執行摘要
我們抓取了全球流量最高網站之 Tranco 前 10,000 名榜單中每個網域的 robots.txt 檔案。接著,我們以符合 RFC 9309 的解析器逐一解析,依網站採用的 AI 機器人政策(若有)進行分類,並統計全球最常造訪的網站中,有多少真的試圖封鎖 ChatGPT、Claude、Perplexity、Gemini、Common Crawl、Bytespider、Apple Intelligence,以及其他在 2026 年用來訓練與提供大型語言模型服務的爬蟲。
在 7,248 個 robots.txt 能順利讀取的網站樣本中,重點數字如下:
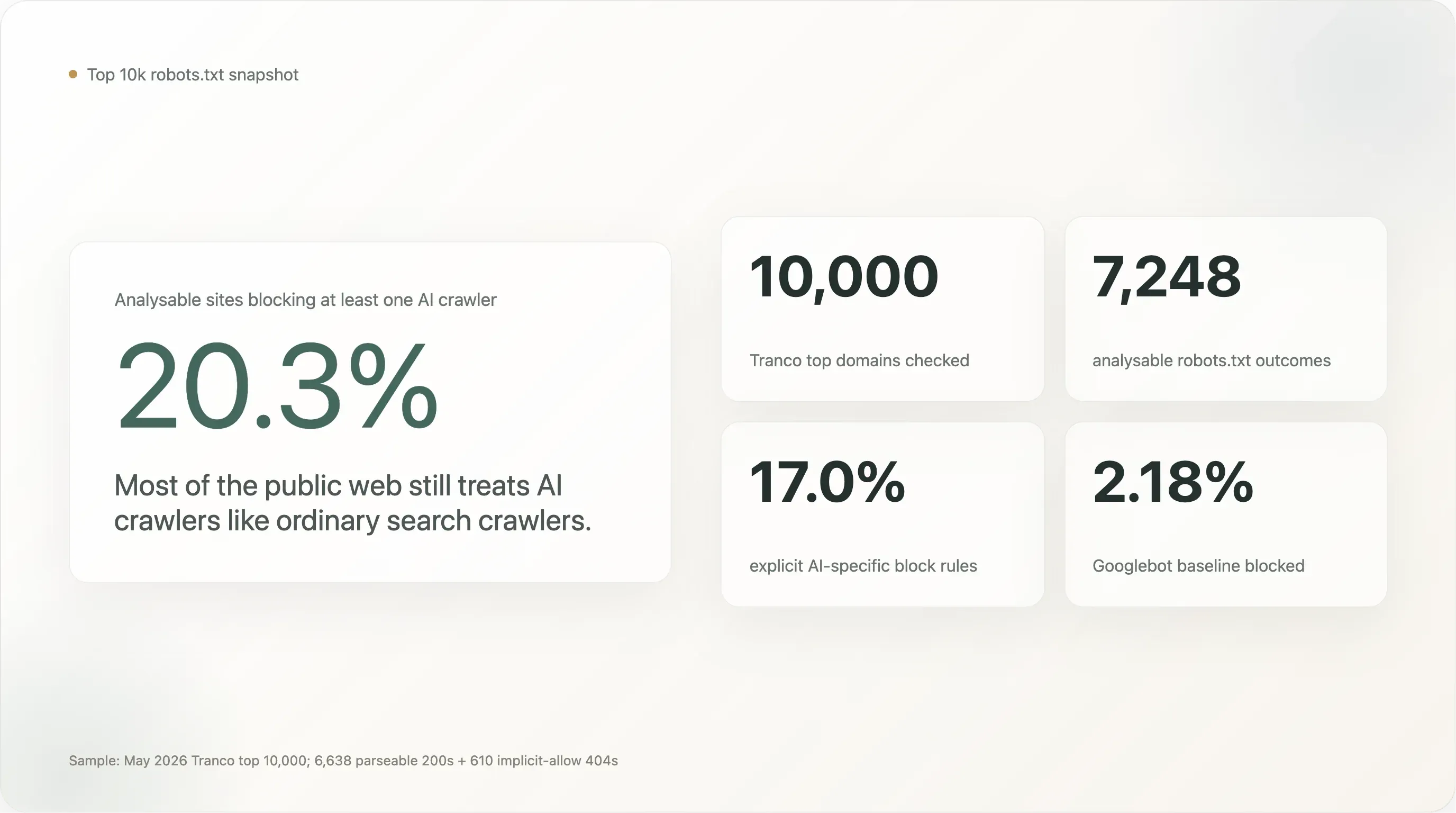
全球前 10,000 名網站中,有 20.3% 封鎖至少一個 AI 爬蟲。17.0% 有明確、針對 AI 的刻意規則。其餘 80% 對 AI 爬蟲的態度,和對 Googlebot 一樣開放。
改變這個故事樣貌的六個發現:
- 新聞機構的封鎖率達 47% —— 這是所有產業中最高的。德國新聞業達 88%,法國 80%,俄羅斯 0%。主導因素是法規,不是技術,也不是產業經濟。
CCBot(Common Crawl)是最常被封鎖的機器人,達 16.3% —— 高於GPTBot(15.8%)和Bytespider(14.9%)。出版商瞄準的是訓練資料來源,不是模型品牌。最常見的選擇性規則是「封鎖CCBot、允許Googlebot」(14.1% 的網站)。- 法國以
.fr網站 50.6% 的 AI 封鎖率領先全球;EU 群組比全球基準高出 16 個百分點。 有 275 份robots.txt明確引用 EU 指令 2019/790。第 4 條是唯一明顯推動數字變化的法律制度。 - 17.8% 是自行撰寫的 AI 規則;4.5% 使用 Cloudflare 的供應商範本;75.7% 什麼都沒說。 大型網站多半自行撰寫;長尾網站則直接打開開關。The Atlantic 和
cloudflare.com本身都在 Cloudflare Managed 名單上。 - 有 108 個網站明確 允許
GPTBot—— WordPress.org、Kaspersky、Norton、Avast、Sophos、The Verge、The Atlantic、NBA.com、The Sun、Branch.io。資安與開發工具類網站明顯偏多。 - AI 政策並沒有在排名前段變得更強硬。 前 100 名、101–1000 名、1001–5000 名、5001–10000 名都落在 19% 到 23% 之間。這個頭條比例反映的是 2026 年公開網路的整體樣貌,而不是某個單一大型網站有多大。
現在的問題,已經不再是「網路是不是在反擊」。而是哪些產業、哪些國家、哪些法規制度,以及哪些 AI 供應商,成了積極政策的目標——哪些沒有。
I. 背景:robots.txt 如何成為 AI 政策載體
自從 OpenAI 於 2023 年 8 月推出 GPTBot 以來,有三股力量重新塑造了 robots.txt 的意義。
AI 供應商迅速增加。 Google 的 Google-Extended、Anthropic 的 ClaudeBot、ByteDance 的 Bytespider、Apple 的 Applebot-Extended、Amazon 的 Amazonbot、Meta 的 Meta-ExternalAgent 先後出現。Common Crawl 原本就存在的 CCBot,因為其封存資料餵給了大多數開源權重模型,反而成了最具影響力的封鎖目標。也出現了非供應商自有的機器人:AI2Bot、cohere-ai、PerplexityBot、YouBot、DuckAssistBot、Diffbot、Omgili。到了 2026 年,一份完整的封鎖清單大約會列出 25 個名稱。
EU 著作權指令 2019/790 第 4 條建立了文本與資料探勘的法定例外,但前提是權利人必須以「機器可讀」方式「明確保留」其權利。2024–2025 年間,EU 出版商與律師界逐漸把 robots.txt 視為表達這種保留的標準方式。我們的資料顯示,有 275 個網站明確引用 2019/790 指令,另有 87 個提到「TDM」;這些內容主要集中在歐洲新聞網站,通常作為 4 到 8 行的法律前言。
Cloudflare 把這個開關產品化了。 在 2024–2025 年間,Cloudflare 推出了「AI Audit」儀表板、「Block AI Bots」切換開關,以及一個帶有 Content-Signal: search=yes,ai-train=no 語法與 EU 2019/790 範本文字的 Managed robots.txt 範本。到了 2026 年 5 月,這個範本已運行在可解析前 10k 網站的 4.5%。Cloudflare 的產品路線圖公開討論要把新帳號預設開啟該開關——這將在沒有任何單一出版商做決定的情況下,把全球封鎖率拉高 5 到 8 個百分點。
到了 2026 年,robots.txt 已不再是 2022 年那種不起眼的設定檔。它在 EU 是一種有條約背書的著作權保留機制,在長尾網站裡則是供應商塑形的政策載體,也是網站經營者與模型訓練者之間一場緩慢協商的前線。
II. 方法論
我們盡量讓這件事看起來無聊、可重現。完整流程(Python 腳本、解析後 CSV、原始 robots.txt 檔案庫、圖表)都隨本報告一併公開。
樣本
我們從 2026 年 5 月的 Tranco 清單開始,下載為 top-1m.csv.zip,再取前 10,000 筆。Tranco 綜合四個上游排名來源(Cisco Umbrella、Majestic、Farsight 與 Cloudflare Radar),以 30 天視窗篩掉不穩定項目,並移除明顯的爬蟲/CDN 雜訊。它產生的清單,是公開資料中最接近「全球網路流量前 10,000」的標準樣貌,也是學術網路研究的常用樣本(自 KU Leuven 於 2018 年推出以來,已被 600 多篇同儕審查論文使用)。
這份清單包含三種網域混合:(a) 人們實際造訪的主網站、(b) 不會提供 / 的基礎設施/API/DNS/CDN 根網域、以及 (c) 大型平台內部使用的網域(例如 gvt1.com、apple-dns.net、googleusercontent.com)。我們沒有先行篩掉這些,而是全部保留,並在分析層標記為 infrastructure 類別。當我們限制為「有可解析 robots.txt 的網站」時,它們自然就會退出結果。
抓取
對 10,000 個網域,我們以 HTTPS 非同步發送 GET /robots.txt,若失敗則回退到 HTTP,最多跟隨 4 次重新導向,總逾時 12 秒,主體上限 500 KB,並使用真正瀏覽器風格的 User-Agent 與 Accept-Language: en-US。並行數維持在 80 個請求。任務在舊金山的一個住宅 IP 上執行。
抓取結果:
| 狀態 | 數量 | 解讀 |
|---|---|---|
200 OK | 6,638 | 已回傳且可解析 robots.txt 內容。 |
404 Not Found | 610 | 不存在 robots.txt。RFC 9309 將其定義為隱含「允許一切」。 |
403 Forbidden | 563 | 來源主動拒絕 robots.txt 請求。排除於分析之外。 |
429 Too Many Requests | 7 | 在這個排名區間,幾乎沒有 CDN 層級的限流。 |
fetch_failed(TLS / DNS / TCP 錯誤) | 2,065 | 多半是 CDN 根網域(akamai.net、cloudfront.net、fastly.net、gtld-servers.net、apple-dns.net),它們不會在 / 提供網站。這不代表「被封鎖」——只是根本沒有 robots.txt 可提供。 |
| 其他 4xx/5xx | 117 | 混合狀況——伺服器錯誤、地理封鎖、回應格式異常。 |
因此,我們得到 7,248 個可分析樣本(6,638 個 200 + 610 個 404)。那 2,065 個 fetch_failed 的確是真實網域,但它們是 CDN/DNS 根節點,不是使用者會造訪的網站;把它們當成有「AI 政策」並不合理。它們在資料集中另作可存取性統計。
