
Несколько месяцев назад коллега из нашей команды продаж задал мне вопрос, который я слышал уже десятки раз: «Если я собираю цены конкурентов с общедоступного сайта, меня правда могут привлечь к ответственности?» Он нашёл каталог контактов поставщиков, цены были аккуратно разложены по строкам, а ему нужна была всего лишь таблица. Сомнения были вполне реальными — и, честно говоря, обоснованными.
В Великобритании нет единственного «закона о веб-скрейпинге». Вместо этого на законность конкретного сбора данных влияют четыре пересекающиеся правовые рамки. Поэтому ответ почти всегда звучит как «зависит» — но это не значит, что всё безнадёжно запутано. В этом гайде я разберу, что на самом деле говорит закон, как он применяется к реальным ситуациям, какие санкции возможны и как оставаться в рамках требований.
Я много времени потратил на изучение этой темы для нашей команды в , и хочу поделиться тем, что узнал, чтобы вам не пришлось собирать картину по кусочкам из пяти разных блогов юридических фирм и одного треда на Reddit.
Что такое веб-скрейпинг (и зачем его используют британские компании)
Веб-скрейпинг — это использование программного обеспечения для автоматического сбора данных с веб-сайтов вместо утомительного копирования и вставки со страниц в таблицу.
Сама по себе эта техника нейтральна. Она не является по своей природе ни законной, ни незаконной. Важны то, что именно вы собираете, как вы это делаете и как потом используете данные.
Британские компании применяют скрейпинг для самых разных законных задач:
- Сравнение цен: например, PriceSpy UK с помощью автоматизированного веб-скрейпинга.
- Поиск лидов: отделы продаж собирают названия компаний, email и телефоны из открытых каталогов.
- Исследование рынка: аналитики отслеживают объявления о недвижимости, сайты вакансий и ассортимент конкурентов.
- Академические исследования: Управление национальной статистики получило более с сайтов супермаркетов в 2014–2015 годах.
- Обучение моделей ИИ: быстро растущий — и юридически пока не до конца урегулированный — сценарий использования.
Тренд очевиден. Опрос 500 лиц, принимающих решения (в том числе 200 в Великобритании), показал, что считают публичные веб-данные критически важными или очень важными для мировой экономики, а получают их как минимум ежедневно.
При этом также заявили, что их организации беспокоит отсутствие чёткого регулирования. Именно поэтому и появилась эта статья.
Законен ли веб-скрейпинг в Великобритании? Прямой ответ
В британском праве нет нормы, которая бы полностью запрещала веб-скрейпинг. Но несколько законов регулируют, как именно его можно проводить, и законность конкретного проекта зависит от четырёх факторов:
- Какие данные вы собираете (персональные или фактические/неперсональные)
- Как вы к ним получаете доступ (открытая страница или обход логина, CAPTCHA и других защит)
- Что написано в условиях сайта (запрещён ли автоматизированный доступ?)
- Как вы используете данные потом (внутренний анализ или коммерческая перепродажа)
Лучшее сравнение, которое я нашёл: веб-скрейпинг похож на фотографирование в общественном месте. Сделать снимок на улице само по себе не незаконно — но отдельные объекты, места, способы съёмки и последующее использование могут создать правовой риск. Со скрейпингом всё так же. Публичная доступность важна, но это далеко не вся история.
Недавняя консультация ICO по GenAI — одно из самых ясных официальных заявлений Великобритании о скрейпинге персональных данных. В ней говорится, что законный интерес остаётся для обучения генеративных моделей ИИ на основе персональных данных, собранных веб-скрейпингом, — но только если разработчик проходит жёсткую трёхчастную проверку. Это высокий порог, и он показывает, насколько серьёзно британские регуляторы относятся к скрейпингу данных.
Четыре закона Великобритании, которые применяются к веб-скрейпингу
Четыре перекрывающиеся правовые рамки — любая задача по сбору данных может задеть одну, две или все четыре.
UK GDPR и Закон о защите данных 2018 года
Если вы собираете персональные данные — имена, email, телефоны, IP-адреса, профили в соцсетях — применяется UK GDPR. «Публично доступные» данные не означают «свободные для использования».
Персональные данные, которые видны публично, всё равно остаются персональными данными.
Для коммерческого скрейпинга самым релевантным законным основанием обычно является законный интерес (статья 6) — но одной ссылки на него недостаточно. Нужно:
- определить конкретную законную цель;
- показать, что обработка необходима для этой цели;
- сопоставить ваш интерес с правами людей, чьи данные вы собираете.
Ответ ICO по GenAI особенно прямой: разработчики не должны считать, что одного лишь широкого общественного блага достаточно; им нужно обосновать, почему альтернативы скрейпингу не подходят, и использовать механизмы прозрачности, чтобы люди могли понимать и реализовывать свои права. Источник: .
Для B2B-лидогенерации логика та же. Отдел продаж может опираться на законный интерес при сборе публично указанных контактных данных компаний, но при этом всё равно должен документировать законный интерес, минимизировать объём собираемых полей, избегать данных особой категории, по возможности предоставлять информацию о конфиденциальности и уважать отказы.
Авторское право, права на базы данных и исключение TDM
Авторское право защищает оригинальный контент сайта: текст, изображения, описания товаров, статьи. Фактические данные вроде цен сами по себе обычно в меньшей степени затрагивают авторское право — но если вы копируете и публикуете защищённое выражение, это уже нарушение.
Права на базы данных для скрейпинга важнее, чем думает большинство. После Brexit Великобритания сохранила sui generis-права на базы данных по образцу ЕС, и извлечение «существенной части» защищённой базы — каталогов, товарных каталогов, списков на маркетплейсах — может нарушать право даже тогда, когда отдельные точки данных являются фактическими.
Исключение для текстового и дата-майнинга (TDM) по разрешает копирование для анализа текста и данных только при наличии законного доступа и если цель — некоммерческое исследование. Это очень узкая норма. Коммерческий скрейпинг, коммерческое обучение ИИ и коммерческая перепродажа наборов данных под неё не подпадают.
Правительство Великобритании рассматривало расширение этого исключения для обучения ИИ, но по состоянию на свой решило не вводить реформы, пока не будет уверено, что они соответствуют целям авторов, разработчиков ИИ и экономики Великобритании. В нынешнем режиме для копирования защищённых произведений в целях обучения ИИ обычно требуется разрешение, если только не применяется уже существующее исключение.
Условия использования сайта и договорное право
У большинства сайтов есть Условия использования (ToS), которые запрещают или ограничивают автоматизированный скрейпинг. Получив доступ к сайту, вы можете уже соглашаться с этими условиями — особенно если проходите через экран согласия (clickwrap). Соглашения browsewrap, где условия спрятаны за ссылкой в подвале страницы, оцениваются более индивидуально, но британские суды демонстрировали готовность применять ограничения ToS к скрейпингу. В споре суд признал видимые условия сайта обязательными в контексте screen scraping.
robots.txt — это не закон. Это машинно-читаемый сигнал от владельца сайта. Типичный файл выглядит так:
1User-agent: *
2Disallow: /account/
3Disallow: /checkout/
4Disallow: /private/
5Crawl-delay: 10Игнорирование robots.txt само по себе не делает скрейпинг незаконным, но суды и ICO рассматривают это как доказательство намерений владельца сайта. Игнорирование robots.txt повышает ваш юридический риск, особенно если оно сочетается с нарушением ToS или агрессивной частотой запросов.
Закон о неправомерном использовании компьютеров 1990 года
Вот этот закон людей действительно заставляет нервничать — и не зря. Он устанавливает уголовную ответственность. Раздел 1 касается несанкционированного доступа к компьютерным материалам (максимум ). Раздел 3 касается несанкционированных действий, нарушающих работу компьютера (максимум ).
Риск по CMA минимален, если данные действительно публичные и скрейпер не обходит технические барьеры. Риск растёт, если вы:
- обходите логин-стены, CAPTCHA или IP-блокировки;
- используете украденные учётные данные или создаёте фальшивые аккаунты;
- отправляете такой объём трафика, что это мешает работе целевого сервиса.
В Великобритании нет аккуратного американского правила в духе «публичные данные — свободная добыча». Поэтому британские рекомендации осторожнее: публичный доступ заметно снижает риск по CMA, но условия сайта, технические меры защиты и знание скрейпером о запретах всё ещё имеют значение.
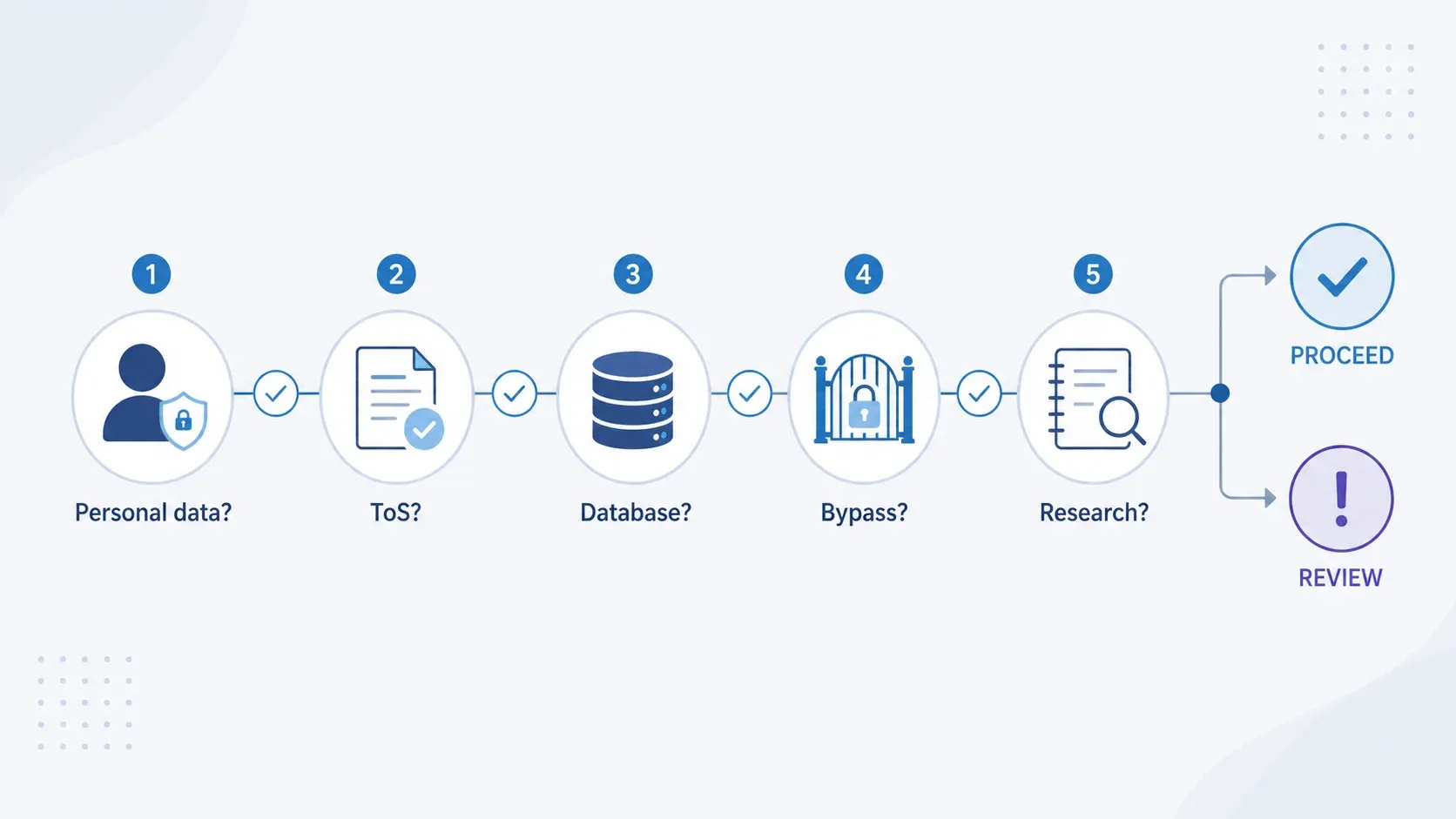
«Могу ли я легально собрать это?» — быстрый алгоритм принятия решения
Прежде чем что-то собирать, пройдите через эти пять контрольных точек. Это не юридическая консультация — просто 60-секундная первичная оценка риска.
