

失效連結、孤兒頁面,還有一個 2019 年的「測試」頁面,居然還被 Google 收錄了。只要你有在管網站,這種痛你一定懂。
一款好的 爬蟲 可以把這些問題通通抓出來,還能幫你完整描繪整個網站架構,讓你真正知道該修哪裡。不過很多人常把「網站爬蟲」和「網頁擷取器」混為一談,但它們其實不是同一件事。
我實測了 10 款免費 爬蟲,跑過真實網站。有些很適合做 SEO 稽核,有些則更擅長資料擷取。以下就是我測完之後,真正有用的工具,以及不夠理想的地方。
什麼是網站爬蟲?先搞懂基本概念
先釐清一件事:網站爬蟲和網頁擷取器不是同一回事。這兩個名詞常被大家混著用,像在甩披薩麵團一樣隨口就講,但本質上完全不同。你可以把爬蟲想成網站的地圖測繪師——它會走訪每個角落、沿著每個連結前進,最後畫出整個網站頁面的地圖。它的任務是發現:找出網址、整理網站結構、建立內容索引。這也是 Google 這類搜尋引擎的機器人在做的事,也正是 SEO 工具用來檢查網站健康狀況的方式 (Thunderbit Blog: What Is a Web Crawler?)。
相對地,網頁擷取器更像資料挖掘員。它不在乎整張地圖,只想把值錢的資訊挖出來:產品價格、公司名稱、評論、電子郵件,凡是你想得到的都行。擷取器會從爬蟲找到的頁面中,提取特定欄位 (Thunderbit Blog: How to Web Crawl a Site?)。
來個比喻:
- 爬蟲: 走遍超市每一條走道,記錄所有商品的人。
- 擷取器: 直接走到咖啡區,把每一款有機咖啡的價格抄下來的人。
這有什麼差別?如果你只是想找出網站上有哪些頁面(例如做 SEO 稽核),你需要的是爬蟲。如果你想把競爭對手網站上的所有產品價格抓下來,你需要的是擷取器——或更理想地說,是一個兩者都能做的工具。
為什麼要用線上網站爬蟲?對企業有什麼好處
那麼,為什麼要用網站爬蟲?因為網路內容只會越來越多,不會變少。事實上,超過 54% 的企業品牌都使用專門的爬蟲平台 來優化網站,而有些 SEO 工具每天甚至會爬取 70 億 個頁面。
爬蟲可以幫你做到這些事:
- SEO 稽核: 找出失效連結、缺少標題、重複內容、孤兒頁面等問題 (SEO.ai)。
- 連結檢查與 QA: 在使用者遇到之前,先抓出 404 錯誤和重新導向迴圈 (Screaming Frog)。
- 網站地圖產生: 自動建立 XML 網站地圖,方便搜尋引擎和規劃使用 (PowerMapper)。
- 內容盤點: 建立你所有頁面的清單、階層關係和中繼資料。
- 合規與無障礙檢查: 檢查每個頁面是否符合 WCAG、SEO 與法律規範 (SiteOne Crawler)。
- 效能與安全性: 標記速度慢的頁面、過大的圖片或安全問題 (SiteOne Crawler)。
- AI 與分析資料來源: 將爬取到的資料輸入分析工具或 AI 工具 (Thunderbit Blog: Crawl4AI Review)。
以下是使用情境與企業角色的對照表:
| 使用情境 | 最適合對象 | 效益/結果 |
|---|---|---|
| SEO 與網站稽核 | 行銷、SEO、小型企業主 | 找出技術問題、優化架構、提升排名 |
| 內容盤點與 QA | 內容經理、網站管理員 | 稽核或搬遷內容,找出失效連結/圖片 |
| 開發名單(擷取) | 業務、商務開發 | 自動化名單開發,為 CRM 補充新潛客 |
| 競品情報 | 電商、產品經理 | 追蹤競品價格、新品與庫存變化 |
| 網站地圖與結構複製 | 開發者、DevOps、顧問 | 在改版或備份時複製網站結構 |
| 內容彙整 | 研究人員、媒體、分析師 | 從多個網站收集資料進行分析或趨勢監測 |
| 市場研究 | 分析師、AI 訓練團隊 | 蒐集大量資料供分析或 AI 模型訓練 |
(Thunderbit Blog: How to Web Crawl a Site?)
我們如何挑選最佳免費網站爬蟲工具
我花了不少深夜時間(還喝了多到不太想承認的咖啡),一邊研究 爬蟲 工具、一邊看文件、還實際跑測試。以下是我評估的重點:
- 技術能力: 能不能處理現代網站(JavaScript、登入、動態內容)?
- 使用難易度: 對非技術人員友不友善?還是一定得會命令列?
- 免費方案限制: 真的是免費,還是只是試用噱頭?
- 線上可用性: 它是雲端工具、桌面應用程式,還是程式庫?
- 特色功能: 有沒有什麼特別之處——像 AI 擷取、視覺化網站地圖、事件驅動爬取?
我逐一測試每個工具、查看使用者回饋,並把功能並排比較。如果某個工具讓我想把筆電直接丟出窗外,那它就不會出現在名單裡。
快速比較表:10 款最佳免費網站爬蟲一覽
| 工具與類型 | 核心功能 | 最佳使用情境 | 技術需求 | 免費方案細節 |
|---|---|---|---|---|
| BrightData(雲端/API) | 企業級爬取、代理伺服器、JS 渲染、CAPTCHA 解決 | 大規模資料蒐集 | 具備部分技術能力會更好 | 免費試用:3 個爬蟲,每個 100 筆紀錄(總計約 300 筆) |
| Crawlbase(雲端/API) | API 爬取、反機器人、代理伺服器、JS 渲染 | 需要後端爬取基礎設施的開發者 | 需整合 API | 免費:約 7 天 5,000 次 API 呼叫,之後每月 1,000 次 |
| ScraperAPI(雲端/API) | 代理輪換、JS 渲染、非同步爬取、預建端點 | 開發者、價格監控、SEO 資料 | 設定需求很低 | 免費:7 天 5,000 次 API 呼叫,之後每月 1,000 次 |
| Diffbot Crawlbot(雲端) | AI 爬取與擷取、知識圖譜、JS 渲染 | 大規模結構化資料、AI/ML | 需整合 API | 免費:每月 10,000 點數(約 1 萬頁) |
| Screaming Frog(桌面版) | SEO 稽核、連結/中繼資料分析、網站地圖、自訂擷取 | SEO 稽核、網站管理者 | 桌面程式、圖形介面 | 免費:每次爬取 500 個 URL,只提供核心功能 |
| SiteOne Crawler(桌面版) | SEO、效能、無障礙、安全性、離線匯出、Markdown | 開發者、QA、搬遷、文件化 | 桌面版/CLI、圖形介面 | 免費且開源,GUI 報表可顯示 1,000 個 URL(可設定) |
| Crawljax(Java,開源) | 針對 JavaScript 密集網站的事件驅動爬取、靜態匯出 | 開發者、動態 Web App 的 QA | Java、CLI/設定檔 | 免費且開源,無限制 |
| Apache Nutch(Java,開源) | 分散式、外掛式、Hadoop 整合、自訂搜尋 | 自建搜尋引擎、大規模爬取 | Java、命令列 | 免費且開源,僅需自行負擔基礎設施成本 |
| YaCy(Java,開源) | 點對點爬取與搜尋、隱私、網站/內網索引 | 私有搜尋、去中心化 | Java、瀏覽器介面 | 免費且開源,無限制 |
| PowerMapper(桌面版/SaaS) | 視覺化網站地圖、無障礙、QA、瀏覽器相容性 | 代理商、QA、視覺化整理 | 圖形介面、容易上手 | 免費試用:30 天,每次掃描 100 頁(桌面版)或 10 頁(線上版) |
BrightData:企業級雲端網站爬蟲

