ตัวดึงข้อมูล TechCrunch

ได้รับความไว้วางใจจากมืออาชีพในบริษัทชั้นนำ














ปลดล็อกข้อมูล TechCrunch ได้ในสองคลิก
ดึงข้อมูล TechCrunch แบบง่าย ๆ ในสองคลิก
การคัดลอกชื่อบทความ ผู้เขียน วันที่เผยแพร่ หรือแม้แต่เนื้อหาทั้งบทความจาก TechCrunch ด้วยตนเองนั้นเสียเวลา Thunderbit ช่วยให้คุณข้ามความยุ่งยากเหล่านี้ไปได้ แค่ชี้ไปที่ข้อมูลที่ต้องการ แล้ว AI ของเราจะจัดการส่วนที่เหลือ สองคลิก ก็เริ่มดึงข้อมูลได้โดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียวหรือยุ่งกับการตั้งค่าที่ซับซ้อน
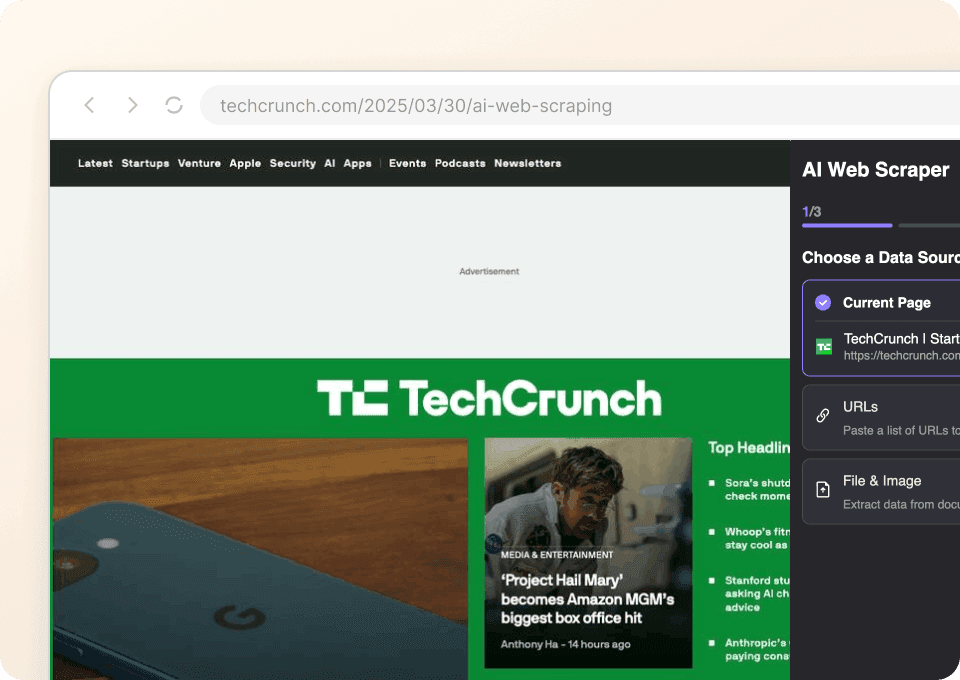
ได้ข้อมูล TechCrunch ที่สะอาดทันที
การดึง HTML ดิบจาก TechCrunch ไม่ช่วยอะไร — คุณต้องการข้อมูลที่สะอาดและมีโครงสร้าง Thunderbit จะทำความสะอาดและจัดรูปแบบข้อมูลให้อัตโนมัติขณะดึงข้อมูล