

Есть в том, чтобы открыть терминал, ввести одну команду и увидеть, как сырые веб-данные потоком льются в окно, что-то почти вечное — будто вы только что распечатали Матрицу. Для разработчиков и технически продвинутых пользователей cURL — это та самая волшебная палочка: неприметный инструмент командной строки, который тихо работает на миллиардах устройств — от облачных серверов до вашего умного холодильника. И даже в 2026 году, несмотря на все яркие no-code и AI-инструменты для скрейпинга, веб-скрейпинг с cURL по-прежнему остается рабочим выбором для тех, кому важны скорость, контроль и возможность автоматизации через скрипты.
 Я много лет создаю инструменты автоматизации и помогаю командам работать с веб-данными, и cURL до сих пор выручает меня, когда нужно быстро забрать страницу, отладить API или прототипировать рабочий процесс парсинга. В этом руководстве я покажу вам, как выполнять веб-скрейпинг cURL: мы разберем и базовые приемы, и профессиональные трюки — с реальными примерами команд, практическими советами и честным взглядом на то, где cURL блистает, а где упирается в потолок. А если вы больше из числа бизнес-пользователей и не хотите связываться с командной строкой, я покажу, как Thunderbit — наш AI Web Scraper — поможет вам пройти путь от «мне нужны эти данные» до «вот моя таблица» всего за два клика — без единой строки кода.
Я много лет создаю инструменты автоматизации и помогаю командам работать с веб-данными, и cURL до сих пор выручает меня, когда нужно быстро забрать страницу, отладить API или прототипировать рабочий процесс парсинга. В этом руководстве я покажу вам, как выполнять веб-скрейпинг cURL: мы разберем и базовые приемы, и профессиональные трюки — с реальными примерами команд, практическими советами и честным взглядом на то, где cURL блистает, а где упирается в потолок. А если вы больше из числа бизнес-пользователей и не хотите связываться с командной строкой, я покажу, как Thunderbit — наш AI Web Scraper — поможет вам пройти путь от «мне нужны эти данные» до «вот моя таблица» всего за два клика — без единой строки кода.
Давайте разберемся, почему cURL по-прежнему актуален для веб-скрейпинга в 2026 году, как использовать его эффективно и когда пора взять инструмент помощнее.
