
Dự án scraping đầu tiên của mình đúng kiểu “tự lực cánh sinh”: một script Python tự viết, xài chung proxy, và… 기도 (cầu nguyện). Cứ tầm ba ngày là nó lại “toang” một phát cho nhớ đời.
Nhưng tới năm 2026 thì mọi thứ đã khác hẳn. Các api thu thập dữ liệu giờ gần như gánh trọn phần “khó nhằn” — proxy, render, CAPTCHA, retry — để bạn khỏi phải đau đầu. Chúng trở thành nền móng cho đủ thứ: từ theo dõi giá, thu thập dữ liệu thị trường, cho tới pipeline dữ liệu huấn luyện AI.
Có một điểm đáng chú ý nữa: các công cụ chạy bằng AI như Thunderbit đang khiến nhiều tình huống “bắt buộc phải dùng API” trở nên… không còn cần thiết, nhất là với người không biết code. Mình sẽ nói kỹ ở phần dưới.
Dưới đây là 10 API scraping mà mình đã dùng hoặc đánh giá — mỗi cái mạnh ở đâu, yếu ở đâu, và khi nào bạn thậm chí không cần API.
Vì sao nên cân nhắc Thunderbit AI thay vì các API Web Scraping truyền thống?
Trước khi vào danh sách API, phải nói về “con voi trong phòng”: tự động hóa bằng AI. Mình đã dành nhiều năm giúp các đội nhóm tự động hóa những việc lặp lại nhàm chán, và mình có thể khẳng định: có lý do ngày càng nhiều doanh nghiệp bỏ qua các API nặng code để chuyển thẳng sang AI agent như Thunderbit.
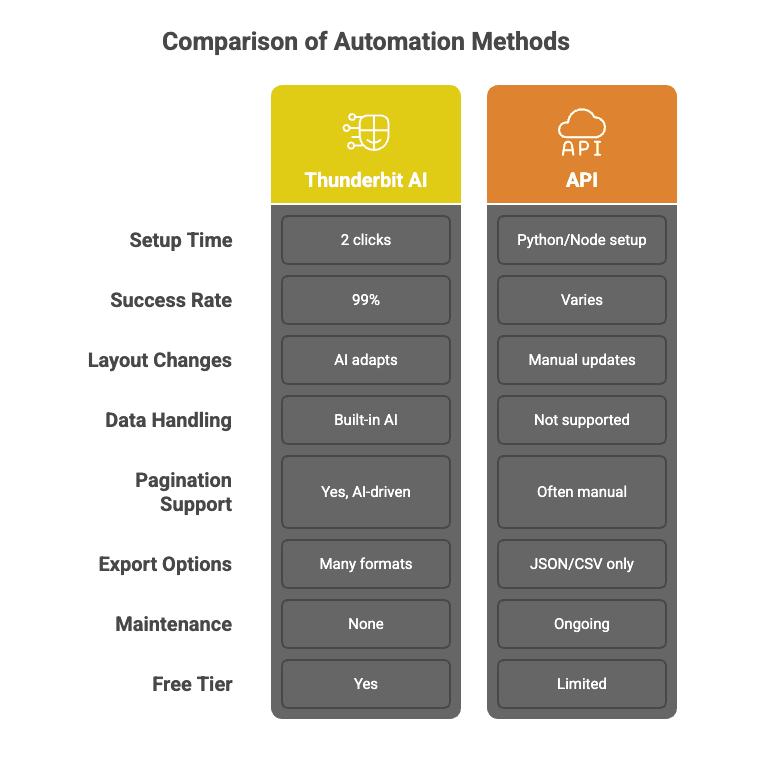
Điều khiến Thunderbit khác biệt so với API scraping truyền thống:
-
Gọi API theo kiểu “waterfall” để đạt tỷ lệ thành công 99%
AI của Thunderbit không phải kiểu gọi một lần rồi “hên xui”. Nó dùng mô hình waterfall — tự chọn phương pháp scraping phù hợp nhất cho từng tác vụ, tự retry khi cần, và hướng tới tỷ lệ thành công 99%. Bạn nhận được dữ liệu, chứ không phải nhận thêm drama.
-
Không cần code, thiết lập chỉ hai cú nhấp
Quên chuyện viết script Python hay đọc tài liệu API dài như truyện chương hồi. Với Thunderbit, bạn chỉ cần bấm “AI Suggest Fields” rồi bấm “Scrape”. Xong. Mẹ mình cũng dùng được (dù bà vẫn nghĩ “đám mây” là kiểu thời tiết xấu).
-
Scrape hàng loạt: nhanh và chuẩn
Mô hình AI của Thunderbit có thể xử lý song song hàng nghìn website khác nhau, tự thích nghi theo từng layout ngay khi chạy. Cảm giác như có cả đội thực tập sinh — chỉ khác là họ không xin nghỉ đi uống cà phê.
-
Không phải bảo trì
Website đổi liên tục. API truyền thống? Dễ gãy. Thunderbit? AI đọc trang “mới tinh” mỗi lần chạy, nên bạn không phải cập nhật code khi site đổi bố cục hay thêm nút mới.
-
Trích xuất dữ liệu theo nhu cầu & xử lý sau trích xuất
Cần làm sạch, gắn nhãn, dịch, hay tóm tắt dữ liệu? Thunderbit làm luôn trong quá trình trích xuất — kiểu như ném 10.000 trang web vào ChatGPT và nhận lại một bộ dữ liệu được cấu trúc gọn gàng.
-
Scrape trang con & phân trang
AI của Thunderbit có thể tự theo link, xử lý phân trang, thậm chí làm giàu bảng dữ liệu bằng thông tin từ các trang con — không cần viết code tùy biến.
-
Xuất dữ liệu miễn phí & tích hợp đa nền tảng
Xuất sang Excel, Google Sheets, Airtable, Notion, hoặc tải CSV/JSON — không khóa tính năng, không “lắt léo”.
So sánh nhanh để bạn hình dung rõ hơn:
Muốn xem chạy thực tế? Thử ngay Thunderbit Chrome Extension.
API thu thập dữ liệu (Data Scraping API) là gì?
Quay lại nền tảng một chút. API thu thập dữ liệu là công cụ cho phép bạn trích xuất dữ liệu từ website theo cách lập trình — mà không cần tự build scraper từ đầu. Cứ tưởng tượng nó như một “robot” bạn sai đi lấy giá mới nhất, review, hoặc danh sách sản phẩm, rồi nó trả về dữ liệu ở dạng có cấu trúc (thường là JSON hoặc CSV).
Chúng hoạt động thế nào? Phần lớn API scraping sẽ xử lý những thứ “bẩn và khó” — xoay proxy, giải CAPTCHA, render JavaScript — để bạn tập trung vào thứ quan trọng nhất: dữ liệu. Bạn gửi request (thường gồm URL và vài tham số), API trả về nội dung đã sẵn sàng đưa vào quy trình vận hành.
Lợi ích chính:
- Tốc độ: API có thể scrape hàng nghìn trang mỗi phút.
- Khả năng mở rộng: Theo dõi 10.000 sản phẩm? No problem.
- Tích hợp: Kết nối vào CRM, BI, hoặc data warehouse khá nhẹ nhàng.
Nhưng như bạn sẽ thấy, không phải API nào cũng “ngon” như nhau — và cũng không phải cái nào cũng đúng kiểu “cài một lần chạy mãi” như quảng cáo.
Tôi đánh giá các API này như thế nào
Mình đã “lăn lộn chiến trường” khá lâu — test, làm hỏng, và đôi khi vô tình DDoS chính server của mình (đừng kể với đội IT cũ của mình). Với danh sách này, mình tập trung vào:
- Độ ổn định: Có chạy được thật không, kể cả với site khó?
- Tốc độ: Khi chạy quy mô lớn thì trả kết quả nhanh cỡ nào?
- Giá: Có hợp túi tiền startup và mở rộng được cho doanh nghiệp lớn không?
- Khả năng scale: Chịu được hàng triệu request hay “ngã” ở mốc 100?
- Thân thiện với dev: Tài liệu có rõ không? Có SDK và ví dụ code không?
- Hỗ trợ: Khi mọi thứ lệch nhịp (và chắc chắn sẽ có), có ai support không?
- Phản hồi người dùng: Review thực tế, không phải lời marketing.
Mình cũng dựa nhiều vào trải nghiệm dùng thật, phân tích đánh giá, và phản hồi từ cộng đồng Thunderbit (tụi mình khá khó tính, kiểu 깐깐).
10 API đáng cân nhắc trong năm 2026
Vào phần chính: đây là danh sách cập nhật các API và nền tảng web scraping tốt nhất cho người dùng doanh nghiệp lẫn developer trong năm 2026.
1. Oxylabs
 Tổng quan:
Tổng quan:
Oxylabs là “hạng nặng” cho nhu cầu trích xuất dữ liệu web cấp doanh nghiệp. Với pool proxy cực lớn và các API chuyên biệt cho đủ thứ từ SERP đến e-commerce, đây là lựa chọn quen thuộc của Fortune 500 và những ai cần độ tin cậy ở quy mô lớn.
Tính năng nổi bật:
- Mạng proxy khổng lồ (residential, datacenter, mobile, ISP) tại 195+ quốc gia
- API scraper có chống bot, giải CAPTCHA, render headless browser
- Nhắm mục tiêu theo vị trí, giữ session, độ chính xác dữ liệu cao (tỷ lệ thành công 95%+)
- OxyCopilot: trợ lý AI tự tạo truy vấn API và code parsing
Giá:
Từ khoảng ~$49/tháng cho một API, $149/tháng cho gói all-in-one. Có trial 7 ngày với tối đa 5.000 request.
Phản hồi người dùng:
Được chấm 4.8/5 trên G2, nổi bật về độ ổn định và hỗ trợ. Điểm trừ lớn nhất: giá cao, nhưng “tiền nào của nấy”.
2. ScrapingBee
 Tổng quan:
Tổng quan:
ScrapingBee đúng kiểu “bạn thân của developer” — gọn, dễ xài, giá dễ chịu, tập trung đúng trọng tâm. Bạn gửi URL, nó lo headless Chrome, proxy, CAPTCHA, rồi trả về trang đã render hoặc dữ liệu bạn cần.
Tính năng nổi bật:
- Render bằng headless browser (hỗ trợ JavaScript)
- Tự xoay IP và giải CAPTCHA
- Proxy stealth cho các site khó
- Thiết lập tối giản — chỉ cần gọi API
Giá:
Có gói miễn phí khoảng ~1.000 lượt gọi/tháng. Gói trả phí từ ~$29/tháng cho 5.000 request.
Phản hồi người dùng:
Thường xuyên đạt 4.8/5 trên G2. Dev thích vì đơn giản; người không biết code có thể thấy hơi “trống trải”.
3. Apify
 Tổng quan:
Tổng quan:
Apify giống “dao đa năng Thụy Sĩ” của web scraping. Bạn có thể tự build scraper (“Actors”) bằng JavaScript hoặc Python, hoặc dùng thư viện actor dựng sẵn cực lớn cho các website phổ biến. Linh hoạt tới mức kiểu “cần gì cũng có đường”.
Tính năng nổi bật:
- Scraper tùy biến và dựng sẵn (Actors) cho gần như mọi site
- Hạ tầng cloud, lịch chạy, quản lý proxy tích hợp sẵn
- Xuất dữ liệu ra JSON, CSV, Excel, Google Sheets, v.v.
- Cộng đồng năng động và hỗ trợ qua Discord
Giá:
Có gói miễn phí vĩnh viễn với $5/tháng credit. Gói trả phí từ $39/tháng.
Phản hồi người dùng:
4.7+ trên G2/Capterra. Dev mê vì linh hoạt; người mới sẽ gặp đường cong học tập (hơi “ngợp” lúc đầu).
4. Decodo (trước đây là Smartproxy)
 Tổng quan:
Tổng quan:
Decodo (đổi tên từ Smartproxy) tập trung vào tiêu chí “dễ dùng và đáng tiền”. Họ kết hợp hạ tầng proxy mạnh với scraping API cho web tổng quát, SERP, e-commerce và mạng xã hội — gói gọn trong một subscription.
Tính năng nổi bật:
- Một scraping API dùng chung cho mọi endpoint (không cần mua add-on lẻ)
- Scraper chuyên dụng cho Google, Amazon, TikTok, v.v.
- Dashboard thân thiện, có playground và trình tạo code
- Hỗ trợ live chat 24/7
Giá:
Từ khoảng ~$50/tháng cho 25.000 request. Trial 7 ngày với 1.000 request.
Phản hồi người dùng:
Được khen “đáng tiền” và hỗ trợ nhanh. 4.7/5 trên G2.
5. Octoparse
 Tổng quan:
Tổng quan:
Octoparse là “quán quân no-code”. Nếu bạn ghét code nhưng vẫn cần dữ liệu, ứng dụng desktop dạng point-and-click này (kèm tính năng cloud) cho phép bạn dựng scraper trực quan và chạy local hoặc trên cloud.
Tính năng nổi bật:
- Trình dựng workflow trực quan — click để chọn trường dữ liệu
- Trích xuất trên cloud, lên lịch chạy, tự xoay IP
- Template cho các site phổ biến và marketplace cho scraper tùy chỉnh
- Octoparse AI: kết hợp RPA và ChatGPT để làm sạch dữ liệu và tự động hóa quy trình
Giá:
Gói miễn phí tối đa 10 tác vụ chạy local. Gói trả phí từ $119/tháng (tính năng cloud, tác vụ không giới hạn). Trial 14 ngày cho tính năng premium.
Phản hồi người dùng:
4.4/5 trên G2. Người không biết code rất thích, nhưng người dùng nâng cao có thể gặp giới hạn.
6. Bright Data
 Tổng quan:
Tổng quan:
Bright Data là “ông lớn” — nếu bạn cần quy mô, tốc độ, và đủ mọi tính năng, đây là nền tảng hợp bài. Sở hữu mạng proxy lớn nhất thế giới và IDE scraping mạnh, sản phẩm hướng tới doanh nghiệp.
Tính năng nổi bật:
- 150M+ IP (residential, mobile, ISP, datacenter)
- Web Scraper IDE, data collector dựng sẵn, và dataset mua sẵn
- Chống bot nâng cao, giải CAPTCHA, hỗ trợ headless browser
- Tập trung vào tuân thủ và pháp lý (Ethical Web Data initiative)
Giá:
Trả theo dùng: khoảng ~$1.05 mỗi 1.000 request, proxy từ $3–$15/GB. Có trial cho đa số sản phẩm.
Phản hồi người dùng:
Được khen về hiệu năng và tính năng, nhưng giá và độ phức tạp có thể là rào cản với team nhỏ.
Xem các sản phẩm của Bright Data
7. WebAutomation
 Tổng quan:
Tổng quan:
WebAutomation là nền tảng cloud dành cho người không phải developer. Với marketplace extractor dựng sẵn và trình tạo no-code, đây là lựa chọn hợp lý cho người dùng business muốn có dữ liệu nhanh, không muốn đụng code.
Tính năng nổi bật:
- Extractor dựng sẵn cho các site phổ biến (Amazon, Zillow, v.v.)
- Trình tạo extractor no-code dạng point-and-click
- Lên lịch chạy trên cloud, giao dữ liệu, và bảo trì do nền tảng xử lý
- Tính phí theo số dòng (trả theo lượng dữ liệu trích xuất)
Giá:
Gói Project $74/tháng (~400k dòng/năm), pay-as-you-go $1 mỗi 1.000 dòng. Trial 14 ngày với 10 triệu credit.
Phản hồi người dùng:
Người dùng thích vì dễ dùng và giá minh bạch. Hỗ trợ tốt, phần bảo trì do đội ngũ xử lý.
8. ScrapeHero
 Tổng quan:
Tổng quan:
ScrapeHero khởi đầu là dịch vụ tư vấn scraping theo yêu cầu, sau đó phát triển thành nền tảng cloud tự phục vụ. Bạn có thể dùng scraper dựng sẵn cho các site phổ biến hoặc đặt dự án được quản lý trọn gói.
Tính năng nổi bật:
- ScrapeHero Cloud: scraper dựng sẵn cho Amazon, Google Maps, LinkedIn, v.v.
