
Låt mig avslöja en hemlighet: jag trodde länge att web scraping var något som var förbehållet hackers i luvtröjor eller data scientists med fler skärmar än sunt förnuft. Men i dag är det lika vanligt i affärsvärlden att extrahera data från en webbplats som att ta morgonkaffet — skillnaden är lyckligtvis att du inte behöver kunna Python eller dricka tre espressos före lunch. Faktum är att med framväxten av AI webbskrapare kan även den som tror att “HTML” är en ny smörgås på Subway plocka strukturerad data från det vilda webben.
Om du någon gång har kopierat och klistrat in rader med produktinformation, säljleads eller prislistor i ett kalkylblad är du långt ifrån ensam. Nästan 73 % av företagen använder nu web scraping för marknadsinsikter och bevakning av konkurrenter. Och med en marknad för web scraping-programvara som förväntas nå $2,49 miljarder till 2032 är det tydligt: dataextraktion från webben är inte längre bara för teknikeliten. Så oavsett om du jobbar med försäljning, marknadsföring eller bara vill slippa göra datainmatning för hand är den här guiden för dig. Jag går igenom grunderna, jämför traditionella och AI-drivna arbetssätt och visar hur du kommer i gång — utan att du behöver en luvtröja.
Grunderna i en Webbskrapare: Vad betyder det att skrapa data från en webbplats?
Vi börjar enkelt. En webbskrapare är bara ett verktyg, ett skript eller ett Chrome-tillägg som automatiskt samlar in data från webbplatser. Tänk på det som en extremt snabb praktikant som aldrig klagar på monotona uppgifter. I stället för att du kopierar och klistrar in information rad för rad gör en webbskrapare allt på några sekunder — och den ber inte ens om kaffepaus.
Det finns två huvudsakliga typer av data du kommer att stöta på:
- Strukturerad data: Det här är den snygga, kalkylbladsredo typen — tänk tabeller med produktnamn, priser eller e-postadresser. Den är organiserad, märkt och lätt att analysera.
- Ostrukturerad data: Det här är vilda västern — blogginlägg, recensioner, bilder eller annat som inte passar prydligt i rader och kolumner. De flesta webbskrapningsprojekt syftar till att omvandla ostrukturerad data till strukturerad data så att den faktiskt går att använda.
Om du någon gång har kopierat en tabell från en webbplats till Excel, grattis — du har gjort manuell web scraping. Föreställ dig nu att göra det på 10 000 sidor. (Gör det inte på riktigt. Det är just det webbskrapare är till för.)
Varför skrapa data från webbplatser? Viktiga affärsfördelar
Så varför ens bry sig om att skrapa data? Det korta svaret är: företag lever på data, och webben är världens största databas. Oavsett om du arbetar med försäljning, marknadsföring, e-handel eller fastigheter kan dataextraktion från webben ge dig ett rejält försprång.
Här är några av de vanligaste affärsanvändningsfallen:
| Användningsområde | Beskrivning | Exempel på ROI/fördel |
|---|---|---|
| Leadgenerering | Samla in kontaktuppgifter, e-postadresser eller företagslistor från kataloger eller sociala sajter | Säljteam sparar tid och hittar fler kvalificerade leads |
| Prisbevakning | Följa konkurrenters priser, lagernivåer eller kampanjer i realtid | Handlare justerar priser dynamiskt och ökar försäljningen med 4 % |
| Marknadsundersökning | Samla recensioner, nyheter eller sentiment i sociala medier för att upptäcka trender | Marknadsförare anpassar kampanjer efter aktuella konsumentinsikter |
| Konkurrentanalys | Bevaka rivalers produktkataloger, lanseringar eller innehåll | Företag reagerar snabbare på förändringar i marknaden |
| Fastighetsanalys | Skrapa bostadsannonser, priser och tillgänglighet | Mäklaren och investerare hittar möjligheter före marknaden |
Faktum är att 25–30 % av återförsäljarna i Storbritannien och Europa använder dynamiska prissättningsstrategier som drivs av pris-skrapning av konkurrenter. Och företag som John Lewis och ASOS har sett mätbara försäljningslyft genom att utnyttja webdata för smartare beslut.
Traditionella Verktyg för Webbskrapning: Hur fungerar de?
Låt oss spola tillbaka till det “klassiska” sättet att skrapa data — innan AI började visa musklerna. Traditionella webbskrapare är oftast skript (vanligtvis skrivna i Python) eller webbläsartillägg som följer en uppsättning regler för att hämta datan du vill ha.
Så här brukar processen se ut:
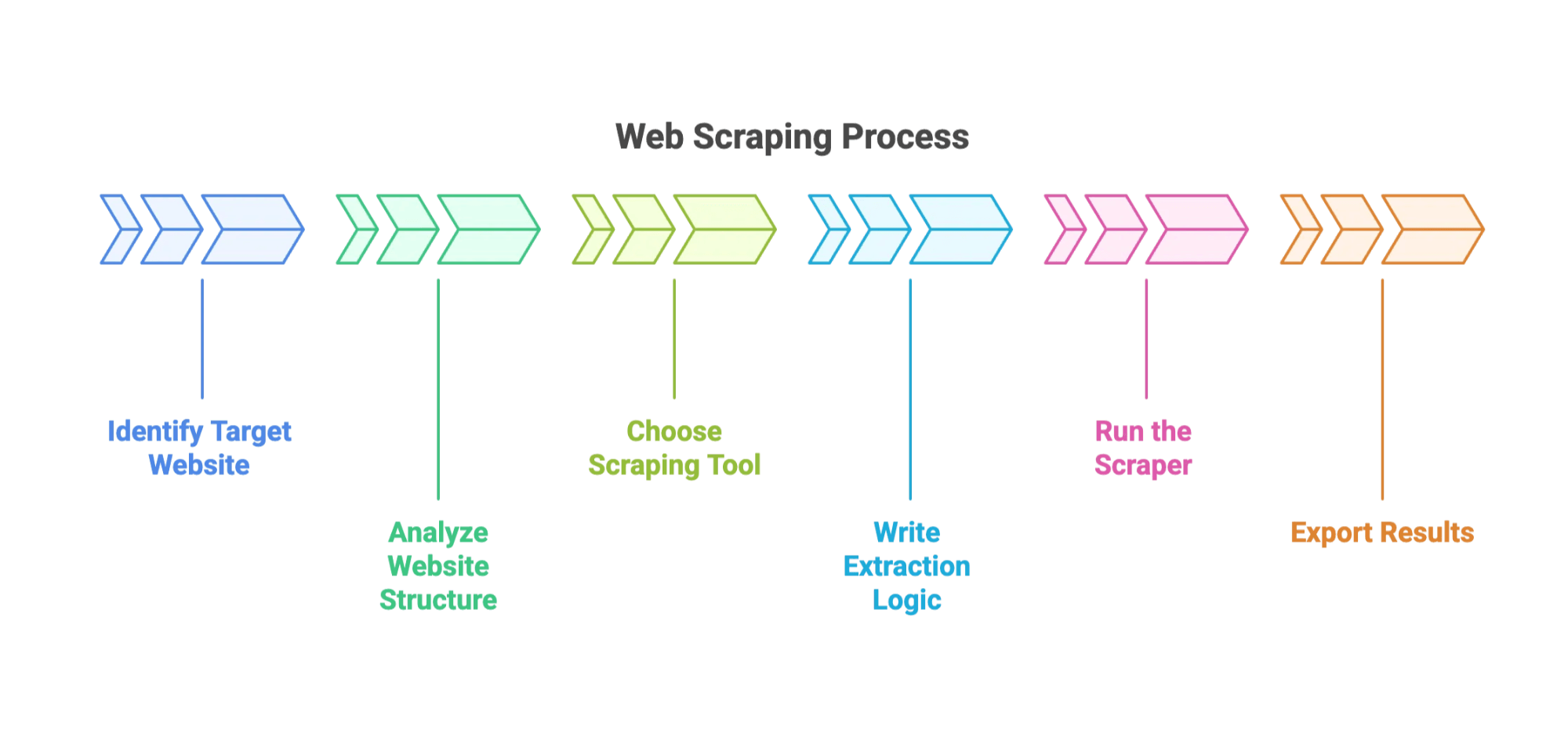
- Identifiera din målwebbplats och de datafält du behöver.
- Analysera webbplatsens struktur. (Det betyder att du letar runt i HTML-koden med webbläsarens utvecklarverktyg. Det är som digital arkeologi.)
- Välj verktyg: Populära alternativ är BeautifulSoup, Scrapy eller webbläsarplugins.
- Skriv extraktionslogiken: Tala om för verktyget hur det ska hitta datan — oftast genom CSS-selektorer eller XPath.
- Kör webbskraparen: Se hur den samlar in data över flera sidor.
- Exportera resultaten: Vanligen som CSV, JSON eller direkt till Excel.
Steg för steg: extrahera data med en traditionell webbskrapare
Säg att du vill skrapa produktlistor från en e-handelswebbplats. Här är en nybörjarvänlig genomgång:
- Steg 1: Installera Python och BeautifulSoup-biblioteket.
- Steg 2: Använd webbläsaren för att inspektera produktsidan. Hitta de HTML-taggar som innehåller produktnamn och pris.
- Steg 3: Skriv ett kort skript som hämtar sidan, tolkar HTML:en och extraherar relevanta fält.
- Steg 4: Loopa igenom flera sidor (hantera sidnumrering).
- Steg 5: Exportera datan till en CSV-fil.
Det låter enkelt, men tro mig — ditt första skript kommer förmodligen att gå sönder minst en gång. (Mitt första försök skrapade 500 rader med “None” eftersom jag stavat ett klassnamn fel. Oops.)
Vanliga utmaningar med traditionella lösningar för webbskrapning
Här blir det lite knepigare:
- Ändringar på webbplatsen: Även en liten justering i sidans layout kan få din skrapare att gå sönder. 10–15 % av skrapare går sönder varje vecka på grund av ändringar.
- Motåtgärder mot bottar: CAPTCHA, IP-blockeringar och hastighetsbegränsningar kan stoppa dig direkt. Du behöver hantera proxies, fördröjningar och ibland till och med lösa CAPTCHA.
- Tekniska kunskaper krävs: Du behöver kunna en del kodning och HTML/CSS.
- Underhåll: Skrapare kräver ständig övervakning och uppdateringar.
- Rörig data: Du kommer att lägga tid på att städa upp inkonsekventa format, saknade värden eller konstig teckenkodning.
För en nybörjare kan det kännas som att försöka baka en tårta medan receptet hela tiden ändras och ugnen ibland låser ute dig.
Här kommer AI-webbskraparen: gör dataextraktion tillgänglig för alla
Skrapa data från vilken webbplats som helst med AI Get Started Free
Nu till det roliga. AI-webbskrapare förändrar spelet (hoppsan, jag höll nästan på att använda den förbjudna formuleringen). I stället för att skriva kod eller pilla med selektorer kan du bara tala om för verktyget vad du vill ha på vanlig svenska. AI:n räknar ut resten.
Thunderbit (det är vi!) är ett bra exempel på den här nya generationen. Med Thunderbit kan du extrahera strukturerad data från vilken webbplats som helst med naturligt språk — ingen kod krävs. Oavsett om du arbetar med försäljning, marknadsföring eller e-handel kan du samla in datan du behöver på minuter, inte dagar.
Thunderbit AI Webbskrapare: hur den förenklar dataextraktion
Låt mig visa hur Thunderbit gör livet enklare:
- AI-föreslå fält: Klicka bara på “AI-föreslå fält” så läser Thunderbit av webbplatsen, föreslår kolumnnamn och ger till och med förslag på hur varje fält ska extraheras.
- Skrapa undersidor: Behöver du mer detaljer? Thunderbit kan besöka varje undersida (till exempel enskilda produktsidor) och berika din datatabell automatiskt.
- Direktmallar: För populära sajter som Amazon eller Zillow kan du använda färdiga mallar — ingen konfiguration behövs.
- Gratis dataexport: Exportera din data till Excel, Google Sheets, Airtable eller Notion. Ladda ner som CSV eller JSON. Inga dolda avgifter.
