
Nói thật nhé: web là một nơi rất, rất hỗn độn. Mỗi ngày, tôi cứ có cảm giác như mình đang đứng trước một vòi nước kỹ thuật số khổng lồ — tin tức, bài đánh giá, danh sách sản phẩm, tweet, giao dịch bất động sản, đủ cả — tất cả tuôn ra thành một dòng lộn xộn, không có cấu trúc. Và nếu bạn đang điều hành doanh nghiệp, cố gắng hiểu mớ hỗn độn này chẳng khác nào đi tìm kim trong đống rơm… mà đống rơm còn đang cháy. (Tôi từng trải qua rồi. Không hề vui chút nào.)
Nhưng điều đáng nói là: ẩn sau mớ dữ liệu trực tuyến lộn xộn đó là vàng ròng — những insight có thể thúc đẩy doanh số, giúp bạn vượt mặt đối thủ và tự động hóa những việc nhàm chán mà chẳng ai muốn làm. Đó chính là lúc thu thập dữ liệu web phát huy tác dụng. Với đúng công cụ, bạn có thể biến núi dữ liệu web phi cấu trúc thành những bảng tính gọn gàng, có thể hành động ngay, sẵn sàng cho bước đi lớn tiếp theo. Và với tư cách là người đã làm việc nhiều năm trong SaaS và tự động hóa, tôi có thể nói thế này: thu thập dữ liệu web giờ không còn chỉ dành cho lập trình viên nữa. Nó dành cho bất kỳ ai muốn làm việc thông minh hơn, chứ không phải vất vả hơn.
Ý nghĩa của Web Scraping: Biến hỗn loạn trực tuyến thành dữ liệu có thể dùng được

Vậy chính xác thì web scraping là gì? Bỏ qua thuật ngữ chuyên môn đi và nói thẳng cho dễ hiểu: web scraping là quá trình dùng phần mềm để trích xuất thông tin cụ thể từ website rồi chuyển nó sang định dạng có cấu trúc — như Excel, Google Sheets hoặc cơ sở dữ liệu. Hãy tưởng tượng có một trợ lý kỹ thuật số cần mẫn, ngày đêm sao chép đúng thông tin bạn cần từ hàng nghìn trang web và sắp xếp lại cho bạn. Đó chính là web scraping, hiểu đơn giản là vậy.
Bạn cũng có thể nghe người ta nhắc đến “data scraping”. Điểm khác nhau là thế này: data scraping là khái niệm rộng, chỉ việc lấy dữ liệu từ bất kỳ nguồn nào (website, PDF, hình ảnh, v.v.). Web scraping thì cụ thể là trích xuất dữ liệu từ các website trên internet. Nói cách khác, mọi web scraping đều là data scraping, nhưng không phải mọi data scraping đều là web scraping. (Giống như mọi hình vuông đều là hình chữ nhật, nhưng không phải hình chữ nhật nào cũng là hình vuông.)
Nếu muốn một định nghĩa trang trọng hơn, web scraping là “data scraping được dùng để trích xuất dữ liệu từ website” (Wikipedia). Nhưng trong thực tế, nó chỉ là tự động hóa cho việc nghiên cứu trực tuyến — không còn phải copy-paste đến rã cả ngón tay nữa.
Vì sao Web Scraping quan trọng với doanh nghiệp hiện đại
Data Scraping là gì và cách thực hiện trong năm 2025 Get Started Free
Hãy nói về chuyện kinh doanh. Vì sao web scraping lại quan trọng đến vậy lúc này? Bởi vì internet đang ngập trong dữ liệu phi cấu trúc — khoảng 80%–90% dữ liệu mới đều là phi cấu trúc — từ bài đăng mạng xã hội đến danh sách sản phẩm. IDC dự đoán tổng حجم dữ liệu toàn cầu sẽ đạt 175 zettabyte vào năm 2025 — đúng là một con số khổng lồ.
