网络增长得太快,说实话已经有点跟不上了——到 2026 年,几乎,而其中很大一部分,正是企业在抓取数据,用来支持销售、运营和竞争研究。我亲眼看着网页爬虫从技术爱好者的“加分项”,变成了从销售团队到房产经纪人都离不开的必备能力。但问题是:不是所有网页爬虫公司都一样。选对了,工作流就能顺畅自动化;选错了,可能就要迎来一整周的复制粘贴噩梦。
所以,这次我认真梳理了 2026 年最值得关注的网页爬虫公司。不管你是只想两步拿到数据的非技术用户,还是希望完全掌控流程的开发者,这份清单都覆盖了最优秀的选择——也会坦白讲清楚每一家擅长什么、短板又在哪里。我们开始吧。
为什么企业需要顶级网页爬虫公司
如果你曾经试着整理潜在客户名单、监控竞品价格,或者从几十页、几千页产品页面里提取数据,你一定知道手动采集有多折磨人。它又慢、又容易出错,而且说实话,没人会觉得这事有趣。这也是为什么,企业把它用在从、价格监控,到市场研究和情绪分析的各种场景里。
真正的价值在于:自动化。现代网页爬虫公司可以让你:
- 自动处理重复性调研(再也不用疯狂复制粘贴)
- 轻松扩展规模到数千个页面,而不需要额外人力
- 直接把数据集成到你最常用的工具里(Excel、Google 表格、Notion、CRM)
- 比竞争对手更快拿到更新、更丰富的数据,抢先一步
但选择这么多,怎么挑?这正是这篇指南要解决的问题。
我们如何评估顶级网页爬虫公司
不是每个爬虫都适合每一种用户,也不适合每一种任务。下面是我评估这些产品时看的标准:
- 易用性: 非程序员能不能很快上手?界面是否直观?
- 自动化与功能: 是否支持分页、子页面、定时任务和动态内容?
- 可扩展性: 能不能处理大型项目,还是只适合小任务?
- 集成能力: 数据导出或连接到其他工具有多方便?
- 价格: 有没有免费层?对中小企业是否友好?能否满足企业级扩展?
- 支持与社区: 需要时有没有教程、模板和真正能帮上忙的支持?
我也看了每家公司的独特之处——因为有时候,“最好”的工具并不是功能最多的那个,而是最适合你工作流的那个。
好了,开始看名单吧。
1. Thunderbit
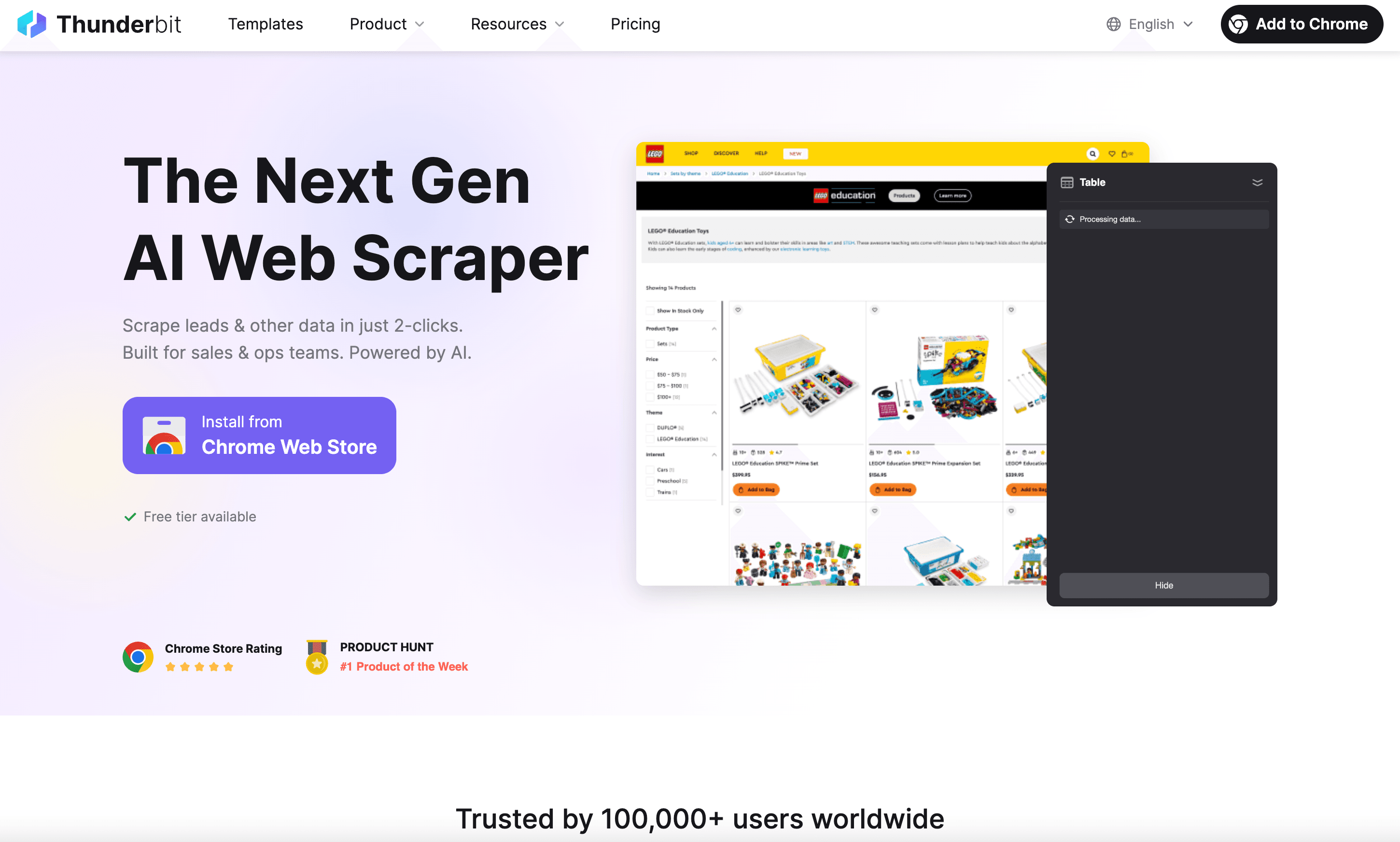 是我对 2026 年最兴奋的 AI 网页爬虫——当然不只是因为我参与了它的打造!Thunderbit 专为想要数据、而不是麻烦的企业用户设计。它的 Chrome 扩展可以让你用自然语言提示词和 AI 字段建议抓取任何网站。无需编码、无需模板、没有压力。
是我对 2026 年最兴奋的 AI 网页爬虫——当然不只是因为我参与了它的打造!Thunderbit 专为想要数据、而不是麻烦的企业用户设计。它的 Chrome 扩展可以让你用自然语言提示词和 AI 字段建议抓取任何网站。无需编码、无需模板、没有压力。
Thunderbit 的突出优势:
- 两步抓取: 只要点击“AI 建议字段”和“抓取”,剩下的交给 Thunderbit 的 AI。
- 支持子页面与分页: 先轻松抓取列表页,再让 AI 访问每个子页面获取更多细节。
- 即用模板: 针对 Amazon、Zillow、Shopify 等热门网站,直接使用预置模板,一键抓取。
- 免费导出数据: 可导出到 Excel、Google 表格、Notion 或 Airtable——你的数据不会被付费墙拦住。
- AI 数据增强: 抓取时即可对数据打标签、分类和翻译。
- 定时与云端抓取: 可设置周期任务,或在云端运行抓取以提升速度。
