
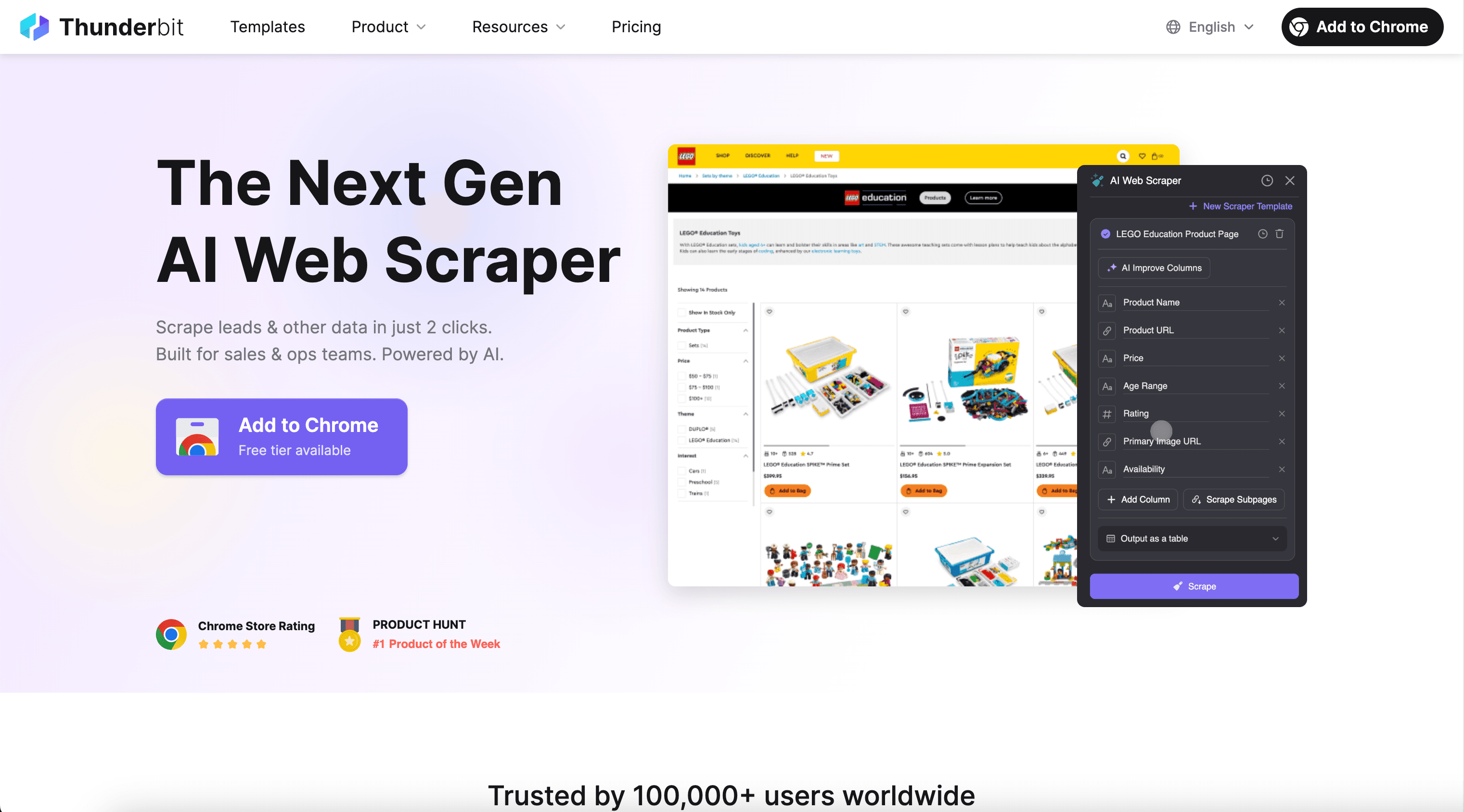
Thunderbit’s Image Scraper помогает извлекать URL изображений и связанные данные страницы со страниц списков и детальных страниц, а затем с помощью ИИ превращает всё в аккуратную таблицу, которую можно экспортировать куда угодно. За пару кликов через AI Web Scraper вы соберёте изображения товаров для e-commerce процессов или превью из соцсетей для контент-аналитики.
🖼️ Что такое Image Scraper
Image Scraper на базе ИИ — это , который позволяет собирать изображения (и контекст вокруг них) с сайтов вроде Amazon и TikTok. Откройте нужную страницу, нажмите AI Suggest Fields — ИИ предложит оптимальные колонки (URL изображения, заголовок, цена, ссылка на пост и т. д.), затем нажмите Scrape, чтобы получить структурированные данные и экспортировать их в Excel, Google Sheets, Airtable или Notion.
🧲 Что можно собирать с Image Scraper
Нужно ли вам собрать библиотеку товарных изображений, отслеживать карточки конкурентов или выгрузить превью постов для креативного ресёрча — Image Scraper от Thunderbit умеет забирать и изображения, и метаданные с одной и той же страницы. А с помощью Subpage Scraping можно переходить на каждую детальную страницу и дополнять набор данных дополнительными фото, вариантами или описаниями.
🛍️ Сбор изображений товаров для e-commerce
Например, со страницы результатов поиска Amazon, такой как , можно собрать миниатюры товаров, названия, цены, рейтинги и URL карточек. Это полезно для наполнения каталога, мониторинга конкурентов, исследований мерчандайзинга и креативных тестов.
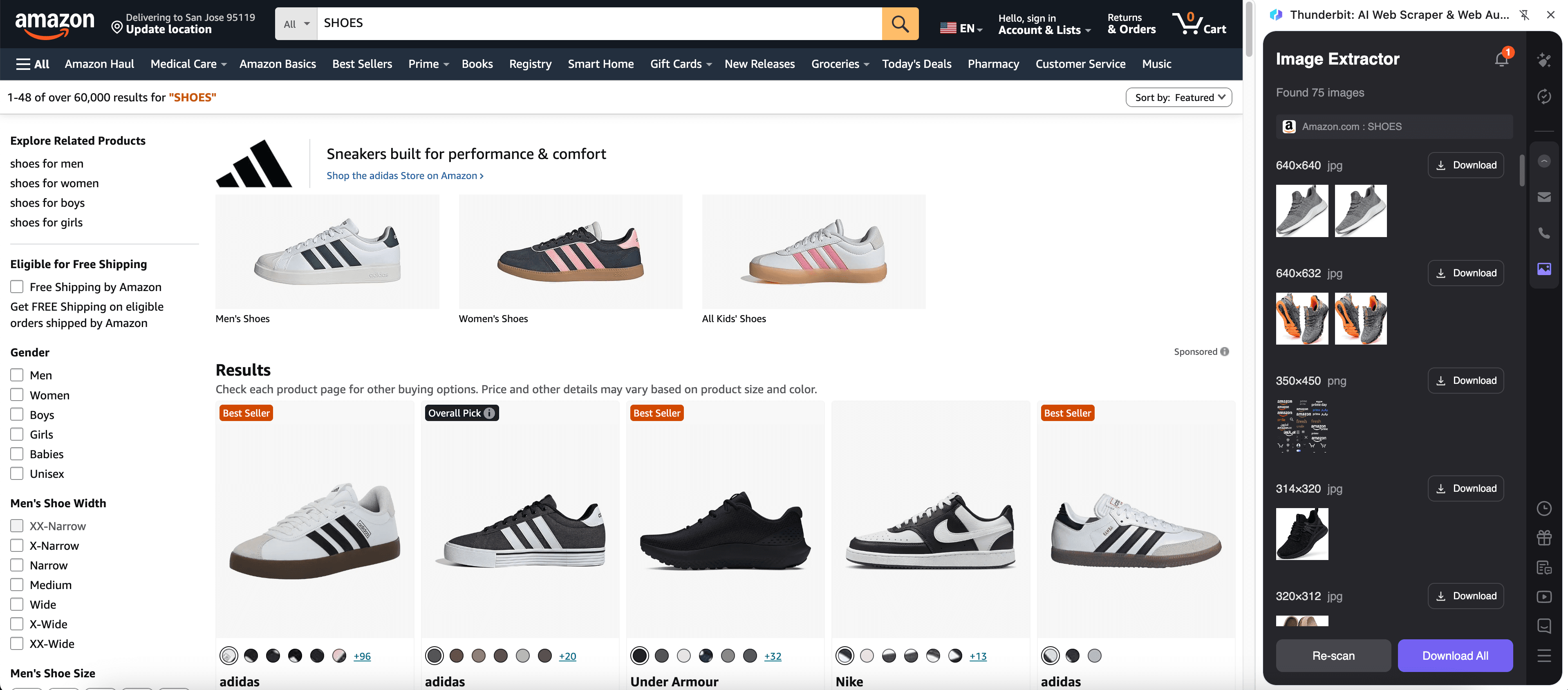
Шаги:
- Установите и зарегистрируйте аккаунт.