- Schemalagd skrapning: Ställ in återkommande körningar så att datan hålls färsk — perfekt för prisbevakning eller uppdateringar av leads.
- AI-autofyll: Låt AI fylla i webbformulär åt dig (ja, även det där 10-sidiga formuläret för leverantörsregistrering).
- Extraktorer för e-post, telefon och bilder: Hämta kontaktuppgifter eller bilder med ett klick.
Och det bästa? Du behöver inte kunna ett endaste dugg kod. Thunderbits Chrome-tillägg finns här, och du kan läsa mer på vår officiella webbplats.
Prova Thunderbit AI Webbskrapare gratis
Jämförelse mellan traditionella och AI-drivna lösningar för webbskrapning
Låt oss se hur de två arbetssätten står sig mot varandra:
| Aspekt | Traditionell webbskrapare | AI-webbskrapare (Thunderbit) |
|---|---|---|
| Användarvänlighet | Kräver kodning eller komplex konfiguration | Kodfritt gränssnitt med naturligt språk |
| Anpassningsförmåga | Går lätt sönder vid ändringar på sajten | AI anpassar sig automatiskt till layoutändringar |
| Underhåll | Högt — kräver täta uppdateringar | Lågt — AI hanterar de flesta ändringar |
| Tekniska kunskaper | Kräver programmerings- och HTML-kunskaper | Utformat för affärsanvändare |
| Konfigurationstid | Från timmar till dagar | Minuter |
| Databearbetning | Manuell rensning behövs | AI rensar och strukturerar datan automatiskt |
| Kostnad | Gratis (öppen källkod), men hög tidsinsats | Prisvärda planer, gratis exportalternativ |
För de flesta affärsanvändare, särskilt nybörjare, är AI-webbskrapare som Thunderbit det tydliga vinnande valet när det gäller hastighet, enkelhet och tillförlitlighet. Traditionella verktyg har fortfarande sin plats för mycket skräddarsydda eller storskaliga projekt — men för 95 % av användningsfallen är AI vägen att gå.
Steg-för-steg-guide: hur du skrapar data från en webbplats som nybörjare
