เครื่องมือดึงข้อมูล Goodreads

ได้รับความไว้วางใจจากมืออาชีพในบริษัทชั้นนำ














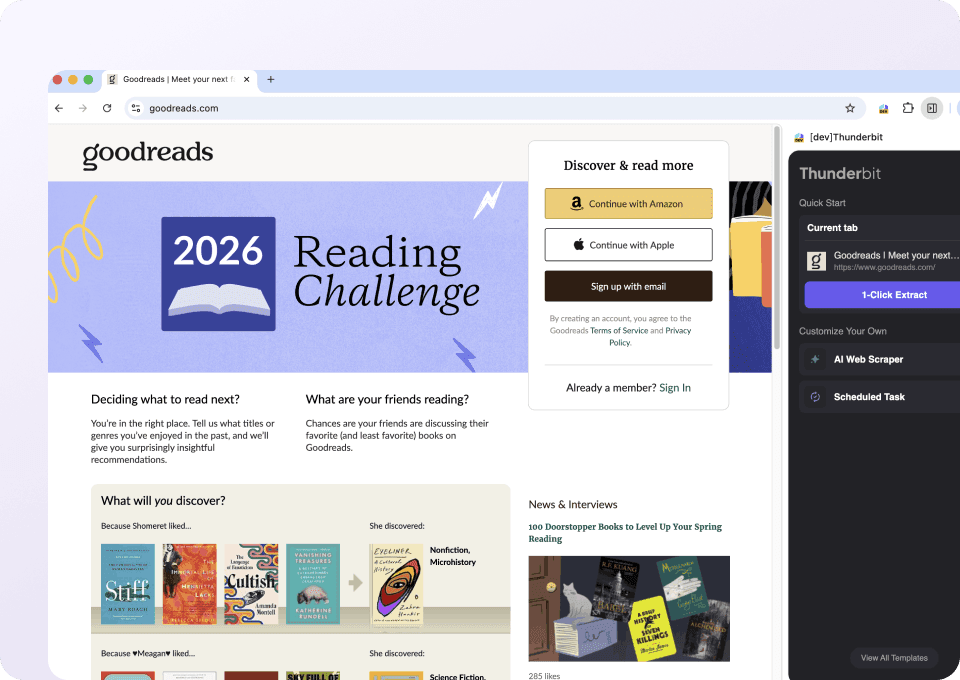
ดึงข้อมูล Goodreads ได้ในไม่กี่วินาที ไม่ใช่หลายชั่วโมง
ดึงข้อมูล Goodreads ได้ในสองคลิก
เบื่อกับการคัดลอกชื่อหนังสือ ชื่อผู้เขียน คะแนน และจำนวนหน้าจาก Goodreads แบบทีละรายการอยู่ใช่ไหม? Thunderbit ช่วยให้คุณดึงข้อมูลได้ในแค่สองคลิก ไม่ต้องเขียนโค้ดหรือเตรียมค่าตั้งซับซ้อน เพียงชี้ไปที่ข้อมูลที่ต้องการ แล้ว AI ของเราจะตรวจจับฟิลด์และดึงข้อมูลให้อัตโนมัติ
ข้อมูล Goodreads ที่สะอาด พร้อมใช้งาน
ข้อมูล Goodreads อาจยุ่งเหยิงได้ Thunderbit จะทำความสะอาดและจัดโครงสร้างข้อมูลให้อัตโนมัติขณะดึงข้อมูล ลองนึกภาพว่าคุณได้ Google Sheet ที่จัดรูปแบบมาอย่างสมบูรณ์ มีทั้งชื่อหนังสือ ผู้เขียน คะแนนเฉลี่ย จำนวนรีวิว และจำนวนหน้า พร้อมสำหรับการวิเคราะห์ทันที ไม่ต้องมานั่งเก็บกวาดข้อมูลเองอีกต่อไป
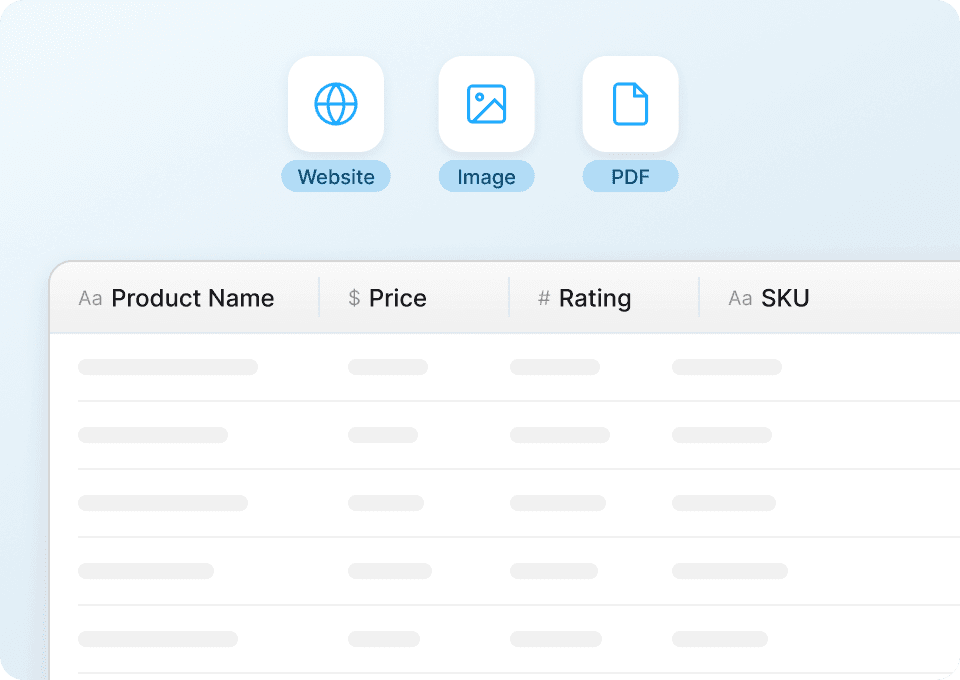
ดึงข้อมูล Goodreads หลายร้อยหน้า
การดึงข้อมูล Goodreads ด้วยมือทีละหน้าทั้งน่าเบื่อและใช้เวลามาก Thunderbit สามารถดึงข้อมูลจาก Goodreads หลายร้อยหน้าได้อัตโนมัติในครั้งเดียว แค่ใส่รายการ URL แล้วระบบจะดึงข้อมูลหนังสือ ผู้เขียน หรือข้อมูลอื่น ๆ ที่คุณต้องการได้อย่างรวดเร็วและมีประสิทธิภาพ

การดึงข้อมูล Goodreads ทำให้ปวดหัวอยู่หรือเปล่า?
ดูว่า Thunderbit ทำให้การดึงข้อมูลจาก Goodreads ง่ายขึ้นอย่างไร
เครื่องมือดึงข้อมูลแบบดั้งเดิม
วิธีการแบบเก่าThunderbit
แนวทางที่ฉลาดกว่าอย่าเพิ่งเชื่อแค่คำเราบอก
ดูว่าผู้ใช้พูดถึง Thunderbit ว่าอย่างไร






คำถามที่พบบ่อย
ที่เกี่ยวข้อง กรณีใช้งาน
สำรวจกรณีใช้งานเพิ่มเติมของเว็บสแครปเปอร์ Thunderbit
Video Scraper
Video Scraper ของ Thunderbit ช่วยดึงข้อมูลวิดีโอและข้อมูลครีเอเตอร์ด้วย AI ได้ภายในไม่กี่คลิก เก็บทั้งรายการวิดีโอ ตัวชี้วัดผลงาน และรายละเอียดโปรไฟล์ แล้วส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion เพื่อใช้ติดตามผลและทำรีเสิร์ชอินฟลูเอนเซอร์ได้ทันที
เรียนรู้เพิ่มเติม ->
Spokeo Scraper
หยุดคัดลอกข้อมูลจาก Spokeo ด้วยตัวเอง — ใช้ Thunderbit ดึงชื่อ อายุ ที่อยู่ และอื่น ๆ ได้ในแค่ไม่กี่คลิก
เรียนรู้เพิ่มเติม ->
HKTVmall Scraper
ดึงชื่อสินค้า ราคา และแม้แต่คะแนนรีวิวจากรายการสินค้า HKTVmall ได้ในไม่กี่คลิก — ไม่ต้องตั้งค่าอะไรซับซ้อน
เรียนรู้เพิ่มเติม ->
United Airlines Scraper
คลิกเพียงไม่กี่ครั้งเพื่อดึงข้อมูลเที่ยวบินของ United Airlines เช่น เลขเที่ยวบิน เวลาเดินทางถึง และสนามบินต้นทาง — ที่เหลือให้ Thunderbit AI จัดการให้หมด
เรียนรู้เพิ่มเติม ->
Carousell 爬虫
ดึงข้อมูลจาก Carousell เช่น ชื่อสินค้า รายละเอียด และราคา ได้โดยไม่ต้องตั้งค่ายุ่งยากหรือเขียนโค้ด
เรียนรู้เพิ่มเติม ->สแครปเปอร์ Substack
ดึงจำนวนผู้ติดตาม Substack ชื่อบทความ และคำอธิบายของสิ่งพิมพ์ลงในสเปรดชีตที่สะอาดเรียบร้อย — ไม่ต้องเขียนโค้ด AI จัดโครงสร้างให้
เรียนรู้เพิ่มเติม ->พร้อมยกระดับการดึงข้อมูลให้แรงขึ้นหรือยัง?
เข้าร่วมกับมืออาชีพกว่า 100,000 คนที่ใช้ Thunderbit เพื่อทำเวิร์กโฟลว์เว็บสแครปปิงให้อัตโนมัติ
ทดลองใช้ฟรีพร้อมเครดิตไม่จำกัดสำหรับ 8 เว็บเพจ