
上周,我们的一位用户告诉我,他花了整整一个下午,把 SuperPages 上的管道工列表一条条复制到表格里——3 个小时只整理了 47 行。最后不但手腕酸痛,数据里还有不少错别字,而且连邮箱都没拿到。听到这个故事,我特别有共鸣,因为我也经历过这种抓狂时刻,而这正是我们打造 的初衷。
SuperPages 是美国历史很久的本地商业目录之一,由 Thryv 运营,覆盖范围很广,横跨多个主要城市和行业——管道工、牙医、律师、暖通技师,基本你能想到的都有。较早的技术文档曾把它描述为一个拥有 1100 万以上商家信息的全国黄页数据库,如今网站上依然能看到密集的本地分类。难点从来不是找不到商家,而是如何把这些信息整理成干净、可用、补充完整的潜在客户名单,而且还不把自己逼疯(或者把整个下午搭进去)。
根据 HubSpot 2024 年销售趋势报告,销售人员每天真正用于销售的时间只有大约 2 小时,剩下的时间都被数据录入、调研之类的任务吞掉了。与此同时,81% 的销售从业者认为 AI 可以帮助他们减少手工工作。本文会介绍 3 种抓取 SuperPages 潜在客户的方法——从零代码 AI 到 Python——让你可以根据自己的技术水平选择最适合的方式,把时间留给真正能带来业绩的事情。
什么是 SuperPages?为什么销售团队这么爱拿它找线索?
SuperPages 是一个面向美国市场的在线商业目录,本地企业会显示联系方式、分类、评分等信息。你可以把它理解为老式黄页电话簿的数字升级版——只不过现在可以按分类和地点搜索,而且每条商家信息都更丰富。
一条典型的 SuperPages 商家信息可能包含:
- 商家名称
- 电话号码
- 街道地址
- 网站链接(如果有)
- 分类(如管道、家庭法律、暖通等)
- 评分和评论
- 营业时间(通常在详情页)
- 描述(详情页)
SuperPages 首页会突出展示一些热门分类,比如家庭服务、管道工、电工、牙医、法律服务、汽车维修、餐饮和宠物服务——而这些行业,恰好就是销售团队、代理公司和本地服务供应商最常做外联的目标。
简而言之,SuperPages 对任何想开发美国本地企业客户的人来说,都是一座金矿。数据结构清晰、覆盖范围广,而且这些分类非常适合直接对应到真实的外联活动中。
为什么要抓取 SuperPages 潜在客户?(最常见的应用场景)
手动浏览 SuperPages,再把数据复制到表格里,简直就是效率黑洞。抓取可以把这个过程自动化,让你在几分钟内拿到有针对性的结构化名单,而不是花几个小时人工整理。并且因为搜索条件是你自己控制的(分类 + 城市 + 关键词),输出结果往往比买来的泛化线索名单更精准。
下面是我从用户那里最常见到的使用场景:
| 应用场景 | 受益人群 | 示例 |
|---|---|---|
| 本地线索开发 | 销售团队、代理公司 | 收集达拉斯的管道工名单,用于冷外联 |
| 竞品调研 | 运营、市场团队 | 对比某个市场里竞争对手的评分和服务 |
| 市场地图绘制 | 商务拓展 | 找出某个邮编区域内所有牙医,为新品发布做准备 |
| 供应商搜寻 | 采购、运营 | 在某个地区寻找带电话和网站信息的供应商 |
