大規模 |
| Java | 中等 | 高 | 良好 | 良好(Selenium/HtmlUnit) | 企業級、長期運作服務 |
| Go (Golang) | 中等 | 非常高 | 持續成長 | 中等(Chromedp) | 高速、並行爬取 |
什麼時候該跳過寫程式:Thunderbit 作為無程式碼網頁爬取方案
老實說,有時候你只是想要資料——不想寫程式、不想除錯,也不想煩惱「為什麼這個 selector 一直不動」。這就是 登場的時候。
身為 Thunderbit 的共同創辦人,我想打造一個讓網頁爬取像叫外送一樣簡單的工具。Thunderbit 的特色如下:
- 2 步驟設定: 只要點一下「AI 建議欄位」再點「爬取」即可。不用折騰 HTTP 請求、代理或反機器人技巧。
- 智慧範本: 一個爬蟲範本可以適應多種頁面版型。網站改版時,不必每次重寫爬蟲。
- 瀏覽器與雲端爬取: 可選擇在瀏覽器內爬取(很適合需要登入的網站)或在雲端爬取(公開資料速度超快)。
- 處理動態內容: Thunderbit 的 AI 會操作真實瀏覽器,因此能處理無限捲動、彈出視窗、登入等情境。
- 匯出到任何地方: 可下載到 Excel、Google 試算表、Airtable、Notion,或直接複製到剪貼簿。
- 免維護: 如果網站改版,只要重新執行 AI 建議即可,不必再熬夜除錯。
- 排程與自動化: 可以設定爬蟲排程執行——不用 cron job,也不用伺服器設定。
- 專用提取器: 需要電子郵件、電話號碼或圖片?Thunderbit 也有一鍵提取器。
最棒的是,你完全不需要懂任何一行程式碼。Thunderbit 是為商務使用者、行銷人員、業務團隊、房地產專業人士——任何需要快速取得資料的人——所打造。
想看看 Thunderbit 的實際操作嗎? 或到我們的 看示範。
結論:2026 年如何選擇最佳網頁爬取語言
到了 2026 年,網頁爬取比以往更容易上手,也更強大。以下是我在多年自動化實戰中學到的事:
- Python 依然是最好的網頁爬取語言,如果你想快速開始,並且希望有大量現成資源可用。
- JavaScript/Node.js 對於爬取動態、JavaScript 密集型網站無可匹敵。
- Ruby 與 PHP 很適合快速腳本與網頁整合,尤其當你本來就在用它們時。
- C++ 與 Go 是你需要速度與規模時的好朋友。
- Java 則是企業級、長期專案的首選。
- 如果你想完全跳過寫程式? 就是你的秘密武器。
在動手之前,先問自己:
- 我的專案規模有多大?
- 我需要處理動態內容嗎?
- 我的技術熟悉度如何?
- 我是想自己開發,還是只想拿到資料?
不妨試試上面的程式碼範例,或在下一個專案中試用 Thunderbit。如果你想更深入了解,也可以看看我們的 ,裡面有更多指南、技巧,以及真實世界的爬取故事。
祝你爬取順利——也願你的資料永遠乾淨、結構化,而且只要一鍵就能拿到。
P.S. 如果你半夜 2 點還卡在網頁爬取的死胡同裡,請記得:永遠還有 Thunderbit。或者咖啡。或者兩者都來。
常見問題
1. 2026 年網頁爬取最好的程式語言是什麼?
Python 仍然是首選,因為它語法易讀、函式庫強大(像 BeautifulSoup、Scrapy、Selenium),而且社群龐大。對新手與專業人士都很適合,特別是需要把爬取與資料分析結合時。
2. 哪種語言最適合爬取 JavaScript 密集型網站?
JavaScript(Node.js)是動態網站的首選。Puppeteer 和 Playwright 這類工具可讓你完整控制瀏覽器,並與透過 React、Vue 或 Angular 載入的內容互動。
3. 有沒有免程式碼的網頁爬取選項?
有—— 是一款無程式碼的 AI 網頁爬蟲,可處理從動態內容到排程等所有事情。只要點一下「AI 建議欄位」就能開始爬取。非常適合需要快速取得結構化資料的業務、行銷或營運團隊。
4. 如果 AI 程式代理可以幫我寫爬蟲,我還需要選語言嗎?
這在 2026 年是個合理的問題。像 Claude Code、Cursor 和 OpenAI Codex 這類工具,確實可以從一段簡短提示詞產出 Scrapy spider、Playwright 腳本,或 Go + Colly crawler——所以「先學哪種語言」的門檻,真的比兩年前低很多。但代理還是會用某種語言產出程式碼,而你(或接手這個專案的人)最後仍然要讀它、除錯、部署它。所以語言選擇依然重要;只是現在更影響後續維護,而不是前 30 行程式碼。如果你完全不想碰程式碼,那就是 的用武之地——它直接跳過語言選擇這件事。
延伸閱讀: