
Исследование на основе краулинга о том, как сайты с высоким трафиком публикуют машиночитаемые указания для больших языковых моделей, как выглядят ранние реализации и почему измерение внедрения требует большего, чем простой подсчет ответов HTTP 200.
- Набор данных:
data/llms_probe_results_top_10000.csv - Список Tranco скачан: 6 мая 2026 года
- Область охвата:
/llms.txtи/llms-full.txtна корневом уровне
Ключевые метрики
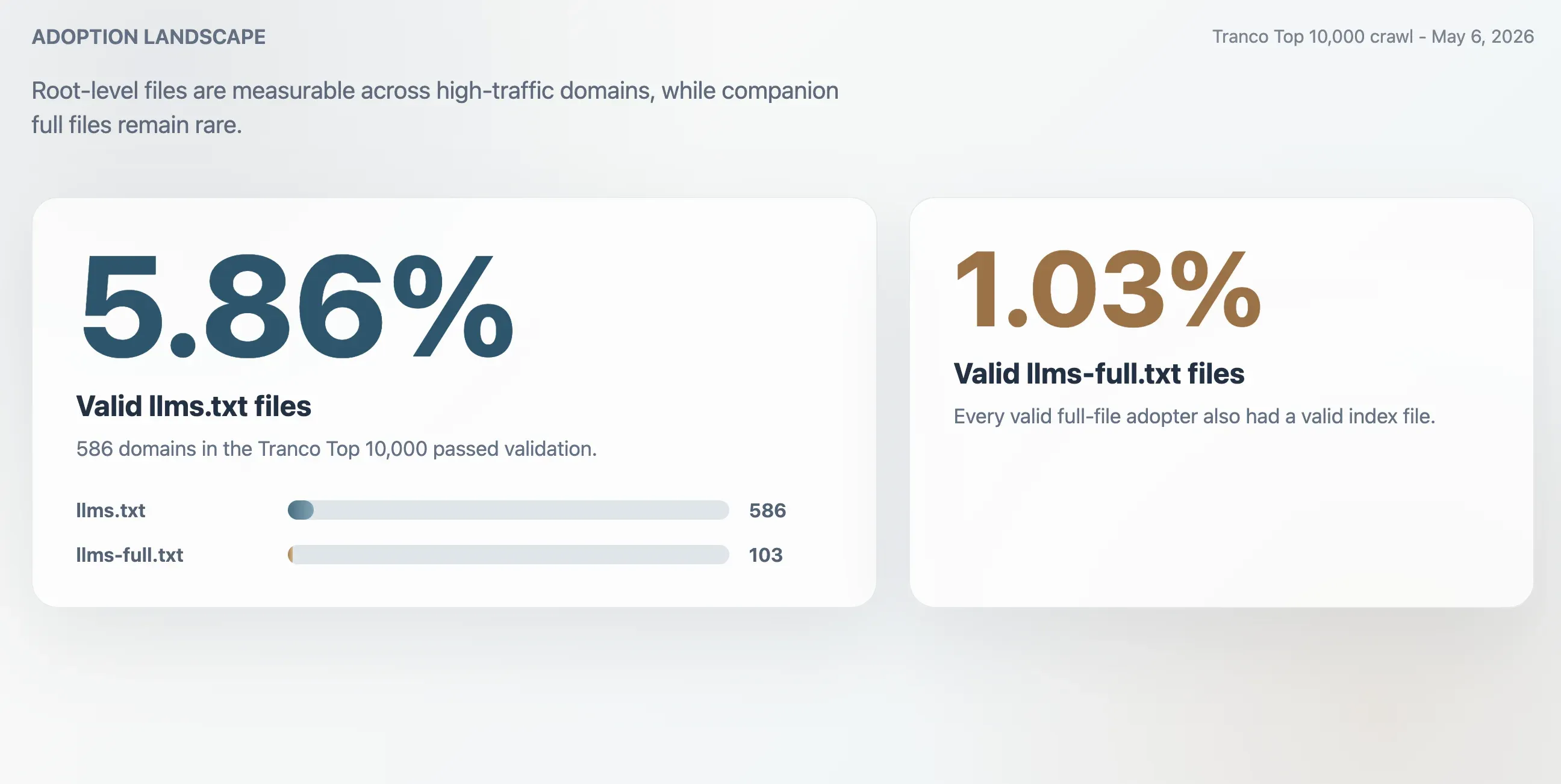
- 5,86%: Доля валидных
llms.txtсреди Tranco Top 10,000, что соответствует 586 доменам. - 1,03%: Доля валидных
llms-full.txt, что соответствует 103 доменам. У каждого валидного полного файла также был валидный индексный файл. - 63,51%: Доля ответов HTTP 200 для
/llms.txt, которые не прошли валидацию. - 2,74x: Примерный завышенный результат, если считать внедрение только по сырым ответам HTTP 200.
Краткое резюме
llms.txt пока остается ранней веб-конвенцией, но уже не выглядит маргинальным экспериментом. В ходе краулинга Top 10,000 доменов Tranco, проведенного 6 мая 2026 года, было найдено 586 валидных файлов llms.txt, что дало наблюдаемую долю внедрения 5,86%. Сопутствующий файл llms-full.txt встречался значительно реже: 103 домена имели валидный полный файл, что соответствует 1,03%.
Самый важный методологический вывод заключается в том, что статус-коды плохо подходят для оценки внедрения. Краулер получил 1 606 ответов HTTP 200 для /llms.txt, но только 586 прошли валидацию. Оставшиеся 1 020 в основном были нецелевыми редиректами, стандартными HTML-страницами, пустыми ответами или другими некорректными результатами. Наивный краулер, который считает каждый ответ 200 признаком внедрения, завысил бы реальную долю примерно в 2,74 раза.
