Flickr 爬虫
Được các chuyên gia tại những công ty hàng đầu tin dùng














Trích xuất dữ liệu Flickr chỉ trong hai cú nhấp chuột
Thunderbit đơn giản hóa việc lấy dữ liệu từ Flickr, không cần viết code.
Hai cú nhấp chuột để lấy dữ liệu Flickr
Việc sao chép thủ công tiêu đề ảnh, tên người dùng tác giả hoặc ngày tải lên từ Flickr vừa tốn thời gian vừa dễ nhầm lẫn. Thunderbit giúp bạn bỏ qua hoàn toàn bước copy-paste. Chỉ cần trỏ vào dữ liệu bạn muốn, chẳng hạn mô tả ảnh hoặc loại giấy phép, rồi AI của chúng tôi sẽ tự xử lý phần còn lại. Chỉ với 2 cú nhấp chuột, bạn đã có thể trích xuất dữ liệu mà không cần viết một dòng code nào.
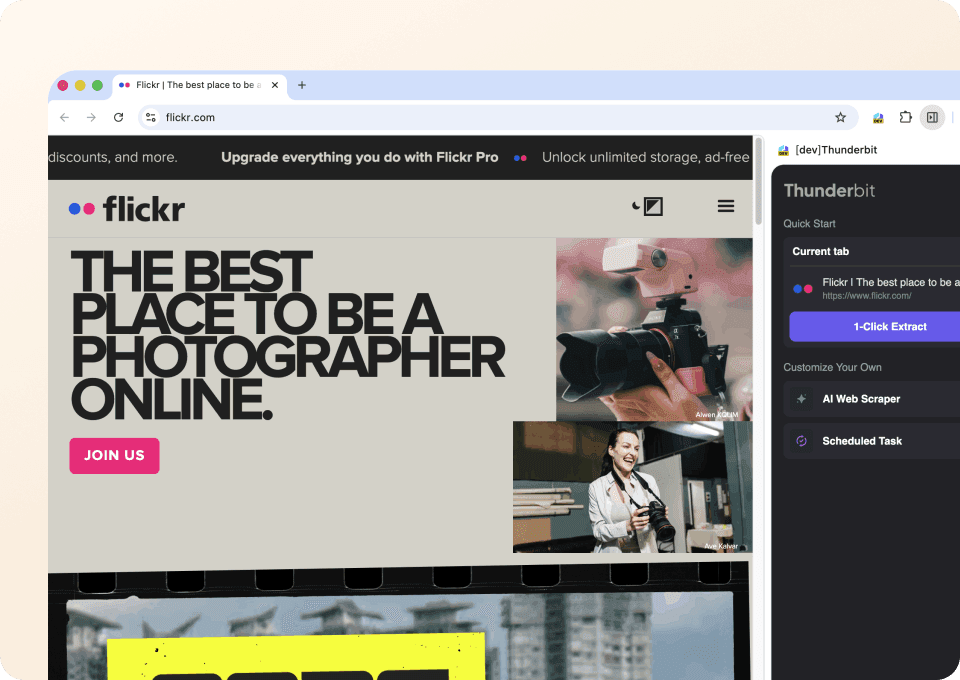
Lấy đầy đủ chi tiết ảnh Flickr
Trang tìm kiếm hoặc thư viện trên Flickr chỉ hiển thị thông tin cơ bản. Để có bức tranh đầy đủ, bạn cần dữ liệu từ từng trang ảnh riêng lẻ. Thunderbit có thể tự động truy cập từng trang con được liên kết, lấy mô tả, thẻ và các thông tin khác, rồi thêm chúng thành các cột mới trong file xuất dữ liệu. Không còn phải tự nhấp vào từng trang rồi sao chép thủ công nữa.
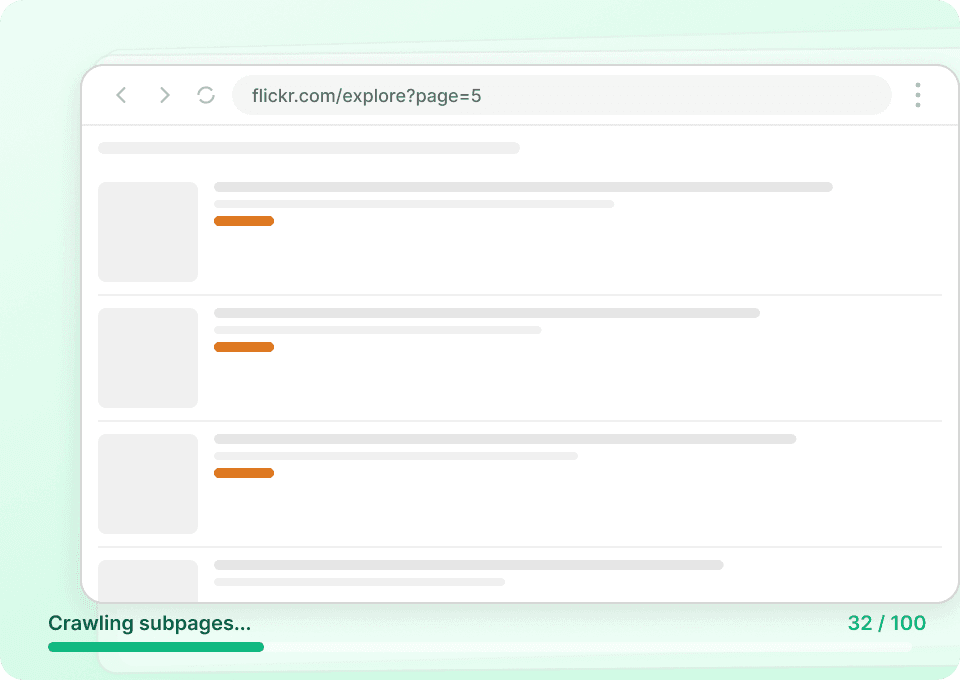
Trích xuất dữ liệu Flickr hàng loạt
Scrape Flickr từng ảnh một vừa chậm vừa kém hiệu quả. Thay vì phải tự mở từng trang và lấy dữ liệu thủ công, Thunderbit cho phép bạn nhập nhiều URL Flickr cùng lúc. Sau đó, công cụ sẽ lần lượt truy cập từng trang, trích xuất tiêu đề ảnh, tên người dùng tác giả và các trường dữ liệu khác, rồi tổng hợp lại cho bạn.

Vì sao Thunderbit khác với các flickr scrapers truyền thống?
Lấy dữ liệu từ Flickr mà không phải đau đầu vì cách scrape truyền thống.
Các trình scrape truyền thống
Cách làm cũThunderbit AI
Cách làm thông minh hơnĐừng chỉ nghe chúng tôi nói
Xem người dùng nói gì về Thunderbit.






Câu hỏi thường gặp
Liên quan trường hợp sử dụng
Khám phá thêm các trường hợp sử dụng của web scraper Thunderbit.

PubMed Scraper
PubMed Scraper của Thunderbit giúp bạn trích xuất dữ liệu có cấu trúc từ trang kết quả tìm kiếm và trang bài viết trên PubMed bằng AI. Thu thập các nghiên cứu y khoa đang thịnh hành, bằng chứng thử nghiệm lâm sàng, tóm tắt (abstract), tác giả, cơ quan/đơn vị (affiliations), ngày xuất bản và liên kết, rồi xuất sang Excel, Google Sheets, Airtable hoặc Notion.
Tìm hiểu thêm ->
Công cụ thu thập dữ liệu Trustpilot
Biến các trang Trustpilot thành một bảng tính gọn gàng với đánh giá, xếp hạng và tên người đánh giá. Chúng tôi đọc từng trang thay bạn, nên bạn không cần viết code hay copy-paste.
Tìm hiểu thêm ->
Trình quét số điện thoại Craigslist
Craigslist Phone Number Scraper của Thunderbit giúp bạn trích xuất số điện thoại và thông tin chi tiết của tin đăng từ kết quả tìm kiếm Craigslist bằng AI. Quét danh sách, mở từng bài đăng để lấy thông tin liên hệ và các trường bổ sung, sau đó xuất sang Excel, Google Sheets, Airtable, Notion, CSV hoặc JSON.
Tìm hiểu thêm ->
Steam Scraper
Chỉ với vài cú nhấp chuột, bạn có thể lấy tên game, giá bán và tỷ lệ đánh giá người dùng từ Steam mà không cần biết lập trình.
Tìm hiểu thêm ->
UNIQLO Scraper
Thu thập dữ liệu sản phẩm Uniqlo như tên, giá và các size còn hàng chỉ với 2 cú nhấp chuột, nhờ tiện ích Chrome của Thunderbit.
Tìm hiểu thêm ->
Công cụ thu thập dữ liệu Trivago
Thu thập tên khách sạn, giá và xếp hạng từ Trivago chỉ với vài cú nhấp — không cần lập trình hay thiết lập.
Tìm hiểu thêm ->Sẵn sàng tăng tốc trích xuất dữ liệu chưa?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Dùng thử miễn phí với tín dụng không giới hạn cho 8 trang web.