

Если вы когда-либо пытались собрать целевой список для продаж, изучить новые рынки или сравнить конкурентов, вы знаете, что Google Maps — это настоящая золотая жила. Но вот главный аргумент: более 1,5 миллиарда поисков «рядом со мной» каждый месяц и 76% пользователей локального поиска посещают бизнес в течение 24 часов (thinkwithgoogle.com) — спрос на актуальные данные о компаниях, привязанных к локации, никогда не был таким высоким.
Независимо от того, работаете ли вы в продажах, маркетинге или операционной деятельности, извлечение структурированных данных из Google Maps может решить, будет ли ваш звонок холодным или превратится в тёплый лид с высокой конверсией.
Я много лет работаю в SaaS и автоматизации и своими глазами видел, как команды используют Python (а теперь и инструменты на базе ИИ, такие как Thunderbit), чтобы превратить Google Maps в стратегический актив.
В этом руководстве я пошагово разберу, как в 2026 году собирать данные Google Maps с помощью Python — с кодом, советами по соблюдению правил и сравнением с no-code-решениями. Если вы опытный Python-разработчик или просто хотите получить рабочие данные как можно быстрее, вы по адресу.
Что значит собирать данные Google Maps с помощью Python?
Начнём с основ: сбор данных Google Maps с помощью Python — это программное извлечение информации о компаниях, такой как названия, адреса, рейтинги, отзывы, номера телефонов и координаты, чтобы потом анализировать, фильтровать и выгружать её для бизнеса.

Сделать это можно двумя основными способами:
- Google Maps Places API: официальный и лицензированный способ. Вы используете API-ключ, отправляете запросы к серверам Google и получаете структурированные JSON-данные. Это стабильно, предсказуемо и в целом соответствует правилам, но есть квоты и стоимость.
- Веб-скрейпинг HTML: вы автоматизируете браузер с помощью инструментов вроде Playwright или Selenium, загружаете Google Maps, выполняете поиск и разбираете отрендеренную страницу. Это гибче, но хрупко: Google часто меняет структуру сайта, а сбор HTML может нарушать условия использования Google.
Типичные поля данных, которые можно извлечь:
- Название компании
- Категория/тип
- Полный адрес (плюс город, штат, почтовый индекс, страна)
- Широта и долгота
- Номер телефона
- URL сайта
- Рейтинг и количество отзывов
- Уровень цен
- Статус компании (открыто/закрыто)
- Часы работы
- Place ID (уникальный идентификатор Google)
- URL Google Maps
Почему это важно? Потому что эти поля лежат в основе всего: от лидогенерации и планирования территорий до анализа конкурентов и исследования рынка. Главное — извлекать именно те данные, которые нужны вашему бизнесу, а не собирать всё подряд.
Почему команды продаж и маркетинга извлекают данные из Google Maps с помощью Python
Перейдём к практике. Почему в 2026 году так много команд продаж и маркетинга одержимы данными Google Maps?
- Лидогенерация: создавайте сверхточные списки локальных компаний с контактами и рейтингами для outreach-кампаний.
- Планирование территорий: разбивайте зоны продаж, доставки или обслуживания на основе реальной плотности и типов бизнеса.
- Мониторинг конкурентов: отслеживайте расположение, рейтинги и отзывы конкурентов во времени, чтобы находить тренды и возможности.
- Исследование рынка: анализируйте категории бизнеса, часы работы и тональность отзывов, чтобы принимать решения по выходу на рынок.
- Выбор локации: в недвижимости и ритейле оценивайте потенциальные точки по близлежащей инфраструктуре, пешеходному трафику и конкуренции.
Реальное влияние: согласно HubSpot 2025 State of Sales, 92% отделов продаж планируют увеличивать инвестиции в ИИ и данные, а команды, использующие таргетированные локальные данные, показывают конверсию до 8 раз выше, чем те, кто полагается на обычные холодные списки (martal.ca). Одно исследование по лидогенерации для франшиз показало $15 новой выручки на каждый $1, потраченный на списки лидов на основе Google Maps.
