

Вы регистрируетесь в ScraperAPI, видите на тарифе Hobby «100 000 кредитов» и начинаете парсить сайты. Через три дня в панели видно, что 80% этих кредитов уже сгорели — а вы обработали, может быть, 6 000 страниц. Что произошло? Дело в системе кредитных множителей, и это, пожалуй, самая важная вещь в ScraperAPI, которую почти не объясняет ни один обзор. Я потратил недели на изучение документации ScraperAPI, собрал реальные данные по ценам у пяти конкурентов и перечитал все треды на Reddit и отзывы на Capterra, которые смог найти. Этот обзор ScraperAPI — тот самый материал, которого мне самому не хватало, когда наша команда впервые начала оценивать scraping API. Я разберу реальную математику кредитов, покажу, где ScraperAPI реально силён, а где откровенно проваливается, соберу мнения пользователей с G2, Capterra и Reddit и — честно говоря — помогу понять, нужен ли вам scraping API вообще.
Что такое ScraperAPI и для кого он создан?
ScraperAPI — это API для веб-скрейпинга, которое берёт на себя всю сложную инфраструктуру большого парсинга: ротацию прокси через 40+ миллионов IP-адресов в 50+ странах, автоматическое решение CAPTCHA, рендеринг JavaScript и повторные попытки при ошибках. Вы отправляете ему URL через простой API-запрос, а в ответ получаете HTML (или уже разобранный JSON, если используете их endpoints со структурированными данными). Компания основана в 2018 году Daniel Ni, базируется в Лас-Вегасе и сейчас обслуживает более 10 000 брендов, включая Deloitte, Sony и Alibaba, обрабатывая 36 миллиардов API-запросов в месяц.
Основная аудитория — команды разработчиков и технические специалисты, которые строят собственные пайплайны для сбора данных. Если ты не пишешь код, ScraperAPI не для тебя (ниже объясню подробнее).
Базовый набор возможностей: ротация прокси, рендеринг JavaScript, геотаргетинг, structured data endpoints для популярных сайтов и автоматические повторы запросов, завершившихся ошибкой.
Но вот что многие обзоры упускают: цифры кредитов, указанные на странице тарифов ScraperAPI, сильно вводят в заблуждение, если не понимать, как работают множители. Поэтому начнём именно с этого.
Как на самом деле работает система кредитов ScraperAPI (часть, которую большинство обзоров пропускает)
ScraperAPI использует модель оплаты на основе кредитов. Базовая идея простая: 1 API-запрос = 1 кредит. Но на практике почти никогда так не бывает. Реальная стоимость запроса зависит от двух вещей: домена, который вы парсите, и включённых функций. И эти расходы складываются совсем не так, как ожидается.
Таблица кредитных множителей, которую должен видеть каждый пользователь до регистрации

Даже до включения любых параметров тип сайта уже определяет базовую стоимость в кредитах:
| Категория домена | Базовые кредиты за запрос | Примеры |
|---|---|---|
| Обычные сайты | 1 | Блоги, новостные сайты, простой HTML |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (поисковые системы) | 25 | Google, Bing |
| Социальные сети | 30 |
Поверх этого дополнительные параметры добавляют ещё кредиты:
| Параметр | Дополнительные кредиты | Примечания |
|---|---|---|
render=true (рендеринг JS) | +10 | На всех тарифах |
screenshot=true | +10 | На всех тарифах |
premium=true (premium proxy) | +10 | На всех тарифах |
ultra_premium=true | +30 | Только платные тарифы |
| Обход антибот-защиты (Cloudflare, DataDome, PerimeterX) | +10 за каждый | Определяется автоматически — вручную не выбирается |
premium=true + render=true вместе | +25 | НЕ +20 |
ultra_premium=true + render=true вместе | +75 | НЕ +40 |
Вот последний пункт и есть главное «но». Комбинирование функций стоит ДОРОЖЕ, чем простая сумма отдельных надбавок. Premium proxy (+10) плюс рендеринг JavaScript (+10) логично должны стоить +20 кредитов, но ScraperAPI берёт +25. Ultra-premium (+30) плюс рендеринг JavaScript (+10) должны обходиться в +40, но на деле это +75 — почти вдвое больше. Такой нелинейный подсчёт не особо заметен в документации, и именно поэтому пользователи пишут, что кредиты исчезают слишком быстро.
