

Web scraping có bất hợp pháp không? Đó là câu hỏi triệu đô mà tôi nghe từ các founder, marketer và những người mê dữ liệu gần như mỗi tuần.
Với 51% lưu lượng internet hiện nay đến từ bot — lần đầu tiên lưu lượng tự động vượt qua hoạt động của con người — và một phần lớn trong đó là web scraping phục vụ phân tích kinh doanh, sales và huấn luyện AI, cũng không lạ khi ai cũng muốn biết ranh giới pháp lý nằm ở đâu.
Hôm nay bạn có thể đọc một tiêu đề nói rằng tòa án đã phán quyết việc thu thập dữ liệu công khai là hoàn toàn hợp lệ. Ngày hôm sau, cơ quan quản lý lại cảnh báo về việc thu thập dữ liệu "bất hợp pháp" từ mạng xã hội. Ngay cả với những người như tôi, ngày ngày xây dựng các công cụ AI web scraping tại Thunderbit, chuyện này cũng đủ rối.
Vậy web scraping có bất hợp pháp không? Câu trả lời không đơn giản là có hoặc không. Nó phụ thuộc vào dữ liệu bạn thu thập là gì, lấy từ đâu, bạn dùng dữ liệu như thế nào, và luật ở quốc gia của bạn quy định ra sao.
Trong bài phân tích chuyên sâu này, tôi sẽ bóc tách bức tranh pháp lý, gỡ bỏ vài hiểu lầm phổ biến, và chia sẻ những mẹo thực tế (kèm một vài câu chuyện “xương máu”) để bạn tuân thủ tốt hơn — dù bạn là một founder đơn lẻ hay một nhóm dữ liệu của Fortune 500.
Web scraping và pháp luật: Có một ranh giới rõ ràng không?
Nếu bạn đang mong chờ một câu trả lời gói gọn trong một câu, thì để tôi tiết kiệm thời gian cho bạn: pháp luật vẫn chưa vạch ra một ranh giới thật rõ cho web scraping.
Thay vào đó, đây là một bức tranh chắp vá của nhiều quy định chồng lấn lên nhau — quyền sở hữu dữ liệu, quyền riêng tư, sở hữu trí tuệ, luật chống hack, và cả những Điều khoản dịch vụ (ToS) nổi tiếng khó chịu. Mỗi yếu tố đều có thể liên quan, và câu trả lời thường phụ thuộc vào tình huống cụ thể của bạn (multilogin.com).
Hãy chia nhỏ thành 3 nhóm pháp lý lớn:
- Quyền sở hữu dữ liệu: Nhìn chung, các sự kiện và thông tin công khai (như giá cả hoặc số điện thoại) thường không được bảo hộ bản quyền. Nhưng nội dung sáng tạo (bài viết, hình ảnh) và cơ sở dữ liệu độc quyền có thể được bảo vệ — đặc biệt ở EU, nơi có khái niệm "quyền đối với cơ sở dữ liệu" (cliffordchance.com).
- Quyền riêng tư: Các luật riêng tư hiện đại (như GDPR ở châu Âu, PIPL ở Trung Quốc) coi dữ liệu cá nhân là một loại tài sản được quản lý — ngay cả khi nó được đăng công khai. Việc thu thập tên, email hoặc hồ sơ mạng xã hội mà không có cơ sở pháp lý có thể khiến bạn gặp rắc rối (ico.org.uk).
- Hợp đồng (Điều khoản dịch vụ): Nhiều trang web ghi rõ trong ToS rằng họ cấm scraping. Dù ToS không phải là luật, tòa án có thể xem đó là hợp đồng ràng buộc. Vi phạm có thể dẫn tới kiện tụng, và trong một số trường hợp còn có thể kích hoạt các điều luật chống hack nếu bạn vượt qua các rào cản kỹ thuật (cliffordchance.com).
Vậy web scraping có bất hợp pháp không? Có lúc có, có lúc không, và rất thường là “còn tùy”. Mọi thứ nằm ở chi tiết.
So sánh góc nhìn pháp lý: Mỹ, EU, Anh, Trung Quốc
Dưới đây là bảng tóm tắt cách các khu vực lớn tiếp cận web scraping:
| Khu vực | Thu thập dữ liệu công khai | Thu thập dữ liệu cá nhân/riêng tư | Thực thi & điểm đáng chú ý |
|---|---|---|---|
| Mỹ | Nhìn chung được phép với dữ liệu công khai (xem hiQ v. LinkedIn). Vi phạm ToS có thể dẫn đến kiện dân sự. | Bị hạn chế/bất hợp pháp nếu vượt qua đăng nhập hoặc lạm dụng dữ liệu cá nhân. Luật bang (như CCPA) có thể áp dụng. | Thư yêu cầu chấm dứt vi phạm, chặn IP, kiện tụng. CFAA áp dụng nếu bạn vượt rào cản kỹ thuật. |
| EU | Được phép có điều kiện với dữ liệu công khai, không phải dữ liệu cá nhân. Có thể áp dụng quyền cơ sở dữ liệu. Luật AI Act của EU (2026) bổ sung yêu cầu minh bạch cho dữ liệu huấn luyện AI. | Được quản lý rất chặt dưới GDPR — ngay cả dữ liệu cá nhân công khai cũng cần cơ sở pháp lý. | Cơ quan Bảo vệ Dữ liệu có thể phạt vì vi phạm quyền riêng tư. Quyền bản quyền/quyền cơ sở dữ liệu cũng được thực thi. EU AI Act cấm thu thập hình ảnh khuôn mặt để huấn luyện AI. |
| Anh | Tương tự EU. Dữ liệu công khai, không phải dữ liệu cá nhân, có thể được thu thập, nhưng phải tôn trọng quyền dữ liệu và hợp đồng. | Rất nghiêm với dữ liệu cá nhân — UK GDPR áp dụng. Computer Misuse Act hình sự hóa việc truy cập trái phép. | ICO có thể phạt vì vi phạm bảo vệ dữ liệu. Tòa án có thể thực thi ToS. |
| Trung Quốc | Bị kiểm soát chặt. Dữ liệu công khai, không phải dữ liệu cá nhân, có thể được thu thập cho mục đích nội bộ, nhưng môi trường pháp lý khá thận trọng. | Hạn chế rất mạnh — PIPL yêu cầu có sự đồng ý đối với dữ liệu cá nhân. Luật chống cạnh tranh không lành mạnh cũng được áp dụng. | Có vụ án hình sự đối với hoạt động scraping quy mô lớn. Tòa án dùng luật cạnh tranh không lành mạnh để ngăn chặn scraping trái phép. |
Web scraping có bất hợp pháp không? Các yếu tố pháp lý quan trọng cần xem xét
Vậy điều gì thực sự quyết định dự án scraping của bạn là hợp pháp hay rủi ro? Đây là những yếu tố lớn nhất:
- Dữ liệu công khai hay riêng tư: Thu thập dữ liệu mà bất kỳ ai cũng có thể thấy trên web mở thường an toàn hơn. Còn thu thập dữ liệu nằm sau lớp đăng nhập, tường phí hoặc rào cản kỹ thuật? Khả năng cao là bất hợp pháp (thunderbit.com).
- Bản chất của dữ liệu: Dữ liệu cá nhân (tên, email, hồ sơ) sẽ kích hoạt luật riêng tư. Nội dung có bản quyền (bài viết, hình ảnh) không thể sao chép nguyên xi toàn bộ. Còn các dữ kiện thuần túy (giá cả, thời tiết) thì thường được xem là có thể thu thập (oxylabs.io).
- Mục đích sử dụng: Phân tích nội bộ hoặc nghiên cứu thường được nhìn thoáng hơn so với việc đăng lại hay bán dữ liệu đã thu thập. Dùng dữ liệu scraping để cạnh tranh trực tiếp với nguồn gốc? Đó là công thức cho một vụ kiện (thunderbit.com).
- Tuân thủ quy tắc của website: Luôn kiểm tra robots.txt và ToS. Robots.txt không có tính ràng buộc pháp lý, nhưng tôn trọng nó là thực hành tốt. Vi phạm ToS có thể dẫn đến kiện dân sự hoặc tệ hơn (promptcloud.com).
- Biện pháp kỹ thuật: Thu thập ở tốc độ giống con người và không vượt qua các biện pháp bảo vệ là rất quan trọng. Nếu bạn “đập” vào máy chủ quá mạnh hoặc né CAPTCHA, bạn có thể vượt sang vùng xám của hacking (cliffordchance.com).
Điều gì đã thay đổi trong giai đoạn 2024–2026: các vụ án và quy định quan trọng
Bức tranh pháp lý của web scraping đã thay đổi đáng kể kể từ năm 2023. Đây là những diễn biến mà mọi scraper đều cần biết:
Các phán quyết lớn của tòa án
-
Meta v. Bright Data (2024): Một tòa án liên bang Hoa Kỳ phán rằng Điều khoản dịch vụ của Meta không cấm việc scraping dữ liệu công khai bởi người dùng không đăng nhập. Thẩm phán kết luận rằng “một khách truy cập không được coi là ‘người dùng’ trừ khi họ có tài khoản.” Sau đó Meta đã rút các yêu cầu còn lại. Đây là một chiến thắng mang tính bước ngoặt cho việc thu thập dữ liệu công khai.
-
X Corp v. Bright Data (2024): Twitter (nay là X) thua một vụ kiện tương tự, củng cố cùng một nguyên tắc: thu thập dữ liệu công khai mà không đăng nhập không vi phạm ToS, vì scraper chưa từng đồng ý với các điều khoản đó.
-
Reddit v. Perplexity AI (tháng 10/2025): Reddit đã kiện Perplexity AI và một số nhà cung cấp scraping, viện dẫn DMCA và cáo buộc vượt qua hệ thống chống bot. Điều này cho thấy một chiến lược pháp lý mới: các nền tảng đang chuyển sang bản quyền và cáo buộc vượt cơ chế bảo vệ thay vì CFAA.
-
NYT v. OpenAI (tháng 3/2025): Một thẩm phán liên bang cho phép vụ kiện bản quyền của New York Times chống OpenAI tiếp tục, bác bỏ yêu cầu bác đơn của OpenAI. Điều này có thể tạo ra tiền lệ quan trọng về việc scraping nội dung để huấn luyện mô hình AI có được xem là “sử dụng hợp lý” hay không.
-
Thỏa thuận của Anthropic (tháng 9/2025): Anthropic đồng ý trả 1,5 tỷ USD để dàn xếp một vụ kiện tập thể về bản quyền tại Mỹ liên quan đến việc dùng văn bản có bản quyền để huấn luyện mô hình AI của họ — cho thấy chi phí của việc scraping phục vụ AI là hoàn toàn có thật.
