

Большинство руководств по парсингу eBay живут примерно три месяца. Я знаю это не понаслышке: команда Thunderbit не раз наблюдала, как разработчики перебирают сломанные фрагменты кода, устаревшие CSS-селекторы и «рабочие» GitHub-репозитории, которые перестали работать ещё после второго редизайна eBay.
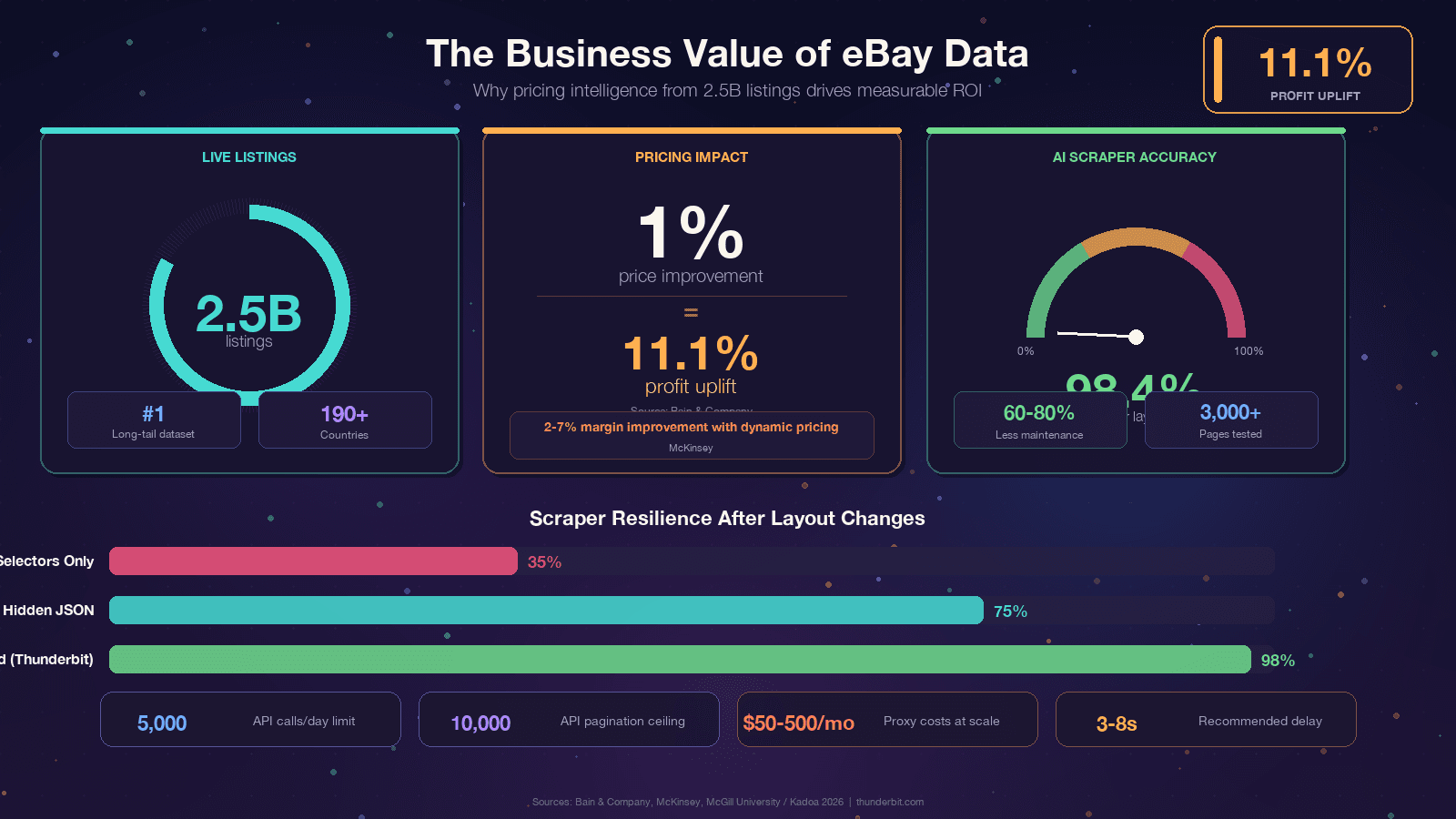
eBay хранит около 2,5 млрд активных объявлений — это крупнейшая общедоступная long-tail база цен в открытом интернете после Amazon. Эти данные лежат в основе всего: от ценообразования для реселлеров до конкурентной разведки. Но получить их программно — задача не из простых: React-фронтенд eBay постоянно меняет CSS-классы, A/B-тесты показывают разным пользователям разную структуру DOM, а между вами и HTML стоит Akamai Bot Manager. В этом руководстве вы получите Python-код, который работает сегодня, поймёте, почему ломаются парсеры и как строить устойчивые решения, разберётесь в честном сравнении eBay API и парсинга, а также увидите no-code альтернативу на случай, если Python не стоит таких усилий.
Что значит парсить eBay на Python?
Парсинг eBay на Python — это написание скриптов, которые автоматически загружают страницы eBay, разбирают HTML (или скрытый JSON) и извлекают структурированные данные — заголовки, цены, информацию о продавце, даты продаж, варианты товара — в удобный формат, например CSV, таблицу или базу данных.
На eBay можно парсить несколько типов страниц:
- Страницы результатов поиска (например, все объявления по запросу «AirPods Pro»)
- Страницы товаров (полные характеристики, изображения, данные продавца)
- Проданные / завершённые объявления (реальные цены и даты сделок)
- Профили продавцов и отзывы
Для этой задачи Python — язык по умолчанию. Его экосистема — Requests, BeautifulSoup, lxml, pandas — позволяет легко скачивать страницы, разбирать HTML и преобразовывать данные. Но важно понимать разницу между парсингом HTML сайта и использованием официального API eBay — об этом поговорим дальше.
Зачем парсить eBay? Реальные кейсы для бизнеса
Если вы читаете эту статью, у вас, скорее всего, уже есть своя причина. Но полезно опираться на конкретную бизнес-ценность, потому что ROI данных eBay действительно впечатляет. Bain выяснила, что улучшение реализованной цены всего на 1% даёт рост прибыли на 11,1% для тысяч компаний. McKinsey связывает динамическое ценообразование в ритейле с ростом продаж до 5% и улучшением маржи на 2–7%.
Чаще всего eBay используют для таких задач:
| Сценарий | Какие данные нужны | Бизнес-результат |
|---|---|---|
| Мониторинг цен и репрайсинг | Активные цены, доставка, состояние товара | Конкурентное ценообразование, защита маржи |
| Анализ конкурентов | Ассортимент, акции, условия доставки | Стратегическое позиционирование, поиск пробелов в ассортименте |
| Исследование рынка и трендов | Скорость появления объявлений, тренды категорий, спрос | Поиск новых товаров, прогнозирование спроса |
| Реселлерское ценообразование / оценка | Цены продаж, даты продаж, состояние товара | Рыночная стоимость, решение по покупке |
| Анализ отзывов и настроений | Отзывы, рейтинги, политика возврата | Понимание качества товара и удовлетворённости клиентов |
| Лидогенерация | Профили продавцов, данные магазина, контактная информация | B2B-выход на продавцов с высоким GMV |
Общий знаменатель один: данные в eBay есть, но они заперты внутри веб-страниц.
Парсинг — это способ превратить их в конкурентное преимущество.
Официальный API eBay или Python-парсинг: что выбрать?
Это тот вопрос, на который я хотел бы чаще видеть честный ответ в руководствах. У eBay есть официальные API — в первую очередь Browse API — и многие пользователи не понимают, что лучше: API или прямой парсинг. Ответ зависит только от того, какие данные вам нужны.
| Критерий | eBay Browse/Finding API | Парсинг eBay на Python |
|---|---|---|
| Проданные / завершённые объявления | Ограниченно — Marketplace Insights API существует, но доступ часто отклоняют | Полный доступ через параметры URL LH_Sold=1&LH_Complete=1 |
| Лимиты запросов | 5 000 запросов в день на базовом тарифе | Управляется вами самостоятельно (зависит от прокси) |
| Поля данных | Заранее определённые (название, цена, категория, базовые данные продавца) | Всё, что видно на странице (отзывы, полные характеристики, матрица вариантов) |
| Сложность настройки | OAuth 2.0, регистрация приложения, API-ключи | pip install + код |
| Стабильность | Стабильные эндпоинты | Ломается при изменении HTML |
| Стоимость | Есть бесплатный тариф, платно при больших объёмах | Код бесплатный, но на масштабе нужны прокси |
| Данные по вариантам/MSKU | Частично — во многих случаях только родительский SKU | Полные данные (через разбор скрытого JSON) |
| Глубина пагинации | Жёсткий предел в 10 000 товаров | Теоретически без ограничений |
Короткое уточнение: старый Finding API (включая findCompletedItems) полностью отключили в феврале 2025 года. Если вы используете ebaysdk-python или любую библиотеку, которая обращается к Finding module, в продакшене она сейчас сломана.
Моя рекомендация: используйте Browse API для стабильных, умеренных по объёму структурированных запросов по активным объявлениям. Используйте парсинг Python, когда вам нужны цены продаж, отзывы, данные по вариантам или любые поля, которых нет в API. Многие команды совмещают оба подхода.
Какие инструменты и библиотеки нужны для парсинга eBay на Python
Прежде чем писать код, соберём стек. Для большинства страниц eBay вам не нужен headless-браузер — данные уже встроены в HTML, который отдаёт сервер.
| Библиотека | Назначение |
|---|---|
requests или httpx | HTTP-клиент для загрузки страниц eBay |
curl_cffi | HTTP-клиент с TLS-фингерпринтом как у реального браузера (критично для обхода Akamai) |
beautifulsoup4 | HTML-парсер для извлечения через CSS-селекторы |
lxml | Быстрый backend-парсер для BeautifulSoup |
jmespath | Язык запросов для разбора вложенного JSON |
pandas | Обработка данных и экспорт в CSV/Excel |
gspread | Интеграция с Google Sheets |
Установите всё одной командой:
pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread
Используйте Python 3.11+ — pandas 3.0 требует 3.10+, а 3.11 даёт прирост скорости 10–60% на I/O-зависимых задачах.
Отдельно стоит выделить curl_cffi: это, пожалуй, самое полезное улучшение, которое может сделать eBay-скрейпер в 2026 году. eBay использует Akamai Bot Manager, а основной способ обнаружения у Akamai — TLS-фингерпринт. Обычный requests отправляет JA3-подпись, характерную для Python, и мгновенно попадает под фильтр. curl_cffi имитирует TLS-рукопожатие настоящего Chrome, что помогает обходить примерно 90% защищённых Akamai-целей без headless-браузера.
Попробовать Thunderbit для любого сайта
Пошагово: как парсить результаты поиска eBay на Python
Это основное руководство. Мы будем парсить страницы результатов поиска eBay и извлекать карточки товаров.
- Сложность: начальный–средний уровень
- Время: около 30 минут до первого рабочего парсинга
- Что понадобится: Python 3.11+, библиотеки выше, терминал и URL поиска на eBay
Шаг 1: Подготовьте Python-проект
Создайте папку проекта и установите зависимости:
mkdir ebay-scraper && cd ebay-scraper
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install requests curl_cffi beautifulsoup4 lxml pandas
Создайте файл scrape_ebay.py. Это будет ваша рабочая область.
Шаг 2: Сформируйте URL поиска eBay
Структура поискового URL у eBay довольно простая. Главный параметр — _nkw (ключевое слово):
import urllib.parse
keyword = "airpods pro"
base_url = "https://www.ebay.com/sch/i.html"
params = {
"_nkw": keyword,
"_ipg": "120", # товаров на странице: 60, 120 или 240 (240 может вызвать подозрение у антибота)
"_pgn": "1", # номер страницы
}
url = f"{base_url}?{urllib.parse.urlencode(params)}"
print(url)
# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1
Другие полезные параметры:
LH_BIN=1— только Buy It Now_sacat=175673— конкретная категория_sop=12— сортировка по best match (10 = самая низкая цена+доставка, 13 = недавно добавленные)LH_Complete=1&LH_Sold=1— проданные / завершённые объявления (об этом ниже есть отдельный раздел)
Шаг 3: Отправьте запрос и обработайте ответ
Здесь curl_cffi действительно оправдывает себя. Обычный requests.get() часто возвращает 403 от Akamai. С curl_cffi мы имитируем реальный Chrome-браузер:
from curl_cffi import requests as cffi_requests
import random, time
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
]
HEADERS = {
"User-Agent": random.choice(USER_AGENTS),
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
}
def fetch_page(url, max_retries=5):
delay = 2
for attempt in range(max_retries):
try:
r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
if r.status_code == 200:
return r.text
if r.status_code in (403, 429, 503):
retry_after = r.headers.get("Retry-After")
sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
print(f" Статус {r.status_code}, повтор через {sleep_for:.1f} сек...")
time.sleep(sleep_for)
delay *= 2
continue
r.raise_for_status()
except Exception as e:
print(f" Ошибка запроса: {e}, повторяем...")
time.sleep(delay)
delay *= 2
raise RuntimeError(f"Не удалось получить страницу после {max_retries} попыток: {url}")
Экспоненциальная задержка с разбросом по времени важна — фиксированные интервалы сами по себе являются бот-фингерпринтом.
Шаг 4: Разберите карточки товаров на странице поиска
Сейчас eBay находится в процессе миграции между двумя макетами страниц результатов. Устойчивый парсер должен уметь работать с обоими:
| Поле | Старый макет | Новый макет |
|---|---|---|
| Контейнер карточки | li.s-item | li.s-card или div.su-card-container |
| Заголовок | .s-item__title | .s-card__title |
| Ссылка | a.s-item__link[href] | a.su-link[href] |
| Цена | span.s-item__price | .s-card__price |
Код разбора, который поддерживает оба варианта:
from bs4 import BeautifulSoup
def parse_search_results(html):
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item, li.s-card, div.su-card-container")
results = []
for card in cards:
# Заголовок — пробуем оба макета
title_el = card.select_one(".s-item__title, .s-card__title")
title = title_el.get_text(strip=True) if title_el else None
# Пропускаем фальшивую карточку-заглушку «Shop on eBay»
if not title or "Shop on eBay" in title:
continue
# Цена
price_el = card.select_one("span.s-item__price, .s-card__price")
price = price_el.get_text(strip=True) if price_el else None
# URL
link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
url = link_el["href"].split("?")[0] if link_el else None
# Изображение
img_el = card.select_one("img.s-item__image-img, .s-card__image img")
image = None
if img_el:
image = img_el.get("src") or img_el.get("data-src")
# Доставка
ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
shipping = ship_el.get_text(strip=True) if ship_el else None
results.append({
"title": title,
"price": price,
"url": url,
"image": image,
"shipping": shipping,
})
return results
Ловушка с первой карточкой — классическая ошибка. Первый li.s-item на многих страницах поиска eBay — это скрытая заглушка с заголовком «Shop on eBay» и без реальной цены. Обязательно фильтруйте её.
Шаг 5: Обработайте пагинацию и соберите несколько страниц
eBay использует параметр _pgn для пагинации. Ссылка на следующую страницу обычно имеет вид a.pagination__next:
import urllib.parse
def scrape_ebay_search(keyword, max_pages=5):
all_results = []
for page_num in range(1, max_pages + 1):
params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Парсим страницу {page_num}: {url}")
html = fetch_page(url)
results = parse_search_results(html)
if not results:
print(f" На странице {page_num} нет результатов, останавливаемся.")
break
all_results.extend(results)
print(f" Найдено {len(results)} объявлений (всего: {len(all_results)})")
# Вежливая пауза — 3–8 секунд со случайным разбросом
time.sleep(random.uniform(3, 8))
return all_results
Случайная пауза 3–8 секунд — не опция, а необходимость.
eBay и Akamai отслеживают устойчивый поток запросов выше 1 req/s с одного IP.
Шаг 6: Экспортируйте данные в CSV или JSON
import pandas as pd
results = scrape_ebay_search("airpods pro", max_pages=3)
df = pd.DataFrame(results)
df.to_csv("ebay_airpods.csv", index=False)
df.to_json("ebay_airpods.json", orient="records", indent=2)
print(f"Экспортировано {len(df)} объявлений в CSV и JSON.")
Теперь у вас должна быть аккуратная таблица с объявлениями eBay. На моей машине парсинг 3 страниц (360 объявлений) занял около 45 секунд с учётом задержек.
Как парсить страницы товаров eBay на Python
Поиск даёт сводку. А страницы товара содержат самое ценное: полное описание, рейтинг продавца, характеристики товара, карусели изображений и данные по вариантам.
Разбор страницы конкретного объявления
Страницы товаров eBay находятся по адресу /itm/<ITEM_ID>. Самый надёжный способ извлечения данных — JSON-LD: eBay вставляет блок схемы Product, который переживает почти любые изменения CSS:
import json
def parse_item_page(html):
soup = BeautifulSoup(html, "lxml")
item = {}
# 1. JSON-LD — самый стабильный способ извлечения
for tag in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(tag.string or "")
except (json.JSONDecodeError, TypeError):
continue
if isinstance(data, dict) and data.get("@type") == "Product":
item["title"] = data.get("name")
item["brand"] = (data.get("brand") or {}).get("name")
item["images"] = data.get("image")
offers = data.get("offers") or {}
item["price"] = offers.get("price")
item["currency"] = offers.get("priceCurrency")
break
# 2. CSS-резервные селекторы для полей, которых нет в JSON-LD
def first_text(selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
item.setdefault("title", first_text([
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
]))
item["condition"] = first_text([
".x-item-condition-text .ux-textspans",
])
item["seller"] = first_text([
".x-sellercard-atf__info__about-seller a .ux-textspans",
])
item["shipping"] = first_text([
"div.ux-labels-values--shipping .ux-textspans--BOLD",
])
# 3. Характеристики товара
specifics = {}
for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
if k and v:
specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
item["specifics"] = specifics
return item
Здесь главное правило — сначала JSON-LD, потом CSS-резервные варианты. Именно это помогает строить парсеры, которые не ломаются каждый квартал. Ниже поясню подробнее.
Как парсить варианты товаров eBay (данные MSKU)
У некоторых объявлений eBay есть несколько вариантов — разные цвета, размеры, объёмы памяти. Визуальный DOM показывает только диапазон цен вроде «$899 to $1,099», пока пользователь не выберет вариант. Реальные цены по каждому варианту хранятся в скрытом JavaScript-объекте MSKU.
Это как раз тот случай, где API eBay отдаёт только частичные данные (родительский SKU), поэтому парсинг оказывается лучше.
import re, json
def extract_variants(html):
# Негрубое сопоставление критично — жадный .+ захватит всю страницу
m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
if not m:
return []
try:
msku = json.loads(m.group(1))
except json.JSONDecodeError:
return []
item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
skus = []
for combo_key, variation_id in msku.get("variationCombinations", {}).items():
option_ids = combo_key.split("_")
options = [item_labels.get(oid, oid) for oid in option_ids]
var = msku.get("variationsMap", {}).get(str(variation_id), {})
bin_model = var.get("binModel", {})
price_spans = bin_model.get("price", {}).get("textSpans", [{}])
price = price_spans[0].get("text") if price_spans else None
qty = var.get("quantity")
skus.append({
"options": options,
"price": price,
"quantity_available": qty,
"variation_id": variation_id,
})
return skus
Именно этот негрубый (.+?) в регулярном выражении ломает большинство парсеров eBay. Жадный .+ захватывает всё до последнего "QUANTITY" на странице и в итоге даёт битый JSON. Я видел эту ошибку минимум в трёх «рабочих» руководствах.
Как парсить проданные и завершённые объявления eBay на Python
Это тот сценарий, ради которого парсинг часто и нужен вместо API. Данные о проданных товарах — что реально купили, по какой цене и в какой день — это золотой стандарт для исследования рынка, оценки ресейла и appraisal. В Browse API eBay этого нет. Marketplace Insights API теоретически это умеет, но доступ к нему относится к категории Limited Release и часто отклоняется.
Нужные параметры URL: LH_Complete=1 (завершённые объявления) и LH_Sold=1 (только реально проданные). Нужно передавать оба параметра. Если указать только LH_Sold=1, в некоторых категориях eBay тихо вернёт активные объявления — это ошибка, на которую чаще всего попадаются.
def scrape_sold_listings(keyword, max_pages=3):
all_sold = []
for page_num in range(1, max_pages + 1):
params = {
"_nkw": keyword,
"_ipg": "120",
"_pgn": str(page_num),
"LH_Complete": "1",
"LH_Sold": "1",
}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Парсим страницу проданных товаров {page_num}...")
html = fetch_page(url)
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item")
for card in cards:
title_el = card.select_one(".s-item__title")
title = title_el.get_text(strip=True) if title_el else None
if not title or "Shop on eBay" in title:
continue
# Включаем только реально проданные товары (зелёная метка POSITIVE)
sold_tag = card.select_one(
".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
)
if sold_tag is None:
continue # Завершённое, но не проданное объявление — пропускаем
price_el = card.select_one("span.s-item__price")
price = price_el.get_text(strip=True) if price_el else None
# Разбираем дату продажи
sold_date = None
import re, datetime as dt
card_text = card.get_text()
m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
if m:
sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
link_el = card.select_one("a.s-item__link[href]")
url = link_el["href"].split("?")[0] if link_el else None
all_sold.append({
"title": title,
"sold_price": price,
"sold_date": sold_date,
"url": url,
})
if not cards:
break
time.sleep(random.uniform(3, 8))
return all_sold
Ключевое отличие в HTML: у реально проданных товаров цена выделена зелёным (в обёртке .POSITIVE), а у завершённых, но не проданных — красная и перечёркнутая. Всегда фильтруйте по классу .POSITIVE.
Почему парсеры eBay ломаются и как строить устойчивые решения
Если ваш парсер eBay перестал работать, вы не одиноки. Это главная боль в любой ветке форума по парсингу eBay, которую я читал. Вопрос не в том, сломается ли ваш парсер, а в том, когда.
Почему это происходит:
- eBay использует React-рендеринг с динамически генерируемыми CSS-классами, которые меняются при деплое
- A/B-тесты показывают разную структуру DOM разным пользователям (двойной макет
s-item/s-card— живой пример прямо сейчас) - Периодические редизайны меняют вложенность HTML, даже если сами данные остаются прежними
- Старые селекторы вроде
#itemTitleи#prcIsumубрали много лет назад, но они до сих пор встречаются в учебниках
Как отмечает руководство Scrapfly за 2026 год: «Главная сложность парсинга eBay — это работа с изменениями CSS-селекторов. eBay регулярно обновляет фронтенд, ломая парсеры, которые завязаны на конкретные названия классов».
Как сделать парсер eBay долговечным
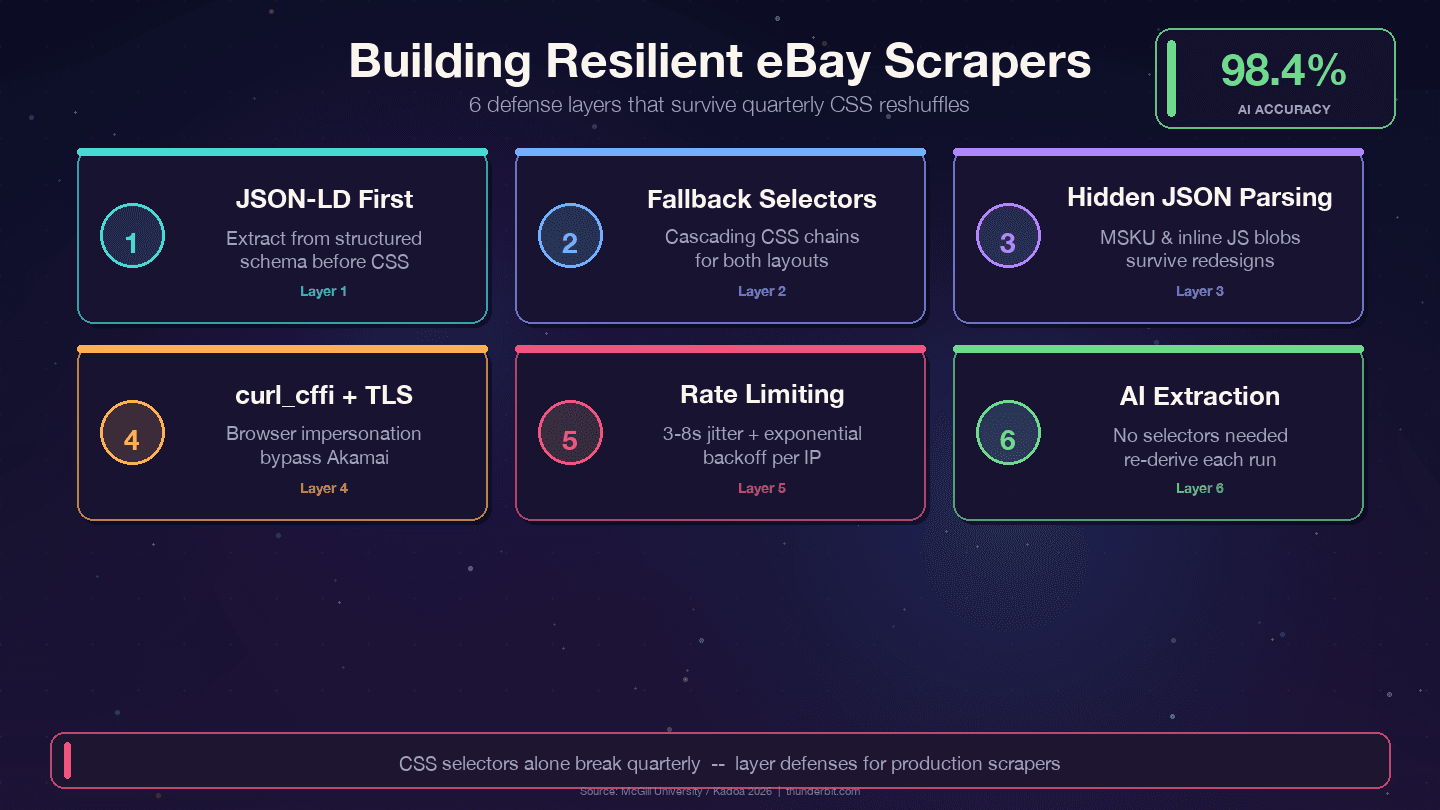
Четыре стратегии, которые переживают квартальные перестройки eBay:
1. Ставьте JSON-LD выше CSS-селекторов. eBay встраивает структурированные данные Product на каждой странице товара. Слой данных меняется намного реже, чем слой отображения: дизайнеры переписывают CSS-классы каждый квартал, а backend-поля вроде price, name и seller привязаны к внутренним API и почти не переименовываются.
2. Используйте каскадные fallback-селекторы. Никогда не полагайтесь на один CSS-селектор. Всегда давайте альтернативы:
def first_text(soup, selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
title = first_text(soup, [
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
"[data-testid='x-item-title'] h1",
])
3. Разбирайте скрытые JSON-блоки. Объект вариантов MSKU и встроенные JavaScript-данные переживают изменения CSS, потому что формируются на стороне сервера. Регулярное извлечение из <script> требует больше работы на старте, но заметно снижает затраты на поддержку.
4. Логируйте ошибки селекторов. Добавьте мониторинг, чтобы понимать когда селектор перестал совпадать, а не просто получать пустой набор данных:
if title is None:
print(f"WARNING: title selector failed for {url}")
5. Используйте curl_cffi с имитацией браузера. Это помогает обходить TLS-фингерпринт Akamai без headless-браузера.
Альтернатива на базе ИИ: без поддержки селекторов
Если вам надоело каждые несколько месяцев править селекторы, существует принципиально другой подход. Инструменты вроде Thunderbit используют ИИ, чтобы заново читать страницу при каждом запуске и автоматически строить логику извлечения. Исследование McGill University сравнило ИИ и селекторные парсеры на 3 000 страницах и показало, что ИИ-методы сохраняли точность 98,4% даже после изменения макета, а отраслевые бенчмарки говорят о снижении затрат на поддержку парсеров на 60–80%.
| Подход | Ломается ли при изменении HTML на eBay? | Затраты на поддержку |
|---|---|---|
| Жёстко прописанные CSS-селекторы | Да, каждый квартал | Высокие — постоянные правки |
| Извлечение скрытого JSON / JSON-LD | Редко | Низкие |
| Парсинг на базе ИИ (Thunderbit) | Нет — ИИ переопределяет селекторы при каждом запуске | Практически нет |
Парсите данные eBay с помощью ИИ Get Started Free
О рабочем процессе Thunderbit я расскажу подробнее ниже. Пока главное: если вы строите парсер, который должен работать месяцами, делайте упор на JSON-first извлечение и fallback-селекторы. Если же вы не хотите вообще поддерживать селекторы, ИИ-подход точно стоит посмотреть.
Как автоматизировать регулярный парсинг eBay для мониторинга цен
Разовый парсинг полезен. Но мониторинг цен, отслеживание наличия и анализ конкурентов требуют регулярного сбора данных. Почти в каждой статье по теме мониторинга цен это упоминают, но почти нигде не показывают, как именно автоматизировать процесс.
Вариант 1: Cron в Linux/macOS или Task Scheduler в Windows
Самый простой способ — завернуть Python-скрипт в cron. Всегда используйте абсолютный путь к Python из вашего virtualenv — cron запускается в минимальном окружении:
crontab -e
# Каждый день в 08:15
15 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1
В Windows используйте PowerShell:
$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
$T = New-ScheduledTaskTrigger -Daily -At 8:15am
Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T
Для этого нужен всегда включённый компьютер, а прокси и антибот-защиту вы настраиваете сами.
Вариант 2: Cloud Functions (serverless)
AWS Lambda или Google Cloud Functions позволяют запускать парсинг без отдельного сервера. Но настройка сложнее: нужно упаковать зависимости, учитывать таймауты (у Lambda максимум 15 минут) и всё равно управлять прокси. Зато сервер не нужно обслуживать.
Вариант 3: No-code расписание в Thunderbit
Функция Thunderbit Scheduled Scraper позволяет описать интервал простыми словами, например «каждый день в 8 утра», указать URL eBay и нажать Schedule. Всё работает в облаке, а антибот-защита встроена.
| Подход | Сложность настройки | Нужен сервер? | Есть антибот-защита? |
|---|---|---|---|
| Cron + Python-скрипт | Средняя | Да (машина должна быть включена постоянно) | Прокси на вашей стороне |
| Cloud function (Lambda) | Высокая | Нет (serverless) | Прокси на вашей стороне |
| Thunderbit Scheduled Scraper | Низкая (всё описывается словами) | Нет (облако) | Встроена |
Для хранения данных повторяющихся парсингов локальная база SQLite — отличный выбор для истории цен. Используйте ON CONFLICT ... DO UPDATE (а не INSERT OR REPLACE, который ломает внешние ключи и перезаписывает столбцы):
CREATE TABLE IF NOT EXISTS listings (
item_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
price REAL,
last_price REAL,
first_seen_at TEXT DEFAULT (datetime('now')),
last_seen_at TEXT DEFAULT (datetime('now'))
);
CREATE TABLE IF NOT EXISTS price_history (
item_id TEXT NOT NULL,
observed_at TEXT NOT NULL DEFAULT (datetime('now')),
price REAL NOT NULL,
PRIMARY KEY (item_id, observed_at)
);
Попробовать Thunderbit Scheduled Scraper
Не хотите кодить? Как парсить eBay за 2 минуты с Thunderbit
Я уже подробно разобрал Python-код. Теперь хочу честно сказать, когда он вам не нужен.
Если вы бизнес-пользователь и делаете разовое исследование рынка, реселлер сравнивает цены или ecommerce-команде нужны данные сегодня, без спринта у разработчиков, Python — это перебор. Настройка, поддержка селекторов, прокси — всё это слишком много накладных расходов ради задачи «мне просто нужны эти 200 объявлений в таблице».
Как Thunderbit парсит eBay (пошагово)
- Установите расширение Thunderbit для Chrome — карта не нужна.
- Откройте любую страницу результатов поиска или товара на eBay в Chrome.
- Нажмите “AI Suggest Fields” в боковой панели Thunderbit. ИИ прочитает страницу и предложит столбцы: Title, Price, Condition, Shipping, Seller, Rating.
- Нажмите “Scrape”. Расширение пройдёт по пагинации и заполнит таблицу данных. Для eBay у Thunderbit есть готовые шаблоны парсера, которые запускаются в один клик.
- Экспортируйте в Google Sheets, Airtable, Notion, CSV, JSON или Excel — бесплатно.
Весь процесс занимает меньше 2 минут.
Я засёк.
Обогащение подстраниц: данные со страницы товара без лишнего кода
После парсинга страницы результатов Thunderbit может перейти на страницу каждого объявления и добавить дополнительные поля — полные характеристики, данные продавца, описание, все изображения. Это заменяет более чем 20 строк Python-кода для парсинга подстраниц, который мы писали выше, одним кликом.
Когда Python всё же лучше
Python выигрывает, когда вам нужно:
- Масштабное парсирование (десятки тысяч страниц за один запуск)
- Глубоко кастомная логика разбора или трансформация данных
- Интеграция в существующие data pipeline (Airflow, dbt, Kafka)
- Тонкий контроль TLS/сессий для продвинутой антибот-защиты
- Экономика на больших объёмах — на миллионах строк поддерживаемый стек выгоднее SaaS по подписке или кредитам
Для большинства разовых или средних по масштабу задач Thunderbit быстрее и проще. Для production-пайплайнов на больших объёмах Python даёт полный контроль.
Как не попасть под блокировку при парсинге eBay на Python
eBay и Akamai — это реальность. Что действительно работает на практике:
- Используйте
curl_cffiсimpersonate="chrome124"— это самое заметное улучшение по сравнению с обычнымrequests - Ротируйте User-Agent из списка актуальных браузеров (Chrome 143, Firefox 124, Safari 26)
- Добавляйте случайные паузы по 3–8 секунд между запросами — фиксированные интервалы легко распознаются
- Используйте residential или rotating proxies для всего, что превышает несколько десятков страниц. Data center IP (AWS, GCP, DigitalOcean) Akamai быстро помечает как подозрительные.
- Соблюдайте
robots.txt— большинство фильтрованных browse URL там явно запрещены; страницы товаров (/itm/<id>) — нет - Обрабатывайте CAPTCHA корректно — распознавайте её и повторяйте попытку с другим IP либо используйте сервис решения CAPTCHA
- Не атакуйте сервер слишком часто. Прецедент eBay v. Bidder's Edge показывает, что doctrine trespass to chattels применяется, если парсинг действительно ухудшает работу серверов. Держитесь примерно на уровне 1 req/s на IP — и вы будете далеко от этой границы.
Для коммерческого использования с высокими объёмами лучше сочетать Browse API для активных объявлений и точечный парсинг только для sold comps и тех данных, которых нет в API. Такой гибридный подход чище и технически, и юридически.
Законно ли парсить eBay на Python?
Я не юрист, и эта статья не является юридической консультацией. Поэтому коротко.
Правовая ситуация в целом стала более благоприятной для сбора публично доступных данных. Основные прецеденты:
- hiQ v. LinkedIn (9-й округ, 2022): парсинг общедоступных данных не нарушает CFAA
- Van Buren v. United States (Верховный суд США, 2021): сузил трактовку положения CFAA «превышение разрешённого доступа»
- Meta v. Bright Data (Северный округ Калифорнии, 2024): парсинг без входа в аккаунт не нарушает условия платформы, потому что парсер не является «пользователем»
При этом обновление Пользовательского соглашения eBay от февраля 2026 года прямо запрещает «buy-for-me agents, LLM-driven bots или любые end-to-end процессы, которые пытаются оформить заказ без участия человека». Граница понятна: чтение публичных страниц — это одно; автоматизация checkout — совсем другое.
Лучшие практики: собирайте только публично видимые данные. Не создавайте фейковые аккаунты и не обходите login wall. Не перепродавайте массово защищённые авторским правом изображения объявлений. А для коммерческих проектов обязательно консультируйтесь с юристами.
Выводы и главные тезисы
Python — самый гибкий способ парсить eBay, но он требует постоянной поддержки, потому что HTML сайта меняется. Логика выбора такая:
- Используйте eBay Browse API для стабильных структурированных запросов средней интенсивности по активным объявлениям
- Используйте Python-парсинг для проданных объявлений, отзывов, данных по вариантам и всего, чего нет в API
- Используйте Thunderbit, если хотите получать данные eBay без написания и поддержки кода
Код в этом руководстве построен на устойчивости: сначала JSON-LD, затем каскадные CSS-fallback-селекторы, а для вариантов — разбор скрытого JSON. Такой многоуровневый подход означает, что парсер не умрёт в тот же день, когда фронтенд-команда eBay выпустит очередной редизайн.
Если хотите попробовать no-code путь, бесплатный тариф Thunderbit позволяет протестировать его на страницах eBay прямо сейчас. А если хотите посмотреть, как работает шаблон парсера eBay, до него всего один клик.
Больше материалов по инструментам веб-парсинга ищите в наших гайдах: лучшие автоматизированные инструменты для веб-парсинга, как выгружать данные с сайтов в Excel и лучшие Python-инструменты для веб-парсинга. Также можно посмотреть обучающие видео на канале Thunderbit в YouTube.
Попробовать Thunderbit для парсинга eBay Get Started Free
Часто задаваемые вопросы
1. Можно ли бесплатно парсить eBay на Python?
Да. Все библиотеки (Requests, BeautifulSoup, curl_cffi, pandas) бесплатны и с открытым исходным кодом. Расходы появляются на масштабе — residential proxies для большого объёма обычно стоят $50–500 в месяц в зависимости от трафика. Для небольших проектов (несколько сотен страниц) можно парсить даже со своего домашнего IP, если аккуратно ограничивать частоту запросов.
2. Как парсить проданные и завершённые объявления eBay на Python?
Добавьте LH_Complete=1&LH_Sold=1 к параметрам поискового URL. Нужно указать оба параметра — LH_Sold=1 по отдельности в некоторых категориях молча возвращает активные объявления. Отфильтруйте результаты по CSS-классу .POSITIVE у элемента цены: он означает реальную продажу, а не просто завершённое, но не проданное объявление.
3. Блокирует ли eBay веб-парсинг?
eBay использует Akamai Bot Manager, который определяет парсеры в первую очередь через TLS-фингерпринт и поведенческий анализ. Обычные запросы requests часто получают 403. Использование curl_cffi с имитацией браузера, ротацией User-Agent и случайными паузами 3–8 секунд между запросами помогает обойти большую часть блокировок. На масштабе помогают residential proxies.
4. Что выбрать: API eBay или веб-парсинг?
Используйте Browse API для стабильных запросов средней частоты по активным объявлениям (до 5 000 запросов в день). Используйте парсинг, когда нужны история цен продаж, полные данные по вариантам/MSKU, отзывы или любые поля, которых нет в API. Marketplace Insights API формально предоставляет данные о продажах, но доступ к нему ограничен и часто отклоняется.
5. Как проще всего парсить eBay без кода?
Расширение Thunderbit для Chrome использует ИИ, чтобы читать страницы eBay, предлагать столбцы данных и извлекать объявления в один клик. Оно умеет работать с пагинацией, обогащением подстраниц и экспортом в Google Sheets, Excel, Airtable или Notion. Готовые шаблоны парсера eBay делают задачу ещё быстрее для типовых сценариев.
Подробнее




