Парсинг Facebook по-прежнему актуален в 2026 году, но только если выбрать правильную модель сбора данных. Pew Research Center сообщил 20 ноября 2025 года, что , а Meta 29 апреля 2026 года заявила, что её в марте 2026 года. Такой масштаб по-прежнему делает Facebook полезным для мониторинга Marketplace, исследования публичных страниц, лидогенерации и отслеживания конкурентов. Сложность не в том, чтобы найти сценарии использования. Сложность в том, чтобы получать чистые данные и не застревать на экранах входа, динамической подгрузке, временных блокировках или хрупких настройках парсинга.
Этот ежегодный список составлен с упором на скорость принятия решения. Я перепроверил официальные страницы продуктов, документацию и сигналы по ценам 8 мая 2026 года, а затем оставил только те инструменты, которые действительно подходят для реальных бизнес-пользователей. Если ваш процесс чаще всего выглядит как «забрать данные со страницы и отправить их в таблицу», начните с Thunderbit. Если вам нужна инфраструктура уровня API, обратите внимание на Bright Data, Apify и Nimble by Nimbleway. Если в вашей работе после сбора данных нужны облачные автоматизации или последующие действия, PhantomBuster заслуживает отдельного внимания.
Быстрый выбор по задачам
- Нужен самый быстрый no-code экспорт из Facebook или Marketplace? Начните с .
- Нужны API корпоративного уровня и управляемое снятие блокировок? В шортлист стоит включить .
- Нужны гибкие облачные сценарии парсинга? Присмотритесь к .
- Нужен сбор публичных данных через API с меньшими затратами на поддержку парсера? Рассмотрите .
- Нужен бюджетный API для более лёгких задач? всё ещё актуален.
- Нужны и парсинг, и автоматизация рабочих процессов? подойдёт лучше.
- Нужен визуальный конструктор сценариев с расписанием? остаётся надёжным no-code вариантом.
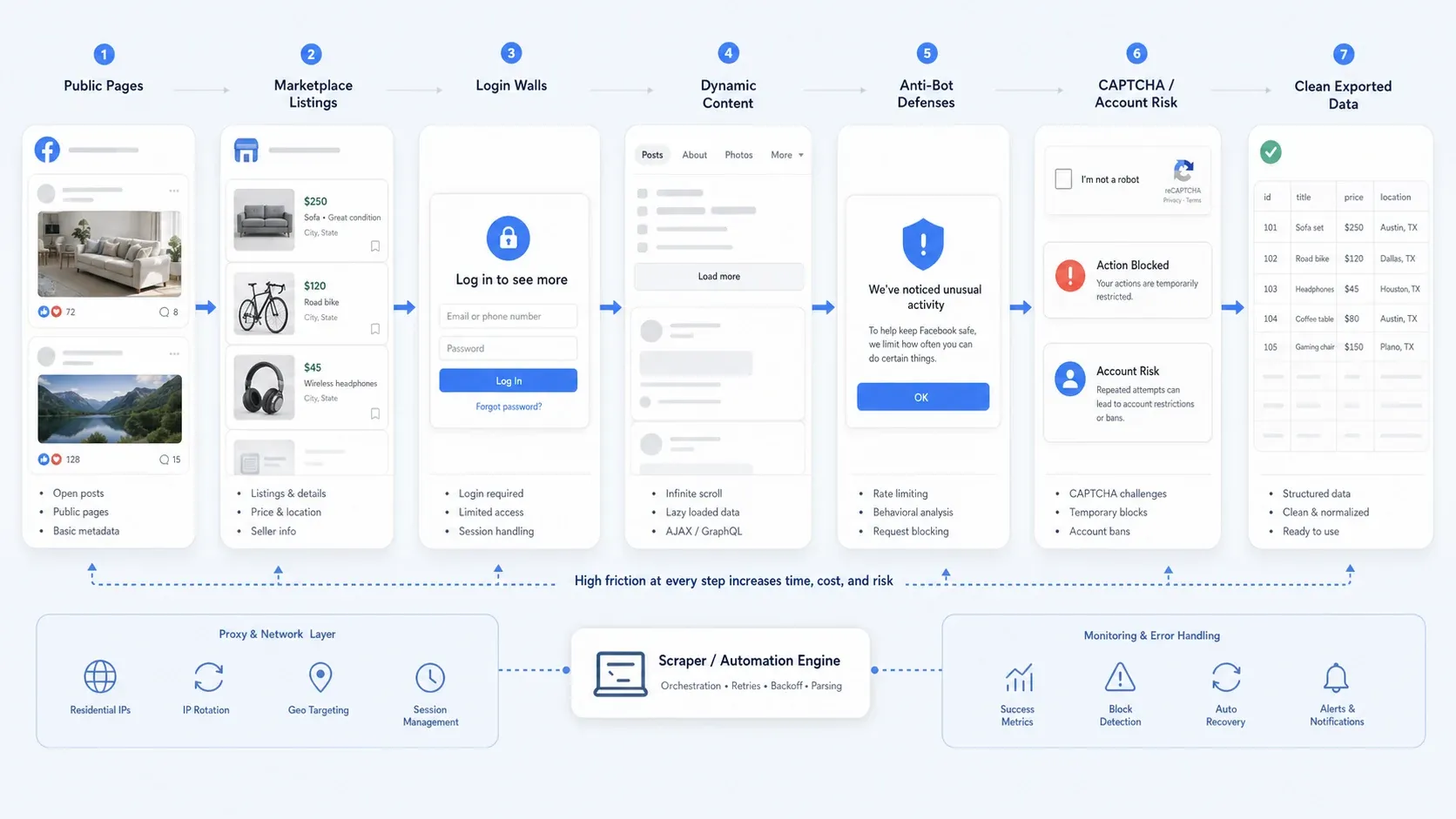
Почему парсинг Facebook в 2026 году всё ещё сложен
Сбор данных из Facebook сегодня редко сводится только к выбору CSS-селекторов. На практике большинство команд сталкиваются с одной или несколькими из следующих проблем:
- Частично открытый доступ: часть страниц остаётся публичной, а другие сценарии требуют входа, чтобы увидеть больше деталей.
- Динамический контент: страницы Marketplace, длинные цепочки комментариев и контент страниц часто подгружаются постепенно.
- Антибот-защита: ограничение частоты запросов, поведенческие проверки, CAPTCHA и временные блокировки ломают наивные автоматизации.
- Операционные риски: сбор данных только после входа гораздо рискованнее, чем парсинг публичных страниц, особенно если важны безопасность аккаунта и повторяемость.
Как я оценивал эти инструменты
Я оптимизировал эту страницу под выбор шортлиста, а не под перечисление всех функций. Инструменты ниже сравнивались по следующим критериям:
- Соответствие рабочему процессу: действительно ли продукт подходит для задач сбора данных из Facebook и Marketplace, с которыми сталкиваются реальные команды?
- Простота использования: могут ли нетехнические пользователи или небольшие команды быстро получить рабочий результат?
- Масштаб и надёжность: остаётся ли инструмент актуальным после разового парсинга?
- Антибот-защита и работа с сессиями: сколько инфраструктурных проблем продукт снимает с команды?
- Качество результата: можно ли получить структурированные данные в CSV, Sheets или downstream-системы без серьёзной очистки?
- Сигнал по цене: реально ли продукт оценить без сложного enterprise-процесса?
- Подход к комплаенсу: ориентирован ли инструмент на сбор публичных данных и ответственное использование?
