Темп цифровых новостей сегодня реально 숨가쁘게 빠르다. Каждую минуту публикуются, обновляются или тихо-тихо правятся тысячи заголовков — в крупных медиа, нишевых блогах и социальных лентах. Для масштаба: ежедневно обрабатывает более 4 миллионов новостных материалов, а проект отслеживает новости на 100+ языках и обновляет глобальную ленту каждые 15 минут. Для специалистов в медиа, исследователей и команд business intelligence попытка вручную удержаться на плаву в этом потоке — всё равно что вычерпывать воду из тонущей лодки кофейной кружкой.
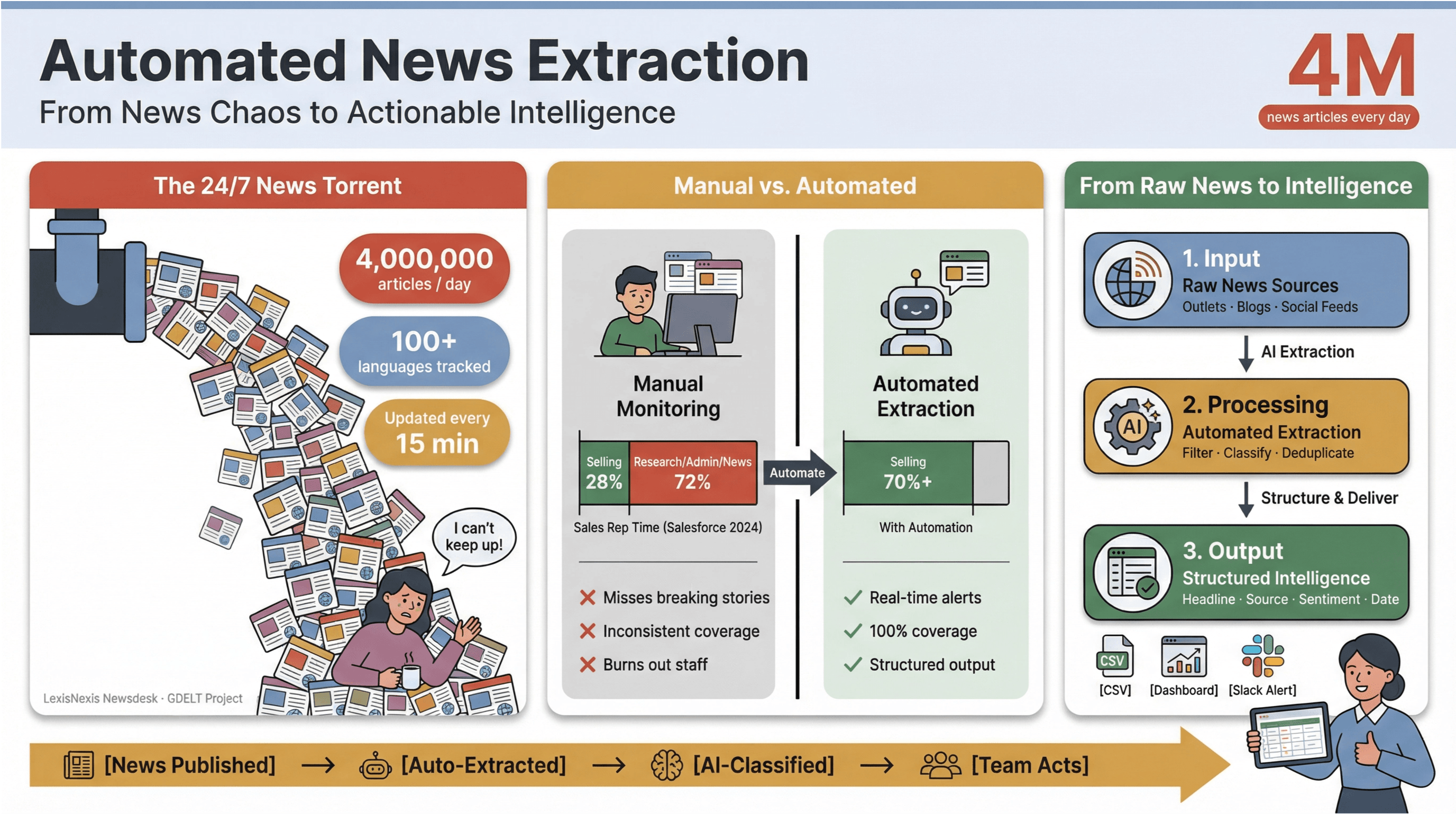
Я не раз видел, как ручной мониторинг новостей просто 먹어치우듯 съедает время и выжигает ресурсы. Команды продаж тратят на собственно продажи меньше трети недели — по данным Salesforce, всего — а остальное уходит на ресёрч, админку и бесконечное переключение вкладок с новостями. Поэтому автоматизированное извлечение новостей стало скрытым козырем современных команд: это почти единственный способ превратить хаос круглосуточного новостного цикла в структурированную, применимую на практике аналитику — не доводя сотрудников до 번아웃 и не упуская действительно важные сюжеты.
Разберёмся, что на деле означает автоматизированное извлечение новостей, почему оно критично всем, кому важны данные в реальном времени, и как выстроить надёжный и соответствующий требованиям процесс с помощью лучших инструментов (включая то, как делает всё это удивительно простым — даже для людей без технического бэкграунда, вроде моей мамы).
Автоматизированное извлечение новостей: почему это необходимо современным редакциям
Автоматизированное извлечение новостей — это ровно то, как звучит: использование программ, которые собирают новостной контент автоматически и превращают его в структурированные, удобные для поиска данные — условно, в строки и столбцы вместо «грязных» веб-страниц или PDF. На практике это означает, что вы можете отслеживать сотни (или тысячи) источников, вытягивать ключевые поля — заголовок, время публикации, автора, текст — и отправлять всё это в дашборды, алерты или аналитику ниже по цепочке, не прибегая к Ctrl+C/Ctrl+V.
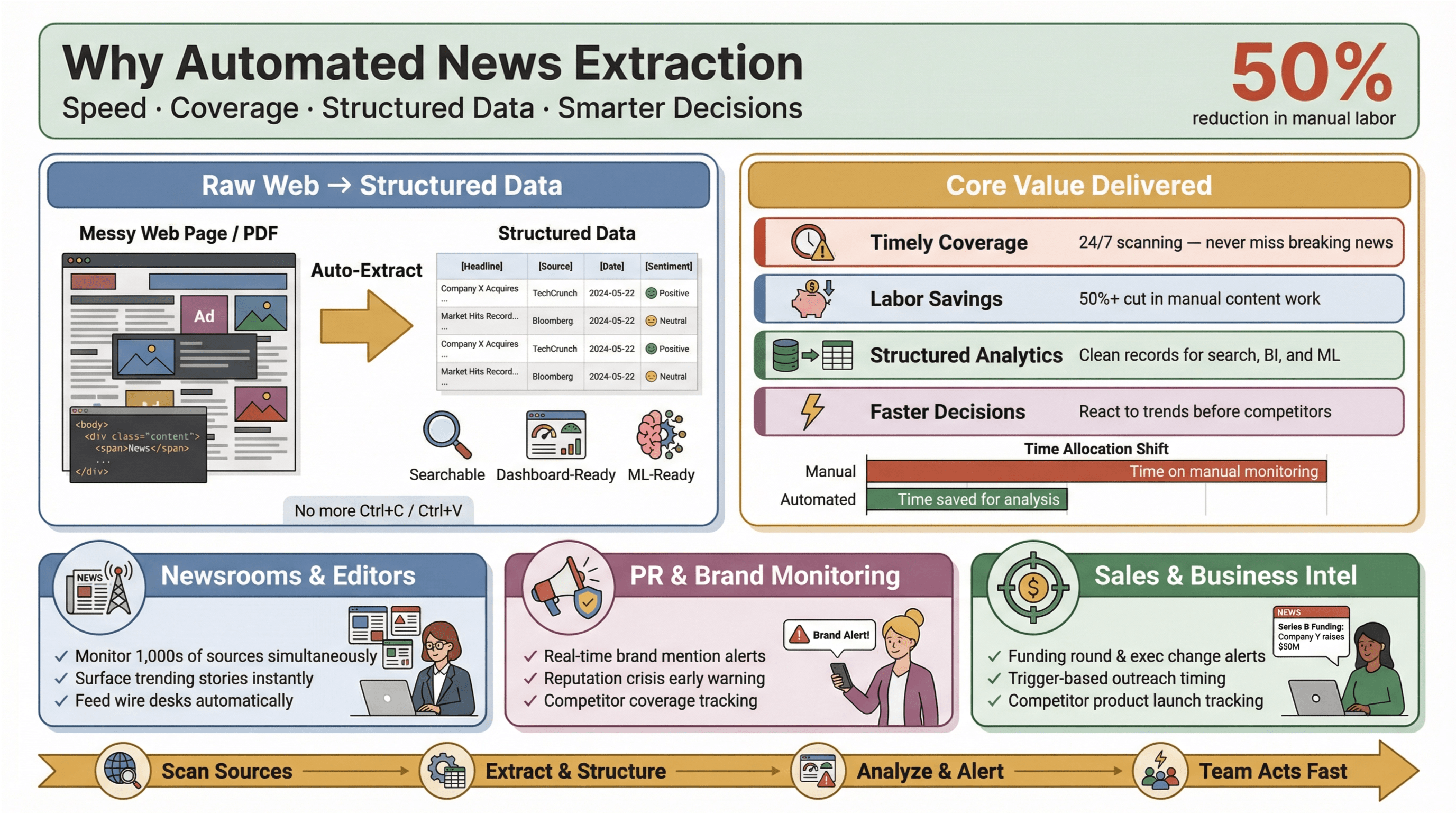
Почему это важно? Потому что в нынешней медиасреде скорость решает всё. Будь вы редактором, PR-менеджером, который отслеживает упоминания бренда, или аналитиком, наблюдающим за конкурентами, «узнать первым» часто означает разницу между тем, чтобы воспользоваться шансом, и тем, чтобы догонять. Инструменты автоматизированного извлечения позволяют даже небольшим командам работать на уровне крупных игроков: собирать новости в реальном времени со всего интернета, снижать ручную нагрузку и быстро находить то, что действительно важно.
И эффект вполне измерим: исследования показывают, что автоматизация способна сократить ручной труд по обновлению контента как минимум на 50%, освобождая время для анализа и принятия решений.
Ключевая ценность автоматизированного извлечения новостей для индустрии