BrightData 可以說是 網站爬取 界的「重型機具」。它是雲端平台,具備大規模代理網路、JavaScript 渲染、CAPTCHA 解決,以及可自訂爬取的 IDE。如果你在做大規模資料蒐集——像是追蹤數百個電商網站的價格——BrightData 的基礎設施幾乎很難被超越 (aimultiple.com)。
優點:
- 能處理有強力反機器人機制的艱難網站
- 可擴充性高,適合企業需求
- 提供常見網站的預建範本
限制:
- 沒有永久免費方案,只有試用(3 個爬蟲,每個 100 筆)
- 對單純的網站稽核來說可能太重
- 對非技術使用者有一定學習門檻
如果你需要大規模爬網,BrightData 就像租一台 F1 賽車。只是別期待試駕完之後它還會繼續免費讓你開 (BrightData Pricing)。
Crawlbase:適合開發者的 API 驅動免費網站爬蟲

Crawlbase(前身為 ProxyCrawl)主打程式化爬取。你只要把網址丟給它的 API,它就會回傳 HTML,並在背後處理代理、地理定位和 CAPTCHA (Capterra)。
優點:
- 成功率高(99% 以上)
- 能處理大量 JavaScript 的網站
- 很適合整合進自己的應用程式或工作流程
限制:
- 需要一些 API 或 SDK 整合能力
- 免費方案:約 7 天 5,000 次 API 呼叫,之後每月 1,000 次
如果你是開發者,想在不自己管理代理的情況下大規模爬網,Crawlbase 是不錯的選擇 (Crawlbase Pricing)。
ScraperAPI:簡化動態網站爬取

ScraperAPI 就是那種「你幫我抓就好」的 API。你只要提供網址,它會處理代理、無頭瀏覽器和反機器人機制,然後回傳 HTML(某些網站還能直接回傳結構化資料)。它特別適合動態頁面,而且免費方案相當大方 (ScraperAPI Pricing)。
優點:
- 對開發者來說超簡單,只要一個 API 呼叫
- 可處理 CAPTCHA、IP 封鎖、JavaScript
- 免費:7 天 5,000 次 API 呼叫,之後每月 1,000 次
限制:
- 沒有視覺化爬取報告
- 如果你想沿著連結繼續爬,還是得自己寫爬取邏輯
如果你想在幾分鐘內把網站爬取功能接進程式,ScraperAPI 幾乎可以直接下手。
Diffbot Crawlbot:自動化網站結構探索

Diffbot Crawlbot 的重點在於「智慧」。它不只是爬網,而是用 AI 分類頁面,並將文章、產品、活動等內容擷取成結構化 JSON。就像有個真的懂內容的機器實習生在幫你做事 (Diffbot Free Plan)。
優點:
- AI 驅動的擷取,不只是單純爬取
- 能處理 JavaScript 和動態內容
- 免費:每月 10,000 點數(約 1 萬頁)
限制:
- 偏向開發者使用(需整合 API)
- 不是視覺化 SEO 工具,比較適合資料專案
如果你需要大規模結構化資料,尤其是做 AI 或分析用途,Diffbot 真的很強。
Screaming Frog:免費桌面版 SEO 爬蟲

Screaming Frog 是 SEO 稽核領域的經典桌面爬蟲。免費版每次可爬 500 個 URL,功能相當完整:失效連結、中繼資料、重複內容、網站地圖等等都有 (Screaming Frog User Guide)。
優點:
- 速度快、檢查細、在 SEO 圈信任度高
- 不需要寫程式,輸入網址就能開始
- 每次最多 500 個 URL,免費可用
限制:
- 只有桌面版,沒有雲端版本
- 進階功能(例如 JS 渲染、排程)需要付費授權
如果你認真做 SEO,Screaming Frog 幾乎是必備工具——只是別期待它免費幫你爬 10,000 頁網站。
SiteOne Crawler:靜態網站匯出與文件化工具

SiteOne Crawler 是技術稽核的瑞士刀。它是開源、跨平台工具,不只能爬網、做稽核,還能把網站匯出成 Markdown,方便文件整理或離線使用 (SiteOne Crawler)。
優點:
- 涵蓋 SEO、效能、無障礙、安全性
- 可將網站匯出,用於備份或搬遷
- 免費且開源,沒有使用限制
限制:
- 比部分圖形介面工具更偏技術向
- GUI 報表預設最多 1,000 個 URL(可設定)
如果你是開發者、QA 或顧問,想要更深入的洞察,而且又喜歡開源,那 SiteOne 絕對值得一試。
Crawljax:適合動態頁面的開源 Java 網頁爬蟲
Crawljax 是專門型工具:它透過模擬使用者互動(點擊、填表等),來爬取現代、JavaScript 很重的網站應用程式。它採用事件驅動設計,甚至能輸出動態網站的靜態版本 (Wikipedia: Crawljax)。
優點:
- 非常適合爬取 SPA 和 AJAX 密集型網站
- 開源且可擴充
- 沒有使用限制
限制:
- 需要 Java,且要具備一些程式或設定能力
- 不適合非技術使用者
如果你想像真實使用者一樣去爬 React 或 Angular 應用,Crawljax 就是你的好夥伴。
Apache Nutch:可擴充的分散式網站爬蟲

