老實說,Amazon 幾乎就是整個網路世界的百貨公司、超市和電子產品店。若你在做業務、電商或營運,你一定知道 Amazon 上發生的事不會只停留在 Amazon——它會影響你的定價、庫存,甚至下一次重大產品發布。問題是:那些誘人的產品資訊、價格、評分和評論,全都被鎖在一個為購物者設計、不是為數據型團隊設計的網頁介面裡。那麼,要怎麼在不把週末都拿來複製貼上、活得像 1999 年那樣的情況下,拿到這些資料呢?
這就是網頁爬蟲派上用場的地方。在這份指南裡,我會示範兩種擷取 Amazon 產品資料的方法:傳統的「捲起袖子,用 Python 自己寫」做法,以及現代的「讓 AI 幫你扛重活」路線,使用像 這樣的免程式碼網頁爬蟲。我會帶你看實際的 Python 程式碼(包含各種坑與補救方式),再示範 Thunderbit 如何只用幾個點擊就拿到同樣的資料——完全不需要寫程式。不論你是開發者、商業分析師,還是只是厭倦手動輸入資料的人,這篇都能幫到你。
為什麼要擷取 Amazon 產品資料?(amazon scraper python,python 網頁爬蟲)
Amazon 不只是全球最大的線上零售商,也是全球最大的競爭情報露天市場。Amazon 上有 和 ,所以對任何想要以下資訊的人來說,Amazon 都是一座金礦:

- 監控價格(並即時調整你的售價)
- 分析競爭對手(追蹤他們的新產品、評分與評論)
- 開發潛在客戶(找出賣家、供應商,甚至潛在合作夥伴)
- 預測需求(觀察庫存水位與銷售排名)
- 掌握市場趨勢(挖掘評論與搜尋結果)
而且這不只是理論——真實企業已經看到真實 ROI。例如,有一家電子產品零售商利用擷取來的 Amazon 定價資料,將 ;另有品牌在自動化競品價格追蹤後,看到 。
以下快速整理一些常見用途,以及你可以期待的 ROI:
| 用途 | 使用者 | 典型 ROI / 效益 |
|---|---|---|
| 價格監控 | 電商、營運 | 利潤率提升 15%+、銷售提升 4%、分析師時間減少 30% |
| 競爭對手分析 | 業務、產品、營運 | 更快調整價格、提升競爭力 |
| 市場研究(評論) | 產品、行銷 | 更快迭代產品、更好的廣告文案、SEO 洞察 |
| 潛在客戶開發 | 業務 | 每月 3,000+ 筆名單、每位業務每週省下 8+ 小時 |
| 庫存與需求預測 | 營運、供應鏈 | 降低 20% 庫存過剩、減少缺貨 |
| 趨勢發掘 | 行銷、高階主管 | 提早發現熱門商品與類別 |
更驚人的是: 現在都表示資料分析帶來了可衡量的價值。若你沒有擷取 Amazon,就等於把洞察(以及金錢)留在桌上。
概覽:Amazon Scraper Python vs. 免程式碼網頁爬蟲工具
要把 Amazon 資料從瀏覽器拿到試算表或儀表板,主要有兩種方法:
-
Amazon Scraper Python(python 網頁爬蟲):
使用 Python 函式庫如 Requests 和 BeautifulSoup 自己寫腳本。這種方式給你完整控制權,但你需要會寫程式、處理反機器人機制,還得在 Amazon 改版時維護腳本。
-
免程式碼網頁爬蟲工具(像 Thunderbit):
使用一個讓你點選、抓取資料的工具——不需要寫程式。像 這類現代工具甚至會用 AI 判斷要抓哪些資料、處理子頁面與分頁,還能直接匯出到 Excel 或 Google Sheets。
兩者比較如下:
| 比較項目 | Python 爬蟲 | 免程式碼(Thunderbit) |
|---|---|---|
| 設定時間 | 高(安裝、撰寫、除錯) | 低(安裝擴充功能) |
| 所需技能 | 需要寫程式 | 不需要(點選即可) |
| 彈性 | 無上限 | 常見用途下彈性高 |
| 維護 | 你自己修程式碼 | 工具自動更新 |
| 反機器人處理 | 自己處理代理、標頭 | 內建,由工具代勞 |
| 擴充性 | 手動(執行緒、代理) | 雲端爬取、平行處理 |
| 資料匯出 | 自訂(CSV、Excel、資料庫) | 一鍵匯出到 Excel、Sheets |
| 成本 | 免費(但要算上你的時間和代理) | Freemium,規模化時付費 |
接下來幾節,我會帶你走過這兩種方法——先看如何用 Python 建立 Amazon 爬蟲(含實際程式碼),再看如何用 Thunderbit 的 AI 網頁爬蟲做同樣的事。
Amazon Scraper Python 入門:先備條件與設定
在我們開始寫程式前,先把環境準備好。
你需要:
- Python 3.x(可從 下載)
- 程式碼編輯器(我喜歡 VS Code,但任何都可以)
- 以下函式庫:
requests(處理 HTTP 請求)beautifulsoup4(HTML 解析)lxml(快速 HTML 解析器)pandas(資料表與匯出)re(正規表示式,內建)
安裝函式庫:
1pip install requests beautifulsoup4 lxml pandas專案設定:
- 為你的專案建立一個新資料夾。
- 打開編輯器,建立一個新的 Python 檔案(例如
amazon_scraper.py)。 - 可以開始了!
逐步教學:用 Python 擷取 Amazon 產品資料
我們先從抓取單一 Amazon 產品頁面開始。(別擔心,稍後我也會講如何抓多個產品與多頁資料。)
1. 發送請求並擷取 HTML
先抓取產品頁面的 HTML。(把 URL 換成任何 Amazon 產品頁都可以。)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)提醒: 這種基本請求很可能會被 Amazon 擋下。你可能會看到 503 錯誤,或是 CAPTCHA,而不是產品頁面。為什麼?因為 Amazon 知道你不是一個真正的瀏覽器。
處理 Amazon 的反機器人機制
Amazon 不太喜歡機器人。若想避免被擋,你需要:
- 設定 User-Agent 標頭(假裝自己是 Chrome 或 Firefox)
- 輪換 User-Agent(不要每次都用同一個)
- 節流請求(加入隨機延遲)
- 使用代理(適用於大規模爬取)
以下是設定標頭的方法:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)想再進階一點?可以準備一組 User-Agent 清單,每次請求都輪換。若是大量任務,最好使用代理服務(市面上很多),但小規模爬取時,標頭加延遲通常就夠了。
擷取關鍵產品欄位
拿到 HTML 後,就可以用 BeautifulSoup 解析。
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")接著,來抓重點資料:
商品標題
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else None價格
Amazon 的價格可能出現在幾個不同位置,試試這些:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.text評分與評論數
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # 例如 "1,554 ratings"主圖片網址
Amazon 有時會把高解析度圖片藏在 HTML 內的 JSON 裡。可以用這個快速正規表示式方法:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else None或者直接抓主圖片標籤:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else None產品詳細資訊
品牌、重量和尺寸等規格通常會在表格裡:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = value或者,如果 Amazon 使用的是「detailBullets」格式:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()列印結果:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)擷取多個產品並處理分頁
單一產品很好,但你大概會想抓整個清單。以下是如何抓搜尋結果和多頁資料。
從搜尋頁取得產品連結
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)處理分頁
Amazon 的搜尋網址會使用 &page=2、&page=3 等參數。
1for page in range(1, 6): # 抓前 5 頁
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page=\{page\}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... 如上擷取產品連結 ...逐頁抓取產品並匯出 CSV
把產品資料收集到一個字典清單中,然後用 pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # 字典清單
3df.to_csv("amazon_products.csv", index=False)或匯出成 Excel:
1df.to_excel("amazon_products.xlsx", index=False)Amazon Scraper Python 專案最佳實務
老實說,Amazon 一直都在改網站,也一直都在對抗爬蟲。以下是讓專案持續運作的方法:
- 輪換標頭與 User-Agent(可使用
fake-useragent之類的函式庫) - 大量爬取時使用代理
- 節流請求(每次請求之間隨機
time.sleep()) - 優雅處理錯誤(遇到 503 重試,被擋時退讓)
- 撰寫彈性的解析邏輯(每個欄位準備多個選擇器)
- 監控 HTML 變化(如果腳本突然全部回傳
None,先檢查頁面) - 遵守 robots.txt(Amazon 禁止抓取許多區塊——請負責任地爬取)
- 邊抓邊清理資料(去掉貨幣符號、逗號與多餘空白)
- 保持與社群連結(論壇、Stack Overflow、Reddit 的 r/webscraping)
維護你的爬蟲檢查清單:
- [ ] 輪換 User-Agent 與標頭
- [ ] 大規模爬取時使用代理
- [ ] 加入隨機延遲
- [ ] 將程式模組化,方便更新
- [ ] 監控封鎖或 CAPTCHA
- [ ] 定期匯出資料
- [ ] 記錄你的選擇器與邏輯
若想更深入了解,可以看看我的 。
免程式碼替代方案:用 Thunderbit AI 網頁爬蟲抓 Amazon
好,你已經看過 Python 的做法了。但如果你不想寫程式——或者你只想兩個點擊就把資料拿到手,然後繼續過日子呢?這就是 登場的時候。
Thunderbit 是一個 AI 網頁爬蟲 Chrome 擴充功能,讓你完全不寫程式就能擷取 Amazon 產品資料(以及幾乎任何網站的資料)。以下是我喜歡它的原因:
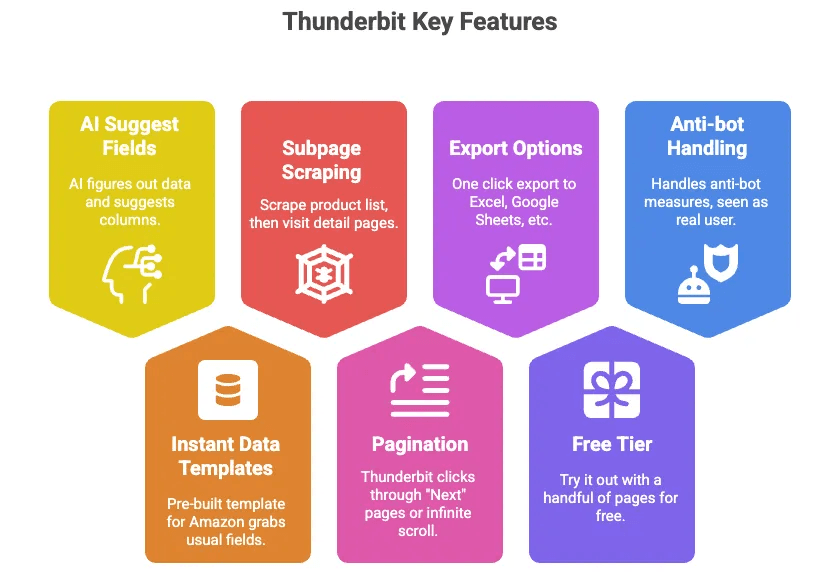
- AI 建議欄位: 只要點一下按鈕,Thunderbit 的 AI 就會判斷頁面上有哪些資料,並建議欄位(例如標題、價格、評分等)。
- 即時資料範本: 對 Amazon 來說,已經有預先建立好的範本,可以直接抓取所有常見欄位——完全不需要設定。
- 子頁面爬取: 先抓商品清單,再讓 Thunderbit 自動拜訪每個商品詳情頁,擷取更多資訊。
- 分頁: Thunderbit 可以幫你點「下一頁」或處理無限捲動。
- 匯出到 Excel、Google Sheets、Airtable、Notion: 一鍵完成,資料立刻可用。
- 免費方案: 可以先用少量頁面免費試用。
- 自動處理反機器人機制: 因為它在你的瀏覽器中執行(或在雲端執行),Amazon 會把它視為真實使用者。
逐步教學:用 Thunderbit 擷取 Amazon 產品資料
其實非常簡單:
-
安裝 Thunderbit:
下載 並登入。
-
打開 Amazon:
前往你想擷取的 Amazon 頁面(搜尋結果、產品詳情頁,任何頁面都可以)。
-
點選「AI 建議欄位」或使用範本:
Thunderbit 會建議要擷取的欄位(或你可以直接選擇 Amazon Product 範本)。
-
檢視欄位:
如果需要,可以自行調整欄位(新增、刪除、重新命名等)。
-
點選「擷取」:
Thunderbit 會從頁面抓取資料,並以表格顯示。
-
處理子頁面與分頁:
如果你抓的是清單,點「擷取子頁面」即可拜訪每個商品詳情頁並拉取更多資訊。Thunderbit 也可以自動幫你點選「下一頁」。
-
匯出你的資料:
點選「匯出到 Excel」或「匯出到 Google Sheets」。完成。
-
(可選)排程擷取:
需要每天更新這些資料?使用 Thunderbit 的排程器即可自動化。
就這麼簡單。沒有程式碼、沒有除錯、沒有代理、也沒有頭痛問題。如果你想看視覺化操作流程,可以查看 或 。
Amazon Scraper Python vs. 免程式碼網頁爬蟲:並排比較
把前面內容整合一下:
| 比較項目 | Python 爬蟲 | Thunderbit(免程式碼) |
|---|---|---|
| 設定時間 | 高(安裝、撰寫、除錯) | 低(安裝擴充功能) |
| 所需技能 | 需要寫程式 | 不需要(點選即可) |
| 彈性 | 無上限 | 常見用途下彈性高 |
| 維護 | 你自己修程式碼 | 工具自動更新 |
| 反機器人處理 | 自己處理代理、標頭 | 內建,由工具代勞 |
| 擴充性 | 手動(執行緒、代理) | 雲端爬取、平行處理 |
| 資料匯出 | 自訂(CSV、Excel、資料庫) | 一鍵匯出到 Excel、Sheets |
| 成本 | 免費(但要算上你的時間和代理) | Freemium,規模化時付費 |
| 最適合 | 開發者、客製化需求 | 商業使用者、快速成果 |
如果你是喜歡折騰細節、又需要高度客製化的開發者,Python 會很適合你。如果你想要速度、簡單,且完全不寫程式,Thunderbit 就是最佳選擇。
何時為 Amazon 資料選擇 Python、免程式碼,或 AI 網頁爬蟲
選擇 Python,如果:
- 你需要客製邏輯,或想把爬取整合進後端系統
- 你要做超大規模爬取(數萬筆商品)
- 你想理解爬蟲背後的運作原理
選擇 Thunderbit(免程式碼、AI 網頁爬蟲),如果:
- 你想快速拿到資料,不想寫程式
- 你是商業使用者、分析師或行銷人員
- 你希望讓團隊自己就能取得資料
- 你想避開代理、反機器人機制和維護的麻煩
兩者一起用,如果:
- 你想先用 Thunderbit 快速做原型,再為正式環境建立客製 Python 解法
- 你想用 Thunderbit 做資料收集,再用 Python 做資料清理/分析
對大多數商業使用者來說,Thunderbit 能在極短時間內滿足 90% 的 Amazon 爬取需求。至於另外 10%——高度客製、大規模或深度整合的需求——Python 仍然是王者。
結論與重點整理
擷取 Amazon 產品資料,對任何業務、電商或營運團隊來說,都是一種超能力。不論你是在追蹤價格、分析競爭對手,還是只是想把團隊從無止盡的複製貼上中解救出來,都有適合你的解法。
- Python 爬取 給你完整控制權,但也伴隨學習曲線與持續維護成本。
- 像 Thunderbit 這樣的免程式碼網頁爬蟲 讓每個人都能取得 Amazon 資料——不用寫程式、沒有壓力,只有成果。
- 最佳做法?選擇最符合你的技能、時程與商業目標的工具。
如果你有興趣,不妨試試 Thunderbit——免費就能開始,而且你會驚訝於自己多快就能拿到需要的資料。如果你是開發者,也別怕混搭:有時候最快的做法,就是讓 AI 幫你完成那些無聊的部分。
常見問題
1. 為什麼企業會想擷取 Amazon 產品資料?
擷取 Amazon 可以讓企業監控價格、分析競爭對手、蒐集評論做產品研究、預測需求,並開發銷售名單。Amazon 擁有超過 6 億項商品和近 200 萬名賣家,是很豐富的競爭情報來源。
2. 用 Python 和像 Thunderbit 這類免程式碼工具來擷取 Amazon,主要差異是什麼?
Python 爬蟲提供最高彈性,但需要寫程式、設定時間,以及持續維護。Thunderbit 是免程式碼的 AI 網頁爬蟲,讓使用者透過 Chrome 擴充功能就能即時擷取 Amazon 資料——不需要寫程式,還內建反機器人處理與匯出到 Excel 或 Sheets 的功能。
3. 擷取 Amazon 資料合法嗎?
Amazon 的服務條款通常禁止爬取,而且他們也積極實施反機器人機制。不過,許多企業仍會在負責任的前提下,擷取公開可見資料,例如遵守請求速率限制並避免過量請求。
4. 使用網頁爬蟲工具可以從 Amazon 擷取哪些資料?
常見資料欄位包括商品標題、價格、評分、評論數、圖片、產品規格、庫存狀態,甚至賣家資訊。Thunderbit 也支援子頁面爬取與分頁,能擷取多個商品與多頁資料。
5. 什麼時候該選擇 Python 爬取,而不是像 Thunderbit 這類工具?反之亦然?
如果你需要完整控制、客製邏輯,或計畫把爬取整合到後端系統,就用 Python。如果你想快速拿到結果、不想寫程式、需要容易擴充,或你是正在尋找低維護解法的商業使用者,就用 Thunderbit。
想更深入了解嗎?看看這些資源:
祝你擷取順利——也祝你的試算表永遠保持最新。