
Знаете, если бы мне платили по доллару каждый раз, когда кто-то присылает PDF, набитый «важными данными», и ожидает, что я волшебным образом превращу его в таблицу, я бы, наверное, уже мог купить себе пожизненный запас кофе — и, возможно, еще пару лишних расширений для Chrome. PDF встречаются повсюду: договоры с клиентами, каталоги товаров, исследовательские статьи, счета — что угодно. Но как только доходит до реального использования данных внутри этих файлов? Вот тут-то и начинается веселье, то есть головная боль.
Мне самому не раз приходилось через это проходить — копировать, вставлять, выправлять форматирование и иногда просто сдаваться, когда все окончательно разваливалось, а изображения и ссылки исчезали в никуда. Но есть и хорошие новости: мир извлечения данных из PDF сильно изменился, особенно с появлением инструментов на базе ИИ. Если вам надоело часами вручную вбивать цифры или вы уже сходите с ума из-за сломанных таблиц, вы по адресу. Давайте разберемся, что такое извлечение данных из PDF, почему это важно и как такие инструменты, как Thunderbit, наконец делают этот процесс безболезненным.
Что такое извлечение данных из PDF? Разбираемся в основах
Начнем с простого: PDF scraping — это просто модное название для «автоматического извлечения структурированных данных из PDF-файлов». PDF scraper — это инструмент (программа, расширение или сервис), который вытаскивает нужные вам данные — текст, таблицы, изображения, ссылки и многое другое — и преобразует их в удобный формат вроде Excel, Google Sheets или базы данных.
Но вот в чем загвоздка: PDF — это не веб-страницы и не файлы Excel. Скорее, это цифровые печатные страницы, созданные так, чтобы выглядеть одинаково везде, а не легко разбираться компьютером. В одних PDF есть выделяемый текст, другие — это просто отсканированные изображения (тогда нужен OCR — оптическое распознавание символов), а форматирование может быть каким угодно. Поэтому извлечение данных из PDF — это не просто копирование текста, а расшифровка головоломки из макетов, шрифтов и порой даже скрытых метаданных.
Что можно извлечь из PDF?
- Обычный текст (абзацы, заголовки и т. д.)
- Таблицы (например: финансовые показатели, характеристики товаров, данные опросов)
- Изображения и графику (диаграммы, логотипы, отсканированные подписи)
- Гиперссылки и ссылки-источники (встроенные URL, цитаты)
- Данные из форм (поля из заполняемых форм)
- Метаданные (автор, заголовок, дата создания, теги)
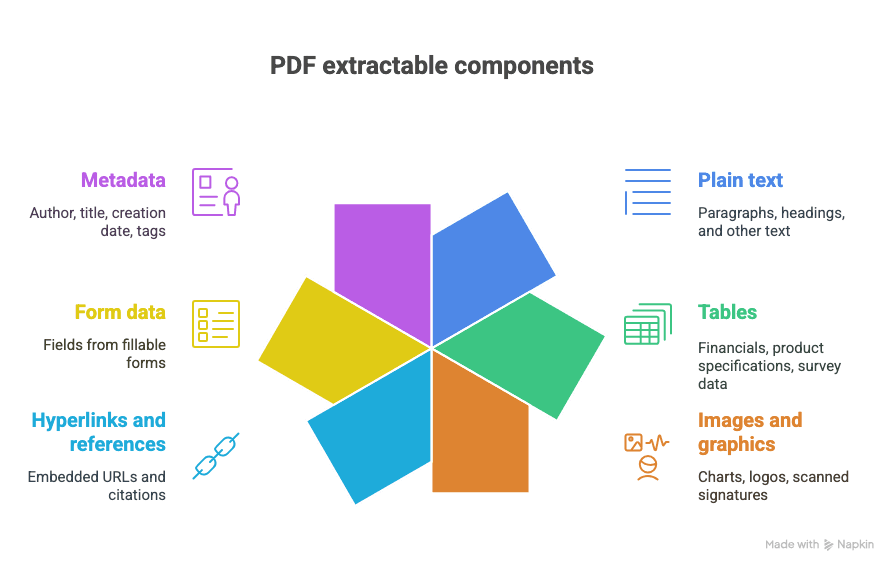
И да, иногда все это перемешано в одном великолепно хаотичном документе.
