

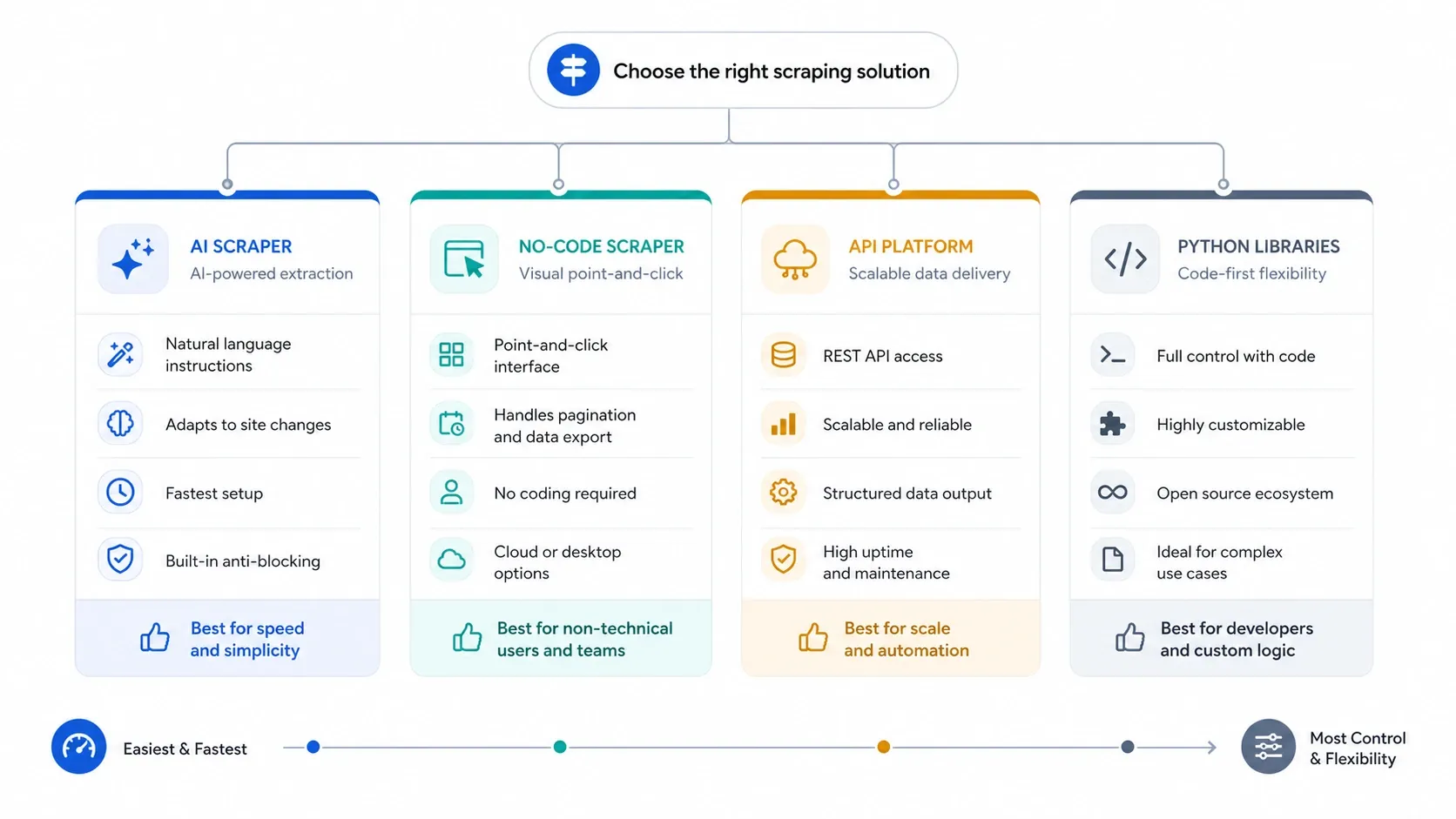
Nếu bạn cần dữ liệu web vào năm 2026, câu hỏi khó nhất không còn là “có thu thập được hay không?” nữa. Mà là “lớp công cụ nào giúp tôi lấy được dữ liệu dùng được với ít công sức thiết lập, bảo trì và chi phí hạ tầng nhất?” Vì vậy, trang này được sắp xếp theo mức độ phù hợp trước: công cụ thu thập dữ liệu web AI để đi nhanh, công cụ no-code cho các tác vụ trình duyệt lặp lại, API cho quy mô lớn và xử lý chống bot, rồi đến thư viện Python cho đội ngũ muốn toàn quyền kiểm soát.
Câu trả lời nhanh
- Chọn công cụ thu thập dữ liệu web AI nếu bạn muốn đi từ trang web đến bảng tính nhanh nhất với thiết lập tối thiểu.
- Chọn công cụ thu thập dữ liệu no-code nếu bạn cần phân trang rõ ràng hơn, lập lịch, xử lý đăng nhập hoặc kiểm soát tác vụ lặp lại.
- Chọn API thu thập dữ liệu nếu việc hiển thị trang, chống bot, chạy đồng thời và tỷ lệ vượt chặn quan trọng hơn sự đơn giản của giao diện.
- Chọn thư viện Python nếu đội ngũ của bạn muốn toàn quyền với request, phân tích cú pháp, tự động hóa trình duyệt, cơ chế thử lại và triển khai.
Với đa số đội ngũ kinh doanh, sai lầm thường là đi xuống tầng công nghệ quá sớm. Hãy bắt đầu bằng công cụ nhẹ nhất có thể làm việc ổn định, rồi chỉ chuyển từ AI sang no-code, sang API, sang code khi quy trình thực sự buộc bạn phải nâng cấp.
Tải trọn bộ hình minh họa tại đây: bộ hình minh họa công cụ thu thập dữ liệu web.
Bảng so sánh nhanh: Công cụ thu thập dữ liệu web nhìn trong một phút
Các tín hiệu giá bên dưới được kiểm tra lại theo trang sản phẩm, trang giá hoặc tài liệu chính thức vào ngày 12/5/2026. Với những nhà cung cấp dùng mô hình tính phí tùy chỉnh hoặc theo mức sử dụng, tôi mô tả mô hình giá thay vì ép vào một con số hàng tháng giả định như nhau.
| Công cụ | Danh mục | Phù hợp nhất | Vì sao có mặt trong danh sách 2026 này | Tín hiệu giá (kiểm tra tháng 5/2026) |
|---|---|---|---|---|
| Thunderbit | Công cụ thu thập dữ liệu web AI | Sales, ops, ecommerce, bất động sản | Con đường nhanh nhất từ trang web đến bảng có cấu trúc, không cần kỹ thuật | Gói miễn phí, các gói trả phí, giá cho doanh nghiệp |
| Kadoa | Nền tảng trích xuất AI | Đội ngũ dữ liệu và các chương trình định kỳ quy mô lớn | Phù hợp mạnh với quy trình trích xuất kiểu agent có khả năng tự phục hồi | Có bản đánh giá miễn phí, các gói tính theo mức sử dụng và doanh nghiệp |
| Octoparse | Công cụ thu thập dữ liệu no-code | Nhà phân tích và tác vụ vận hành lặp lại | Thu thập dữ liệu trên cloud trưởng thành cùng trình dựng tác vụ trực quan | Gói miễn phí, Standard từ $69/tháng, các gói cao hơn |
| ParseHub | Công cụ thu thập dữ liệu low-code | Người không viết code nhưng có tư duy kỹ thuật và nhà nghiên cứu | Logic điều hướng linh hoạt cho các trang khó | Gói miễn phí, các gói trả phí từ $189/tháng |
| Web Scraper | Công cụ thu thập dữ liệu no-code trên trình duyệt | Người mới và các tác vụ lặp lại nhẹ | Mô hình sitemap đơn giản, có lớp cloud tùy chọn | Tiện ích miễn phí, Cloud từ $50/tháng |
| Browse AI | Công cụ thu thập dữ liệu kiểu robot no-code | Giám sát và đội ngũ ưu tiên bảng tính | Mạnh về giám sát lặp lại và cảnh báo thay đổi | Gói miễn phí, các gói trả phí, gói quản lý |
| Bardeen | Tự động hóa trình duyệt AI | Tự động hóa GTM và revops | Tốt nhất khi thu thập dữ liệu chỉ là một bước trong quy trình lớn hơn | Gói miễn phí, Basic từ $10/tháng, Premium và Enterprise |
| ScrapeStorm | Công cụ thu thập dữ liệu trực quan có hỗ trợ AI | Người muốn thiết lập trực quan nhanh | Cầu nối hữu ích giữa bộ chọn thủ công và hỗ trợ AI | Dùng thử miễn phí, các gói trả phí, giá doanh nghiệp |
| ScraperAPI | API thu thập dữ liệu | Nhà phát triển cần mở rộng khối lượng request | API đơn giản kèm proxy, CAPTCHA và xử lý hiển thị hộ | Dùng thử 7 ngày, trả phí từ $49/tháng |
| Bright Data Web Scraper | Nền tảng thu thập dữ liệu doanh nghiệp | Các chương trình nặng về mua sắm và tuân thủ | Bộ công cụ thu thập dữ liệu toàn diện nhất trong nhóm | Giá theo sản phẩm và theo mức sử dụng |
| Zyte | API + bộ chống bot | Đội ngũ nhà phát triển và dữ liệu | Hỗ trợ thao tác trình duyệt mạnh, hiển thị JS và xoay IP | Tín dụng dùng thử $5, các gói tính theo mức sử dụng |
| ZenRows | API thu thập dữ liệu | Startup và đội ngũ phát triển | API chống bot gọn gàng, dễ tiếp cận hơn | Dùng thử miễn phí, Developer từ $69/tháng |
| ScrapingBee | API thu thập dữ liệu | Đội ngũ thu thập trang nhiều JavaScript | Hữu ích khi hiển thị trang là điểm nghẽn chính | Dùng thử miễn phí, trả phí từ $49/tháng |
| Selenium | Tự động hóa trình duyệt mã nguồn mở | Luồng kiểu QA và thu thập nhiều tương tác | Vẫn rất hữu ích khi hành vi người dùng chính xác là yếu tố quan trọng | Miễn phí và mã nguồn mở |
| Beautiful Soup | Thư viện phân tích cú pháp Python | Thu thập dữ liệu Python nhẹ | Trình phân tích dễ dùng nhất cho HTML lộn xộn | Miễn phí và mã nguồn mở |
| Playwright | Tự động hóa trình duyệt hiện đại | Ứng dụng web hiện đại và đội ngũ phát triển | Lựa chọn hiện đại tốt nhất cho thu thập dữ liệu bằng script | Miễn phí và mã nguồn mở |
| urllib3 | Thư viện HTTP Python | Nhà phát triển muốn kiểm soát request ở mức thấp | Nền tảng hữu ích khi bạn muốn tự nắm hành vi truyền tải | Miễn phí và mã nguồn mở |
Cách chọn đúng công cụ thu thập dữ liệu web
Hãy dùng bốn bộ lọc này trước khi so sánh các thương hiệu:
- Thời gian để có đầu ra hữu ích đầu tiên
Nếu công cụ không thể lấy ra một bảng thật nhanh, thì với hầu hết trường hợp kinh doanh nó đã thua. - Gánh nặng bảo trì
Một scraper rẻ nhưng cứ hỏng mỗi khi bố cục thay đổi thì thực ra không hề rẻ. - Giới hạn quy mô
Một tiện ích trình duyệt có thể hoàn hảo cho 50 trang mỗi tuần nhưng lại tệ cho 5 triệu request mỗi tháng. - Độ phù hợp với quy trình
Công cụ thu thập dữ liệu tốt nhất cho revops hiếm khi là công cụ tốt nhất cho kỹ sư nền tảng.
Khung ra quyết định thường đơn giản hơn các đội ngũ nghĩ:
- Nếu bạn muốn thu thập lead, danh sách hoặc trang sản phẩm mà không cần chạm vào bộ chọn, hãy bắt đầu với AI.
- Nếu bạn cần tác vụ lặp lại, chạy trên cloud và kiểm soát rõ hơn, hãy chuyển sang trình dựng trực quan no-code.
- Nếu chống bot, hiển thị JavaScript và chạy đồng thời mới là vấn đề thật sự, hãy nhảy sang API.
- Nếu bạn muốn tự nắm mọi lớp, hãy dùng thư viện Python và chấp nhận gánh nặng bảo trì.
Các công cụ thu thập dữ liệu web AI tốt nhất cho quy trình kinh doanh nhanh
Đây là nhóm đầu tiên tôi sẽ thử nếu bạn muốn đầu ra sẵn sàng cho bảng tính với cấu hình ít nhất có thể.
1. Thunderbit
Thunderbit vẫn là điểm khởi đầu dễ nhất ở đây cho người không biết code. Lợi thế cốt lõi không chỉ là “AI” theo nghĩa chung chung; mà là sản phẩm rút ngắn vòng thiết lập. Bạn mở một trang, nhờ AI gợi ý trường dữ liệu, làm giàu qua các trang con khi cần, rồi gửi kết quả thẳng tới những công cụ mà đội ngũ bạn đang dùng.
- Phù hợp nhất cho: tìm kiếm khách hàng tiềm năng, giám sát ecommerce, thu thập dữ liệu bất động sản và các nhóm ops sống trong trình duyệt.
- Điểm nổi bật: con đường nhanh nhất từ trang lộn xộn đến bảng có cấu trúc.
- Lưu ý: nếu bạn cần logic kiểu crawler hoặc luồng kỹ thuật tùy biến cao, cuối cùng bạn sẽ chuyển sang API hoặc code.
- Tín hiệu giá: gói miễn phí, các gói tự phục vụ trả phí và giá cho doanh nghiệp.
Video hướng dẫn này vẫn là cách nhanh nhất để đánh giá xem thu thập dữ liệu ưu tiên AI có đủ cho quy trình của bạn hay không:
Dùng thử Thunderbit AI Web Scraper miễn phí
2. Kadoa
Kadoa là lựa chọn AI thiên về hạ tầng hơn trong nhóm này. Nó hợp lý khi bạn muốn trích xuất có khả năng tự phục hồi và các tác vụ lặp lại ở quy mô vận hành lớn hơn mức mà đa số tiện ích trình duyệt có thể xử lý.
- Phù hợp nhất cho: đội ngũ dữ liệu, chương trình tình báo nội bộ và khối lượng trích xuất định kỳ lớn.
- Điểm nổi bật: điều phối kiểu agent và câu chuyện mạnh hơn về giảm công bảo trì.
- Lưu ý: nặng hơn mức mà phần lớn người dùng kinh doanh cần cho các lần thu thập nhanh, một lần.
- Tín hiệu giá: đánh giá miễn phí, các gói tính theo mức sử dụng và doanh nghiệp.
Các công cụ thu thập dữ liệu web no-code tốt nhất cho tác vụ lặp lại
Khi công việc thu thập trở nên định kỳ, trình dựng quy trình trực quan và chạy trên cloud sẽ quan trọng hơn tốc độ một cú nhấp đơn thuần.
3. Octoparse
Octoparse vẫn là một trong những công cụ no-code đáng tin cậy nhất khi công việc lớn hơn một tiện ích trình duyệt nhưng chưa đến mức thành một dự án kỹ thuật tùy biến. Giá trị của nó nằm ở sự kết hợp giữa chạy trên cloud, mẫu quy trình và trình dựng tác vụ trực quan đã trưởng thành.
- Phù hợp nhất cho: nhà phân tích, đội ngũ định giá và các tác vụ thu thập định kỳ có ý nghĩa vận hành rõ rệt.
- Điểm nổi bật: nhiều chiều sâu hơn plugin trình duyệt nhưng không buộc bạn phải viết code.
- Lưu ý: sự linh hoạt này đi kèm đường cong học tập dốc hơn so với các công cụ ưu tiên AI.
- Tín hiệu giá: gói miễn phí, Standard từ $69/tháng, các tầng trả phí cao hơn.
Nếu bạn muốn đánh giá một không gian làm việc no-code truyền thống hơn trước khi đầu tư vào bộ công cụ ưu tiên AI, tổng quan chính thức của Octoparse này vẫn rất hữu ích:
4. ParseHub
ParseHub vẫn còn giá trị vì có rất nhiều đội ngũ muốn logic tác vụ từng bước hơn là một AI scraper nhẹ. Sản phẩm này không phải là đẹp nhất trong nhóm, nhưng vẫn rất linh hoạt.
- Phù hợp nhất cho: nhà nghiên cứu, nhà báo và người không viết code nhưng có nền tảng kỹ thuật, chấp nhận thiết lập nhiều hơn.
- Điểm nổi bật: logic điều kiện và kiểm soát điều hướng mạnh hơn nhiều công cụ dành cho người mới.
- Lưu ý: học chậm hơn và cảm giác ít hiện đại hơn các sản phẩm mới.
- Tín hiệu giá: gói miễn phí, các gói trả phí từ $189/tháng.
5. Web Scraper
Web Scraper là một trong những lựa chọn gọn gàng nhất để “học cách cơ bản mà không cần mua cả một nền tảng.” Nếu bạn thích mô hình sitemap, đây vẫn là một điểm khởi đầu hợp lý.
- Phù hợp nhất cho: người mới, dự án cá nhân và các tác vụ nhỏ chạy qua trình duyệt.
- Điểm nổi bật: thiết lập đơn giản và dễ chuyển từ tiện ích cục bộ sang gói cloud.
- Lưu ý: sẽ trở nên hạn chế khi bạn cần logic thích ứng tốt hơn hoặc khả năng vượt chặn mạnh hơn.
- Tín hiệu giá: tiện ích miễn phí, Cloud từ $50/tháng.
6. Browse AI
Browse AI vẫn là lựa chọn mạnh khi vừa cần thu thập vừa cần giám sát. Mô hình robot của nó rất trực quan với người dùng kinh doanh, những người nghĩ theo kiểu “hãy theo dõi trang này và báo cho tôi khi có thay đổi.”
- Phù hợp nhất cho: giám sát đối thủ, theo dõi giá và các đội ngũ ưu tiên bảng tính.
- Điểm nổi bật: onboarding mượt, giám sát lặp lại và đầu ra thân thiện với tự động hóa.
- Lưu ý: các tác vụ phức tạp, khối lượng lớn có thể tốn kém nhanh hơn các bộ công cụ ưu tiên API.
- Tín hiệu giá: gói miễn phí, các gói trả phí, gói quản lý.
Với các đội ngũ đánh giá việc giám sát trang thay vì trích xuất một lần, video tổng quan chính thức ngắn này vẫn là một tín hiệu tốt để kiểm tra:
7. Bardeen
Bardeen không tập trung quá nhiều vào độ sâu thu thập dữ liệu thuần túy mà tập trung vào điều gì xảy ra sau khi thu thập xong. Nó mạnh nhất khi trích xuất web chỉ là một bước trong một quy trình tự động hóa trình duyệt lớn hơn.
- Phù hợp nhất cho: ops GTM, định tuyến lead, chuyển sang CRM và tự động hóa ngay trong trình duyệt.
- Điểm nổi bật: câu chuyện tự động hóa quy trình rất mạnh xoay quanh chính thao tác thu thập.
- Lưu ý: không phải lựa chọn sạch nhất khi độ chính xác trích xuất là điều duy nhất quan trọng.
- Tín hiệu giá: gói miễn phí, Basic từ $10/tháng, các tầng Premium và Enterprise.
8. ScrapeStorm
ScrapeStorm vẫn lấp đầy khoảng giữa khá hữu ích cho những người muốn có hỗ trợ AI nhưng vẫn kỳ vọng một môi trường thu thập dữ liệu trực quan truyền thống hơn.
- Phù hợp nhất cho: thu thập thư mục, thu thập trang ecommerce và các tác vụ định kỳ được cấu hình bằng hình ảnh.