Apache Nutch 是開源爬蟲界的老大哥。它是為大規模、分散式爬取而設計的——例如自己打造搜尋引擎,或索引數百萬個頁面 (Martechvibe)。
優點:
- 搭配 Hadoop 可擴充到數十億頁面
- 可高度自訂、可擴充
- 免費且開源
限制:
- 學習曲線陡峭(Java、命令列、設定)
- 不適合小型網站或一般使用者
如果你想大規模爬網,而且不怕命令列操作,Nutch 就是你的工具。
YaCy:點對點網站爬蟲與搜尋引擎
YaCy 是一款獨特的去中心化爬蟲與搜尋引擎。每個實例都能自行爬取與建立索引,還可以加入點對點網路,與其他人共享索引 (TechRadar: YaCy)。
優點:
- 重視隱私,沒有中央伺服器
- 很適合建立私有搜尋或內網搜尋
- 免費且開源
限制:
- 結果品質取決於網路覆蓋範圍
- 需要一些安裝設定(Java、瀏覽器介面)
如果你對去中心化有興趣,或想打造自己的搜尋引擎,YaCy 是一個很有意思的選項。
PowerMapper:適合 UX 與 QA 的視覺化網站地圖工具

PowerMapper 的核心就是把網站結構視覺化。它會爬取你的網站並產生互動式網站地圖,同時也會檢查無障礙、瀏覽器相容性和 SEO 基礎項目 (Slickplan Review)。
優點:
- 視覺化網站地圖很適合代理商和設計師
- 可檢查無障礙與合規性
- 圖形介面簡單直覺,不需要技術背景
限制:
- 只有試用版(30 天,每次掃描桌面版 100 頁/線上版 10 頁)
- 完整版需付費
如果你需要向客戶展示網站架構,或檢查合規狀況,PowerMapper 是一個很實用的工具。
如何根據需求選擇合適的免費網站爬蟲
工具這麼多,到底該怎麼選?我的快速建議如下:
- SEO 稽核: Screaming Frog(小型網站)、PowerMapper(視覺化)、SiteOne(深度稽核)
- 動態 Web App: Crawljax
- 大規模或自訂搜尋: Apache Nutch、YaCy
- 需要 API 的開發者: Crawlbase、ScraperAPI、Diffbot
- 文件整理或封存: SiteOne Crawler
- 企業級試用: BrightData、Diffbot
選擇時要考慮的重點:
- 擴充性: 你的網站或爬取任務有多大?
- 使用便利性: 你習慣寫程式,還是希望點幾下就能用?
- 資料匯出: 你需要 CSV、JSON,還是要跟其他工具整合?
- 支援資源: 卡住時,有沒有社群或說明文件可參考?
當網站爬取遇上網頁擷取:為什麼 Thunderbit 是更聰明的選擇
使用 AI 從任何網站抓取資料 Get Started Free
現實是,大多數人爬網站不只是為了做漂亮的地圖。真正的目的通常是拿到結構化資料——不管是商品清單、聯絡資訊,還是內容盤點。這正是 Thunderbit 的用武之地。
Thunderbit 不只是爬蟲或擷取器,而是一個結合兩者的 AI Chrome 擴充功能。它的運作方式如下:
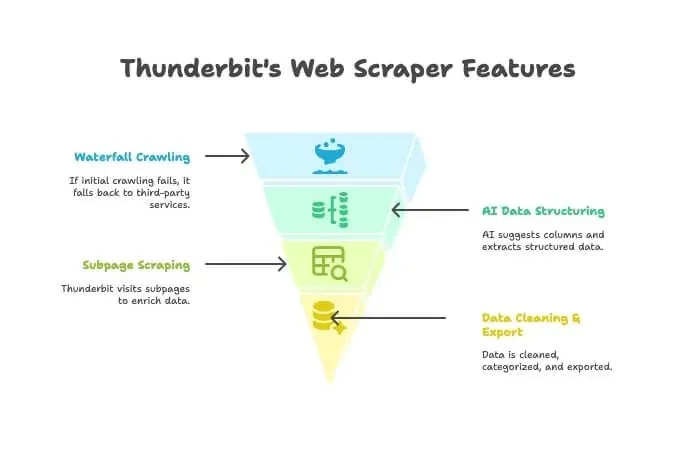
- AI 爬蟲: Thunderbit 會像爬蟲一樣探索網站。
- 瀑布式爬取: 如果 Thunderbit 自己的引擎無法抓到頁面(例如遇到很強的反機器人防線),它會自動切換到第三方爬取服務,不需要手動設定。
- AI 資料結構化: 一旦拿到 HTML,Thunderbit 的 AI 就會自動建議合適的欄位,並擷取結構化資料(名稱、價格、電子郵件等),你完全不需要寫任何 selector。