- Откройте нужную страницу, например: .
- Нажмите AI Suggest Fields — инструмент предложит названия колонок и типы данных для изображений и атрибутов товара.
- Нажмите Scrape, запустите сбор и экспортируйте в Excel, Google Sheets, Airtable, Notion, CSV или JSON.
Названия колонок
| Колонка | Описание |
|---|---|
| 🖼️ Image URL | Ссылка на миниатюру товара со страницы списка (удобно для создания библиотеки изображений). |
| 🏷️ Product Title | Название товара, как оно показано в результатах поиска. |
| 🔗 Product URL | Ссылка на страницу товара для обогащения данных через subpage scraping. |
| 💲 Price | Цена из выдачи (если доступна), сохранённая числом для аналитики. |
| ⭐ Rating | Средний рейтинг в звёздах, отображаемый в списке. |
| 🧾 Review Count | Общее число отзывов, показанное для товара. |
| 🏪 Brand / Store | Бренд или название магазина, если указано в карточке. |
| 📦 Prime / Shipping Badge | Значки доставки/Prime и другие индикаторы, видимые в карточке. |
Совет: После сбора со страницы списка используйте Scrape Subpages, чтобы зайти в каждую карточку товара и собрать дополнительные изображения (галерею), варианты или более подробные описания.
🎬 Анализ изображений у инфлюенсеров в соцсетях
Например, с профиля TikTok, такого как , можно собрать превью постов, URL постов, подписи (если видны) и метрики вовлечённости. Это помогает в контент-аудитах, подборках вдохновения, исследовании инфлюенсеров и отслеживании трендов.
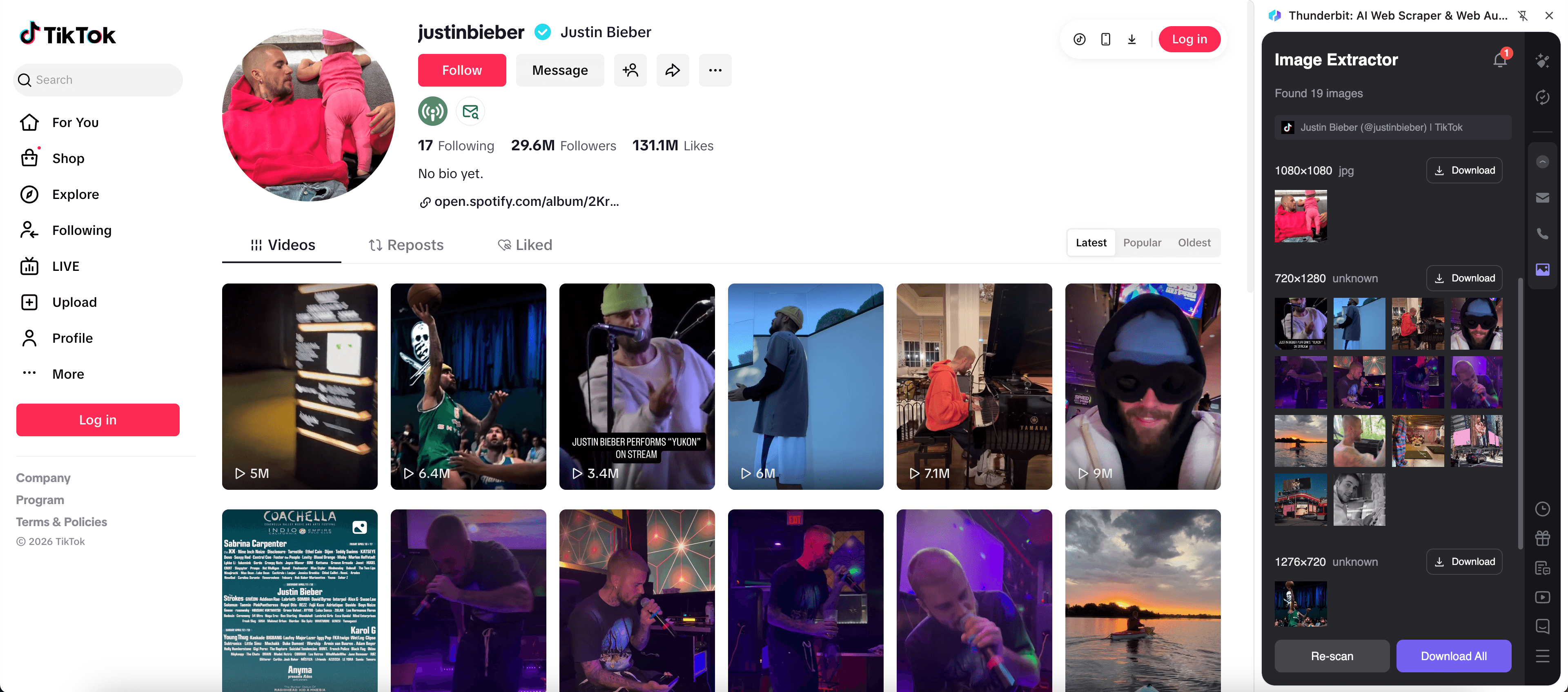
Шаги:
- Установите и зарегистрируйте аккаунт.
- Откройте нужную страницу, например: .
- Нажмите AI Suggest Fields, чтобы сгенерировать колонки для превью, ссылок и видимых метаданных.
- Нажмите Scrape, соберите данные и экспортируйте их в удобный инструмент.
Названия колонок
| Колонка | Описание |
|---|---|
| 🖼️ Thumbnail Image URL | Превью-изображение каждого поста в сетке профиля. |
| 🔗 Post URL | Прямая ссылка на пост для более глубокого анализа через subpage scraping. |
| 📝 Caption / Text | Текст подписи к посту, если он доступен на странице. |
| 👤 Creator Handle | Ник/handle аккаунта, связанного с контентом. |