- Vận hành no-code, lên lịch, và giao dữ liệu qua cloud
- Giải pháp tùy chỉnh cho nhu cầu đặc thù
- Có API để tích hợp theo kiểu lập trình
Giá:
Gói cloud từ $5/tháng. Dự án tùy chỉnh từ $550 mỗi site (một lần).
Phản hồi người dùng:
Được khen về độ ổn định, chất lượng dữ liệu và hỗ trợ. Hợp khi bạn muốn nâng cấp từ tự làm sang dịch vụ quản lý.
9. Sequentum
 Tổng quan:
Tổng quan:
Sequentum là “dao đa năng” cho doanh nghiệp — tối ưu cho tuân thủ, khả năng audit, và quy mô cực lớn. Nếu bạn cần SOC-2, audit trail, và cộng tác theo nhóm, đây là lựa chọn đáng cân nhắc.
Tính năng nổi bật:
- Trình thiết kế agent low-code (point-and-click + scripting)
- Triển khai dạng SaaS cloud hoặc on-premise
- Quản lý proxy, giải CAPTCHA, headless browser tích hợp
- Audit trail, phân quyền theo vai trò, tuân thủ SOC-2
Giá:
Pay-as-you-go ($6/giờ runtime, $0.25/GB export), gói Starter $199/tháng. Tặng $5 credit khi đăng ký.
Phản hồi người dùng:
Doanh nghiệp thích vì tính năng tuân thủ và khả năng mở rộng. Ban đầu hơi “khó vào form”, nhưng hỗ trợ và đào tạo rất ổn.
10. Grepsr
 Tổng quan:
Tổng quan:
Grepsr là dịch vụ trích xuất dữ liệu dạng managed — bạn chỉ cần nói bạn muốn gì, họ sẽ build, chạy và bảo trì scraper giúp bạn. Rất hợp với doanh nghiệp muốn có dữ liệu mà không muốn vướng kỹ thuật.
Tính năng nổi bật:
- Dịch vụ managed (“Grepsr Concierge”) — họ thiết lập và bảo trì toàn bộ
- Dashboard cloud để lên lịch, theo dõi, tải dữ liệu
- Nhiều định dạng đầu ra và tích hợp (Dropbox, S3, Google Drive)
- Tính phí theo bản ghi dữ liệu (không tính theo request)
Giá:
Gói Starter $350 (trích xuất một lần), subscription định kỳ báo giá theo nhu cầu.
Phản hồi người dùng:
Khách hàng thích vì gần như “giao khoán”, hỗ trợ phản hồi nhanh. Hợp với team không kỹ thuật và những ai ưu tiên tiết kiệm thời gian hơn là mày mò.
Bảng so sánh nhanh: Top API Web Scraping
Đây là “phao cứu sinh” tóm tắt cả 10 nền tảng:
| Nền tảng | Loại dữ liệu hỗ trợ | Giá khởi điểm | Dùng thử miễn phí | Dễ sử dụng | Hỗ trợ | Điểm nổi bật |
|---|---|---|---|---|---|---|
| Oxylabs | Web, SERP, e-com, bất động sản | $49/tháng | 7 ngày/5k req | Thiên về dev | 24/7, enterprise | OxyCopilot AI, proxy cực lớn, nhắm mục tiêu theo vị trí |
| ScrapingBee | Web tổng quát, JS, CAPTCHA | $29/tháng | 1k lượt gọi/tháng | API đơn giản | Email, forum | Headless Chrome, proxy stealth |
| Apify | Mọi loại web, dựng sẵn/tùy biến | Miễn phí/$39/tháng | Miễn phí vĩnh viễn | Linh hoạt, hơi phức tạp | Cộng đồng, Discord | Marketplace Actor, hạ tầng cloud, tích hợp |
| Decodo | Web, SERP, e-com, social | $50/tháng | 7 ngày/1k req | Thân thiện | Live chat 24/7 | API hợp nhất, playground tạo code, đáng tiền |
| Octoparse | Mọi loại web, no-code | Miễn phí/$119/tháng | 14 ngày | Trực quan, no-code | Email, forum | UI point-and-click, cloud, Octoparse AI |
| Bright Data | Toàn web, datasets | $1.05/1k req | Có | Mạnh nhưng phức tạp | 24/7, enterprise | Mạng proxy lớn nhất, IDE, dataset sẵn |
| WebAutomation | Dữ liệu có cấu trúc, e-com, bất động sản | $74/tháng | 14 ngày/10M dòng | No-code, có template | Email, chat | Extractor dựng sẵn, tính phí theo dòng |
| ScrapeHero | E-com, maps, việc làm, tùy chỉnh | $5/tháng | Có | No-code, managed | Email, ticket | Scraper cloud, dự án tùy chỉnh, giao qua Dropbox |
| Sequentum | Mọi loại web, enterprise | $0/$199/tháng | $5 credit | Low-code, trực quan | Hỗ trợ sát sao | Audit trail, SOC-2, on-prem/cloud |
| Grepsr | Dữ liệu có cấu trúc, managed | $350 (một lần) | Chạy mẫu | Managed hoàn toàn | Đại diện riêng | Concierge thiết lập, tính theo dữ liệu, tích hợp |
Chọn công cụ Web Scraping phù hợp cho doanh nghiệp của bạn
Vậy rốt cuộc nên chọn cái nào? Đây là cách mình thường tư vấn cho các team:
-
Nếu bạn muốn không cần code, có kết quả ngay, và làm sạch dữ liệu bằng AI:
Chọn Thunderbit. Đây là con đường nhanh nhất từ “tôi cần dữ liệu” đến “tôi đã có dữ liệu” — và bạn không phải canh script hay API.
-
Nếu bạn là developer thích kiểm soát và linh hoạt:
Thử Apify, ScrapingBee, hoặc Oxylabs. Bạn sẽ có nhiều quyền lực hơn, nhưng cũng phải tự xử lý một phần thiết lập và bảo trì.
-
Nếu bạn là người dùng business muốn công cụ trực quan:
WebAutomation rất hợp cho kiểu point-and-click, đặc biệt với e-commerce và lead gen.
-
Nếu bạn cần tuân thủ, audit, hoặc tính năng cấp doanh nghiệp:
Sequentum sinh ra cho nhu cầu này. Giá cao hơn, nhưng đáng tiền với ngành bị quản lý chặt.
-
Nếu bạn muốn “giao cho người khác làm hết”:
Grepsr hoặc dịch vụ managed của ScrapeHero là lựa chọn phù hợp. Bạn trả thêm một chút, đổi lại đỡ đau đầu.
Nếu vẫn phân vân, đa số nền tảng đều có trial — cứ test vài vòng để chốt cái hợp nhất.
Điểm rút ra quan trọng
- API web scraping đang trở thành hạ tầng thiết yếu cho doanh nghiệp dựa trên dữ liệu — thị trường được dự báo chạm mốc 1,8 tỷ USD vào năm 2030.
- Scrape thủ công đã lỗi thời — với chống bot, proxy, và website đổi liên tục, chỉ có API và công cụ AI mới mở rộng quy mô hiệu quả.
- Mỗi API/nền tảng có thế mạnh riêng:
- Oxylabs và Bright Data cho quy mô và độ ổn định
- Apify cho tính linh hoạt
- Decodo cho “đáng tiền”
- WebAutomation cho no-code
- Sequentum cho tuân thủ
- Grepsr cho dịch vụ managed “khỏi lo kỹ thuật”
- Tự động hóa bằng AI (như Thunderbit) đang thay đổi cuộc chơi — tỷ lệ thành công cao hơn, không cần bảo trì, và xử lý dữ liệu tích hợp mà API truyền thống khó theo kịp.
- Công cụ tốt nhất là công cụ hợp với quy trình, ngân sách và kỹ năng kỹ thuật của bạn. Đừng ngại thử nghiệm.
Nếu bạn muốn tạm biệt những script hay gãy và chuỗi ngày debug bất tận, hãy thử Thunderbit — hoặc xem thêm các hướng dẫn trên Thunderbit Blog để đào sâu về scrape Amazon, Google, PDF, và nhiều chủ đề khác.
Và nhớ nha: trong thế giới dữ liệu web, thứ đổi nhanh hơn cả website chính là công nghệ mình dùng để scrape. Cứ tò mò, cứ tự động hóa — và mong rằng proxy của bạn sẽ không bao giờ bị chặn (제발).




