
Все вокруг говорят о принятии решений на основе данных, но при этом часто забывают, сколько времени и сил съедает сам сбор информации. Если тебе хоть раз приходилось собирать данные вручную, ты знаешь, насколько это выматывает. Я видел немало компаний, у которых из-за неэффективного сбора данных так и не получалось запустить стратегию, основанную на данных. Если ситуация тебе знакома, в этой статье ты найдешь свежие решения.
💡 В этой статье мы разберем, что такое data scraping, как эта сфера меняется вместе с технологиями, чем плохи старые подходы и какие преимущества дает AI-подход. А еще покажем практические советы для реального применения.
Что такое Data Scraping?
Data scraping, или web scraping, — это извлечение структурированных данных со страниц сайта с помощью специальных инструментов, чаще всего из таблиц и похожих блоков. Это очень эффективный способ быстро собрать большой объем информации. Например, можно получить общедоступные данные из Google Maps для поиска лидов, извлечь SKU товаров с Amazon для перепродажи или анализа рынка, либо собрать отзывы из Yelp для понимания мнения клиентов.
Как менялся Data Scraping вместе с технологиями
Раньше сбор данных казался задачей только для технарей — либо требовал бесконечного ручного копирования и вставки. Но сейчас на дворе 2025 год, и в игру активно входит AI. Data scraping больше не ограничивается программистами или простейшей автоматизацией.
Почему традиционные методы перестают справляться
Современные сайты создают все больше сложностей: динамическая подгрузка контента (например, на React/Vue), рост мультимодальных данных (текст, видео, изображения) и нестандартизированные структуры (несколько шаблонов на одной странице). Недавние исследования выделяют три главные проблемы традиционных методов web scraping:
-
Бездна затрат на поддержку
Традиционные веб-скраперы требуют постоянного ручного обслуживания — примерно 3–5 часов в месяц на каждый сайт. Когда сайт обновляется или меняет фронтенд-фреймворк, ломается около 60% XPath-селекторов. AI-инструменты, благодаря языковым моделям и умению работать с кодом, могут автоматически адаптироваться к 90% структурных изменений, сокращая расходы на поддержку на 60–80%. Для современных сайтов на React/Vue AI-решения сохраняют стабильность data scraping за счет семантического понимания, даже если меняются названия классов. -
Ограниченный охват типов данных
Традиционные методы умеют забирать только структурированные данные, но упускают ценную информацию, например:- данные внутри изображений
- текст в статьях
- неструктурированные данные без HTML-тегов
-
Проблемы с качеством данных
Традиционные подходы плохо справляются с динамическим контентом, из-за чего данные часто оказываются неполными или неточными:- на страницах с пагинацией (например, в списках товаров) обычные скраперы захватывают только 30–50% контента первого экрана;
- на страницах с бесконечной прокруткой (например, в лентах соцсетей) теряется более 60% важной информации;
- при сопоставлении неструктурированных данных высока доля ошибок, из-за чего списки могут смещаться и искажаться.
Именно здесь на сцену выходят AI-инструменты вроде Thunderbit. Ниже я разберу их преимущества подробнее.
Расцвет AI-сбора данных
Извлекайте данные с любого сайта с помощью AI Get Started Free
К 2025 году AI, особенно большие языковые модели (LLM), уже показали впечатляющие возможности. Они понимают и генерируют естественный язык, справляются со сложными задачами анализа данных и предлагают более эффективные решения. Многие инструменты для data scraping теперь используют LLM, чтобы преодолеть ограничения традиционных методов. Изучив 13 инструментов для сбора данных за последние месяцы, я рекомендую Thunderbit AI Web Scraper.
Вот почему Thunderbit выделяется:
-
Революционный способ взаимодействия:
Пользователь просто вводит обычную команду на естественном языке, а система сама строит план сбора данных. По сравнению с традиционными инструментами это сокращает время настройки на 87%. -
Сильные стороны локального сбора данных:
Будучи расширением для браузера, Thunderbit предлагает:- мгновенный сбор данных
- работу с динамическими страницами и страницами с бесконечной прокруткой
- сбор данных со страниц, где требуется вход в аккаунт
-
Мощная обработка мультимодальных данных:
Thunderbit умеет работать с разными типами данных, например:- извлекать данные из текста в статьях
- вытягивать финансовые таблицы из PDF
- распознавать данные из нескольких изображений и собирать их в таблицы
- извлекать субтитры из видео и кратко их пересказывать
С Thunderbit можно легко закрывать самые разные сценарии сбора данных. Давай посмотрим, как им пользоваться.
Как собирать данные с помощью AI
Следуй этим четырем шагам, чтобы использовать мощные AI web scraping возможности Thunderbit:
-
Установи расширение для браузера
Перейди на сайт Thunderbit и скачай расширение в Chrome Web Store. После установки закрепи его на панели инструментов браузера. -
Зарегистрируйся и получи бесплатные кредиты
Зарегистрируйся прямо в расширении и получи пробные кредиты. С их помощью можно протестировать основные функции, включая AI web scraping, автозаполнение форм и интеллектуальное суммирование. Сначала лучше поиграться с инструментом бесплатно в playground, чтобы оценить его возможности, а уже потом тратить кредиты. -
Запусти умный сбор данных
Открой шаблон из боковой панели Thunderbit. С помощью описания на естественном языке выбери нужные данные и их тип, задай формат извлечения или уточни другие параметры. Затем нажми кнопку scrape, чтобы начать сбор данных.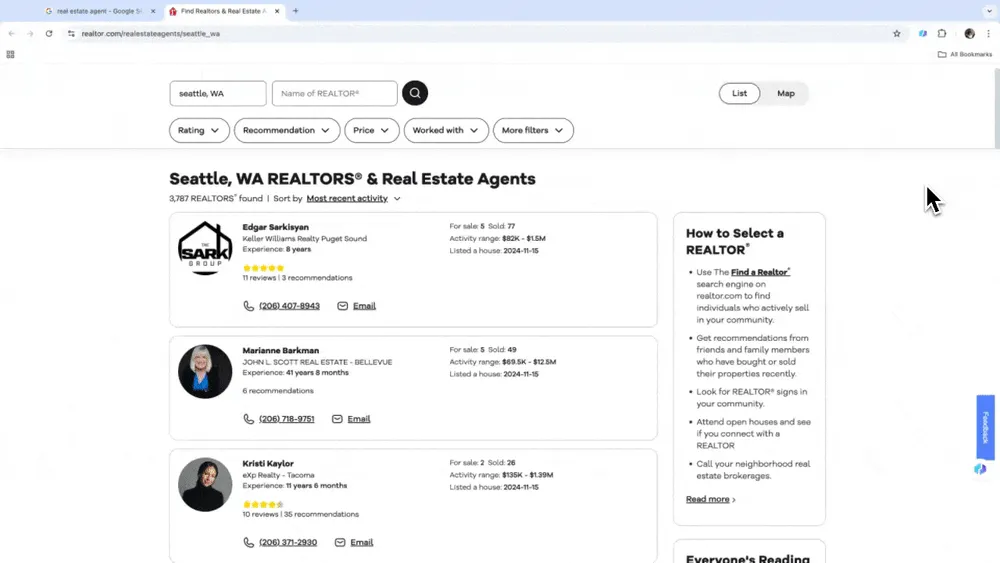
Продвинутые функции скрапинга (Pro-тариф)
Если оформить Pro Tier Thunderbit или начать бесплатный пробный период, ты получишь доступ к следующим функциям:
-
Мультимодальная обработка данных
Поддерживает сложные сценарии, такие как разбор PDF-документов (финансовые отчеты, инструкции к продуктам), извлечение данных из изображений (ценники, спецификации) и сбор субтитров из видео. Система автоматически приводит неструктурированные данные к единому виду. -
Глубокий сбор со вложенных страниц
Можно перейти по внутренним ссылкам на странице (например, на страницы товаров или страницы отзывов), интеллектуально распознать связанные данные и автоматически объединить их в основную таблицу. Отлично подходит для каталогов товаров, объектов недвижимости и других похожих сценариев. -
Готовая библиотека шаблонов
Мгновенно используй оптимизированные шаблоны для сбора данных более чем для 30 платформ, включая TikTok, Amazon и Zillow. Они автоматически адаптируются к изменениям структуры страниц. Новые пользователи в среднем экономят 83% времени на настройке. -
Пакетный сбор данных
Запускай несколько задач одновременно, поддерживая импорт списка URL для массового сбора. -
Умная работа с пагинацией
Автоматически распознает и собирает контент с пагинированных страниц, включая кнопки "load more" и навигацию по страницам, а также поддерживает страницы с бесконечной прокруткой. Тесты показали, что инструмент способен полностью собрать данные более чем со 200 страниц списков товаров.
Практическое руководство по Thunderbit
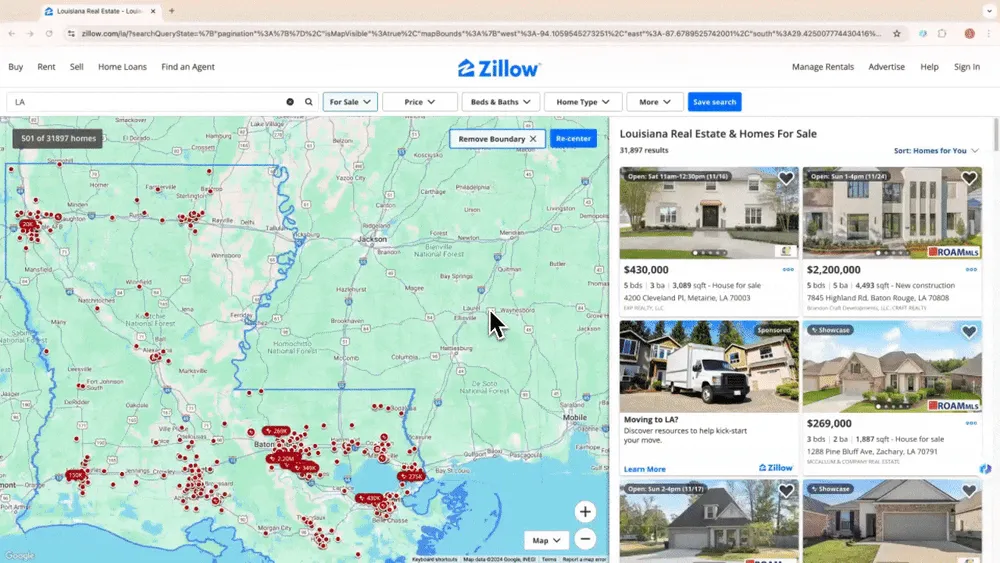
Сценарий 1: Сбор данных о недвижимости
Если ты риелтор и хочешь собрать данные об объектах на Zillow, или инвестор, ищущий выгодные варианты, надежный веб-скрапер может стать твоим лучшим помощником. AI web scraper Thunderbit позволяет легко извлекать важную информацию об объектах Zillow, чтобы ты всегда оставался в курсе и сохранял конкурентное преимущество. Посмотри видеоурок о том, как собирать данные Zillow с помощью Thunderbit.
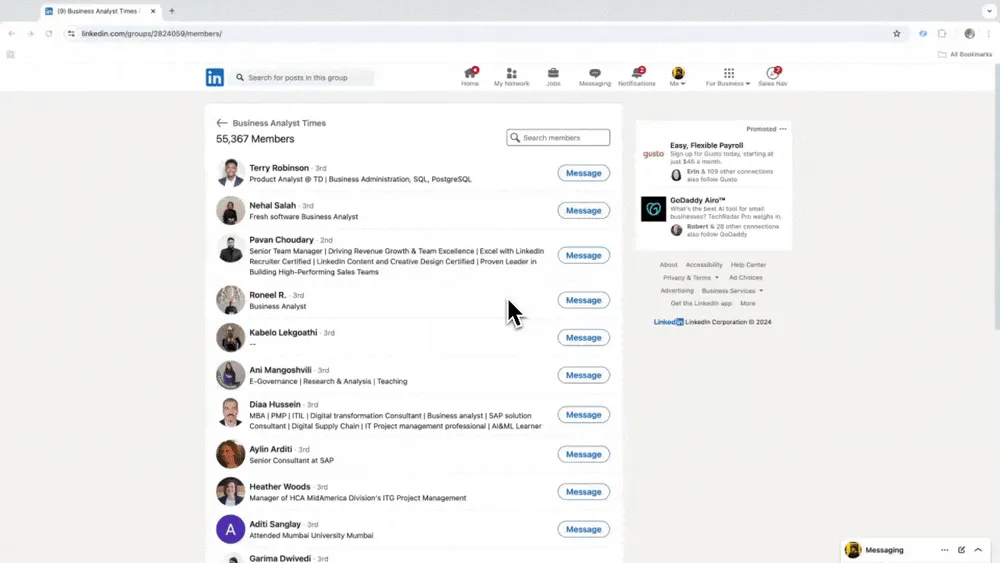
Сценарий 2: Поиск кандидатов и клиентов
Если ты работаешь в HR и ищешь кандидатов, или занимаешься продажами и находишь новые лиды, надежный веб-скрапер станет мощным ассистентом. Thunderbit помогает извлекать полезные контактные и корпоративные данные с публичных сайтов, каталогов и профилей, упрощая поиск талантов и управление лидами. После использования ты заметишь, что долгие ручные поиски и копирование-вставка уходят в прошлое. Для готового сценария начни с Website Contact Scraper.
