

Интернет растёт так быстро, что это уже трудно даже нормально представить. Каждый день публикуются миллиарды новых страниц, товаров, отзывов и наборов данных — и всё это питает самые разные задачи: от маркетинговых исследований и обучения ИИ до вашего следующего заказа на Amazon. За годы работы в SaaS и автоматизации я не раз убеждался: правильные данные могут и помочь бизнесу принять верное решение, и, наоборот, потопить его. Но вот в чём загвоздка: собирать, обновлять и интерпретировать весь этот web-объём становится всё сложнее, а не проще. Классические веб-скрейперы уже не успевают за темпом, и бизнесу нужен более умный и быстрый способ превращать интернет в практические инсайты. На сцену выходит cloud crawler — инструмент, который тихо, но уверенно меняет то, как компании находят и используют веб-данные в больших масштабах.
Так что же такое cloud crawler? Чем он отличается от привычных web scraper? И почему команды — от продаж до операционных подразделений — делают ставку на эту технологию, чтобы не выпасть из мира, где всё крутится вокруг данных? Давайте разберёмся спокойно, без лишнего шума, простыми словами, и посмотрим, как cloud crawler’ы (особенно решение Thunderbit) меняют правила игры для современного бизнеса.
Что такое cloud crawler? Следующий шаг в поиске данных
Извлекайте данные с любого сайта с помощью ИИ Get Started Free
Объясним по-простому: cloud crawler — это не просто веб-скрейпер, который работает в облаке. Скорее, это движок для поиска и анализа данных — умная облачная система, которая автоматически находит, извлекает и анализирует огромные массивы информации по всему интернету. Обычный web scraper обычно забирает данные с нескольких страниц, часто по одной за раз и, как правило, с одного устройства. Cloud crawler работает совсем на другом уровне: он запускается в мощных облачных дата-центрах, одновременно обходит тысячи и даже миллионы страниц и умеет обрабатывать всё — от текста до изображений и PDF, каким бы сложным или разросшимся ни был сайт.
Представьте это так: если web scraper — это один библиотекарь, который вручную переписывает фрагменты из книги, то cloud crawler — это команда суперкомпьютеров, которая одновременно сканирует всю библиотеку, сразу помечает, структурирует и анализирует содержание. Результат? Бизнес получает более полные, свежие и полезные данные — без ограничений локального железа и без ручной рутины (Sitebulb, Octoparse).
Cloud crawler vs. традиционный web scraper: в чём реальная разница?
Если ты когда-либо пользовался web scraper, то знаешь базовый принцип: указываешь страницу, задаёшь, что нужно собрать, и запускаешь извлечение данных. Но по мере того как интернет становится больше и сложнее, старый подход начинает упираться в потолок. Вот как cloud crawler и традиционный web scraper выглядят в сравнении:
| Характеристика / аспект | Традиционный web scraper | Cloud crawler |
|---|---|---|
| Развёртывание | Работает на вашем локальном устройстве или сервере | Запускается в облаке (удалённые дата-центры) |
| Масштаб | Ограничен мощностью вашего компьютера | Массово параллельная обработка — тысячи страниц одновременно |
| Скорость | Медленнее, особенно на больших объёмах | Высокоскоростная пакетная обработка |
| Поддержка и обновления | Нужны частые доработки, ломается при изменениях сайта | Облачный, автоматически обновляется, менее хрупкий |
| Типы данных | Обычно текст, иногда изображения | Текст, изображения, PDF, сложные макеты |
| Доступ | Привязан к вашему устройству и сети | Доступен из любой точки и с любого устройства |
| Планирование | Вручную или простая автоматизация | Расширенное планирование, повторяющиеся задачи |
| Лучше всего подходит для | Небольших проектов и простых сайтов | Больших объёмов, регулярных и сложных задач |
Cloud crawler’ы созданы для современного интернета, где данные есть везде, а скорость и масштаб — не опция, а необходимость (GPTBots, Octoparse).
Как cloud crawler резко повышает эффективность сбора данных
Вот тут начинается самое интересное. Cloud crawler’ы используют мощность облачных вычислений, чтобы обрабатывать тысячи веб-страниц параллельно. Это значит, что ты можешь собрать весь каталог интернет-магазина, отслеживать цены конкурентов на десятках сайтов или агрегировать объявления по недвижимости со всех крупных порталов — и всё это за долю того времени, которое занял бы традиционный скрейпер.
Почему это важно? Потому что в ecommerce, финансах и недвижимости свежесть данных решает всё. Цены, остатки и рыночные тренды меняются буквально каждую минуту. Ждать часы или даже дни, пока локальный скрейпер закончит работу, просто нельзя. Cloud crawler’ы не зависят от RAM твоего ноутбука или стабильности офисного Wi‑Fi — они масштабируются по мере необходимости, так что ты спокойно справляешься с большими задачами (Zyte, Octoparse).
Больше всего от такой эффективности выигрывают следующие отрасли:
- Ecommerce: мониторинг цен, агрегация товарных каталогов, анализ отзывов
- Недвижимость: сбор объявлений, отслеживание рыночных трендов, сравнение объектов
- Финансы: анализ новостей и настроений, мониторинг акций и криптовалют, отслеживание регуляторных изменений
- Продажи и маркетинг: генерация лидов, исследование конкурентов, выявление трендов
И это, честно говоря, только верхушка айсберга. Если тебе нужны веб-данные в масштабе, cloud crawler — это новый лучший помощник.
Решение Thunderbit Cloud Crawler: быстро, гибко и мощно
На минуту надену шляпу Thunderbit (хотя, если честно, я её почти не снимаю). Облачный режим Thunderbit — это наш ответ на современные задачи с данными: cloud crawler, созданный для бизнес-пользователей, которым нужен результат, а не головная боль.
Вот чем выделяется cloud crawler Thunderbit:
- Пакетный сбор на высокой скорости: извлекайте до 50 страниц одновременно, используя облачные серверы в США, ЕС и Азии для глобального охвата. Больше не нужно ждать, пока ноутбук медленно переварит длинный список.
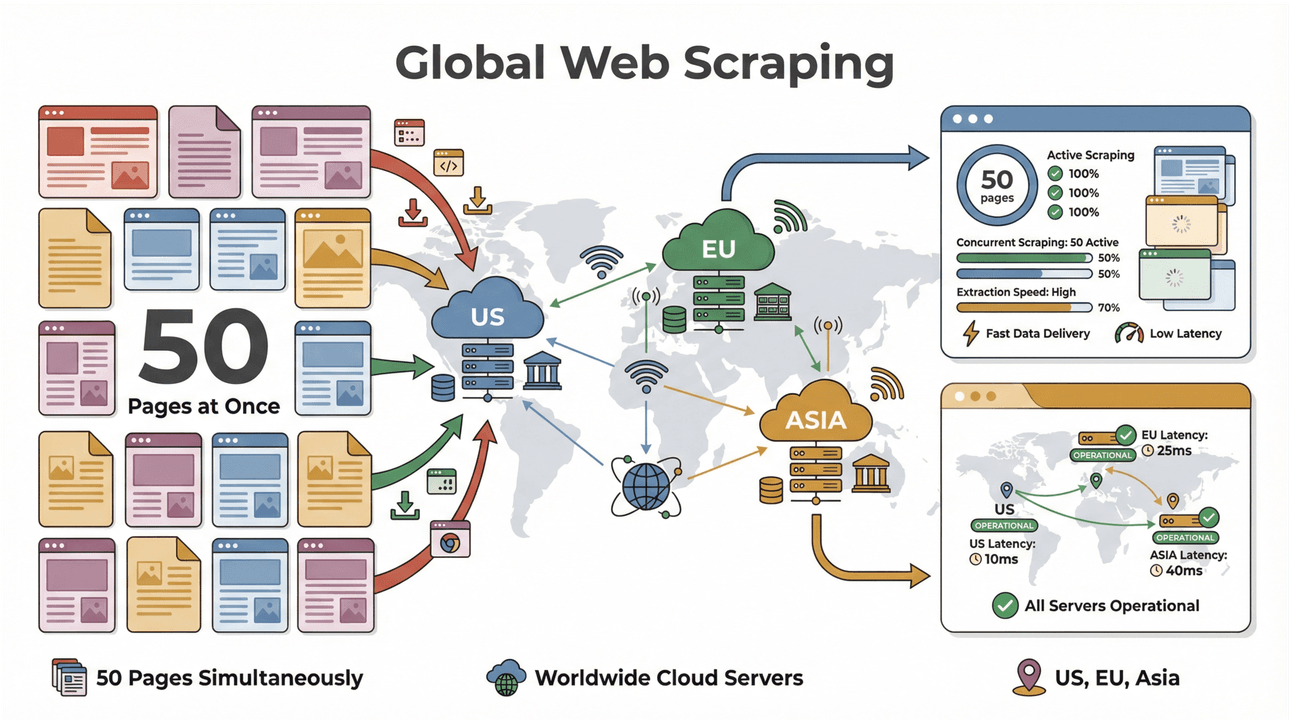
- Поддержка сложных страниц: ИИ Thunderbit справляется со всем — от динамических ecommerce-сайтов до сложных PDF и даже извлечения изображений. Если это есть в интернете, Thunderbit, скорее всего, сможет это собрать (Thunderbit).
- Сканирование вложенных страниц: Нужно обогатить данные деталями со вложенных страниц, например характеристиками товара или биографией автора? ИИ Thunderbit может переходить по подстраницам и объединять результаты в основной набор данных (Thunderbit).
- Умная структура данных: используй “AI Suggest Fields”, чтобы Thunderbit сам проанализировал сайт и предложил лучшие столбцы — без кода и без ручной настройки шаблонов.
- Экспорт куда удобно: отправляйте данные прямо в Excel, Google Sheets, Airtable или Notion. Либо скачивайте их в CSV/JSON — как удобнее твоему процессу (Thunderbit).
- Без обслуживания: ИИ Thunderbit подстраивается под изменения на сайте, поэтому тебе не придётся постоянно чинить сломанные скрейперы (Thunderbit).
И да, попробовать всё это можно в бесплатном тарифе — так что верить мне на слово не нужно.
Попробуйте Thunderbit Cloud Scraper бесплатно
Развёртывание cloud crawler: облако или локально — что выбрать?
Одно из главных преимуществ cloud crawler’ов — гибкость развёртывания. В случае с традиционным локальным crawler’ом ты привязан к конкретному устройству, сети и, как правило, к куче настроек и проблем. Если компьютер уснёт или пропадёт интернет, сбор данных остановится. Чтобы масштабироваться, нужно покупать железо или запускать несколько скриптов.
Cloud crawler’ы переворачивают эту модель:
- Не нужно специальное оборудование: вся тяжёлая работа выполняется в облаке. Запустить крупный сбор можно хоть с Chromebook, хоть с Mac, хоть даже с телефона.
- Доступ из любой точки: в дороге? На удалёнке? Без проблем — ваш cloud crawler всегда под рукой.
- Лёгкое масштабирование: нужно собрать 10 000 страниц вместо 100? Просто увеличьте размер задачи — без участия IT.
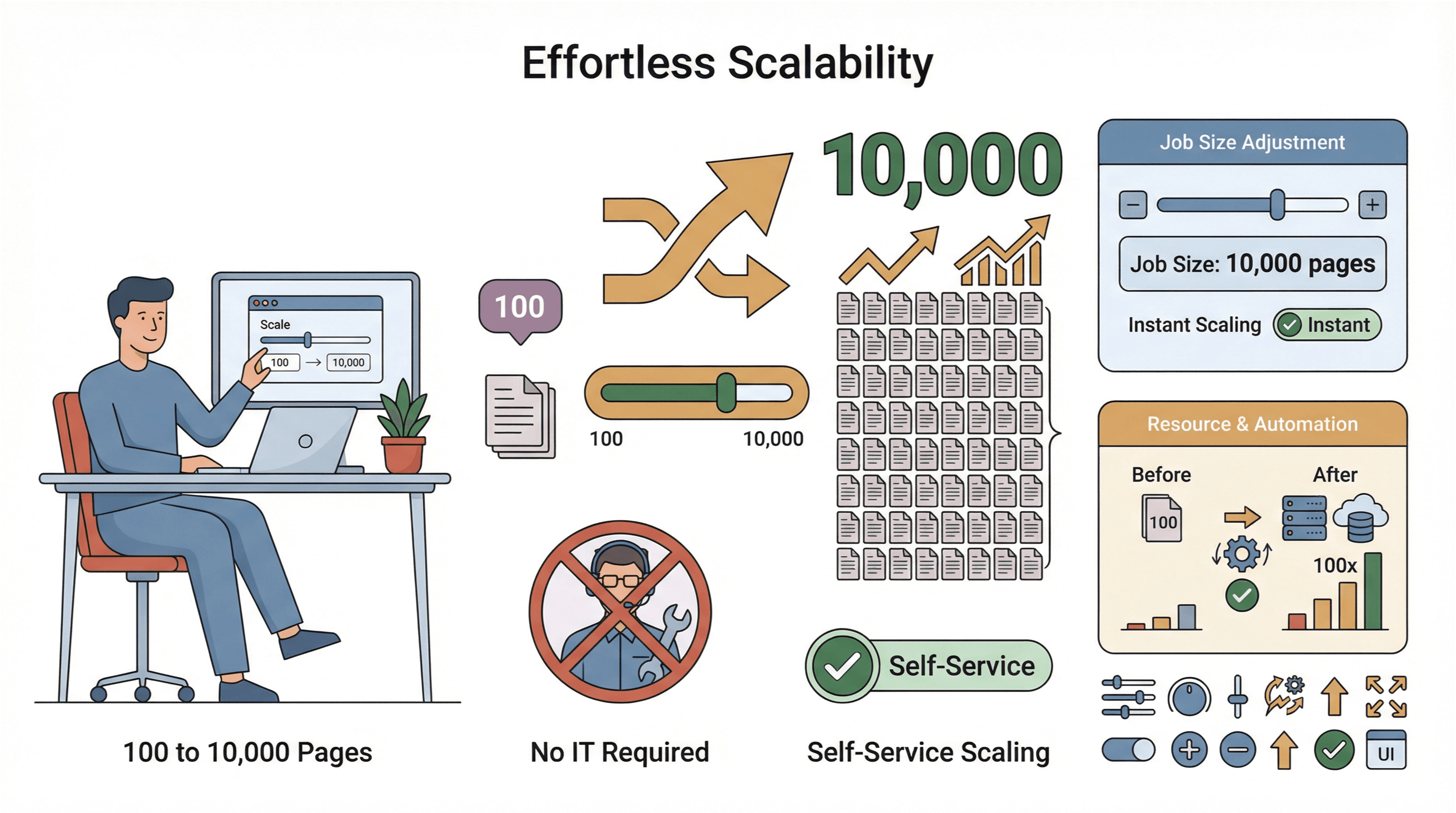
- Сбор данных по всему миру: благодаря облачным серверам в разных регионах ты можешь работать с геоограниченным контентом и проще соблюдать требования комплаенса (PromptCloud).
Конечно, безопасность и соответствие требованиям — всегда в приоритете. Лучшие cloud crawler’ы, включая Thunderbit, используют шифрование, соблюдают условия сайтов и предлагают функции, помогающие ответственно работать с чувствительными данными.
Реальный эффект: как cloud crawler’ы меняют стратегии, основанные на данных
Перейдём к практике. Почему компании переходят на cloud crawler’ы? Потому что видят реальный и измеримый результат:
- Анализ рынка в реальном времени: ритейлеры используют cloud crawler’ы, чтобы отслеживать цены и остатки конкурентов в режиме реального времени, выстраивая динамическое ценообразование и быстрее реагируя на изменения рынка (Zyte).
- Прогнозирование потребительских трендов: бренды собирают отзывы, публикации в соцсетях и обсуждения на форумах, чтобы замечать новые тенденции и быстро корректировать кампании.
- Продажи и лидогенерация: sales-команды формируют актуальные списки лидов из каталогов, страниц мероприятий и даже PDF — и загружают в CRM свежие, релевантные контакты (Thunderbit).
- Операции и комплаенс: финансовые компании используют cloud crawler’ы для отслеживания регуляторных обновлений, новостей и отчётности в разных юрисдикциях — снижая риски и опережая изменения.
Общий вывод простой: cloud crawler’ы помогают командам работать быстрее, принимать более умные решения и обходить конкурентов, которые всё ещё движутся по медленной полосе.
На что смотреть при выборе cloud crawler’а
Посмотреть цены и возможности Thunderbit Get Started Free
Не все cloud crawler’ы одинаковы. Если ты выбираешь инструмент, вот характеристики, которые действительно важны (и в которых Thunderbit особенно силён):
- Масштабируемость: справляется ли он с тысячами страниц одновременно? Замедляется ли при росте нагрузки?
- Простота использования: удобен ли интерфейс для нетехнических пользователей? Можно ли настроить сбор в несколько кликов?
- Поддержка разных типов данных: текст, изображения, PDF, вложенные страницы — умеет ли он работать со всем этим?
- Интеграции: экспортирует ли он данные в твои любимые инструменты (Excel, Sheets, Notion, Airtable)?
- Планирование: можно ли запускать повторяющиеся задачи, чтобы данные всегда были свежими?
- ИИ-помощь: есть ли умные подсказки по полям, обогащение данных и адаптация к изменениям сайта?
- Безопасность и соответствие требованиям: защищены ли ваши данные и учётные данные? Помогает ли инструмент соблюдать законы о конфиденциальности?
Thunderbit закрывает все эти пункты, поэтому это один из лучших вариантов для команд, которым нужна мощность без лишней боли.
Как начать использовать cloud crawler для вашего бизнеса
Готовы попробовать? Вот как обычно бизнес-пользователь начинает работать с cloud crawler’ом вроде Thunderbit:
- Установите расширение Thunderbit для Chrome: быстрая установка, без участия IT.
- Выберите цель: откройте сайт, список или документ, который нужно собрать.
- Нажмите “AI Suggest Fields”: пусть ИИ Thunderbit просканирует страницу и предложит лучшие столбцы для извлечения.
- Настройте под себя: добавляйте, удаляйте или переименовывайте поля, чтобы они соответствовали вашим задачам.
- Выберите облачный режим: для больших задач или сложных сайтов переключитесь в cloud mode для максимальной скорости.
- Запустите сбор: Thunderbit обработает до 50 страниц одновременно в облаке.
- Проверьте и экспортируйте: просмотрите результаты, затем экспортируйте их в Excel, Google Sheets, Notion или Airtable.
- Настройте повторяющиеся задачи: если данные нужны регулярно, запланируйте сбор — и они будут обновляться автоматически (Thunderbit Docs).
Совет: начните с небольшой задачи, чтобы привыкнуть к процессу, а потом увеличивайте объём по мере уверенности. И не стесняйтесь обращаться к поддержке Thunderbit или документации — они для этого и нужны.
Начните cloud crawling с Thunderbit
Будущее сбора данных: что дальше для cloud crawler’ов?
Революция cloud crawler’ов только начинается. Вот за чем я слежу в ближайшие годы:
- Более умное извлечение с ИИ: cloud crawler’ы всё лучше понимают контекст, связи между сущностями и даже тональность — а значит, собираемые данные становятся ценнее (GPTBots).
- Поддержка новых типов данных: ожидается лучшая работа с видео, аудио и интерактивным контентом — не только со статическим текстом и изображениями.
- Глубокая автоматизация: от автопланирования до уведомлений в реальном времени — cloud crawler’ы станут ещё более автономными для бизнеса.
- Усиление compliance: по мере развития законов о конфиденциальности cloud crawler’ы будут получать больше инструментов, помогающих соответствовать требованиям.
- Интеграция с BI и ИИ-инструментами: прямые потоки данных из cloud crawler’ов в аналитические системы, дашборды и платформы машинного обучения.
Иными словами, cloud crawler’ы готовы стать фундаментом цифровой бизнес-стратегии — от запусков продуктов до прогнозирования на основе ИИ (Thunderbit Blog).
Заключение: почему cloud crawler’ы необходимы современному бизнесу
Подведём итог: интернет взрывается от объёма данных, а старые методы их сбора уже не справляются. Cloud crawler’ы — это следующий этап эволюции: они дают скорость, масштаб и интеллект, с которыми традиционные скрейперы просто не могут конкурировать. Такие инструменты, как Thunderbit, позволяют любой команде — технической или нет — раскрыть полный потенциал веб-данных, принимать более умные решения, быстрее реагировать на изменения и получать реальное конкурентное преимущество.
Если ты готов оставить ручной сбор данных и медленные процессы в прошлом, сейчас самое время посмотреть, что cloud crawler может дать твоему бизнесу. Попробуй облачный режим Thunderbit и убедись, насколько простым и мощным может быть современный поиск данных. А если хочешь узнать больше, загляни в Thunderbit Blog — там есть ещё больше гайдов, советов и практических примеров.
FAQ
1. Что такое cloud crawler простыми словами?
Cloud crawler — это облачный инструмент, который автоматически находит, извлекает и анализирует большие объёмы данных в интернете. В отличие от традиционных скрейперов, работающих на локальном устройстве, cloud crawler’ы функционируют в мощных дата-центрах, что позволяет им работать быстрее и в гораздо большем масштабе.
2. Чем cloud crawler отличается от обычного web scraper?
Cloud crawler’ы работают в облаке, обрабатывают тысячи страниц одновременно, поддерживают сложные типы данных, такие как изображения и PDF, и не требуют обслуживания или локального оборудования. Традиционные скрейперы ограничены мощностью твоего устройства и лучше подходят для небольших и простых задач.
3. В чём основные преимущества использования cloud crawler?
Cloud crawler’ы обеспечивают быстрый сбор данных в больших объёмах, поддерживают сложные сайты, доступны из любой точки и предлагают расширенные функции, такие как планирование и извлечение данных с помощью ИИ. Они идеально подходят для бизнеса, которому нужны свежие и полезные данные без задержек.
4. Как работает cloud crawler Thunderbit для бизнес-пользователей?
Cloud crawler Thunderbit позволяет настроить сбор данных всего в несколько кликов — без программирования. Ты можешь извлекать данные с сайтов, PDF и изображений, обогащать их с помощью ИИ и сразу экспортировать в Excel, Google Sheets, Notion или Airtable. Он создан для тех, кто хочет результата, а не сложности.
5. Насколько безопасен cloud crawling и соответствует ли он законам о конфиденциальности?
Да, ведущие cloud crawler’ы, такие как Thunderbit, используют шифрованные соединения и лучшие практики защиты данных. Важно собирать только общедоступную информацию и соблюдать условия использования сайтов и требования законодательства о конфиденциальности.
Готовы посмотреть, на что способен cloud crawler? Скачайте Thunderbit и уже сегодня начните исследовать мир облачного сбора данных в больших масштабах.
Попробуйте Thunderbit Cloud Crawler уже сегодня Get Started Free
Узнайте больше