Điều đáng chú ý hơn: 60–80% thời gian của nhân viên bị lãng phí chỉ để tìm và chuẩn bị dữ liệu, chứ không phải để phân tích nó. Giống như thuê một đầu bếp nhưng bắt họ cả ngày đi gọt khoai tây thay vì nấu ăn. Michael Shulman, Head of Machine Learning tại Kensho, từng nói: “Vì phần lớn dữ liệu trên thế giới là phi cấu trúc, nên khả năng phân tích và hành động dựa trên nó mở ra một cơ hội rất lớn.”
Web scraping đảo ngược hoàn toàn cách làm truyền thống. Thay vì vật lộn với website bằng tay, bạn tự động hóa toàn bộ quy trình — thu thập dữ liệu trực tiếp, theo thời gian thực, từ bất kỳ đâu trên web. Không ngạc nhiên khi 71% công ty dịch vụ tài chính và hơn một nửa doanh nghiệp bán lẻ/thương mại điện tử đã dùng web scraping cho dữ liệu bên ngoài. Dữ liệu không chỉ là dầu mỏ mới — nó là tiền tệ mới, và web scraping là cách để bạn đổi nó thành giá trị.
Các trường hợp sử dụng Web Scraping phổ biến trong nhiều ngành
Web scraping không phải là công cụ chỉ làm được một việc. Nó được dùng ở khắp nơi — từ đội sales đến nhà phân tích bất động sản. Dưới đây là vài ví dụ thực tế:
- Lead bán hàng & tìm kiếm khách hàng B2B: Scrape các trang tuyển dụng hoặc danh bạ doanh nghiệp để xây dựng danh sách lead mới, đúng mục tiêu. Một công ty SaaS đã thấy số lead đủ điều kiện tăng 40% nhờ tự động hóa quy trình này.
- Giám sát giá và sản phẩm trong thương mại điện tử: Nhà bán lẻ scrape website đối thủ để lấy giá và tình trạng tồn kho, rồi điều chỉnh giá của chính mình gần như theo thời gian thực. Kết quả? Doanh số tăng và khách hàng trung thành hơn.
- Danh sách bất động sản: Các nền tảng tổng hợp và nhà đầu tư scrape website nhà đất để lấy tin đăng, giá cả và xu hướng — giúp họ phát hiện tài sản định giá thấp và khu vực tiềm năng (nghiên cứu điển hình).
- Du lịch & khách sạn: Scrape website hãng bay và khách sạn để lấy giá vé, tình trạng phòng và đánh giá — phục vụ cho công cụ so sánh giá và phân tích cảm xúc.
- Tài chính & đầu tư: Quỹ phòng hộ scrape mọi thứ, từ hồ sơ nộp cho SEC đến đánh giá sản phẩm, để săn tín hiệu dữ liệu thay thế. 71% công ty tài chính hiện đã dùng web scraping trong hoạt động của họ.
Tóm lại: nếu trên web có dữ liệu giá trị, thì luôn có cách để scrape nó và biến nó thành giá trị kinh doanh.
Web Scraping hoạt động như thế nào: Từ website đến bảng tính
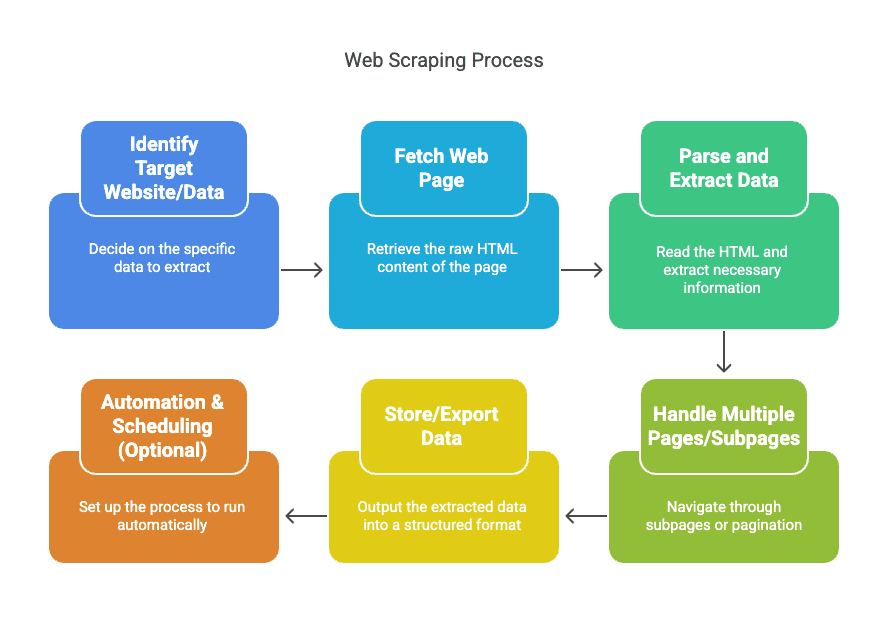
Hãy làm rõ quy trình này. Web scraping không phải phép màu — nó là một pipeline. Cách thường diễn ra như sau:
- Xác định website/dữ liệu mục tiêu: Quyết định bạn muốn lấy gì (ví dụ: tên sản phẩm và giá từ xyz).