Среди валидных внедрений качество реализации выше, чем предполагает чисто символический подход. Медианный размер валидного файла составлял около 7,1 КБ, 61,77% валидных файлов были больше 5 КБ, 70,82% содержали шесть и более Markdown-разделов, а 77,47% — 11 и более Markdown-ссылок. В число ранних последователей вошли Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog и Cloudinary.
llms.txtлучше всего понимать как объясняющий и навигационный сигнал для AI-систем, а не как заменуrobots.txt. Важно не просто наличие файла, а то, помогает ли он машинам находить авторитетную, компактную и актуальную информацию.
Контекст: веб добавляет сигналы для AI
Сайты уже давно используют robots.txt, чтобы выражать предпочтения для краулеров, sitemap.xml, чтобы улучшать обнаружение URL, и структурированные данные, чтобы помогать поисковым и платформенным системам интерпретировать страницы. Генеративный AI создает другую проблему. Контент может использоваться для обучения, поиска, суммаризации, агентного браузинга, помощи в коде, поддержки клиентов и генерации ответов. Это создает две одновременные потребности: издатели хотят больше контроля над автоматическим использованием, но при этом им важно, чтобы AI-системы находили правильную каноническую информацию, когда все же взаимодействуют с их сайтом.
Исходное предложение llms.txt, представленное Джереми Говардом в 2024 году, описывает файл как Markdown-документ, размещаемый в корне сайта и предоставляющий удобную для LLM информацию на этапе инференса. В предложении утверждается, что HTML-страницы часто содержат навигацию, рекламу, скрипты и другой шум, из-за которого языковым моделям сложнее их обрабатывать. Краткий Markdown-файл может указывать моделям на самые важные страницы, документацию, API, примеры, политики и сведения о продукте.
Дополнительный контекст дают внешние исследования. Data Provenance Initiative — “Consent in Crisis” описывает быстрый рост ограничений, связанных с AI, в robots.txt и условиях использования, и утверждает, что существующие веб-механизмы согласия не были рассчитаны на массовое повторное использование веб-данных для AI. Cloudflare Radar AI Insights также сделали видимыми паттерны AI-краулеров и robots.txt на уровне Top 10,000 доменов. В такой среде llms.txt находится на конструктивной стороне AI-сигналов: не «не сканируй это», а «если нужно понять этот сайт, начни отсюда».
Внешние данные и спор о внедрении
Публичная дискуссия вокруг llms.txt распадается на два утверждения. Оптимистичное — что файл дает AI-системам более чистый и эффективный путь к авторитетному контенту. Скептическое — что ни один крупный поставщик LLM публично не пообещал использовать его как сигнал ранжирования, краулинга или цитирования, поэтому издателям не стоит ожидать роста трафика только из-за этого файла. Три внешних источника, рассмотренные в этом обновлении, поддерживают более взвешенный вывод: llms.txt — полезная инфраструктура, но доказательства прямого влияния на трафик пока ограничены и зависят от контекста.
Бенчмарки внедрения быстро меняются
Трекер внедрения Rankability сообщил о доле внедрения 0,3% среди 1 000 крупнейших сайтов по состоянию на 22 июня 2025 года, то есть 3 сайта из 1 000. В описании методологии говорится о ежемесячном автоматическом сканировании domain.com/llms.txt с валидацией, исключающей редиректы и HTML-ответы. Эта методика в целом схожа с консервативным подходом к валидации в данном исследовании.
Разница в результатах велика: это исследование выявило 75 валидных файлов llms.txt в Tranco Top 1,000 на 6 мая 2026 года, то есть 7,50%. Эти два числа не следует трактовать как строгий временной ряд, поскольку источники ранжирования, детали реализации, логика валидации и время краулинга могут различаться. Тем не менее, контраст указывает, что внедрение заметно изменилось между серединой 2025 года и маем 2026 года, особенно среди сайтов разработчиков, SaaS, облачных сервисов, безопасности и документации.
| Источник | Снимок | Выборка | Сообщенная валидная доля внедрения | Интерпретация |
|---|---|---|---|---|
| Rankability | 22 июня 2025 | Top 1,000 сайтов | 0,3% | Ранний публичный бенчмарк, показывающий минимальное внедрение в середине 2025 года. |
| Это исследование | 6 мая 2026 | Tranco Top 1,000 | 7,50% | Поздний краулинг, показывающий заметное внедрение среди сайтов с высоким трафиком. |
| Это исследование | 6 мая 2026 | Tranco Top 10,000 | 5,86% | Более широкая выборка, показывающая, что внедрение измеримо, но еще не массово. |
Эксперименты с трафиком остаются неоднозначными
Search Engine Land опубликовал в январе 2026 года анализ 10 сайтов, отслеживаемых 90 дней до и 90 дней после внедрения. В статье сообщалось, что у двух сайтов трафик от AI вырос на 12,5% и 25%, у восьми не было заметного улучшения, а у одного падение составило 19,7%. Главный вывод был осторожным в плане причинности: у двух успешных кейсов одновременно запускались новые шаблоны, перестраивались ресурсные центры, добавлялись извлекаемые сравнительные таблицы, появлялись публикации в прессе, исправлялись технические проблемы или публиковались новые FAQ-материалы. В таком контексте llms.txt документировал более сильную работу с контентом и технической частью; сам по себе он, похоже, не был причиной роста.
Личный эксперимент Рената Алибекова в блоге пришел к более позитивному выводу на основе более маленького наблюдения на уровне сайта. Были сравнены два четырехмесячных периода в Yandex.Metrica после добавления и llms.txt, и llms-full.txt. Переходы из LLM выросли с 75 до 92, то есть на 23%, а число пользователей — с 51 до 64. Сессии из Perplexity выросли с 29 до 55, а из ChatGPT снизились с 31 до 26. В том же посте отмечается, что общий реферальный трафик рос быстрее — с 160 до 290 сессий, поэтому доля сессий от LLM снизилась с 47% до 32%.
| Тип доказательства | Наблюдаемый результат | Главная оговорка | Как это влияет на отчет |
|---|---|---|---|
| 10-сайтовое исследование Search Engine Land до/после | У двух сайтов рост, у восьми — без измеримого изменения, у одного — падение. | В позитивных кейсах одновременно менялись контент, PR и техника. | Поддерживает трактовку llms.txt как инфраструктуры, а не самостоятельного рычага роста. |
| Наблюдение Алибекова в личном блоге до/после | Переходы из LLM выросли на 23% за последующий период. | Нет контрольной группы; общий реферальный трафик вырос на 81%, а доля LLM снизилась. | Показывает возможный плюс для технических блогов, особенно через Perplexity, но причинность не изолирована. |
| Это исследование внедрения на основе краулинга | 586 валидных файлов и множество структурированных реализаций. | Измеряет наличие и структуру, а не последующее влияние на трафик. | Показывает масштаб и зрелость внедрения, но не ROI сам по себе. |
Что проясняет спор
Внешние данные уточняют интерпретацию этого набора данных. Хорошо структурированный файл llms.txt может снизить трение при машинной обработке, особенно для документации разработчиков, справки по API и контента базы знаний. Но самые сильные кейсы роста трафика по-прежнему, похоже, зависят от контента, который полезен, извлекаем, авторитетен и обнаружим не только через сам файл. Поэтому практический вопрос заключается не в том, «важен ли llms.txt?» сам по себе, а в том, является ли файл частью более широкой системы контента, читаемого AI.
Обновленная интерпретация:
llms.txtследует внедрять как недорогую инфраструктуру для AI. Не стоит позиционировать его как замену лучшей документации, структурированного контента, технической доступности, цитирования, ссылок или авторитетности бренда.
Попробовать Thunderbit для AI-скрейпинга веба
Методология
В качестве выборки в исследовании использовался Tranco Top 10,000. Tranco — это ориентированный на исследования рейтинг популярных сайтов, разработанный так, чтобы быть более стабильным и устойчивым к манипуляциям, чем многие традиционные списки. Исходный файл Tranco был скачан 6 мая 2026 года; значение Last-Modified у источника — 5 мая 2026 года, 22:17:59 GMT.
Краулер проверял два пути на корневом уровне для каждого домена:
https://example.com/llms.txtс fallback на HTTP при необходимости.https://example.com/llms-full.txtс fallback на HTTP при необходимости.
Для каждого запроса краулер записывал код статуса, финальный URL, метод получения, размер ответа в байтах, тип контента, сообщение об ошибке, время выполнения и результат валидации. Успешные тела ответов сохранялись в raw_llms_txt/ для проверки и вторичного анализа.
