

В интернете полно ценных данных — будь вы в продажах, e-commerce или маркетинговых исследованиях, веб-скрейпинг — это секретное оружие для генерации лидов, мониторинга цен и конкурентного анализа. Но есть одна проблема: чем больше компаний используют скрейпинг, тем активнее сайты дают отпор. Перемены налицо: анализ ppc.land за 2024 год показал, что более трети из топ-1000 сайтов уже блокируют как минимум скрейлер OpenAI — а более широкий набор IP-банов, CAPTCHA и браузерного фингерпринтинга теперь скорее норма, чем исключение.
Если вы хоть раз видели, как ваш Python-скрипт спокойно работает 20 минут, а потом внезапно упирается в стену из ошибок 403, вы знаете, насколько это раздражает.
Я много лет работаю в SaaS и автоматизации и на практике видел, как проекты по скрейпингу в одно мгновение превращаются из «вау, как это просто» в «почему меня блокируют везде?». Поэтому давайте без лишней теории: я покажу, как делать веб-скрейпинг на Python и не попасть под блокировку, поделюсь лучшими техниками и фрагментами кода, а также расскажу, когда пора задуматься об альтернативах на базе ИИ, таких как Thunderbit. Будь вы опытным Python-разработчиком или просто пытаетесь кое-как скрейпить данные, в конце у вас будет набор инструментов для надежного извлечения данных без блокировок.
Что такое веб-скрейпинг без блокировок на Python?
Если говорить по сути, веб-скрейпинг без блокировок — это извлечение данных с сайтов так, чтобы не задевать их антибот-защиту. В мире Python речь идет не просто о написании цикла requests.get() — нужно вести себя как обычный пользователь и оставаться на шаг впереди систем обнаружения.
Почему именно Python? Python — самый популярный язык для веб-скрейпинга благодаря простому синтаксису, огромной экосистеме (вспомните requests, BeautifulSoup, Scrapy, Selenium) и гибкости — от быстрых скриптов до распределенных краулеров. Но популярность имеет цену: многие антибот-системы теперь настроены на распознавание именно паттернов скрейпинга на Python.
Так что, если вы хотите скрейпить стабильно, нужно идти дальше базовых приемов. А это значит понимать, как сайты выявляют ботов, и как их обходить — не выходя за рамки этики и закона.
Почему важно избегать блокировок в проектах веб-скрейпинга на Python
Блокировка — это не просто техническая неполадка, она может сорвать целые бизнес-процессы. Разберем по пунктам:
| Сценарий использования | Последствия блокировки |
|---|---|
| Генерация лидов | Неполные или устаревшие списки потенциальных клиентов, потеря продаж |
| Мониторинг цен | Пропущенные изменения цен у конкурентов, неверные ценовые решения |
| Агрегация контента | Пробелы в новостях, отзывах или исследовательских данных |
| Аналитика рынка | Слепые зоны в отслеживании конкурентов или отрасли |
| Объявления о недвижимости | Неточные или устаревшие данные об объектах, упущенные возможности |
Когда скрейпер блокируют, вы не просто теряете данные — вы тратите ресурсы, рискуете нарушить требования комплаенса и, возможно, принимаете плохие бизнес-решения на основе неполной информации. В мире, где 79% компаний используют веб-скрейпинг для генерации лидов, надежность решает все.
Как сайты обнаруживают и блокируют Python-веб-скрейперы
Сайты научились очень неплохо распознавать ботов. Вот самые распространенные методы антискрейпинга, с которыми вы столкнетесь (Medium, Bright Data):
- Черные списки IP-адресов: Слишком много запросов с одного IP? Блокировка.
- Проверка User-Agent и заголовков: Запросы без нужных заголовков или с шаблонными значениями (например, стандартный
python-requests/2.25.1) сразу выделяются. - Ограничение частоты запросов: Слишком много запросов за короткое время вызывает замедление или бан.
- CAPTCHA: Задачи в духе «докажите, что вы не робот», с которыми бот не справляется (по крайней мере легко).
- Поведенческий анализ: Сайты отслеживают роботоподобные паттерны — например, одинаковые клики через одинаковые интервалы.
- Ловушки (honeypots): Скрытые ссылки или поля, на которые клюют только боты.
- Браузерный фингерпринтинг: Сбор подробностей о браузере и устройстве для выявления автоматизации.
- Отслеживание cookie и сессий: Боты, которые некорректно работают с cookie или сессиями, попадают под подозрение.
Представьте это как досмотр в аэропорту: если вы выглядите, двигаетесь и ведете себя как все, проходите быстро. Но если вы пришли в тренче и темных очках, готовьтесь к дополнительным вопросам.
Основные приемы Python для веб-скрейпинга без блокировок
Перейдем к практике: как на самом деле избегать блокировок при скрейпинге на Python. Вот ключевые стратегии, которые должен знать каждый скрейпер:

Ротация прокси и IP-адресов
Почему это важно: Если все запросы идут с одного IP, вы — легкая цель для IP-банов. Ротация прокси позволяет распределять запросы между множеством IP, и заблокировать вас становится гораздо сложнее.
Как сделать в Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...еще прокси
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# обработка ответа
Для большей надежности можно использовать платные прокси-сервисы (например, residential или rotating proxies) (ScrapingBee).
Настройка User-Agent и пользовательских заголовков
Почему это важно: Стандартные заголовки Python кричат «бот». Имитируйте реальный браузер, задавая user-agent и другие заголовки.
Пример кода:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Меняйте user-agent, чтобы стать еще менее заметным (ZenRows).
Случайное время запросов и паттерны поведения
Почему это важно: Боты быстрые и предсказуемые, а люди — медленные и непоследовательные. Добавляйте задержки и меняйте маршрут навигации.
Совет для Python:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # Ждем 2–7 секунд
Если вы используете Selenium, можно также рандомизировать путь кликов и поведение прокрутки.
Управление cookie и сессиями
Почему это важно: Многие сайты требуют cookie или токены сессии для доступа к контенту. Боты, которые игнорируют это, получают блокировку.
Как это сделать в Python:
import requests
session = requests.Session()
response = session.get(url)
# session автоматически обработает cookie
Для более сложных сценариев используйте Selenium, чтобы захватывать и переиспользовать cookie.
Имитирование поведения человека с помощью headless-браузеров
Почему это важно: Некоторые сайты используют JavaScript, движение мыши или прокрутку как признаки реального пользователя. Headless-браузеры вроде Selenium или Playwright умеют имитировать такие действия.
Пример с Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Это помогает обходить поведенческий анализ и работать с динамическим контентом (ScrapingBee).
Продвинутые стратегии: обход CAPTCHA и honeypot в Python
CAPTCHA создана, чтобы останавливать ботов на месте. Хотя некоторые Python-библиотеки умеют решать простые CAPTCHA, большинство серьезных скрейперов используют сторонние сервисы (например, 2Captcha или Anti-Captcha), чтобы решать их за плату (Medium).
Пример интеграции:
# Псевдокод использования API 2Captcha
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Дождаться решения, затем отправить его вместе с запросом
Honeypots — это скрытые поля или ссылки, на которые реагируют только боты. Не нажимайте ничего и не отправляйте ничего, если этого не видно в обычном браузере (ZenRows).
Как проектировать надежные заголовки запросов с библиотеками Python
Помимо user-agent, можно ротировать и случайным образом менять другие заголовки (например, Referer, Accept, Origin и т. д.), чтобы еще лучше маскироваться.
В Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Другие заголовки
}
}
В Selenium: используйте профили браузера или расширения для настройки заголовков, либо внедряйте их через JavaScript.
Держите список заголовков в актуальном состоянии — для ориентира копируйте реальные запросы браузера через DevTools.
Когда традиционного Python-скрейпинга уже недостаточно: рост антибот-технологий
Вот реальность: чем популярнее скрейпинг, тем быстрее развиваются и антибот-механизмы. Крупные сайты теперь блокируют не только очевидных ботов, но и продвинутые headless-браузеры с ротацией прокси. Обнаружение с помощью ИИ, динамические пороги запросов и браузерный фингерпринтинг делают задачу незаметной работы даже для продвинутых Python-скриптов все сложнее (Medium).
Иногда, как бы умно вы ни писали код, вы все равно упираетесь в стену. И вот тогда стоит рассмотреть другой подход.
Thunderbit: альтернатива Python-скрейпингу на базе ИИ
Когда Python достигает своих пределов, на помощь приходит Thunderbit — no-code веб-скрейпер на базе ИИ, созданный для бизнес-пользователей, а не только для разработчиков. Вместо борьбы с прокси, заголовками и CAPTCHA Thunderbit с помощью ИИ читает сайт, предлагает лучшие поля для извлечения и берет на себя все — от переходов по подстраницам до экспорта данных.
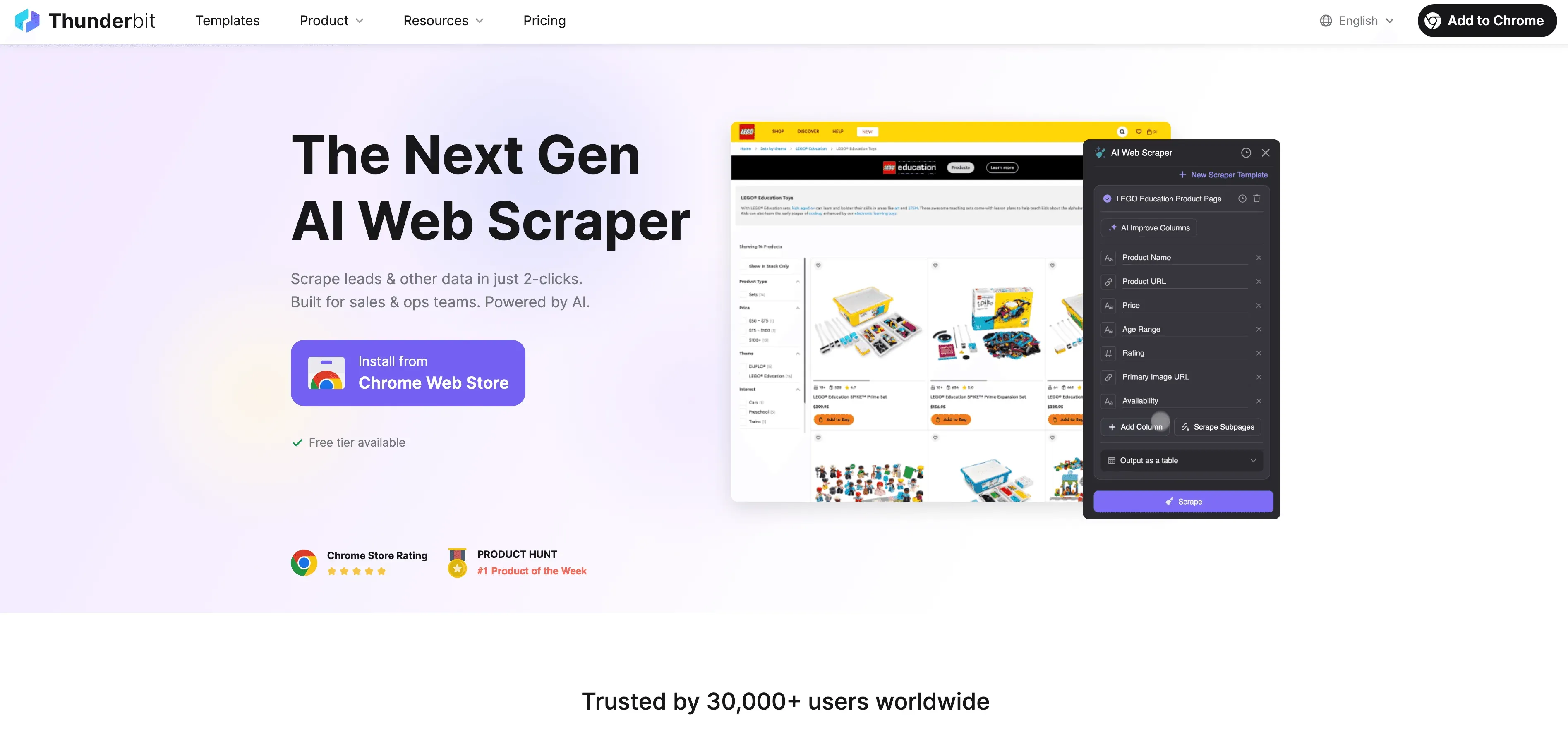
Чем Thunderbit отличается?
- Подсказка полей на базе ИИ: нажмите «AI Suggest Fields», и Thunderbit просканирует страницу, предложит столбцы и даже сгенерирует инструкции для извлечения.
- Скрейпинг подстраниц: Thunderbit может заходить на каждую подстраницу (например, страницы товаров или профили LinkedIn) и автоматически обогащать вашу таблицу.
- Облачный или браузерный скрейпинг: выбирайте самый быстрый вариант — облако для публичных сайтов, браузер для страниц с логином.
- Плановый скрейпинг: настроили один раз и забыли — Thunderbit может скрейпить по расписанию, так что ваши данные всегда свежие.
- Готовые шаблоны: для популярных сайтов (Amazon, Zillow, Shopify и т. д.) Thunderbit предлагает шаблоны в один клик — без настройки.
- Бесплатный экспорт данных: экспорт в Excel, Google Sheets, Airtable или Notion — без дополнительных платежей.
Thunderbit доверяют более 100 000 пользователей по всему миру, и вам не нужно писать ни строчки кода.
Извлекайте данные с любого сайта с помощью ИИ Get Started Free
Как Thunderbit помогает избегать блокировок и автоматизировать извлечение данных
ИИ в Thunderbit не просто имитирует поведение человека — он адаптируется к каждому сайту в реальном времени, снижая риск блокировки. Вот как это работает:
- ИИ адаптируется к изменениям макета: меньше переделок, когда сайт меняет дизайн — не нужно каждую неделю заново настраивать селекторы.
- Обработка подстраниц и пагинации: Thunderbit сам переходит по ссылкам и страницам списка так, как это сделал бы человек.
- Пакетный облачный скрейпинг: запускайте задачи из облака Thunderbit, а не с ноутбука, с размером пакетов, зависящим от тарифа (актуальные лимиты см. на странице цен).
- Меньше кода для поддержки: не вам приходится ночью искать сломанные селекторы, когда сайт меняется; ИИ просто перечитывает страницу.
Если хотите разобраться глубже, посмотрите статью Как скрейпить любой сайт с помощью ИИ.
Сравнение Python-скрейпинга и Thunderbit: что выбрать?
Сравним их бок о бок:
| Характеристика | Python-скрейпинг | Thunderbit |
|---|---|---|
| Время настройки | Среднее–высокое (скрипты, прокси и т. д.) | Низкое (2 клика, остальное делает ИИ) |
| Технические навыки | Нужен код | Код не требуется |
| Надежность | Нестабильная (легко ломается) | Высокая (ИИ адаптируется к изменениям) |
| Риск блокировок | Средний–высокий | Низкий (ИИ имитирует пользователя и адаптируется) |
| Масштабируемость | Нужен собственный код и облачная настройка | Встроенный облачный и пакетный скрейпинг |
| Поддержка | Частая (изменения сайта, блокировки) | Минимальная (ИИ автоматически подстраивается) |
| Варианты экспорта | Вручную (CSV, БД) | Прямо в Sheets, Notion, Airtable, CSV |
| Стоимость | Бесплатно, но требует много времени | Есть бесплатный тариф, для масштаба — платные планы |
Когда использовать Python:
- Вам нужен полный контроль, собственная логика или интеграция с другими Python-процессами.
- Вы скрейпите сайты с минимальной антибот-защитой.
Когда использовать Thunderbit:
- Вам важны скорость, надежность и отсутствие настройки.
- Вы скрейпите сложные или часто меняющиеся сайты.
- Вы не хотите возиться с прокси, CAPTCHA или кодом.
Попробуйте Thunderbit AI Web Scraper бесплатно
Пошаговое руководство: как настроить веб-скрейпинг на Python без блокировок
Разберем практический пример: будем собирать данные о товарах с тестового сайта, применяя лучшие практики защиты от блокировок.
1. Установите нужные библиотеки
pip install requests beautifulsoup4 fake-useragent
2. Подготовьте скрипт
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Замените на свои URL
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Извлекайте данные здесь
print(soup.title.text)
else:
print(f"Блокировка или ошибка на {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Случайная задержка
3. Добавьте ротацию прокси (необязательно)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Еще прокси
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...остальной код
4. Обрабатывайте cookie и сессии
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...остальной код
5. Советы по устранению проблем
- Если видите много ошибок 403/429, уменьшите скорость запросов или попробуйте новые прокси.
- Если натыкаетесь на CAPTCHA, рассмотрите использование Selenium или сервиса решения CAPTCHA.
- Всегда проверяйте
robots.txtсайта и условия использования.
Выводы и ключевые моменты
Веб-скрейпинг на Python — мощный инструмент, но риск блокировки постоянно растет по мере развития антибот-технологий. Лучший способ понять, как предотвратить веб-скрейпинг? Сочетать технические best practices — ротацию прокси, умные заголовки, случайные задержки, работу с сессиями и headless-браузеры — с уважением к правилам сайтов и этике.
Но иногда даже лучших приемов Python недостаточно. Вот тогда и нужны ИИ-инструменты вроде Thunderbit — no-code, созданные для работы с изменениями макета и пагинацией, которые ломают жесткие скрипты, и ориентированные на бизнес-пользователей, которым не хочется каждый вечер присматривать за задачей в Selenium.
Хотите увидеть, насколько простым может быть скрейпинг? Скачайте расширение Thunderbit для Chrome и попробуйте сами — или загляните в наш блог за новыми советами и уроками по скрейпингу.
Извлекайте данные без блокировок
Часто задаваемые вопросы
1. Почему сайты блокируют Python-веб-скрейперы?
Сайты блокируют скрейперы, чтобы защитить свои данные, предотвратить перегрузку серверов и остановить автоматических ботов, злоупотребляющих их сервисами. Python-скрипты легко распознать, если они используют стандартные заголовки, не работают с cookie или отправляют слишком много запросов слишком быстро.
2. Какие способы лучше всего помогают избежать блокировки при скрейпинге на Python?
Используйте ротацию прокси, задавайте реалистичные user-agent и заголовки, рандомизируйте время запросов, управляйте cookie/сессиями и имитируйте поведение человека с помощью инструментов вроде Selenium или Playwright.
3. Чем Thunderbit помогает избегать блокировок по сравнению с Python-скриптами?
Thunderbit использует ИИ, чтобы подстраиваться под макет сайта, имитировать поведение человека и автоматически обрабатывать подстраницы и пагинацию. Это снижает риск блокировок за счет более естественного поведения и обновления подхода в реальном времени — без кода и прокси.
4. Когда использовать Python-скрейпинг, а когда — ИИ-инструмент вроде Thunderbit?
Используйте Python, если вам нужна собственная логика, интеграция с другим Python-кодом или вы скрейпите простые сайты. Используйте Thunderbit для быстрого, надежного и масштабируемого скрейпинга — особенно если сайты сложные, часто меняются или агрессивно блокируют скрипты.
5. Законен ли веб-скрейпинг?
Веб-скрейпинг законен для общедоступных данных, но вы должны соблюдать условия использования каждого сайта, правила конфиденциальности и применимые законы. Никогда не скрейпьте чувствительные или частные данные и всегда делайте это этично и ответственно.
Готовы скрейпить умнее, а не тяжелее? Попробуйте Thunderbit и забудьте о блокировках.
Узнать больше:
- Скрапинг Google News на Python: пошаговое руководство
- Создайте инструмент отслеживания цен Best Buy на Python
- 14 способов делать веб-скрейпинг без блокировок
- 10 лучших советов, как не попасть под блокировку при веб-скрейпинге
Попробуйте AI Web Scraper Get Started Free