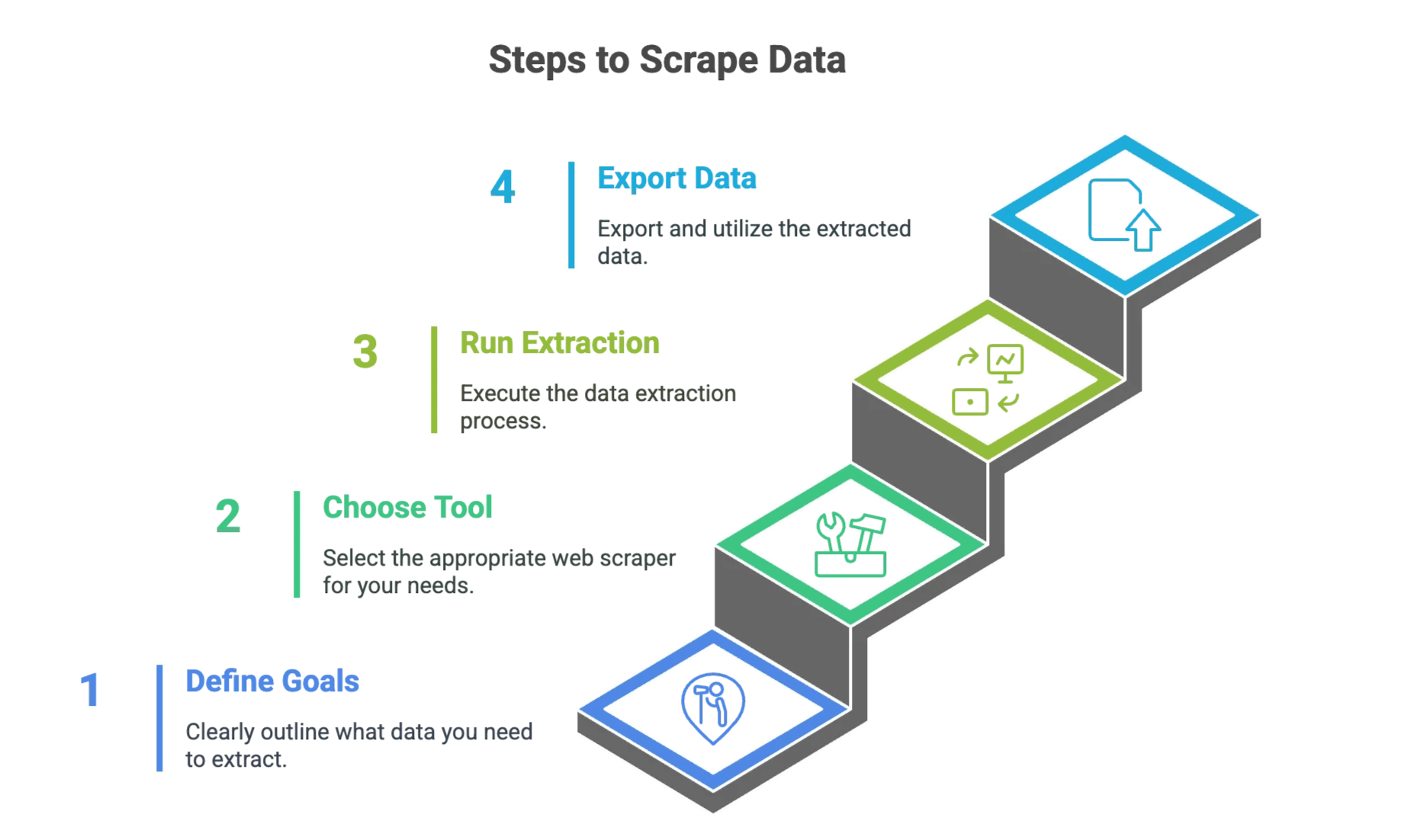
Steg 1: Definiera dina mål för dataextraktion
Innan du börjar, var tydlig med vad du behöver. Fråga dig själv:
- Vilken eller vilka webbplatser vill jag skrapa?
- Vilka datafält är viktiga? (t.ex. produktnamn, pris, e-postadress, telefon)
- Hur ofta behöver jag den här datan? (engångsvis eller återkommande?)
Gör en checklista. Till exempel: “Jag vill samla in produktnamn, priser och betyg från de första 5 sidorna på XYZ.com.”
Steg 2: Välj rätt verktyg för webbskrapning
Här är ett snabbt beslutsflöde:
- Är du bekväm med kod och vill ha full kontroll? Testa ett traditionellt verktyg som BeautifulSoup eller Scrapy.
- Vill du ha fart, enkelhet och ingen kod? Välj en AI-webbskrapare som Thunderbit.
Om du är osäker, börja med AI. Du kan alltid gå djupare senare.
Steg 3: Konfigurera och kör din dataextraktion
Traditionellt arbetssätt
- Installera verktyget: Sätt upp Python och nödvändiga bibliotek.
- Inspektera webbplatsen: Använd webbläsarens utvecklarverktyg för att hitta HTML-strukturen.
- Skriv ditt skript: Definiera hur varje datafält ska hittas och extraheras.
- Testa på en sida: Säkerställ att du får rätt data.
- Skala upp: Lägg till sidnumrering eller loopar för att täcka fler sidor.
- Exportera datan: Spara som CSV eller JSON.
AI-arbetssätt (Thunderbit)
- Installera Thunderbits Chrome-tillägg: Ladda ner här.
- Öppna målwebbplatsen: Gå till sidan du vill skrapa.
- Klicka på “AI-föreslå fält”: Thunderbit läser sidan och föreslår kolumner.
- Granska förhandsvisningen: Kontrollera att datan ser rätt ut. Justera kolumnerna vid behov.
- Klicka på “Skrapa”: Thunderbit samlar in datan åt dig.
- Exportera datan: Ladda ner till Excel, Google Sheets, Airtable eller Notion.
För en visuell genomgång, kolla in vår Thunderbit YouTube-kanal.