- Điểm nổi bật: dễ bắt đầu hơn nhiều công cụ trực quan đời cũ.
- Lưu ý: ít tinh chỉnh hơn so với các leader trong phân khúc và có thể thấy hạn chế hơn trên những trang khó.
- Tín hiệu giá: dùng thử miễn phí, các gói trả phí, giá doanh nghiệp.

API thu thập dữ liệu tốt nhất khi quy mô và chống bot là điều quan trọng
Đây là nhóm nên chuyển sang khi ràng buộc thực sự không còn là “tôi chọn dữ liệu như thế nào?” nữa mà thành “tôi làm sao giữ cho nó ổn định khi tải lớn?”
9. ScraperAPI
ScraperAPI vẫn là một trong những sản phẩm API-first dễ tiếp cận nhất cho nhà phát triển muốn ngừng bận tâm về proxy và tỷ lệ thành công của request.
- Phù hợp nhất cho: nhà phát triển cần mở rộng từ prototype lên production nhanh.
- Điểm nổi bật: API đơn giản cộng với hỗ trợ proxy, CAPTCHA và hiển thị trang.
- Lưu ý: bạn vẫn phải tự lo phần phân tích dữ liệu, cơ chế thử lại và chất lượng dữ liệu đầu ra.
- Tín hiệu giá: dùng thử 7 ngày, trả phí từ $49/tháng.
10. Bright Data Web Scraper
Bright Data là lựa chọn nặng ký khi khả năng vượt chặn, kho proxy, tư thế tuân thủ và các tùy chọn quản lý quan trọng hơn sự đơn giản.
- Phù hợp nhất cho: thu thập ở quy mô doanh nghiệp và các chương trình nhạy cảm về tuân thủ.
- Điểm nổi bật: bộ công cụ rộng nhất trong so sánh này, từ proxy đến các sản phẩm thu thập được quản lý.
- Lưu ý: rất dễ mua quá tay nếu quy trình của đội ngũ bạn vẫn còn khá đơn giản.
- Tín hiệu giá: giá theo sản phẩm và theo mức sử dụng.
11. Zyte
Zyte vẫn là một lựa chọn nghiêm túc cho đội ngũ phát triển muốn có thao tác trình duyệt, hiển thị JS, xoay IP và tư thế chống bot trong cùng một câu chuyện nền tảng.
- Phù hợp nhất cho: các chương trình thu thập do kỹ sư dẫn dắt và hệ thống trích xuất lặp lại.
- Điểm nổi bật: bộ chống phát hiện mạnh và quy trình ưu tiên API.
- Lưu ý: phù hợp hơn với đội ngũ có quyền sở hữu kỹ thuật so với người dùng kinh doanh.
- Tín hiệu giá: tín dụng dùng thử $5, các gói tính theo mức sử dụng.
12. ZenRows
ZenRows là một trong những trải nghiệm nhà phát triển gọn gàng nhất trong nhóm API nếu bạn muốn xử lý chống bot mà không phải đi qua quy trình mua sắm kiểu doanh nghiệp.
- Phù hợp nhất cho: startup, nhà phát triển và các nhóm công cụ nội bộ gọn nhẹ.
- Điểm nổi bật: mức độ tiếp cận tương đối thấp cộng với định vị chống bot mạnh.
- Lưu ý: vẫn là một sản phẩm API, nên bạn vẫn phải tự quản logic ứng dụng và khâu QA.
- Tín hiệu giá: dùng thử miễn phí, Developer từ $69/tháng.
13. ScrapingBee
ScrapingBee hợp lý khi nhu cầu thực sự của bạn là một trang đã được hiển thị và ít phải lo hạ tầng hơn, đặc biệt với các trang nhiều JavaScript.
- Phù hợp nhất cho: nhà phát triển thu thập các trang động và muốn giảm tải phần hiển thị.
- Điểm nổi bật: API đơn giản xoay quanh duyệt không giao diện và proxy.
- Lưu ý: nó giúp giảm gánh hạ tầng, chứ không thay thế nhu cầu có logic thu thập tốt.