| 📅 Post Date | Дата/время, если доступно (часто удобнее забирать со страницы поста). |
| ▶️ Views | Количество просмотров, показанное в сетке (если отображается). |
| ❤️ Likes | Количество лайков, если видно (часто лучше забирать со страницы поста). |
| 🧩 Tags / Hashtags | Хэштеги, извлечённые из текста подписи, если присутствуют. |
Совет: TikTok часто подгружает контент динамически. Если вы авторизованы или важна именно ваша сессия браузера, выбирайте Browser Scraping. Если страница публичная и доступна без ограничений, Cloud Scraping обычно быстрее.
🎯 Зачем использовать Image Scraper
Сбор изображений почти никогда не сводится к «скачать картинки». Обычно нужен кадр + контекст (название, URL, цена, автор, вовлечённость), чтобы затем искать, фильтровать и анализировать.
Вот как команды используют AI-инструмент для извлечения URL изображений:
- E-commerce команды: собирают наборы изображений конкурентов, отслеживают изменения ассортимента и сравнивают цены вместе с визуалами с маркетплейсов и сайтов брендов.
- Маркетинг: собирает креативные референсы, ведёт доски вдохновения для рекламы и связывает визуалы с метриками эффективности.
- Продажи: обогащают списки лидов бренд-материалами и контекстом страницы для персонализации аутрича.
- Недвижимость: собирают фото объявлений вместе с адресом, ценой и характеристиками объекта (особенно эффективно с subpage scraping).
- Аналитики и исследователи: превращают «грязные» страницы в структурированные датасеты без поддержки хрупких селекторов.
Thunderbit рассчитан на бизнес-задачи, где важны скорость, точность и минимальная настройка, а также экспорт в инструменты, которые уже есть в вашем стеке.
🧩 Как пользоваться Image Scraper в Chrome
- Установите Thunderbit Chrome Extension: скачайте из и создайте аккаунт на .
- Откройте страницу с большим количеством изображений: это может быть страница списка (например, ) или сетка профиля (например, ).
- Запустите сбор с ИИ: нажмите AI Suggest Fields, чтобы получить названия колонок и типы данных, затем при необходимости отредактируйте (например, добавьте “Image Alt Text” или “Variant”).
- Соберите данные и обогатите через subpages: нажмите Scrape для текущей страницы, затем используйте Scrape Subpages, чтобы перейти по каждому URL товара/поста и собрать дополнительные изображения и детали.
Если нужен более подробный разбор AI-сценариев, помогут эти материалы:
💳 Стоимость использования Image Scraper
Image Scraper в Thunderbit работает по кредитной системе, где 1 кредит = 1 строка результата в таблице. Если вы собрали 120 строк (товаров или постов), будет списано 120 кредитов.
Важно:
- Сбор с ИИ включён в Thunderbit — можно начинать сразу.
- На тарифе Free доступен сбор 6 страниц в месяц (лимит по страницам).
- В бесплатном пробном периоде можно собрать 10 страниц бесплатно — удобно протестировать связку «список + subpages» на реальном процессе.
- Экспорт в Excel, Google Sheets, Airtable, Notion, CSV или JSON — бесплатный.
Если вы регулярно собираете изображения (ежедневный мониторинг, большие каталоги или несколько рынков), годовые планы обычно выгоднее за счёт скидки. Сравнить варианты можно на странице .
❓ FAQ
-
Что такое AI Powered Image Scraper?
AI Powered Image Scraper — это инструмент внутри , который извлекает URL изображений и связанные метаданные со страниц и превращает их в структурированные строки и колонки. Вместо ручной настройки селекторов вы нажимаете AI Suggest Fields, и ИИ Thunderbit предлагает схему таблицы под конкретную страницу. -
Что такое Thunderbit?
Thunderbit — это AI Web Scraper Chrome Extension для бизнес-пользователей, которым нужны быстрые структурированные данные из интернета без кода. Также доступны функции продуктивности: subpage scraping, работа с пагинацией, Scheduled Scraper, а ещё бесплатные экстракторы email-адресов, телефонов и изображений. -
Можно ли собирать изображения и одновременно сохранять контекст (название, цена, ссылка)?
Да. Thunderbit рассчитан на сбор изображений и полей вокруг них — например, названия товара, цены, рейтинга или URL поста. Это удобно, когда нужно фильтровать изображения по атрибутам или позже объединять их с другими наборами данных. -
Как subpage scraping помогает при сборе изображений?
На многих сайтах в списке показывается только одна миниатюра, а в карточке — полноценная галерея. С Subpage Scraping Thunderbit может перейти по каждому URL товара или поста и добавить в ту же таблицу дополнительные колонки: дополнительные URL изображений, описания или информацию о вариантах. -
Thunderbit скачивает файлы изображений или только извлекает URL?
Thunderbit в первую очередь извлекает URL изображений и связанные поля в структурированный датасет. При экспорте в Airtable или Notion поля с изображениями могут подгружаться в их медиатеки — так набор данных проще просматривать и использовать. -
Чем отличается Cloud Scraping от Browser Scraping для страниц с изображениями?
Cloud Scraping быстрее и позволяет собирать до 50 страниц за один запуск — отлично подходит для публичных страниц, например многих e-commerce листингов. Browser Scraping выполняется в вашей сессии Chrome и лучше подходит, когда нужен логин, региональные настройки или динамический контент, зависящий от состояния локального браузера. -
Можно ли собирать страницы с бесконечной прокруткой или пагинацией?
Да. Thunderbit поддерживает и пагинацию по кликам, и бесконечный скролл. Для сбора изображений это важно, потому что многие списки подгружают новые товары/посты при прокрутке, а Thunderbit может продолжать добавлять строки по мере расширения списка. -
Сколько стоит собрать 500 строк с изображениями?
Поскольку 1 кредит = 1 строка результата, сбор 500 строк потребует 500 кредитов. Итоговая стоимость зависит от лимита кредитов в вашем месячном или годовом плане; оценить расход можно, сначала запустив небольшой тестовый сбор. -
Можно ли собирать изображения с Amazon или TikTok?
Всегда соблюдайте условия использования сайта, уважайте авторские права и правила конфиденциальности, а также следуйте применимым законам и требованиям. Thunderbit предоставляет инструменты для извлечения данных, но ответственность за корректное использование данных лежит на вас.
📚 Узнать больше
- Начните с
- Больше туториалов и сценариев — в
- Основы скрейпинга:
- Датасеты на основе списков:
- Быстрый экспорт чистых таблиц:
- Если также нужно извлекать текст из документов: