
Alla pratar om datadrivna beslut, men det många glömmer är hur tidskrävande och omständligt det faktiskt är att samla in data. Har du någon gång försökt samla in information för hand vet du hur segt det kan vara. Jag har sett många företag kämpa med att få sina datadrivna strategier att lyfta just på grund av ineffektiv datainsamling. Om du känner igen dig har den här artikeln några nya lösningar för dig.
💡 I den här artikeln går vi igenom vad dataskrapning är och hur tekniken utvecklas med hjälp av ny teknik. Vi tittar på nackdelarna med äldre metoder, lyfter fördelarna med AI-driven dataskrapning och delar praktiska tips för verkliga användningsfall.
Vad är dataskrapning?
Dataskrapning, eller webbskrapning, handlar om att hämta strukturerad information från webbsidor med hjälp av verktyg, ofta presenterad i tabellform. Det är ett mycket effektivt sätt att samla stora mängder data snabbt. Du kan till exempel hämta offentlig information från Google Maps för leadgenerering, skrapa e-handels-SKU:er från Amazon för vidareförsäljning eller marknadsanalys, eller samla in omdömen från sociala medier och Yelp för kundinsikter.
Det tekniska skiftet inom dataskrapning
Förr i tiden kändes datainsamling som något bara tekniker kunde hantera, eller så handlade det om massor av manuell copy-paste. Men nu är det 2025 och AI har tagit plats. Dataskrapning är inte längre bara för programmerare eller enkel automatisering.
Traditionella metoder räcker inte längre
Moderna webbplatser skapar också fler utmaningar: dynamiskt innehåll som laddas löpande (till exempel med React- eller Vue-ramverk), mer multimodala datatyper (text, video, bilder) och icke-standardiserade datastrukturer (flera mallar på samma sida). Nya studier pekar på tre stora problem med traditionella metoder för webbskrapning:
-
En underhållskostnad utan botten Traditionella webbskrapare kräver ständigt manuellt underhåll, ungefär 3–5 timmar per månad och webbplats. När en sajt uppdateras eller byter frontend-ramverk slutar 60 % av XPath-selektorerna fungera. AI-verktyg, med språkmodeller och kodintelligens, kan automatiskt anpassa sig till 90 % av strukturella ändringar och minska underhållskostnaderna med 60–80 %. För moderna sajter byggda i React/Vue håller AI-verktyg dataskrapningen stabil genom semantisk förståelse, även när klassnamn ändras.
-
Begränsad datatäckning Traditionella metoder kan bara fånga strukturerad data och missar värdefull information som:
- Data i bilder
- Textinnehåll i artiklar
- Ostrukturerad data utan HTML-taggar
-
Problem med datakvalitet Traditionella metoder har svårt med dynamiskt innehåll, vilket leder till ofullständig eller felaktig data:
- För paginerad data, som e-handelslistor, fångar traditionella skrapare bara 30–50 % av innehållet på första skärmen.
- Sidor med oändlig scroll, som flöden i sociala medier, tappar över 60 % av den kritiska datan.
- Hög felfrekvens vid matchning av ostrukturerad data, till exempel feljusterade listor.
Det är här AI-drivna verktyg som Thunderbit kommer in. Nedan bryter jag ner fördelarna.
AI-dataskrapning växer snabbt
Skrapa data från vilken webbplats som helst med AI Get Started Free
År 2025 har AI, särskilt stora språkmodeller (LLM:er), visat riktigt imponerande förmågor. De kan förstå och generera naturligt språk, lösa komplexa analysuppgifter och ge effektivare lösningar. Många verktyg för dataskrapning använder nu LLM:er för att komma runt begränsningarna i traditionella metoder. Efter att ha testat 13 verktyg för dataskrapning de senaste månaderna rekommenderar jag Thunderbit AI Web Scraper.
Det här gör Thunderbit särskilt starkt:
-
En helt ny typ av interaktion: Användaren kan skriva enkla instruktioner på naturligt språk, och systemet skapar automatiskt en skrapplan. Det minskar konfigurationstiden med 87 % jämfört med traditionella verktyg.
-
Stora fördelar med lokal skrapning: Som webbläsartillägg erbjuder Thunderbit:
- Direkt dataskrapning
- Skrapning av dynamiska sidor och sidor med oändlig scroll
- Skrapning av sidor som kräver inloggning
-
Kraftfull hantering av multimodal data: Thunderbit kan hantera flera typer av data, till exempel:
- Extrahera textdata ur artiklar
- Extrahera finansiella tabeller från PDF-filer
- Känna igen data från flera bilder och bygga tabeller
- Skrapa undertexter från video och sammanfatta dem
Med Thunderbit kan du enkelt hantera många olika insamlingsscenarier. Låt oss se hur du använder Thunderbit.
Så här skrapar du data med AI
Följ de här fyra stegen för att utnyttja Thunderbits kraftfulla AI-baserade webbskrapning:
-
Installera webbläsartillägget Gå till Thunderbits webbplats och ladda ner tillägget från Chrome Web Store. När det är installerat fäster du det i webbläsarens verktygsfält.
-
Registrera dig och få gratis krediter Skapa ett konto i tillägget för att få provkrediter. De här krediterna låter dig testa kärnfunktioner som AI-webbskrapning, autofyll av formulär och smart sammanfattning. Det är klokt att först prova verktyget gratis i playground-läget innan du använder krediterna, så att du ser hur bra det fungerar.
-
Starta smart skrapning Öppna en mall från Thunderbits sidopanel. Använd språkbeskrivningar för att välja vilken data och vilken typ du vill hämta, ställ in specifika extraktionsformat eller justera andra detaljer. Klicka sedan på skrapa för att börja dataskrapningen.
Avancerade skrapfunktioner (Pro-nivå)
Genom att prenumerera på Thunderbits Pro-nivå eller börja med en gratis testperiod låser du upp följande funktioner:
-
Multimodal databehandling Hanterar komplexa scenarier som tolkning av PDF-dokument (finansiella rapporter/produktmanualer), extraktion av bilddata (prislappar/specifikationer) och skrapning av videosubtitlar. Systemet standardiserar automatiskt ostrukturerad data.
-
Djup skrapning av undersidor Du kan välja att gå in på alla undermenyer och länkar på en sida, som produktsidor/sidor med användarrecensioner, känna igen relaterad data på ett intelligent sätt och automatiskt slå ihop den i huvudtabellen. Perfekt för produktkataloger inom e-handel, bostadsannonser och mycket mer.
-
Förbyggt bibliotek med mallar Använd direkt optimerade skrapmallar för över 30 plattformar som TikTok, Amazon och Zillow, med automatisk anpassning till ändringar i sidstrukturen. Nya användare sparar i genomsnitt 83 % av konfigurationstiden.
-
Masskörning av skrapuppgifter Kör flera skrapjobb samtidigt med stöd för import av URL-listor för batchskrapning.
-
Intelligent hantering av paginering Känner automatiskt igen och skrapar paginerat innehåll, inklusive knappar som "ladda fler" och sidnavigering, samt stöd för sidor med oändlig scroll. Testat för att kunna skrapa över 200 sidor med e-handelslistor fullt ut.
Praktisk guide till Thunderbit
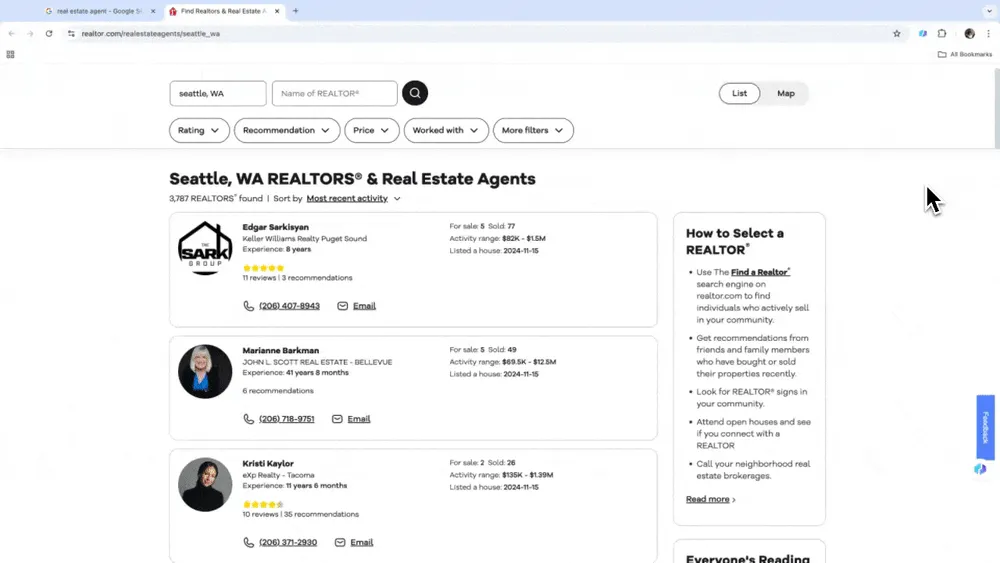
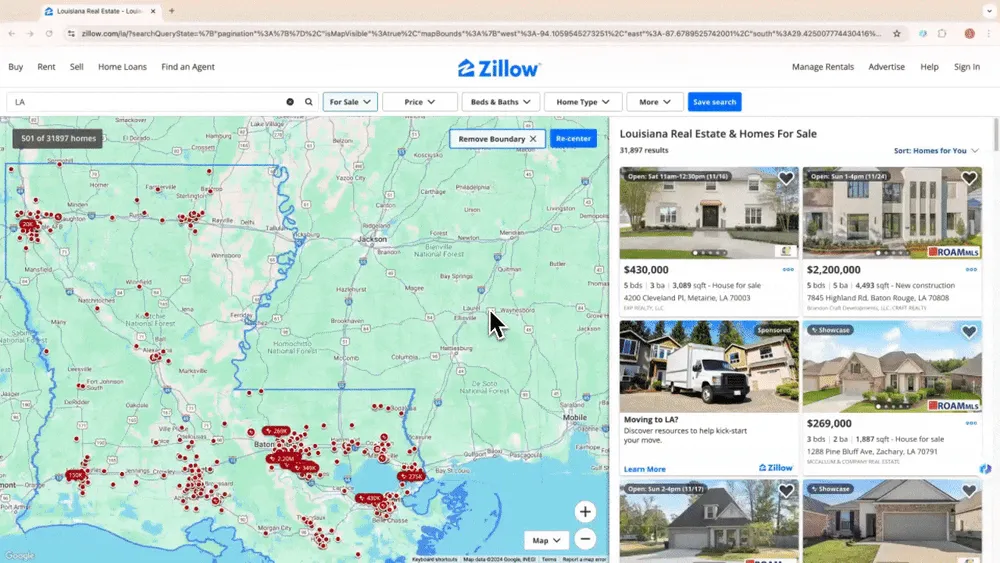
Scenario 1: Insamling av fastighetsdata
Om du är mäklare och vill samla in fastighetsdata från Zillow, eller investerare som letar efter lönsamma möjligheter, kan en pålitlig webbskrapare vara din bästa hjälpreda. Thunderbits AI-webbskrapare gör det enkelt att extrahera viktig fastighetsinformation från Zillow, så att du håller dig uppdaterad och konkurrenskraftig. Kolla in en videoguide om hur du skrapar Zillow med Thunderbit.
Scenario 2: Sourcing av talanger och kundprospektering
Om du arbetar inom HR och letar efter talanger, eller om du är säljare och behöver nya leads, kan en pålitlig webbskrapare vara ett kraftfullt stöd. Thunderbit låter dig extrahera användbar kontakt- och företagsdata från offentliga webbplatser, kataloger och profilsidor, vilket hjälper dig att effektivisera talangsökning och leadhantering. När du har använt det märker du snabbt att tidskrävande manuell sökning och copy-paste hör till det förflutna. För ett färdigt arbetsflöde kan du börja med Website Contact Scraper.
Scenario 3: Marknadsanalys och kundmålgrupper
Om du driver företag och samlar platsbaserad data för marknadsanalys, eller om du arbetar med försäljning och vill hitta lokala företagsleads, kan en pålitlig webbskrapare förändra spelplanen. Thunderbit gör det enkelt att extrahera viktig data från Google Maps, så att du kan fatta mer välgrundade beslut och förbättra din outreach.
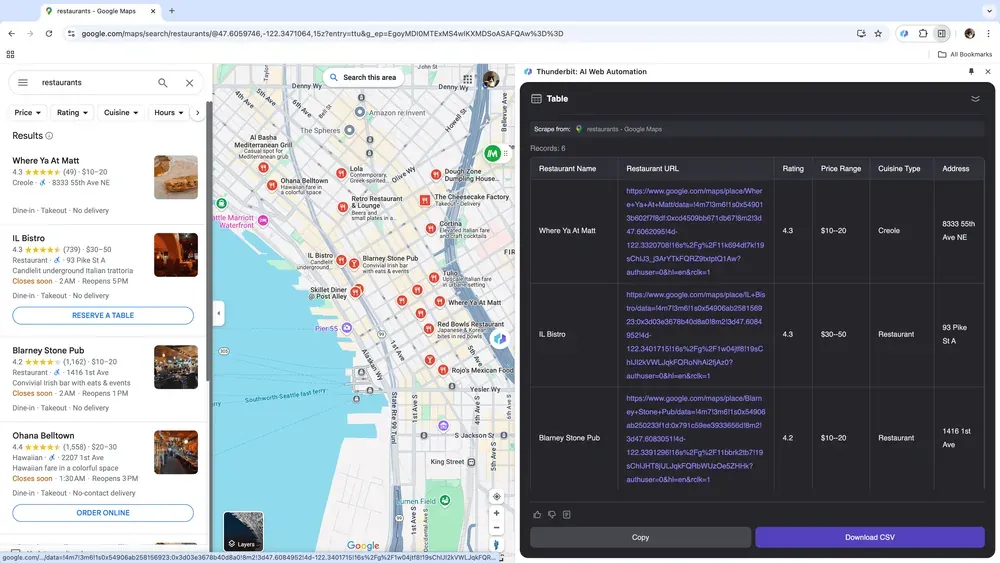
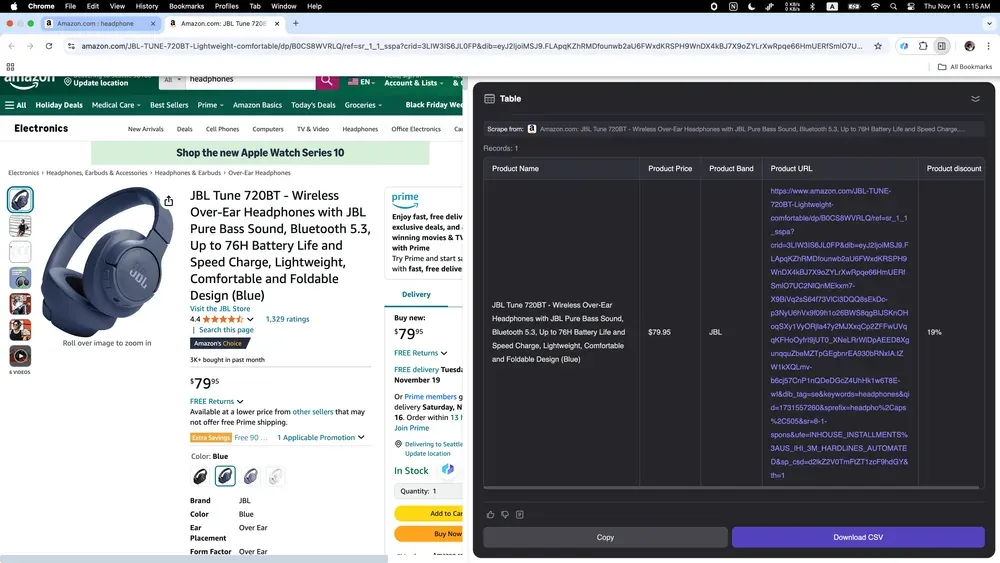
Scenario 4: Analys av e-handelsdata
Om du säljer online och vill förstå konkurrenterna, eller om du är entreprenör och följer marknadstrender, är Thunderbit ett perfekt verktyg! Det kan enkelt samla in produktdata från Amazon, inklusive detaljerade beskrivningar, priser och användarrecensioner.
Thunderbit AI Web Scraper omdefinierar hur affärsanvändare samlar in data och gör processen snabbare, enklare och mer effektiv än någonsin. Oavsett om du letar efter fastigheter, söker potentiella kunder eller analyserar trender inom e-handel kan AI-webbskrapare spara dig otaliga timmar och mycket krångel. Ta till dig kraften i AI för webbskrapning och se hur din produktivitet tar ett kliv framåt. Redo att komma igång? Testa Thunderbit och ta det första steget mot smartare webbskrapning.
Testa Thunderbit AI Web Scraper
Exklusiva tips för datarensning
Med traditionella skrapare börjar den verkliga utmaningen efter dataskrapningen: datarensning. Thunderbits AI kan utföra datarensning under själva dataskrapningen med hjälp av LLM, vilket minskar arbetsbördan för datarensning med 83 % genom följande innovativa funktioner:
Tips 1: Intelligent fältjustering
När du arbetar med heterogen data från flera källor, till exempel att skrapa LinkedIn och Zillow samtidigt, skapar Thunderbits AI automatiskt semantiska kopplingar mellan fält:
- Identifierar automatiskt fältsamband mellan olika datakällor, till exempel "price" ↔ "售价" ↔ "Price"
- Slår intelligent ihop liknande fält, till exempel "area" och "square feet"
- Standardiserar data mellan plattformar, till exempel att LinkedIns "current position" och Zillows "property status" enhetliggörs som taggdata
Tips 2: Kontextmedveten komplettering
Med språkmodellernas förmåga att förstå sammanhang når Thunderbit en branschledande ifyllnadsgrad på 99 %:
- Adresskomplettering: Fyller automatiskt i stad och delstat utifrån postnummer, till exempel 10001 → New York City, NY
- Prognos för karriärväg: Förutspår möjliga arbetslivserfarenheter utifrån utbildningsbakgrunden på LinkedIn
Tips 3: Datoptimering
- Flerspråkig översättning, med stöd för realtidsöversättning på 12 språk, inklusive engelska, kinesiska och japanska
- Intelligent sammanfattning, som kondenserar en produktbeskrivning på 500 ord till tre viktiga säljpunkter
- Enhetsstandardisering, som automatiskt konverterar square feet ↔ square meter och Fahrenheit ↔ Celsius
- Formatstandardisering, där datum enhetliggörs till YYYY-MM-DD och valuta till USD
Tips 4: Kvalitetskontroll
- Intelligent felrättning: Fixar automatiskt formatfel, till exempel telefonnummer +01 138-1234-5678 → +113812345678
- Logisk validering: Säkerställer att "year built" är tidigare än "last renovation time"
Tips 5: AI-taggning
Skapar automatiskt smarta taggar med hjälp av naturlig språkbehandling:
- Taggar för sentimentanalys, som automatiskt märker kundomdömen som positiva/negativa/neutrala
- Taggar för affärsvärde, som automatiskt markerar "high-potential clients"/"properties to follow up on"
- Taggar för branschklassificering, som automatiskt märker LinkedIn-profiler med "tech|finance|healthcare"
Nackdelarna med dataskrapning
Även om dataskrapning skapar stort värde är det viktigt att erkänna de hinder företag kan stöta på. Juridiska frågor ligger i framkant - regler som GDPR och CCPA ställer strikta krav på hur data får samlas in och kräver noggrann efterlevnad av integritetslagar. Webbplatser använder ofta avancerade skydd som Cloudflare för att upptäcka och blockera skrapning genom IP-begränsningar.
Framtiden för dataskrapning i AI-eran
AI:s utveckling håller på att förvandla webbskrapning till en intuitiv företagslösning. Tänk dig att du bara skriver in en domän, som zillow.com, och din förfrågan, till exempel "skrapa alla bostadsannonser i New York City", och sedan ser AI automatiskt kartlägga varje relevant datapunkt - från objektsdetaljer till prisutveckling - utan manuell konfiguration. Dessa intelligenta system kommer att integrera den insamlade datan sömlöst i affärsflöden, till exempel genom att automatiskt mata in prospektdata från LinkedIn i CRM-system eller skicka e-handelsmått till analysdashboards. Avancerad mönsterigenkänning kommer att möjliggöra prediktiv skrapning som proaktivt övervakar lagersaldo eller nya marknadstrender. Viktigt är också att AI hanterar regelefterlevnad dynamiskt, anpassar skrapparametrar i realtid efter förändrade regler och samtidigt behåller transparenta spår för granskning.
Det AI-drivna skiftet demokratiserar inte bara tillgången till viktig affärsinsikt, utan omformar i grunden hur organisationer arbetar med webdata. I takt med att tekniken mognar kommer tidiga användare som implementerar AI-baserade skraplösningar som Thunderbit att få tydliga konkurrensfördelar i datadrivet beslutsfattande.
Vanliga frågor
-
Vad är Thunderbit? Thunderbit är ett smart webbläsartillägg baserat på stora språkmodeller (LLM), utformat för moderna behov av datainsamling. Det erbjuder inte bara AI-baserad webbskrapning utan även multimodal databehandling, med stöd för omfattande extraktion från dynamiska webbsidor, PDF-dokument, bilder och videor. Som en lokal webbläsarlösning kan det direkt hantera sidor som kräver inloggning, till exempel LinkedIn, och automatiskt anpassa sig till förändringar i moderna frontend-ramverk.
-
Hur fungerar Thunderbits AI-webbskrapare? Thunderbits AI-webbskrapare använder AI för att extrahera strukturerad data från webbplatser. Användare kan klicka på "AI Suggest Columns" för att låta AI föreslå hur den aktuella sajten ska skrapas och sedan klicka på "Scrape" för att samla in datan. Den kan bearbeta data från vilken webbplats, PDF eller bild som helst med bara två klick.
-
Vad är skillnaden mellan listskrapning och undersideskrapning? Listskrapning är optimerad för paginerade scenarier, till exempel e-handelslistor, och känner automatiskt igen pagineringslogik och skrapar tusentals poster. Undersideskrapning använder ett trädliknande insamlingsläge, till exempel Zillow-listningar → detaljsidor → planritningar, och bygger automatiskt relationer mellan huvud- och undertabeller genom semantisk koppling.
-
Kan personer utan programmeringskunskaper använda Thunderbit? Thunderbit har ett gränssnitt för interaktion med naturligt språk: användaren beskriver bara sitt behov, till exempel "namn, e-post, telefon", och systemet skapar automatiskt en skrapplan. Våra testdata visar att 85 % av användarna slutför sin första datainsamling inom 10 minuter, utan någon kunskap om webbprogrammering.
-
Vilka typer av data kan Thunderbit hantera? Thunderbit stöder intelligent igenkänning av många datatyper:
- Strukturerad data: tabeller, listor, till exempel Amazons produktspecifikationer
- Ostrukturerad data: recensionstext, PDF-dokument, med automatisk igenkänning
- Multimodal data: prislappar i bilder, extraktion av videosubtitlar
- Dynamisk data: innehåll med oändlig scroll, bilder som laddas senare
- Relaterad data: relationskartläggning mellan sidor, till exempel LinkedIn-kontakter → företagsinformation
-
Hur kommer man igång med Thunderbit? Läs mer om våra skrapfunktioner eller utforska vårt mallbibliotek för att komma igång direkt.
Läs mer:
- De bästa verktygen och programvarorna för webbskrapning 2025
- Hur du skrapar vilken webbplats som helst med AI
- Så här ställer du in Thunderbit
Testa AI Web Scraper Get Started Free