Параметры, которые не расходуют дополнительные кредиты: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Что реально даёт каждый тариф: от Free до Enterprise
Вот актуальные тарифы ScraperAPI:
| Тариф | Ежемесячная цена | Годовой (в мес.) | API кредиты | Параллельные потоки | Геотаргетинг |
|---|---|---|---|---|---|
| Free | $0 | — | 1 000 | 5 | Нет |
| Hobby | $49 | $44 | 100 000 | 20 | Только США и ЕС |
| Startup | $149 | $134 | 1 000 000 | 50 | Только США и ЕС |
| Business | $299 | $269 | 3 000 000 | 100 | На уровне стран (50+ стран) |
| Scaling | $475 | $427 | 5 000 000 | 200 | На уровне стран |
| Enterprise | Индивидуально | Индивидуально | 5 000 000+ | 200+ | На уровне стран |
А теперь — реальная стоимость 1 000 запросов на каждом тарифе с учётом множителей:
| Тариф | Обычный (1×) | Рендеринг JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
Тариф за $49 в месяц, который рекламируется как «100 000 кредитов», на деле даёт лишь 1 333 реальных запроса, если вы парсите защищённые сайты с ultra-premium и рендерингом JavaScript. Это выходит в $36.75 за 1 000 страниц — дороже, чем многие fully managed scraping-сервисы.
Почему кредиты заканчиваются быстрее, чем вы ожидаете
Пользователей обычно удивляют три вещи.
Во-первых: ценообразование по домену включается автоматически. Вы не выбираете 5× множитель для Amazon или 25× для Google вручную. Он применяется в момент, когда ScraperAPI распознаёт домен. То же относится к дополнительным кредитам за обход антибота (+10 за Cloudflare, DataDome, PerimeterX) — они тоже начисляются автоматически при обнаружении.
Во-вторых: кредиты НЕ переносятся на следующий месяц. Неиспользованные кредиты сгорают в конце каждого биллингового периода. Накопления нет.
И в-третьих — это особенно неприятно — Pay-As-You-Go доступен только на тарифе Scaling ($475/мес.) и выше. Если вы на Hobby, Startup или Business и исчерпали кредиты до конца цикла, доступ просто отключается до следующего расчётного периода. Единственный выход — перейти на более высокий тариф.
Один пользователь на Reddit писал, что ему назвали цену $3 600 за 60 миллионов кредитов по схеме 1 кредит за запрос Amazon, но после оплаты внезапно применили множитель 5× без предварительного уведомления. Его пакет на 60M фактически оказался эквивалентен лишь 12M запросов — разница в 80% от ожидаемого.
Ловушка кредитов в DataPipeline
У no-code функции DataPipeline в ScraperAPI (запланированный скрейпинг с доставкой через webhook) свой отдельный, заметно более дорогой график списания кредитов. Обычный базовый запрос стоит 6 кредитов в DataPipeline вместо 1 кредита через стандартный API:
| Тип запроса | Стандартный API | DataPipeline | Соотношение |
|---|---|---|---|
| Базовый обычный запрос | 1 | 6 | 6× |
| Базовый e-commerce | 5 | 10 | 2× |
| Базовый SERP | 25 | 30 | 1.2× |
| Ultra-premium + JS (обычный) | 75 | 80 | 1.07× |
Пользователи, которые настраивают no-code пайплайны и ожидают стандартные расходы по кредитам, обнаруживают, что сжигают в 6 раз больше кредитов даже на базовых запросах. Это документировано, но искать это нужно отдельно.
Реальная стоимость одного запроса: ScraperAPI против конкурентов
Рекламные цены мало что значат без учёта множителей. Я собрал актуальные тарифы пяти поставщиков и сравнил их на уровне около $300 в месяц в трёх типичных сценариях.