Xu hướng lớn: từ CFAA sang luật hợp đồng và bản quyền
Xu hướng khá rõ: CFAA (Computer Fraud and Abuse Act) đang mất dần sức mạnh như một vũ khí chống lại những người scraping dữ liệu công khai. Những công ty từng cố dùng CFAA để đối phó với scraping dữ liệu công khai — như Meta, X, LinkedIn — phần lớn đều không thành công. Thay vào đó, mặt trận pháp lý đang chuyển sang:
- Luật hợp đồng (vi phạm ToS — nhưng tòa án đang nói rằng người không dùng dịch vụ không bị ràng buộc bởi ToS)
- Yêu cầu bản quyền (đặc biệt với dữ liệu huấn luyện AI)
- Các điều luật chống vượt rào cản (DMCA Section 1201)
Với người làm scraping, điều đó có nghĩa là rủi ro pháp lý không biến mất — nó chỉ chuyển hướng.
Thay đổi về quy định
- Cập nhật CCPA 2026: Các quy định CCPA sửa đổi của California có hiệu lực từ ngày 1/1/2026, bổ sung quy tắc mới cho công nghệ ra quyết định tự động (ADMT), đánh giá rủi ro và nghĩa vụ của các data broker.
- Các luật riêng tư cấp bang mới của Mỹ: Indiana, Kentucky và Rhode Island đã ban hành các luật bảo mật dữ liệu toàn diện, có hiệu lực trong năm 2026.
- EU AI Act: Việc thực thi toàn phần bắt đầu vào ngày 2/8/2026 — yêu cầu nhà phát triển AI phải công bố nguồn dữ liệu huấn luyện, tôn trọng cơ chế từ chối bản quyền, và cấm thu thập hình ảnh khuôn mặt cho hệ thống AI.
- AI Accountability for Publishers Act (tháng 2/2026): Một dự luật của Mỹ đề xuất yêu cầu các công ty AI phải xin phép và trả phí cho nhà xuất bản trước khi thu thập nội dung của họ.
Chính sách scraping của các nền tảng lớn: Bạn cần biết gì
Không phải website nào cũng đối xử với scraping giống nhau. Dưới đây là cái nhìn theo từng nền tảng về những gì các trang lớn cho phép, chặn gì, và tòa án đã nói gì:
| Nền tảng | ToS về scraping | Biện pháp kỹ thuật | Thực thi pháp lý | Mức độ an toàn thực tế |
|---|---|---|---|---|
| Google (Search & Maps) | Cấm truy cập tự động trong ToS. Maps Platform có điều khoản "No Scraping" rất rõ ràng. | Thử thách SearchGuard JS, CAPTCHA, giới hạn tốc độ. robots.txt được cập nhật năm 2025 để chặn các bot AI. | Đã kiện scraper vào tháng 12/2025 theo DMCA. Chủ động chặn các bot AI (Anthropic, Meta, OpenAI). | Thu thập dữ liệu doanh nghiệp công khai trên Google Maps có thể bảo vệ được về mặt pháp lý (tiền lệ hiQ), nhưng hãy chuẩn bị bị chặn kỹ thuật. Nên dùng API chính thức khi có thể. |
| Amazon | Cấm rõ ràng mọi hình thức scraping trong Conditions of Use (“không robot, spider, scraper, hay bất kỳ phương tiện tự động nào khác”). | Phát hiện bot rất gắt, CAPTCHA, chặn IP. robots.txt chặn mọi bot trừ Googlebot/Bingbot. Từ 2025 cũng chặn rõ các bot AI. | Kiện Perplexity AI vào tháng 11/2025. Thường xuyên gửi thư yêu cầu chấm dứt vi phạm. Cập nhật BSA vào tháng 3/2026 với quy tắc cho agent AI. | Dữ liệu sản phẩm công khai (giá, danh sách) là dữ kiện và có thể thu thập theo luật Mỹ, nhưng Amazon phản ứng rất mạnh. Hãy giới hạn tốc độ và tránh dữ liệu cá nhân. |
| Cấm scraping trong ToS; yêu cầu người dùng đồng ý để truy cập dịch vụ. | Hầu hết dữ liệu hồ sơ nằm sau lớp đăng nhập, phát hiện bot, giới hạn tốc độ. | Vụ hiQ xác nhận scraping hồ sơ công khai không vi phạm CFAA, nhưng LinkedIn thắng ở các yêu cầu về hợp đồng/cạnh tranh không lành mạnh khi có tài khoản giả. | Hồ sơ công khai (nhìn thấy mà không cần đăng nhập) có cơ sở pháp lý tương đối tốt để thu thập. Tuyệt đối không tạo tài khoản giả hoặc thu thập dữ liệu sau khi đăng nhập. | |
| Meta (Facebook & Instagram) | ToS cấm scraping; có quy tắc riêng cho dữ liệu khi đăng nhập và không đăng nhập. | Phần lớn nội dung nằm sau lớp đăng nhập, phát hiện bot nâng cao. | Thua Bright Data năm 2024 — tòa phán ToS không áp dụng với scraper không đăng nhập. Đã rút các yêu cầu còn lại. | Dữ liệu công khai (trang doanh nghiệp, bài đăng công khai) mà không cần đăng nhập an toàn hơn. Đừng bao giờ scrape hồ sơ riêng tư hoặc dữ liệu sau đăng nhập. |
| X (Twitter) | Cập nhật ToS năm 2023 để cấm mọi scraping và crawling nếu không có sự đồng ý bằng văn bản. Xóa ngoại lệ robots.txt cũ. | robots.txt chặn mọi crawler (Disallow: /). Thử thách Cloudflare Turnstile. Giới hạn tốc độ nghiêm ngặt (300 req/giờ). Chấm điểm uy tín IP. | Thua Bright Data về dữ liệu công khai, nhưng vẫn siết chặt quyền truy cập kỹ thuật. | Tweet và hồ sơ công khai có cơ sở pháp lý để thu thập, nhưng rào cản kỹ thuật của X thuộc hàng khó nhất năm 2026. Không có hạ tầng proxy cao cấp thì rất dễ bị chặn. |
Điểm mấu chốt: Tòa án nhất quán rằng việc thu thập dữ liệu công khai, nhìn thấy được mà không cần đăng nhập không vi phạm CFAA. Nhưng các nền tảng vẫn có thể tấn công bạn bằng luật hợp đồng, bản quyền hoặc các lý thuyết chống vượt rào cản — và họ sẽ làm cuộc sống của bạn trở nên khó khăn bằng các biện pháp kỹ thuật. Hãy luôn scraping một cách có trách nhiệm.
Dữ liệu huấn luyện AI và web scraping: Biên giới pháp lý mới
Nếu bạn theo dõi tin tức trong năm 2026, bạn sẽ biết rằng thu thập dữ liệu để huấn luyện mô hình AI đã trở thành chiến trường pháp lý nóng nhất. Đây là những gì đang diễn ra:
- Các vụ kiện bản quyền đang tăng lên. New York Times, các tác giả và nhà xuất bản đã kiện OpenAI, Anthropic và những bên khác, cáo buộc rằng việc thu thập hàng loạt nội dung có bản quyền để huấn luyện LLM không phải là “fair use”. Anthropic đã dàn xếp một vụ kiện tập thể lớn với số tiền 1,5 tỷ USD vào năm 2025 — cho thấy chi phí của việc scraping phục vụ AI là rất thật.
- Lập luận “fair use” còn khá yếu. Tòa án Mỹ vẫn chưa đưa ra phán quyết dứt khoát về việc huấn luyện AI bằng dữ liệu scraping có phải là fair use hay không. Những phán quyết ban đầu cho thấy điều này phụ thuộc rất nhiều vào cách dữ liệu được thu thập và điều gì được làm với đầu ra của AI.
- Luật mới đang đến gần. AI Accountability for Publishers Act (được đưa ra vào tháng 2/2026) nhằm yêu cầu các công ty AI phải xin phép và trả tiền cho nhà xuất bản trước khi thu thập nội dung của họ.
- EU AI Act (thực thi toàn phần từ tháng 8/2026) yêu cầu nhà phát triển AI công bố nguồn dữ liệu huấn luyện, tôn trọng cơ chế từ chối bản quyền có thể đọc bằng máy (theo ngoại lệ TDM của Chỉ thị Bản quyền), và gắn nhãn nội dung do AI tạo ra. Luật này cũng cấm các hệ thống AI thu thập hình ảnh khuôn mặt từ internet.
- Bot/crawler AI/LLM đang bùng nổ. Tỷ trọng lưu lượng web của các AI crawler đã tăng gấp 4 lần, từ 2,6% lên 10,1% chỉ trong 8 tháng. Riêng GPTBot của OpenAI đã tăng 305%. Đáp lại, các website lớn (Amazon, Reddit, NYT) đang cập nhật robots.txt để chặn rõ ràng các AI crawler.
Điều này có nghĩa gì với bạn: Nếu bạn thu thập dữ liệu cho mục đích kinh doanh truyền thống (tạo lead, theo dõi giá, nghiên cứu thị trường), những quy định riêng cho AI có thể không áp dụng trực tiếp. Nhưng nếu bạn đưa dữ liệu scraping vào mô hình AI, hãy cực kỳ thận trọng — và nên xin tư vấn pháp lý.
Luật web scraping trên toàn thế giới: So sánh nhanh
Hãy lùi lại một bước và xem bức tranh toàn cầu ra sao:
- Hoa Kỳ: Không có lệnh cấm chung. Thu thập từ các website công khai nhìn chung là hợp pháp (hiQ v. LinkedIn), và các phán quyết năm 2024 trong vụ Meta và X Corp càng củng cố lập luận cho việc thu thập dữ liệu công khai. Nhưng scraping sau lớp đăng nhập hoặc vượt qua rào cản kỹ thuật vẫn có thể kích hoạt CFAA. Xu hướng hiện nay là các công ty chuyển sang dùng luật hợp đồng và yêu cầu bản quyền. Luật riêng tư cũng đang mở rộng nhanh: CCPA đã nhận các cập nhật lớn có hiệu lực từ ngày 1/1/2026, bao gồm quy tắc mới về ra quyết định tự động và nghĩa vụ của data broker. Indiana, Kentucky và Rhode Island cũng đã ban hành luật riêng tư toàn diện trong năm 2026.
- Liên minh châu Âu: Luật riêng tư rất nghiêm. GDPR áp dụng cả với dữ liệu cá nhân công khai. Quyền cơ sở dữ liệu có thể ngăn chặn việc scraping quy mô lớn đối với dữ liệu có cấu trúc (cliffordchance.com). MỚI: EU AI Act sẽ được thực thi toàn phần từ ngày 2/8/2026, yêu cầu nhà phát triển AI công bố nguồn dữ liệu huấn luyện và tôn trọng cơ chế từ chối bản quyền. Luật này cấm thu thập hình ảnh khuôn mặt từ internet cho hệ thống AI.
- Vương quốc Anh: Tương tự các quy định EU sau Brexit. Dữ liệu công khai có thể được thu thập, nhưng việc thu thập thông tin cá nhân bị quản lý chặt. Computer Misuse Act có thể hình sự hóa truy cập trái phép.