Что такое cURL? Основа веб-скрейпинга с cURL
По своей сути cURL — это инструмент командной строки и библиотека для передачи данных по URL. Он существует уже почти 30 лет (да, правда) и вездесущ: встроен в операционные системы, используется в скриптах и незаметно обрабатывает передачу данных более чем в двадцати миллиардах установок. Если вы когда-либо запускали быструю команду, чтобы получить веб-страницу, протестировать API или скачать файл, велика вероятность, что вы уже использовали cURL.
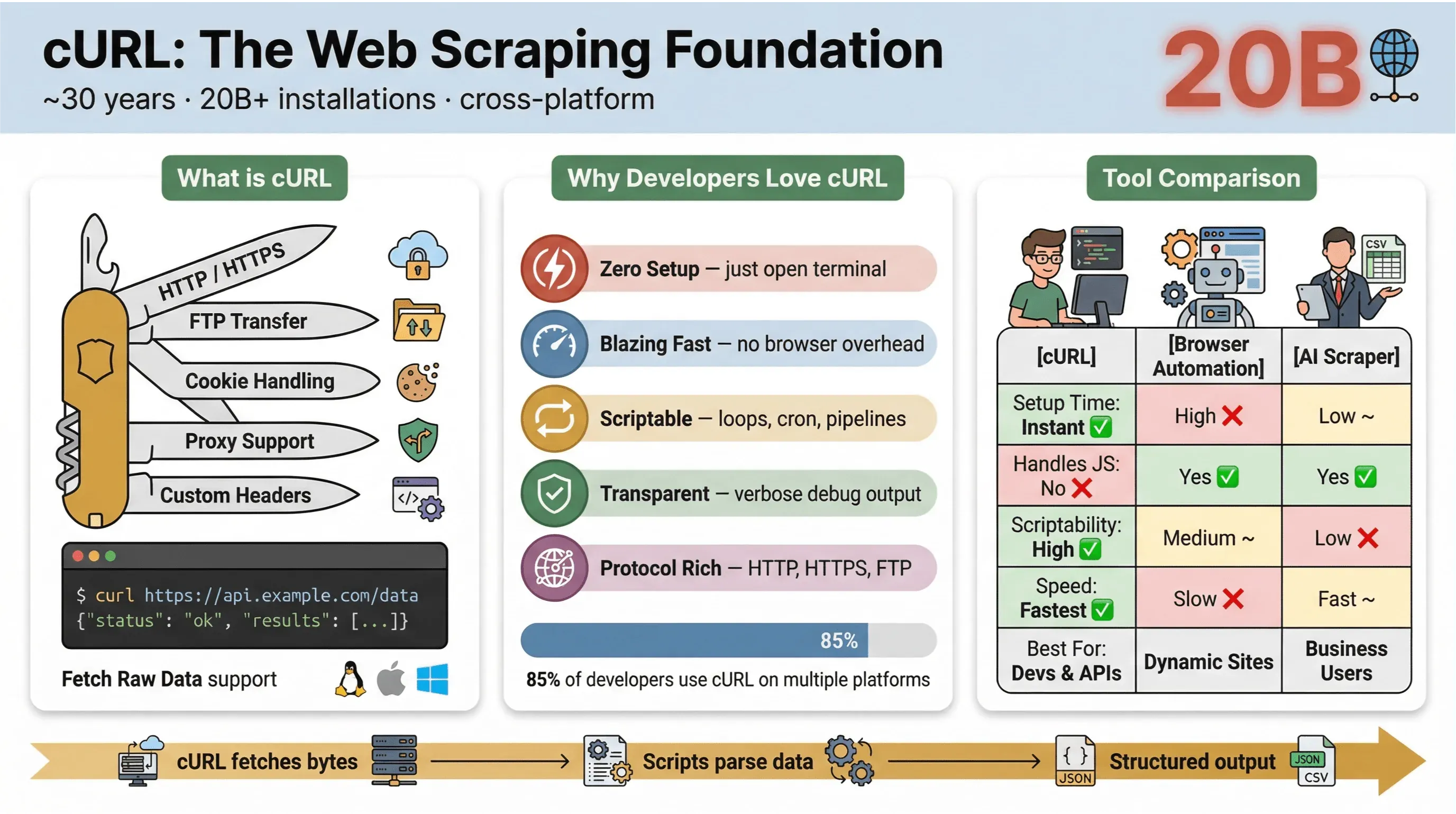 Вот почему cURL так популярен для веб-скрейпинга:
Вот почему cURL так популярен для веб-скрейпинга:
- Легкий и кроссплатформенный: работает в Linux, macOS, Windows и даже на встроенных устройствах.
- Поддержка протоколов: умеет работать с HTTP, HTTPS, FTP и многими другими.
- Удобен для скриптов: отлично подходит для автоматизации, cron-задач и вспомогательных скриптов.
- Не требует взаимодействия с пользователем: создан для неинтерактивной работы — идеально для пакетных задач и конвейеров.
Но давайте четко обозначим: основная задача cURL — получать сырые данные: HTML, JSON, изображения — что угодно. Он не парсит, не рендерит и не структурирует эти данные за вас. Думайте о cURL как о «первой миле» веб-скрейпинга: он приносит вам байты, а вот чтобы превратить их в структурированную информацию, понадобятся другие инструменты — например, Python-скрипты, grep/sed/awk или AI web scraper.
Если хотите почитать официальную документацию, загляните в руководство cURL по HTTP scripting.
Зачем использовать cURL для веб-скрейпинга? (учебник по веб-скрейпингу cURL)
Почему же разработчики и технические пользователи снова и снова возвращаются к cURL для веб-скрейпинга, даже когда вокруг столько новых инструментов? Вот чем cURL выделяется:
- Минимум подготовки: никаких установок и зависимостей — просто откройте терминал и работайте.
- Скорость: данные можно получить мгновенно, не дожидаясь загрузки браузера.
- Удобство для скриптов: легко проходить по списку URL, автоматизировать запросы и выстраивать цепочки команд.
- Поддержка протоколов и функций: cookies, прокси, редиректы, пользовательские заголовки и многое другое.
- Прозрачность: вы точно видите, что происходит, благодаря подробному или отладочному выводу.
В опросе пользователей cURL 2025 года 85,7% респондентов сообщили, что используют cURL как инструмент командной строки, а 96,2% — что используют его в Linux. Это по-прежнему главная платформа для cURL с большим отрывом.
--- Он по-прежнему остается швейцарским ножом для HTTP-запросов, быстрых выгрузок данных и отладки.
Вот краткое сравнение cURL с другими способами скрейпинга:
| Функция | cURL | Автоматизация браузера (например, Selenium) | AI Web Scraper (например, Thunderbit) |
|---|---|---|---|
| Время настройки | Мгновенно | Высокое | Низкое |
| Удобство для скриптов | Высокое | Среднее | Низкое (код не нужен) |
| Работа с JavaScript | Нет | Да | Да (Thunderbit: через браузер) |
| Поддержка cookies/сессий | Вручную | Автоматически | Автоматически |
| Структурирование данных | Вручную (сначала парсинг) | Вручную (сначала парсинг) | На основе AI/шаблонов |
| Лучший вариант для | Разработчиков, быстрых выгрузок | Сложных, динамических сайтов | Бизнес-пользователей, структурированного экспорта |
Если коротко: cURL незаменим для быстрых, автоматизируемых выгрузок данных — особенно со статических страниц, API или когда нужно автоматизировать простые сценарии. Но как только требуется парсить сложный HTML, обрабатывать JavaScript или экспортировать структурированные данные, вам понадобится более специализированный инструмент.
Начнем: базовые примеры команд cURL для веб-скрейпинга
Перейдем к практике. Вот как использовать cURL для базовых задач веб-скрейпинга — шаг за шагом.
Получение сырого HTML с помощью cURL
Самый простой сценарий: забрать HTML веб-страницы.
curl https://books.toscrape.com/
Эта команда получает главную страницу Books to Scrape — публичного демонстрационного сайта для веб-скрейпинга. В терминале вы увидите сырой HTML-вывод: ищите теги вроде <title> или фрагменты вроде “In stock”.
Сохранение вывода в файл
Хотите сохранить HTML для последующего парсинга? Используйте флаг -o:
curl -o page.html https://books.toscrape.com/
Теперь у вас будет файл page.html с полным HTML-контентом. Это отлично подходит для дальнейшего анализа или парсинга другими инструментами.
Отправка POST-запросов с помощью cURL
Нужно отправить форму или обратиться к API? Используйте флаг -d для POST-запросов. Вот пример с httpbin — сайтом, созданным для HTTP-тестирования:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
В ответ вы получите JSON, который отражает отправленные данные — удобно для тестирования и прототипирования.
Просмотр заголовков и отладка
Иногда нужно посмотреть заголовки ответа или отладить запрос:
-
Только заголовки (HEAD-запрос):
curl -I https://books.toscrape.com/ -
Заголовки вместе с телом ответа:
curl -i https://httpbin.org/get -
Подробный/отладочный вывод:
curl -v https://books.toscrape.com/
Эти флаги помогают понять, что происходит «под капотом», — а это критически важно для отладки.
Вот краткая справочная таблица по этим командам:
| Задача | Пример команды | Примечания |
|---|---|---|
| Получить HTML | curl URL | Выводит HTML в терминал |
| Сохранить в файл | curl -o file.html URL | Записывает вывод в файл |
| Просмотреть заголовки | curl -I URL или curl -i URL | -I — только HEAD, -i — заголовки вместе с телом |
| Отправить form-data | curl -d "a=1&b=2" URL | Отправляет данные в формате form-urlencoded |
| Отладить запрос/ответ | curl -v URL | Показывает подробную информацию о запросе и ответе |
Больше примеров вы найдете в официальной документации cURL по scripting.
Уровень выше: продвинутый веб-скрейпинг с cURL (web-scraping-with-curl)
Когда базовые приемы уже освоены, cURL открывает целый набор продвинутых возможностей для более сложных задач скрейпинга.
Работа с cookies и сессиями
Многие сайты используют cookies, чтобы сохранять сессии входа или отслеживать пользователей. С помощью cURL можно сохранять cookies и использовать их повторно в последующих запросах:
# Сохраняем cookies после входа
curl -c cookies.txt https://example.com/login
# Используем cookies в следующих запросах
curl -b cookies.txt https://example.com/account
Это позволяет имитировать браузерные сессии и получать доступ к страницам за логином — если, конечно, там нет JavaScript-проверки.
Подмена User-Agent и пользовательских заголовков
Некоторые сайты отдают разный контент в зависимости от User-Agent или заголовков. По умолчанию cURL представляется как “curl/VERSION”, и это может приводить к блокировке или выдаче другого контента. Чтобы имитировать браузер:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Можно также задать пользовательские заголовки, например предпочтительный язык:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Так вы получите тот же контент, который увидел бы обычный браузер.
Использование прокси для веб-скрейпинга
Нужно направить запросы через прокси — например, для проверки геолокации или чтобы избежать IP-блокировок? Используйте флаг -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Только обязательно используйте прокси ответственно и в рамках условий использования сайта.
Автоматизация скрейпинга нескольких страниц
Хотите собрать данные с нескольких страниц, например со страниц каталога с пагинацией? Используйте простой shell-цикл:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Так вы заберете страницы с 2 по 5 каталога Books to Scrape и сохраните каждую в отдельный файл. (Первая страница — это главная.)
Ограничения веб-скрейпинга с cURL: что нужно знать
Как бы я ни любил cURL, это не серебряная пуля. Вот где он уступает:
- Нет выполнения JavaScript: cURL не справится со страницами, которым нужен JavaScript для рендеринга контента или обхода антибот-проверок (developers.cloudflare.com).
- Нужен ручной парсинг: вы получаете сырой HTML или JSON, но разбирать их придется самостоятельно — часто с помощью дополнительных скриптов или инструментов.
- Ограниченная работа с сессиями: сложные логины, токены или многошаговые формы могут быстро превратиться в головную боль.
- Нет встроенного структурирования данных: cURL не превращает веб-страницы в строки, таблицы или таблицы Excel.
- Уязвимость к антибот-детекции: многие сайты используют продвинутую защиту от ботов — JavaScript, fingerprinting, CAPTCHA, — которую cURL просто не обходит (datadome.co).
Вот краткая сравнительная таблица:
| Ограничение | Только cURL | Современные инструменты для скрейпинга (например, Thunderbit) |
|---|---|---|
| Поддержка JavaScript | Нет | Да |
| Структурирование данных | Вручную | Автоматически (AI/шаблон) |
| Работа сессий | Вручную | Автоматически |
| Обход антибот-защиты | Ограниченно | Продвинуто (через браузер/AI) |
| Простота использования | Для технических пользователей | Для нетехнических пользователей |
Для статических страниц и API cURL великолепен. Но для всего более динамичного или защищенного вам придется перейти на следующий уровень инструментов.
Thunderbit против cURL: лучший подход к веб-скрейпингу для нетехнических пользователей
Теперь поговорим о Thunderbit — нашем AI-powered web scraper в виде расширения для Chrome. Если вы менеджер по продажам, маркетолог или специалист по операциям и хотите просто перенести данные с сайта в Excel, Google Sheets или Notion — без работы в командной строке, — Thunderbit создан именно для вас.
Вот как Thunderbit выглядит на фоне cURL:
| Функция | cURL | Thunderbit |
|---|---|---|
| Интерфейс пользователя | Командная строка | Клики мышью (расширение Chrome) |
| AI-подсказка полей | Нет | Да (AI читает страницу и предлагает столбцы) |
| Работа с пагинацией/подстраницами | Вручную через скрипт | Автоматически (AI определяет и собирает данные) |
| Экспорт данных | Вручную (парсинг + сохранение) | Напрямую в Excel, Google Sheets, Notion, Airtable |
| JavaScript/защищенные страницы | Нет | Да (скрейпинг через браузер) |
| No-code не требуется | Нет (нужны скрипты) | Да (подойдет любому) |
| Бесплатный тариф | Всегда бесплатно | Бесплатно до 6 страниц (10 с пробным бустом) |
С Thunderbit вы просто открываете расширение, нажимаете «AI Suggest Fields», а AI сам определяет, какие данные нужно извлечь. Можно собирать таблицы, списки, карточки товаров и даже автоматически заходить на подстраницы. Затем вы экспортируете данные прямо в любимые бизнес-инструменты — без парсинга и без головной боли.
Thunderbit доверяют более 100 000 пользователей по всему миру, и особенно он популярен среди команд продаж, ecommerce и недвижимости, которым нужны структурированные данные быстро.
Попробуйте расширение Thunderbit для Chrome для веб-скрейпинга
Хотите протестировать? Скачайте расширение Chrome здесь.
Совмещение cURL и Thunderbit: гибкие стратегии веб-скрейпинга
Если вы технический пользователь, вовсе не обязательно выбирать только один инструмент. Более того, многие команды используют cURL и Thunderbit вместе, чтобы получить максимум гибкости:
- Прототипирование с cURL: с его помощью можно быстро проверить endpoint’ы, посмотреть заголовки и понять, как сайт отвечает.
- Масштабирование с Thunderbit: когда нужны структурированные данные, скрейпинг нескольких страниц или повторяемый рабочий процесс, переходите на Thunderbit для извлечения данных в пару кликов и прямого экспорта.
Вот пример рабочего процесса для исследования рынка:
- Используйте cURL, чтобы получить несколько страниц и изучить структуру HTML.
- Определите нужные поля данных, например названия товаров, цены, отзывы.
- Откройте Thunderbit, нажмите «AI Suggest Fields» и дайте AI настроить скрейпер.
- Соберите все страницы, включая подстраницы и списки с пагинацией, и экспортируйте в Google Sheets.
- Анализируйте, делитесь и используйте данные — ручной парсинг не нужен.
Вот краткая таблица принятия решения:
| Сценарий | Использовать cURL | Использовать Thunderbit | Использовать оба |
|---|---|---|---|
| Быстро получить API или статическую страницу | ✅ | ||
| Нужны структурированные данные в таблице | ✅ | ||
| Отладка заголовков/cookies | ✅ | ||
| Скрейпинг динамических/JS-страниц | ✅ | ||
| Создание повторяемого no-code процесса | ✅ | ||
| Сначала прототип, потом масштабирование | ✅ | ✅ | Гибридный процесс |
Распространенные проблемы и ошибки при веб-скрейпинге с cURL
Прежде чем увлечься cURL, давайте поговорим о реальных трудностях, с которыми вы столкнетесь:
- Антибот-системы: многие сайты теперь используют продвинутую защиту — JavaScript-челленджи, CAPTCHA, fingerprinting, — которую cURL не обходит (developers.cloudflare.com).
- Проблемы с качеством данных: изменения HTML, отсутствующие поля или непоследовательная верстка могут ломать скрипты.
- Расходы на поддержку: каждый раз, когда сайт меняется, придется обновлять логику парсинга.
- Юридические и комплаенс-риски: всегда проверяйте условия использования сайта, robots.txt и применимые законы перед скрейпингом. То, что данные публичны, не означает, что их можно свободно использовать (calawyers.org, polsinelli.com).
- Ограничения масштабирования: cURL отлично подходит для небольших задач, но для крупномасштабного скрейпинга понадобятся прокси, контроль лимитов запросов и обработка ошибок.
Советы по отладке и соблюдению правил:
- Всегда начинайте с сайтов, где скрейпинг разрешен, или с демо-сайтов, например Books to Scrape.
- Соблюдайте rate limits — не «бомбите» endpoint’ы.
- Избегайте сбора персональных данных, если у вас нет законного основания.
- Если упираетесь в JavaScript или CAPTCHA, подумайте о переходе на браузерный инструмент вроде Thunderbit.
Пошаговое резюме: как парсить сайты с помощью cURL
Вот ваш краткий чек-лист по веб-скрейпингу с cURL:
- Определите целевой URL: начните со статической страницы или API endpoint’а.
- Получите страницу:
curl URL - Сохраните вывод в файл:
curl -o file.html URL - Проверьте заголовки/отладку:
curl -I URL,curl -v URL - Отправьте POST-данные:
curl -d "a=1&b=2" URL - Работа с cookies/сессиями:
curl -c cookies.txt ...,curl -b cookies.txt ... - Задайте пользовательские заголовки/User-Agent:
curl -A "..." -H "..." URL - Следуйте за редиректами:
curl -L URL - Используйте прокси, если нужно:
curl -x proxy:port URL - Автоматизируйте скрейпинг нескольких страниц: используйте shell-циклы или скрипты.