解析
所有 200 回應都以 protego 解析,這是一個符合 RFC 9309 的 Python 實作,且已在 Scrapy 的生產環境中使用。對每一個(網站,機器人)配對,我們計算三件事:
can_fetch_root——該機器人是否被允許抓取/,採用標準中的群組紀錄語意、最長匹配優先,以及當兩者同時存在時,特定機器人封鎖會覆蓋User-agent: *。has_specific_rule——檔案中是否包含一行明確命名該機器人的User-agent:(不區分大小寫)。disallow_count——匹配區塊中有多少條Disallow:指令,用來區分整站封鎖與路徑層級限制。
這個組合很重要,因為表面上的「封鎖率」會掩蓋兩種完全不同的現象:一種是品牌刻意寫出 User-agent: GPTBot \n Disallow: /,明確表態反制;另一種則是多年以前為 staging 或維護用途設下的通用 User-agent: * \n Disallow: / 規則,剛好也把所有當時尚未存在的 AI 機器人一起擋掉。本報告中,**「任一 AI 封鎖」包含兩種情況;「明確 AI 封鎖」**則是刻意書寫的子集合。
涵蓋的機器人
我們追蹤 25 個機器人,分成三類:
- AI 訓練爬蟲(16):
GPTBot、ClaudeBot、anthropic-ai、CCBot、Google-Extended、Meta-ExternalAgent、Bytespider、Applebot-Extended、Diffbot、Amazonbot、ImagesiftBot、FacebookBot、cohere-ai、AI2Bot、Omgili、Omgilibot。 - AI 推理/即時檢索機器人(7):
PerplexityBot、Perplexity-User、ChatGPT-User、OAI-SearchBot、ClaudeBot(同時提供訓練與推理)、YouBot、DuckAssistBot。 - 搜尋基準(6):
Googlebot、Bingbot、DuckDuckBot、Slurp(Yahoo)、Baiduspider、YandexBot。
有些機器人同時跨越訓練與推理的分界。ClaudeBot 最明顯——Anthropic 已在 2024 年停用較舊的 anthropic-ai UA,現在改用 ClaudeBot 同時處理訓練與即時檢索,因此 Disallow: ClaudeBot 已不能乾淨對應到「封鎖訓練但保留可見性」。我們保留原本的分類,並在後文說明其影響。
產業分類
我們以分層方式,把每個網域分類到 16 個產業桶之一(news、social、streaming、ecommerce、search、finance、infrastructure、saas、academia、dev、gov、adult、gambling、travel、telecom、unknown):
- 已知網域字典——人工整理約 500 個高流量網域到產業的對照表。
- TLD/後綴模式——
.gov對應gov、.edu與.ac.*對應academia、可識別的 CDN 後綴對應infrastructure。 - 網域名稱關鍵字——news、post、shop、bank、porn、casino 等作為備援訊號。
- 首頁抓取——對前 3 層無法分類,且回傳
robots.txt200的網站,我們抓取首頁 HTML,擷取<title>、<meta name="description">、<meta property="og:type">,並以關鍵字分數比對語言模型式的類別線索。
最終得到 3,407 個網站(34%)有明確產業標籤,另有 6,593 個維持 unknown。unknown 類別主要是非英語的區域入口網站、不符合任何單一分類的大型企業 .com 品牌網站,以及我們沒有字典對照的中小語言市場傳統媒體。本文若提到某一產業百分比,其分母是該產業的已分類樣本,不是完整 10,000。
III. 發現
發現 1 —— 每五個高流量網站中,就有一個封鎖至少一個 AI 機器人
在 7,248 個可分析網站中,1,472 個(20.31%) 封鎖至少一個 AI 機器人。1,230 個(16.97%) 有刻意的 AI 專屬規則。Googlebot 的基準值是 2.18%(158 個網站——多半是把一切都封掉的維護預設,或少數幾個搜尋引擎封競爭者)。
頭條 20% 是 Googlebot 基準的 9 倍。這確實是一個真訊號——高流量網站封鎖 AI 爬蟲的機率確實比封鎖搜尋爬蟲高出一個數量級——但它也比 2024 年以來媒體上那種「AI 封鎖已接近全面採用」的敘事小得多。即便在網路上最常被造訪的 10,000 個網站裡,仍有五分之六沉默不語。
「任一 AI 封鎖」(20.3%)與「明確 AI 封鎖」(17.0%)之間的差距,絕對值不大,但概念上很重要。這 3.3 個百分點,代表那些只是因為既有的 User-agent: * \n Disallow: / 規則把所有機器人一律攔下,而不是針對 AI 特別表態的網站。17.0% 這個刻意數字,才更接近「全球最大的網站中,有多少真的做過 AI 專屬決策」。
與先前研究對照:
| 來源 | 日期 | 樣本 | 封鎖率 |
|---|---|---|---|
| Originality.ai | 2025 年 3 月 | 1,000 個最熱門新聞(英文) | 35.7% 封鎖 GPTBot |
| Palewire | 2024 年 8 月 | 1,500 個新聞機構 | 36.0% 任一 AI 爬蟲 |
| Reuters Institute | 2025 年春季 | 50 個領先新聞品牌,10 個國家 | 78% 任一 AI 爬蟲 |
| WIRED / NYT | 2023 年底 | 美國前 50 大新聞網站 | 26% 封鎖 GPTBot |
| 本報告(Thunderbit) | 2026 年 5 月 | Tranco 前 10,000 名(全產業) | 20.3% / 17.0% 明確 |
我們的 17.0% 明確值,低於所有只看新聞的研究,因為我們的樣本有三分之二不是新聞。若只看 650 個新聞網站,就會得到 47%——在考慮樣本組成後,和前述研究其實落在同一區間。結構性的圖景是一致的:新聞群體封鎖 AI 的比率是其他網路的 3 到 4 倍。
發現 2 —— 產業深潛:從新聞到電信,差距高達 12 倍
兩年來所有「AI 抓取」報導中,被引用最多的一項發現,就是 Originality.ai 與 Palewire 提出的「80% 的新聞機構封鎖 GPTBot」。我們這次的切分得到較小、但依然顯著的數字:前 10,000 名中的新聞網站,有 47.2% 封鎖至少一個 AI 機器人,45.2% 寫了明確的 AI 規則。
但「新聞 vs 其他一切」太粗糙。完整分布(樣本中 n ≥ 10 的產業)揭示的是更豐富的故事:
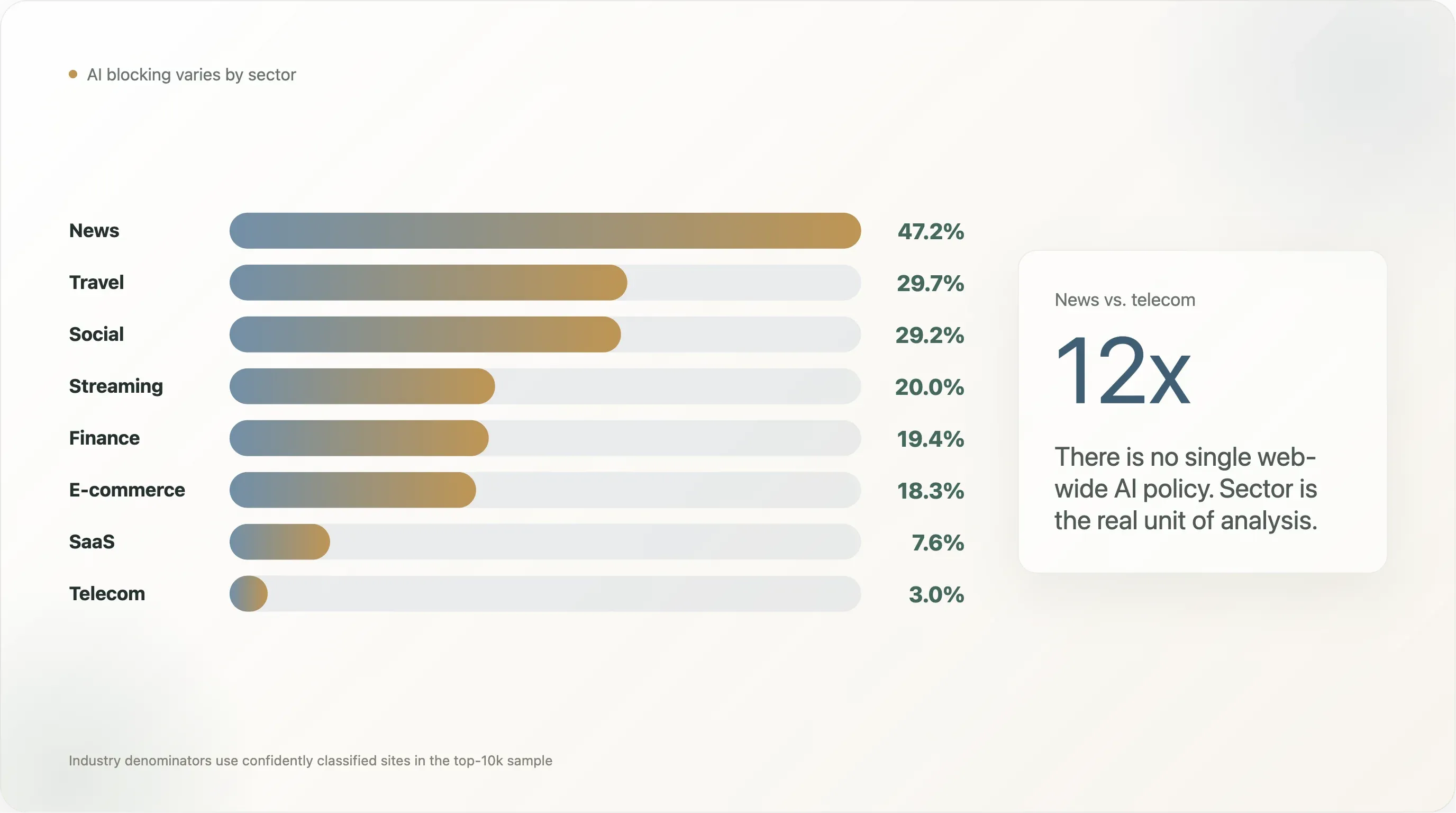
| 產業 | n | 任一 AI 封鎖 | 明確 | Googlebot 被封鎖 | 自行規則 | Cloudflare Managed | 沉默 |
|---|---|---|---|---|---|---|---|
| 新聞 | 650 | 47.2% | 45.2% | 1.5% | 46.9% | 1.5% | 48.5% |
| 旅遊 | 64 | 29.7% | 29.7% | 0.0% | 35.9% | 3.1% | 54.7% |
| 社群 | 65 | 29.2% | 23.1% | 4.6% | 23.1% | 6.2% | 66.2% |
| 串流 | 440 | 20.0% | 17.7% | 0.7% | 16.8% | 3.6% | 75.5% |
| 金融 | 129 | 19.4% | 12.4% | 0.8% | 14.7% | 2.3% | 75.2% |
| 電商 | 224 | 18.3% | 17.4% | 0.4% | 24.1% | 1.3% | 66.1% |
| 成人 | 254 | 17.3% | 14.6% | 0.4% | 10.2% | 7.9% | 79.5% |
| 搜尋 | 12 | 16.7% | 0.0% | 0.0% | 0.0% | 0.0% | 100.0% |
| 學術 | 268 | 14.6% | 13.8% | 0.4% | 13.4% | 3.4% | 77.2% |
| 博彩 | 100 | 14.0% | 13.0% | 0.0% | 18.0% | 4.0% | 77.0% |
| 開發工具 | 129 | 10.1% | 7.8% | 0.0% | 8.5% | 5.4% | 77.5% |
| SaaS | 369 | 7.6% | 6.2% | 0.3% | 9.5% | 0.8% | 87.5% |
| 政府 | 172 | 5.2% | 3.5% | 0.0% | 4.1% | 0.6% | 83.1% |
| 基礎設施 | 47 | 4.3% | 0.0% | 0.0% | 4.3% | 2.1% | 72.3% |
| 電信 | 33 | 3.0% | 3.0% | 0.0% | 12.1% | 0.0% | 78.8% |
新聞與電信之間 12 倍的差距,正說明了為什麼「網路的 AI 政策」不是一個好的分析單位。沒有單一數字;只有各產業的數字,而且彼此差了一個數量級。以下我們會拆解四個最具代表性的發現。
新聞:47% 封鎖,47% 自行撰寫規則。 新聞是率先寫出劇本的群體。Cloudflare Managed 在新聞類別中只佔 1.5%——這些出版商不會把規則外包。文本內容特別豐富:NYT 以 14 行法律前言開頭,引用「EU 指令第 4 條」;BBC 則寫著 「請像人類一樣使用我們的網站,不要像機器人……簡而言之:瀏覽、閱讀、觀看、享受——像人類一樣。」;The Sun 則寫道 「The Sun 不允許未授權使用我們內容來供大型語言模型使用。」。這是把 robots.txt 當政策聲明,而不是設定。
旅遊業 30% —— 出人意料。 Booking、Expedia、TripAdvisor、Kayak,以及主要航空公司,封鎖率只有新聞業的三分之二。選擇性模式很一致:平均的旅遊封鎖者會拒絕 5 到 7 個訓練用 UA,但保留推理用 UA(PerplexityBot、ChatGPT-User、OAI-SearchBot)。聚合價格與評論資料是護城河,回流到網站的引用則是收益。這是任何單一產業中最乾淨的「封鎖訓練、放行推理」模式。
成人內容 17% —— 也出人意料。 早期較小樣本曾顯示 0%。完整樣本顯示,每 6 個成人網站中就有 1 個封鎖至少一個 AI 機器人,而且有全產業最高的 Cloudflare Managed 比率(7.9%)。成人網站的 AI 封鎖中,超過一半來自 Cloudflare 開關,而不是出版商自行決定。影像生成訓練是隱含威脅——Stable Diffusion 級模型學視覺風格,比文字模型學寫作風格更快。
SaaS 只有 7.6%,反直覺。 軟體供應商在 AI 政策話語中聲音最大,但它們的 robots.txt 卻很開放。正確解讀是:SaaS 行銷團隊已正確把 AI 搜尋視為一條分發管道。真正思考過這件事的供應商,正在做的是 opt in,不是 opt out——明確允許 GPTBot 的名單(發現 12)主要由資安與開發工具型 SaaS 主導。
政府 5.2%、電信 3.0%、基礎設施 4.3%、開發工具 10.1%。 公共紀錄義務讓 .gov 上的 Disallow: / 在法律上相當棘手。電信行銷網站想要可被搜尋。CDN 根節點根本沒東西需要保護。開發工具則明確選擇加入(因為當 LLM 引用它的內容時,內容價值會提升)。
結論:沒有任何一個「網路是否在封鎖 AI」的單一數字,能在不失真的前提下完整說明問題。唯一誠實的說法,是按產業層級來報告。
發現 3 —— 以 AI 供應商為切面:誰被封鎖得最多?
另一個自然的切分方式,不是看機器人,而是看 AI 公司。幾家供應商同時運作多個機器人(OpenAI 有三個:GPTBot、ChatGPT-User、OAI-SearchBot;Anthropic 有兩個:ClaudeBot、anthropic-ai;Meta 也有兩個:Meta-ExternalAgent、FacebookBot)。將它們聚合到供應商層級,最接近「公開網路對每一家 AI 公司怎麼看」的答案。
| AI 供應商 | 聚合機器人 | 封鎖至少 1 個機器人的網站 | 可分析樣本占比 |
|---|---|---|---|
| Common Crawl | CCBot | 1,178 | 16.25% |
| OpenAI | GPTBot、ChatGPT-User、OAI-SearchBot | 1,172 | 16.17% |
| Anthropic | ClaudeBot、anthropic-ai | 1,111 | 15.33% |
| ByteDance | Bytespider | 1,082 | 14.93% |
| Meta | Meta-ExternalAgent、FacebookBot | 989 | 13.65% |
Google-Extended | 970 | 13.38% | |
| Amazon | Amazonbot | 877 | 12.10% |
| Apple | Applebot-Extended | 859 | 11.85% |
| Webz.io(Omgili) | Omgili、Omgilibot | 731 | 10.09% |
| Cohere | cohere-ai | 717 | 9.89% |
| Perplexity | PerplexityBot、Perplexity-User | 715 | 9.86% |
| Diffbot | Diffbot | 684 | 9.44% |
| You.com | YouBot | 563 | 7.77% |
| AI2(Allen AI) | AI2Bot | 487 | 6.72% |
| DuckDuckGo | DuckAssistBot | 482 | 6.65% |
Common Crawl 是最被針對的單一實體,儘管它是非營利網路封存庫,不是 LLM 經營者。原因在於槓桿:CCBot 為幾乎所有開源權重模型,以及相當大比例的閉源模型提供資料。先封鎖 CCBot,是出版商能寫出的、覆蓋率最高的規則。
OpenAI、Anthropic、ByteDance 聚集在 14–16%。 OpenAI 領先的一部分,來自計數上的結構(OpenAI 有三個 bot,ByteDance 只有一個)。Bytespider 的 14.9% 是「Bytespider 行為」效應——自 2024 年以來,它已被記錄曾忽略 robots.txt,出版商封鎖它是作為公開訊號,不是因為他們擔心 TikTok。
Meta、Google、Amazon、Apple 在 12–14%,屬於第二梯隊——這些規則多半是防守性書寫,而不是政治表態。小型供應商(Webz.io、Cohere、Perplexity、Diffbot、You.com、AI2、DuckDuckGo)在 6–10%,大多是被 3.8% 的通用底線拉高;針對它們的明確規則大約落在 1–4%。
xAI(Grok)、Mistral,以及大多數歐洲/中國模型實驗室沒有出現在表中——因為它們沒有公開訓練爬蟲的 UA 文件。現有的 robots.txt 生態,是美中供應商先發佈 UA、以及美歐出版商撰寫規則之間的對話;沒有發佈的供應商,在這場協商中是隱形的。
發現 4 —— CCBot 成了新的雷區,不是 GPTBot
前 10k 的機器人排序如下:
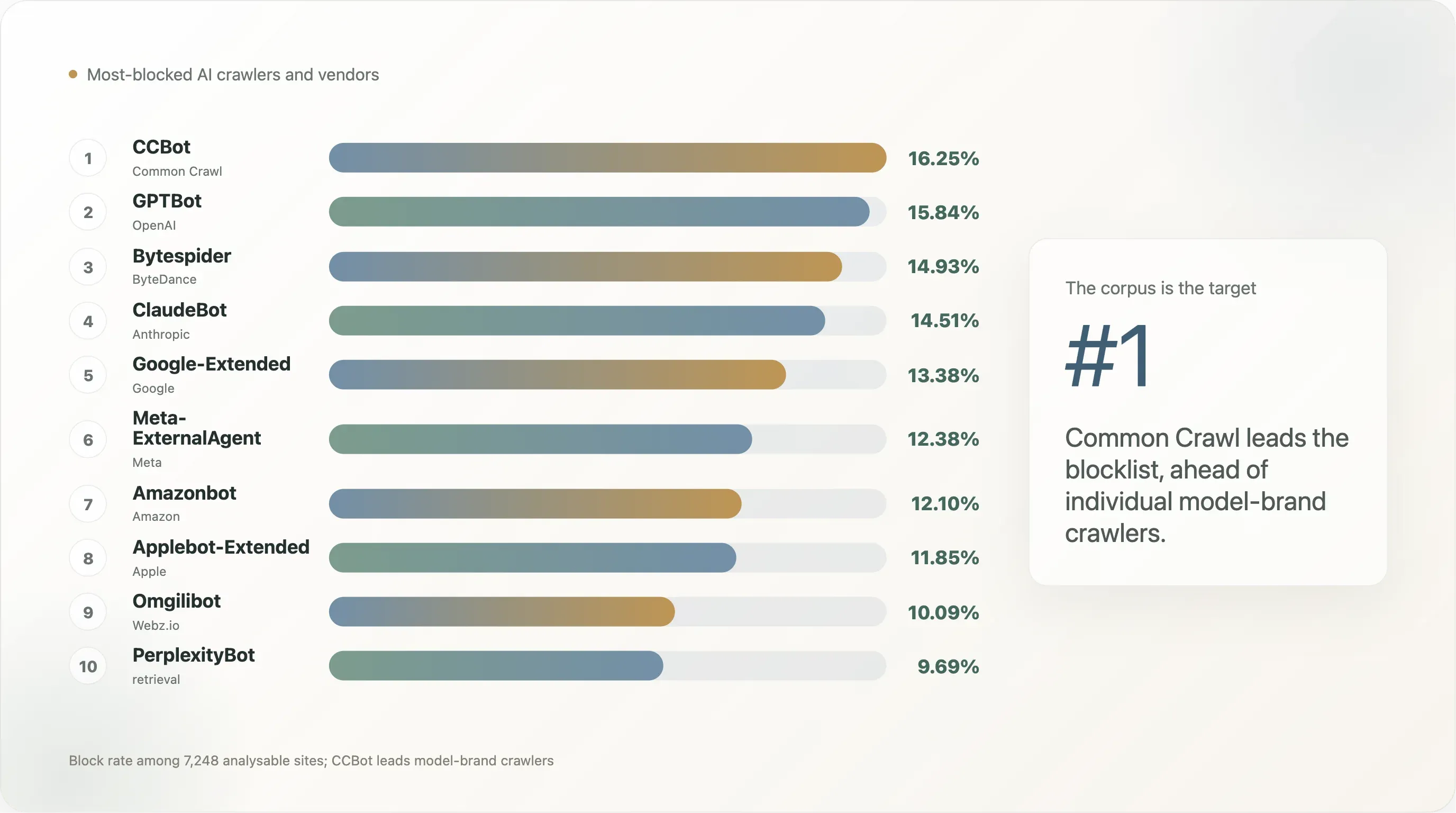
| 排名 | 機器人 | 封鎖率 | 明確規則率 |
|---|---|---|---|
| 1 | CCBot(Common Crawl) | 16.25% | 12.90% |
| 2 | GPTBot(OpenAI) | 15.84% | 12.72% |
| 3 | Bytespider(ByteDance) | 14.93% | 11.35% |
| 4 | ClaudeBot(Anthropic) | 14.51% | 11.13% |
| 5 | Google-Extended | 13.38% | 10.18% |
| 6 | Meta-ExternalAgent | 12.38% | 8.95% |
| 7 | Amazonbot | 12.10% | 8.66% |
| 8 | Applebot-Extended | 11.85% | 8.72% |
| 9 | Omgilibot | 10.09% | 5.31% |
| 10 | anthropic-ai(已棄用) | 9.99% | 6.55% |
| 11 | cohere-ai | 9.89% | 6.42% |
| 12 | PerplexityBot | 9.69% | 6.40% |
| 13 | Diffbot | 9.44% | 5.95% |
| 14 | ChatGPT-User(推理) | 8.90% | 5.73% |
| 15 | YouBot(推理) | 7.77% | 4.29% |
| 16 | OAI-SearchBot(推理) | 6.83% | 3.66% |
| 基準 | Googlebot | 2.18% | — |
| 基準 | Bingbot | 2.27% | — |
這張表說明的是:公開網路最先封的,不是模型品牌,而是資料來源。 Common Crawl 的 2500 億頁封存庫,已成為 GPT-3、GPT-4、Llama 1 / 2 / 3、Falcon、Mistral、BLOOM,以及 2020 年後多數開源權重模型的單一最大訓練輸入。若網站想退出「成為下一代前沿模型的一部分」,最佳做法就是先禁止 CCBot——一旦不進 Common Crawl,你幾乎就等於免費退出開源訓練管線。GPTBot 和 ClaudeBot 之所以排第二、第三,是因為它們是兩個商業產品的可見前端;而資料來源層級的 UA 才是結構性目標。
表中的低排名 AI 機器人也很有資訊量。Omgilibot 的 10% 對一個多數讀者可能從未聽過的 bot 來說,異常地高——它由 Webz.io 運作,這是一家向 LLM 經營者販售網路封存資料的內容資料中介商,而不少新聞機構已在檔案中明確寫上它的名稱。AI2Bot 的 6.7%(以及 Squarespace 網站上的相對應 Ai2Bot-Dolma 規則)顯示學術 LLM 圈也開始被標記,因為出版商未必會區分「非營利研究爬蟲」與「商業爬蟲」。
推理群組——ChatGPT-User、OAI-SearchBot、YouBot、Perplexity-User——比訓練群組低 4 到 8 個百分點。這個差距回答了一個長期的政策問題:答案是「會」;高流量網站確實會區分「為未來模型訓練而抓資料的 bot」與「現在就為使用者問題即時檢索的 bot」。他們不一定每次都分得很清楚(通用規則就不分),但相當一部分網站確實寫出針對訓練端的規則。
發現 5 —— 14% 封鎖 CCBot、同時保留 Googlebot:也就是「封資料來源,留搜尋」的模式
在前 10k 中,最常被採用的選擇性規則是:
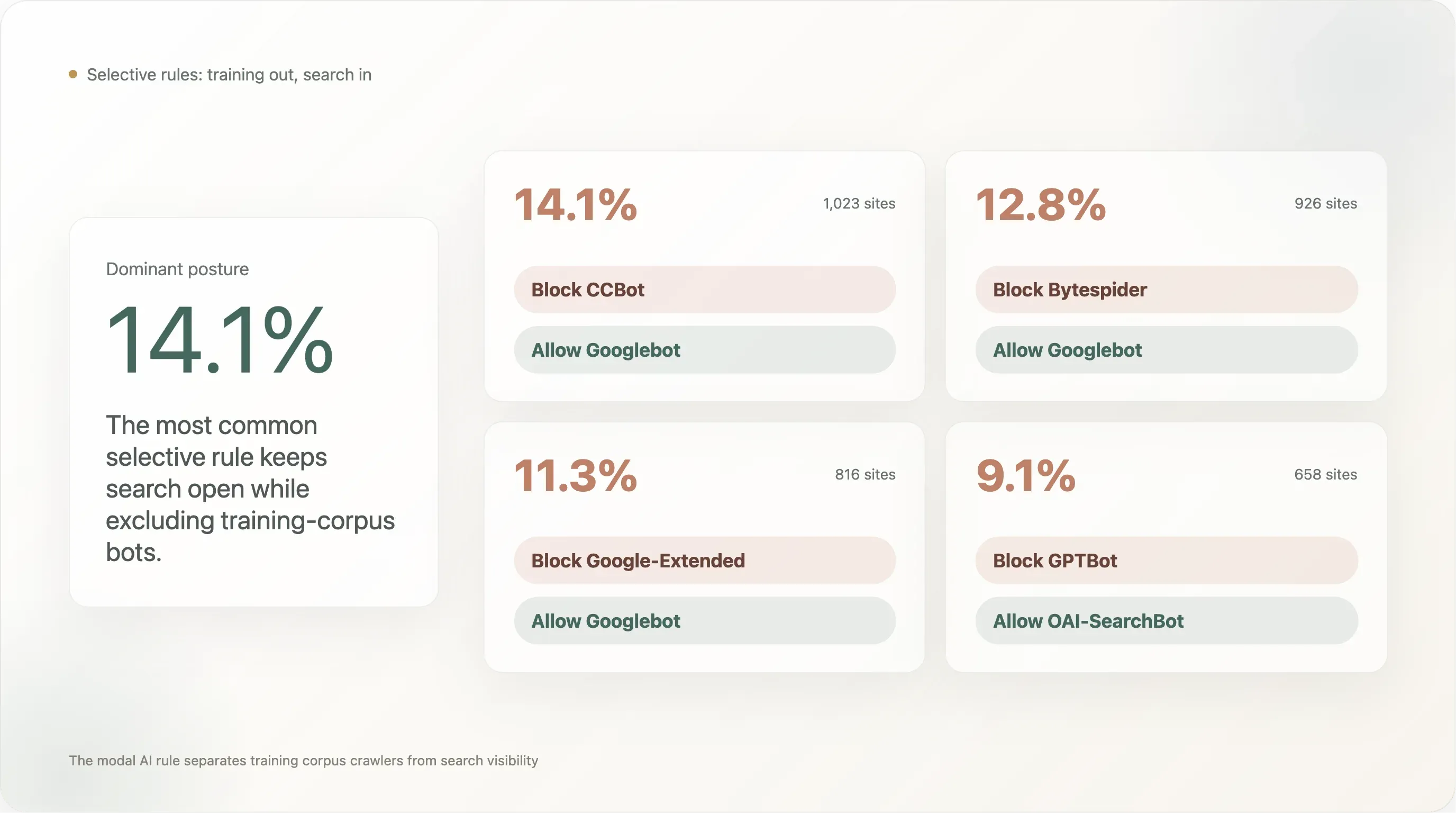
| 規則模式 | 網站數 | 可分析樣本占比 |
|---|---|---|
封鎖 CCBot、允許 Googlebot | 1,023 | 14.11% |
封鎖 Bytespider、允許 Googlebot | 926 | 12.78% |
封鎖 Google-Extended、允許 Googlebot | 816 | 11.26% |
封鎖 GPTBot、允許 OAI-SearchBot | 658 | 9.08% |
封鎖 GPTBot、允許 ChatGPT-User | 525 | 7.24% |
封鎖 CCBot、允許 PerplexityBot | 519 | 7.16% |
封鎖 anthropic-ai、允許 ClaudeBot | 59 | 0.81% |
最常被採納的模式(14.1%)是「封鎖 Common Crawl,但保留 Google 搜尋可見性」。第二名(12.8%)是「封鎖 Bytespider,但保留 Google 搜尋可見性」——也就是封鎖 ByteDance 那個已被貼上風險標記的爬蟲,同時保留合法搜尋基準。第三名(11.3%)是「封鎖 Google 自己的 AI 訓練 UA,但保留 Google 的搜尋 UA」,這正是 Google 設計 Google-Extended 的目的:出版商可以退出 Bard / Gemini 的訓練,同時不會失去搜尋排名。
這三個數字合在一起,描述了前 10k 網路的主流政策姿態:封鎖訓練資料來源的 bot,保留搜尋與推理 bot。少數模式「封鎖訓練,但允許該 LLM 的特定即時檢索 UA」——GPTBot ✗ / ChatGPT-User ✓,占 7.2%——確實存在,但規模小於資料來源層級的切割。
anthropic-ai / ClaudeBot 這列只有 0.81%,反映的是 Anthropic 於 2024 年棄用舊 UA:ClaudeBot 現在同時服務訓練與推理,使得過去 anthropic-ai 所允許的那種「封訓練、放引用」的清楚表達方式不再存在。這是 2024–2025 年間最少被討論的 UA 設計決策之一——它從 robots.txt 中移除了一整類政策表達。
發現 6 —— 新聞的細節:按國家與語言切分
當我們按國別頂級網域(country-code TLD)切新聞類別時——要記住,這代表的是 .de 的德國新聞、.fr 的法國新聞等,而不是網站所使用的語言——產業內部的差異,比新聞與其他產業之間還要大:
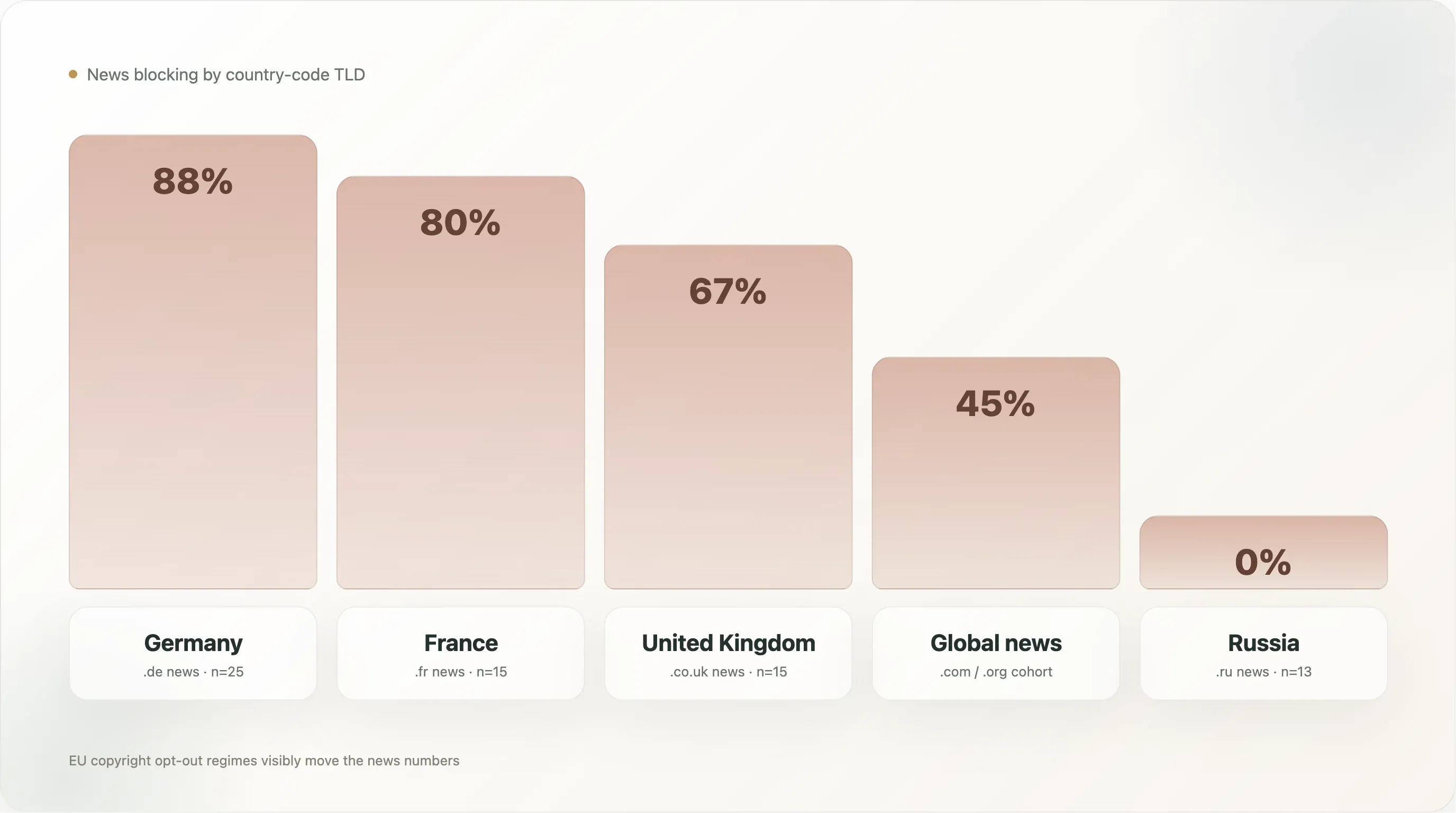
| 國家(僅新聞) | n | 任一 AI 封鎖 | 明確 |
|---|---|---|---|
🇩🇪 德國(.de) | 25 | 88.0% | 88.0% |
🇫🇷 法國(.fr) | 15 | 80.0% | 80.0% |
🇬🇧 英國(.co.uk) | 15 | 66.7% | 53.3% |
🇪🇸 西班牙(.es) | 5 | 60.0% | 60.0% |
🇮🇹 義大利(.it) | 13 | 53.8% | 53.8% |
全球新聞(.com / .org / 等) | 500 | 45.0% | 42.8% |
🇵🇱 波蘭(.pl) | 7 | 42.9% | 42.9% |
🇯🇵 日本(.jp) | 12 | 25.0% | 25.0% |
🇷🇺 俄羅斯(.ru) | 13 | 0.0% | 0.0% |
🇬🇷 希臘(.gr) | 6 | 0.0% | 0.0% |
德國新聞是整個資料集中封鎖率最高的子群,達 88%,而且全部都是 88% 的明確規則——基本上,前 10k 中沒有哪家德國新聞網站會允許 AI 訓練爬蟲抓取其資料庫。這個群體由 Spiegel、Bild、Welt、Zeit、FAZ、Süddeutsche、Heise、Golem、Stern、Focus 領軍——整個德國主流出版界,加上獨立撰寫規則的科技媒體。其下的政治基礎很厚:VG Media(德國出版商集體權利組織)一直是 EU AI 著作權訴訟中最積極的原告群體,而 EU 指令第 4 條在德國法中以 §44b UrhG 實施,並附有明確的機器可讀 opt-out 語言。等 AI 供應商進場時,德國出版商在所有國家群體裡,都是最準備好把這種法律立場翻譯成 robots.txt 規則的一群。
法國新聞 80% 緊追在後。 法國的法律環境相近(2019/790 指令已轉化為法國法律),群體行為也相近——lemonde.fr、lefigaro.fr、liberation.fr、lequipe.fr、20minutes.fr、ouest-france.fr 都有封鎖,而 Le Monde 的檔案還額外引用法國 droit du producteur de base de données(《智慧財產法典》第 L 342-1 條)作為平行的國內法律基礎。法國還有一個額外變數:2024 年巴黎商業法院的判決認為,以 robots.txt 做出的 opt-out 足以構成 Article 4 下的通知;這提供了其他司法管轄區尚未擁有的直接判例支持。