Перейдём к практике. Что именно даёт автоматизированное извлечение новостей редакциям и бизнес-командам?
- Своевременное и полное покрытие: вы больше не пропустите срочную новость из‑за того, что кто-то не проверил ленту. Инструменты сканируют источники 24/7 и не дают «выпасть из ритма».
- Экономия труда и бюджета: небольшие и средние команды могут мониторить столько же источников, сколько и крупные — без армии стажёров.
- Структурированные данные для аналитики: вместо разрозненных статей вы получаете чистые записи, готовые для поиска, дашбордов и машинного обучения.
- Более быстрые и точные решения: новости в реальном времени помогают реагировать на рыночные изменения, PR-кризисы и тренды раньше конкурентов.
В PR и коммуникациях платформы вроде и прямо позиционируют мониторинг медиа в реальном времени как обязательный инструмент для защиты репутации и оперативной реакции на негатив. В продажах новостные алерты превращаются в «карточки контекста» для проспектинга — раунды инвестиций, смена топ-менеджмента, запуск продукта — всё, что помогает выйти на контакт в нужный момент.
Как выбрать инструменты для news scraping под разные задачи
Инструменты для news scraping бывают очень разными. Правильный выбор зависит от целей, технической подготовки и типов новостей, которые вам важны. Вот ориентир, который поможет подобрать подходящий вариант:
Оценка удобства и доступности
Для большинства бизнес-пользователей и журналистов удобство — без компромиссов. Нужен инструмент, который запускается «из коробки», без кода и сложной настройки. No-code и low-code решения вроде , и позволяют собирать скрейперы визуально — навёл, кликнул, извлёк.
Thunderbit особенно выделяется двухшаговым сценарием: опишите, что нужно, дайте ИИ предложить поля — и нажмите «Scrape». Даже без технических навыков можно собрать новостной конвейер за минуты, а не за часы.