Skrapa webbplatsdata med Thunderbit
Steg 4: Exportera och använd din data
När du har din data:
- Exportera till ditt favoritverktyg: Excel, Google Sheets, Airtable, Notion, CSV eller JSON.
- Integrera i ditt arbetsflöde: Använd den för säljutskick, prisanalys, marknadsundersökningar eller vad verksamheten nu behöver.
- Rensa och validera: Även med AI är det klokt att göra stickprovskontroller för att säkerställa noggrannheten.
Tips för lyckad dataextraktion: undvik vanliga fallgropar
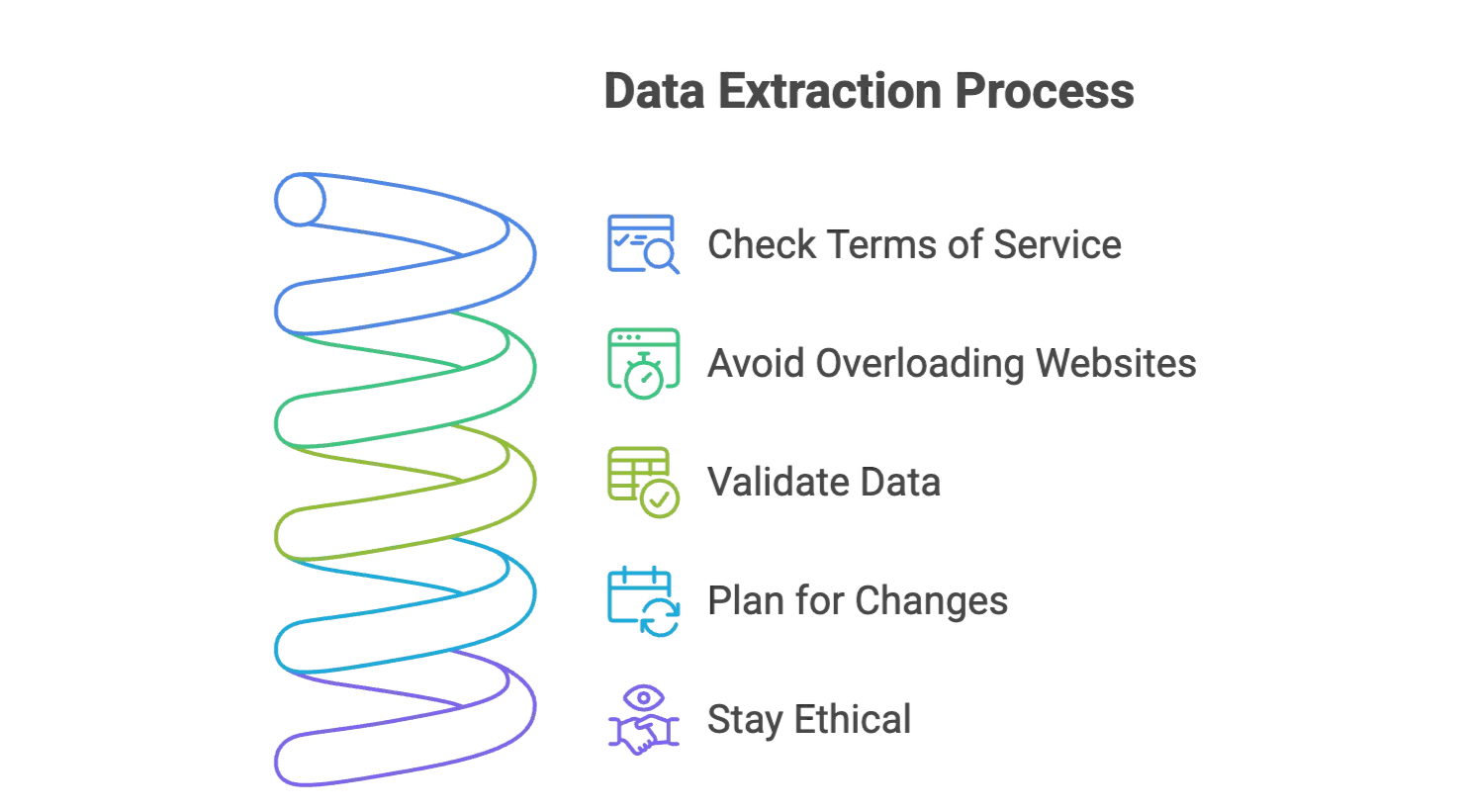
- Kontrollera webbplatsens användarvillkor: Se till att du får skrapa datan. Håll dig till offentlig information och undvik känsliga personuppgifter.
- Överbelasta inte webbplatser: Lägg in pauser mellan begärningar (traditionella verktyg) eller låt Thunderbit hantera det åt dig.
- Validera datan: Kontrollera alltid ett urval av resultaten för att säkerställa riktigheten.
- Planera för ändringar: Webbplatser uppdateras hela tiden. AI-skrapare som Thunderbit anpassar sig automatiskt, men det är bra att hålla koll på större förändringar.
- Var etisk: Skrapa bara det du behöver och ange källan om du använder datan i rapporter eller publikationer.
För fler tips, se vår Vad är data scraping och hur gör man det 2025 och Hur man skrapar vilken webbplats som helst med AI.
Slutsats och viktiga lärdomar
Web scraping har kommit långt — från dagarna med handkodade skript till dagens AI-drivna, nybörjarvänliga verktyg. De stora skillnaderna?

- Traditionella skrapare ger kontroll men kräver kodning, underhåll och tålamod.
- AI-webbskrapare som Thunderbit gör dataextraktion tillgänglig för alla, med kommandon på naturligt språk, omedelbara förhandsvisningar och robusta funktioner som skrapning av undersidor och schemalagd skrapning.
Om du är ny på web scraping, låt dig inte skrämmas. Verktygen har aldrig varit enklare att använda, och affärsnyttan är odiskutabel. Oavsett om du vill generera leads, bevaka priser eller bara sluta kopiera och klistra in, är AI-webbskrapare din nya bästa vän.
Så nästa gång du står och stirrar på ett berg av webdata, kom ihåg: du behöver varken en doktorsexamen i datavetenskap — eller ens en luvtröja. Bara ett tydligt mål, rätt verktyg och kanske en kopp riktigt bra kaffe.
Redo att testa själv? Installera Thunderbit och se hur enkel dataextraktion från webben kan vara.
Nyfiken på mer? Kolla in Thunderbit Blog för fördjupningar om att skrapa Amazon, Google, PDF:er och mer. Lycka till med skrapandet!
Prova Thunderbit AI Webbskrapare nu Get Started Free
Vanliga frågor
F1: Är web scraping lagligt? S: Ja, att skrapa offentlig data är generellt lagligt i många länder. Kontrollera dock alltid webbplatsens användarvillkor och undvik att skrapa känsliga eller personliga uppgifter.
F2: Kan jag skrapa webbplatser som kräver inloggning? S: Ja, men det är mer komplext och kan bryta mot sajtens policy. Du behöver hantering av sessioner eller autentiserade skrapningsverktyg, och det är viktigt att granska de juridiska konsekvenserna.
F3: Hur kan jag skrapa data från webbplatser med mycket JavaScript? S: Använd verktyg som stödjer dynamisk rendering, till exempel headless-webbläsare eller AI-skrapare som simulerar mänskliga interaktioner och tolkar innehåll som renderas med JavaScript.
F4: Vilka är de bästa metoderna för att undvika att bli blockerad? S: Använd hastighetsbegränsning, slumpmässiga fördröjningar, rotation av user-agent och undvik aggressiv skrapning. AI-baserade skrapare hanterar ofta dessa strategier automatiskt.
Läs mer
-
Förstå lagligheten kring web scraping: globala insikter och statistik Översikt över juridiska riktlinjer, branschstatistik och etiska bästa praxis.
-
Web scraping 2025: lägesrapport Trender, marknadstillväxt och AI:s roll i dataextraktion från webben (2024–2025).
-
Vad är en robots.txt-fil? En guide till bästa praxis och syntax Lär dig tolka robots.txt-filer för att vägleda etisk och laglig skrapning.