- Tín hiệu giá: dùng thử miễn phí, trả phí từ $49/tháng.
Các thư viện thu thập dữ liệu web Python tốt nhất cho stack tùy biến
Nhóm này vẫn là câu trả lời đúng khi kiểm soát quan trọng hơn sự tiện lợi và đội ngũ của bạn sẵn sàng tự chịu trách nhiệm bảo trì.
14. Selenium
Selenium không phải công cụ trình duyệt mới nhất, nhưng nó vẫn còn phù hợp ở nơi mà độ chính xác của tương tác người dùng quan trọng hơn thông lượng thu thập thuần túy.
- Phù hợp nhất cho: luồng nhiều tương tác, giao thoa với QA và các trang mà hành vi trình duyệt là thách thức chính.
- Điểm nổi bật: hệ sinh thái trưởng thành và hỗ trợ trình duyệt rộng.
- Lưu ý: nặng và chậm hơn các stack tự động hóa mới hơn trong nhiều khối lượng thu thập.
- Tín hiệu giá: miễn phí và mã nguồn mở.
15. Beautiful Soup

Beautiful Soup vẫn là trình phân tích cú pháp dễ dùng nhất trong stack thu thập Python. Nó không phải một nền tảng thu thập hoàn chỉnh, nhưng vẫn là cách đơn giản nhất để biến HTML lộn xộn thành cấu trúc có thể dùng được.
- Phù hợp nhất cho: tác vụ Python nhẹ, trang HTML tĩnh và nguyên mẫu nhanh.
- Điểm nổi bật: ít gây quá tải nhận thức và khả năng phân tích khoan dung.
- Lưu ý: hãy ghép với
requests, một lớp trình duyệt hoặc một crawler; bản thân nó chỉ phân tích cú pháp. - Tín hiệu giá: miễn phí và mã nguồn mở.
16. Playwright
Playwright là khuyến nghị hiện đại mặc định của tôi cho các đội ngũ phát triển cần tự động hóa trình duyệt mạnh mẽ trên web ngày nay.
- Phù hợp nhất cho: các trang nhiều JavaScript, tự động hóa trình duyệt hiện đại và đội ngũ đã quen viết code.
- Điểm nổi bật: hành vi chờ đợi mạnh, hỗ trợ đa trình duyệt và API gọn.
- Lưu ý: bạn vẫn phải tự lo đồng thời hóa, bộ chọn, hạ tầng trình duyệt và xác thực dữ liệu.
- Tín hiệu giá: miễn phí và mã nguồn mở.
17. urllib3
urllib3 có mặt trong danh sách vì một số đội ngũ muốn kiểm soát trực tiếp hành vi truyền tải hơn là dùng lớp trừu tượng cấp cao hơn. Nó không phải là scraper thân thiện cho người mới, nhưng là một thư viện nền tảng hữu ích khi bạn đang tự xây stack của riêng mình.
- Phù hợp nhất cho: nhà phát triển muốn kiểm soát chặt cơ chế thử lại, proxy, session và hành vi HTTP.
- Điểm nổi bật: nhẹ, đáng tin cậy và được dùng rộng rãi như một phần hạ tầng.
- Lưu ý: bạn đang tự xây phần lớn của stack.
- Tín hiệu giá: miễn phí và mã nguồn mở.
Các công cụ thu thập dữ liệu web miễn phí đáng thử trước
Nếu bạn muốn thử trước khi mua, những điểm khởi đầu miễn phí tốt nhất trong danh sách này là Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright và urllib3. Trải nghiệm miễn phí đủ tốt để bạn hiểu mình thực sự cần kiểu scraper nào, và điều đó thường quan trọng hơn việc ám ảnh với một checklist tính năng hoàn hảo ngay từ ngày đầu.
Danh sách ngắn của tôi theo loại đội ngũ

- Đội ngũ sales, ops và ecommerce: bắt đầu với Thunderbit, rồi so sánh với Browse AI nếu giám sát quan trọng hơn làm giàu dữ liệu từ trang con.
- Nhà phân tích và người vận hành thủ công định kỳ: Octoparse trước, rồi ParseHub nếu bạn cần logic tác vụ tùy biến hơn.
- Đội ngũ tự động hóa GTM: Bardeen nếu dữ liệu cần đi thẳng vào CRM, Sheets hoặc quy trình trình duyệt.
- Đội ngũ phát triển xây công cụ nội bộ: ScraperAPI, ZenRows, Zyte hoặc Playwright tùy vào mức độ bạn muốn tự nắm stack.
- Chương trình dữ liệu doanh nghiệp: Bright Data và Zyte là những cuộc trao đổi hạ tầng nghiêm túc hơn ở đây, còn Kadoa là lựa chọn dẫn dắt bằng AI khi mục tiêu chính là giảm bảo trì.
Khi nào nên chuyển xuống tầng công nghệ sâu hơn
Hãy dùng lộ trình nâng cấp này:
- Giữ nguyên công cụ thu thập dữ liệu web AI cho đến khi bạn chạm giới hạn về tính lặp lại hoặc các trường hợp ngoại lệ.
- Chuyển sang trình dựng no-code khi lập lịch, phân trang và chạy trên cloud quan trọng hơn sự đơn giản một cú nhấp.
- Chuyển sang API khi tỷ lệ vượt chặn, hiển thị trang và chạy đồng thời trở thành nút thắt.
- Chuyển sang thư viện Python khi chi phí trừu tượng hóa của nhà cung cấp cao hơn việc tự nắm toàn bộ hệ thống.
Phần lớn đội ngũ đi theo thứ tự sai. Họ xây quá mức trước rồi sau đó mới nhận ra một công cụ nhẹ hơn đã có thể giải quyết đúng quy trình.
Kết luận cuối
Công cụ thu thập dữ liệu web tốt nhất năm 2026 không phải là công cụ có danh sách tính năng dài nhất. Đó là công cụ đưa dữ liệu chính xác vào quy trình tiếp theo với chi phí bảo trì thấp nhất cho đội ngũ của bạn. Đó là lý do các công cụ ưu tiên AI vẫn thắng cho người vận hành, các công cụ no-code vẫn có giá trị cho tác vụ trình duyệt lặp lại, API thống trị khi quy mô và chặn bot là vấn đề, còn thư viện Python vẫn nắm phần cuối của stack nơi cần kiểm soát cao.
Nếu mục tiêu của bạn là có dữ liệu hữu ích trong tuần này, hãy bắt đầu đơn giản. Nếu khối lượng công việc đã cho thấy rõ rằng tỷ lệ vượt chặn, hiển thị trình duyệt và quyền kiểm soát kỹ thuật là vấn đề thật sự, hãy đi xuống tầng công nghệ một cách có chủ đích thay vì làm theo thói quen.
Bắt đầu với scraper nhẹ nhất nhưng vẫn làm được việc Get Started Free
Câu hỏi thường gặp
1. Công cụ thu thập dữ liệu web nào tốt nhất cho người không rành kỹ thuật vào năm 2026?
Với đa số đội ngũ không rành kỹ thuật, các công cụ ưu tiên AI như Thunderbit và Browse AI vẫn là con đường nhanh nhất vì chúng giảm thời gian thiết lập, công việc với bộ chọn và gánh nặng bảo trì.
2. Tôi nên chọn gì cho các trang nhiều JavaScript hoặc được bảo vệ chống bot?
Đó thường là lúc ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright hoặc Selenium bắt đầu hợp lý hơn các tiện ích trình duyệt.
3. Công cụ thu thập dữ liệu no-code còn phù hợp không khi scraper AI đã tốt hơn?
Có. Octoparse, ParseHub, Web Scraper và Browse AI vẫn rất quan trọng khi bạn cần kiểm soát tác vụ rõ ràng hơn, chạy định kỳ hoặc gỡ lỗi trực quan trên trình duyệt.
4. Những công cụ nào hợp nhất cho đội ngũ phát triển?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup và urllib3 là những lựa chọn tự nhiên nhất khi kỹ sư sở hữu quy trình.
Đọc thêm