Почему извлечение данных из PDF важно: реальные сценарии и бизнес-выгоды
Так зачем вообще извлекать данные из PDF? Потому что ими пользуются все, а содержащиеся в них данные часто критически важны для бизнеса. Вот где извлечение из PDF особенно полезно:
| Сценарий | Ручная работа | С PDF scraper | Экономия времени и снижение ошибок |
|---|---|---|---|
| Извлечение лидов для продаж | Часы на копирование контактов из предложений или PDF с мероприятий, риск потерять лиды | Мгновенно переносит все лиды в таблицу | На 80–90% быстрее, меньше ошибок |
| Данные о товарах для e-commerce | Дни на ввод характеристик из PDF поставщиков, мучения с форматированием | Массовое извлечение в CSV или Sheets | Экономия 95%+ времени, данные единообразны |
| Анализ исследовательских данных | Недели на перепечатку таблиц из научных статей, высокий риск опечаток | Извлекает таблицы, ссылки и даже текст со сканов | Экономия 80% времени, выше точность |
Вот несколько цифр:
- Каждый год создается 2,5 триллиона PDF.
- 90% организаций используют PDF как основной формат для обмена информацией.
- Ручной цифровой админ-труд, например ввод данных из PDF, съедает 40% рабочего времени.
- Автоматизированные инструменты могут снизить уровень ошибок с 5–10% до 1%.
Если вы работаете в продажах, e-commerce или исследовательской сфере, автоматизация извлечения данных из PDF — это не просто удобство, а конкурентное преимущество.
Традиционные методы извлечения данных из PDF: проблемы и ограничения
Давайте честно: старые способы вытащить данные из PDF — это… не лучший опыт. Вот что большинство из нас пробовало, и почему это так раздражает:

1. Ручное копирование и вставка
- Проблемы: форматирование ломается, таблицы превращаются в кашу, изображения и ссылки исчезают, а в итоге остается только головная боль.
- Трудозатраты: очень высокие. Если у вас 5000 PDF, и на каждый уходит по 1 минуте, это более 80 часов жизни, которые уже не вернуть.
- Уровень ошибок: 5–10%. Опечатки, пропущенные строки, случайные удаления — знакомо, проходили.
2. Сначала конвертировать в Word/Excel, потом чистить
- Проблемы: для простых документов иногда работает, но сложные макеты и таблицы ломаются. Потом все равно приходится разгребать хаос.
- Изображения/ссылки: обычно теряются при преобразовании.
- Точечное извлечение: забудьте — вы получаете весь документ, а не только нужное.
3. Собственные скрипты (Python и т. п.)
- Проблемы: нужен программист — или хотя бы кто-то, кто всегда на связи. Каждый новый формат PDF означает доработку скрипта. Сканированные PDF? Удачи.
- Поддержка: сложная. Каждый раз, когда поставщик меняет шаблон счета, ваш скрипт ломается.
- Масштабируемость: не для слабонервных и не для нетехнических команд.
4. Онлайн-конвертеры
- Проблемы: удобно для разовых задач, но чувствительные документы приходится загружать на сервер третьей стороны — а это уже вопросы безопасности и соответствия требованиям.
- Форматирование: результат непредсказуем. Иногда потом уходит больше времени на исправление, чем удалось сэкономить.
Итог: традиционные способы медленные, подвержены ошибкам и плохо масштабируются. Поэтому многие команды просто «мирятся с этим» — но ценой огромных потерь в производительности.
Современные решения для извлечения данных из PDF: от кода до no-code инструментов
К счастью, мы уже не застряли в темных веках. Сегодня есть куда больше умных, быстрых и удобных вариантов для извлечения данных из PDF.
1. Библиотеки для программирования (для разработчиков)
- Примеры: PyPDF2, PDFMiner, Tabula-py.
- Сильные стороны: очень гибкие, можно автоматизировать большие объемы, бесплатные (open source).
- Слабые стороны: долго настраивать, нужны навыки программирования, хрупкие решения (ломаются на новых форматах), ограниченная поддержка OCR/изображений.
2. Онлайн-конвертеры PDF
- Примеры: Smallpdf, PDF2Go, Zamzar.
- Сильные стороны: не требуют настройки, подходят тем, кто не технический специалист, быстро работают для небольших задач.
- Слабые стороны: мало возможностей для кастомизации, вопросы конфиденциальности, ошибки форматирования, ограничения на размер файлов и число страниц.
3. AI-powered PDF scrapers
- Примеры: Thunderbit, Nanonets, Docparser.
- Сильные стороны: не нужен код, работают с текстом/таблицами/изображениями/ссылками, ИИ подсказывает, что извлекать, поддерживают пакетную обработку, интегрируются с Sheets/Notion/Airtable.