Как связать бизнес-цели с полями Google Maps:
| Бизнес-цель | Нужные поля Google Maps |
|---|---|
| Локальный список лидов | name, address, phone, website, category |
| Планирование территорий | name, lat/lng, business_status, opening_hours |
| Бенчмаркинг конкурентов | name, rating, userRatingCount, priceLevel, reviews |
| Выбор локации | category, lat/lng, review density, openingDate |
| Анализ тональности/меню | reviews, editorialSummary, photos, types |
| Outreach по email/телефону | nationalPhoneNumber, websiteUri (затем при необходимости обогащайте) |
Настройка Python-скрейпера для Google Maps: инструменты и требования
Прежде чем начать сбор данных, нужно настроить Python-среду и подготовить нужные инструменты. Вот что потребуется в 2026 году:
1. Установите Python и нужные библиотеки
Рекомендуемая версия Python: 3.10 или новее.
Установите ключевые библиотеки:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
Что они делают:
requests,httpx: HTTP-запросы (вызовы API)beautifulsoup4,lxml: разбор HTML (для веб-скрейпинга)pandas: очистка, анализ и экспорт данныхselenium,playwright: автоматизация браузера (для HTML-скрейпинга)googlemaps,google-maps-places: клиенты Google Maps APIschedule,APScheduler: планирование задачpython-dotenv: безопасная загрузка API-ключей из файлов.envtenacity: повторные попытки и обработка ошибок
2. Получите API-ключ Google Maps (для скрейпинга через API)
- Перейдите в Google Cloud Console.
- Создайте проект или выберите существующий.
- Включите биллинг (это требуется даже для бесплатного уровня).
- Включите “Places API (New)” в разделе APIs & Services > Library.
- Перейдите в Credentials > Create Credentials > API Key.
- Ограничьте ключ нужными API и IP-адресами для безопасности.
- Сохраните API-ключ в файле
.env(никогда не добавляйте его в код):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
Примечание: по состоянию на март 2025 года Google больше не предоставляет универсальный кредит $200 в месяц. Вместо этого для каждого API-уровня действуют бесплатные ежемесячные пороги (см. официальные цены).
Как извлекать данные из Google Maps с помощью Python: пошаговое руководство
Разберём оба основных подхода — через API и через HTML-скрейпинг — чтобы вы могли выбрать подходящий вариант.
Подход 1: использование Google Maps Places API (рекомендуется)
Шаг 1: установите и импортируйте нужные библиотеки
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
Шаг 2: безопасно загрузите API-ключ
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
Шаг 3: сформируйте поисковый запрос
Для поиска компаний, подходящих под ваши критерии, вы будете использовать endpoint Text Search.
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
Шаг 4: отправьте API-запрос
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # фильтр на стороне сервера
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # Всегда указывайте это!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
Шаг 5: обработайте пагинацию и соберите результаты
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
Шаг 6: экспортируйте данные с помощью Pandas
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
Полезные советы:
- Всегда задавайте заголовок
X-Goog-FieldMask, чтобы контролировать расходы. Если запрашивать отзывы или фотографии, цена за 1 000 запросов может вырасти с $5 до $25 (подробности о ценах). - Используйте фильтры на стороне сервера, например
minRating,includedType,locationBias, чтобы не тратить кредиты на нерелевантные результаты. - Кэшируйте значения
place_idдля дедупликации и будущих обновлений.
Подход 2: веб-скрейпинг HTML Google Maps (для учебных целей или разовых задач)
Предупреждение: Google Maps — это одностраничное приложение. Вам понадобится автоматизация браузера (Playwright или Selenium), а сбор HTML может нарушать условия Google. Используйте этот способ для исследований, а не для продакшена.
Шаг 1: установите Playwright и запустите браузер
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
Советы:
- Google случайным образом меняет CSS-классы каждые несколько недель, поэтому этот код может требовать регулярного обновления.
- Используйте человеческие задержки и не скрейпьте слишком быстро, чтобы снизить риск блокировки.
- Никогда не пытайтесь обходить CAPTCHA или систему SearchGuard Google — это может привести к юридическим рискам.
Не скрейпите вслепую: как точно нацелиться на нужные данные
Собирать всё подряд — верный способ потратить время и получить раздутый датасет. Вот как извлекать только действительно важные данные:
- Генерируйте целевые списки URL: используйте собственные фильтры поиска Google Maps (категория, локация, рейтинг, открыто сейчас), чтобы сузить результаты до скрейпинга.
- Используйте поиск по фразе: ищите точные типы бизнеса или ключевые слова, например “vegan bakery in Austin”.
- Фильтры по локации: указывайте город, район или даже координаты и радиус для точности.
- Фильтрация на стороне сервера (API): используйте
minRating,includedTypeиlocationBiasв теле запроса к API. - Фильтрация на стороне клиента (Python): после сбора данных используйте pandas, чтобы оставить компании с рейтингом выше 4.0, более чем 50 отзывами или определёнными категориями.
Пример: оставить только рестораны на Манхэттене с рейтингом выше 4.0
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
Как с помощью библиотек Python организовать и экспортировать данные Google Maps
Когда данные собраны, пора очистить их, проанализировать и передать команде.
Очистка и структурирование данных с помощью Pandas
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
Анализ и сводка данных
Пример: средний рейтинг по районам
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
Экспорт в Excel или CSV
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")
Большой датасет? Используйте формат Parquet для скорости и экономии места:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: альтернатива Python-скрейперу Google Maps на базе ИИ
Если вы думаете: «Для простого списка лидов это слишком много настройки», вы не одиноки. Именно поэтому мы создали Thunderbit — no-code веб-скрейпер на базе ИИ, который позволяет извлекать данные из Google Maps (и не только) буквально за пару кликов.
Почему Thunderbit?
- Не нужен код и API-ключи: просто откройте расширение Thunderbit для Chrome, перейдите в Google Maps и нажмите “AI Suggest Fields”.
- Определение полей с помощью ИИ: ИИ Thunderbit читает страницу и предлагает нужные столбцы — название, адрес, рейтинг, телефон, сайт и многое другое.
- Сбор со вложенных страниц: хотите обогатить таблицу данными с сайта каждой компании? Thunderbit может автоматически заходить на вложенные страницы и подтягивать дополнительные сведения.
- Экспорт в Excel, Google Sheets, Airtable или Notion: больше не нужно возиться с pandas — просто нажмите “Export”, и данные готовы для команды.
- Планируемый сбор: настройте повторяющиеся задачи, чтобы отслеживать конкурентов или автоматически обновлять список лидов.
- Никакого обслуживания: ИИ Thunderbit адаптируется к изменениям сайта, так что вам не придётся постоянно чинить сломанные скрипты.
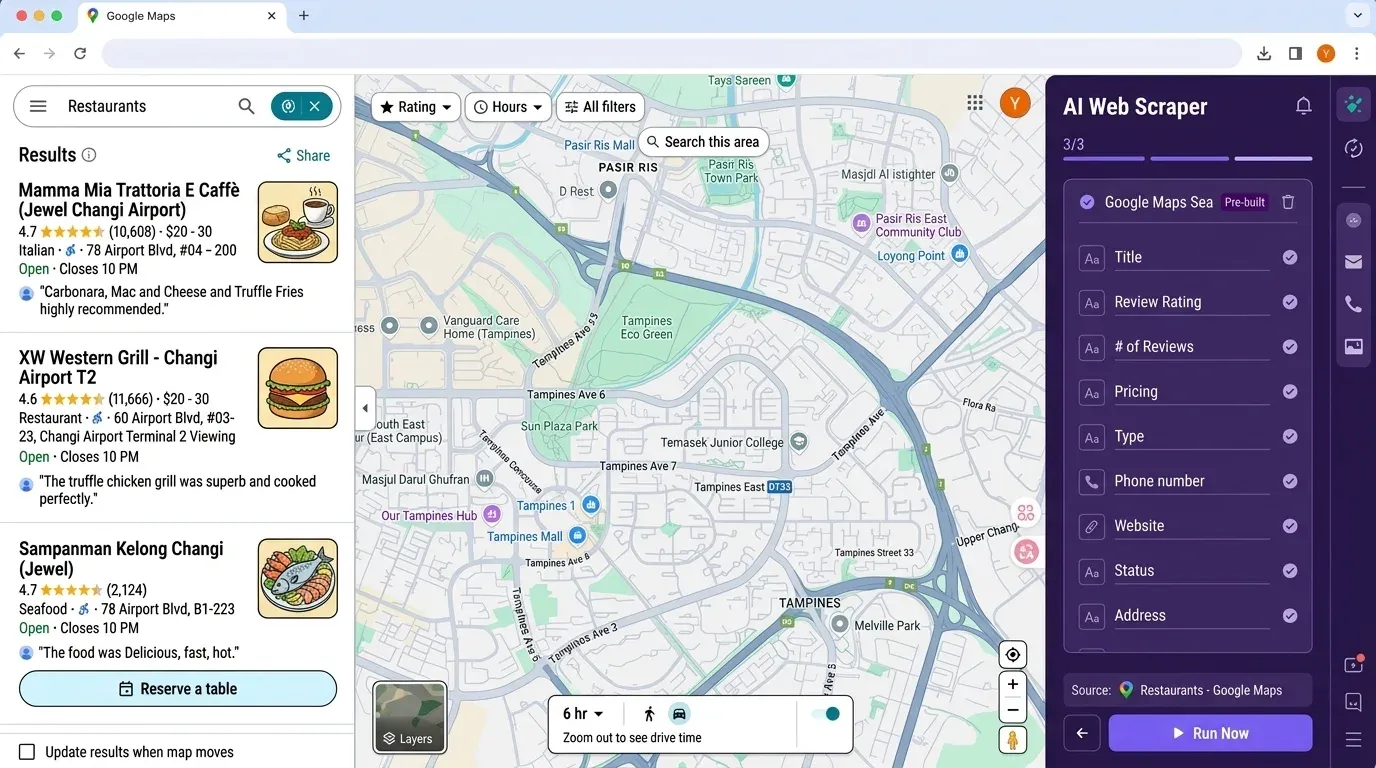
Сравнение рабочего процесса Thunderbit и Python:
| Шаг | Python-скрейпер | Thunderbit |
|---|---|---|
| Установка инструментов | 30–60 мин (Python, pip, библиотеки) | 2 мин (расширение Chrome) |
| Настройка API-ключа | 10–30 мин (Cloud Console) | Не требуется |
| Выбор полей | Ручной код, field masks | AI Suggest Fields (1 клик) |
| Извлечение данных | Написать/запустить скрипт, обработать ошибки | Нажать “Scrape” |
| Экспорт | pandas в CSV/Excel | Экспорт в Excel/Sheets/Notion |
| Поддержка | Ручные обновления при изменениях сайта | ИИ автоматически адаптируется |
Бонус: Thunderbit доверяют более 30 000 пользователей по всему миру, а бесплатный тариф позволяет без оплаты собирать до 6 страниц (или 10 с пробным бустом).