- 子頁面擷取: 如果你想抓每個產品頁的詳細資訊,Thunderbit 可以自動造訪各個子頁,豐富你的表格內容。
- 資料清理與匯出: 它還能一鍵摘要、分類、翻譯,並將資料匯出到 Excel、Google Sheets、Airtable 或 Notion。
- 無程式碼操作: 只要會用瀏覽器就會用 Thunderbit。不用寫程式、不用代理、不用頭痛。
什麼情況下該用 Thunderbit,而不是傳統爬蟲?
- 當你的最終目標是乾淨、可直接使用的試算表,而不只是網址清單。
- 當你想在同一個地方完成整套流程(爬取、擷取、清理、匯出)。
- 當你重視自己的時間和精神狀態。
你可以在這裡下載 Thunderbit 的 Chrome 擴充功能,親自看看為什麼這麼多商務使用者都在轉換工具。
結論:如何從免費網站爬蟲中獲得最大效益
什麼是資料擷取?以及如何執行 Get Started Free
網站爬蟲這些年已經進化很多。無論你是行銷人員、開發者,還是單純想維持網站健康的人,都能找到適合你的免費工具(或至少可免費試用的工具)。從 BrightData、Diffbot 這類企業級平台,到 SiteOne、Crawljax 這類開源寶藏,再到 PowerMapper 這種視覺化工具,選擇比以往更豐富。
但如果你想要一種更聰明、更整合的方式,把「我需要這些資料」快速變成「這是我的試算表」,那麼很值得試試 Thunderbit。它是為了想要成果、而不是只想看報告的商務使用者而打造的。
準備好開始爬了嗎?下載一款工具、跑一次掃描,看看你之前錯過了什麼。如果你想只用兩下點擊,就把爬取變成可直接行動的資料,歡迎看看 Thunderbit。
想看更多深入解析與實用指南,請造訪 Thunderbit Blog。
試用 AI 網頁爬蟲 Get Started Free
常見問題
網站爬蟲和網頁擷取器有什麼差別?
爬蟲負責找出並整理網站上所有頁面(可以想成建立目錄)。擷取器則是從這些頁面中提取特定資料欄位(例如價格、電子郵件或評論)。爬蟲負責找,擷取器負責挖 (Thunderbit Blog: What Is a Web Crawler?)。
哪一款免費網站爬蟲最適合非技術使用者?
如果是小型網站和 SEO 稽核,Screaming Frog 很容易上手。若是想看視覺化網站地圖,PowerMapper 在試用期間表現很不錯。如果你的重點是結構化資料,而且希望完全無程式碼、直接在瀏覽器操作,Thunderbit 是最簡單的選擇。
有些網站會封鎖網站爬蟲嗎?
有,某些網站會透過 robots.txt 或反機器人機制(例如 CAPTCHA、IP 封鎖)來阻擋爬蟲。像 ScraperAPI、Crawlbase 和 Thunderbit(搭配瀑布式爬取)通常可以繞過這些限制,但務必負責任地爬取,並尊重網站規則 (BrightData Pricing)。
免費網站爬蟲有頁數或功能限制嗎?
大多數都有。例如 Screaming Frog 免費版每次爬取限制 500 個 URL;PowerMapper 試用版每次限 100 頁。API 型工具通常有每月點數或呼叫次數限制。像 SiteOne 或 Crawljax 這類開源工具通常沒有硬性限制,但仍會受限於你的硬體資源。
使用網站爬蟲是否合法、是否符合隱私規範?
一般來說,爬取公開網頁是合法的,但一定要查看網站的服務條款與 robots.txt。未經許可,不要爬取私密或受密碼保護的資料;如果你擷取的是個人資料,也要留意隱私法規 (Crawlbase Guide)。