Правила валидации
Ответ засчитывался как валидный файл только если он возвращал успешное тело и не выглядел как стандартный веб-fallback. Путь финального URL должен был оставаться /llms.txt или /llms-full.txt. Пустые ответы отклонялись. Очевидные HTML-документы и app shell отклонялись. Тип контента рассматривался как вспомогательный признак, а не как единственное правило, поскольку небольшое число корректных текстоподобных файлов обслуживалось с необычными типами контента.
Картина внедрения
Краулинг обнаружил 586 валидных файлов llms.txt в Tranco Top 10,000. Это дает валидную долю внедрения 5,86%. Меньший сопутствующий файл llms-full.txt был найден и валиден на 103 доменах, то есть у 1,03% выборки.
| Метрика | Количество | Доля от Top 10,000 |
|---|---|---|
| Просканированных доменов | 10 000 | 100,00% |
| Валидных файлов llms.txt | 586 | 5,86% |
| Валидных файлов llms-full.txt | 103 | 1,03% |
| Ответов HTTP 200 для /llms.txt | 1 606 | 16,06% |
| Ответов HTTP 200, отклоненных как некорректные | 1 020 | 10,20% |
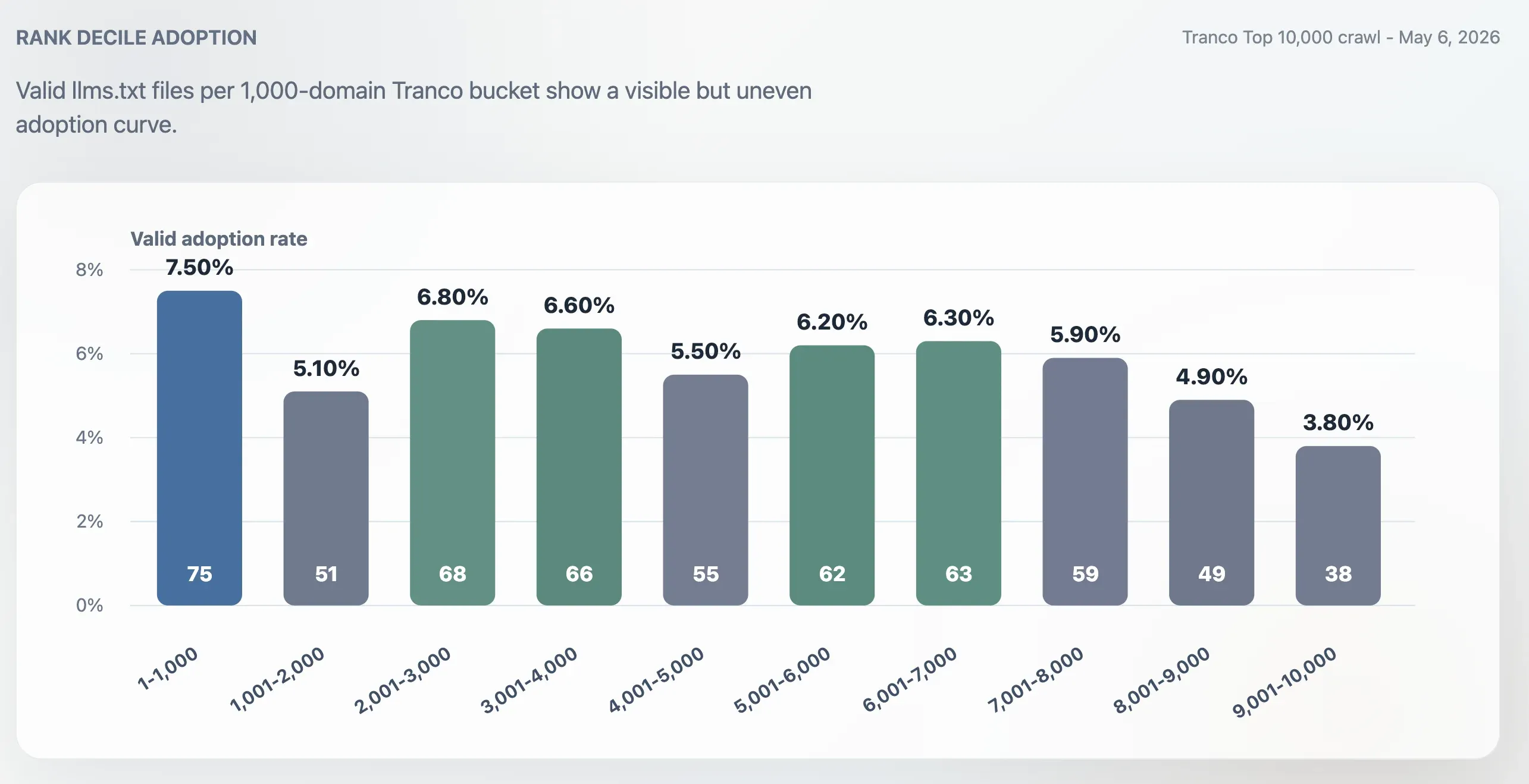
Внедрение не только у самых крупных
Уровень внедрения был выше в Top 1,000, чем в полном Top 10,000, но не ограничивался только самыми крупными сайтами. В Top 1,000 доля внедрения составляла 7,50%. Последний блок из 1 000 доменов, ранги 9 001–10 000, снизился до 3,80%. Средняя часть рейтинга оставалась активной: блоки 2 001–3 000, 3 001–4 000, 5 001–6 000 и 6 001–7 000 находились примерно на уровне 6%.
Ранние последователи
Самым высокоранжированным валидным внедрившим сайт был Cloudflare на позиции Tranco 4. Среди других заметных ранних последователей — Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink и OneSignal.
Эти внедрения не случайны. Обычно у них большие массивы документации, продуктовые линейки, которые нужно объяснять, API или экосистемы для разработчиков, материалы поддержки, страницы с ценами, контент по безопасности и конфиденциальности, а также достаточно сильная репутация бренда, чтобы заботиться о том, как AI-системы интерпретируют их сайты.
| Ранг | Домен | Размер файла | Наблюдаемый паттерн |
|---|---|---|---|
| 4 | cloudflare.com | 4 225 B | Компактный индекс продукта, для разработчиков, компании и цен. |
| 26 | azure.com | 47 037 B | Инструменты для разработчиков, AI, вычисления, хранилище, безопасность, мониторинг и дополнительные ресурсы. |
| 28 | github.com | 27 108 B | Программный доступ, Copilot, MCP, REST API, Actions, репозитории и ссылки на CLI. |
| 248 | stripe.com | 64 229 B | Платежи, Connect, Checkout, Billing, Tax, Atlas, Radar и документация для разработчиков. |
| 265 | salesforce.com | 1,02 MB | Огромный каталог ссылок на продукты и Agentforce без Markdown-заголовков разделов. |
Категории внедрений в Top 1,000
В этом исследовании 75 валидных внедрений в Tranco Top 1,000 были классифицированы по контексту домена, первым заголовкам, структуре сырого файла и ключевым словам контента. Самой большой группой оказались маркетинг, медиа и adtech — 22,67%. Облачные, разработческие и инфраструктурные сайты составили 20,00%. SaaS, продуктивность и customer-operations — 17,33%. Безопасность, идентификация и конфиденциальность — 12,00%.