英國 67% 則較低,原因是數家大型英國出版商(thesun.co.uk、dailymail.co.uk、mirror.co.uk)使用的是 User-agent: * 全拒絕封鎖,而不是 AI 專屬規則,這把明確數字拉低到 53%。整體效果其實一樣——這些網站不允許 AI 抓取——但政策表述方式是「除了這份搜尋引擎白名單外,全部拒絕」,而不是點名 AI bot 的 disallow。法律支撐也較弱:脫歐後,英國雖沿用了 Article 4 的邏輯,但對應的國內判例更薄弱。
俄羅斯新聞 0% 是最令人驚訝的一列。樣本中的 13 個俄羅斯新聞網站(dzen.ru、rbc.ru、ria.ru、kommersant.ru、tass.ru、lenta.ru、gazeta.ru、interfax.ru、kp.ru、tass.com 等)——沒有任何一個封鎖任何 AI 爬蟲。可能的解釋是:俄語 LLM 訓練主要由 Yandex 自家的 GPT 類模型主導(使用的是 Yandex 內部爬蟲,而不是 Common Crawl);俄羅斯的著作權環境尚未出現相當於 Article 4 的法規;而大型俄羅斯出版商把西方 LLM 視為非議題(美國出口管制已讓 OpenAI/Anthropic 服務在俄羅斯受限),把 Yandex 視為國內利害關係人而非對手。政策姿態明顯不同。
日本新聞 25% 則是另一種樣貌。日本國內著作權法有明確的文本與資料探勘例外(《日本著作權法》第 30-4 條,2018 年修正),其允許程度比 EU 指令第 4 條更寬鬆——它允許出於「非享受」目的的 TDM,包括 AI 訓練,而且不要求權利人同意。日本出版商在 opt-out 上的法律抓手較少,對應的 robots.txt 比率也較低。那些真的封鎖的網站,多半是最大、最國際化的出版商(如 asahi.com、nikkei.com),其定位本來就偏國際而非國內。
跨國新聞資料,是本報告中最清楚的證據:主導因素是法規制度,不是技術,也不是產業經濟。 EU 新聞群體落在 54% 到 88% 之間;非 EU 新聞群體(俄羅斯、日本、全球 .com 群體)則介於 0% 到 45%。88% 的高峰出現在 Article 4 實施最成熟的國家;0% 的低點則出現在幾乎沒有 AI 政策法律的國家。
發現 7 —— EU 與其他地區:差距 16 個百分點
把國家視角再往上一層看,EU 與非 EU 的大致分野很明顯:
| 區域 | n | 任一 AI 封鎖 | 明確 |
|---|---|---|---|
EU ccTLD(.fr、.de、.es、.it、.nl、.pl、.se、.dk、.fi、.be、.at、.cz、.hu、.ro、.gr、.pt、.ie、.sk、.bg) | 617 | 35.2% | 33.9% |
非 EU 國家 ccTLD(.uk、.jp、.kr、.cn、.ru、.br、.in、.au、.mx、.ca、.tr、.ar、.cl、.co、.pe) | 897 | 17.2% | 13.6% |
全球(.com、.net、.org 等) | 5,734 | 19.2% | 15.7% |
EU ccTLD 網站封鎖 AI 的比率,是非 EU 國家群體的 兩倍,幾乎也是全球 .com 基準的 兩倍。這個差異在所有 EU 成員國之間都一致(沒有哪一個單一國家主導平均值),在各產業之間也一致(.de 新聞 88%、.de SaaS 約 12%、.de 電商約 25%——全都高於全球同業)。
我們在前 10k 中找到 275 份 robots.txt,在註解中明確引用了 2019/790 指令——約占可解析樣本的 3.8%。這群網站以 EU 出版商為主,但不只限於此:數個美國新聞品牌(尤其是直接寫出「Art. 4 of the EU Directive」的 NYT)、一些英國網站,以及少數較大的歐洲電商網站,也都重現了這些法律文字。另有 87 份檔案明確提到「TDM」或「text and data mining」。460 份檔案含有某種著作權保留語句(如「明確退出」、「保留所有權利」、「不得商業使用」、「不得機器學習」),即使未引用特定法規也是如此。
這一層切分還有兩個更細的觀察:
EU 效應不只出現在新聞。 當我們固定在新聞之後,EU 的非新聞網站封鎖 AI 的比率仍高於非 EU 的非新聞網站(大約 28% 對 14%)。EU 的 SaaS、電商與學術界中,有一小部分但真實存在的網站,已把 Article 4 的框架內化到自己的產業語境中。
EU 風格的語言正逐漸變成事實上的範本,即使在 EU 之外也是如此。 全球採用的 Cloudflare Managed robots.txt 範本,明確在範本文字中引用了「ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790」。一個美國網站若開啟 Cloudflare 的「Block AI Bots」設定,即使未必知道,也等於在主張 EU 的法定權利保留。這是我們找到的較有趣的政策漂移現象之一:一個歐洲法律概念,正透過美國基礎設施供應商的產品介面全球化。
發現 8 —— 範本與範本來源
在 6,638 個回傳可解析 robots.txt 的網站中,其範本來源分布如下:
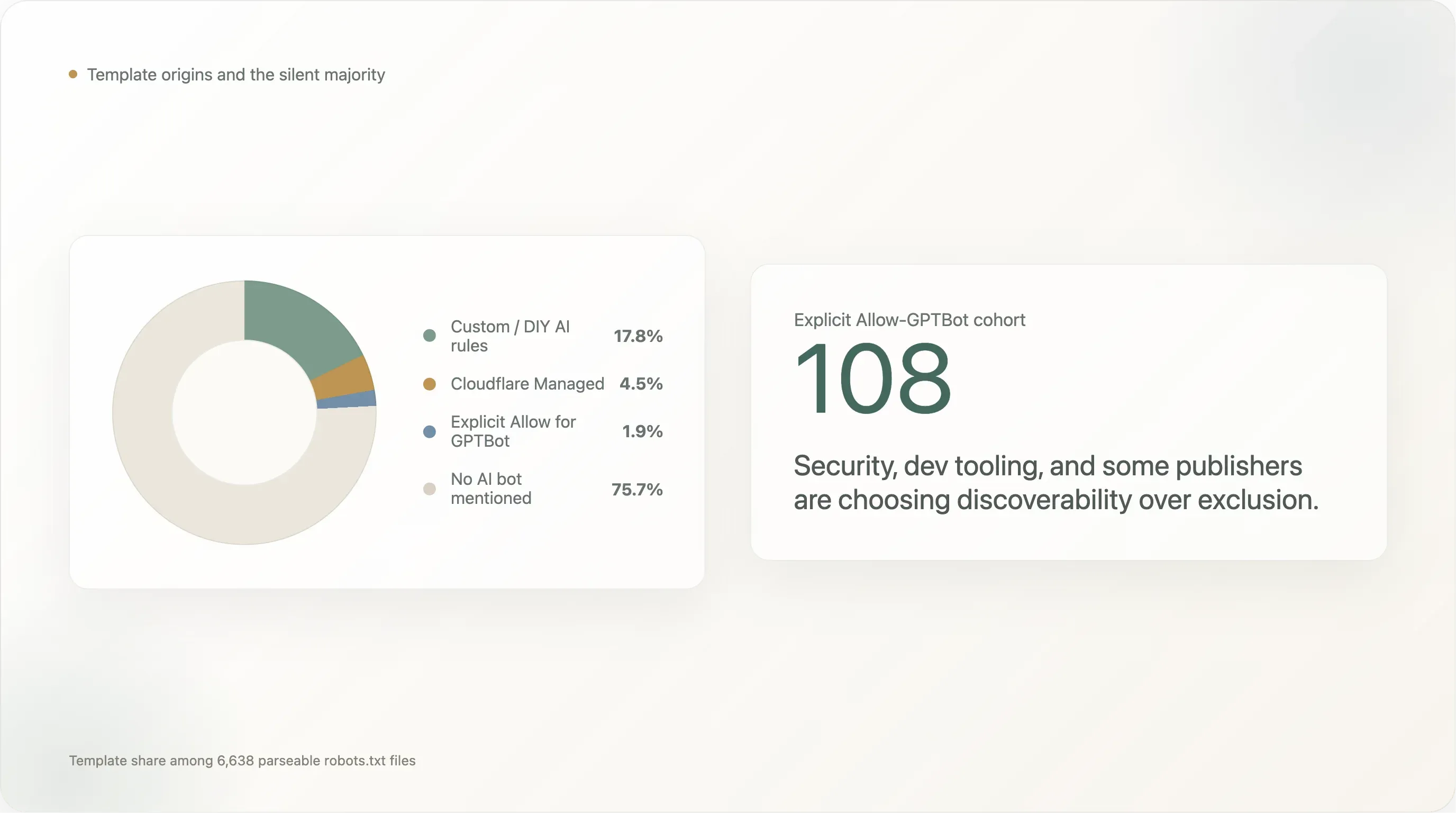
| 範本 | 網站數 | 占比 |
|---|---|---|
| 未提及任何 AI 機器人(預設 Shopify 風格、Yoast、或完全未考慮 AI 的手寫檔) | 5,024 | 75.7% |
| 自訂 / DIY AI 規則 | 1,183 | 17.8% |
Cloudflare Managed(Content-Signal: search=yes,ai-train=no) | 302 | 4.5% |
明確對 GPTBot 設 Allow: / | 124 | 1.9% |
| Squarespace 預設(路徑受限封鎖中的 28 個 AI UA) | 5 | 0.1% |
DIY 規則以 17.8% 居首。 自行撰寫封鎖規則的群體,主要由各大社群平台(facebook.com、twitter.com、linkedin.com、whatsapp.com、tiktok.com、snapchat.com、pinterest.com、x.com、chatgpt.com 本身)、最大型電商網站(amazon.com、amazonvideo.com)、主流新聞品牌(nytimes.com、cnn.com、bbc.com、theguardian.com、forbes.com、reuters.com、bbc.co.uk、t-online.de、weather.com)、重要串流/媒體網站(netflix.com、vimeo.com、soundcloud.com、imdb.com),以及一長串專業服務網站(canva.com、medium.com)所帶領。
Cloudflare Managed 佔 4.5%——比它在排名最前端的滲透率高,但比本報告涵蓋範圍以外長尾市場中的滲透率低。這個範本在 rank 1001–10000 段最常見(4–5%),在曲線最前端幾乎不存在(前 100 名:只有 1 個網站使用;101–1000 名:5 個網站)。大型全球性資產會自己寫規則;長尾網站則使用開關。
幾個值得注意的 Cloudflare Managed 網站。cloudflare.com 自己就在用這個範本,這很一致(Cloudflare 以自己的產品服務自己的網域,屬於 dogfooding)。theatlantic.com 也在用——這是我們找到的唯一一個沒有自訂規則的主要美國新聞品牌。spankbang.com 也在用——它是最高排名、採用 Cloudflare 注入 AI 封鎖的成人網站。linktr.ee 也在用,這代表 Linktree 上整個創作者經濟的 AI 訓練,都是由單一供應商決策一次封掉。launchpad.net、nexusmods.com、vinted.fr、cookielaw.org、rustdesk.com,以及一長串較小媒體資產,共同構成了可見的 Cloudflare Managed 群體。