- Trung Quốc: Rất hạn chế. PIPL và Luật An ninh Dữ liệu yêu cầu có sự đồng ý đối với dữ liệu cá nhân. Tòa án dùng luật cạnh tranh không lành mạnh để ngăn chặn các hành vi scraping gây hại cho doanh nghiệp (malwarebytes.com).
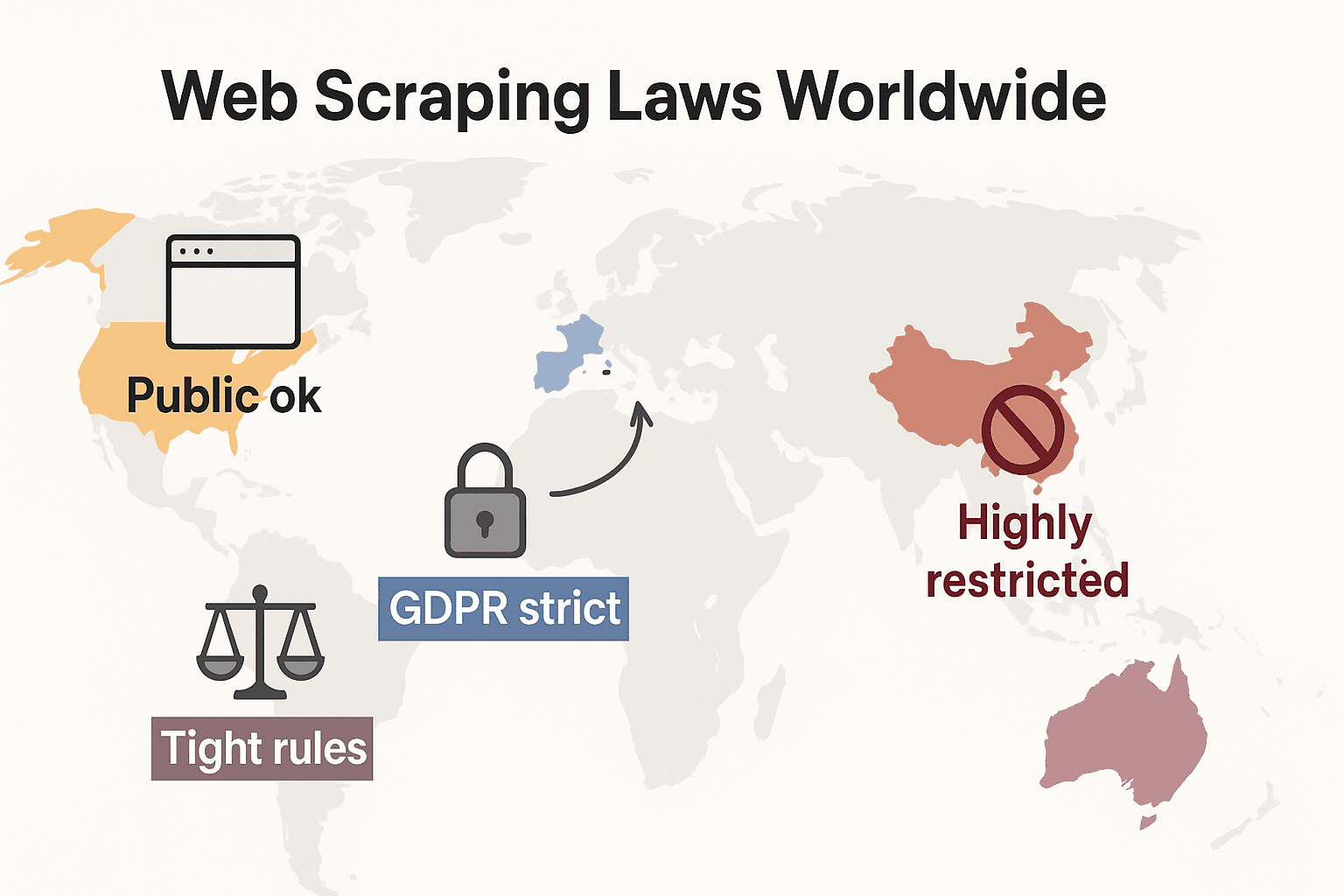
Tóm lại: thu thập dữ liệu công khai, không phải dữ liệu cá nhân, để dùng nội bộ là cách an toàn nhất. Còn những trường hợp khác? Hãy kiểm tra luật địa phương và đi thật cẩn thận.
Những hiểu lầm phổ biến về tính hợp pháp của web scraping
Hãy gỡ bỏ vài hiểu lầm mà tôi nghe suốt:
- Hiểu lầm 1: “Web scraping là bất hợp pháp, hết chuyện.”
Sai. Không có luật nào cấm toàn bộ web scraping. Quan trọng là bạn thu thập cái gì và bằng cách nào (oxylabs.io). - Hiểu lầm 2: “Nếu dữ liệu công khai, tôi muốn làm gì cũng được.”
Chưa đúng hẳn. Dữ liệu công khai vẫn có thể được bảo vệ bởi luật riêng tư hoặc bản quyền, và ToS có thể giới hạn một số mục đích sử dụng (ico.org.uk). - Hiểu lầm 3: “Web scraping cũng giống như hack.”
Không. Scraping các trang web công khai không phải là hack. Còn vượt qua đăng nhập hay rào cản kỹ thuật là câu chuyện khác (calawyers.org). - Hiểu lầm 4: “Chỉ cần không bị phát hiện là được.”
