Wikipedia Search Result Scraper
อยากดึงข้อมูลแบบจำนวนมากใช่ไหม? ลองใช้ Thunderbit ฟรี








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
Collect Topic Data from Wikipedia Search Pages

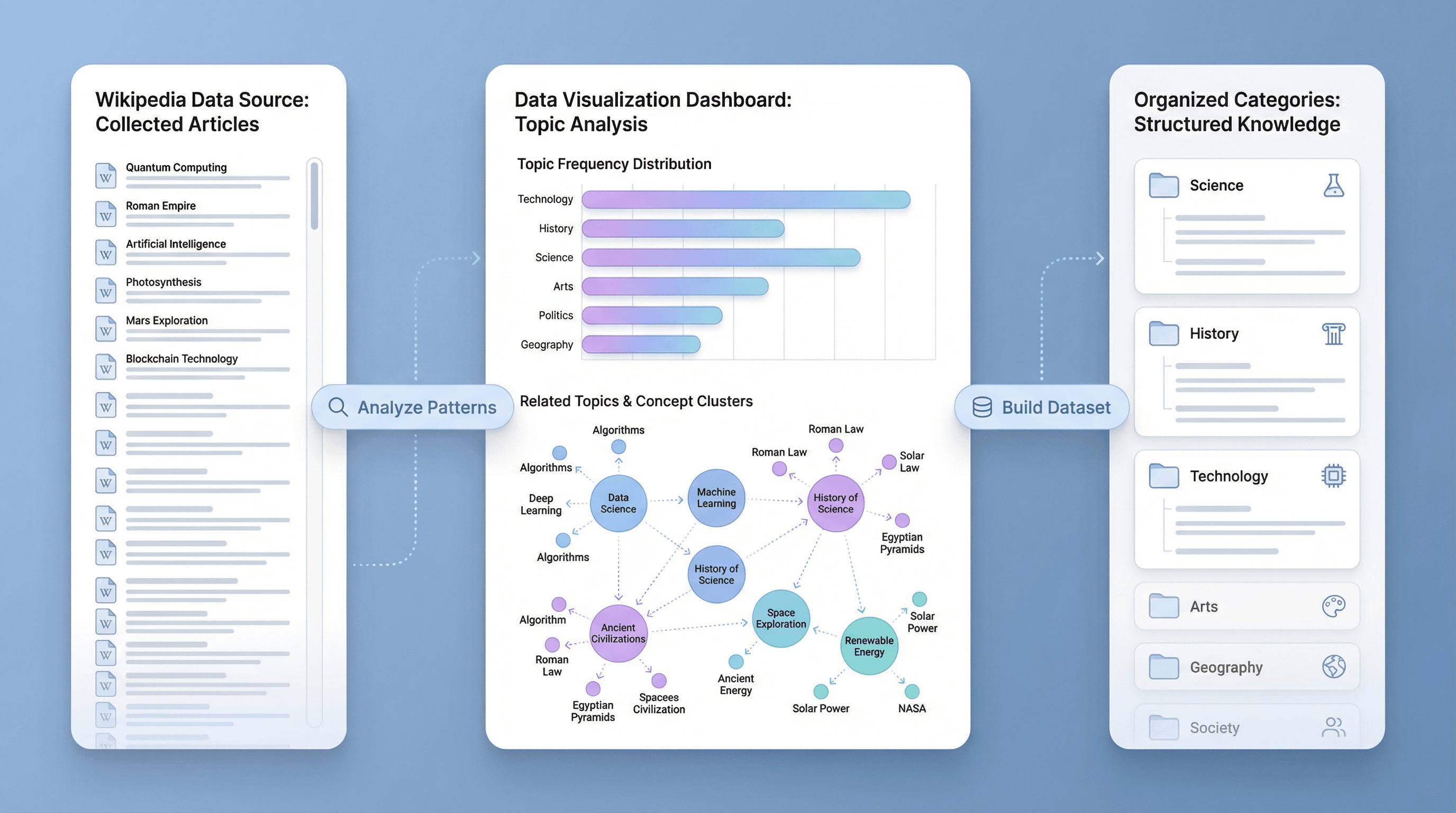
Analyze and Organize Large Sets of Wikipedia Results
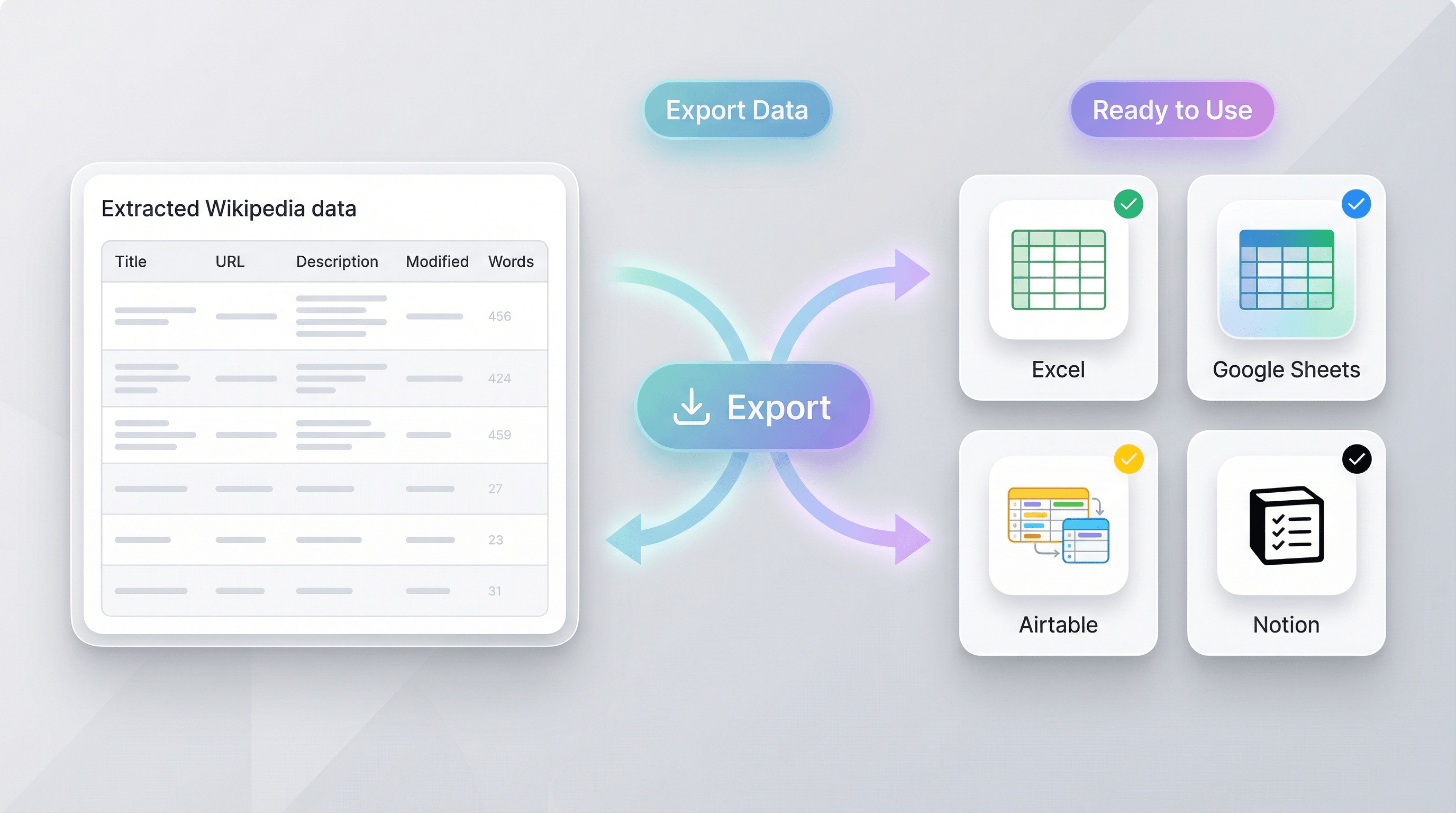
Export Wikipedia Data to Spreadsheets and Databases
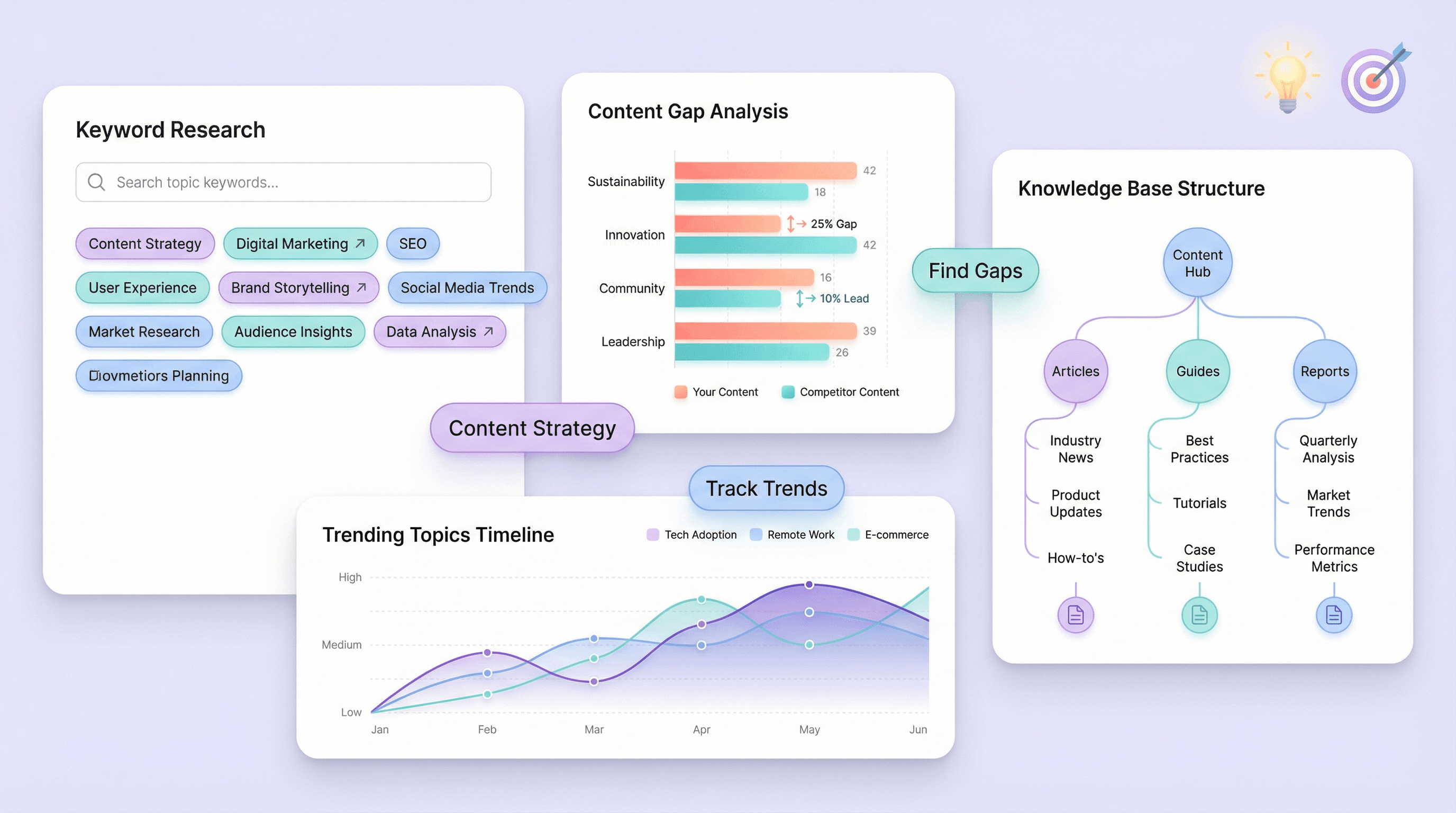
Support Content Strategy and SEO Research
ค้นพบเครื่องมือฟรีเพิ่มเติม
ดึงอีเมลจากข้อความออนไลน์
วางข้อความใดก็ได้ แล้วดึงอีเมลที่ถูกต้องออกมาเป็นรายการที่จัดระเบียบได้อย่างสะอาดตา ประหยัดเวลาในการคัดข้อความจากโน้ต ข้อความสนทนา และเอกสาร
ตัวดึงข้อมูลแผนผังเว็บไซต์
แยกวิเคราะห์ URL ของ XML sitemap และแสดงลิงก์ทุกหน้าลงในตารางที่อ่านง่าย ตรวจสอบโครงสร้างเว็บไซต์ได้รวดเร็ว พร้อมค้นหา URL ที่หายไปหรือไม่คาดคิดสำหรับงาน SEO และ QA
เครื่องมือดึงรูปภาพจากเว็บไซต์
ดึงรูปภาพทั้งหมดจากหน้าเว็บใดก็ได้ได้ทันที แล้วดาวน์โหลดได้อย่างรวดเร็ว ฟรี ใช้งานไว และส่งออกได้ง่ายมาก
ตัวดึงรายการ
ดึงรายการแบบมีลำดับและแบบไม่มีลำดับจาก URL ของหน้าเว็บใดก็ได้ ตรวจสอบรายการที่จัดกลุ่มเป็นข้อความธรรมดาเพื่อจับประเด็นสำคัญได้อย่างรวดเร็ว
Google Scholar scraper
ดึงผลการค้นหาทางวิชาการจากหน้า Google Scholar และส่งออกชื่อบทความ การอ้างอิง ผู้แต่ง และรายละเอียดการตีพิมพ์เป็นไฟล์ CSV เพื่อการค้นคว้าที่รวดเร็วขึ้น
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
เครื่องมือดึง URL และดาวน์โหลดแบบชุด
ดึงลิงก์ทั้งหมดจากหน้าเว็บใดก็ได้และดาวน์โหลดเป็น CSV รวบรวม URL ได้อย่างรวดเร็วสำหรับงานวิจัย การวิเคราะห์ หรือการเก็บข้อมูล
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
เครื่องมือสร้างหัวข้ออีเมลด้วย AI
สร้างหัวข้ออีเมลที่น่าสนใจได้จากคำอธิบายสั้น ๆ ช่วยเพิ่มอัตราการเปิดอ่านด้วยคำแนะนำจาก AI ใช้งานง่าย รวดเร็ว และไม่ต้องสมัครสมาชิก
Amazon สินค้า Scraper
เพียงวาง URL สินค้าจาก Amazon ก็สามารถดึงข้อมูลสินค้าออกมาได้ทันที ไม่ว่าจะเป็นชื่อสินค้า ราคา คะแนนรีวิว และรายละเอียดอื่น ๆ จัดเป็นตารางที่เป็นระเบียบ พร้อมสำหรับส่งออกและตรวจสอบได้อย่างรวดเร็ว
เครื่องมือดึงและตรวจสอบอีเมล
ค้นหาและดึงที่อยู่อีเมลด้วย Email Extractor จากหน้าเว็บ PDF หรือข้อความได้อย่างรวดเร็ว แม่นยำ และพร้อมส่งออกได้ทุกเมื่อ
ตัวแปลงรูปภาพเป็น Excel
แปลงรูปภาพของตาราง ใบเสร็จ หรือรายการ ให้เป็นอาร์เรย์ JSON ที่มีโครงสร้าง เพื่อส่งออกไปยัง Excel ได้ง่าย ประหยัดเวลาการป้อนข้อมูลด้วยมือและเพิ่มความแม่นยำ
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
เครื่องมือดึงเบอร์โทรศัพท์
สแกนหน้าเว็บ ไฟล์ หรือข้อความได้อย่างรวดเร็วเพื่อค้นหาเบอร์โทรศัพท์ รับรายการที่สะอาดและส่งออกได้ภายในไม่กี่วินาที เหมาะสำหรับการสร้างรายชื่อติดต่อหรือยืนยันข้อมูล
เครื่องทดสอบหัวข้ออีเมล
ให้คะแนนหัวข้ออีเมลตามความยาว ความชัดเจน ความเร่งด่วน การปรับให้เป็นส่วนตัว และความเสี่ยงสแปม พร้อมเคล็ดลับที่นำไปใช้ได้จริงเพื่อเพิ่มอัตราการเปิดอ่าน