- Tải trang web: Công cụ scraper lấy HTML thô, giống như trình duyệt của bạn làm.
- Phân tích và trích xuất dữ liệu: Công cụ đọc HTML rồi lấy ra thông tin bạn cần (như giá, tên, đánh giá).
- Xử lý nhiều trang/trang con: Scraper có thể tự theo liên kết sang trang con hoặc bấm qua phân trang.
- Lưu/xuất dữ liệu: Xuất toàn bộ sang định dạng có cấu trúc — CSV, Excel, Google Sheets hoặc cơ sở dữ liệu.
- Tự động hóa & lập lịch (tùy chọn): Thiết lập để chạy theo lịch, giúp dữ liệu luôn mới mà bạn chẳng cần động tay.
Làm thủ công thì sẽ mất rất nhiều thời gian (và tốn cực nhiều cà phê). Với web scraping, bạn tự động hóa toàn bộ quy trình — biến hàng giờ lao động tay chân thành vài phút.
Vai trò của công cụ scraping và dịch vụ web scraping
Bây giờ nói về công cụ. Có rất nhiều lựa chọn ngoài kia — từ tiện ích mở rộng trình duyệt, nền tảng đám mây đến phần mềm desktop. Tóm tắt nhanh như sau:
- Tiện ích mở rộng trình duyệt: Công cụ nhẹ, bấm là dùng, chạy ngay trong trình duyệt của bạn. Rất hợp cho những tác vụ nhanh và đơn giản.
- Phần mềm desktop: Ứng dụng đầy đủ tính năng với giao diện trực quan — xử lý đăng nhập, cuộn vô hạn và nhiều thứ khác.
- Nền tảng đám mây: Chạy scraper trên máy chủ từ xa — lý tưởng cho các tác vụ quy mô lớn, chạy liên tục.
- Mã tùy chỉnh: Dành cho người rành kỹ thuật — tự viết script để có mức kiểm soát tối đa (nhưng cũng dễ đau đầu nhất).
Vì sao nên dùng những công cụ này thay vì copy-paste? Ba lý do: tốc độ, quy mô và độ tin cậy. Một scraper tốt có thể xử lý hàng nghìn trang trong khoảng thời gian bạn chỉ vừa kịp quay lò vi sóng. Thêm nữa, bạn nhận được dữ liệu sạch, có cấu trúc — không lỗi gõ, không bỏ sót chi tiết.
