JD.COM scraper














Extract JD.com product data effortlessly
Clean Jd data, ready when you export
Getting raw data is only half the battle. Thunderbit automatically structures and formats your JD.com data as it extracts it. Export product names, prices, SKUs, ratings, review counts, and brands already cleaned and ready for analysis — no messy data wrangling required.
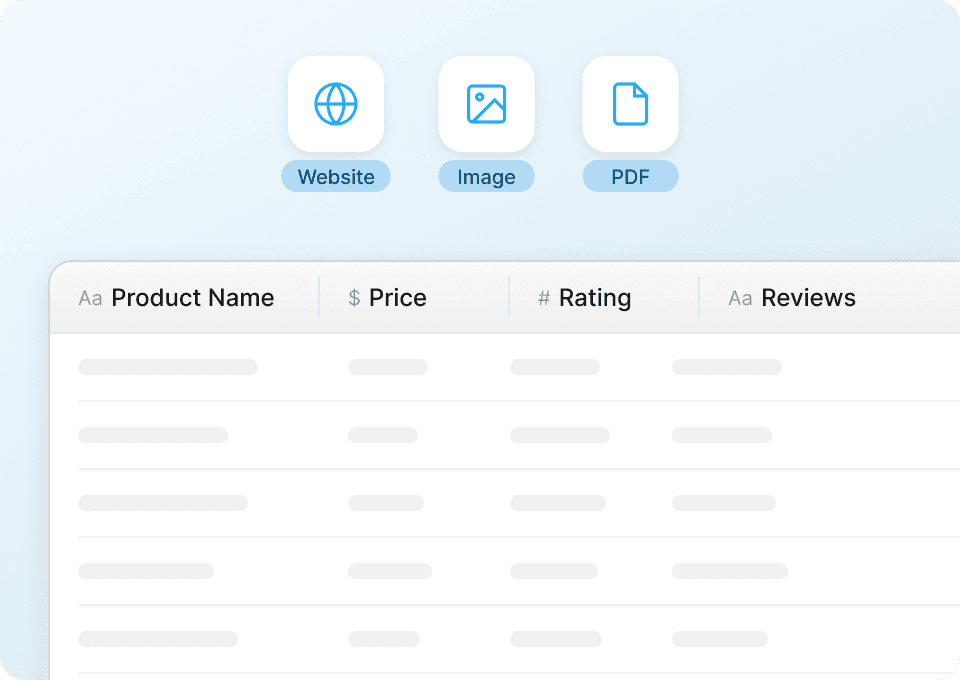
Scrape Jd subpages for complete details
JD.com listing pages often leave out the full story. Thunderbit automatically visits each product subpage to pull complete details — specifications, descriptions, and features — without you clicking through each one manually. All subpage data is appended as new columns, giving you a complete product record in a single export.
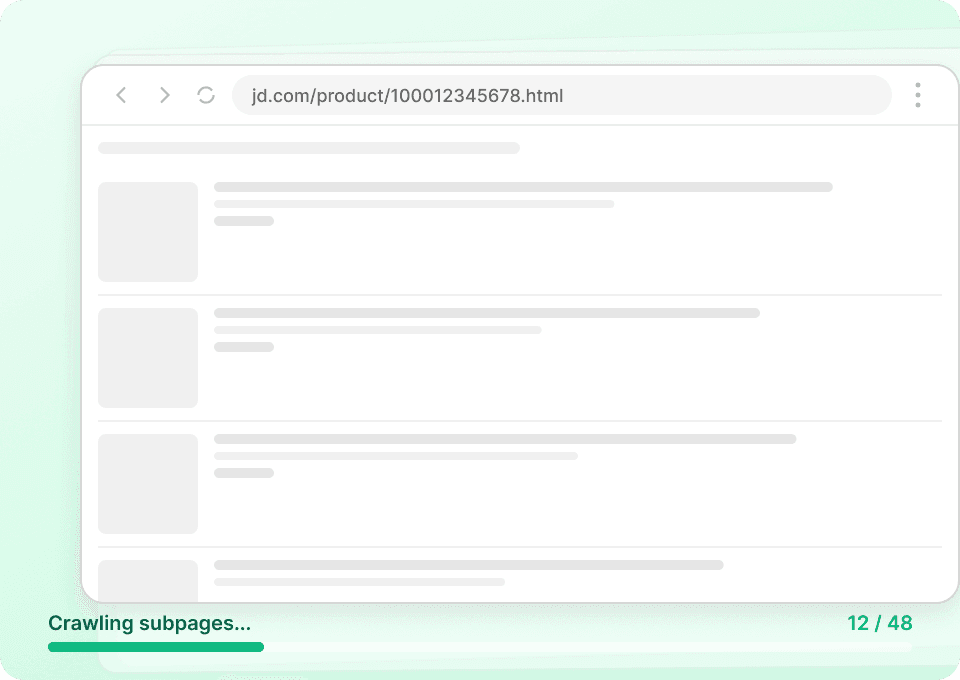
Jd data extraction at scale
Scraping JD.com product by product is slow and unsustainable. With Thunderbit, you can extract data from hundreds of JD.com pages at once — just supply a list of URLs and Thunderbit handles the rest, pulling product names, prices, and every key data point automatically, no matter the volume.

Struggling to scrape JD.com effectively?
See how Thunderbit simplifies data extraction compared to traditional methods.
Traditional scrapers
The old way of doing thingsThunderbit
The smarter approach




Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.
PeopleWhiz scraper
The Thunderbit PeopleWhiz Scraper lets you extract data from PeopleWhiz search results and profiles with AI-powered field suggestions. Gather names, contact details, locations, and more for research, marketing, or lead generation. Transform PeopleWhiz data into structured datasets quickly and efficiently.
Learn more ->Substack scraper
Extract Substack subscriber counts, article titles, and publication descriptions in 2 clicks — then export to Excel, Google Sheets, or Notion. No code needed; Thunderbit's AI handles the structuring for you.
Learn more ->
Amarillas.com Scraper
The Thunderbit Amarillas.com Scraper lets you extract structured data from Amarillas.com, including motels and restaurant listings. Use AI-powered field suggestions to quickly gather business names, locations, contact numbers, ratings, and reviews for research, marketing, or lead generation.
Learn more ->
Tieba Scraper
The Thunderbit Tieba Scraper enables you to extract data from Baidu Tieba, including trending topics and forum categories. Use AI-powered field suggestions to quickly gather topic names, URLs, post counts, and user activity for research, marketing, or content creation. Ideal for analyzing social media trends and discussions on Tieba.
Learn more ->DialIndia Scraper
The Thunderbit DialIndia Scraper lets you extract data from DialIndia's business profiles and travel directories with AI-powered field suggestions. Gather business names, contact details, locations, and descriptions for research, marketing, or lead generation in just a few clicks.
Learn more ->
White Pages Scraper
The Thunderbit White Pages Scraper lets you extract data from White Pages phone and business listings with AI-powered field suggestions. Gather names, phone numbers, addresses, and website URLs for lead generation, marketing, or research in just a few clicks.
Learn more ->Ready to supercharge your data extraction?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.