Базовый HTML-скрейпинг (без JS и без premium proxy)
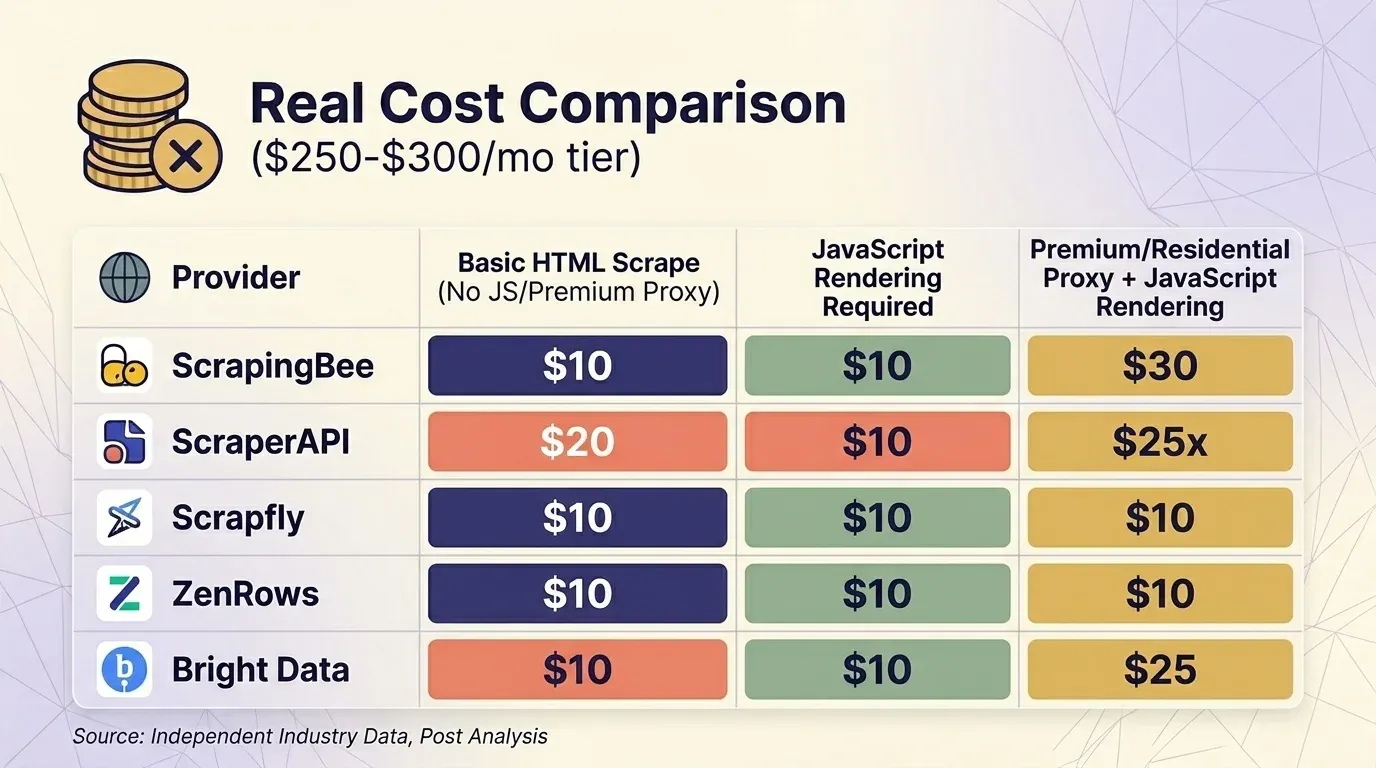
| Поставщик | Тариф | Кредитов за запрос | Реальных запросов | Цена за 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3 000 000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3 000 000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2 500 000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1 071 000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200 000 | $1.50 |
Нужен рендеринг JavaScript
| Поставщик | Тариф | Кредитов за запрос | Реальных запросов | Цена за 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (включён по умолчанию) | 600 000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416 667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300 000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214 000 | $1.40 |
| Bright Data | PAYG | фиксированная цена | ~200 000 | $1.50 |
Premium/Residential proxy + рендеринг JavaScript (защищённые сайты)
| Поставщик | Тариф | Кредитов за запрос | Реальных запросов | Цена за 1K |
|---|---|---|---|---|
| Bright Data | PAYG | фиксированная цена | ~200 000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120 000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120 000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80 645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42 857 | $7.00 |
Bright Data Web Unlocker — единственный поставщик, который не берёт доплату за рендеринг JavaScript: все запросы стоят по одной фиксированной ставке. На уровне около $300 ScrapingBee и ScraperAPI выглядят конкурентоспособно для парсинга защищённых сайтов, а ZenRows — самый дорогой.
Важное замечание по поведению: у ScrapingBee рендеринг JavaScript включён по умолчанию и стоит 5×. Если сравниваешь ScrapingBee и ScraperAPI напрямую, убедись, что сравниваешь одинаковые настройки рендеринга.
Независимый анализ Scrape.do показал, что ScraperAPI в среднем стоит $8.49 за 1 000 запросов — «больше, чем у любого другого протестированного поставщика», — а среднее время ответа составляет 15.7 секунды, что делает его «одним из самых медленных доступных решений». Это стоит учитывать до покупки.
Успешность по конкретным сайтам: где ScraperAPI силён, а где буксует
Ни один scraping API не работает одинаково хорошо на всех сайтах. Независимые бенчмарки Scrapeway (апрель 2026) показывают довольно резкую двугорбую картину.
Производительность по категориям сайтов
| Целевой сайт | Успешность | Средняя скорость | Цена за 1K (тариф Business) |
|---|---|---|---|
| Zillow | 100% | 10.5s | $0.49 |
| Etsy | 99% | 4.8s | $4.90 |
| Amazon | 98% | 6.5s | $2.45 |
| 95% | 17.8s | $14.70 | |
| Walmart | 93% | 11.4s | $2.45 |
| Indeed | 90% | 15.8s | $4.90 |
| StockX | 84% | 3.9s | $4.90 |
| Realtor.com | 12% | 11.8s | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Средняя успешность: 62.8–63.7%, немного выше среднего по отрасли — 58.2–59.5%. Среднее время ответа: 5.2–7.3 секунды, что лучше среднего по отрасли — 9.8 секунды.
Где ScraperAPI работает хорошо
ScraperAPI действительно силён в e-commerce (Amazon, Walmart, Etsy) и недвижимости (Zillow). Structured data endpoints для этих сайтов возвращают разобранный JSON с высокой надёжностью. Если ваш основной сценарий — парсинг товарных страниц Amazon или Google SERP, ScraperAPI можно рассматривать как разумный выбор.