Безопасность и конфиденциальность данных
Большие данные — большая ответственность. Инструменты для news scraping нередко получают доступ к чувствительному контенту, поэтому безопасность и соответствие требованиям должны быть в приоритете. Обратите внимание на:
- Шифрование данных (при передаче и хранении)
- Понятные политики приватности (например, Thunderbit заявляет, что не продаёт пользовательские данные и получает доступ только к тому, что вы сами выбираете для извлечения)
- Гранулярные разрешения (особенно у расширений браузера — всегда проверяйте, к каким данным у инструмента есть доступ)
- Соблюдение местных законов (GDPR, CCPA, а для пользователей ЕС — )
Для дополнительного спокойствия выбирайте проверенных поставщиков, перепроверяйте разрешения расширений и ограничивайте доступ только необходимым.
Соответствие инструментов типам новостей и отраслевым задачам
Некоторые решения особенно сильны в отдельных доменах:
- Финансы: API вроде и дают кластеризацию, сентимент и детекцию событий для финансовых новостей.
- Технологии и стартапы: кастомный сбор через Thunderbit или Octoparse помогает прицельно забирать данные из нишевых блогов, пресс-релизов или афиш мероприятий.
- Политика и регулирование: лицензируемые базы вроде и дают доступ к премиальным источникам и архивам.
Если нужно мониторить смесь крупных, нишевых и международных источников — включая сайты без API — наиболее практичны гибкие AI-ориентированные скрейперы вроде Thunderbit.
Уникальные преимущества Thunderbit для извлечения новостей в реальном времени
Теперь — о том, почему часто оказывается лучшим выбором для автоматизированного извлечения новостей, особенно если вам нужны новостные данные в реальном времени без технической головной боли.
Thunderbit — это AI Web Scraper в формате Chrome-расширения, созданный для бизнес-пользователей, журналистов и аналитиков, которым нужен актуальный, структурированный новостной контент с любого сайта. Вот почему я постоянно к нему возвращаюсь:
- AI Suggest Fields: Thunderbit анализирует новостную страницу и сам предлагает оптимальные колонки для извлечения — заголовок, время, автора, краткое резюме и многое другое. Не нужно возиться с селекторами или шаблонами.
- Subpage Scraping: Нужен полный текст, а не только заголовок? Thunderbit может перейти по каждой ссылке, извлечь основной текст, сущности и теги и собрать всё в одну структурированную таблицу.
- Массовый экспорт и быстрые обновления: Выгружайте данные напрямую в Excel, Google Sheets, Airtable или Notion одним кликом. Никаких марафонов копипаста и ручной возни с CSV.
- Scheduled Scraper: Настройте регулярные задания (каждый час, ежедневно или по своему интервалу), чтобы лента всегда оставалась свежей — идеально для срочных новостей, мониторинга рынка и длительных исследований.
- Адаптивность: ИИ Thunderbit подстраивается под изменения верстки и «длинный хвост» новостных сайтов, поэтому вы меньше чините сломанные скрейперы и больше анализируете.
Свыше и рейтинг 4,8 — инструменту доверяют команды по всему миру: от PR-мониторинга до конкурентной разведки.
ИИ-определение полей и Subpage Scraping
Одна из самых сильных сторон Thunderbit — ИИ-определение полей. Достаточно нажать «AI Suggest Fields», и инструмент просканирует новостную страницу, выделив ключевые элементы: заголовок, дату, автора, краткое описание. Вы можете подправить список или добавить свои поля (например: «помечай статью тегом “earnings”, если в тексте есть квартальные результаты») — дальше ИИ сделает всё сам.
Subpage Scraping особенно полезен для новостей: вы собираете заголовки с главной или раздела, а затем Thunderbit проходит по URL каждой статьи и вытягивает полный текст, сущности и даже изображения. В итоге вы получаете полные, обогащённые записи — готовые для поиска, дашбордов или дальнейшего AI-анализа.
Массовый экспорт и мгновенные обновления
Thunderbit упрощает экспорт новостных данных до одного клика. Можно отправить структурированную ленту в Google Sheets, Airtable, Notion или скачать CSV/Excel. Для команд, которые живут в таблицах и BI-инструментах, это огромная экономия времени.
А благодаря поддержке Scheduled Scraper вы можете запускать сбор каждый час, каждый день или по своему расписанию — чтобы данные всегда были актуальными. И не придётся ждать, пока Google Alerts проиндексирует материалы с задержкой в несколько дней.