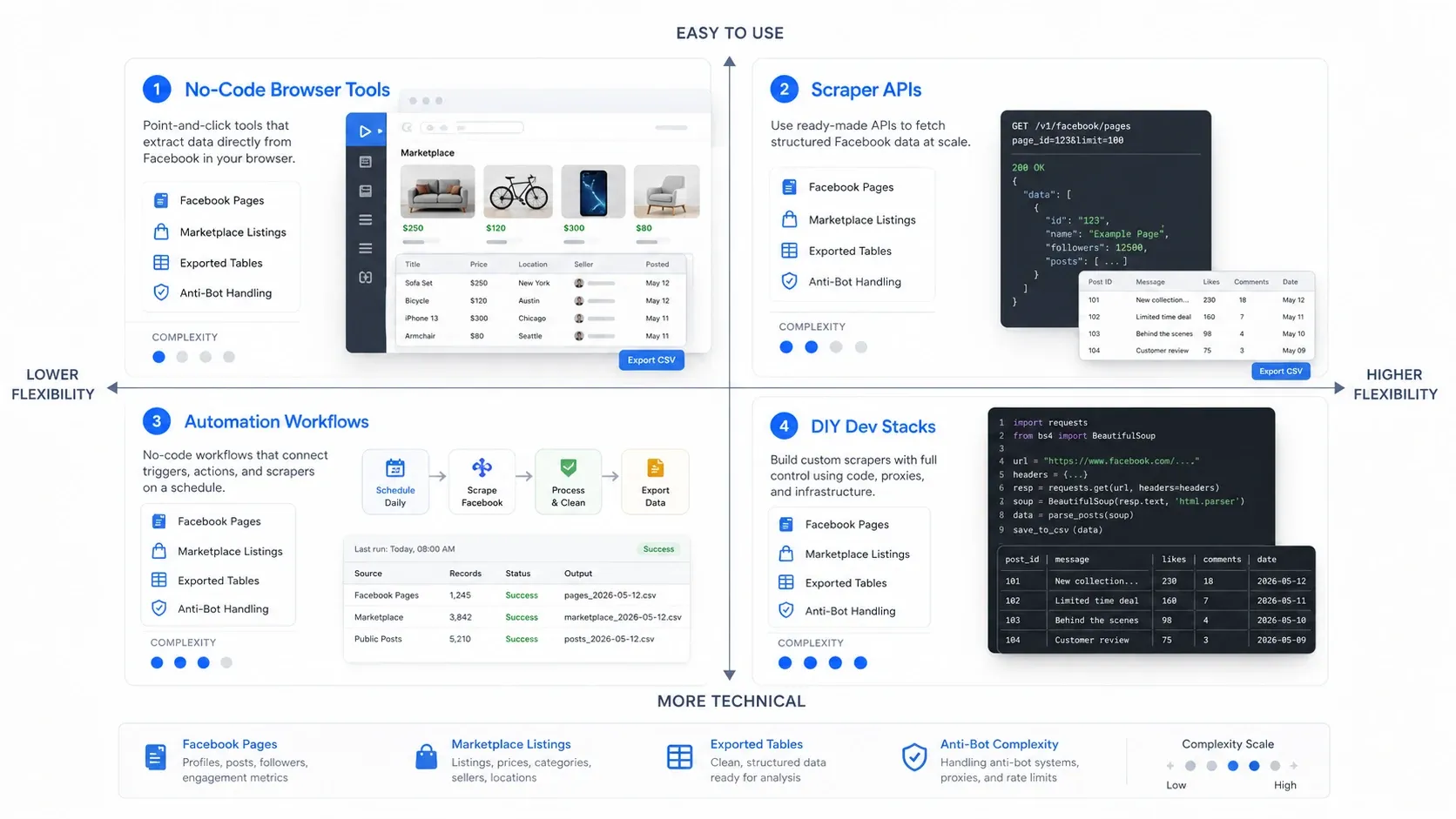
Какой тип Facebook Scraper вам нужен?
Самый быстрый путь к хорошему выбору — сначала выбрать правильную категорию. Инструменты для парсинга Facebook обычно делятся на четыре модели работы:
- No-code браузерные инструменты: лучший вариант, если нужен быстрый сбор со страницы, уже открытой перед вами.
- Scraper API: лучший вариант, если нужен надёжный и повторяемый сбор в большом объёме.
- Автоматизации рабочих процессов: лучший вариант, если парсинг — только один шаг в более широком процессе выхода на рынок.
- DIY dev-стек: лучший вариант, если команде нужен максимальный контроль и она готова взять на себя поддержку.
Сравнительная таблица
| Инструмент | Для чего лучше всего подходит | Почему вошёл в шортлист | Сигнал по цене |
|---|---|---|---|
| Thunderbit | Нетехнические команды и быстрые разовые задачи | AI-распознавание полей, нативная работа с динамическими страницами, быстрый экспорт | Бесплатный пробный период; платные планы по кредитной модели |
| Bright Data | Крупномасштабные пайплайны публичных социальных данных | Специализированные API для парсинга соцсетей, управляемое снятие блокировок, высокая масштабируемость | Оплата по использованию и enterprise-цены |
| Apify | Гибкие облачные сценарии парсинга | Готовые Facebook actors, расписание, API-доступ, пространство для кастомизации | Платные планы платформы плюс тарификация по факту использования |
| Nimble by Nimbleway | Сбор публичных веб-данных через API | API-логика, ориентированная на URL, и меньшая нагрузка на поддержку парсера | Цены по продажной модели |
| ScrapingBot | Небольшие задачи по публичным данным и прототипы | Простой API, поддержка рендеринга, низкий порог входа по цене | Бесплатный тариф; платные планы от примерно $22 в месяц |
| PhantomBuster | Автоматизация GTM-процессов | Облачные автоматизации, сценарии действий в браузере, удобен для лидогенерации | Бесплатный пробный период; платные планы от примерно $56 в месяц |
| Octoparse | Визуальный no-code парсинг по расписанию | Конструктор с drag-and-drop, облачный сбор, повторяемые сценарии | Бесплатный план; платные планы от примерно $119 в месяц |
1. Thunderbit
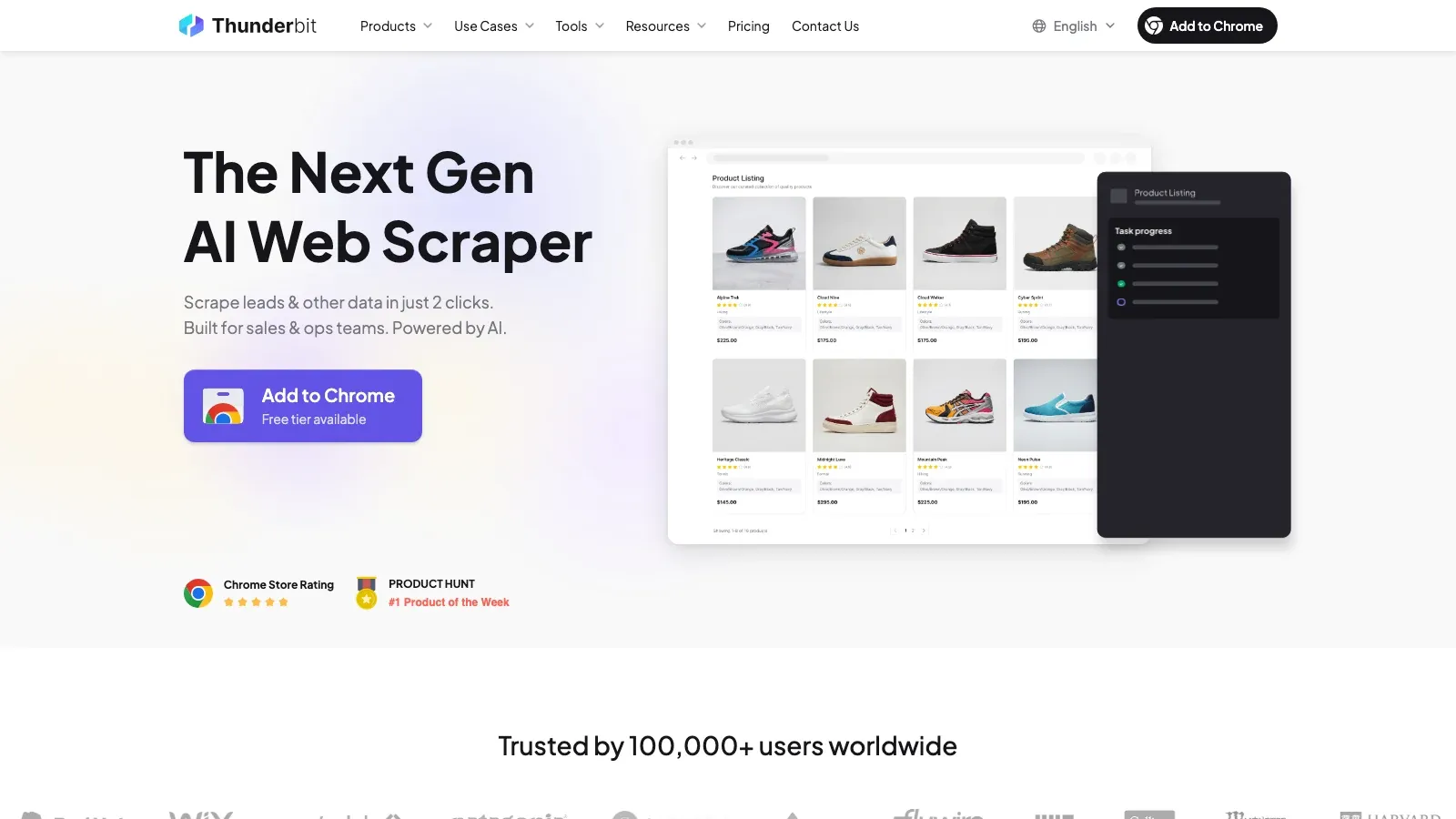
— самый сильный вариант здесь, если ваша цель — быстро превратить страницу Facebook или список результатов Marketplace в структурированные данные без создания и поддержки собственного парсера. Его главное преимущество — семантическое извлечение: он читает страницу, предлагает полезные поля и позволяет экспортировать результат без возни с селекторами, прокси или кодом.
Что выделяет его среди других:
- AI Suggest Fields: Thunderbit определяет вероятные поля, такие как заголовок, цена, продавец, местоположение, контакты и URL.
- Нативная работа в браузере: поскольку инструмент работает там, где отображается страница, он хорошо справляется с динамическими страницами с большой прокруткой.
- Обогащение через подстраницы: можно сначала собрать данные списка, а затем открыть каждое объявление или страницу для более подробной информации.
- Удобный экспорт: Excel, Google Sheets, Airtable и Notion — естественные конечные точки.
Если вы хотите посмотреть одно видео перед тем, как пробовать браузерный workflow на практике, этот подробный разбор Thunderbit — лучшее место для старта, потому что он показывает реальный процесс извлечения данных, а не просто перечисляет функции:
Лучше всего подходит для: нетехнических пользователей, sales-команд, операционных специалистов и исследователей, которым нужен быстрый результат.
Сигнал по цене: доступен бесплатный пробный период; платные планы работают по кредитной модели. См. .
2. Bright Data
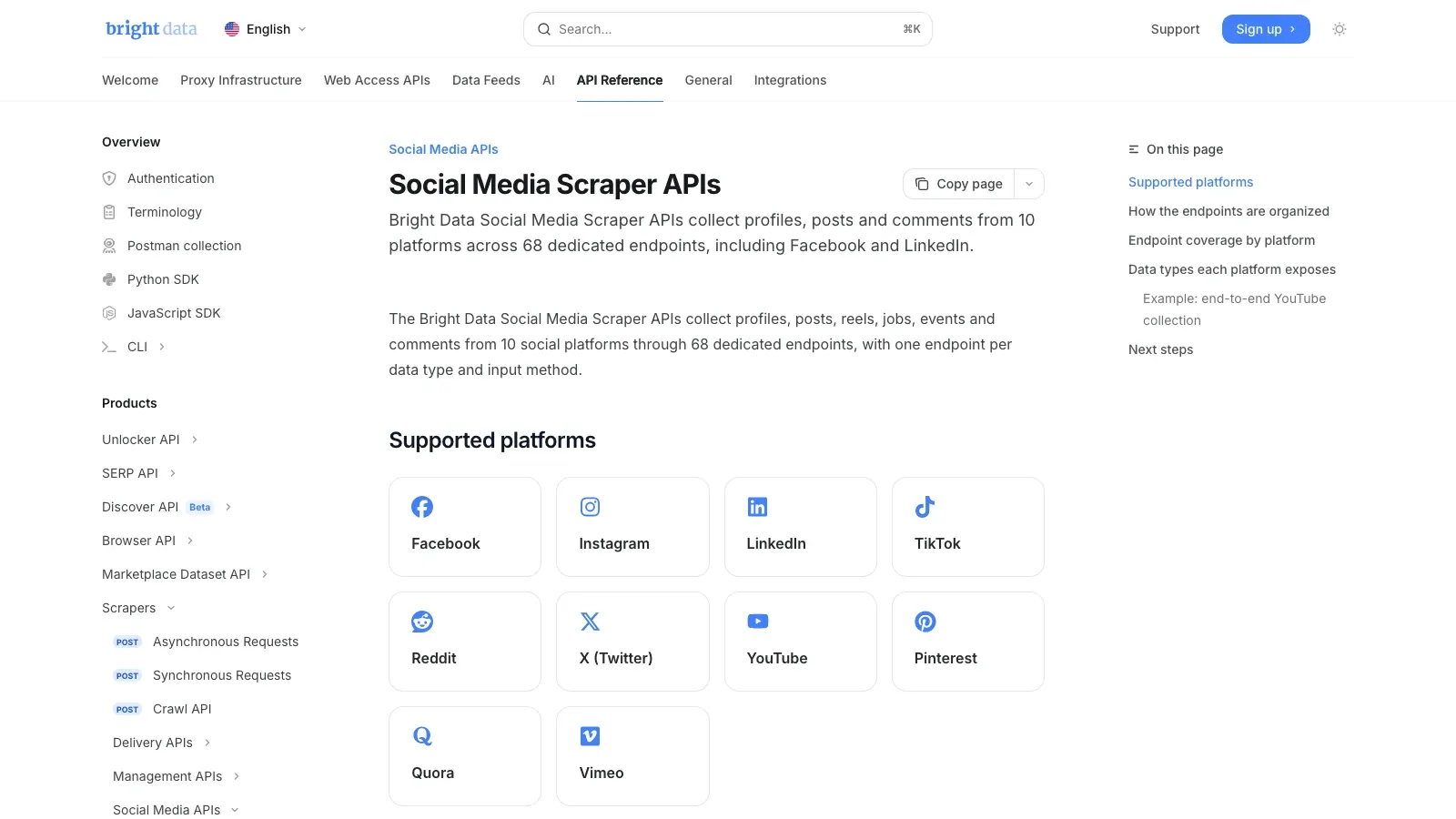
— выбор с фокусом на инфраструктуру. В собственной документации Bright Data указано, что её охватывают 10 платформ и 68 специализированных endpoint'ов, включая Facebook. Если ваша задача — крупномасштабный сбор публичных данных, такой управляемый API-стек обычно куда реалистичнее, чем попытка масштабировать браузерное расширение или самописный парсер.
Почему он заслужил место в шортлисте:
- Специализированные endpoints для парсинга соцсетей
- Управляемое снятие блокировок и извлечение данных
- Структурированная передача данных в пайплайны
- Лучше подходит для задач мониторинга и аналитики, где критична надёжность
Лучше всего подходит для: аналитиков, дата-команд, крупных проектов мониторинга и масштабных публичных социальных датасетов.
Сигнал по цене: цена зависит от продукта и объёма. Уточняйте по .
3. Apify
остаётся актуальным, потому что даёт хороший баланс между шаблонами и полной кастомизацией. Его actor для Facebook Pages Scraper — удобная отправная точка, а сама платформа Apify предоставляет облачное выполнение, расписания, API и пространство для расширения процесса, если задачи становятся сложнее.
Почему он попал в список:
- Готовые Facebook actors
- Облачное выполнение и повторяющиеся расписания
- Гибкий экспорт и доступ к API
- Проще расширять, чем чисто no-code браузерный workflow
Лучше всего подходит для: технических маркетологов, агентств, ops-команд и повторяющихся задач сбора данных на нескольких сайтах.
Сигнал по цене: планы платформы платные, а использование actor тарифицируется отдельно. См. .
4. Nimble by Nimbleway
— это API-first вариант для команд, которые хотят передать URL, а платформе оставить доступ, рендеринг и доставку результата. Nimble позиционирует свой как end-to-end решение для сбора публичных веб-данных, что делает его полезным, когда парсинг Facebook — лишь часть более широкой data stack.
Почему стоит оценить его отдельно:
- API-процесс, ориентированный на URL
- Меньше нагрузки на поддержку парсера для инженерной команды
- Хорошо подходит для устойчивого извлечения публичных веб-данных
- Полезен, когда данные после парсинга идут во внутренние продукты или дашборды
Лучше всего подходит для: команд с инженерным лидерством, продуктовых data-пайплайнов и организаций, которым нужна инфраструктурная абстракция вместо точечных инструментов.
Сигнал по цене: Nimble не делает акцент на публичных self-serve ценах на основных страницах API, поэтому стоит ожидать продажи по запросу и уточнять напрямую у .
5. ScrapingBot
— самый бюджетно-ориентированный API- вариант в этом списке. Это не самая глубокая специализированная платформа именно для Facebook, но она всё равно полезна для небольших задач по публичным данным, где нужен API, поддержка рендеринга и более низкий ценовой порог, чем у enterprise-инфраструктуры парсинга.
Где он уместен:
- Простой API-парсинг публичных страниц
- Низкий порог входа по цене
- Встроенная поддержка рендеринга и прокси
- Лучше для прототипов и лёгких повторяющихся сборов, чем для крупных аналитических программ
Лучше всего подходит для: стартапов, малого бизнеса и разработчиков, тестирующих более лёгкие сценарии сбора данных с публичных страниц.
Сигнал по цене: есть бесплатный тариф; текущая публичная страница с ценами показывает платные планы примерно от .
6. PhantomBuster
— это меньше про «чистую» инфраструктуру парсинга и больше про то, что происходит после сбора данных. Если ваш сценарий звучит как «собрать данные, а затем запустить outreach, обогащение или follow-up-действия», PhantomBuster часто полезнее, чем обычный экстрактор, потому что он построен вокруг облачных автоматизаций и браузерных workflow.
Почему команды всё ещё включают его в шортлист:
- Облачные автоматизации
- Полезен для лидогенерации и GTM-операций
- Лучше подходит, когда парсинг — лишь один шаг в более широком процессе
- Практичен для операторов, которым важны действия, а не только экспорт
Лучше всего подходит для: GTM-команд, growth-команд, рекрутеров и операционных специалистов, которые связывают сбор данных с дальнейшими действиями.
Сигнал по цене: доступен бесплатный пробный период; платные планы на текущей странице цен начинаются примерно от .