Cloudflare 的採用模式,是我們目前看到最具體的證據,說明「網路的 AI 政策」有相當大一部分,是由基礎設施供應商決定的。絕對占比雖小(4.5%),但結構意義重大:這是 Cloudflare 預設提供的範本,而未來 12 個月的 on-by-default 趨勢仍會上升。如果 Cloudflare 把新帳號的開關改成預設開啟,全球封鎖率會在沒有任何出版商作決定的情況下實質上升。
Squarespace 的預設值(前 10k 中有 5 個網站,但在本樣本之外則更多)則是另一種模式:Squarespace 會提供一份 robots.txt,在單一區塊中列出 28 個 AI bot,但這些 bot 只會繼承 User-agent: * 的路徑限制,而不是得到整站封鎖。AI 爬蟲仍可抓取 /、首頁、產品頁、部落格;它們只是不能抓取 /config 或 /account。我們先前已將這視為第三方掃描 Squarespace 網站時出現「AI 封鎖」誤判的來源;這裡也同樣適用。
發現 9 —— AI 政策在排名分布中相當一致
這類研究的直覺通常是:被最多人造訪的網站,應該會有最強硬的 AI 政策——因為它們最怕訓練替代、法律資源最多、也最受公眾關注。但資料並不支持這種直覺。
| 排名區間 | n | 任一 AI 封鎖 | 明確 | Cloudflare Managed |
|---|---|---|---|---|
| 前 100 名 | 67 | 22.4% | 17.9% | 1 個網站 |
| 101–1,000 名 | 598 | 22.9% | 19.2% | 5 個網站 |
| 1,001–5,000 名 | 2,810 | 19.0% | 15.3% | 99 個網站 |
| 5,001–10,000 名 | 3,773 | 20.8% | 17.8% | 197 個網站 |
四個區間都落在 19% 到 23% 之間。前 100 名並不比 5001–10000 名的長尾更強硬。這個頭條比率,看起來更像是 2026 年公開網路的屬性,而不是任何單一網站有多大、或多有名。
有兩個因素。第一,排名前段由基礎設施/SaaS/搜尋/入口網站網域主導(Microsoft、Apple、Google 等),它們自身的 AI 封鎖率本來就低。第二,長尾中包含大量區域新聞出版商與 EU 管轄網站,而如發現 6 與 7 所示,它們封鎖 AI 的程度高於全球平均。這兩股力量大致互相抵消,最終形成相當一致的頭條比例。
Cloudflare Managed 這一欄則確實隨曲線變化。前 1000 名中有 6 個 Cloudflare 管理網站(1.0%);1001–10000 名中有 296 個(5.7%)。大網站自行撰寫;長尾則使用供應商開關。這是資料集中唯一真正有排名依賴性的訊號,也表示 當你沿著流量曲線從網路前段往長尾走時,政策是由供應商設定而非出版商設定的比例會穩定上升。我們預期這個梯度會延伸到前 10 萬甚至更後面。
發現 10 —— 五種解剖:當 robots.txt 真的是政策時,它長什麼樣
數字描述的是資料集的輪廓;而「公開網路上的 AI 政策」真正的樣貌,最好透過閱讀具體檔案來理解。以下五份最值得一看,橫跨整個政策光譜。
解剖 1 —— The New York Times(nytimes.com)
nytimes.com/robots.txt 的前 14 行如下:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.這是把 robots.txt 當法律證物。這份檔案的結構,顯然就是為了在 NYT v. OpenAI 訴訟中可作為證據。它引用「EU 指令第 4 條」——而且是由美國出版商引用——正好說明了發現 7:EU 的法定框架正滲入全球論述。明確禁止「建立或提供含有我們內容的封存或快取資料集」,直接瞄準 Common Crawl。整份檔案超過 60 行,且針對 GPTBot、OAI-SearchBot、ChatGPT-User、anthropic-ai、ClaudeBot、CCBot、Google-Extended、Applebot-Extended、Bytespider、Diffbot、Meta-ExternalAgent、Amazonbot、Omgili、Omgilibot 等都有獨立 User-agent 區塊——每個命名 bot 都是 Disallow: /。
解剖 2 —— Der Spiegel(spiegel.de)——區塊層級的 AI 權限控制
Der Spiegel 的 robots.txt 是我們在整個資料集中找到最具營運成熟度的一份。相關區塊如下:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /註解可譯為「針對選定區塊,試行啟用 OpenAI 搜尋爬蟲。」Spiegel 為 OpenAI 的推理 UA 白名單了七個特定內容類別——國際新聞、合作、健康、家庭、旅遊、心理與生活風格——同時封鎖其餘內容。政治版面、德國國內新聞與調查報導都明確排除在外。Common Crawl、Bytespider、Cohere、Webzio-Extended 以及其他訓練 UA 則在檔案下方直接 Disallow: /。
這是把 robots.txt 當成區塊層級的編輯政策。其內在邏輯是:生活風格內容的訓練替代風險較低,而被引用的推理收益較高,因此 Spiegel 允許 AI 呈現這些區塊;政治與調查內容才是護城河,所以 AI 被排除。我們沒有在其他地方看到這種模式。這意味著編輯、法務與基礎設施團隊之間已達到相當高的內部協調,而大多數新聞編輯部還沒到這一步。我們預期這種更細粒度、區塊層級的政策表達,會在 2026–2027 年擴散——Spiegel 的檔案幾乎可視為領先指標。
解剖 3 —— BBC(bbc.com)——政策聲明型
BBC 的 robots.txt 開頭如下:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.BBC 以版本字串管理 robots.txt(# version: ec59bd... 是一個 git commit hash),禁止 BBC 法務所追蹤的八種特定 AI 用法,並以符合 BBC 品牌語氣的一句話做收尾。那句「明確退出任何司法管轄區中的法定例外」是一種刻意的全球保留——它的意思是:我們不信任任何單一法律制度能給我們想要的保護,所以我們要一次在所有地方都主張退出。 這是資料集中最像精修稿的 robots.txt,讀起來更像新聞稿,而不是設定檔。
解剖 4 —— WordPress.org —— 明確歡迎
把上述內容與 wordpress.org 相比:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org 明確為九個 AI 訓練爬蟲開放許可,包括三個(Bytespider、CCBot、anthropic-ai)最常在其他地方被封鎖的 bot。其背後的隱含理論是:WordPress 的文件與外掛生態是一種公共財,而當 AI 助理能回答相關問題時,其價值會上升。每次有人問 Claude「我在 WordPress 怎麼設定永久連結?」而 Claude 已受訓於 wordpress.org/documentation/,WordPress 的使命就有被服務到。基金會顯然認為,讓內容進入每一個模型的訓練資料庫,是一種戰略上的正面收益,因此用檔案的表達語法清楚說出來。
解剖 5 —— The Verge(theverge.com)——贊助內容混合模式
還有一種值得展示的模式。The Verge 的 AI 規則是 Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp//sp/ 路徑是 The Verge 的贊助/合作內容區塊。編輯內容被封鎖於 AI 訓練之外;贊助內容則被允許。其經濟邏輯非常清楚:贊助商付錢讓內容可被發現,包括透過 AI;而編輯旗艦內容則是護城河。GPTBot 完全開放(推測是與 OpenAI 有直接關係),Applebot 作為搜尋基準也完全開放,其餘則採混合處理。這是我們找到的唯一一種「分層式 AI 存取」結構。
這五份檔案,構成了當前 robots.txt AI 政策的全部光譜。前 10k 中大多數檔案都不像這些——它們不是沉默,就是使用供應商範本。真正長得像這些的檔案,是由那些已決定「這份檔案值得認真閱讀」的人寫的。
補充一點檔案規模:我們樣本中 robots.txt 主體的中位數是 858 位元組——太小,根本無法承載有意義的 AI 政策。真正承載規則的是右尾:1,005 個網站(15.3%)的檔案超過 5 KB,273 個超過 20 KB,最大值是 248 KB。460 份檔案含有著作權保留語句;275 份明確引用 EU 2019/790。 到了 2026 年,robots.txt 越來越像一份有版本控管、經律師審閱的文件,而不是一條設定列。
發現 11 —— 有 108 個網站明確 歡迎 GPTBot
有一小群但非常顯眼的網站,會寫出 User-agent: GPTBot \n Allow: /——這與更常被討論的「Disallow GPTBot」相反。樣本中共有 108 個網站在根路徑明確對 GPTBot 設 Allow。按 Tranco 排名列出前 25 名:
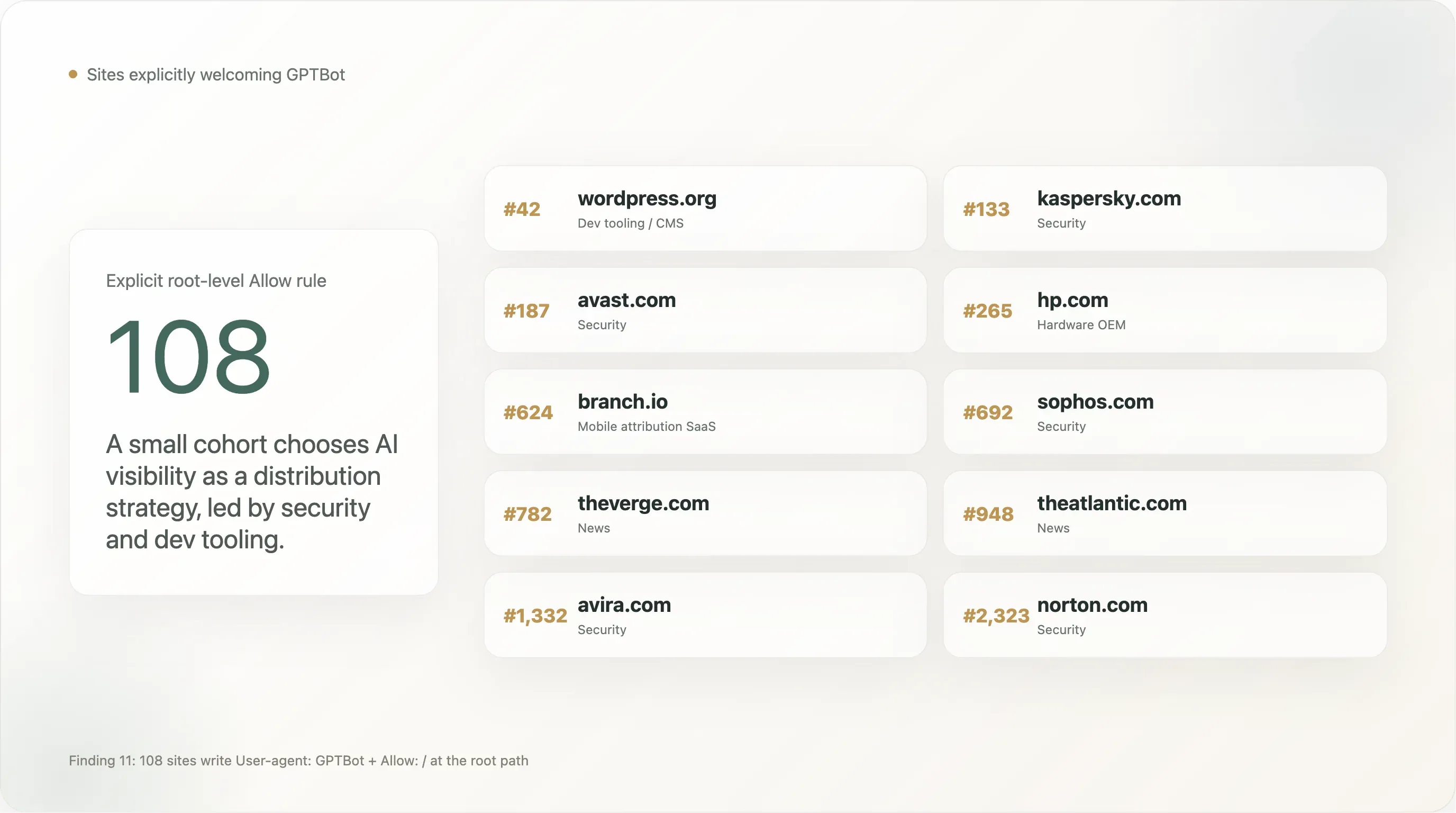
| 排名 | 網域 | 產業 |
|---|---|---|
| 42 | wordpress.org | 開發工具/CMS |
| 133 | kaspersky.com | 資安 |
| 187 | avast.com | 資安 |
| 265 | hp.com | 硬體 OEM |
| 624 | branch.io | 行動歸因 SaaS |
| 692 | sophos.com | 資安 |
| 782 | theverge.com | 新聞 |
| 905 | rambler.ru | 俄羅斯入口網站 |
| 945 | kleinanzeigen.de | 德國市集 |
| 948 | theatlantic.com | 新聞 |
| 1,092 | lge.com | LG Electronics |
| 1,300 | justdial.com | 印度在地搜尋 |
| 1,332 | avira.com | 資安 |
| 1,412 | youm7.com | 埃及新聞 |
| 1,530 | goodreturns.in | 印度金融 |
| 1,621 | publi24.ro | 羅馬尼亞分類廣告 |
| 1,807 | geocomply.com | 合規 SaaS |
| 1,908 | nba.com | 運動 |
| 1,956 | oneindia.com | 印度新聞 |
| 1,974 | mindbox.ru | 俄羅斯 SaaS |
| 2,009 | thesun.co.uk | 新聞 |
| 2,126 | vox.com | 新聞 |
| 2,140 | mgid.com | 原生廣告 |
| 2,314 | ninjarmm.com | IT 管理 SaaS |
| 2,323 | norton.com | 資安 |
幾個模式:
資安公司明顯過度代表。 Kaspersky、Avast、Sophos、Avira、Norton、NinjaRMM 都明確允許 GPTBot。這是刻意的分發策略:當使用者問 ChatGPT「哪一款防毒軟體最適合我的 Windows 電腦?」時,模型訓練資料庫裡有沒有你的品牌,會直接影響推薦。資安是少數幾個 AI 搜尋已經開始取代 SEO 成為主要獲客管道的 B2C 品類之一,而這些品牌最先行動。我們預期其餘資安群體會在 12 個月內跟進。
一些主要新聞品牌出現在名單上,而不是封鎖名單。 The Verge、The Atlantic、Vox、The Sun、NBA.com。這並非矛盾——這些出版商似乎認為,能在 ChatGPT 搜尋中被引用,比免於訓練更有價值,因此寫下明確 Allow 以防止未來被 CDN 或 CMS 過度封鎖。和 NYT / Reuters / BBC / Forbes / Guardian 那種明確 Disallow 的立場相比,兩者都說得通;新聞業並不是鐵板一塊。
The Sun 的存在尤其值得注意,因為同一網站在檔案其他地方也使用了 User-agent: * 全拒絕封鎖。最好的解讀是:AI 訓練被禁止,但 AI 搜尋被允許,而我們還特別把 GPTBot 白名單化,確保 ChatGPT 能引用 The Sun 回答問題。 這是 GPTBot-Allow 規則中法律技巧最高的一種——它同時包含 opt-out 與單一供應商 opt-in。
WordPress.org 的存在,是這份名單中最具影響力的單一項目。 全球開源 CMS 生態中,有相當一部分會導向 WordPress.org 取得文件,或直接從那裡取得外掛。WordPress Foundation 透過在 wordpress.org/robots.txt 明確允許 GPTBot,等於公開宣示 WordPress 文件生態可供訓練——這也會連帶影響 Claude、Gemini、ChatGPT 對「我怎麼...」類 WordPress 問題的回答品質。
完整 Allow-GPTBot 名單中的其餘 83 個網站,則是區域新聞、較小資安供應商、非英語市場的分類廣告平台,以及 B2B SaaS 的長尾。據我們所知,並不存在類似產業級別的「Allow-GPTBot」協調——這條規則是由一個網站一個網站地,被那些認為「進入資料來源」是戰略位置的經營者採納的。
發現 12 —— llms.txt 在這個尺度上幾乎只是傳聞
llms.txt 是一種為 LLM 友善內容探索而提出的替代檔案格式(自 2024 年底以來,由 Mintlify、Anthropic、Vercel 與少數開發工具供應商推廣),但在我們的樣本中幾乎看不到明顯採用。
在 6,638 個回傳可解析 robots.txt 的網站中,只有 83 個(1.15%)提到 llms.txt——通常只是以 Sitemap: https://example.com/llms.txt 形式出現。這比在開發工具密集的商務樣本中測得的相同指標低了兩個數量級;後者因 Vercel 與 Mintlify 的預設值而使採用率被拉高。
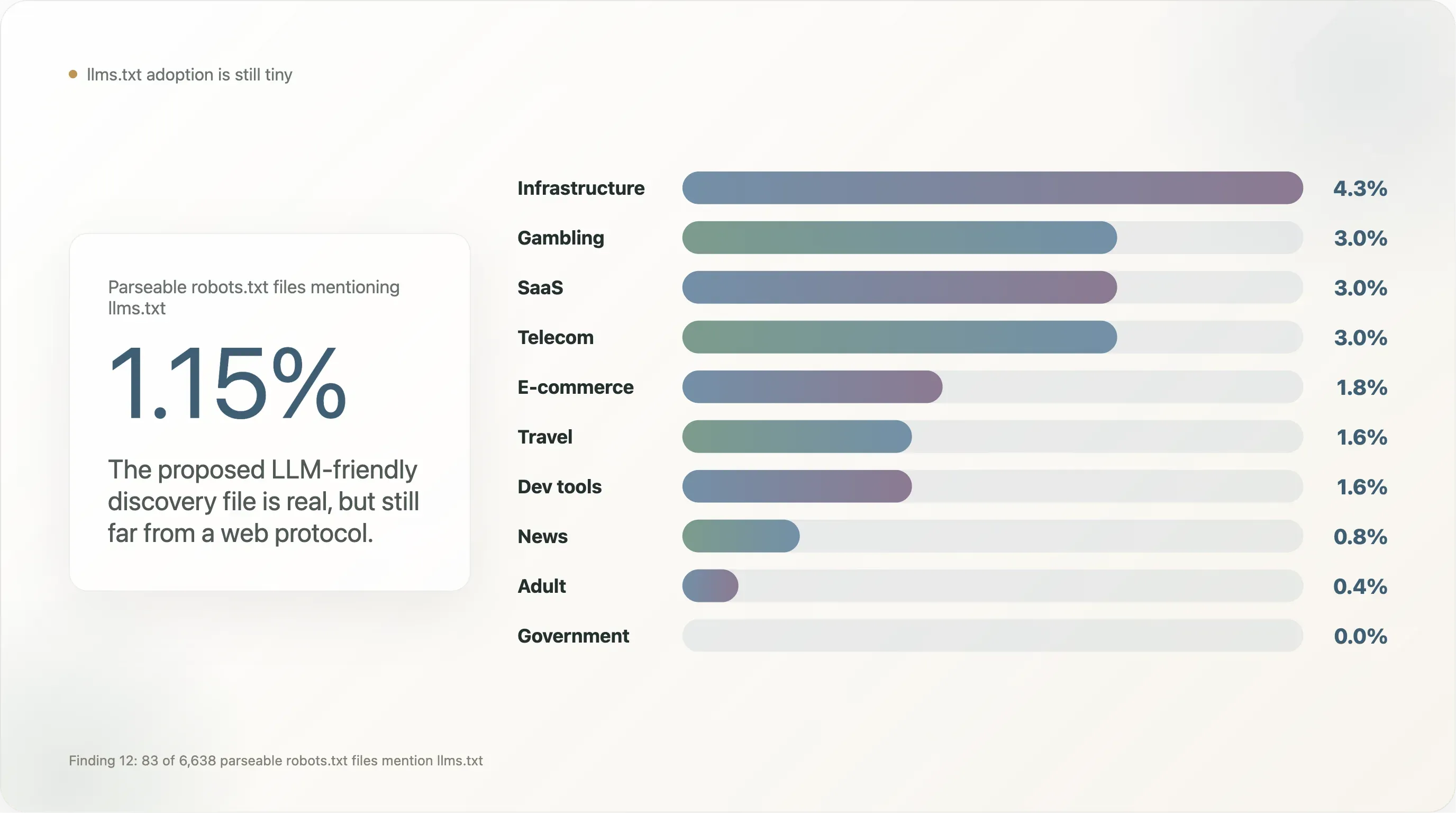
產業分布如下:
| 產業 | n | 提及 llms.txt 的比例 |
|---|---|---|
| 基礎設施 | 47 | 4.3% |
| 博彩 | 100 | 3.0% |
| SaaS | 369 | 3.0% |
| 電信 | 33 | 3.0% |
| 電商 | 224 | 1.8% |
| 旅遊 | 64 | 1.6% |
| 開發工具 | 129 | 1.6% |
| 新聞 | 650 | 0.8% |
| 成人 | 254 | 0.4% |
| 政府 | 172 | 0.0% |
| 學術 | 268 | 0.0% |
| 搜尋 | 12 | 0.0% |
llms.txt 主要集中在與開發工具相近的 SaaS、博彩(這類受監管產業的法遵團隊習慣層層疊加額外中繼資料,因此採納新詞彙型 robots.txt 功能的速度更快),以及 B2B 電商。它在新聞與政府中明顯缺席——這兩個區塊是最積極參與 AI 政策、也最需要採用該標準才能從「供應商實驗」升級為「網路協定」的族群。直到那時,llms.txt 仍然是真實但規模很小;到了 2026 年底做一次追蹤審計,會是一個很好的再測試。
llms.txt 面臨的結構性問題是,它沒有經過任何 IETF 程序標準化,而且主要 AI 供應商也沒有承諾遵循。robots.txt 規則有 30 年的爬蟲基礎設施支撐;llms.txt 沒有。除非至少一家主要供應商(OpenAI、Anthropic、Google、Cloudflare)正式宣告支援,否則這個檔案本質上就是 Mintlify / Vercel 生態的行銷產物。我們不預期 2026 年會有改變。
發現 13 —— 可存取性:前兩/三的網路仍可讀取 robots.txt
一個原本不是設計成發現的附帶觀察:前 10,000 名網站中,有 66% 對單一研究 IP 回傳了可解析的 robots.txt,而且 10,000 個網站裡只有 7 個(0.07%)回傳 429 Too Many Requests。這對 robots.txt 作為公開協定來說是好消息。
作比較,兩個月前對一個 1,008 網域的中型電商樣本執行同樣流程時,52% 的已解析網域回傳了 429——Shopify 與 Cloudflare CDN 對任何非主要搜尋引擎 UA 都採取激進限流。高流量網路顯然友善得多:前段網站較可能具備 (a) 沒那麼激進的 bot 管理層級,或 (b) 對已知研究爬蟲設有明確白名單,或兩者都有。
前 10k 中 21% 的 fetch_failed,主要來自 CDN 根節點(akamai.net、cloudfront.net、fastly.net、apple-dns.net、gtld-servers.net),它們在 / 並不運行 webserver。它們不是在封鎖我們;它們只是沒有東西可提供。若排除這些,真正「嘗試讀取但失敗」的比率只落在低個位數。
這表示這份報告未來的版本——季度快照、年對年比較——都可以在單機上以低成本且可重現的方式執行。審計窗口在曲線前端仍然開著。相較之下,長尾與電商區段的狀況不同,那裡的 CDN 層級限流已經幾乎把 robots.txt 私有化了。我們預期這種分化會加劇:前段網站因為被搜尋引擎索引而必須可讀,所以仍會保持可讀;長尾電商則會因為 Cloudflare 的 bot fight 等級更積極部署而變得更不容易被讀取。robots.txt 的公開可審計性,正沿著「可見網路」與「受營運保護網路」之間的同一條線開始分岔。
IV. 這一切代表什麼
四個主張,按資料支持力度由強到弱排序。
1. 網際網路的 AI 政策是按產業劃分,而不是全球統一。 新聞與電信之間 12 倍的差距,主導了所有匯總數字。若只報導「X% 的網路封鎖 AI」,卻不按產業切分,就會高估 SaaS/政府/開發工具,低估新聞/旅遊/社群。只有按產業報告,才是誠實的框架。
2. EU 著作權指令第 4 條,是唯一明顯在推動數字變化的法律制度。 EU ccTLD 網站的封鎖率是 35%,而全球基準是 19%。美國訴訟(NYT v. OpenAI、美國著作權局 2025 年 1 月報告)改變了美國新聞群體,但沒有改變更廣泛的美國網路。EU 的框架也透過 Cloudflare 的範本向全球滲透——無論客戶所在司法管轄區為何,範本都會引用 2019/790 指令。
3. 兩種並行的「AI 政策」正在被表達,而且彼此不一致。 刻意、手寫的政策(17.8%,主要來自新聞/社群/旅遊/電商)與繼承而來的 Cloudflare Managed 政策(4.5%)在實質上重疊,但合法性不同。在 AI 經營者尋求法律依據以忽略 robots.txt 的世界裡,「我自己寫、也審過」的抗辯,在結構上比「我只是把它打開」更強。訴訟的激勵,就是把政策從第二類推向第一類。
4. 出版商封鎖的,是資料來源,不是模型。 CCBot 以 16.3% 位居第一,甚至高於任何模型品牌 bot,這最能說明問題。封鎖 OpenAI,不能讓出版商退出「被訓練過」;封鎖 CCBot 才能。前 10k 網路中有 14.1% 在封鎖 CCBot 的同時,仍允許 Googlebot。到 2026 年,「封訓練、留搜尋」已是最典型的 AI 規則。
對考慮自身立場的網站來說: 最普遍的姿態是沉默——前 10k 中有 80% 對 AI 什麼都不說。寫規則的 17% 幾乎都集中在 Disallow,但有一小群且持續擴大的網站(以資安供應商為主的 1.5% 明確 Allow GPTBot 名單)正公開選擇相反方向。沒有產業共識,未來 12 個月也不會有。
對 AI 經營者來說: 當世界上 17% 的大型網站已經手寫出明確、刻意的 bot 名稱規則,且 3.8% 的檔案明確引用 EU 法條條號時,再繼續主張 robots.txt 只是語意模糊的舊協定,將愈來愈難維持。是否遵守那些規則,是商業決策;那些規則是否存在,如今已是實證事實。
V. 展望:我們預期 2026 年底前會出現什麼
資料中可見三個趨勢:
Cloudflare Managed 的占比會翻倍以上,合理地可能達到可解析前 10k 的 10% 以上。 Cloudflare 的路線圖公開討論對新帳號預設開啟 Block AI Bots。如果這個開關真的預設開啟,全球封鎖率會在沒有任何出版商決策的情況下上升 5 到 8 個百分點。當 rank 5001–10000 區間的 Cloudflare Managed 占比超過目前的 5.7% 時,我們就會知道這件事正在發生。
區塊層級 AI 政策(如 Spiegel 風格)會在主要新聞旗艦間擴散。 經濟邏輯——讓 AI 引用低風險內容,保護護城河內容——已經足夠有說服力,因此我們預期到 2026 年底,至少還會有 10 家旗艦新聞編輯部推出區塊層級規則。先留意德國與法國的中型媒體;那裡的法制最鼓勵實驗。
明確 Allow GPTBot 的群體會成長,主力是 B2B SaaS 與開發工具。 當 AI 搜尋成為軟體供應商可量化的獲客管道時(資安領域現在已經是),邊際 CMO 會寫下 User-agent: GPTBot \n Allow: /,以避免不小心被過度封鎖。我們預期 108 個網站的名單,年底前大約會翻倍。
我們不預期什麼:沉默多數的占比會有明顯變化。那 80% 對 AI 什麼都不說的網路,包含了政府、電信、基礎設施、B2B SaaS 等產業——它們沒有經濟理由寫規則,也沒有法律壓力去寫。全面性的 AI 政策不會到來。
VI. 限制
- 單一快照偏誤。 抓取發生在 2026 年 5 月初的 36 小時窗口內。前 100 名網站的檔案每天都會變;頭條數字每季預期會有 1–2 個百分點的漂移。
- 產業分類缺口。 在四層分類器之後,10,000 個網站中有 6,593 個仍是
unknown。在樣本數夠大的產業中,百分比相當穩健(新聞:650、串流:440、SaaS:369、學術:268、成人:254、電商:224、政府:172、金融:129、開發工具:129),但 n < 30 時噪音較大。國家新聞切分也有類似限制——DE/FR/UK 的 n ≥ 15,而韓國/瑞典/捷克則落在 n=20–25。 robots.txt是自願性的。Disallow是請求,不是障礙。Bytespider、PerplexityBot等已被記錄忽略規則。我們衡量的是政策宣告,不是政策執行。- 單一美國 IP 的審計。 我們無法讀取 21% 的已解析網域。多數是沒有 webserver 的 CDN 根節點;少數是 CDN 在我們到達原站前就把我們標記的網站。這會讓樣本略微偏向較舊的基礎設施,並偏離以來源國地理封鎖的網站。
- Tranco 清單的語意。 Tranco 會做穩定性篩選;它不是嚴格的使用者行為排名。匯總數字對清單選擇相對穩健,但具體排名位置不是。
- 沒有流量資料。 我們測量的是
robots.txt政策,不是實際 AI bot 吞吐量。政策與流量不一定一致。
VII. 重現本研究
所有用於產生本報告的檔案,都在交付資料夾中。
- tranco_top10k.csv —— 輸入清單
- out/sites.csv —— 網域 × 排名 × 產業 × 語言 × robots.txt 狀態(10,000 列)
- out/fetch_meta.csv —— 每個網域的抓取結果(狀態、scheme、位元組數、錯誤)
- out/bot_status.csv —— 網域 × bot 矩陣(250,000 列:是否封鎖、是否有規則、抓取狀態)
- out/site_meta.csv —— 每個網站一筆分析紀錄(範本、摘要布林值)
- out/analysis.json —— 報告中引用的所有指標
- 01_fetch_robots.py、02_classify.py、03_parse_and_analyze.py —— 完整 Python 流程
歡迎將方法論修正、資料集問題與後續分析寄至 support@thunderbit.com。本報告獨立於 Thunderbit 所持有的任何商業立場;我們打造的是 AI 驅動的網頁爬蟲,而我們在結構上也有理由希望 robots.txt 在公開網路上持續成為一份有意義、機器可讀的契約。本報告中的資料本身即可成立。—— Thunderbit 研究團隊,2026 年 5 月。