Dữ liệu có cấu trúc vs. phi cấu trúc: Vì sao Web Scraping là thiết yếu
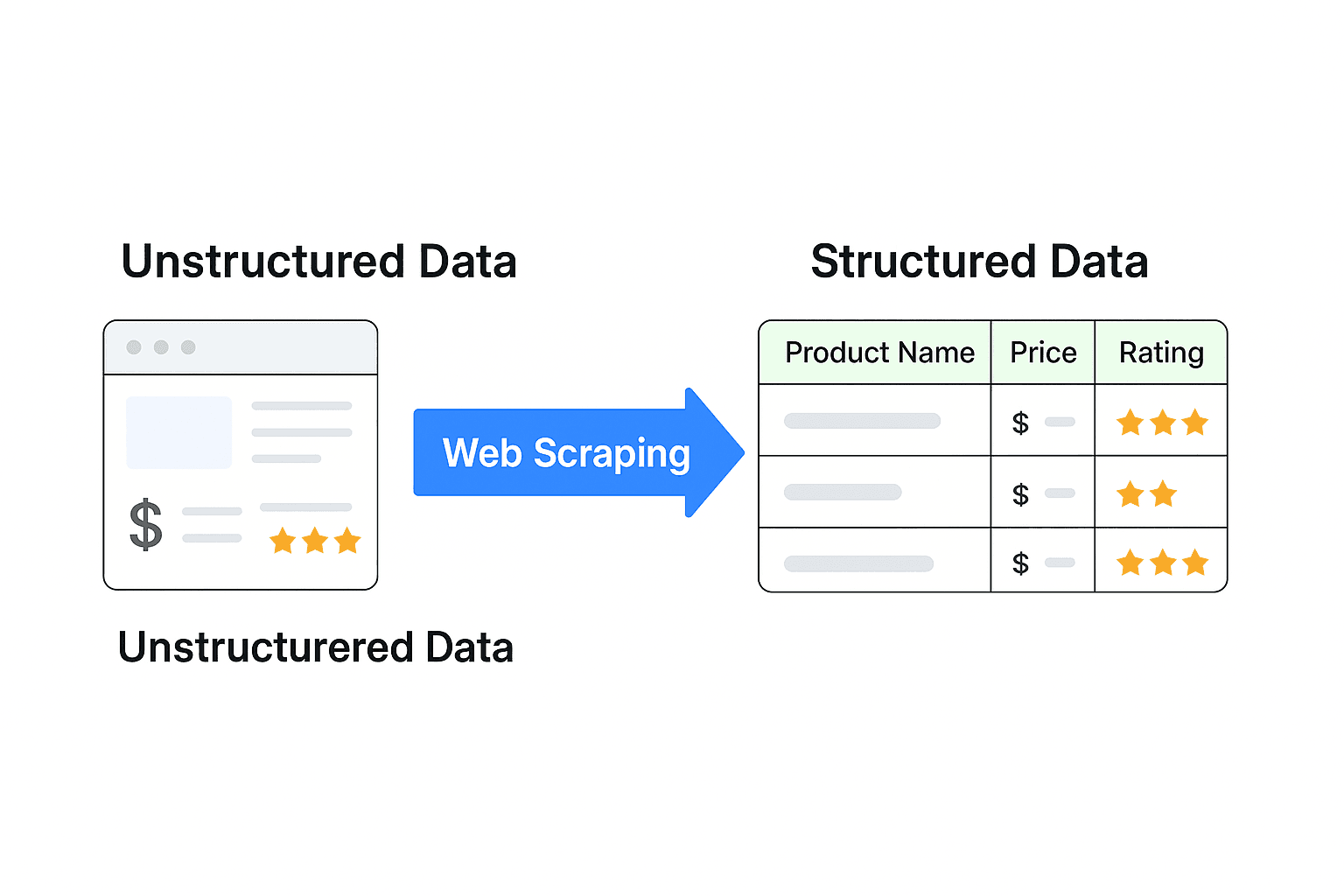
Đây là trọng tâm của vấn đề: phần lớn dữ liệu web đều là phi cấu trúc. Nó được thiết kế cho con người, không phải máy móc. Hãy nghĩ đến một trang sản phẩm với hình ảnh, đánh giá và giá cả bị trộn lẫn với nhau. Bạn không thể cứ thế đưa nó vào Excel rồi bắt đầu phân tích.
Dữ liệu có cấu trúc — như một bảng tính với các cột “Tên sản phẩm”, “Giá” và “Đánh giá” — mới là thứ vận hành phân tích, dashboard và việc ra quyết định. Web scraping là cây cầu biến nội dung web rối rắm thành thông tin sạch và có thể hành động.
Và đây là một con số khá sốc: chỉ khoảng 50% dữ liệu phi cấu trúc của một tổ chức được phân tích. Phần còn lại? Tiềm năng bị lãng phí. Web scraping giúp bạn khai thác giá trị đó.
Các loại giải pháp Web Scraping: Code, không cần code và công cụ dùng AI
Hãy chia nhỏ các lựa chọn của bạn:
- Giải pháp dựa trên code: Viết script bằng Python (dùng các thư viện như BeautifulSoup hoặc Scrapy), JavaScript hoặc R. Linh hoạt tối đa, nhưng bạn sẽ cần kỹ năng lập trình — và cả sự kiên nhẫn khi website thay đổi khiến script bị hỏng.
- Giải pháp không cần code: Công cụ trực quan (tiện ích mở rộng trình duyệt, ứng dụng desktop, nền tảng đám mây) cho phép bạn thiết lập scrape chỉ bằng vài cú click, không cần code. Rất hợp cho người dùng doanh nghiệp chỉ muốn có kết quả.
- Scraper dùng AI: “Tân binh” của thị trường. Các công cụ này dùng AI để tự động nhận diện cần scrape gì, thích ứng với thay đổi của website, thậm chí trích xuất dữ liệu từ PDF hoặc hình ảnh. Thunderbit là một ví dụ điển hình.
Là người đã trải qua cả hai phía — viết code và dùng công cụ không cần code — tôi có thể nói rằng: với hầu hết người dùng doanh nghiệp, scraper không cần code hoặc dùng AI là lựa chọn tốt nhất. Tại sao phải vật lộn với code khi bạn có thể đạt kết quả tương tự chỉ trong 2 cú click?
Những tính năng cần chú ý khi chọn công cụ scraping
Trích xuất dữ liệu từ bất kỳ website nào bằng AI Get Started Free
Không phải scraper nào cũng như nhau. Đây là những gì tôi luôn ưu tiên xem xét (và cũng là điều tôi khuyên mọi đội ngũ kinh doanh nên có):
- Dễ sử dụng: Bạn có thể bắt đầu mà không cần đọc một cuốn hướng dẫn dài như tiểu thuyết không?
- AI phát hiện trường dữ liệu: Công cụ có tự đề xuất nên scrape những gì không?
- Hỗ trợ trang con & phân trang: Có xử lý được danh sách nhiều trang và đi sâu vào các trang chi tiết không?
- Tùy chọn xuất dữ liệu: Có thể đẩy dữ liệu thẳng sang Excel, Google Sheets, Airtable hoặc Notion không?
- Lập lịch: Có thể thiết lập một lần rồi quên đi — tự động scrape theo lịch của bạn không?
- Nhận diện kiểu dữ liệu: Có nhận ra email, số điện thoại, hình ảnh và nhiều loại khác không?
- Mẫu cho các website phổ biến: Scrape 1 click cho Amazon, Zillow, Instagram, v.v.
Với các đội sales, thương mại điện tử và vận hành, những tính năng này đồng nghĩa với ít việc thủ công hơn, ít lỗi hơn và nhiều thời gian hơn để làm những việc thực sự quan trọng.
Thunderbit: AI Web Scraper đơn giản nhất cho mọi người
Được rồi, cho phép tôi quảng cáo một chút — nhưng chỉ vì tôi thực sự tin vào thứ chúng tôi đang xây dựng tại Thunderbit.
Thunderbit là một tiện ích mở rộng Chrome web scraper dùng AI, được thiết kế cho người dùng doanh nghiệp chứ không chỉ cho lập trình viên. Đây là những điểm làm nó khác biệt:
- AI Suggest Fields: Chỉ cần bấm “AI Suggest Fields”, Thunderbit sẽ đọc trang, đề xuất các cột tốt nhất và tự thiết lập mọi thứ cho bạn. Không còn phải đoán mò hay loay hoay với selector nữa.
- Scraping 2 click: Mở trang, để AI đề xuất trường dữ liệu, rồi bấm “Scrape”. Xong. Đơn giản đến thế thôi.
- Trang con & phân trang: AI của Thunderbit tự động phát hiện và scrape trang con cùng danh sách có phân trang — không cần thiết lập thêm.