Сценарий 3: Анализ рынка и таргетинг клиентов
Если ты владелец бизнеса и собираешь географические данные для анализа рынка, или специалист по продажам ищешь локальные бизнес-лиды, надежный веб-скрапер может полностью изменить подход к работе. Thunderbit позволяет легко извлекать ключевые данные из Google Maps, помогая принимать обоснованные решения и точнее выстраивать outreach.
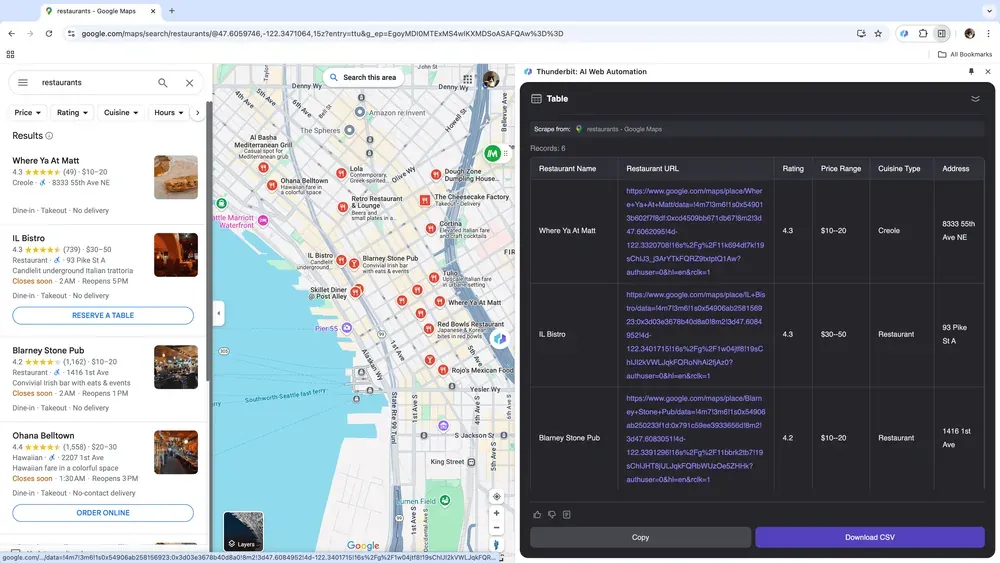
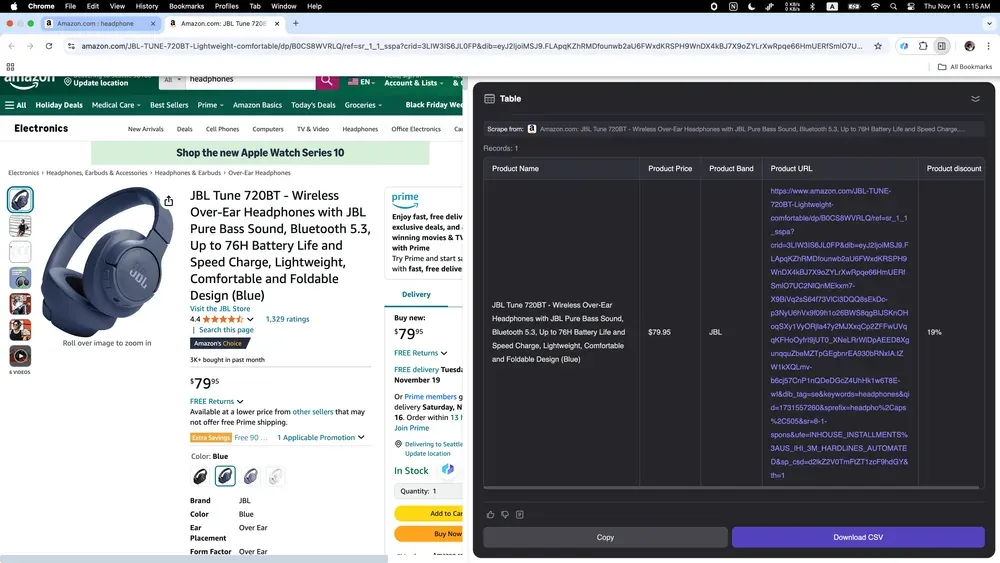
Сценарий 4: Анализ данных для e-commerce
Если ты продавец в интернете и хочешь понять конкурентов, или предприниматель, отслеживающий рыночные тренды, Thunderbit станет идеальным инструментом. Он легко собирает разнообразные данные о товарах с Amazon, включая подробные описания, цены и отзывы пользователей.