Как справляться с операционными сложностями в решениях для новостей в реальном времени
Даже с лучшими инструментами извлечение новостей в реальном времени приносит свои сложности. Вот как решать самые частые:
Управление задержками и актуальностью данных
- Планируйте сбор под скорость новостного потока: для срочных тем запускайте скрейперы каждые 15–30 минут (в ритме ). Для более спокойных тематик достаточно часа или суток.
- Отслеживайте разницу между временем публикации и временем получения: измеряйте лаг между тем, когда статья вышла, и когда ваша система её забрала. Если лаг растёт — проверьте блокировки или замедления.
- Повторно собирайте данные из-за «тихих правок»: новости часто редактируют после публикации. Запланируйте повторный сбор через 24 часа, чтобы поймать исправления или незаметные изменения ().
Ограничения API и различия между источниками
- Учитывайте квоты API: если используете новостные API, следите за rate limit — распределяйте запросы во времени и по возможности кэшируйте результаты ().
- Дедупликация и каноникализация: один и тот же сюжет может появляться по разным URL или обновляться. Сохраняйте canonical URL и используйте хэши (например, заголовок + дата), чтобы не плодить дубликаты ().
- Динамический контент: для бесконечной прокрутки и lazy loading выбирайте инструменты с поддержкой динамического рендеринга и следите за изменениями верстки ().
Умный анализ новостей: роль ИИ и машинного обучения
сбор новостей — лишь первый шаг. Настоящая ценность появляется, когда вы анализируете данные и действуете на их основе — и здесь ИИ и машинное обучение особенно полезны.
- Извлечение сущностей: NLP помогает выделять людей, организации и места, упомянутые в статье ().
- Классификация по темам: автоматическая разметка по теме, тональности или срочности — для более умных дашбордов и алертов ().
- Кластеризация событий: группировка дубликатов и близких материалов из разных изданий, чтобы видеть картину целиком, а не поток почти одинаковых заголовков.
- Персонализация и таргетинг: данные в реальном времени помогают сегментировать аудитории, улучшать рекламный таргетинг и рекомендовать контент — повышая вовлечённость и ROI.
Например, PR-команды с помощью аналитики новостей в реальном времени замечают зарождающиеся кризисы до того, как они станут вирусными, а отделы продаж обогащают списки лидов «триггерными событиями» — инвестициями или наймом руководителей.
Чек-лист лучших практик для автоматизированного извлечения новостей
Ниже — краткий чек-лист, чтобы ваш новостной конвейер работал стабильно:
| Лучшая практика | Зачем это нужно | Как внедрить |
|---|---|---|
| Часто запускать сбор | Снижает задержку, помогает ловить срочные новости | Подстройте частоту под скорость потока (например, каждые 15 минут для быстрых тем) |
| Использовать ИИ-извлечение | Проще переживать изменения верстки, быстрее стартовать | Инструменты вроде Thunderbit, Diffbot, Zyte API |
| Дедупликация и каноникализация | Меньше повторных алертов, чище данные | Сохраняйте canonical URL, используйте хэши для дедупликации |
| Контроль качества извлечения | Раннее обнаружение пропусков, дрейфа и сбоев | Отслеживайте % заполненных записей, лаг и частоту ошибок |
| Соблюдать правовые/комплаенс-границы | Снижает юридические риски, укрепляет доверие | По возможности используйте официальные API/фиды, читайте условия, минимизируйте персональные данные |
| Экспортировать в структурированные форматы | Упрощает дальнейшую аналитику | CSV, Excel, Sheets, Notion, Airtable |
| Планировать повторный сбор из-за правок | Ловит изменения после публикации | Возвращайтесь к статьям через 24ч/1н (модель GDELT) |
| Защищать пайплайн | Сохраняет чувствительные данные | Шифрование, контроль доступа, надёжные инструменты |
Как построить надёжный процесс автоматизированного извлечения новостей
Хочешь собрать собственный «чёрный ящик» для новостных данных? Вот пошаговый план:
- Определите источники: составьте список сайтов, блогов или API, которые нужно мониторить.