7. Octoparse
по-прежнему остаётся одним из лучших визуальных no-code инструментов парсинга для тех, кому нужны повторяемые workflow и облачные запуски по расписанию. Он не такой лёгкий, как Thunderbit, для быстрых разовых задач в Facebook, но даёт нетехническим пользователям более явный контроль над тем, как строится и повторяется логика извлечения.
Почему он остаётся актуальным:
- Визуальный конструктор workflow с drag-and-drop
- Облачный сбор и расписание
- Хорош для структурированных повторяющихся задач
- Лучше подходит аналитикам, которым нужна повторяемость без кода
Лучше всего подходит для: нетехнических аналитиков, SMB ops-команд и повторяющихся задач сбора данных с более явной логикой workflow.
Сигнал по цене: на публичной странице цен Octoparse платные планы начинаются примерно от .
Шортлист по типу команды
Если вы уже понимаете, какая команда будет отвечать за workflow, начните отсюда:
- Соло-оператор или малый бизнес: Thunderbit, ScrapingBot или Octoparse
- Sales / GTM-команда: Thunderbit или PhantomBuster
- Ops-аналитик: Thunderbit, Apify или Octoparse
- Команда по growth-автоматизации: PhantomBuster или Apify
- Команда data engineering: Bright Data, Nimble или Apify

Как выбрать правильный Facebook Scraper
- Выберите Thunderbit, если скорость и простота важнее максимального масштаба.
- Выберите Bright Data, если вам нужны масштаб публичных данных и управляемая надёжность.
- Выберите Apify, если нужна гибкость платформы и actor-ориентированные workflow.
- Выберите Nimble, если вам нужен API-first слой абстракции с меньшей нагрузкой на поддержку парсера.
- Выберите PhantomBuster, если парсинг — лишь один шаг в более широком GTM-процессе автоматизации.
- Выберите Octoparse, если нужна визуальная повторяемость без кода.
- Выберите ScrapingBot, если важен бюджет и задача относительно простая.
Итог
Рынок в 2026 году разделился чётче, чем год назад. На самом деле вы выбираете не один универсальный «лучший Facebook scraper». Вы выбираете модель сбора данных: быстрое no-code извлечение, масштабируемый API, облачную автоматизацию или ручной визуальный контроль workflow. Начните с этого — и шортлист сразу станет намного короче.
Если вашей команде нужен самый быстрый путь от страницы Facebook или объявления Marketplace к полезным структурированным данным, Thunderbit по-прежнему остаётся самым простым стартом. Если у вас значительно выше объём или инженерные требования, больше смысла в Bright Data, Apify и Nimble. Если ваш процесс начинается с парсинга, но заканчивается последующими действиями, умнее всего будет включить в шортлист PhantomBuster.
FAQ
1. Какой инструмент для парсинга Facebook проще всего для нетехнических пользователей?
Thunderbit — самый простой старт для большинства нетехнических пользователей, потому что он работает в браузере, автоматически предлагает поля и быстро экспортирует данные без кода.
2. Какой инструмент для парсинга Facebook лучше всего подходит для крупномасштабного сбора публичных данных?
Bright Data — самый сильный выбор с точки зрения инфраструктуры в этом списке, когда задача — крупномасштабный сбор публичных социальных данных, а надёжность важнее простоты использования.
3. Что делать, если мне нужен и парсинг, и последующая автоматизация?
PhantomBuster — лучший вариант, когда сбор данных — лишь один шаг в более широком workflow лидогенерации или GTM.
4. Сложно ли парсить Facebook в 2026 году?
Да. Динамический контент, экраны входа, лимиты запросов, антибот-системы и риски для аккаунта по-прежнему делают Facebook сложнее, чем простые публичные сайты.
5. Как командам думать о комплаенсе?
Сосредоточьтесь на публичных данных, используйте разумные скорости, избегайте злоупотребления учётными данными и перед масштабированием workflow проверьте условия платформы и применимые правила конфиденциальности.
Дополнительно: