เครื่องมือดึงข้อมูล Flipkart แบบ AI ที่ใช้งานง่าย

ได้รับความไว้วางใจจากมืออาชีพในบริษัทชั้นนำ














ปลดล็อกข้อมูล Flipkart ด้วย Thunderbit
ข้อมูลอีเวนต์สะอาดตา ไม่ต้องลงแรง
ลองนึกภาพว่าคุณต้องดึงรายละเอียดอีเวนต์จากหลายเว็บไซต์ ไม่ใช่แค่ Flipkart เท่านั้น Thunderbit ใช้ได้ทุกที่ แค่ชี้แล้วคลิก ชื่ออีเวนต์ คำอธิบาย วันที่ ข้อมูลสถานที่ และที่อยู่ก็จะปรากฏเป็นตารางที่มีโครงสร้าง เสร็จเลย
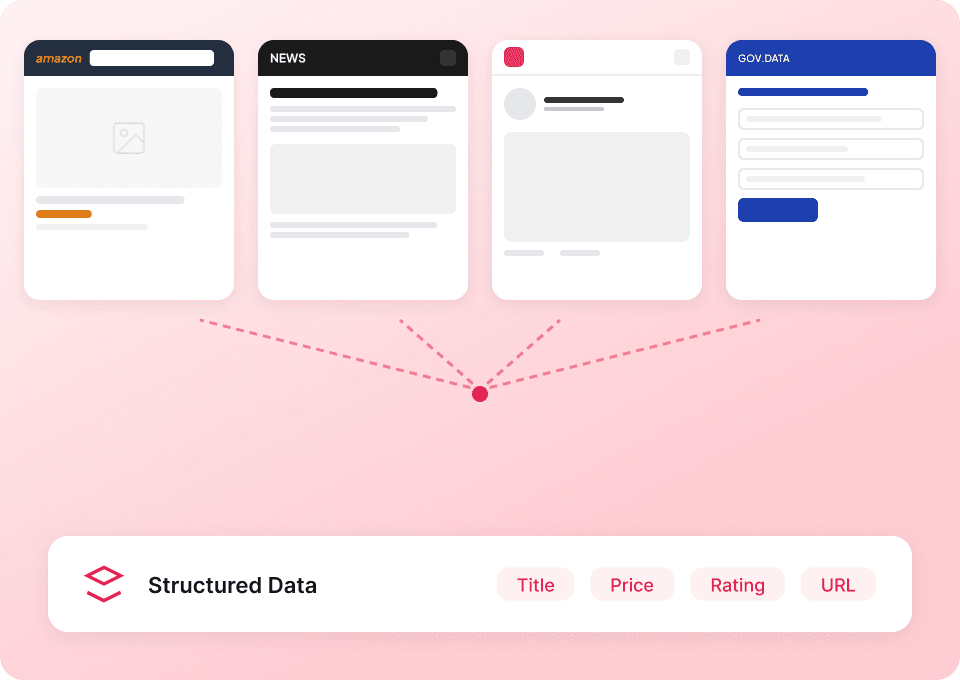
บอกลา ข้อมูล Flipkart ที่ไม่ครบ
ถ้าคุณดึงรายละเอียดได้ครบทุกอย่าง ไม่ใช่แค่สรุปบนหน้ารายการล่ะ? Thunderbit จะเข้าไปยังหน้าย่อยของอีเวนต์แต่ละรายการบน Flipkart แล้วดึงคำอธิบายอีเวนต์แบบเต็ม วันที่เริ่มและสิ้นสุดที่แม่นยำ และที่อยู่สถานที่ครบถ้วน ตอนนี้คุณก็เห็นภาพทั้งหมดแล้ว
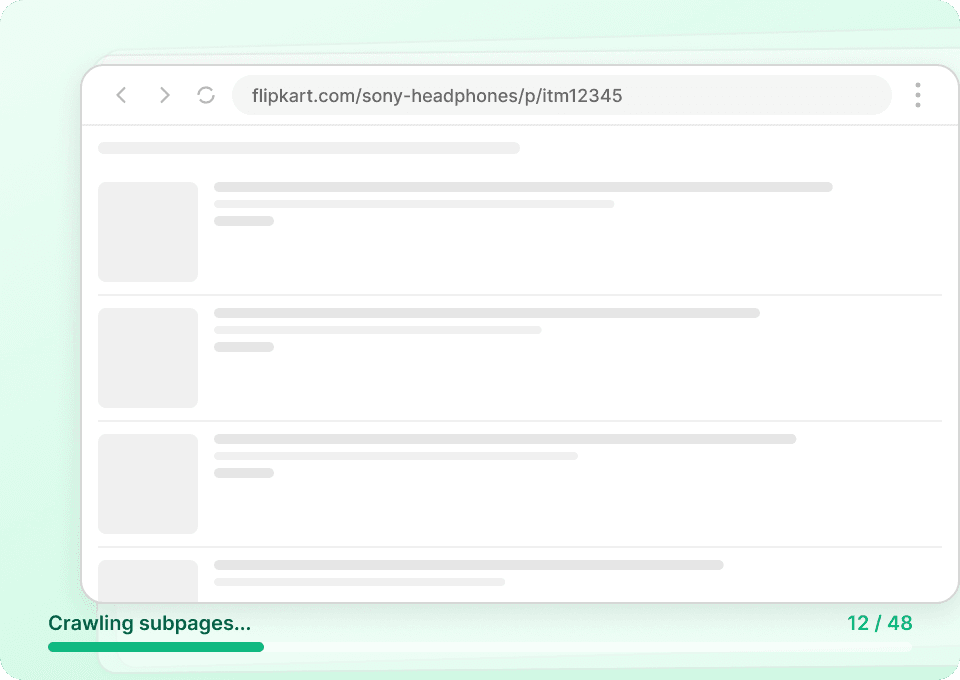
ข้อจำกัดการดึงข้อมูล Flipkart? ไม่มีอีกแล้ว
หยุดดึงข้อมูล Flipkart ทีละหน้าได้เลย วางรายการ URL อีเวนต์จาก Flipkart ลงไป แล้ว Thunderbit จะดึงข้อมูลหลายร้อยหน้าได้ในครั้งเดียว แค่นั้นเอง

วิธีที่ดีกว่าในการดึงข้อมูล Flipkart ให้มีประสิทธิภาพ
ดูว่า Thunderbit ทำให้การดึงข้อมูลง่ายขึ้นอย่างไรเมื่อเทียบกับวิธีแบบดั้งเดิม
เครื่องมือดึงข้อมูลแบบดั้งเดิม
วิธีเดิม ๆ ที่เคยใช้กันThunderbit
วิธีที่ชาญฉลาดกว่าอย่าเพิ่งเชื่อแค่คำเราบอก
ดูว่าผู้ใช้พูดถึง Thunderbit ว่าอย่างไร






คำถามที่พบบ่อย
ที่เกี่ยวข้อง กรณีใช้งาน
สำรวจกรณีใช้งานเพิ่มเติมของเว็บสแครปเปอร์ Thunderbit
เครื่องมือดึงข้อมูล PeopleWhiz
เครื่องมือดึงข้อมูล PeopleWhiz ของ Thunderbit ช่วยให้คุณดึงข้อมูลจากผลการค้นหาและโปรไฟล์บน PeopleWhiz ได้ด้วยคำแนะนำฟิลด์อัจฉริยะจาก AI รวบรวมชื่อ รายละเอียดการติดต่อ ที่ตั้ง และข้อมูลอื่น ๆ สำหรับงานวิจัย การตลาด หรือการหาลูกค้าเป้าหมาย แปลงข้อมูล PeopleWhiz ให้เป็นชุดข้อมูลที่มีโครงสร้างได้อย่างรวดเร็วและมีประสิทธิภาพ
เรียนรู้เพิ่มเติม ->
United Airlines Scraper
คลิกเพียงไม่กี่ครั้งเพื่อดึงข้อมูลเที่ยวบินของ United Airlines เช่น เลขเที่ยวบิน เวลาเดินทางถึง และสนามบินต้นทาง — ที่เหลือให้ Thunderbit AI จัดการให้หมด
เรียนรู้เพิ่มเติม ->Video Scraper
Video Scraper ของ Thunderbit ช่วยดึงข้อมูลวิดีโอและข้อมูลครีเอเตอร์ด้วย AI ได้ภายในไม่กี่คลิก เก็บทั้งรายการวิดีโอ ตัวชี้วัดผลงาน และรายละเอียดโปรไฟล์ แล้วส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion เพื่อใช้ติดตามผลและทำรีเสิร์ชอินฟลูเอนเซอร์ได้ทันที
เรียนรู้เพิ่มเติม ->
ตัวดึงข้อมูล Wikipedia
ดึงข้อมูลอินโฟบ็อกซ์ แหล่งอ้างอิง และเนื้อหาบทความจาก Wikipedia ลงสเปรดชีตที่จัดระเบียบอย่างเรียบร้อย — ไม่ต้องเขียนโค้ด AI จะช่วยจัดโครงสร้างให้คุณ
เรียนรู้เพิ่มเติม ->
Coupang scraper
ดึงชื่อสินค้า ราคา และอัตราส่วนลดจาก Coupang ได้ใน 2 คลิก — ไม่ต้องเขียนโค้ด
เรียนรู้เพิ่มเติม ->
UNIQLO Scraper
เก็บข้อมูลสินค้าจาก Uniqlo เช่น ชื่อ ราคา และไซซ์ที่มีจำหน่ายได้ใน 2 คลิก ด้วยส่วนขยาย Chrome ของ Thunderbit
เรียนรู้เพิ่มเติม ->พร้อมยกระดับการดึงข้อมูลให้แรงขึ้นหรือยัง?
เข้าร่วมกับมืออาชีพกว่า 100,000 คนที่ใช้ Thunderbit เพื่อทำเวิร์กโฟลว์เว็บสแครปปิงให้อัตโนมัติ
ทดลองใช้ฟรีพร้อมเครดิตไม่จำกัดสำหรับ 8 เว็บเพจ