- 完全免费的层级: 免费可抓取最多 6 个页面,试用增强后可达 10 个。付费方案从每月 15 美元起。
Thunderbit 已获得全球超过,从销售团队到电商运营都在使用。如果你想要 2026 年最简单、最友好的网页爬虫体验,Thunderbit 很难被超越。
想看看它怎么工作?亲自试试吧。
2. Scrapy
 是开发者最常用的开源 Python 框架,适合想要完全掌控流程的人。它强大、灵活,经过实战检验,既能爬小网站,也能抓取数百万页面。
是开发者最常用的开源 Python 框架,适合想要完全掌控流程的人。它强大、灵活,经过实战检验,既能爬小网站,也能抓取数百万页面。
最适合: 技术团队、数据工程师,以及任何熟悉 Python 的人。
主要功能:
- 自定义规则创建: 构建 spider 以适配任何网站结构。
- 可扩展且高效: 通过强大的错误处理能力应对大规模抓取。
- 与 Python 生态集成: 可接入 Pandas、Jupyter 等工具。
- 免费且开源: 无许可费用,社区支持也很强大。
提醒一下: Scrapy 有一定学习曲线。如果你不会编程,最好看看别的工具。但对开发者来说,它就是个强力选手()。
3. ParseHub
 是一款桌面应用,把网页爬虫做得更直观、更容易上手。它的点选式界面让你不用写代码也能构建爬虫。
是一款桌面应用,把网页爬虫做得更直观、更容易上手。它的点选式界面让你不用写代码也能构建爬虫。
最适合: 中小企业、研究人员,以及想要灵活性的非程序员。
主要功能:
- 可视化工作流: 点击选择数据,可建立分页和子页面逻辑。
- 云端定时: 即使电脑关机,也能按计划运行抓取任务。
- 导出选项: 可下载为 CSV、Excel 或 JSON。
- 免费方案: 5 个项目,每次运行最多 200 页;付费方案从每月 39 美元起。
ParseHub 尤其适合抓取列表、评论和电商数据()。
4. Octoparse
 是一款无需代码、支持拖放的网页爬虫平台,重点是大规模自动化。对于想在不写脚本的情况下搭建复杂任务的团队来说,它很合适。
是一款无需代码、支持拖放的网页爬虫平台,重点是大规模自动化。对于想在不写脚本的情况下搭建复杂任务的团队来说,它很合适。
最适合: 市场、研究和运营团队。
主要功能:
- 拖放式工作流: 可视化构建爬虫,处理动态内容和无限滚动。
- 云端抓取与定时: 在云端运行任务,支持周期性任务。
- IP 轮换与反封禁: 内置功能帮助抓取高难度网站。
- 导出到 Excel、Sheets、数据库: 轻松融入你的工作流。
- 免费层: 每月最多 10,000 条记录;付费方案从每月 75 美元起。
Octoparse 因其速度和处理大规模项目的能力而备受认可()。
5. DataMiner
 是一款 Chrome 扩展,把网页爬虫直接带进浏览器里。它非常适合快速、基于模板的表格、列表和简单网站抓取。
是一款 Chrome 扩展,把网页爬虫直接带进浏览器里。它非常适合快速、基于模板的表格、列表和简单网站抓取。
最适合: 日常用户、销售运营,以及任何长期使用 Chrome 的人。
主要功能:
- 模板市场: 超过 60,000 个热门网站的预置配方。
- 点选提取: 可视化选择数据,无需代码。
- 导出到 Excel/Google 表格: 一键导出。
- 免费方案: 每月 500 页;付费方案从每月 19 美元起。