- Scheduled Scraper: Muốn theo dõi giá hoặc lead mỗi ngày? Chỉ cần mô tả lịch (“mỗi sáng lúc 9 giờ”), thêm URL, rồi Thunderbit sẽ lo phần còn lại.
- Xuất dữ liệu tức thì: Gửi dữ liệu thẳng sang Excel, Google Sheets, Airtable hoặc Notion — không phí ẩn, không thủ tục rườm rà.
- Bộ trích xuất chuyên biệt: Trích xuất email, số điện thoại và hình ảnh chỉ với 1 click — hoàn toàn miễn phí.
- AI Autofill: Dùng AI để điền biểu mẫu trực tuyến và tự động hóa quy trình làm việc, không chỉ để scrape dữ liệu.
- Phân tích tài liệu & hình ảnh: Tải lên PDF, Word, Excel hoặc hình ảnh — AI của Thunderbit sẽ trích xuất bảng và cấu trúc lại dữ liệu cho bạn.
Và đúng vậy, có gói miễn phí (scrape tối đa 6 trang), nên bạn có thể thử mà gần như không có rủi ro nào. Nếu cần nhiều hơn, các gói trả phí bắt đầu từ 15 USD/tháng cho 500 dòng — rẻ hơn rất nhiều so với đa số công cụ doanh nghiệp.
Đừng chỉ nghe tôi nói. Người dùng đã chia sẻ những câu như: “Thunderbit đúng là web scraper dễ dùng nhất mà tôi từng thử. Tôi đã chuyển từ việc mất hàng giờ viết script sang scrape cả website chỉ trong vài phút — với vài cú click.” Đó là kiểu phản hồi khiến mọi đêm coding muộn trở nên xứng đáng.
Muốn xem Thunderbit hoạt động thế nào? Hãy xem kênh YouTube của chúng tôi hoặc đọc thêm trên Thunderbit Blog.
Dùng thử miễn phí tiện ích mở rộng Thunderbit Chrome
Các thực hành tốt nhất về Web Scraping cho đội ngũ không kỹ thuật
Web scraping rất mạnh mẽ, nhưng cẩn thận một chút sẽ giúp bạn đi xa hơn. Dưới đây là những lời khuyên hàng đầu của tôi để bắt đầu:
- Tôn trọng chính sách website: Luôn kiểm tra điều khoản dịch vụ và robots.txt của site. Chỉ dùng dữ liệu công khai và sử dụng nó có trách nhiệm.
- Đừng làm quá tải máy chủ: Hãy cư xử lịch sự — đừng dội quá nhiều request vào một site. Hầu hết công cụ đều cho phép đặt tốc độ crawl hoặc độ trễ.
- Bắt đầu nhỏ: Hãy test scraper trên vài trang trước. Đảm bảo bạn lấy đúng dữ liệu mình cần rồi mới mở rộng quy mô.
- Xử lý phân trang: Đừng quên scrape tất cả các trang, không chỉ trang đầu tiên.
- Kiểm tra dữ liệu: Làm sạch và rà soát kết quả — xóa bản trùng, sửa định dạng và đảm bảo không thiếu gì.
- Giữ mọi thứ có tổ chức: Ghi lại bạn đã scrape gì, vào lúc nào và từ đâu. Việc đó sẽ giúp bạn đỡ đau đầu sau này.
- Kiểm tra API: Đôi khi có một API chính thức sẽ cung cấp dữ liệu dễ hơn và đáng tin hơn so với việc scrape HTML.
- Theo dõi thay đổi: Website sẽ thay đổi. Nếu scraper ngừng hoạt động, có thể đã đến lúc cập nhật thiết lập của bạn (hoặc để AI xử lý).
- Dùng đúng công cụ: Nếu một công cụ không hiệu quả, hãy thử công cụ khác. Đừng ngại thử nghiệm.
- Giữ đạo đức: Chỉ vì bạn có thể scrape thứ gì đó không có nghĩa là lúc nào bạn nên làm vậy. Hãy tôn trọng quyền riêng tư và quyền sở hữu dữ liệu.