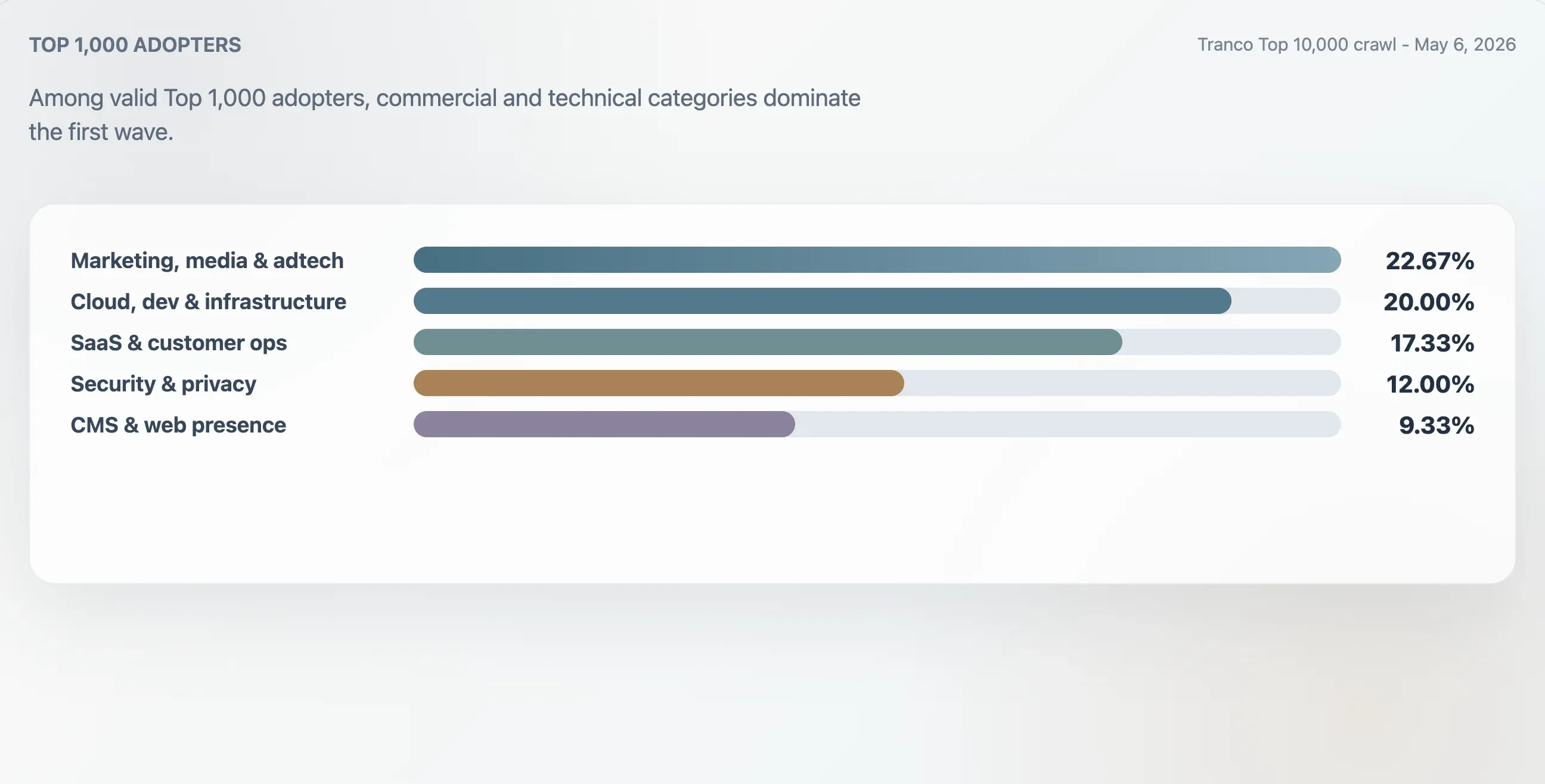
| Категория | Домены | Доля внедривших в Top 1,000 | Медианный балл качества | Медианное число ссылок |
|---|---|---|---|---|
| Маркетинг, медиа и adtech | 17 | 22,67% | 94 | 25 |
| Облако, разработка и инфраструктура | 15 | 20,00% | 94 | 62 |
| SaaS, продуктивность и customer ops | 13 | 17,33% | 94 | 46 |
| Безопасность, идентификация и конфиденциальность | 9 | 12,00% | 98 | 78 |
| CMS, хостинг и веб-присутствие | 7 | 9,33% | 100 | 24 |
Паттерны TLD
Домены верхнего уровня не являются отраслевыми ярлыками, но они полезны как ориентиры. Среди TLD, у которых в выборке было не менее 50 доменов, самый высокий уровень валидного внедрения показал .io — 14,44%. За ним следует .com с 8,19%. Более низкие показатели у .gov, .edu и .net говорят о том, что ранние последователи — это скорее коммерческие и технические сайты, чем институциональные.
Качество реализации
Валидное внедрение не означает одинакового качества реализации. Некоторые файлы — это краткие, хорошо структурированные индексы. Некоторые — в основном текст. Некоторые — простые каталоги ссылок. Некоторые — почти пустые заглушки. Некоторые — многомегабайтные дампы контента, которые могут быть полными, но дорогими для скачивания и парсинга.
Среди валидных файлов llms.txt 362 были больше 5 КБ, то есть 61,77% валидных внедрений. Медианный размер файла составлял около 7,1 КБ. P90 размера файла — 156 КБ, P95 — 356 КБ, P99 — 2,54 МБ, а самый большой наблюдаемый файл — 7,97 МБ.
Частые сигналы контента
Сканирование валидных файлов по ключевым словам показало, что многие сайты публикуют не просто декларацию, а направляют модели к практическому материалу. Термины support или help встречались в 70,31% валидных файлов. Термины blog, guide или tutorial — в 67,92%. Термины security, privacy, compliance или terms — в 61,43%. Pricing встречался в 53,92%, documentation — в 52,22%, API — в 33,96%, а сигналы changelog или release — в 27,30%.
Оценка качества и архетипы
Чтобы перейти от присутствия к зрелости, это исследование создало легкий скоринговый показатель внедрения. В нем учитываются тип контента, размер файла, Markdown-структура, количество ссылок, покрытие тем и признаки риска, такие как отсутствие заголовков, отсутствие Markdown-ссылок, необычный тип контента, слишком маленькие файлы, очень большие файлы и поведение в стиле link dump. Это не формальный стандарт. Это исследовательская модель оценки для сравнения наблюдаемых реализаций.