DataMiner 很适合快速任务和非技术用户()。
6. Import.io
 是一个企业级平台,专注于把网页内容转化为结构化数据,用于分析和商业智能。
是一个企业级平台,专注于把网页内容转化为结构化数据,用于分析和商业智能。
最适合: 数据需求大、集成要求高的企业。
主要功能:
- 托管服务模式: Import.io 团队可以为你构建并维护爬虫。
- 可视化界面: 无需代码即可构建提取工作流。
- API 访问: 将抓取数据直接集成到你的应用和仪表盘中。
- 合规与安全: 企业级控制、PII 脱敏等。
价格: 定制报价,通常从每月约 299 美元起()。
7. Apify
 是一个对开发者友好的自动化平台,拥有庞大的预构建 “Actors”(抓取机器人)市场,并支持构建自定义工作流。
是一个对开发者友好的自动化平台,拥有庞大的预构建 “Actors”(抓取机器人)市场,并支持构建自定义工作流。
最适合: 开发者、代理商,以及需要灵活性的团队。
主要功能:
- Actor 市场: 可直接使用热门网站的现成爬虫,也可以自己构建。
- 云基础设施: 支持大规模运行抓取、定时任务和 API 集成。
- GitHub 集成: 自动化工作流和 CI/CD。
- 按需付费: 先有免费额度,然后按使用量计费;付费方案从每月 39 美元起。
Apify 非常适合简单和复杂项目()。
8. Diffbot
 使用 AI 和知识图谱,把非结构化网页内容转化为结构化、可被机器读取的数据。你可以把它理解成网页爬虫的“大脑”。
使用 AI 和知识图谱,把非结构化网页内容转化为结构化、可被机器读取的数据。你可以把它理解成网页爬虫的“大脑”。
最适合: 企业、研究人员,以及任何需要大规模自动化提取的人。
主要功能:
- AI 驱动提取: 可自动识别文章、产品、组织等内容。
- 知识图谱: 通过 API 访问全球最大的网站数据图谱。
- 数据增强: 拉取相关实体、新闻和上下文信息。
- API 优先: 可与 BI 工具和数据管道集成。
价格: 从每月 299 美元起()。
9. WebHarvy
 是一款基于 Windows 的桌面爬虫,带有可视化点选界面。对于想避开代码、偏好桌面应用的用户来说,它很合适。
是一款基于 Windows 的桌面爬虫,带有可视化点选界面。对于想避开代码、偏好桌面应用的用户来说,它很合适。
最适合: Windows 用户、研究人员,以及中小企业。
主要功能:
- 可视化选择: 点击数据即可定义字段,无需代码。
- 支持图片和多页导航: 可抓取文本、图片并跟随分页。
- 导出到 Excel、XML、数据库: 输出方式灵活。
- 一次性许可证: 付一次,永久使用()。
WebHarvy 尤其受电商和分类信息网站抓取用户欢迎()。
10. Mozenda
 是一个基于云的平台,专为企业级数据提取和自动化而打造。
是一个基于云的平台,专为企业级数据提取和自动化而打造。
最适合: 大型组织、合规要求严格的行业。
主要功能:
- 云端自动化: 集中安排、监控和管理抓取任务。
- 数据转换: 清洗、增强并以多种格式导出数据。
- 团队协作: 支持多用户和工作流管理。
- 企业支持: 合规性、可靠性和专属帮助()。
价格: 约每月 99 美元;也提供企业定价。
11. Sequentum
 是一款面向数据专业人士和代理商的高级桌面/网页爬虫。
是一款面向数据专业人士和代理商的高级桌面/网页爬虫。
最适合: 数据专业人士、代理商,以及需要深度自动化的人。
主要功能:
- 高级脚本: 自动处理复杂提取逻辑。
- 报告与监控: 跟踪任务、接收提醒并管理大型项目。
- 集成: 可导出到数据库、API 或云存储。
- 没有免费层: 仅提供付费许可证()。
Sequentum 专为高吞吐、可定制的提取而打造。
12. Helium Scraper
 是一款带可视化工作流构建器的桌面工具,非常适合从复杂且动态的网站中提取数据。
是一款带可视化工作流构建器的桌面工具,非常适合从复杂且动态的网站中提取数据。
最适合: 高级用户、分析师,以及任何想要灵活性又不想写代码的人。
主要功能:
- 可视化工作流: 通过拖放界面构建提取逻辑。
- 支持动态内容: 可处理大量 JavaScript 的网站。
- 数据转换: 导出前先清洗和整理数据。
- 导出选项: Excel、CSV、数据库等。
- 一次性费用: 永久许可证约 199 美元()。
Helium Scraper 尤其适合非标准网站和自定义工作流。
对比顶级网页爬虫公司:功能一览
下面给你一个快速对比,帮你找到最合适的工具:
| 公司 | 最适合 | 易用性 | 自动化与 AI | 可扩展性 | 导出选项 | 免费层 / 价格 |
|---|---|---|---|---|---|---|
| Thunderbit | 非程序员、中小企业 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Excel、表格、Notion | 免费(6 页),$15/月起 |
| Scrapy | 开发者 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Python、CSV、数据库 | 免费,开源 |
| ParseHub | 中小企业、研究人员 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | CSV、Excel、JSON | 免费(5 个项目),$39+ |
| Octoparse | 运营、市场 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Excel、数据库、API | 免费(1 万行),$75+ |
| DataMiner | Chrome 用户 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | Excel、表格 | 免费(500 页),$19+ |
| Import.io | 企业 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | API、数据库、云 | 定制报价,$299+/月 |
| Apify | 开发者、代理商 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | API、数据库、表格 | 免费额度,$39+/月 |
| Diffbot | 研究、分析 | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | API、知识图谱 | $299+/月 |
| WebHarvy | Windows 用户 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | Excel、XML、数据库 | 一次性,$139+ |