ทำให้คุณวิเคราะห์หมวดหมู่บทความ ติดตามผู้เขียน หรือเปรียบเทียบวันที่เผยแพร่ได้ทันที ส่งออกไปยัง Google Sheets, Notion หรือ Airtable โดยตรง แล้วเริ่มทำงานกับข้อมูลที่จัดระเบียบเรียบร้อยได้เลยโดยไม่ต้องปวดหัวกับการทำความสะอาดข้อมูลด้วยมือ
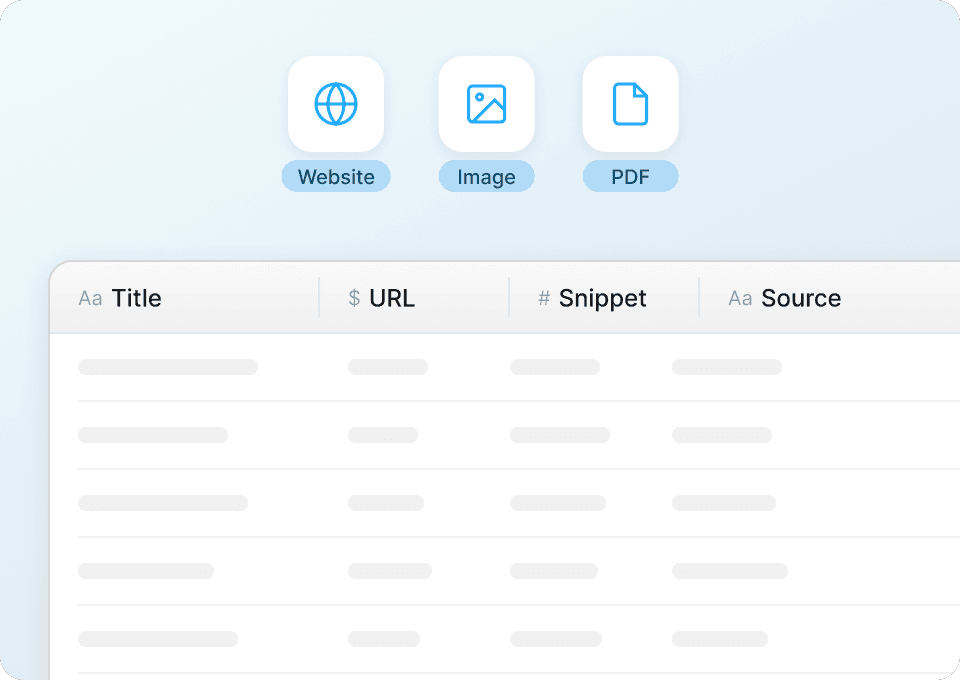
ดึงข้อมูลได้ทุกเว็บไซต์ ไม่ใช่แค่ TechCrunch
ทำไมต้องเรียนรู้เครื่องมือใหม่สำหรับทุกเว็บไซต์? Thunderbit ใช้งานได้กับแทบทุกเว็บไซต์ รวมถึง TechCrunch เรามีเทมเพลตสำเร็จรูปกว่า 50 แบบเพื่อช่วยให้คุณเริ่มต้นได้เร็วขึ้น ไม่ว่าคุณจะเก็บเนื้อหาบทความ แท็ก หรือรายละเอียดอื่น ๆ Thunderbit คือโซลูชันเดียวสำหรับการดึงข้อมูลจากทั่วทั้งเว็บ
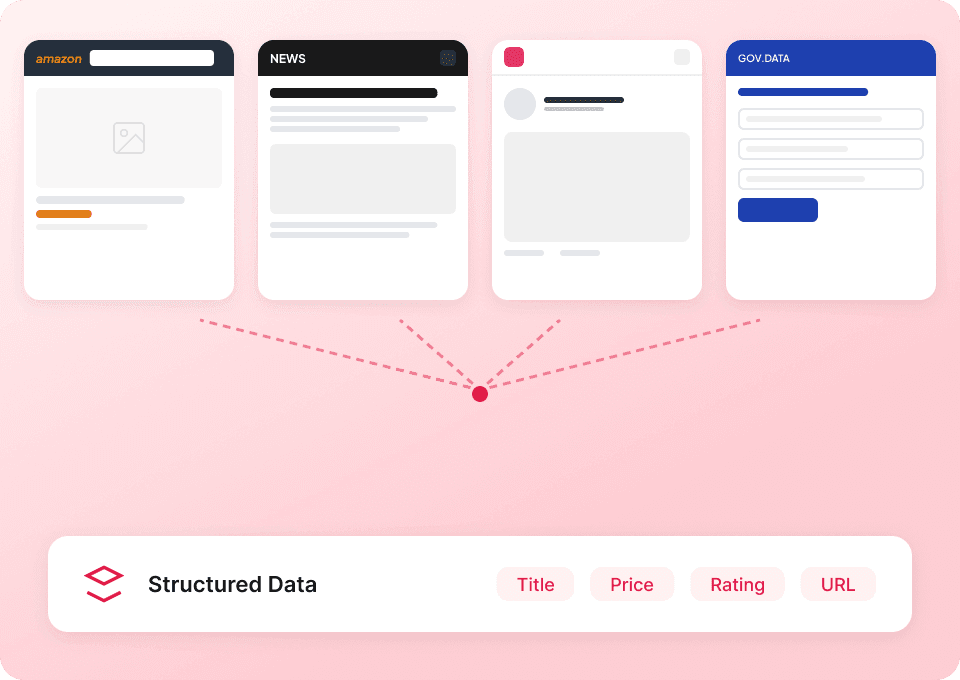
กำลังดึงข้อมูล TechCrunch อย่างมีประสิทธิภาพได้ยากอยู่ใช่ไหม?