По этой модели 416 валидных файлов были отнесены к сильным структурированным индексам, 107 — к пригодным индексам, 24 — к тонким или нерегулярным, а 39 — к символическим или с низкой полезностью. Отдельный анализ архетипов выявил 296 структурированных индексов, 113 текстовых файлов с разделами, 63 каталога ссылок, 52 тонких индекса, 50 символических или заглушечных файлов и 12 массивных дампов контента.
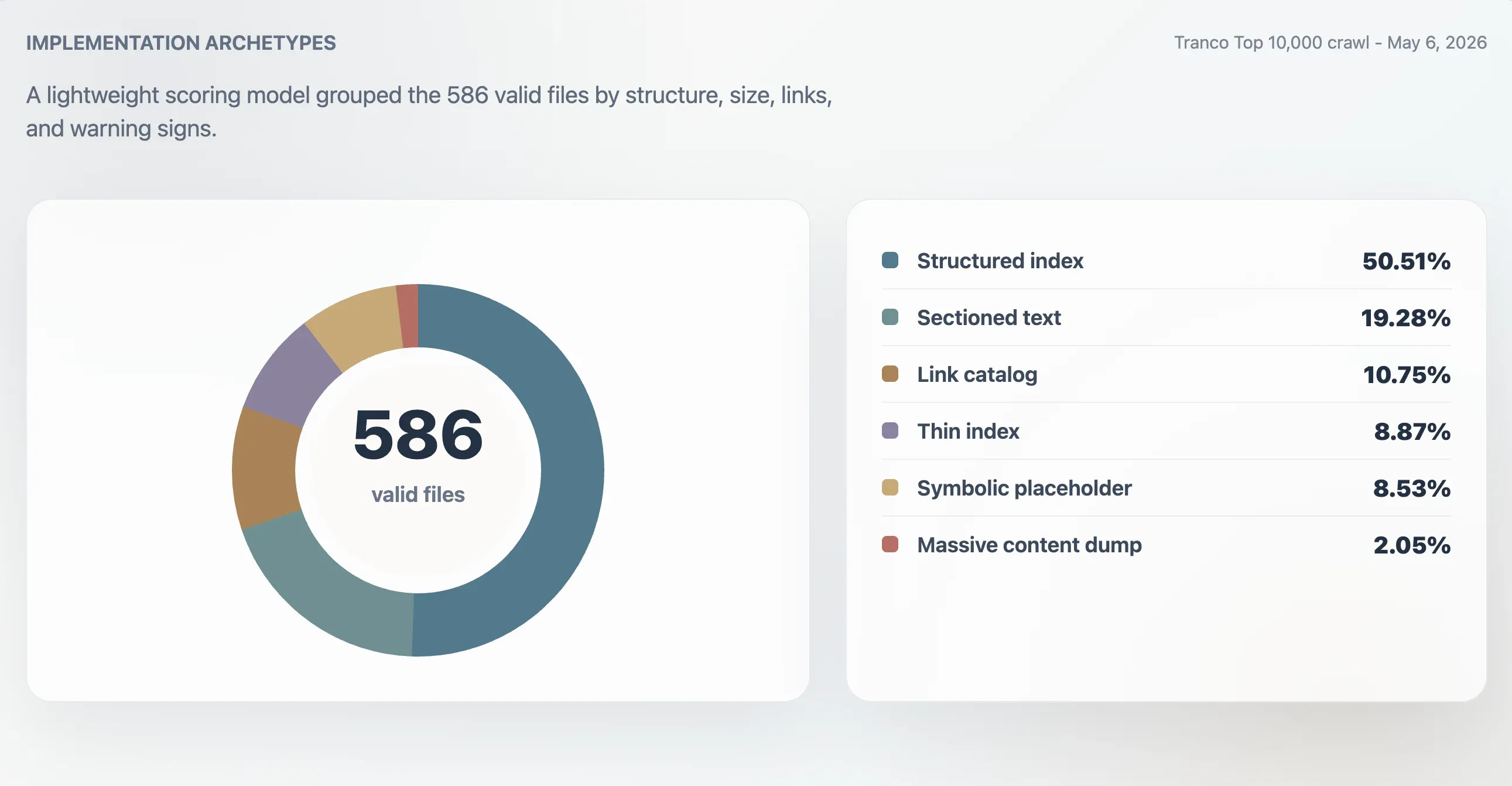
| Архетип | Домены | Доля валидных файлов | Медианный балл | Медианный размер файла | Медианное число ссылок |
|---|---|---|---|---|---|
| Структурированный индекс | 296 | 50,51% | 98 | 11 241 B | 61,5 |
| Текст с разделами | 113 | 19,28% | 78 | 4 718 B | 0 |
| Каталог ссылок | 63 | 10,75% | 86 | 4 160 B | 23 |
| Тонкий индекс | 52 | 8,87% | 66 | 2 814 B | 0 |
| Символический или заглушка | 50 | 8,53% | 27 | 15 B | 0 |
| Массивный дамп контента | 12 | 2,05% | 74 | 2,84 MB | 7 259,5 |
У крупнейших внедрения плотнее
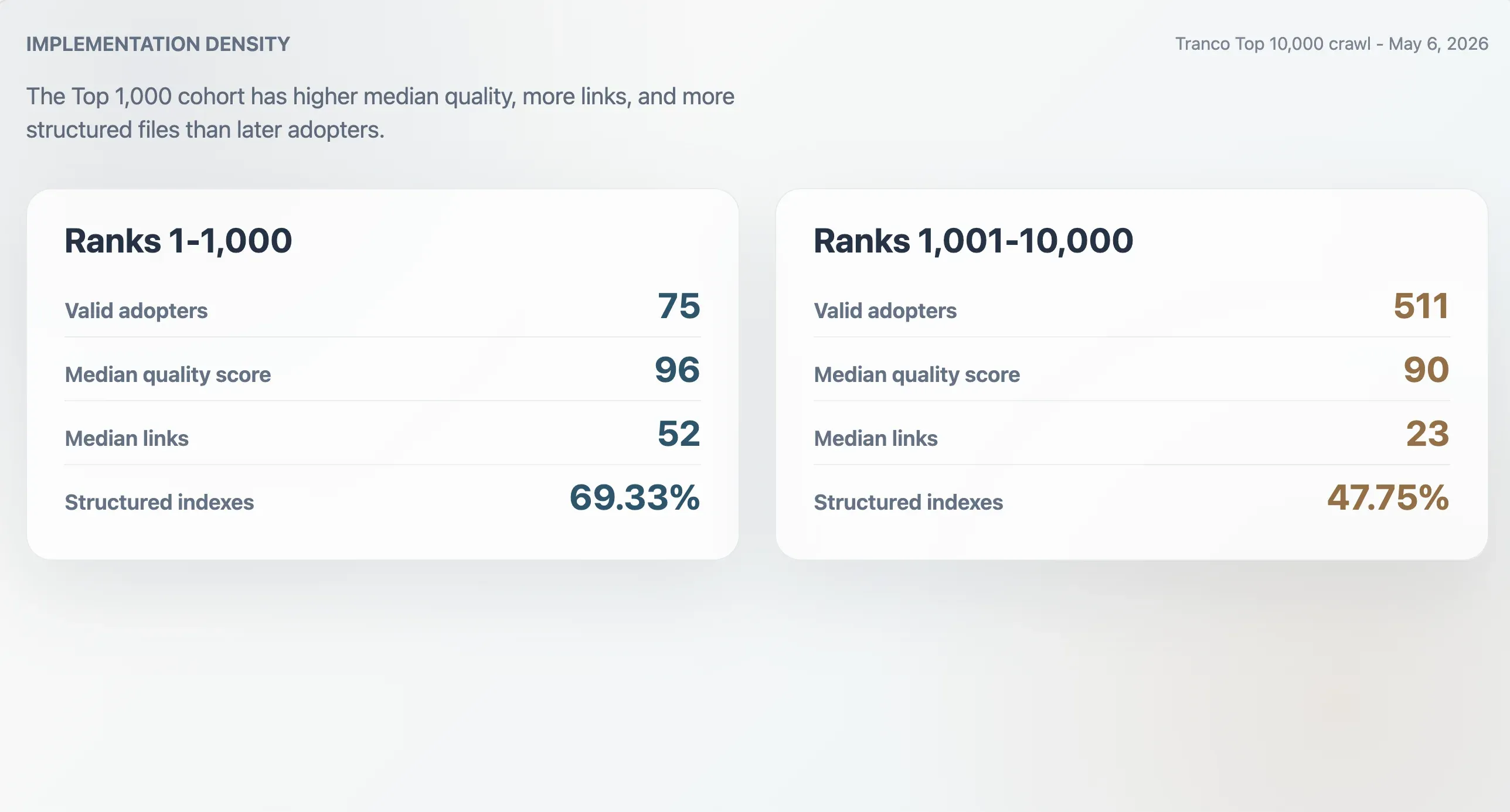
У 75 валидных внедрений в Tranco Top 1,000 медианный балл качества составлял 96, медианный размер файла — 9 068 байт, медианное число Markdown-ссылок — 52, а медианное число разделов — 11. У 511 внедрений, находящихся в диапазоне рангов 1 001–10 000, медианы были ниже: балл 90, размер файла 6 506 байт, 23 Markdown-ссылки и 9 разделов. В Top 1,000 сайты также чаще представляли собой структурированные индексы: 69,33% против 47,75% в более поздней когорте.
Проблема ложноположительных результатов

Наибольший риск измерений — ложноположительные результаты. Из 1 606 доменов, вернувших HTTP 200 для /llms.txt, 1 020 не прошли валидацию. Самой частой причиной некорректности был редирект не на тот путь — 618 случаев. Еще 367 ответов были стандартными HTML-документами. Двадцать девять вернули пустое тело, а шесть были другими или некатегоризированными некорректными ответами.
Это важно, потому что многие крупные сайты отправляют неизвестные пути на страницы входа, главные страницы, app shell, региональные страницы, экраны согласия или маркетинговые fallback-страницы. Для краулера, который смотрит только на код статуса, такие ответы могут выглядеть нормальными, но при этом не содержат валидного сигнала llms.txt.
llms-full.txt: реже и неровнее
Сопутствующий файл llms-full.txt встречался значительно реже, чем llms.txt. Краулинг обнаружил 103 валидных полных файла, что составляет 17,58% от числа валидных внедрений llms.txt и 1,03% всей выборки Top 10,000.
Реализации полного файла были неоднородными. Среди 103 доменов с двумя файлами у 57 llms-full.txt был больше индексного файла, но у 46 либо полный файл был не больше индексного, либо его размер был меньше 100 байт. Медианное соотношение размера full/index составляло 1,43, но экстремальные случаи были намного выше. Полный файл Supabase был примерно в 7 139 раз больше индексного файла. У Made-in-China.com полный файл достигал 89,89 MB.
| Домен | llms.txt | llms-full.txt | Соотношение |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7 139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Рекомендация: публикуйте
llms-full.txtтолько тогда, когда у сайта уже есть стабильный пайплайн документации, дисциплина версионирования и понятная причина открывать большой объем контента в одном машиночитаемом файле.
llms.txt, robots.txt и sitemap.xml
llms.txt не следует считать новым robots.txt. Оба файла машиночитаемы и расположены в корне, но сообщают о разном. robots.txt — это сигнал предпочтений краулера и контроля доступа. sitemap.xml — это сигнал обнаружения URL. llms.txt — это объясняющий и навигационный сигнал.
| Сигнал | Основная роль | Типичный читатель | Интерпретация в этом исследовании |
|---|---|---|---|
robots.txt | Задать предпочтения краулера и ограничения на уровне путей. | Поисковые краулеры, AI-краулеры, архивные краулеры, обычные боты. | Сигнал управления и доступа. |
sitemap.xml | Перечислить обнаруживаемые URL для систем индексирования. | Поисковые системы и индексирующие пайплайны. | Сигнал обнаружения. |
llms.txt | Дать краткий контекст сайта, важные ссылки, документацию, API, примеры и ссылки на политики. | LLM-приложения, AI-агенты, инструменты для разработчиков, retrieval-системы. | Сигнал объяснения и навигации. |
Рекомендации
Для сайтов, которые рассматривают llms.txt, самые сильные реализации в этом наборе данных и внешние данные по трафику указывают на практичный подход:
- Публикуйте
/llms.txtв корне и держите его доступным без логина, выполнения JavaScript, consent wall или редиректов вне пути. - По возможности отдавайте его как
text/plainилиtext/markdown. - Начните с краткого описания сайта, затем сгруппируйте ссылки по продукту, документации, API, ценам, changelog, примерам, поддержке, политикам и ресурсам компании.
- Предпочитайте канонические ссылки вместо исчерпывающих списков URL.
- Избегайте пустых символических файлов; в лучшем случае это слабый сигнал.
- Избегайте огромных недифференцированных дампов, если только нет сильного сценария машинного потребления и надежного пайплайна генерации.
- После публикации проверяйте финальный URL, тело ответа, тип контента, Markdown-структуру, число ссылок и размер файла.
Командам также стоит аккуратно формулировать ожидания. Доступные публичные эксперименты не доказывают, что llms.txt сам по себе повышает AI-реферальный трафик. Если команда хочет проверить бизнес-эффект, ей следует одновременно отслеживать переходы из LLM, цитируемые страницы, запросы ботов, свежесть индекса и изменения контента. Полезный эксперимент должен сравнивать сопоставимые группы страниц, по возможности удерживать контентные обновления постоянными и отдельно учитывать трафик конкретных платформ, таких как Perplexity, ChatGPT, Gemini, Claude и Bing/Copilot.
Ограничения
Это снимок на основе краулинга, а не вечная истина. Сайты могут добавлять, удалять или менять файлы llms.txt в любой момент. Некоторые домены могут блокировать автоматические запросы или вести себя по-разному в зависимости от географии, TLS-конфигурации, логики редиректов, user agent или защитных механизмов против ботов. Исследование тестировало только файлы на корневом уровне и не искало поддомены или нестандартные пути.
Скор качества и архетипы — это исследовательские инструменты, а не официальные метки соответствия. Тематический анализ основан на ключевых словах и должен читаться как ориентир. Исследование не доказывает, что какая-либо конкретная AI-платформа уже сейчас читает, соблюдает или использует llms.txt в продакшене.
Внешние данные по трафику, рассмотренные в этой версии, тоже имеют ограничения. Анализ Search Engine Land сильнее как осторожное многосайтовое наблюдение, чем как рандомизированный эксперимент. Результат Алибекова полезен как прозрачный кейс-стади на уровне сайта, но в нем нет контрольной группы, и он включает период, когда общий реферальный трафик заметно вырос. Эти источники помогают сформировать рамку спора, но не превращают этот краулинг в причинное исследование трафика.
Файлы и воспроизводимость
| Файл | Назначение |
|---|---|
crawl_llms_txt.py | Краулер для /llms.txt и /llms-full.txt. |
analyze_llms_txt.py | Основной анализ внедрения и генерация графиков. |
deep_analyze_llms_txt.py | Вторичный анализ по децилям рангов, TLD, тематическим сигналам, скору качества, архетипам и поведению при двухфайловой схеме. |
deep_dive_early_quality.py | Классификация ранних последователей и глубокий анализ качества реализации. |
data/llms_probe_results_top_10000.csv | Основной набор результатов краулинга. |
data/deep_analysis_top_10000.json | Сводка вторичного анализа. |
data/deep_early_quality_analysis.json | Категории ранних последователей, сравнение когорт по качеству, детали архетипов и кейс-стади. |
Источники
- The /llms.txt file, Jeremy Howard, 2024.
- HTTP Archive Web Almanac 2024 Methodology.
- Cloudflare Radar: Expanded AI insights.
- Cloudflare Radar AI Insights.
- Consent in Crisis: The Rapid Decline of the AI Data Commons, Data Provenance Initiative.
- Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation.
- Does llms.txt matter?, Search Engine Land, January 2026.
- The State of llms.txt Adoption, Rankability, June 2025.
- How LLMS.txt Increased AI Chat Traffic by 23%, Renat Alimbekov.
Исправления методологии, замечания по набору данных и предложения по дальнейшему анализу можно направлять на support@thunderbit.com. Этот отчет опубликован независимо от любой коммерческой позиции, которую занимает Thunderbit. Данные в этом отчете говорят сами за себя. — Исследовательская команда Thunderbit, май 2026 года.
Попробуйте Thunderbit для сбора и анализа веб-данных Get Started Free




