

«У вас могут быть данные без информации, но не может быть информации без данных.» — Дэниел Киз Моран*
По последним оценкам, в интернете уже больше 1,5 миллиарда сайтов, а каждый день публикуется около 2 миллионов новых постов. Этот океан данных хранит ценные инсайты для принятия решений, но есть нюанс: примерно 80% из них — неструктурированные данные, а значит, для полезного использования их нужно дополнительно обрабатывать. Именно здесь и нужны инструменты для веб-скрейпинга — они становятся незаменимыми для всех, кто хочет работать с онлайн-данными.
Если вы только начинаете разбираться в веб-скрейпинге, такие термины, как веб-компоненты и HTML, могут звучать немного пугающе. Но в эпоху ИИ эти задачи стало гораздо проще решать. Современные инструменты для скрейпинга на базе ИИ помогают начать работу без глубоких технических знаний. С ними можно быстро собирать и обрабатывать данные — навыки программирования не нужны.
Лучшие инструменты и программы для веб-скрейпинга
- Thunderbit — простой в использовании AI веб-скрейпер с отличными результатами
- Browse AI — для мониторинга в реальном времени и массового извлечения данных
- Bardeen AI — для no-code автоматизации с широкими интеграциями с приложениями
- Web Scraper — для более профессионального визуального веб-скрейпинга
- Octoparse — мощный no-code скрейпинг с обходом IP-блокировок и защиты от ботов
- Diffbot — продвинутый API для извлечения данных с помощью ИИ и knowledge graph
Попробуйте использовать ИИ для веб-скрейпинга
Попробуйте! Можно нажимать, изучать и запускать процесс, пока вы смотрите.
Как работает веб-скрейпинг?
Веб-скрейпинг — это просто извлечение данных с сайтов. Вы задаёте инструменту набор инструкций, а он идёт и вытаскивает текст, изображения или любые нужные вам данные в таблицу со страницы. Это удобно для самых разных задач: от отслеживания цен в интернет-магазинах до сбора исследовательских данных и даже просто для создания хорошей таблицы в Excel или Google Sheets.
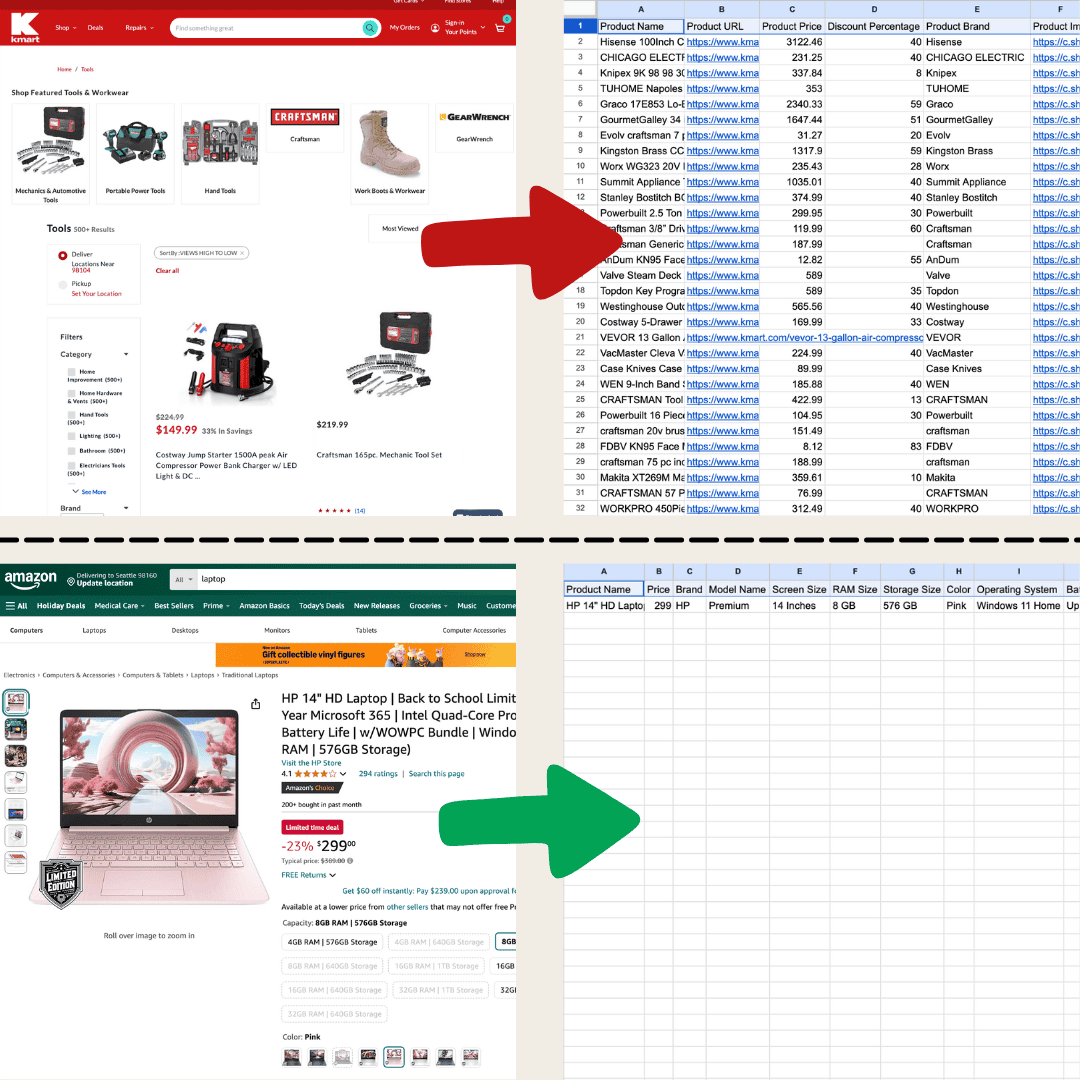 Я сделал это в Thunderbit с помощью AI Web Scraper.
Я сделал это в Thunderbit с помощью AI Web Scraper.
Есть несколько способов сделать это. На самом простом уровне можно просто копировать и вставлять всё вручную, но при большом объёме данных это отнимает слишком много времени. Поэтому большинство людей используют один из трёх подходов: традиционные веб-скрейперы, AI веб-скрейперы или собственный код.
Традиционные веб-скрейперы работают по заранее заданным правилам о том, какие данные нужно собирать, исходя из структуры страницы. Например, можно настроить их на извлечение названий товаров или цен из определённых HTML-тегов. Лучше всего они подходят для сайтов, которые редко меняются, потому что при любых изменениях макета вам придётся возвращаться и настраивать скрейпер заново.
 Чтобы освоить традиционный скрейпер, потребуется довольно много времени, и, скорее всего, вам придётся сделать десятки кликов, чтобы завершить настройку.
Чтобы освоить традиционный скрейпер, потребуется довольно много времени, и, скорее всего, вам придётся сделать десятки кликов, чтобы завершить настройку.
Собирайте данные с любого сайта с помощью ИИ Get Started Free
AI веб-скрейперы по сути работают так: ChatGPT читает весь сайт, а затем извлекает контент в зависимости от ваших задач. Он может одновременно выполнять извлечение данных, перевод и краткое резюмирование. Такие инструменты используют обработку естественного языка, чтобы анализировать и понимать структуру сайта, а значит, легче справляются с изменениями на страницах. Например, если сайт немного перестроит разделы, AI веб-скрейпер сможет адаптироваться без необходимости что-то переписывать. Поэтому они отлично подходят для сайтов, которые часто меняются, или для более сложных структур.
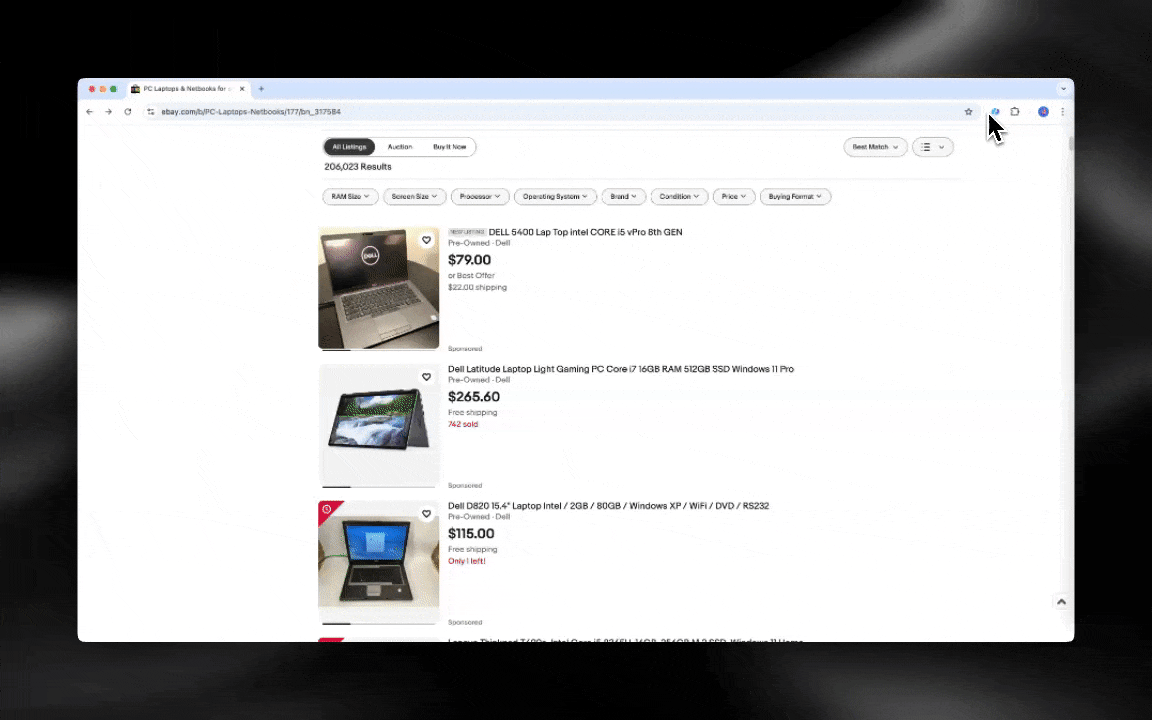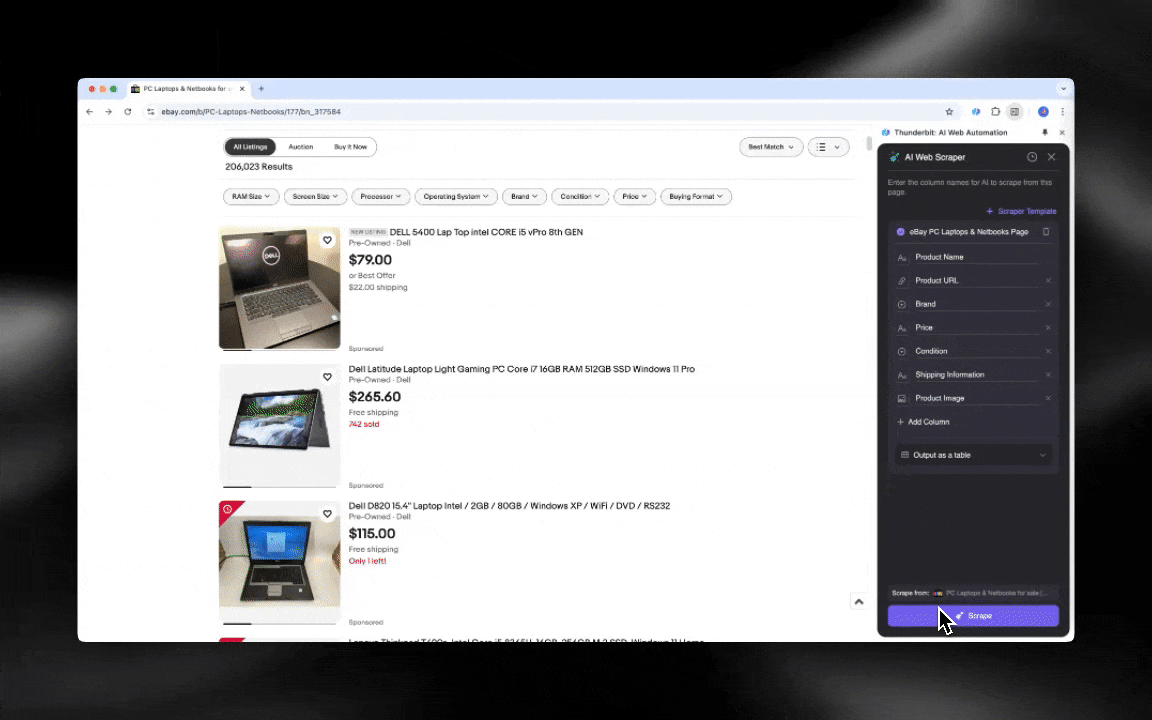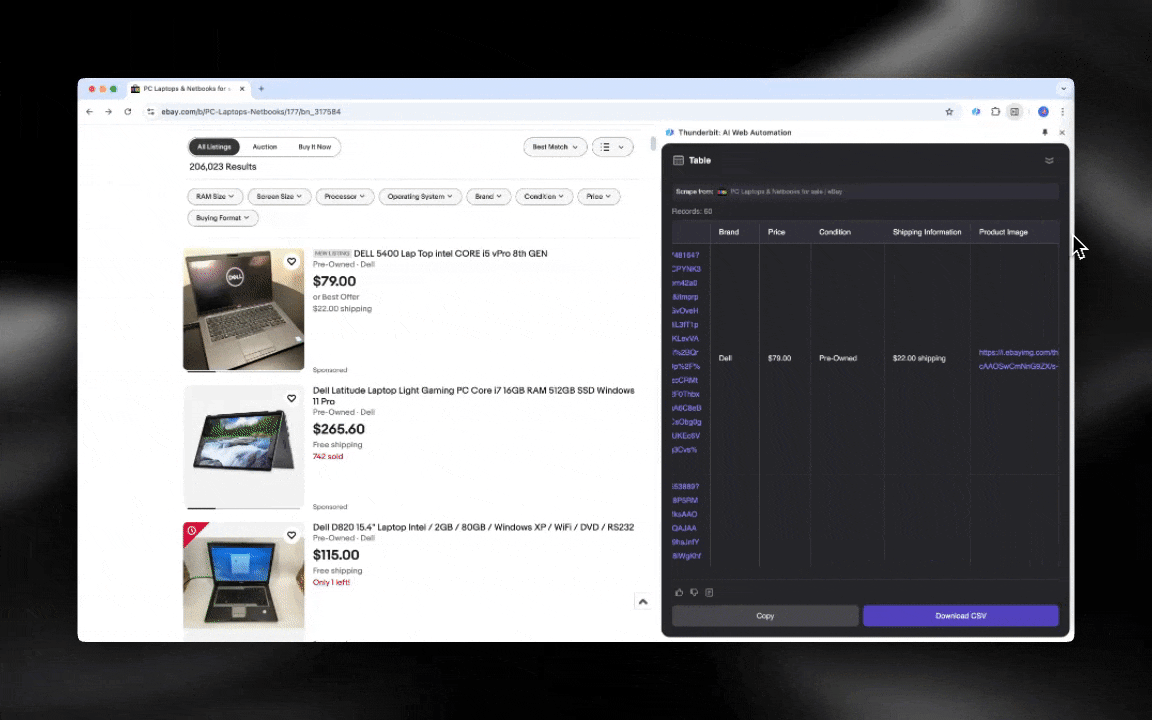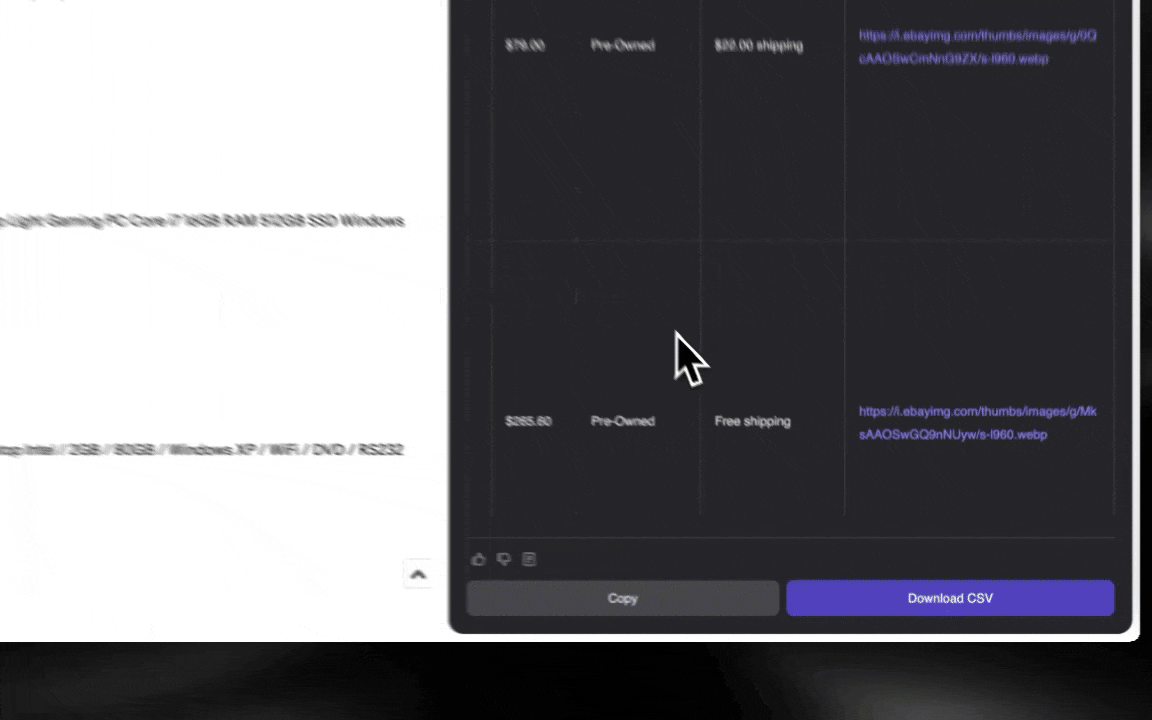 AI веб-скрейпер легко освоить, и он выдаёт подробные данные всего за несколько кликов!
AI веб-скрейпер легко освоить, и он выдаёт подробные данные всего за несколько кликов!
Какой выбрать? Это зависит от задачи. Если вы уверенно работаете с кодом или вам нужно собрать большие объёмы данных с популярного сайта, традиционные скрейперы могут быть очень эффективны. Но если вы только начинаете заниматься веб-скрейпингом или хотите инструмент, который спокойно переживает обновления сайта, чаще лучше выбрать AI веб-скрейпер. Подробные сценарии смотрите в таблице ниже!
| Сценарий | Лучший выбор |
|---|---|
| Лёгкий скрейпинг страниц, таких как каталоги, сайты магазинов или любые страницы со списками | AI Web Scraper |
| На странице меньше 200 строк данных, а создание скрейпера в традиционном веб-скрейпере занимает слишком много времени | AI Web Scraper |
| Для данных, которые нужно собрать, требуется определённый формат для загрузки в другой сервис. Например: извлечь контактную информацию для загрузки в HubSpot. | AI Web Scraper |
| Массовая работа с широко используемыми сайтами, например с десятками тысяч страниц товаров Amazon или объявлениями Zillow о недвижимости. | Traditional Web Scraper |
Лучшие инструменты и программы для веб-скрейпинга: краткий обзор
| Инструмент | Цена | Ключевые функции | Плюсы | Минусы |
|---|---|---|---|---|
| Thunderbit | От $9 в месяц, есть бесплатный тариф | AI веб-скрейпер, автоматически определяет и форматирует данные, поддерживает несколько форматов, экспорт в один клик, удобный интерфейс. | Без кода, поддержка ИИ, интеграции с Google Sheets и другими приложениями | Масштабный скрейпинг может быть медленным, продвинутые функции могут стоить дороже |
| Browse AI | От $48,75 в месяц, есть бесплатный тариф | No-code интерфейс, мониторинг в реальном времени, массовое извлечение данных, интеграция рабочих процессов. | Удобен в использовании, интегрируется с Google Sheets и Zapier | Сложные страницы требуют дополнительной настройки, массовый скрейпинг может вызывать тайм-ауты |
| Bardeen AI | От $60 в месяц, есть бесплатный тариф | No-code автоматизация, интеграции с более чем 130 приложениями, MagicBox превращает задачи в рабочие процессы. | Широкие интеграции, подходит для масштабирования бизнеса | Новым пользователям нужно время, чтобы освоиться, настройка занимает много времени |
| Web Scraper | Бесплатно для локального использования, $50 в месяц за облако | Визуальное создание задач, поддержка динамических сайтов (AJAX/JavaScript), облачный скрейпинг. | Хорошо работает с динамическими сайтами | Для лучшей настройки нужны технические знания |
| Octoparse | От $119 в месяц, есть бесплатный тариф | No-code скрейпинг, автоопределение элементов страницы, облачный скрейпинг с задачами по расписанию, библиотека шаблонов для популярных сайтов. | Мощные функции для динамических сайтов, умеет обходить ограничения | Для сложных сайтов требуется обучение |
| Diffbot | От $299 в месяц | API для извлечения данных, API без правил, NLP для неструктурированного текста, обширный knowledge graph. | Сильное ИИ-извлечение, широкие возможности API-интеграции, масштабный скрейпинг | Кривая обучения для нетехнических пользователей, требуется время на настройку |
Лучший веб-скрейпер в эпоху ИИ
Thunderbit
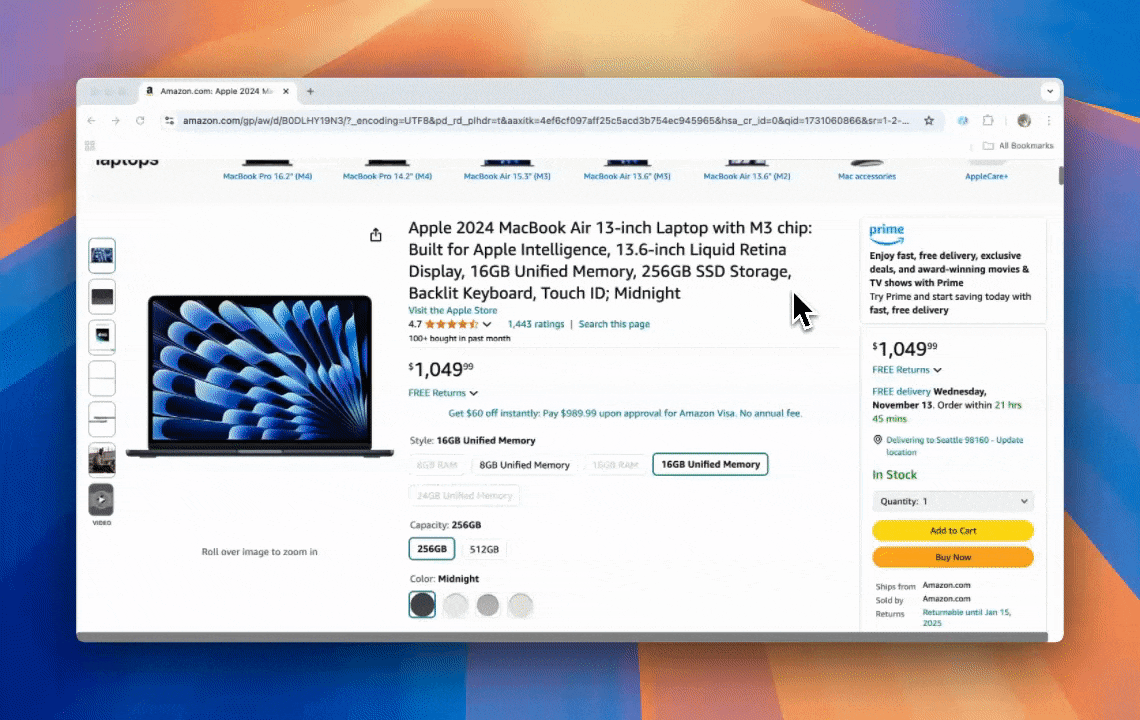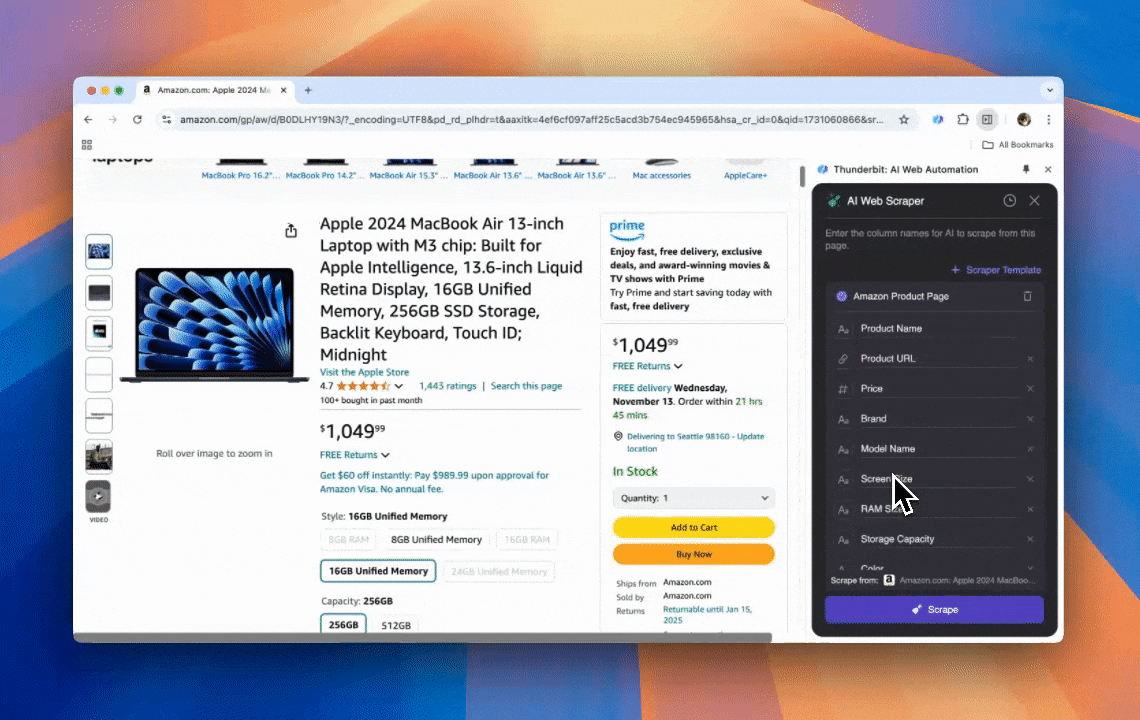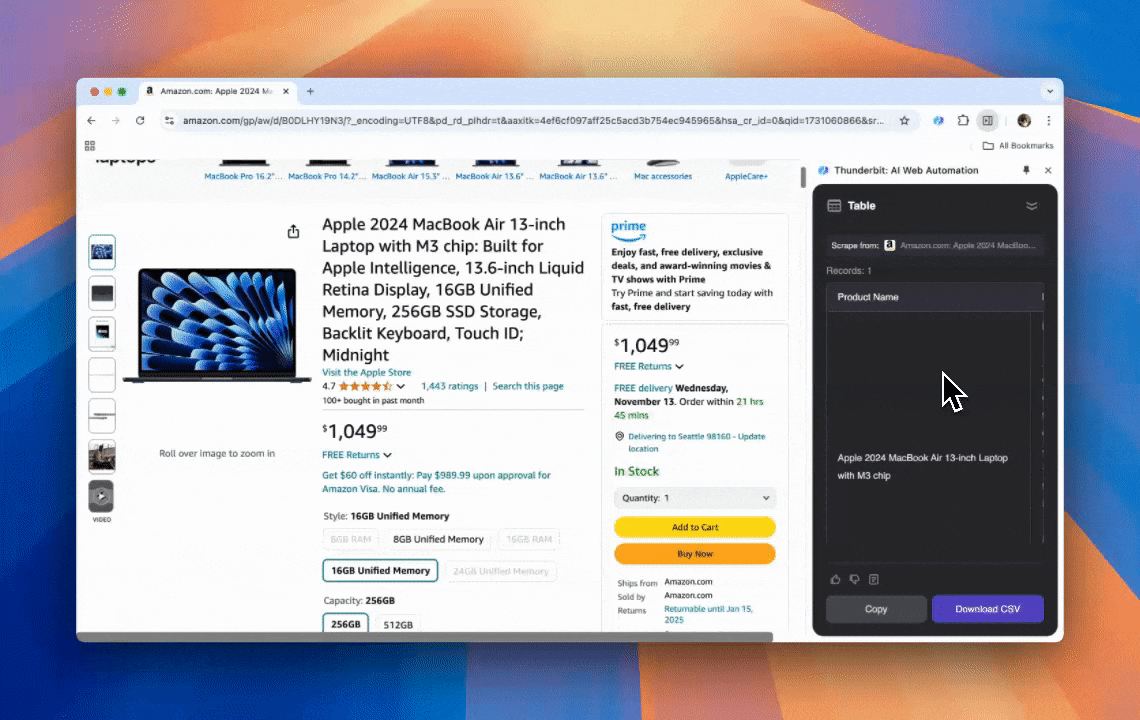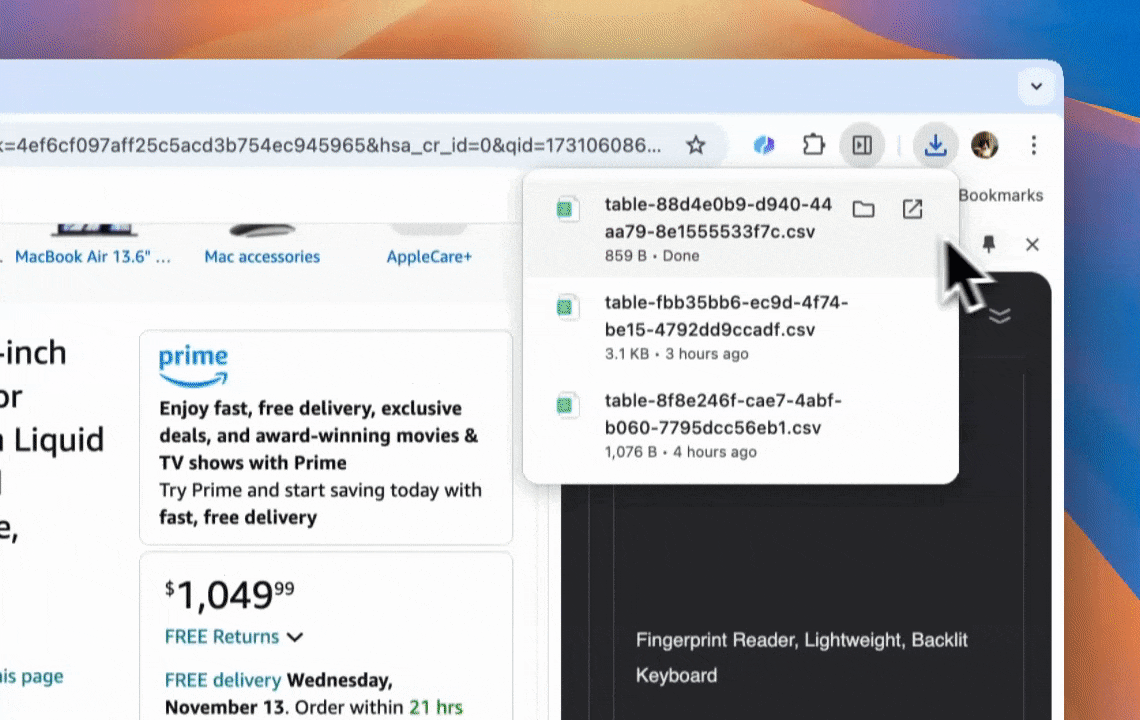
Thunderbit — это мощный и удобный AI-инструмент для веб-автоматизации, который позволяет пользователям без навыков программирования легко извлекать и структурировать данные. Благодаря расширению Chrome, AI Web Scraper от Thunderbit упрощает сбор данных: пользователи могут быстро получать веб-данные без ручного взаимодействия с элементами страницы и без настройки отдельных скрейперов под разные макеты страниц.
Ключевые функции
- Гибкость на базе ИИ: AI Web Scraper от Thunderbit автоматически определяет и форматирует веб-данные, избавляя от необходимости использовать CSS-селекторы.
- Самый простой опыт скрейпинга: всё, что нужно, — нажать «AI suggest column», а затем нажать «Scrape» на странице, с которой вы хотите извлечь данные. И всё.
- Поддержка разных форматов данных: Thunderbit может собирать URL, изображения и отображать полученные данные в нескольких форматах.
- Автоматическая обработка данных: ИИ Thunderbit может сразу переформатировать данные, включая их краткое резюмирование, категоризацию и перевод в нужный формат.
- Простой экспорт данных: экспортируйте данные в Google Sheets, Airtable или Notion одним кликом, упрощая управление данными.
- Удобный интерфейс: интуитивный интерфейс делает его доступным пользователям любого уровня.
Цена
У Thunderbit есть тарифы по уровням, начиная с $9 в месяц за 5 000 кредитов. Максимальный тариф — $199 за 240 000 кредитов. Также при годовом плане все кредиты вы получаете сразу.
Плюсы:
- Сильная поддержка ИИ упрощает извлечение и обработку данных.
- Без кода, подходит пользователям любого уровня.
- Идеален для лёгкого скрейпинга, например каталогов, сайтов магазинов и т. д.
- Широкие возможности интеграции для прямого экспорта в популярные приложения.
Минусы:
- Массовый сбор данных может занять некоторое время, чтобы обеспечить точность.
- Некоторые продвинутые функции могут требовать платной подписки.
Хотите узнать больше? Начните с установки Thunderbit или узнайте, как легко собирать данные с сайтов с помощью Thunderbit.
Лучший веб-скрейпер для мониторинга данных и массового извлечения
Browse AI
Browse AI — это надёжный no-code инструмент для сбора данных, созданный для того, чтобы помогать пользователям извлекать и отслеживать данные без написания кода. В Browse AI есть некоторые функции ИИ, но до полноценного AI-скрейпинга он всё же не дотягивает. Тем не менее, начать работу с ним пользователям действительно проще.
Ключевые функции
- No-code интерфейс: позволяет создавать собственные рабочие процессы простыми кликами.
- Мониторинг в реальном времени: использует ботов для отслеживания изменений на страницах и передачи обновлённой информации.
- Массовое извлечение данных: способен обрабатывать до 50 000 записей за один раз.
- Интеграция рабочих процессов: связывает несколько ботов для более сложной обработки данных.
Цена
От $48,75 в месяц, включая 2 000 кредитов. Есть бесплатный тариф, который даёт 50 кредитов в месяц, чтобы попробовать базовые функции.
Плюсы:
- Есть интеграции с Google Sheets и Zapier.
- Готовые боты упрощают типовые задачи извлечения данных.
Минусы:
- Для сложных страниц может потребоваться дополнительная настройка.
- Скорость массового скрейпинга может отличаться, иногда возникают тайм-ауты.
Лучший веб-скрейпер для интеграции рабочих процессов
Bardeen AI
Bardeen AI — это no-code инструмент автоматизации, созданный для упрощения рабочих процессов за счёт связывания различных приложений. Хотя он использует ИИ для создания пользовательских автоматизаций, по гибкости он не дотягивает до полноценного инструмента AI-скрейпинга.
Ключевые функции
- No-code автоматизация: позволяет настраивать рабочие процессы кликами.
- MagicBox: описывает задачи простым языком, а Bardeen AI превращает их в рабочие процессы.
- Широкие возможности интеграции: интегрируется более чем с 130 приложениями, включая Google Sheets, Slack и LinkedIn.
Цена
От $60 в месяц, включая 1 500 кредитов (примерно 1 500 строк данных). В бесплатном тарифе даётся 100 кредитов в месяц для знакомства с базовыми функциями.
Плюсы:
- Широкие возможности интеграций помогают решать самые разные бизнес-задачи.
- Гибкий и масштабируемый вариант для бизнеса любого размера.
Минусы:
- Новым пользователям может понадобиться время, чтобы освоить всю платформу.
- Первоначальная настройка может занять много времени.
Лучший визуальный веб-скрейпер для опытных пользователей
Web Scraper
Да, вы не ослышались: инструмент действительно называется «Web Scraper». Web Scraper — это популярное расширение для браузеров Chrome и Firefox, которое позволяет извлекать данные без кода, предлагая визуальный способ создания задач скрейпинга. Однако, чтобы по-настоящему освоить этот инструмент, вам, возможно, придётся несколько дней смотреть и изучать обучающие материалы выше. Если хотите, чтобы скрейпинг не перегружал голову, выбирайте AI Web Scraper.
Ключевые функции
- Визуальное создание: позволяет настраивать задачи скрейпинга, нажимая на элементы страницы.
- Поддержка динамических сайтов: умеет работать с AJAX-запросами и JavaScript на динамических сайтах.
- Облачный скрейпинг: позволяет запускать задачи по расписанию через Web Scraper Cloud для периодического сбора данных.
Цена
Бесплатно для локального использования; платные тарифы начинаются с $50 в месяц за облачные функции.
Плюсы:
- Хорошо работает с динамическими сайтами.
- Бесплатно для локального использования.
Минусы:
- Для оптимальной настройки требуются технические знания.
- Для изменений нужно проводить сложное тестирование.
Лучший веб-скрейпер для обхода IP-блокировок и защиты от ботов
Octoparse
Octoparse — это универсальная программа для более технически продвинутых пользователей, позволяющая собирать и отслеживать конкретные веб-данные без кода; особенно полезна для больших объёмов данных. Octoparse не использует браузер пользователя для работы — вместо этого он применяет облачные серверы для сбора данных. Поэтому он может предлагать разные способы обхода IP-блокировок и некоторых механизмов защиты сайтов от ботов.
Ключевые функции
- Работа без кода: пользователи могут создавать задачи скрейпинга без написания кода, что делает инструмент доступным людям с разным уровнем технической подготовки.
- Умное автоопределение: автоматически определяет данные на странице, быстро находит элементы, доступные для скрейпинга, и упрощает настройку.
- Облачный скрейпинг: поддерживает круглосуточный облачный сбор данных с задачами по расписанию для гибкого получения информации.
- Большая библиотека шаблонов: предлагает сотни готовых шаблонов, позволяя быстро получать данные с популярных сайтов без сложной настройки.
Цена
Тариф Octoparse начинается с $119 в месяц и включает 100 задач. Также доступен бесплатный тариф с 10 задачами в месяц, чтобы протестировать базовый функционал.
Плюсы:
- Мощные функции позволяют эффективно работать с динамическими сайтами.
- Есть решения для обхода ограничений при скрейпинге и проблем с динамическим контентом.
Минусы:
- Для сложных структур сайтов может потребоваться больше времени на настройку.
- Новым пользователям может понадобиться время, чтобы освоить работу с инструментом.
Лучший веб-скрейпер для продвинутого API извлечения данных на базе ИИ
Diffbot
Diffbot — это продвинутый инструмент для извлечения веб-данных, который использует ИИ, чтобы превращать неструктурированный контент в структурированные данные. Благодаря мощным API и knowledge graph, Diffbot помогает пользователям извлекать, анализировать и управлять информацией из интернета, что подходит для разных отраслей и сценариев использования.
Ключевые функции
- API для извлечения данных: Diffbot предлагает API для извлечения данных без правил, позволяя просто передать URL для автоматического получения информации и избавляя от необходимости настраивать правила для каждого сайта.
- API обработки естественного языка: извлекает из неструктурированного текста структурированные сущности, связи и тональность, помогая пользователям строить собственные knowledge graph.
- Knowledge graph: у Diffbot один из крупнейших knowledge graph, соединяющий обширные данные о сущностях, включая сведения о людях и организациях.
Цена
Тариф Diffbot начинается с $299 в месяц и включает 250 000 кредитов (примерно 250 000 извлечений веб-страниц через API).
Плюсы:
- Сильные возможности извлечения данных без правил и высокая гибкость.
- Широкие возможности API-интеграции для лёгкого подключения к существующим системам.
- Поддерживает масштабный сбор данных и подходит для корпоративных задач.
Минусы:
- На начальную настройку нетехническим пользователям может понадобиться время на обучение.
- Для использования API нужно написать программу, которая будет к нему обращаться.
Для чего можно использовать скрейперы?
Если вы только начинаете заниматься веб-скрейпингом, вот несколько популярных сценариев, которые помогут стартовать. Многие используют скрейперы, чтобы собирать карточки товаров Amazon, вытаскивать данные о недвижимости с Zillow или собирать сведения о компаниях из Google Maps. Но это только начало — вы можете использовать Thunderbit AI Web Scraper для сбора данных практически с любого сайта, упрощая задачи и экономя время в повседневной работе. Для исследований, отслеживания цен или построения баз данных веб-скрейпинг открывает бесконечные возможности для полезной работы с данными интернета.
FAQ
-
Законен ли веб-скрейпинг?
Обычно веб-скрейпинг законен, но необходимо соблюдать условия использования сайта и учитывать характер данных, к которым вы получаете доступ. Всегда изучайте соответствующие правила и следуйте требованиям закона.
-
Нужны ли навыки программирования для работы с инструментами веб-скрейпинга?
Большинству инструментов из этого списка навыки программирования не нужны, но таким инструментам, как Octoparse и Web Scraper, для лучшего результата могут пригодиться базовые знания о структуре веб-страниц и программный подход.
-
Есть ли бесплатные инструменты для веб-скрейпинга?
Да, доступны бесплатные инструменты вроде BeautifulSoup, Scrapy и Web Scraper, а некоторые сервисы также предлагают бесплатные тарифы с ограниченным набором функций.
-
Какие основные сложности возникают при веб-скрейпинге?
К распространённым сложностям относятся работа с динамическим контентом, CAPTCHA, IP-блокировки и сложные HTML-структуры. Продвинутые инструменты и методы позволяют эффективно решать эти проблемы.
Подробнее:
Используйте ИИ и работайте без усилий. Get Started Free