Где ScraperAPI не справляется
Социальные сети — почти мёртвая зона. У Instagram, Twitter/X и Booking.com в независимых тестах успешность 0%. LinkedIn работает на 95%, но при 30 кредитах за запрос цена получается очень высокой.
Сайты с обязательным логином — под запретом. ScraperAPI поддерживает сохранение сессии через параметр session_number, но запрещает парсить данные за страницами входа. Он не умеет работать с заполнением форм, двухфакторной аутентификацией и сложными auth-flow.
Устаревшие данные на защищённых целях. На сложных сайтах ScraperAPI применяет принудительный кэш результатов на 10 минут, поэтому при сборе чувствительных ко времени данных (цены, остатки на складе) вы можете получать данные, которым уже до 10 минут.
В бенчмарке Proxyway за 2025 год у ScraperAPI был худший показатель успешности среди всех поставщиков на Google — 81.72%.
Краткое резюме по категориям сайтов
| Категория сайта | Производительность ScraperAPI | Известные проблемы | Возможная альтернатива |
|---|---|---|---|
| Amazon / e-commerce | ✅ Сильно (SDP endpoints) | На масштабе дорого по кредитам | Шаблоны Thunderbit (1 клик, без кредитов за строку для шаблона) |
| Google SERP | ✅ Сильно | Геотаргетинг стоит отдельно; в одном бенчмарке — самый низкий показатель по Google | — |
| Недвижимость (Zillow) | ✅ Отлично (100%) | — | — |
| Instagram / соцсети | ❌ 0% успешности | Полный провал | Playwright + proxies (своими силами) |
| SPA с тяжёлым JS | ⚠️ Средне | Требуется headless-рендеринг за 10× кредитов | Scrapfly, ZenRows |
| Сайты с логином | ❌ Запрещено условиями | Нет поддержки сессий/авторизации | Thunderbit browser scraping (использует вашу сессию входа) |
| Booking.com / travel | ❌ 0% успешности | Полный провал | Bright Data |
Что говорят реальные пользователи: сводка по G2, Capterra и Reddit
Я собрал отзывы с трёх площадок. Вот актуальные оценки:
| Платформа | Оценка | Отзывы |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Подоценки Capterra: удобство использования — 4.9/5, поддержка — 4.6/5, функции — 4.5/5, соотношение цены и качества — 4.5/5.
Сводка по настроениям и темам
| Тема | Позитивные сигналы | Негативные сигналы |
|---|---|---|
| Простота настройки / документация | «Настраивается очень легко. Можно начать парсить за минуты.» — сообщество Latenode; оценка Ease of Use на Capterra — 4.9/5 | — |
| Прозрачность цен | «Доступный стартовый тариф» (несколько отзывов Capterra) | «Разбор кредитных затрат может сбивать с толку» — John S., Founder, Capterra (февраль 2025); «Цены выросли на 1000%, а качество ухудшилось» — CTO, Online Media, Capterra (сентябрь 2022) |
| Надёжность | «Отлично работает для Amazon/Google» (G2, Capterra) | «ScraperAPI начинает сбоить на тяжёлых задачах» — emcarter, Latenode; «80% отказов на некоторых целях» (Reddit) |
| Поддержка клиентов | «Оперативная команда» (Capterra) | Пользователь сообщил, что ему назвали одну цену, а затем выставили счёт по ставке в 5× выше без предупреждения (Reddit) |
| Долгосрочная ценность | Оплата только за успешные запросы (200/404) | «Если вы работаете на больших объёмах, расходы могут быстро вырасти», а собственная инфраструктура в долгосрочной перспективе «экономически выгоднее» — mikezhang, Latenode |
Вывод: ScraperAPI ценят за простоту первоначальной настройки и стабильную работу на популярных, хорошо поддерживаемых сайтах. Основные претензии — неожиданная цена (множители, неочевидный рост расходов) и нестабильность на более сложных целях.
Structured Data Endpoints ScraperAPI: стоят ли они премиальных кредитов?
ScraperAPI предлагает 18 structured data endpoints на 5 платформах, возвращающих уже разобранный JSON вместо сырого HTML:
- Amazon (3 endpoints): данные товара по ASIN, результаты поиска, предложения конкурентов. Возвращает 18+ полей, включая цены, рейтинги, описания, отзывы, BSR, изображения, информацию о продавце. Поддерживает 21 региональный маркетплейс.
- Google (5 endpoints): SERP (органическая выдача, knowledge graph, видео, похожие вопросы, пагинация), Shopping, Maps, News, Jobs.
- Walmart (4 endpoints): товар, поиск, категория, отзывы.
- eBay (2 endpoints): товар, поиск.
- Redfin (4 endpoints): поиск, данные агента, аренда, объекты на продажу.