| Mozenda | 企业 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Excel、API、云 | $99+/月,企业版 |
| Content Grabber | 数据专业人士、代理商 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 数据库、API、云 | 仅付费许可证 |
| Helium Scraper | 高级用户、分析师 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | Excel、CSV、数据库 | 一次性,$199 |
快速推荐:
- 适合非程序员: Thunderbit、DataMiner、ParseHub、WebHarvy
- 适合开发者: Scrapy、Apify、Content Grabber
- 适合企业: Import.io、Diffbot、Mozenda
- 适合灵活的可视化工作流: Thunderbit、Octoparse、Helium Scraper
结论:为你的业务选择合适的网页爬虫伙伴
到 2026 年,网页爬虫早就不只是技术人员的工具了——它已经成了任何需要数据来更快、更聪明做决策的企业核心能力。选对网页爬虫公司,可以帮你节省大量时间,提升投资回报率,还能挖掘出竞争对手可能错过的洞察。
我的建议是:
- 按团队来选工具: 非技术用户会喜欢 Thunderbit 或 DataMiner。开发者可以看看 Scrapy 或 Apify。企业则建议关注 Import.io 或 Diffbot。
- 考虑规模和集成: 你是否需要抓取数千个页面?你是否希望数据直接进入 Sheets、Notion 或 CRM?
- 先从免费试用开始: 大多数工具都提供免费层——先拿真实项目测试,再决定是否投入。
- 别怕组合使用: 有时候,最好的工作流其实是把几款工具搭配起来。
如果你已经准备好看看网页爬虫到底能有多简单,。你的表格和你的心态都会感谢你。
想看更多深度解析、技巧和教程,欢迎访问 。
常见问题
1. 什么是网页爬虫?为什么它在 2026 年对企业很重要?
网页爬虫是从网站自动提取数据的过程。它对企业很关键,因为它能快速、大规模地收集线索、监控价格、做市场研究等数据,从而节省时间并提升决策质量。
2. 哪家网页爬虫公司最适合非技术用户?
Thunderbit 和 DataMiner 是非程序员的首选,因为它们分别提供了 AI 驱动和可视化的界面。两者都能让你只用几次点击就提取数据,无需写代码。
3. 选择网页爬虫公司时,我应该看哪些功能?
重点看易用性、自动化能力(分页、子页面、定时任务)、可扩展性、导出选项(Excel、Sheets、API)以及客户支持。选择最符合你技术水平和业务需求的工具。
4. 有免费的网页爬虫解决方案吗?
有!Thunderbit、DataMiner、ParseHub 和 Octoparse 都提供免费层。Scrapy 作为开源工具对开发者完全免费。免费方案很适合小项目,或者在扩展前先测试。
5. 抓取数据时,如何保持合规和道德?
始终尊重网站的服务条款和隐私政策。只抓取公开可用的数据,避免对网站造成过载,并注意 GDPR 等数据隐私法规。许多顶级网页爬虫公司都提供合规功能和最佳实践指南。
准备好更聪明地开始抓取了吗? 或前往 浏览更多指南。
了解更多