- Парсите и структурируйте данные: при необходимости подключайте дополнительные инструменты/скрипты.
- Переходите на Thunderbit для структурированного no-code-скрейпинга или динамических страниц.
Заключение и ключевые выводы: как выбрать правильный инструмент для веб-скрейпинга
Собирайте данные с любого сайта с помощью AI Get Started Free
Веб-скрейпинг с cURL в 2026 году по-прежнему остается мощным навыком для технических пользователей — особенно для быстрых выгрузок данных, прототипирования и автоматизации. Скорость, удобство для скриптов и повсеместность cURL делают его базовым инструментом в арсенале любого разработчика. Но по мере того как веб становится более динамичным и защищенным, а бизнес-пользователям нужны структурированные данные без кода, такие инструменты, как Thunderbit, заново определяют возможное.
Ключевые выводы:
- Используйте cURL для статических страниц, API и быстрого прототипирования — особенно когда нужен полный контроль.
- Переходите на Thunderbit (или похожие AI web scraper), когда нужны структурированные данные, работа с динамическими/JS-страницами или no-code процесс, удобный для бизнеса.
- Комбинируйте оба инструмента для максимальной гибкости: прототипируйте с cURL, масштабируйте и структурируйте с Thunderbit.
- Всегда скрейпьте ответственно — соблюдайте условия сайта, лимиты запросов и правовые границы.
Хотите увидеть, насколько простым может быть веб-скрейпинг? Попробуйте бесплатное расширение Thunderbit для Chrome и оцените AI-извлечение данных на практике. А если хотите углубиться, загляните в блог Thunderbit за новыми руководствами, советами и отраслевыми инсайтами. Вам также могут понравиться:
- Как собрать данные с любого сайта с помощью AI
- Как выгрузить данные сайта в Excel с помощью AI
- Что такое data scraping и как делать это в 2025 году
Удачного скрейпинга — пусть ваши данные всегда будут чистыми, структурированными и доступными в один командный вызов или один клик.
Изучите тарифы Thunderbit для масштабируемого веб-скрейпинга
FAQ
1. Может ли cURL работать со страницами, которые рендерятся через JavaScript?
Нет, cURL не умеет выполнять JavaScript. Он получает только сырой HTML, который отдает сервер. Если странице нужен JavaScript для рендеринга контента или обхода антибот-проверок, cURL не сможет достать данные. В таких случаях используйте браузерные инструменты вроде Thunderbit.
2. Как сохранить вывод cURL сразу в файл?
Используйте флаг -o: curl -o filename.html URL. Эта команда записывает тело ответа в файл вместо того, чтобы показывать его в терминале.
3. В чем разница между cURL и Thunderbit для веб-скрейпинга?
cURL — это инструмент командной строки для получения сырых веб-данных, отлично подходит для технических пользователей и автоматизации. Thunderbit — это расширение Chrome с AI, созданное для бизнес-пользователей, которым нужно извлекать структурированные данные с любого сайта, работать с динамическими страницами и экспортировать данные напрямую в Excel или Google Sheets — без кода.
4. Законно ли скрейпить сайты с помощью cURL?
Сбор публичных данных в США в целом считается законным после недавних судебных решений, но всегда проверяйте условия использования сайта, robots.txt и применимые законы. Не собирайте персональные или защищенные данные без разрешения, а также соблюдайте лимиты запросов и этические нормы (calawyers.org, polsinelli.com).
5. Когда стоит перейти с cURL на более продвинутый инструмент вроде Thunderbit?
Если нужно скрейпить динамические/JS-страницы, получить структурированные данные в таблице или вы предпочитаете no-code-рабочий процесс, Thunderbit — лучший выбор. Используйте cURL для быстрых технических задач; Thunderbit — для повторяемого извлечения данных, удобного для бизнеса.
Больше советов и руководств по веб-скрейпингу ищите в блоге Thunderbit или на нашем YouTube-канале.
Попробуйте AI Web Scraper Thunderbit Get Started Free