SDE доступны на всех тарифах, включая Free. ScraperAPI заявляет 99.99% успешности для поддерживаемых SDE-доменов — хотя независимые бенчмарки дают более неоднозначную картину в зависимости от сайта.
Полнота данных
Amazon SDP — самое сильное предложение ScraperAPI. Оно возвращает полный набор полей: цена, отзывы, BSR, варианты, изображения, информация о продавце и многое другое. Google SERP SDP возвращает органические результаты, рекламу, featured snippets и блок People Also Ask. По полноте данных эти две платформы действительно проработаны хорошо.
Эффективность по кредитам: SDP против собственного парсинга
На тарифе Business ($299/мес., 3 млн кредитов) парсинг 10 000 товаров Amazon через SDE обойдётся в 50 000 кредитов (по 5 кредитов за каждый) — примерно на $5 от стоимости тарифа. Если строить свой парсер на стандартных запросах (по 1 кредиту каждый), это стоило бы лишь 10 000 кредитов, но пришлось бы тратить время разработчиков на создание и поддержку парсера.
Для маленьких команд без разработчиков SDE реально экономят время.
Для команд с инженерным ресурсом, которые парсят большие объёмы, 5× премия по кредитам оправдана с трудом.
Как SDP сравниваются с no-code шаблонами для скрейпинга
Этот сравнительный момент важнее, чем кажется из большинства обзоров. Thunderbit предлагает мгновенные шаблоны для Amazon, Shopify, Zillow и 50+ других сайтов, которые не требуют кода и не берут кредитов за строку для самого шаблона.
Попробовать шаблоны Thunderbit для скрейпинга в 1 клик
| Фактор | ScraperAPI SDP (Amazon) | Шаблон Thunderbit для Amazon | |---|---|---|---|---| | Время настройки | 30–60 мин (код + интеграция API) | ~2 минуты (установить расширение, открыть Amazon, нажать шаблон) | | Стоимость за 1 000 товаров (тариф Business) | ~$5 (50 000 кредитов по $0.10/кредит) | ~$16.50 (1 000 строк × 1 кредит по $0.0165/кредит на Pro) | | Возвращаемые поля | 18+ (полный набор) | Название товара, цена, рейтинг, отзывы, изображения, URL и др. | | Варианты экспорта | JSON (нужен код для разбора) | Excel, CSV, Google Sheets, Airtable, Notion — в 1 клик | | Поддержка и обслуживание | ScraperAPI поддерживает SDP | Команда Thunderbit поддерживает шаблоны | | Технические навыки | Нужны Python/Node.js | Не нужны |
Для команд разработчиков, которые массово парсят Amazon, SDP у ScraperAPI на масштабе выгоднее по цене за товар. Для бизнес-пользователей, которым нужны данные Amazon в таблице без написания кода, Thunderbit на порядок быстрее в настройке и использовании.
А нужен ли вам вообще scraping API? No-code путь, который большинство обзоров игнорирует
Многие, кто ищет «обзор Scraper API», ещё не решили, нужен ли им вообще API-ориентированный процесс. Они сначала пытаются понять, нужен ли он вообще.
И удивительно часто ответ — нет. Рынок web scraping API оценивается в $2.03 млрд и растёт на 14–18% CAGR, но этот рост в основном обеспечивают enterprise-команды разработчиков, а не менеджер по продажам, которому нужно собрать 500 лидов с сайта.