ดูว่า Thunderbit ทำให้การดึงข้อมูล TechCrunch ง่ายขึ้นอย่างไรเมื่อเทียบกับวิธีแบบดั้งเดิม
ตัวดึงข้อมูลแบบดั้งเดิม
วิธีการแบบเดิมThunderbit
แนวทางที่ฉลาดกว่าไม่ต้องเชื่อเราอย่างเดียว
ดูว่าผู้ใช้ของเราพูดถึง Thunderbit ว่าอย่างไร







คำถามที่พบบ่อย
เกี่ยวข้อง การใช้งาน
สำรวจการใช้งาน Thunderbit web scraper เพิ่มเติม

Carousell 爬虫
ดึงข้อมูลจาก Carousell เช่น ชื่อสินค้า รายละเอียด และราคา ได้โดยไม่ต้องตั้งค่ายุ่งยากหรือเขียนโค้ด
ดูเพิ่มเติม ->
HKTVmall Scraper
ดึงชื่อสินค้า ราคา และแม้แต่คะแนนรีวิวจากรายการสินค้า HKTVmall ได้ในไม่กี่คลิก — ไม่ต้องตั้งค่าอะไรซับซ้อน
ดูเพิ่มเติม ->
Coupang scraper
ดึงชื่อสินค้า ราคา และอัตราส่วนลดจาก Coupang ได้ใน 2 คลิก — ไม่ต้องเขียนโค้ด
ดูเพิ่มเติม ->สแครปเปอร์ Substack
ดึงจำนวนผู้ติดตาม Substack ชื่อบทความ และคำอธิบายของสิ่งพิมพ์ลงในสเปรดชีตที่สะอาดเรียบร้อย — ไม่ต้องเขียนโค้ด AI จัดโครงสร้างให้
ดูเพิ่มเติม ->
เครื่องมือดึงข้อมูล Trivago
ดึงชื่อโรงแรม ราคา และคะแนนจาก Trivago ได้ในไม่กี่คลิก — ไม่ต้องเขียนโค้ดหรือตั้งค่าใด ๆ
ดูเพิ่มเติม ->
PlayStation Scraper
ปลดล็อกข้อมูลเกม PlayStation เช่น ชื่อเกม ประเภทเกม และราคาที่ลดแล้วได้ในไม่กี่คลิก ไม่ต้องคัดลอกวางเองให้เสียเวลาอีกต่อไป
ดูเพิ่มเติม ->พร้อมยกระดับการดึงข้อมูลของคุณแล้วหรือยัง?
เข้าร่วมกับมืออาชีพกว่า 100,000 คนที่ใช้ Thunderbit เพื่อทำเวิร์กโฟลว์เว็บสแครปปิ้งอัตโนมัติ
ทดลองใช้ฟรีพร้อมเครดิตไม่จำกัดสำหรับ 8 เว็บเพจ