Nghĩ vậy khá nguy hiểm. Nhiều website dùng công nghệ chống bot và sẽ phát hiện ra. Im lặng không có nghĩa là đồng ý. - Hiểu lầm 5: “Chỉ cần ghi nguồn hoặc dùng nội bộ là được phép.”
Ghi nguồn không thể gạt sang một bên luật bản quyền hoặc quyền riêng tư. Dùng nội bộ thì an toàn hơn, nhưng không phải giấy thông hành miễn phí. - Hiểu lầm 6: “Mọi web scraping đều vi phạm quyền riêng tư.”
Không phải scraping nào cũng liên quan đến dữ liệu cá nhân. Nhưng thu thập khối lượng lớn thông tin cá nhân mà không có biện pháp bảo vệ thì gần như luôn bất hợp pháp (oxylabs.io). - Hiểu lầm 7: “Nếu ToS của website cấm scraping thì scrape là bất hợp pháp.”
Không hẳn. Năm 2024, tòa án trong Meta v. Bright Data và X Corp v. Bright Data đã phán rằng ToS không thể ràng buộc những người dùng chưa từng đồng ý với chúng — tức là nếu bạn scraping mà không đăng nhập hoặc tạo tài khoản, ToS của website có thể không áp dụng cho bạn. Đây vẫn là lĩnh vực đang phát triển, nhưng là một thay đổi rất đáng kể.
Cách thu thập dữ liệu hợp pháp: Thực hành tốt để tuân thủ
Đây là checklist tôi hay dùng để scraping đúng luật và có đạo đức:
- Đọc và tôn trọng Điều khoản dịch vụ của website. Nếu họ nói “không scraping”, hãy cân nhắc dừng lại hoặc xin phép (ql2.com).
- Chỉ bám vào dữ liệu công khai. Nếu cần mật khẩu để xem, đó là dữ liệu bị hạn chế — đừng scrape (thunderbit.com).
- Kiểm tra robots.txt và thu thập một cách lịch sự. Không có tính ràng buộc pháp lý, nhưng là phép lịch sự tốt. Đừng dồn dập gửi quá nhiều request — hãy giãn cách hợp lý (promptcloud.com).
- Tránh dữ liệu cá nhân trừ khi bạn có cơ sở pháp lý. Nếu bắt buộc phải thu thập, hãy tuân thủ GDPR/CCPA và tối thiểu hóa dữ liệu lấy về.
- Đừng đăng lại nguyên xi nội dung đã scrape. Hãy thêm giá trị, phân tích, hoặc xin phép (thunderbit.com).
- Đừng đưa nội dung đã scrape vào mô hình AI mà chưa kiểm tra bản quyền. Môi trường pháp lý đang thay đổi rất nhanh — hãy xin tư vấn nếu đây là use case của bạn.
- Dùng API chính thức hoặc export dữ liệu khi có thể. Chúng được thiết kế cho mục đích này và thường an toàn hơn (thunderbit.com).
- Minh bạch và có trách nhiệm. Nếu bạn thu thập dữ liệu cá nhân, hãy thông báo cho người liên quan và lưu nhật ký hoạt động.
- Tối thiểu hóa và bảo vệ dữ liệu. Chỉ lấy thứ bạn cần, giữ dữ liệu chính xác và lưu trữ an toàn.
- Luôn cập nhật và xin tư vấn pháp lý cho các trường hợp biên. Luật và phán quyết đang thay đổi rất nhanh — đặc biệt là EU AI Act và các luật riêng tư cấp bang của Mỹ. Khi không chắc, hãy hỏi chuyên gia.
Thử tiện ích Thunderbit Chrome cho scraping tuân thủ
Dùng công cụ web scraping hợp pháp: Doanh nghiệp cần biết gì
Các công cụ web scraping như Thunderbit giúp việc thu thập dữ liệu trở nên dễ tiếp cận với cả người không biết code, nhưng bạn vẫn cần dùng chúng một cách có trách nhiệm:
- Chọn công cụ chú trọng tuân thủ. Ví dụ, Thunderbit chỉ scrape những gì bạn có thể nhìn thấy trong trình duyệt — không có mánh khóe API hay truy cập trái phép (thunderbit.com).
- Bám vào các use case hợp pháp. Phân tích nội bộ, nghiên cứu thị trường và theo dõi giá cạnh tranh nhìn chung khá an toàn. Còn đăng lại hoặc bán dữ liệu đã scrape? Rủi ro cao hơn nhiều.
- Cấu hình công cụ để tuân thủ. Thiết lập độ trễ crawl, tôn trọng robots.txt và dùng template chỉ thu thập những gì bạn cần.
- Giữ trong nội bộ. Dùng dữ liệu đã scrape nội bộ an toàn hơn so với đăng lại.
- Đào tạo đội ngũ. Đảm bảo mọi người hiểu rõ quy tắc và thực hành tốt.
- Tận dụng tính năng tuân thủ có sẵn. Thunderbit cảnh báo người dùng về các website rủi ro, scrape ở tốc độ giống con người và không lưu dữ liệu của bạn trên máy chủ của họ.
- Đừng cố cưỡng ép. Nếu một công cụ không scrape được một trang, đừng tìm cách bẻ khóa vòng qua nó. Không phải dữ liệu nào cũng có thể lấy ra mà không có rủi ro.
Cách Thunderbit tiếp cận: Cho phép AI web scraping tuân thủ
Tại Thunderbit, chúng tôi đã dành rất nhiều thời gian để nghĩ về tính tuân thủ. Đây là cách AI Web Scraper của chúng tôi giúp người dùng đi đúng luật:
- Chỉ scrape những gì bạn nhìn thấy. Thunderbit hoạt động ngay trong phiên trình duyệt của bạn, nên không thể truy cập dữ liệu mà bạn không thể sao chép thủ công.