Scraping API vs no-code инструмент: рамка принятия решения в сравнении
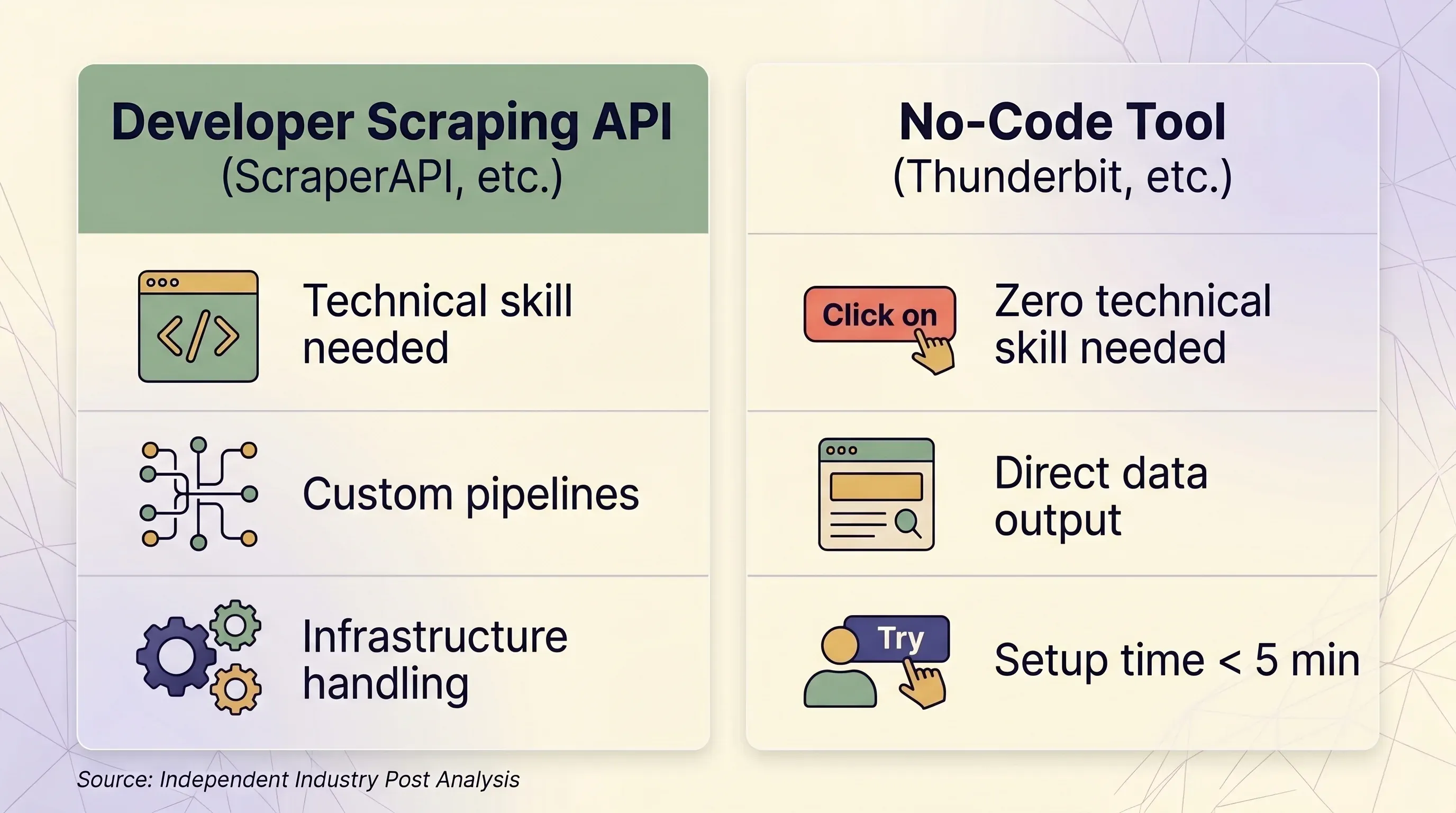
| Фактор | Scraping API (ScraperAPI и др.) | No-code инструмент (Thunderbit и др.) | |---|---|---|---|---| | Лучший сценарий | Разработчики, строящие data pipelines на масштабе | Бизнес-пользователи, маркетологи, sales-команды, исследователи | | Нужны технические навыки | Python/Node.js, HTTP, парсинг JSON | Нет — работа в браузере по клику | | Время запуска | Минимум 1–2 часа (код + тесты + отладка) | Менее 5 минут | | Обход антибота | Премиальные прокси (10–75 кредитов за запрос) | Настоящая браузерная сессия — естественный обход fingerprinting | | Сайты с логином | ❌ Запрещено условиями ScraperAPI | ✅ Browser Scraping использует вашу сессию входа | | Масштаб (страниц/день) | 100K–3M+ запросов в месяц | По запросу, обычно менее 1 000 страниц в день | | Формат данных | Сырой HTML или JSON (нужен код для разбора) | Структурированные строки/колонки — сразу готовы к работе | | Экспорт | JSON, CSV (через код) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Поддержка и обслуживание | Нужно обновлять селекторы, retry-логику, инфраструктуру | Не требуется — AI заново читает структуру страницы каждый раз | | Единица тарификации | Кредиты за запрос (переменно: 1–75 кредитов/запрос) | Кредиты за строку (1 кредит = 1 строка, 2 — для подстраниц) | | Стартовая цена | $49/мес. за 100K кредитов | $9/мес. за 5 000 кредитов (при годовой оплате) | | Бесплатный тариф | 1 000 кредитов/мес., 5 параллельных запросов | 6 страниц/мес., 30 кредитов/страница | | Предсказуемость цены | Низкая — множители создают неожиданные расходы | Высокая — 1 строка всегда = 1 кредит |
Когда scraping API действительно нужен
- У вас есть команда разработчиков или инженеров
- Нужно программно парсить 100K+ страниц в день
- Нужна глубокая настройка заголовков, сессий и логики повторов
- Ваши цели хорошо поддерживаются (Amazon, Google, Walmart, Zillow)
Когда no-code инструмент вроде Thunderbit подходит больше
- Вы работаете в sales, e-commerce ops, marketing или real estate — не в инженерии
- Нужны данные с десятков разных сайтов без написания отдельных парсеров
- Хотите прямой экспорт в Excel, Google Sheets, Airtable или Notion
- Нужно парсить сайты с логином (Thunderbit browser scraping использует вашу сессию)
- Хотите, чтобы AI перечитывал страницу заново каждый раз — без поддержки кода, когда сайт меняет дизайн
- Нужен парсинг подстраниц: Thunderbit может заходить на каждую детальную страницу и автоматически обогащать строки
Рабочий процесс Thunderbit Chrome Extension действительно простой: установите расширение, откройте нужную страницу, нажмите «AI Suggest Fields», затем «Scrape» и экспортируйте данные. AI сам определяет, какие данные есть на странице, и предлагает столбцы — не нужно писать селекторы или код. Подробнее о принципе работы читайте в нашем гайде для начинающих по веб-скрейпингу.
62% компаний в 2024 году столкнулись с перерасходом облачных затрат, а у компаний, использующих usage-based pricing без должных ограничений, на 23% выше отток клиентов из-за bill shock. Предсказуемость модели оплаты за строку стоит учитывать, если вас уже когда-то неприятно удивляли переменные API-расходы.
Попробовать AI Web Scraper от Thunderbit
Плюсы и минусы ScraperAPI в одном месте
| Плюсы | Минусы |
|---|---|
| Сильная прокси-инфраструктура (40M+ IP, 50+ стран) | Запутанная система кредитных множителей — при комбинировании функций стоимость выше суммы частей |
| Отличная документация и простая первоначальная настройка (Capterra Ease of Use: 4.9/5) | Кредиты НЕ переносятся на следующий месяц |
| Надёжно работает с Amazon, Google, Zillow, Etsy | 0% успешности на Instagram, Twitter/X, Booking.com |
| Оплата только за успешные запросы (200/404) | Ответы 404 всё равно расходуют кредиты |
| 18 structured data endpoints с выводом разобранного JSON | Сайты с логином прямо запрещены |
| Доступен на всех тарифах, включая Free | Pay-As-You-Go только на Scaling ($475/мес.) и выше |
| Политика возврата без вопросов в течение 7 дней | Принудительный кэш на 10 минут для сложных целей — риск устаревших данных |
| Рост выручки на 30–35% г/г говорит об активной разработке | DataPipeline может стоить до 6× стандартных кредитов API |
| — | Геотаргетинг за пределами США и ЕС требует Business ($299/мес.) |
| — | Нет проактивных уведомлений о расходе — нужно вручную проверять панель |
Практические советы, как выжать максимум из ScraperAPI, если вы всё же решите его использовать
Ежедневно отслеживайте расход кредитов
Панель ScraperAPI показывает статистику использования: среднюю задержку, домены, на которых выполнялся скрейпинг, и показатели параллельности. Но проактивных уведомлений о расходе нет — ни email, ни SMS, когда кредиты заканчиваются. Проверять нужно вручную. История аналитики ограничена 2 неделями на тарифах Hobby/Startup и 6 месяцами на Business+.
Поставьте себе напоминание в календаре и проверяйте панель каждый день в первый месяц. Нужно понять, как быстро сгорают кредиты именно на ваших целевых сайтах.
Начните с бесплатного тарифа, чтобы протестировать свои цели
Используйте 1 000 бесплатных кредитов (плюс 7-дневный trial на 5 000 кредитов), чтобы проверить успешность на ваших конкретных сайтах до перехода на платный тариф. Зафиксируйте, какие сайты требуют рендеринг JavaScript или premium proxy, чтобы посчитать реалистичную месячную стоимость с учётом множителей.
Не включайте премиум-функции без необходимости
ScraperAPI НЕ включает premium proxy или рендеринг JavaScript автоматически — вы должны явно указать render=true, premium=true или ultra_premium=true. Но ценообразование по домену действительно включается автоматически: Amazon всегда стоит 5 кредитов, Google — 25, LinkedIn — 30. Кредиты за обход антибота (+10 за Cloudflare, DataDome, PerimeterX) тоже добавляются автоматически при обнаружении. Учитывайте это перед запуском больших партий запросов.
Используйте structured data endpoints для поддерживаемых сайтов
Если вы парсите Amazon или Google, SDE экономят время разработки, даже если стоят больше кредитов. Для неподдерживаемых сайтов оцените, не окажется ли no-code инструмент быстрее и дешевле, чем разработка собственного парсера.
Держите запасной план для ненадёжных целей
Если успешность ScraperAPI на конкретном сайте ниже 90%, стоит направлять такие запросы через другого провайдера или использовать браузерный инструмент. Для сайтов с логином ScraperAPI просто не подойдёт — нужен инструмент вроде Thunderbit, который работает в рамках вашей браузерной сессии.
Знайте подводные камни
- Ответы 404 расходуют кредиты — ScraperAPI списывает кредиты и за 200, и за 404
- Отменённые запросы тоже тарифицируются, если вы отменили их до завершения 70-секундного окна обработки
- Принудительный 10-минутный кэш на сложных целях — возможны устаревшие данные
- Pay-As-You-Go доступен только на Scaling ($475/мес.) и выше — пользователей младших тарифов при исчерпании кредитов просто отключают
- Геотаргетинг за пределами США и ЕС требует тариф Business ($299/мес.)
Главные выводы: ScraperAPI — это ваш инструмент или нет?
Вот к чему я пришёл после всех исследований:
- ScraperAPI — хороший выбор для команд разработчиков, которые парсят большие объёмы хорошо поддерживаемых сайтов вроде Amazon, Google, Walmart и Zillow. Structured data endpoints действительно полезны, прокси-инфраструктура большая, а документация выше среднего.
- Система кредитных множителей — главный риск. Если не понимать, как складываются множители, вы почти наверняка переплатите. Разрыв между рекламируемыми кредитами и реальными запросами может составлять 5–75×. Перед покупкой обязательно просчитайте математику под свой кейс.
- Надёжность зависит от сайта. ScraperAPI отлично работает с e-commerce и недвижимостью, посредственно — с job boards и соцсетями, и полностью бесполезен для Instagram, Twitter/X и Booking.com. Не стоит ожидать одинакового качества везде.
- Для нетехнических команд ScraperAPI — не тот инструмент. Если вы в sales, marketing или operations и вам нужны структурированные данные без кода, no-code решение вроде Thunderbit даст результат буквально в два клика — с AI-определением полей, прямым экспортом в таблицы, обогащением подстраниц и без затрат на поддержку. Посмотрите расширение Thunderbit для Chrome или обучающие видео на YouTube-канале Thunderbit.
- Для разработчиков с ограниченным бюджетом сначала протестируйте бесплатный тариф ScraperAPI на ваших целевых сайтах, а затем сравните эффективную стоимость за запрос с ScrapingBee, Scrapfly и Bright Data. Самый дешёвый вариант зависит исключительно от вашего сценария и требований к функциям.
Хотите увидеть, как эти цифры выглядят именно для ваших задач по скрейпингу? Начните с бесплатного тарифа ScraperAPI, чтобы протестировать свои сайты, или установите Thunderbit, чтобы понять, насколько далеко могут завести два клика. Подробнее о ценах — в наших тарифах.
FAQ
ScraperAPI бесплатный?
Да, у ScraperAPI есть бесплатный тариф с 1 000 API-кредитов в месяц и 7-дневный trial на 5 000 кредитов. Однако кредитные множители для рендеринга JavaScript, premium proxy или дорогих доменов (Amazon = 5×, Google = 25×, LinkedIn = 30×) означают, что реальная ёмкость может быть намного ниже 1 000 запросов. На бесплатном тарифе ultra-premium proxy недоступны.
Сколько стоит ScraperAPI за один запрос?
Это сильно зависит от флагов функций и целевого домена. Стандартный запрос к простому HTML-сайту стоит 1 кредит. Запрос к Amazon — 5 кредитов. Запрос к Google SERP — 25 кредитов. Добавление рендеринга JavaScript увеличивает стоимость на 10 кредитов. Комбинация ultra-premium proxy и рендеринга JavaScript стоит 75 кредитов за запрос. На тарифе Hobby ($49/мес., 100K кредитов) это примерно от $0.00049 за запрос (стандартный) до $0.0368 за запрос (ultra-premium + JS). Подробные таблицы выше дают полную картину.
Подходит ли ScraperAPI для Amazon?
Amazon Structured Data endpoint у ScraperAPI — одна из его сильнейших функций, с 98% успешности в независимых бенчмарках и полным разобранным JSON-выводом (18+ полей). Но каждый запрос к Amazon стоит минимум 5 кредитов, поэтому на масштабе расходы быстро растут. Для небольших команд, которым нужны данные Amazon в таблице без кода, шаблон Thunderbit для Amazon предлагает альтернативу в 1 клик с прямым экспортом.
Какие лучшие альтернативы ScraperAPI?
Для разработчиков: ScrapingBee (самый дешёвый для базового HTML), Scrapfly (хорош для рендеринга JavaScript), Bright Data (лучший для защищённых сайтов — фиксированная цена независимо от рендеринга) и ZenRows. Для нетехнических пользователей: Thunderbit — no-code AI-расширение для Chrome с прямым экспортом в Excel, Google Sheets, Airtable и Notion. Смотрите наше сравнение лучших AI web scraper для более глубокого анализа.
Может ли ScraperAPI парсить сайты с логином?
ScraperAPI поддерживает сохранение сессии через параметр session_number (тот же IP для нескольких запросов), но прямо запрещает парсинг данных за логином. Он не умеет работать с заполнением форм, двухфакторной аутентификацией и сложными цепочками авторизации. Для сайтов с логином надёжнее использовать браузерные инструменты, такие как Thunderbit, которые используют вашу существующую браузерную сессию для доступа к видимому контенту.
Подробнее