Nếu muốn tìm hiểu sâu hơn, hãy xem hướng dẫn của chúng tôi: Data Scraping là gì và cách thực hiện trong năm 2025.
Kết luận: Khai mở giá trị kinh doanh với Web Scraping

Tổng kết lại nhé. Web đang tràn ngập dữ liệu giá trị, nhưng phần lớn vẫn bị khóa trong các định dạng phi cấu trúc. Web scraping chính là chiếc chìa khóa mở khóa dữ liệu đó — biến hỗn loạn thành rõ ràng, và biến công việc tay chân thành tăng trưởng.
Dù bạn làm sales, thương mại điện tử, bất động sản hay vận hành, web scraping có thể giúp bạn:
- Tạo ra lead mới hơn, chất lượng hơn
- Theo dõi đối thủ và thị trường theo thời gian thực
- Tự động hóa các quy trình tẻ nhạt và tiết kiệm hàng giờ mỗi tuần
- Ra quyết định thông minh hơn, nhanh hơn và dựa trên dữ liệu
Và nhờ các công cụ hiện đại — đặc biệt là những giải pháp dùng AI như Thunderbit — bạn không cần phải là lập trình viên hay nhà khoa học dữ liệu mới bắt đầu được. Chỉ cần chọn một dự án, thử một công cụ nào đó (tiện ích Chrome Extension của chúng tôi là nơi rất đáng để bắt đầu), rồi xem bạn có thể làm được nhiều hơn bao nhiêu khi để tự động hóa gánh phần nặng.
Trong một thế giới nơi “dữ liệu là dầu mỏ mới”, web scraping chính là cái bơm của bạn. Vậy nên cứ mạnh dạn biến vòi dữ liệu trực tuyến đó thành một dòng insight ổn định, rồi nhìn doanh nghiệp của bạn phát triển.
Chúc bạn scrape vui vẻ! Và nếu có lúc nào đó bị kẹt, bạn biết tìm tôi ở đâu rồi đấy (hoặc ít nhất là biết tìm Thunderbit ở đâu).
Bắt đầu scraping với Thunderbit AI
Câu hỏi thường gặp
1. Web scraping là gì, nói đơn giản?
Web scraping là dùng phần mềm để tự động lấy dữ liệu cụ thể từ website — như giá, đánh giá hoặc tin tuyển dụng — rồi biến nó thành thứ hữu ích, chẳng hạn như bảng tính. Hãy xem nó như thuê một thực tập sinh robot làm toàn bộ việc copy-paste nhàm chán cho bạn, 24/7.
2. Tôi có cần biết lập trình để dùng không?
Giờ thì không cần nữa. Nhờ các công cụ không cần code và dùng AI như Thunderbit, bạn có thể scrape website chỉ với vài cú click — không Python, không debug, không vấn đề gì. Nếu bạn có thể lướt web, bạn cũng có thể scrape web.
3. Tôi có thể scrape những loại dữ liệu nào?
Gần như mọi thứ công khai trên mạng:
- Danh sách và giá sản phẩm
- Bất động sản
- Tin tuyển dụng
- Danh bạ doanh nghiệp
- Hồ sơ mạng xã hội
- Bảng trong PDF và hình ảnh (đúng vậy, cả những thứ đó nữa)
Nếu nó ở trên mạng và nhìn thấy được, luôn có cách để scrape nó.
4. Web scraping có hợp pháp không?
Nhìn chung là có — miễn là bạn scrape dữ liệu công khai một cách có trách nhiệm. Đừng làm quá tải máy chủ, hãy tôn trọng điều khoản dịch vụ và tránh scrape thông tin cá nhân hoặc nội dung bị khóa đăng nhập. Nếu không chắc, hãy làm theo cách có đạo đức và giữ mọi thứ sạch sẽ.
Đọc thêm
- 3 cách Web Scraping thúc đẩy tăng trưởng kinh doanh
- Nghiên cứu điển hình: Một nhà bán lẻ đã dùng scraping để tăng doanh số như thế nào
- Vì sao dữ liệu bên ngoài là tương lai của chiến lược cạnh tranh
Thử AI Web Scraper Get Started Free