| 本地 SEO 开发 | 代理公司 | 找出没有网站或列表信息较弱的商家 |
| 区域规划 | 外勤销售 | 按城市、邮编或服务区域对承包商分组 |
美国 B2B 潜在客户开发市场在 2024 年估值约为 85 亿美元,预计到 2034 年将达到 182 亿美元——说明这类数据的需求不会下降。刚抓取出来、且按分类和地域细分的名单,通常比泛泛购买的名单更有针对性,但在外联前仍然需要验证和去重(后面会详细说)。
最终会得到什么:SuperPages 抓取数据样例
在讲方法之前,我先让你看看最后会得到什么。很多教程都会跳过这一步,但如果你真的要投入时间,最好先知道回报长什么样。
下面是一个样例输出表(虚构数据,但结构真实):
| 商家名称 | 电话 | 地址 | 网站 | 分类 | 评分 | 营业时间 | 邮箱(补全后) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Plumbing | 4.6 | 周一至周五 7:00-18:00 | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | HVAC | 4.8 | 周一至周六 8:00-19:00 | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Dentists | 4.4 | 周一至周四 9:00-17:00 | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Legal Services | 4.2 | 周一至周五 8:30-17:30 | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Auto Repair | 4.7 | 周一至周六 8:00-18:00 | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Pet Grooming | 4.9 | 周二至周日 9:00-17:00 | booking@echoparkpets.example |
有几点值得注意:
- 来自搜索结果页:商家名称、电话、部分地址、分类、评分、列表 URL。
- 来自商家详情页(子页面):完整地址、营业时间、描述、评论,有时还有网站。
- 来自补全:邮箱(通常只会在商家自己的网站上,或通过补全工具找到)。
- 来自清洗:电话规范成 E.164 格式、州/邮编标准化、去重键、来源 URL 和抓取时间。
这类输出可以直接放进 CRM、Google Sheets 或 Airtable,马上开始跟进。
抓取 SuperPages 潜在客户的 3 种方法:快速对比

每个人的技术熟练度和耐心都不一样,所以我把三种方法并排放在这里,方便你按需选择:
| 对比维度 | Thunderbit(AI 零代码) | 可视化爬虫(如 Octoparse) | Python(Requests + BS4) |
|---|---|---|---|