- Слабые стороны: у некоторых есть лимиты по кредитам или страницам, может понадобиться интернет-соединение, для сложных документов иногда нужно время, чтобы разобраться.
Сравнение инструментов для извлечения данных из PDF: какой подход подходит вам?
| Инструмент/метод | Настройка | Лучше всего подходит для | Извлекает | Есть кастомизация? | Стоимость |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Средняя (UI/код) | Таблицы в PDF | Таблицы | Частично | Бесплатно |
| PDFMiner | Требуется код | PDF с большим количеством текста | Текст | Да (через код) | Бесплатно |
| PyPDF2 | Требуется код | Простой текст и метаданные | Текст, метаданные | Да (через код) | Бесплатно |
| Smallpdf/онлайн-конвертер | Нет (через веб) | Быстрые конвертации | Весь документ (Word/Excel) | Нет | Freemium |
| Thunderbit | Установка в 2 клика | Бизнес-пользователи, команды | Текст, таблицы, изображения, ссылки | Да (через AI prompts) | Freemium ($16.5/мес. для Pro) |
Знакомьтесь: Thunderbit — расширение Chrome для AI PDF Scraper
Как извлекать данные из PDF с помощью ИИ Get Started Free
А теперь поговорим об инструменте, который сильно облегчил мою жизнь — и жизнь многих бизнес-пользователей: Thunderbit.
Чем Thunderbit отличается?
- Извлечение в 2 клика: откройте PDF в Chrome, нажмите расширение Thunderbit — и дальше ИИ сделает все сам.
- Подсказки полей на основе ИИ: функция Thunderbit «AI Suggest Fields» читает ваш PDF и рекомендует столбцы, которые вам, скорее всего, нужны (например, «Имя», «Email», «Цена» и т. д.).
- Работает с изображениями, ссылками и таблицами: не только с обычным текстом — Thunderbit может извлекать изображения, гиперссылки и даже запускать OCR для сканированных документов.
- Кастомные подсказки: нужны только номера телефонов или характеристики товара? Добавьте свою инструкцию, и Thunderbit сосредоточится именно на этом.
- Экспорт куда угодно: отправляйте данные прямо в Excel, Google Sheets, Airtable или Notion. Больше никаких танцев с CSV.
- Пакетное и подстраничное извлечение: есть список PDF или ссылок? Thunderbit может обработать их все за один проход.
- Надежность уровня бизнеса: создан для точности, конфиденциальности и реальных рабочих процессов.
Проще говоря, это как цифровой стажер, которому нравится вводить данные вручную и который никогда не устает.
Как извлекать данные из PDF с помощью Thunderbit: пошаговое руководство
Скачать расширение Thunderbit для Chrome Get Started Free
Готовы увидеть, насколько это просто? Вот как я использую Thunderbit, чтобы превращать PDF в структурированные и удобные данные:
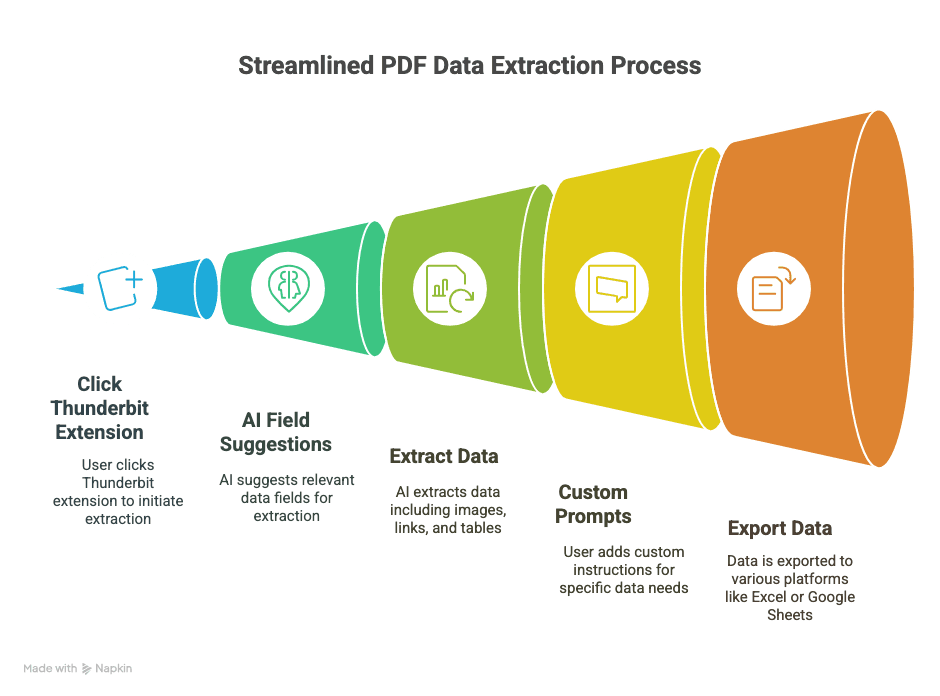
1. Установите Thunderbit
- Скачайте расширение Thunderbit для Chrome.
- Зарегистрируйтесь — через Google-аккаунт или email, это занимает секунды.
2. Откройте PDF в Chrome
- Откройте PDF по ссылке или перетащите локальный PDF в вкладку Chrome.
3. Запустите Thunderbit на PDF
- Нажмите на значок Thunderbit в панели инструментов браузера.
- Выберите «AI Web Scraper» — Thunderbit определит, что это PDF, и будет готов к работе.
4. Позвольте ИИ предложить поля
- Нажмите «AI Suggest Columns».
- ИИ Thunderbit просканирует PDF и предложит столбцы (например, «Дата», «Сумма», «Имя контакта» и т. д.).
- Просмотрите извлеченные данные в таблице прямо в расширении.
5. Настройте при необходимости
- Переименуйте столбцы, удалите лишние или добавьте свои (например, «Срок гарантии» или «URL товара»).
- Если данные сложные, выделите текст в PDF, чтобы обучить ИИ тому, что именно вам нужно.
6. Выберите формат экспорта
- Выберите CSV, Google Sheets, Airtable или Notion.
- Предоставьте Thunderbit доступ к подключению — это разовая настройка.
7. Запустите извлечение и экспорт
- Нажмите «Scrape» или «Export».
- Thunderbit обработает PDF и отправит данные туда, куда вам нужно — обычно за считанные секунды.
Попробовать PDF Scraper Thunderbit сейчас
Вот и все. Никакого кода, никакого копипаста, никакой драмы.
Советы по точному извлечению данных из PDF с Thunderbit
- Проверяйте поля, предложенные ИИ: ИИ умен, но быстрый взгляд поможет убедиться, что вы получаете именно то, что нужно.
- Работайте со сложными таблицами: если таблица многостраничная или странно отформатирована, используйте предпросмотр, чтобы заметить проблемы и при необходимости подправить столбцы.
- Извлекайте изображения/ссылки: не забудьте включить эти поля, если в вашем PDF они есть — Thunderbit тоже может их захватить.
- Сканированные PDF: встроенный OCR Thunderbit работает хорошо, но чем чище скан, тем лучше результат.
- Кастомные подсказки: нужны только email или телефоны? Добавьте запрос вроде «Извлеки все email-адреса», и Thunderbit сосредоточится на них.
Продвинутое извлечение данных из PDF: изображения, ссылки и пользовательские данные
Thunderbit — это не только про обычный текст. Вот как можно выжать из ваших PDF еще больше:
- Изображения: извлекайте логотипы, диаграммы и любую встроенную графику. Thunderbit может даже распознавать текст внутри изображений.
- Гиперссылки: вытаскивайте все URL или ссылки-источники — отлично подходит для научных статей или резюме.
- Пользовательские типы данных: используйте ИИ-подсказки, чтобы извлечь только то, что вам нужно (например, «Найди все артикулы товаров и их цены»).
- Сводки и категоризация: добавьте столбец и попросите Thunderbit кратко пересказать раздел или автоматически распределить данные по категориям.
Извлечение данных из PDF под конкретные бизнес-задачи
- Продажи: извлеките только контактную информацию из пакета предложений.
- E-commerce: вытащите характеристики товаров, цены и изображения из каталогов поставщиков.
- Исследования: достаньте таблицы, ссылки и даже сгенерируйте краткие сводки по научным статьям.
А когда данные уже у вас, структурируйте их для удобного анализа в Excel, Google Sheets или Notion — Thunderbit делает всю тяжелую работу, а вы просто пользуетесь результатом.
Экспорт и использование данных из PDF: от извлечения к действию
Извлечь данные — это только начало. Вот как заставить их работать на вас:
- Варианты экспорта: CSV, Excel, Google Sheets, Airtable, Notion — выбирайте, что удобнее.
- Советы по форматированию: используйте настройки типов столбцов в Thunderbit (число, дата, текст), чтобы данные были чистыми и готовыми к анализу.
- Интеграция в рабочие процессы: подключайте экспортированные данные к CRM, системам учета запасов или аналитическим дашбордам.
- Совместная работа: делитесь Google Sheets или базами Airtable с командой — все работают с одними и теми же актуальными данными.
Самое приятное? Больше не нужно пересылать таблицы по почте туда-сюда или гадать, не пропустили ли вы строку.
Распространенные ошибки при извлечении данных из PDF и как их избежать
Даже с лучшими инструментами могут всплывать подводные камни. Вот чему я научился — иногда на собственных ошибках:
- Ошибки OCR: размытые сканы или необычные шрифты могут сбить с толку даже хороший OCR. По возможности используйте самые чистые PDF и перепроверяйте важные поля.
- Сложные макеты: многостолбцовые или вложенные таблицы могут потребовать чуть больше ручного контроля — используйте ручной выбор Thunderbit или подсказки.
- Типы данных: числа с запятыми или даты в необычном формате? Задайте тип столбца до экспорта или приведите данные в порядок в Excel/Sheets.
- Ограничения по размеру файла/страницам: очень большие PDF лучше разбивать на части или использовать облачный режим Thunderbit для пакетных задач.
- «Галлюцинации» ИИ: редко, но бывает, что ИИ угадывает название столбца или подставляет недостающие данные. Всегда выборочно проверяйте результат, особенно если речь о важных числах.
- Ручная проверка: для критически важной информации сделайте быструю валидацию — автоматические инструменты точны, но человеческий взгляд лишним не будет.
И если упретесь в стену, поддержка и сообщество Thunderbit всегда готовы помочь.
Заключение и ключевые выводы: как заставить извлечение из PDF работать на ваш бизнес
Подведем итог. Извлечение данных из PDF раньше было кошмаром — медленно, с ошибками и просто утомительно. Но с современными инструментами, такими как Thunderbit, это теперь быстро, точно и, осмелюсь сказать, почти приятно.
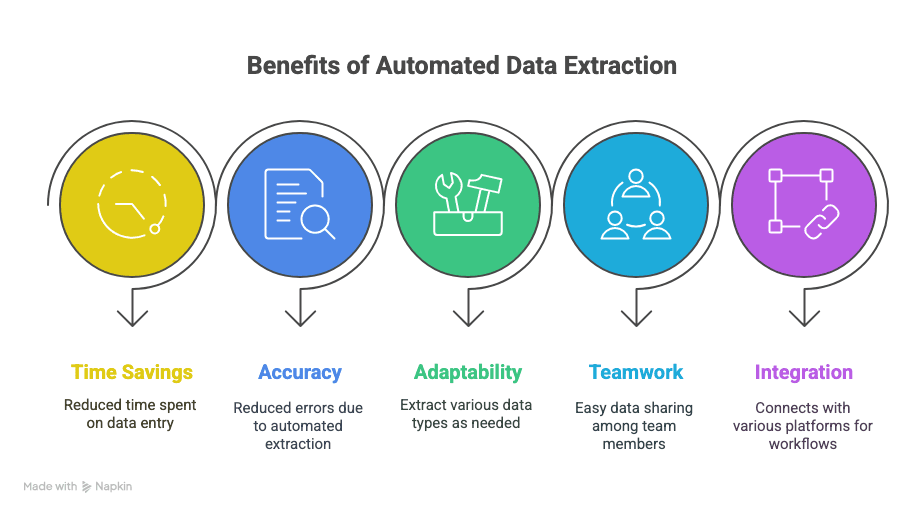
Что вы получаете:
- Экономию времени: часы, а то и недели, освобожденные от ручного ввода данных.
- Меньше ошибок: автоматическое извлечение означает меньше опечаток и пропущенных строк.
- Гибкость: извлекайте ровно то, что нужно — текст, таблицы, изображения, ссылки и все остальное.
- Совместную работу: мгновенно делитесь данными с командой, где бы она ни находилась.
- Более умные рабочие процессы: интеграции с Sheets, Notion, Airtable и не только.
Готовы попробовать? Скачайте расширение Thunderbit для Chrome, запустите его на следующем PDF и увидите, насколько проще может стать жизнь. Ваше будущее «я» — и ваши запястья — скажут вам спасибо.
Больше советов и руководств ищите в блоге Thunderbit или углубитесь в тему с материалом Как извлекать данные из PDF с помощью ИИ.
Давайте превращать PDF-головную боль в рост продуктивности — по одному клику за раз.
Шуай Гуань, сооснователь и CEO, Thunderbit
Попробовать AI PDF Scraper Thunderbit Get Started Free