AI web scraper Thunderbit по-новому определяет, как бизнес-пользователи собирают данные, делая это быстрее, проще и эффективнее, чем когда-либо. Независимо от того, ищешь ли ты объекты недвижимости, потенциальных клиентов или анализируешь тренды в e-commerce, AI web scrapers сэкономят тебе массу времени и избавят от рутины. Используй силу AI в web scraping и почувствуй, как растет твоя продуктивность. Готов начать? Попробуй Thunderbit и сделай первый шаг к более умному сбору данных.
Попробовать AI Web Scraper Thunderbit
Эксклюзивные советы по очистке данных
В случае с традиционными скраперами настоящая работа начинается уже после data scraping — на этапе очистки данных. AI Thunderbit умеет выполнять очистку прямо во время сбора с помощью LLM, сокращая объем ручной работы по очистке данных на 83% благодаря следующим функциям:
Совет 1: Интеллектуальное сопоставление полей
При работе с разнородными данными из нескольких источников (например, если одновременно собирать данные из LinkedIn и Zillow) AI Thunderbit автоматически строит семантические связи между полями:
- автоматически определяет соответствия полей в разных источниках данных (например, "price" ↔ "售价" ↔ "Price")
- интеллектуально объединяет похожие поля (например, "area" и "square feet")
- стандартизирует данные между платформами (например, "current position" в LinkedIn и "property status" в Zillow можно привести к единому типу тегов)
Совет 2: Заполнение с учетом контекста
Благодаря пониманию контекста со стороны больших языковых моделей Thunderbit достигает ведущего в отрасли уровня заполнения данных — 99%:
- Заполнение адреса: автоматически добавляет город и штат по ZIP-коду (например, ввод 10001 → New York City, NY)
- Прогноз карьерного пути: определяет возможный опыт работы на основе образования в профиле LinkedIn
Совет 3: Оптимизация данных
- Многоязычный перевод (поддерживает перевод в реальном времени на 12 языков, включая английский, китайский и японский)
- Умное резюмирование (сокращает описание товара на 500 слов до трех ключевых преимуществ)
- Приведение единиц к единому виду (автоматически конвертирует square feet ↔ square meters, Fahrenheit ↔ Celsius)
- Стандартизация форматов (даты приводятся к YYYY-MM-DD, валюта — к USD)
Совет 4: Проверка качества
- Интеллектуальная коррекция ошибок: автоматически исправляет ошибки формата (например, phone number +01 138-1234-5678 → +113812345678)
- Логическая проверка: следит за тем, чтобы "year built" был раньше, чем "last renovation time"
Совет 5: AI-тегирование
Автоматически создает умные теги с помощью обработки естественного языка:
- теги тональности (автоматически помечает отзывы как положительные/отрицательные/нейтральные)
- теги бизнес-ценности (автоматически присваивает метки вроде "high-potential clients" / "properties to follow up on")
- теги отраслевой классификации (автоматически отмечает профили LinkedIn тегами "tech|finance|healthcare")
Минусы data scraping
Хотя сбор данных дает огромную ценность, важно учитывать и сложности, с которыми могут столкнуться компании. В первую очередь это юридические вопросы: такие нормы, как GDPR и CCPA, устанавливают строгие требования к сбору и обработке данных, поэтому соблюдать законы о конфиденциальности нужно особенно внимательно. Кроме того, сайты часто используют продвинутую защиту, например Cloudflare, чтобы выявлять и блокировать скрапинг по IP-ограничениям.
Будущее data scraping в эпоху AI
Развитие AI превращает web scraping в интуитивно понятный корпоративный инструмент. Представь: ты просто вводишь домен, например zillow.com, и задаешь запрос вроде "собери все объявления о недвижимости в New York City", а AI сам выстраивает всю карту данных — от характеристик объектов до ценовых трендов — без ручной настройки. Такие интеллектуальные системы будут бесшовно встраивать собранные данные в бизнес-процессы, автоматически передавая информацию о лидах из LinkedIn в CRM или отправляя e-commerce-метрики в аналитические панели. Продвинутые алгоритмы распознавания паттернов откроют возможности предиктивного scraping — системы смогут заранее отслеживать изменения запасов или появление новых рыночных трендов. И что особенно важно, AI будет динамически учитывать требования compliance, меняя параметры сбора данных в реальном времени в соответствии с новыми правилами и сохраняя прозрачный аудит действий.
Этот AI-переход не только демократизирует доступ к важной бизнес-аналитике, но и полностью меняет то, как компании работают с веб-данными. По мере развития этих технологий ранние пользователи решений вроде Thunderbit получат заметное преимущество в принятии решений на основе данных.
FAQ
-
Что такое Thunderbit? Thunderbit — это умное браузерное расширение на базе больших языковых моделей (LLM), созданное для современных задач сбора данных. Оно не только поддерживает AI web scraping, но и предлагает мультимодальную обработку данных, позволяя извлекать информацию с динамических страниц, из PDF-документов, изображений и видео. Будучи локальным решением для браузера, оно может работать даже со страницами, где требуется вход в аккаунт, например LinkedIn, и автоматически адаптироваться к изменениям современных фронтенд-фреймворков.
-
Как работает AI web scraper Thunderbit? AI web scraper Thunderbit использует AI для извлечения структурированных данных с сайтов. Пользователь может нажать "AI Suggest Columns", чтобы AI предложил, как лучше собрать данные с текущего сайта, а затем нажать "Scrape", чтобы начать сбор. Инструмент способен обрабатывать данные с любого сайта, PDF или изображения всего за два клика.
-
Чем отличается сбор списков от сбора подстраниц? Сбор списков оптимален для сценариев с пагинацией, например для списков товаров в e-commerce: он автоматически распознает логику страниц и собирает тысячи записей. Сбор подстраниц использует древовидную модель обхода, например для Zillow: список объектов → страницы с деталями → планы этажей. При этом связи между основными и вложенными таблицами строятся автоматически на основе семантической связи.
-
Могут ли Thunderbit использовать не программисты? У Thunderbit есть интерфейс, основанный на естественном языке: пользователю достаточно описать задачу, например "имя, email, телефон", и система сама сформирует план сбора. По нашим тестовым данным, 85% пользователей завершают первый сбор данных менее чем за 10 минут, не имея опыта в веб-программировании.
-
Какие типы данных умеет обрабатывать Thunderbit? Thunderbit поддерживает интеллектуальное распознавание многих типов данных:
- структурированные данные: таблицы, списки (например, характеристики товаров Amazon)
- неструктурированные данные: текст отзывов, PDF-документы (автоматическое распознавание)
- мультимодальные данные: ценники на изображениях, извлечение субтитров из видео
- динамические данные: контент с бесконечной прокруткой, изображения с lazy loading
- связанные данные: сопоставление связей между страницами (например, контакты LinkedIn → информация о компании)
-
Как начать пользоваться Thunderbit? Узнай больше о наших возможностях сбора данных или изучи нашу библиотеку шаблонов, чтобы сразу приступить к работе.
Подробнее:
- Лучшие инструменты и программы для web scraping в 2025 году
- Как собрать данные с любого сайта с помощью AI
- Как настроить Thunderbit
Попробовать AI Web Scraper Get Started Free