| 搭建时间 | 约 2 分钟(安装扩展) | 约 15 分钟(创建流程) | 约 30 分钟(装库、写代码) |
| 需要写代码吗 | 不需要 | 不需要 | 需要(Python) |
| 分页处理 | 内置(点击或滚动) | 需要配置 | 手写代码 |
| 子页面补全 | 一键子页面抓取 | 需要单独工作流/循环 | 需要单独脚本 |
| 反封锁能力 | 云端抓取自动处理 | 取决于套餐/代理插件 | 全靠自己(代理、请求头、限速) |
| 导出选项 | Excel、Google Sheets、Airtable、Notion、CSV、JSON | CSV、Excel、数据库 | 你自己写什么就导出什么 |
| 最适合 | 销售团队、代理公司、非开发者 | 半技术用户 | 想完全掌控的开发者 |
我的建议是:如果你希望 2 分钟内就开始抓取,直接看方法 1;如果你喜欢可视化流程,也不介意一些配置,可以试试方法 2;如果你想完全掌控并且会 Python,那就直接跳到方法 3。
方法 1:用 Thunderbit 抓取 SuperPages 潜在客户(AI,零代码)
这是从“我有一个 SuperPages 搜索结果”到“我已经拿到一份潜在客户名单”最快的方式。不需要写代码,不需要搭工作流,也不用配代理。虽然我有点偏爱这个方法——毕竟 Thunderbit 就是我们做的——但我会把整个过程讲清楚,你可以自己判断。
难度:入门
所需时间:完整抓取一个分类/城市页面约 5 分钟
你需要:Chrome 浏览器、Thunderbit Chrome 扩展(免费版即可)
第 1 步:安装 Thunderbit,并打开 SuperPages
前往 安装 Thunderbit 扩展,大概 1 分钟就能完成。安装后,打开一个 SuperPages 搜索结果页——比如在 superpages.com 上搜索 “Plumbers in Los Angeles, CA”。
你应该能在浏览器工具栏里看到 Thunderbit 图标,并且侧边栏已经准备就绪。
第 2 步:点击“AI Suggest Fields”,自动识别数据列
打开 Thunderbit 侧边栏,点击 “AI Suggest Fields”。Thunderbit 的 AI 会读取页面,并根据识别到的内容自动推荐字段,通常包括商家名称、电话、地址、网站、分类、评分和列表 URL。
你可以在抓取前随时调整、添加或删除字段。想增加一个自定义列,比如“是否有网站?”或“是否有服务区域?”只要在 Field AI Prompt 里用自然语言描述就行。例如,你可以让某一列执行“把电话格式化成 +1XXXXXXXXXX”,或者“判断是面向住宅还是商业客户”。
这时你应该已经能在 Thunderbit 面板里看到一个配置好的表格预览。
第 3 步:点击“Scrape”,看数据自动填充
点击蓝色的 “Scrape” 按钮。Thunderbit 会提取当前页面上的所有商家信息,并逐行填入表格。对于普通的 SuperPages 结果页,这通常只需要 30–45 秒。
Thunderbit 会自动处理分页——它能识别 “Next” 按钮或者无限滚动,并持续抓取,直到页面结束或者达到你设置的上限。如果你要抓取大量结果(比如某个都会区所有的管道工),可以切换到云端抓取模式,它最多可以一次处理 50 页,而且不会占用你的浏览器。
第 4 步:使用子页面抓取,补全每条商家信息
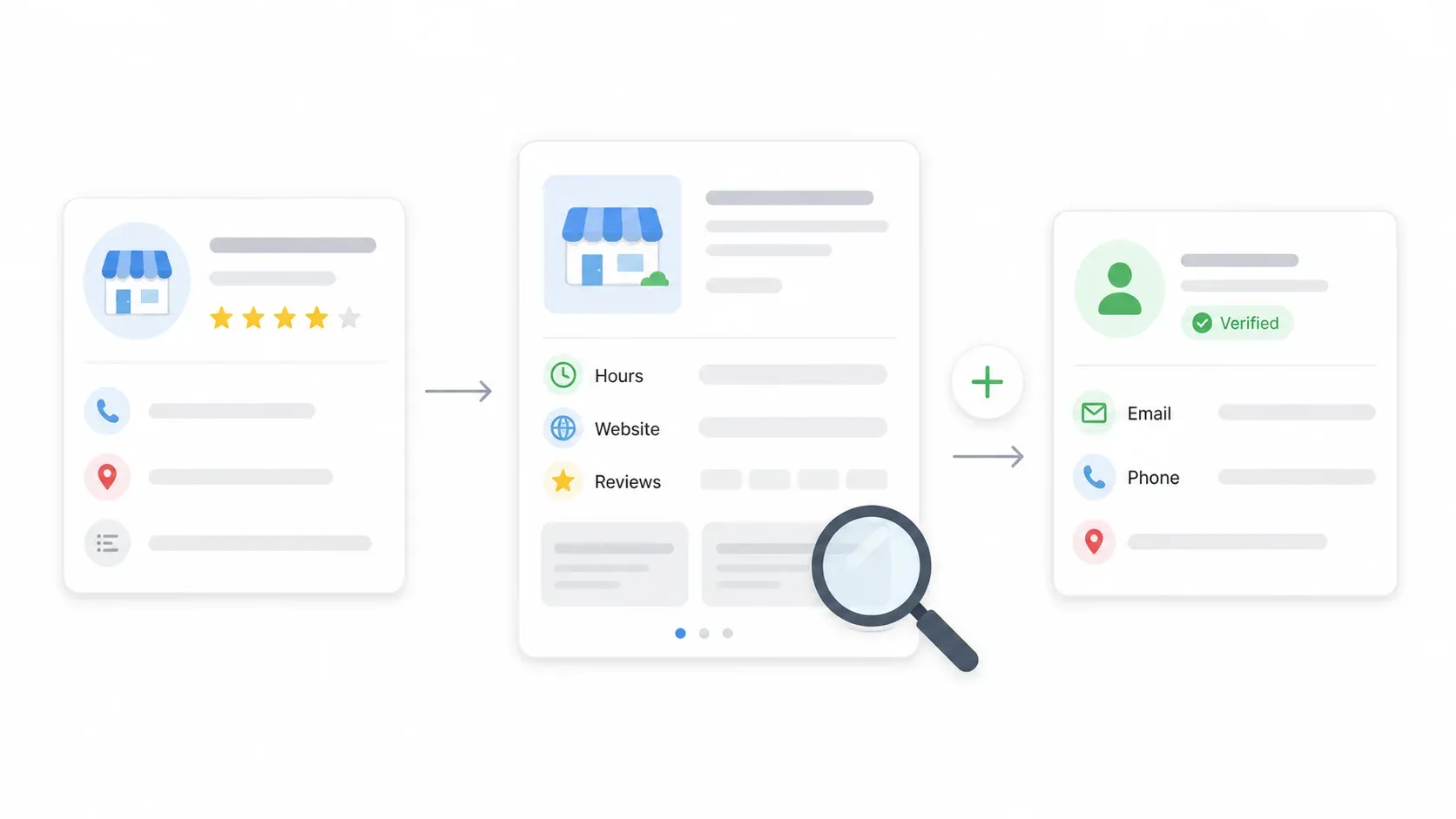
搜索结果页只能给你基础信息,但真正有价值的内容——营业时间、完整描述、评论,有时还有邮箱——都在每个商家的详情页里。点击 “Scrape Subpages”,Thunderbit 会逐个访问每条商家的详情页,把营业时间、描述、网站 URL 以及那里能看到的任何联系方式补充到表格中。
整个过程只需要点一下。没有额外工作流,也不需要配置。补全后的数据会直接追加到你原来的表格里。
第 5 步:把潜在客户导出到 Excel、Google Sheets、Airtable 或 Notion
等你对数据满意后,点击导出。Thunderbit 可以把线索直接发送到:
- Google Sheets(适合 CRM 准备和协作分享)
- Airtable(轻量级流程表)
- Notion(调研数据库)
- Excel / CSV(导入 CRM)
- JSON(交给开发者继续处理)
所有导出选项都是免费的。如果你要把线索导入 HubSpot 或 Salesforce,导出到 CSV 或 Google Sheets 通常是最快的路径。
小技巧:尽量按“分类 + 城市”抓取,不要用过于宽泛的全州搜索。比如 “Emergency plumbers Dallas TX” 会比 “plumbers Texas” 得到更精确、更可执行的名单。建议再加上 “Source URL” 和 “Scraped At” 列,方便追踪来源。
方法 2:用可视化爬虫抓取 SuperPages(以 Octoparse 为例)
像 Octoparse 这样的可视化爬虫,介于两者之间:不需要编程,但配置量比 Thunderbit 更多。Octoparse 甚至还提供了一个预置的 SuperPages 模板,适合一些简单场景。
难度:中级
所需时间:约 20–30 分钟(设置 + 抓取)
你需要:Octoparse 账号(有免费方案,但功能有限)
第 1 步:新建任务并加载 SuperPages URL
打开 Octoparse,点击 “New Task”,然后粘贴你的 SuperPages 搜索链接(例如 “https://www.superpages.com/los-angeles-ca/plumbers”)。内置浏览器会把页面加载出来。
第 2 步:自动识别或手动选择字段
点击 “Auto-detect”——Octoparse 会扫描页面,并高亮它认为相关的数据字段。查看 Data Preview 面板。根据我的经验,自动识别通常能抓到大部分字段,但也可能把一些多余内容(比如广告标签或导航文本)一起抓进来,或者漏掉部分字段。所以你大概率还是要手动增删几个字段。
根据 Octoparse 的帮助文档,自动识别会生成一个包含分页和数据提取步骤的基础工作流,但用户仍可能需要手动补充缺失的数据。
第 3 步:构建工作流并配置分页
点击 “Create workflow”。Octoparse 会生成一个逐步执行的操作序列。检查分页步骤——确认它能正确点击 “Next” 或加载更多结果。如果你想抓取每个商家的详情页信息(营业时间、邮箱、描述),还需要在工作流中添加详情页循环或子页面动作。相比 Thunderbit 的一键子页面抓取,这一步会复杂不少。
第 4 步:运行任务并导出数据
可以在本地运行任务(适合小任务),也可以在 Octoparse 云端运行(适合定时任务或大任务——云端属于付费功能)。任务结束后,可导出为 CSV、Excel 或 JSON。
需要注意的限制:Octoparse 免费计划包含 10 个任务、每月最多 50,000 行,以及仅限本地提取。云端运行、IP 轮换、验证码处理以及部分导出集成都需要付费方案(按年计费大约从每月 69 美元起)。
方法 3:用 Python 抓取 SuperPages(Requests + BeautifulSoup)
这是开发者路线:自由度最高,责任也最大。如果你习惯写和维护 Python 脚本,这种方式给你的灵活性最多,但也最容易踩坑。
难度:高级
所需时间:约 30–60 分钟(环境搭建 + 编码 + 调试)
你需要:Python 3.x、pip、requests、beautifulsoup4、lxml、代码编辑器
第 1 步:搭建 Python 环境
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandas第 2 步:检查 SuperPages 的 HTML 结构
在 SuperPages 的结果页打开开发者工具(F12),确认商家名称、地址、电话、网站和详情页链接对应的 CSS 选择器。要注意:HTML 结构可能随时变化,而且不会提前通知,这意味着你的选择器随时可能失效。
第 3 步:编写列表抓取脚本并处理分页
下面是一个简化示例。重要提醒:在我的测试中,直接请求 SuperPages 会返回 Cloudflare 的 “Attention Required” 拦截页。一个简单的 Requests 脚本在大规模运行时可能会失败——你可能需要浏览器会话上下文、限速、重试,或者使用授权替代方案。
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("被拦截了。请放慢速度,或切换到浏览器/云端抓取。")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)第 4 步:抓取详情页做数据补全
你需要再写一个函数,访问每个详情页 URL,提取营业时间、邮箱、描述和评论。这意味着限速、错误处理,以及可能需要代理——这些都得你自己负责。
第 5 步:把数据保存成 CSV 或 JSON
可以使用 Python 的 csv 或 json 模块。同时你还需要自己写去重、清洗和导出逻辑。
常见坑点:
- SuperPages 可能会用 Cloudflare 或类似的反爬系统拦截请求(我在测试中已经确认过)。
- 这里的选择器故意写得比较宽泛,因为 SuperPages 的页面结构可能会变化。
- 不要默认搜索结果页里有邮箱,它们几乎不会直接展示。
- 真正用于生产的爬虫,需要检查 robots/TOS、限速、重试/退避、结构化日志和错误捕获。
如果你想更深入了解 Python 抓取,可以看看我们关于 Python 网页抓取或 BeautifulSoup 教程的指南。
从原始数据到真实线索:完整流程(抓取 → 清洗 → 验证 → 导入 CRM)
很多抓取教程到这里就结束了,但真正的价值才刚开始。抓取只是原料,把它变成可用的潜在客户名单,还需要几个步骤。
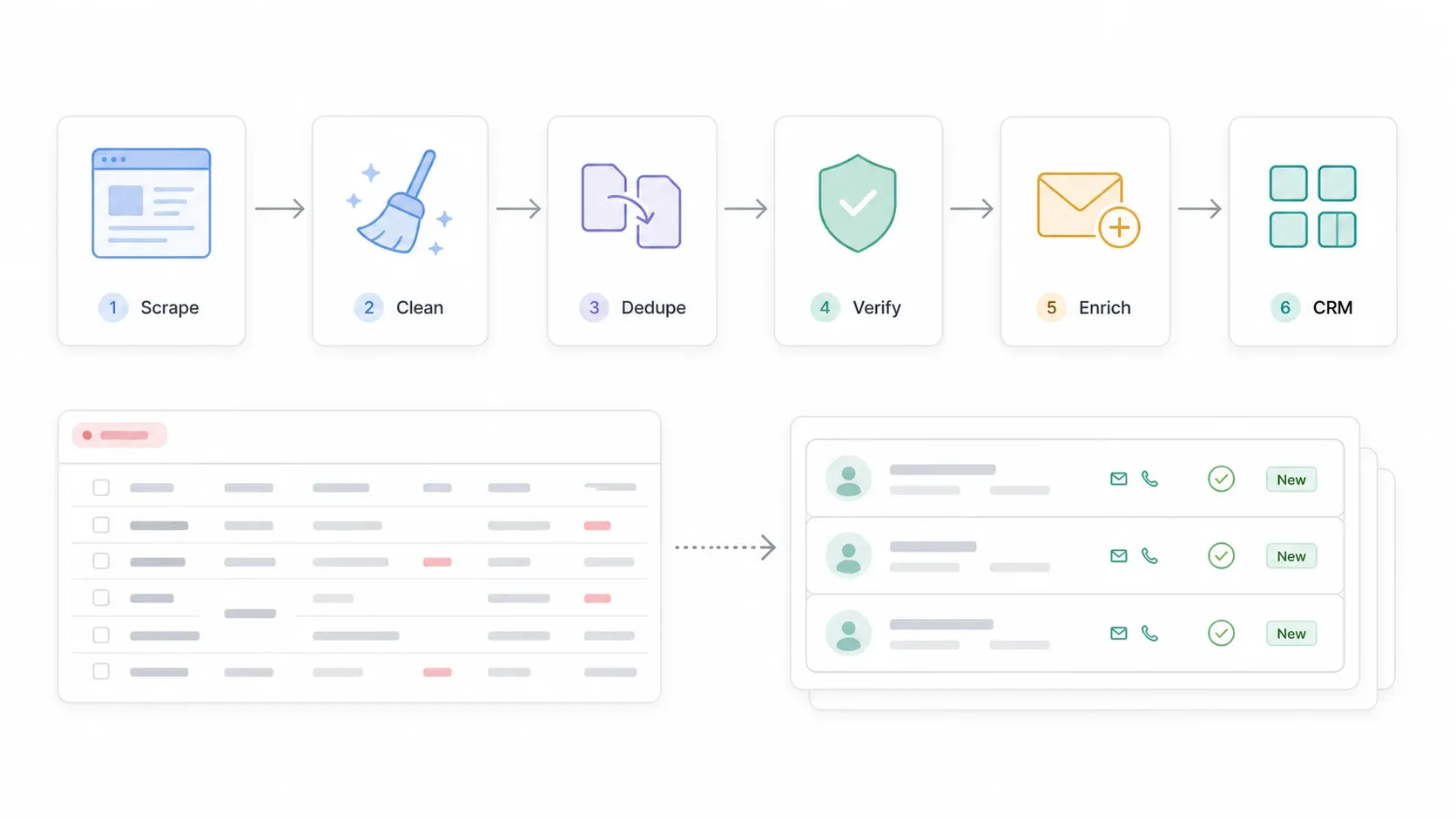
完整流程如下:
SuperPages 搜索 → 抓取列表 → 抓取详情页/网站 → 导出到 Google Sheets 或 CSV → 清洗电话、地址、分类 → 去重 → 验证邮箱/电话 → 补全缺失联系人 → 导入 CRM → 合规外联
去重:移除重复商家
SuperPages 经常会把同一家商家放在多个分类里。如果你同时抓了同一城市的 “plumbers” 和 “drain cleaning”,就很容易出现重复。
- 主去重键:标准化电话 + 标准化街道地址。
- 次级键:域名 + 城市。
- 兜底:商家名称 + 邮编(连锁品牌需要人工复核)。
在 Google Sheets 中,可以用 =UNIQUE(A:H) 处理完全一致的整行;也可以创建一个辅助列,比如 =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")),用来捕捉近似重复项。在 Excel 中,可以使用“数据 > 删除重复项”。
数据清洗:标准化电话、地址和格式
- 将电话号码格式化为 E.164(美国格式:+1 后接 10 位数字)。这是大多数 CRM 和外呼系统最常见的格式。你可以在 Thunderbit 中用 Field AI Prompt 在抓取时自动格式化。
- 标准化地址:展开缩写、补全缺失的邮编,必要时拆分为街道/城市/州/邮编列。
- 去掉 URL 中的 HTML 残留、多余空格和追踪参数。
- 添加
source_directory、source_url和scraped_at列,方便追溯。
外联前先验证邮箱和电话
不要把刚抓来的邮箱全部一股脑发冷邮件。验证可以保护你的发件人信誉,并保持较低的退信率。
- 邮箱验证:ZeroBounce(起价约 39 美元/2000 credits,外加每月 100 个免费 credits)或 Bouncer(8 美元/1000 credits,credits 永不过期)都是不错的选择。
- 电话校验:Twilio Lookup 提供格式化和验证功能,基础查询免费;来电显示识别每次请求 0.01 美元。
- Thunderbit 的免费 Email Extractor 和 Phone Number Extractor 可以补到列表页遗漏的联系方式。
补全:当 SuperPages 没有邮箱时怎么办?
很多 SuperPages 商家信息根本不会显示邮箱,尤其是搜索结果页。可以这样做:
- 抓取商家自己网站的 Contact、About 或页脚页面。Thunderbit 的子页面抓取或 Email Extractor 可以批量完成。
- 使用 Apollo、BetterContact、Icypeas 或 Prospeo 这类补全工具。先提醒一下:对小型本地商家(比如两个人的小管道店、个人牙医),大型 B2B 数据库经常会抓不到内容。对这类场景来说,优先从官网提取通常更有效。
- 组合多个目录。把 SuperPages、Yellow Pages 和 Google Maps 同一分类/城市的数据抓下来,再合并去重。这样交叉比对后,记录会更完整。
如果你曾经把本地 SMB 名单丢进 Apollo,结果大部分都是空白,你不是一个人。这也是为什么对这类受众来说,“先官网再补全”的方法更重要。
导入 CRM:把线索放进 HubSpot、Salesforce 或 Google Sheets
- HubSpot:进入 Data Management > Data Integration > Import data > Quick import(仅联系人)。上传你的
.csv或.xlsx,HubSpot 的导入指南会教你如何映射字段。 - Salesforce:使用 Data Import Wizard。准备 CSV,映射源字段和 Salesforce 字段,然后执行导入。
- Google Sheets / Airtable / Notion:Thunderbit 可以直接导出到这三个工具,不需要中间再转 CSV。
提示:导入前先把抓取字段映射到 CRM 字段。花几分钟做映射,后面能省下几个小时的手工整理。
SuperPages 和其他本地商业目录对比:去哪里找最好的线索?
SuperPages 是一个很好的起点,但它不是唯一值得抓取的目录。下面是它和其他平台的对比:
| 目录 | 线索量 | 可用字段 | 数据新鲜度 | 反爬难度 | 最适合 |
|---|---|---|---|---|---|
| SuperPages | 很大(以美国为主) | 名称、电话、地址、网站、分类、评分 | 中等 | 中等 | 家庭服务、承包商、中小企业 |
| Yellow Pages | 很大(以美国为主) | 与 SuperPages 类似 | 中等 | 中等 | 通用本地企业外联 |
| Google Maps | 非常大(全球) | 名称、电话、地址、网站、评论、营业时间、照片 | 高(可由商家更新) | 高(反机器人较强) | 最新的本地数据 |
| Yelp | 很大(以美国为主) | 名称、电话、地址、评论、价格区间 | 高 | 高 | 餐饮、零售、服务型企业 |
| Manta | 中等 | 名称、电话、地址、营收估算、员工数 | 中等 | 低 | B2B 开发(营收/员工数据) |
| BBB | 中等 | 名称、电话、地址、认证信息、投诉记录 | 中等 | 低 | 更可信、经过验证的企业 |
来源:SuperPages 首页、VLDB SuperPages 论文、Google Places API 文档、Yelp Places API 文档、Manta 首页、BBB 指南。
Thunderbit 可以在这些平台上通用——包括 Google Maps 和 SuperPages 这类热门网站的 Instant Template——这样你就可以用同一套流程处理多个来源,并把线索名单合并起来。根据我的经验,最好的做法往往是针对同一分类/城市抓取两到三个目录,然后去重。重叠部分能补缺口,让你得到更完整的全貌。
想了解更多其他目录的抓取方法,可以看看我们的 、 和 指南。
抓取 SuperPages 潜在客户的法律与合规建议
我不是律师,下面也不是法律意见——但我在这个领域待得够久,知道忽视合规通常是最快翻车的方式。下面给你一个实用版说明。
公开企业数据 vs. 个人数据
商家信息——公司名称、企业电话、公司地址、企业网站——通常会被视为公开的商业数据。这与 GDPR 或 CCPA 下的个人消费者数据不同。但“公开”并不等于“完全没规则”。一定要检查网站的服务条款。
SuperPages 的使用条款(2019 年 7 月更新)包含一条“禁止数据挖掘”的规定:未经 Thryv 事先同意,用户不得使用机器人、爬虫、蜘蛛程序或类似工具收集或提取数据。本文讨论的是方法和工作流,但在大规模抓取之前,你应该先查看这些条款,并在需要时获得授权。
外联合规:CAN-SPAM 和 TCPA 基础要求
如果你打算把抓到的邮箱用于冷邮件外联,FTC 的 CAN-SPAM 指南要求你:
- 不得使用虚假或误导性的邮件头
- 不得使用欺骗性的主题行
- 在需要时必须明确标识这是一封广告邮件
- 必须提供有效的实体邮寄地址
- 必须提供清晰可用的退订方式,并及时处理退订请求
如果你要用抓到的电话号码进行冷呼叫,请先检查 National Do Not Call Registry,并遵守 TCPA 规则——尤其是在自动拨号、预录语音和短信方面。FTC 还在 2024 年宣布了新变化,以加强对欺骗性 B2B 电话营销和 AI 诈骗电话的保护。
快速合规清单
- ✅ 只抓取公开展示的企业数据
- ✅ 查看 SuperPages 的使用条款,并在需要时取得授权
- ✅ 外联前先验证联系人
- ✅ 邮件中提供退订方式
- ✅ 遵守 robots.txt 和限速规则
- ✅ 维护 DNC 和邮件屏蔽名单
- ⚠️ 避免抓取个人/消费者数据
- ⚠️ 不要未经法律审核就转售原始抓取数据
选择你的方法,开始搭建潜在客户名单
抓取 SuperPages 潜在客户,不只是从网页上提取几行数据那么简单。真正的价值来自完整流程:抓取、清洗、去重、验证、补全、导入,以及合规外联。
快速总结一下:
- Thunderbit 是销售团队、代理公司和非开发者最快的方式。两步抓取,一步子页面补全,还能免费导出到 Google Sheets、Airtable、Notion 或 Excel。现在就可以免费试用。
- Octoparse 是一个不错的可视化工作流工具,适合想要更多配置控制的半技术用户。
- Python 给开发者最大的灵活性——但也带来了维护成本、反封锁麻烦,而且没有内置补全能力。
- 别忘了:同样的工作流也适用于 Yellow Pages、Google Maps、Yelp、Manta 和 BBB。多抓几个来源、合并、去重,你就能得到最完整的本地线索名单。
如果你想看看 Thunderbit 的实际效果,可以去我们的 看演示,或者查看 看看哪种方案适合你的团队。
现在就把这些目录页面变成销售管道吧——愿你的电话永远格式正确,愿你的邮箱永远验证通过。
常见问题
抓取 SuperPages 潜在客户合法吗?
抓取公开可访问的商业目录数据用于 B2B 调研,在行业里很常见,但 SuperPages 的使用条款禁止在未经 Thryv 事先同意的情况下进行数据挖掘。务必先查看网站条款,在需要时获取授权,并遵守 CAN-SPAM 和 TCPA 这类外联法规。本文介绍的方法和工作流仅供学习参考——如何合规使用,责任在你。
我能从 SuperPages 获取哪些数据?
一次典型抓取通常能拿到商家名称、电话、地址、网站、分类、评分、营业时间和描述。邮箱通常不会直接出现在搜索结果页里——你一般需要进入商家详情页,或者访问企业自己的网站(借助子页面抓取或邮箱提取器)才能找到。
不会写代码,也能抓 SuperPages 吗?
可以。像 Thunderbit(AI Chrome 扩展)和 Octoparse(可视化爬虫)这样的工具,都可以让你不写一行代码就抓取 SuperPages。Thunderbit 是最快的方案——安装扩展、打开 SuperPages 搜索页、点击 “AI Suggest Fields”,然后点 “Scrape” 就行。
抓取 SuperPages 时,分页怎么处理?
Thunderbit 会自动处理分页——它能识别 “Next” 按钮或无限滚动并持续抓取。Octoparse 需要你在工作流中手动配置分页步骤。Python 则需要自己写循环逻辑(递增页码、判断最后一页)。
怎么从 SuperPages 列表里拿到邮箱?
大多数 SuperPages 列表在搜索结果页都不会显示邮箱。你可以用 Thunderbit 的子页面抓取去访问每个详情页,或者用免费的 Email Extractor 去抓商家官网。剩下的缺口,还可以试试 Apollo、BetterContact 或 Prospeo 这类补全工具——不过对于小型本地商家来说,通常还是“先官网后补全”的方式更有效。
了解更多