- Hướng dẫn người dùng bằng cảnh báo. Nếu bạn cố scrape một website có chính sách chống scraping nghiêm ngặt, Thunderbit sẽ nhắc bạn.
- Tốc độ scraping giống con người. Dù bạn scrape cục bộ hay trên cloud, Thunderbit đều tránh làm quá tải máy chủ.
- Lựa chọn dữ liệu linh hoạt. AI của chúng tôi gợi ý các cột phù hợp, giúp bạn chỉ thu thập thứ mình cần.
- Xử lý trang con và phân trang. Thunderbit điều hướng website như một người dùng thật, tôn trọng cấu trúc của trang.
- Quyền riêng tư và bảo mật. Dữ liệu của bạn ở lại với bạn — Thunderbit không lưu hay tái sử dụng dữ liệu đó.
- Xuất dữ liệu thân thiện với tuân thủ. Xuất trực tiếp sang Google Sheets, Airtable, Notion hoặc CSV để dùng nội bộ an toàn.
- Lên lịch và tự động hóa. Thiết lập các lần scrape định kỳ với khoảng thời gian hợp lý.
- Hỗ trợ đa ngôn ngữ. Giao diện Thunderbit hỗ trợ 34 ngôn ngữ, giúp việc tuân thủ trở nên dễ tiếp cận trên toàn cầu.
- Cập nhật template thường xuyên. Các template tức thì cho website phổ biến luôn được cập nhật theo thay đổi pháp lý và kỹ thuật.
Bằng cách tích hợp tuân thủ ngay trong sản phẩm, Thunderbit giúp các nhóm thu thập dữ liệu họ cần — mà không phải đau đầu vì pháp lý.
Đi trước một bước: Thích ứng với thay đổi pháp lý và kỹ thuật trong web scraping
Khám phá thêm các hướng dẫn về web scraping Get Started Free
Web scraping không phải kiểu “thiết lập một lần rồi để đó”. Luật pháp và cấu trúc website luôn thay đổi. Đây là cách để bạn đi trước:
- Theo dõi các diễn biến pháp lý. Tốc độ thay đổi tăng mạnh trong giai đoạn 2024–2026 — hãy theo dõi tin tức về luật công nghệ, cập nhật từ cơ quan quản lý và các blog ngành (như blog của Thunderbit). Đặc biệt chú ý tới việc thực thi EU AI Act (tháng 8/2026), các luật riêng tư cấp bang mới của Mỹ và các vụ kiện bản quyền AI đang diễn ra.
- Thích ứng với thay đổi kỹ thuật. Các website liên tục cập nhật giao diện và biện pháp chống bot. Những nền tảng lớn (Amazon, X, Google) đã siết chặt đáng kể trong giai đoạn 2025–2026. AI và template của Thunderbit được thiết kế để thích ứng tự động.
- Ưu tiên API chính thức khi có thể. Nếu một website chuyển sang mô hình API trả phí, hãy cân nhắc chuyển theo để đảm bảo độ ổn định và tuân thủ.
- Kiểm tra hoạt động scraping thường xuyên. Ghi lại nguồn dữ liệu, kiểm tra thay đổi ToS hoặc chính sách, và điều chỉnh chiến lược khi cần.
- Tận dụng các bản cập nhật template của Thunderbit. Đội ngũ của chúng tôi luôn giữ template cập nhật, nên bạn không phải lo các thay đổi phá vỡ quy trình hay yêu cầu tuân thủ mới.
- Giữ sự linh hoạt. Nếu một nguồn dữ liệu trở nên quá rủi ro, hãy chuyển sang nguồn khác hoặc tìm một mối hợp tác.
Với công cụ và tư duy đúng đắn, bạn có thể giữ cho pipeline dữ liệu luôn chạy — mà không đạp phải mìn pháp lý.
Kết luận: Điều hướng bối cảnh pháp lý của web scraping
Web scraping không tự động là bất hợp pháp — nó là một công cụ mạnh mẽ cho kinh doanh, nghiên cứu và đổi mới. Nhưng như bất kỳ công cụ nào, nó cũng đi kèm quy tắc. Điều cốt lõi là hiểu bạn đang thu thập dữ liệu gì, bằng cách nào, và sẽ làm gì với dữ liệu đó. Hãy tôn trọng luật địa phương, tuân thủ chính sách website, và dùng các công cụ chú trọng compliance như Thunderbit để vận hành một cách minh bạch.
Các phán quyết 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) đã củng cố lập luận cho việc thu thập dữ liệu công khai, nhưng các rủi ro mới đang nổi lên xoay quanh dữ liệu huấn luyện AI, cáo buộc bản quyền và EU AI Act. Chính sách của từng nền tảng cũng khác nhau rất nhiều — Google, Amazon, LinkedIn, Meta và X đều thực thi quy định theo những cách riêng — nên hãy nắm rõ bối cảnh trước khi scrape.
Nếu bạn không chắc chắn, hãy xin tư vấn pháp lý — đặc biệt với các dự án lớn hoặc nhạy cảm. Và hãy nhớ: bối cảnh pháp lý luôn thay đổi, vì vậy hãy luôn cập nhật và linh hoạt.
Muốn tìm hiểu thêm về web scraping, compliance và tự động hóa? Hãy xem Thunderbit Blog để đọc thêm hướng dẫn, hoặc tự trải nghiệm tiện ích Chrome của Thunderbit.
Bắt đầu web scraping tuân thủ với Thunderbit
Câu hỏi thường gặp
1. Web scraping có bất hợp pháp ở mọi nơi không?
Không. Web scraping không tự thân là bất hợp pháp, nhưng tính hợp pháp còn tùy vào bạn thu thập gì, thu thập như thế nào và bạn ở đâu. Việc thu thập dữ liệu công khai, không phải dữ liệu cá nhân, để dùng nội bộ thường được phép ở hầu hết các khu vực, nhưng thu thập dữ liệu cá nhân hoặc có bản quyền, hoặc vi phạm điều khoản của website, có thể là bất hợp pháp (oxylabs.io).
2. Nếu tôi bỏ qua robots.txt thì có khiến scraping trở thành bất hợp pháp không?
Robots.txt không có giá trị ràng buộc pháp lý, nhưng tốt nhất vẫn nên tôn trọng nó. Việc bỏ qua robots.txt không tự động khiến bạn bị kiện, nhưng nếu có tranh chấp thì nó có thể khiến bạn trông giống một “bad actor” (promptcloud.com).
3. Tôi có thể scrape Google, Amazon hoặc LinkedIn không?
Câu trả lời là khá phức tạp. Cả ba đều cấm scraping trong ToS, nhưng tòa án đã phán rằng ToS có thể không ràng buộc người không đăng nhập (xem Meta v. Bright Data và X Corp v. Bright Data, đều năm 2024). Việc thu thập dữ liệu công khai nhìn thấy được (giá sản phẩm, danh sách doanh nghiệp, hồ sơ công khai) nhìn chung có cơ sở pháp lý tốt tại Mỹ. Tuy vậy, mỗi nền tảng thực thi theo cách rất khác nhau: Amazon mạnh tay nhất về pháp lý (đã kiện Perplexity AI vào tháng 11/2025); LinkedIn dựa nhiều vào rào cản kỹ thuật và yêu cầu hợp đồng; Google ngày càng dùng thực thi dựa trên DMCA. Hãy luôn scraping có trách nhiệm và chuẩn bị cho các biện pháp đối phó kỹ thuật.
4. Tôi có thể scrape Facebook hoặc Instagram không?
Sau Meta v. Bright Data (2024), việc thu thập dữ liệu công khai từ Facebook và Instagram mà không đăng nhập có nền tảng pháp lý mạnh hơn. Tòa án phán rằng ToS của Meta không áp dụng cho người không phải người dùng. Nhưng đừng bao giờ tạo tài khoản giả hoặc scrape dữ liệu sau lớp đăng nhập — đó là vượt quá giới hạn.
5. Tôi có thể scrape X (Twitter) không?
X đã cập nhật ToS năm 2023 để cấm mọi scraping nếu không có sự đồng ý bằng văn bản và đã triển khai các biện pháp kỹ thuật rất mạnh (Cloudflare Turnstile, giới hạn 300 request/giờ, chấm điểm uy tín IP). Tuy nhiên, Bright Data đã thắng kiện trên các cơ sở tương tự — dữ liệu công khai được scrape mà không có tài khoản không bị ràng buộc bởi ToS của X. Về mặt kỹ thuật, X là một trong những nền tảng khó scrape nhất vào năm 2026.
6. Thu thập dữ liệu để huấn luyện mô hình AI có hợp pháp không?
Đây là câu hỏi lớn nhất chưa có lời giải trong năm 2026. Các vụ kiện lớn (NYT v. OpenAI, thỏa thuận 1,5 tỷ USD của Anthropic) cho thấy rủi ro pháp lý rất cao. EU AI Act yêu cầu công bố nguồn dữ liệu huấn luyện và tôn trọng cơ chế từ chối bản quyền. Dự luật AI Accountability for Publishers Act được đề xuất sẽ yêu cầu xin phép và thanh toán. Nếu bạn scrape để huấn luyện AI, hãy xin tư vấn pháp lý trước khi làm.
7. Cách an toàn nhất để dùng công cụ web scraping như Thunderbit là gì?
Chỉ scrape dữ liệu công khai, tôn trọng điều khoản của website, tránh thông tin cá nhân nếu không có cơ sở pháp lý, và dùng dữ liệu cho nội bộ. Thunderbit được thiết kế để giúp bạn tuân thủ bằng cách chỉ scrape những gì hiển thị trong trình duyệt và cảnh báo về các website rủi ro (thunderbit.com).
8. Tôi có thể scrape dữ liệu cho mục đích thương mại không?
Còn tùy. Dùng dữ liệu đã scrape cho phân tích nội bộ hoặc nghiên cứu thường an toàn hơn. Còn đăng lại hoặc bán dữ liệu đã scrape, đặc biệt nếu là dữ liệu có bản quyền hoặc dữ liệu cá nhân, sẽ rủi ro hơn rất nhiều và có thể cần giấy phép hoặc sự cho phép.
9. Làm sao để theo kịp các thay đổi pháp lý và kỹ thuật trong web scraping?
Hãy theo dõi tin tức về luật công nghệ, giám sát các website mục tiêu để phát hiện thay đổi ToS hoặc chính sách, và dùng các công cụ như Thunderbit vốn thường xuyên cập nhật template và tính năng tuân thủ. Những điều quan trọng cần theo dõi trong năm 2026: việc thực thi EU AI Act (tháng 8), các vụ kiện bản quyền AI đang diễn ra và các luật riêng tư mới ở cấp bang của Mỹ. Khi không chắc, hãy hỏi chuyên gia pháp lý.
Thử AI Web Scraper Get Started Free