Соблюдение правил: условия использования Google Maps и этика скрейпинга
Вот где большинство Python-руководств уже опасно устарели. Что нужно знать в 2026 году:
- Google Maps Platform ToS §3.2.3 строго запрещает скрейпинг, кэширование или экспорт данных вне официальных API (cloud.google.com). Единственное исключение: координаты широты/долготы можно кэшировать до 30 дней; Place IDs можно хранить бессрочно.
- Пользователи API связаны договором: если вы используете API-ключ, значит согласились с условиями Google — даже если собираете только публичные данные.
- Обход технических барьеров (CAPTCHA, SearchGuard) теперь может считаться нарушением DMCA §1201, что влечёт уголовную ответственность (ppc.land).
- GDPR и законы о конфиденциальности: если вы собираете персональные данные (emails, телефоны, имена авторов отзывов) из Google Maps, у вас должно быть законное основание, и вы обязаны выполнять запросы на удаление. Французский CNIL оштрафовал KASPR на €200 000 в 2024 году за сбор контактов LinkedIn (edpb.europa.eu).
- Лучшие практики:
- По возможности по умолчанию используйте Places API.
- Ограничивайте частоту запросов (≤10 QPS для API, 1–2 запроса/с для HTML-скрейпинга).
- Никогда не обходите CAPTCHA или технические блокировки.
- Не распространяйте собранные персональные данные.
- Соблюдайте запросы на отказ и удаление данных.
- Всегда проверяйте местные законы — GDPR, CCPA и другие реально применяются.
Итог: если для вас важна комплаенс-безопасность, оставайтесь на API и минимизируйте объём собираемых данных. Для большинства бизнес-пользователей no-code-инструмент вроде Thunderbit снижает риски (не нужен API-ключ, нет перепубликации данных).
Планирование и автоматизация сбора данных Google Maps с помощью Python
Если вам нужно поддерживать данные в актуальном состоянии — например, для еженедельного мониторинга конкурентов или ежемесячного обновления списка лидов — автоматизация станет вашим лучшим другом.
Простое планирование с schedule
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
Планирование уровня production с APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # 3:15 утра ± 10 мин
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
Советы по безопасной автоматизации
- Добавляйте случайный jitter в расписание, чтобы не создавать предсказуемый шаблон.
- Для HTML-скрейпинга не превышайте 1–2 запроса в секунду.
- При использовании API следите за квотой и настройте оповещения по биллингу.
- Всегда логируйте ошибки и ведите файл «dead-letter» для неудачных запросов.
Бонус Thunderbit: с Thunderbit можно настраивать повторяющиеся сборы прямо в интерфейсе — без кода, cron-задач и настройки сервера.
Главные выводы: эффективный, точный и соответствующий правилам сбор данных Google Maps
Подведём итоги:
- Google Maps — источник №1 для данных о бизнес-локациях, который питает всё: от лидогенерации до исследования рынка.
- Сбор через Python даёт гибкость и контроль, но требует настройки, поддержки и соблюдения правил — особенно по мере усиления антибот-защиты Google и правоприменения.
- Извлечение через API — самый безопасный и масштабируемый путь для большинства команд. Всегда используйте field masks и фильтры на стороне сервера, чтобы контролировать расходы.
- HTML-скрейпинг хрупок и рискован — используйте его только для разовых исследований и никогда не обходите технические ограничения.
- Нацеливайте сбор данных: используйте поиск по фразе, фильтры по локации и рабочие процессы на pandas, чтобы извлекать только необходимое.
- Thunderbit — самый быстрый путь для тех, кто не пишет код: ИИ, без настройки, мгновенный экспорт и встроенное планирование.
- Комплаенс важен: соблюдайте условия Google, законы о конфиденциальности и лимиты запросов, чтобы избежать юридических проблем.
Больше руководств и советов ищите в блоге Thunderbit и на нашем канале YouTube.
FAQ
1. Законно ли в 2026 году собирать данные Google Maps с помощью Python?
Сбор данных Google Maps через официальный API разрешён в рамках условий Google, если вы соблюдаете квоты и не распространяете ограниченные данные. HTML-скрейпинг Google Maps прямо запрещён условиями Google и несёт юридические риски, особенно если вы обходите технические ограничения или собираете персональные данные без согласия. Всегда проверяйте местные законы (GDPR, CCPA и т. д.) и придерживайтесь лучших практик комплаенса.
2. В чём разница между использованием Google Maps API и веб-скрейпингом HTML?
API стабилен, лицензирован и предназначен для извлечения данных, но требует API-ключа и подчиняется квотам и оплате. HTML-скрейпинг использует автоматизацию браузера для извлечения данных с отрендеренной страницы, но он хрупкий (сайт часто меняется), может нарушать условия и несёт более высокий юридический риск. Для большинства бизнес-задач рекомендован именно API.
3. Сколько стоит извлечение данных из Google Maps с помощью Python в 2026 году?
Цены Google Places API рассчитываются за 1 000 запросов и зависят от запрашиваемых полей: от $5 (Essentials) до $25 (Enterprise+Atmosphere). Есть бесплатные ежемесячные пороги (10 000 для Essentials, 5 000 для Pro, 1 000 для Enterprise), но при больших объёмах затраты быстро растут. Всегда используйте field masks и фильтры на стороне сервера, чтобы контролировать расходы.
4. Чем Thunderbit отличается от Python-скрейперов для Google Maps?
Thunderbit — это no-code веб-скрейпер на базе ИИ, который позволяет извлекать данные Google Maps (и не только) без программирования, API-ключей и постоянной поддержки. Он идеально подходит для отделов продаж и маркетинга, которым нужен быстрый и надёжный экспорт в Excel, Google Sheets, Airtable или Notion. Для технических пользователей, которым нужна кастомная логика, Python даёт больше гибкости, но требует больше настройки и управления комплаенсом.
5. Как автоматизировать регулярное извлечение данных Google Maps?
В Python используйте библиотеки планирования вроде schedule или APScheduler, чтобы запускать скрейпер по расписанию — ежедневно, еженедельно и т. д. Добавляйте случайный jitter, чтобы избежать обнаружения, и следите за квотой API. С Thunderbit можно настраивать повторяющиеся сборы прямо в интерфейсе — без кода и без настройки сервера.
Готовы превратить Google Maps в суперсилу для продаж и маркетинга? Независимо от того, любите ли вы Python или хотите самое быстрое no-code-решение, все инструменты уже доступны в 2026 году. Попробуйте Thunderbit для мгновенного ИИ-скрейпинга — или засучите рукава и погрузитесь в API. В любом случае пусть ваши списки лидов будут свежими, выгрузки — чистыми, а кампании — полными локальных клиентов с высокой вероятностью конверсии. Удачного скрейпинга!
Подробнее
- Учебник по веб-скрейпингу на Python: как извлечь данные с сайта
- Как использовать BeautifulSoup: учебник по веб-скрейпингу на Python
- Учебник по веб-скрейпингу на Python: как собирать данные с сайта
- Как эффективно собирать данные с сайта с помощью Python
- Как написать веб-скрейпер на Python: от начала до конца