- Настройте извлечение: в Thunderbit (или другом инструменте) задайте поля (с «AI Suggest Fields» это делается очень быстро).
- Запланируйте сбор: выберите частоту под скорость новостей — каждый час для срочных тем, ежедневно для более спокойных.
- Обогащение через подстраницы: для каждого заголовка соберите полный текст, сущности и теги.
- Дедупликация и нормализация: сохраняйте canonical URL, хэшируйте записи и приводите поля к единому виду.
- Экспорт и интеграции: отправляйте структурированные данные в Excel, Google Sheets, Airtable или Notion для анализа.
- Мониторинг и адаптация: следите за качеством извлечения, изменениями верстки и корректируйте настройки.
- Соблюдайте требования: проверяйте условия, уважайте robots.txt и минимизируйте сбор персональных данных.
Если представить это визуально, получится так:
Источники → Извлечение (AI-поля) → Обогащение подстраниц → Дедупликация → Экспорт → Аналитика/алерты → Мониторинг
Итоги и ключевые выводы
Автоматизированное извлечение новостей — уже не «приятное дополнение», а необходимость для всех, кто хочет быть впереди в мире, где новости появляются (и меняются) каждую минуту. Следуя лучшим практикам и используя подходящие инструменты, вы сможете превратить «пожарный шланг» цифровых новостей в стабильный поток структурированной, применимой информации.
Главное:
- Масштаб и скорость онлайн-новостей требуют автоматизации — вручную не успеть.
- Инструменты автоматизированного извлечения экономят время и деньги и позволяют небольшим командам покрывать источники на уровне крупных организаций.
- При выборе инструмента важно сбалансировать удобство, безопасность и адаптивность — Thunderbit выделяется простотой на базе ИИ и экспортом в реальном времени.
- Стройте процесс вокруг актуальности, дедупликации, комплаенса и контроля качества — так вы получите надёжные и полезные новостные данные.
- ИИ и машинное обучение раскрывают дополнительную ценность — для более умного таргетинга, персонализации и принятия решений.
Если вы всё ещё копируете заголовки вручную или ждёте, пока Google Alerts «догонит» события, пора переходить на новый уровень. Установите и убедитесь, насколько простым может быть автоматизированное извлечение новостей. А за дополнительными советами, сценариями и подробными разборами загляните в .
FAQs
1. Что такое автоматизированное извлечение новостей и как оно работает?
Автоматизированное извлечение новостей — это процесс, при котором программа собирает новостные статьи и преобразует их в структурированные данные (например, таблицы или JSON) для анализа, поиска или уведомлений. Инструменты вроде Thunderbit используют ИИ, чтобы находить ключевые поля (заголовок, время, автор, основной текст) и автоматически извлекать их со страниц или через API.
2. Почему данные новостей в реальном времени так важны для бизнеса?
Новости в реальном времени помогают компаниям быстро реагировать на рыночные события, PR-кризисы и действия конкурентов. В продажах, PR или исследованиях актуальная информация позволяет принимать более быстрые и точные решения и опережать конкурентов.
3. Как Thunderbit упрощает news scraping для пользователей без технических навыков?
Thunderbit работает по простой схеме из двух шагов: вы описываете, какие данные нужны, а ИИ предлагает поля. Благодаря Subpage Scraping и мгновенному экспорту в Excel или Google Sheets даже нетехнические пользователи могут собрать надёжный новостной пайплайн за считанные минуты.
4. Какие юридические и комплаенс-аспекты нужно учитывать при сборе новостей?
Всегда проверяйте условия использования целевых сайтов, по возможности выбирайте официальные API или фиды и соблюдайте директивы robots.txt. Не извлекайте контент, требующий логина или находящийся за paywall, без разрешения, и минимизируйте сбор персональных данных, чтобы соответствовать законам о приватности.
5. Как обеспечить надёжность процесса извлечения новостей в долгосрочной перспективе?
Планируйте регулярный сбор, контролируйте качество извлечения и используйте инструменты, которые адаптируются к изменениям верстки (например, ИИ-извлечение Thunderbit). Убирайте дубликаты, отслеживайте лаг между публикацией и извлечением и настраивайте уведомления о сбоях или пропущенных полях, чтобы пайплайн оставался здоровым и актуальным.
Узнать больше