| Контрольная точка | Если ДА | Если НЕТ |
|---|---|---|
| Данные являются персональными (имена, email и т. д.)? | Применяется UK GDPR. Определите законное основание, проведите LIA, минимизируйте поля, запланируйте прозрачность. | GDPR может не применяться, но проверьте другие факторы. |
| В ToS сайта прямо запрещён скрейпинг? | Риск нарушения договора. Рассмотрите API, лицензию или юридическую проверку. | Риск по договору ниже, но проверьте robots.txt. |
| Извлекается существенная часть базы данных? | Вероятно, нарушаются sui generis-права на базу данных. Подумайте о лицензии или более узком извлечении. | Авторское право всё равно может распространяться на отдельный скопированный контент. |
| Обходите логин, CAPTCHA или механизмы доступа? | Возможное уголовное правонарушение по CMA 1990. Остановитесь и получите юридическую оценку. | Риск по CMA ниже, если доступ действительно публичный. |
| Цель — некоммерческое исследование? | Может применяться исключение TDM по разделу 29A, если доступ законный. | Широкой коммерческой «гавани» в UK нет. Нужен полный анализ IP и договора. |
Эх, жаль, что никто не показал мне это, когда я только начинал разбираться в compliance для нашей команды. Это превращает юридическую сложность в структурированную самопроверку, которую можно пройти меньше чем за минуту.
Реальные сценарии: законен ли ваш конкретный скрейпинг в Великобритании?
Абстрактный закон — это одно. А людей на самом деле интересует: «Проблемы возникнут именно у моего проекта?»
Логично. Ниже — пять распространённых сценариев скрейпинга в Великобритании с краткой оценкой юридического риска для каждого.
Сбор цен на товары для сравнения
Один из самых распространённых — и часто самых низкорисковых — бизнес-сценариев. Цены являются фактическими данными, а автоматизированный сбор цен — именно так работают сайты вроде PriceSpy.
Но риск не исчезает полностью. Если целевой сайт запрещает скрейпинг в ToS, если вы копируете описания товаров или изображения, или если извлекаете существенную часть тщательно собранной базы товаров, могут возникнуть вопросы по договору, авторскому праву и правам на базы данных.
Уровень риска: НИЗКИЙ–СРЕДНИЙ
Ключевой шаг по compliance: собирать только фактические поля цены, не копировать дословные описания товаров, соблюдать ToS и robots.txt, использовать ограничение частоты запросов и не публиковать прямую копию каталога конкурента.
Коммерческая сборка и перепродажа данных
Самый рискованный коммерческий сценарий, без преувеличения. Вы превращаете чужие инвестиции в данные в продукт для продажи — и это может одновременно затронуть все четыре правовые опоры.
Уровень риска: ВЫСОКИЙ
Ключевой шаг по compliance: необходима юридическая проверка. Рассмотрите лицензионные соглашения с владельцами данных. Если продукт включает персональные данные, добавьте оценку воздействия на защиту данных.
Извлечение бизнес-контактной информации для лидогенерации
Каждая команда продаж, с которой я общался, делает что-то в этом духе: собирает email, телефоны и названия компаний из каталогов. Подвох в том, что бизнес-контактные данные часто являются персональными. Email конкретного сотрудника — это персональные данные, даже если он публично указан.
Уровень риска: СРЕДНИЙ
Ключевой шаг по compliance: провести оценку законного интереса (LIA), по возможности собирать только рабочие, а не личные контактные данные, документировать законное основание и предусмотреть механизм отказа. Инструменты вроде могут снизить риск доступа в этом сценарии, потому что работает в браузере пользователя — оно получает доступ только к тому, что пользователь уже и так видит, без обхода защитных механизмов.
Академический анализ или анализ данных для портфолио
Если вы занимаетесь действительно некоммерческим исследованием, у вас самый сильный путь через исключение по авторскому праву: раздел 29A CDPA, при условии законного доступа.
Уровень риска: НИЗКИЙ (если это действительно некоммерческое исследование)
Ключевой шаг по compliance: документировать некоммерческую цель, указывать источники, по возможности анонимизировать или агрегировать данные и не распространять заново защищённый авторским правом контент или персональные данные.
Сбор контента для обучения модели ИИ
Это тот вопрос, который в 2026 году задают все, — и ответ по-прежнему не очень удобный. ICO рассматривает веб-скрейпинг персональных данных для обучения как высокорисковую скрытую обработку. В отчёте правительства Великобритании за 2026 год не появилось широкого коммерческого исключения TDM.
Уровень риска: СРЕДНИЙ–ВЫСОКИЙ
Ключевой шаг по compliance: лицензирование, проверка происхождения набора данных, анализ авторского права, фильтрация персональных данных, документирование законного основания и постоянный мониторинг изменений политики Великобритании.
Таблица-сводка по сценариям
| Сценарий | Какие законы затрагиваются | Уровень риска | Ключевой шаг по compliance |
|---|---|---|---|
| Мониторинг цен на товары | ToS, права на базы данных, авторское право | Низкий–средний | Собирать фактические поля, учитывать сигналы сайта |
| Коммерческая перепродажа данных | Все четыре правовые рамки | Высокий | Нужны юридическая проверка и лицензия |
| B2B-лидогенерация | UK GDPR, ToS | Средний | Провести LIA, минимизировать персональные данные |
| Академическое исследование | Авторское право (исключение TDM), GDPR при наличии персональных данных | Низкий | Сохранять некоммерческую цель, не публиковать заново |
| Обучение модели ИИ | UK GDPR, авторское право, права на базы данных | Средний–высокий | Лицензировать данные, документировать законное основание, следить за политикой |
Великобритания, США и ЕС: чем отличается право на веб-скрейпинг
Если вы работаете только в Великобритании, этот раздел можно пропустить. Но большинство компаний, с которыми я общаюсь, скрейпят международно — или как минимум сайты, размещённые в других юрисдикциях. Различия важнее, чем кажется.
This paragraph contains content that cannot be parsed and has been skipped.
Практический вывод: если вы скрейпите в нескольких юрисдикциях, ориентируйтесь на самое строгое применимое право. В США доступ к публичным данным по hiQ более разрешительный, но это не «разрешение на всё» — hiQ в итоге всё равно запретили заниматься скрейпингом LinkedIn, и компания заплатила $500K. В ЕС архитектура TDM шире благодаря DSM Directive. Великобритания находится где-то посередине — без широкого коммерческого исключения TDM, с сильными правами на базы данных и активным регулятором.
Санкции и правоприменение: что реально происходит, если вас поймают
Расплывчатые предупреждения о «штрафах» и «юридических проблемах» никому не помогают. Вот конкретные цифры.
Штрафы по UK GDPR
Максимальное наказание: , в зависимости от того, что больше.
Реальный пример: Clearview AI получила штраф от ICO в 2022 году за сбор изображений лиц из социальных сетей Великобритании. Трибунал первой инстанции отменил решение по юрисдикционным основаниям, но удовлетворил апелляцию ICO и направил дело на новое рассмотрение. В декабре 2025 года ICO отметил, что у Clearview было .
Уголовные наказания по Computer Misuse Act
- Раздел 1 (несанкционированный доступ): до
- Раздел 3 (несанкционированное нарушение работы): до
Уголовное преследование за обычный сбор публичных страниц случается крайне редко.
Риск резко меняется, когда поведение похоже на взлом, неправомерное использование учётных данных, обход CAPTCHA или создание помех для сервиса.
Авторское право и права на базы данных
Гражданско-правовые убытки плюс судебный запрет. За умышленное коммерческое нарушение возможна и уголовная ответственность, но большинство споров о скрейпинге рассматриваются как гражданские иски.
Нарушение договора (ToS)
Гражданские убытки, отключение аккаунта, IP-блокировка. На практике это обычно самый распространённый способ реагирования — и часто именно с него всё начинается.
Сводка по тяжести санкций
| Правовая рамка | Максимальное наказание | Вероятность для типичного бизнес-скрейпинга | Реальный пример |
|---|---|---|---|
| UK GDPR | £17,5 млн или 4% мирового оборота | Средняя, если персональные данные в большом масштабе; низкая для неперсональных | Штраф Clearview AI £7,5 млн |
| CMA, раздел 1 | 2 года лишения свободы | Низкая для публичных страниц; выше при обходе защит | Рекомендации CPS по несанкционированному доступу |
| CMA, раздел 3 | 10 лет лишения свободы | Низкая, если только трафик не мешает работе систем | Примеры помех уровня DDoS |
| Авторское право / права на базы данных | Убытки и судебный запрет | Средняя при копировании защищённого контента или тщательно собранных баз | Линия дел Ryanair и BHB |
| Нарушение ToS | Убытки, прекращение доступа, блокировка | Высокая как практический путь правоприменения | Споры о screen scraping в деле Ryanair |
Как правильный инструмент для скрейпинга снижает ваш юридический риск
Сам по себе инструмент не делает незаконный скрейпинг законным. Но он может убрать риск, которого можно было избежать.
По моему опыту, разница между инструментом, который уважает сигналы сайта, и инструментом, который агрессивно обходит всё подряд, — это часто разница между обычным проектом по данным и юридической головной болью.
Уважение robots.txt и сигналов сайта
Ответственный инструмент должен облегчать проверку и соблюдение robots.txt до начала скрейпинга. Хотя этот файл не имеет обязательной силы, суды и ICO рассматривают его соблюдение как признак добросовестности. В пользователям советуют собирать общедоступные данные и уважать robots.txt и условия использования.
Скрейпинг в браузере vs. в облаке
С юридической точки зрения это важно. Скрейпинг в браузере получает доступ только к тому, что пользователь видит в своей авторизованной сессии, то есть по сути автоматизирует то, что вы делали бы вручную. Облачный скрейпинг отправляет запросы с серверов, что быстрее для публичных сайтов, но со стороны сайта может выглядеть как «автоматизированный доступ».
поддерживает оба режима. Скрейпинг в браузере подходит для сайтов, где нужен вход в систему, снижая риск «несанкционированного доступа» по CMA, а облачный скрейпинг хорошо работает для общедоступных страниц e-commerce, где важна скорость. Такой двойной подход позволяет подбирать метод скрейпинга под юридический профиль риска каждого сайта.
Нет обхода механизмов защиты
Инструмент, который работает внутри браузера и не взламывает CAPTCHA или login wall, изначально менее рискован с точки зрения Computer Misuse Act. Расширение Thunderbit для Chrome работает в сессии браузера пользователя — оно получает доступ только к тому, что пользователь уже видит.
Прозрачный экспорт данных (поддержка compliance с GDPR)
Thunderbit экспортирует данные напрямую в Excel, Google Sheets, Airtable или Notion. Пользователь сам контролирует, куда уходят данные. Это помогает с прозрачностью по GDPR и документированием законного основания: вы точно знаете, какие данные собрали и куда они были отправлены. Никакой скрытой обработки или удержания данных со стороны инструмента.
Ограничение частоты запросов и ответственное использование
Агрессивные объёмы запросов могут спровоцировать применение раздела 3 CMA (несанкционированное нарушение работы). Ограничение частоты запросов — это не просто техническая рекомендация, а ещё и юридическая мера защиты. Ответственные инструменты не перегружают серверы, а значит снижают и правовой риск, и вероятность того, что ваш IP заблокируют.

Практический чек-лист compliance для веб-скрейпинга в Великобритании
Пройдите его перед тем, как что-то собирать:
- Прочитайте Условия использования сайта и политику допустимого использования.
- Проверьте файл robots.txt и зафиксируйте, запрещены ли нужные пути.
- Определите, являются ли нужные вам данные персональными. Если да — установите законное основание по UK GDPR.
- Оцените, не извлекаете ли вы «существенную часть» базы данных.
- Убедитесь, что вы не обходите технические средства доступа (CAPTCHA, логины, лимиты запросов).
- Если цель — некоммерческое исследование, задокументируйте это, чтобы воспользоваться исключением TDM.
- Используйте ограничение частоты запросов. Не перегружайте целевой сервер.
- Документируйте всё: законное основание, проверку ToS, собранные поля данных, места экспорта, срок хранения.
- Если есть сомнения, получите юридическую консультацию у solicitor, специализирующегося на защите данных и интеллектуальной собственности.
Этот чек-лист не заменяет мнение юриста, но даёт надёжную стартовую рамку и показывает вашу добросовестность, если позже возникнут вопросы.
Ключевые выводы
- Веб-скрейпинг в Великобритании не является незаконным — но он регулируется четырьмя пересекающимися правовыми рамками: UK GDPR, авторским правом/правами на базы данных, договорным правом и Computer Misuse Act.
- Законность любого сбора зависит от того, что именно вы собираете, как получаете доступ, что говорят условия сайта и как вы потом используете данные.
- Скрейпинг персональных данных несёт наибольшую нагрузку по compliance. Законный интерес обычно является единственным рабочим законным основанием, и для него нужна задокументированная балансировка интересов.
- В Великобритании нет широкого коммерческого исключения TDM. Коммерческое обучение ИИ и перепродажа наборов данных связаны с высоким риском без лицензирования.
- Перед стартом используйте приведённые выше алгоритм принятия решения и таблицу сценариев, чтобы оценить свою ситуацию.
- Выбирайте инструменты, которые соответствуют лучшим практикам compliance: доступ через браузер, отсутствие обхода CAPTCHA, прозрачный экспорт данных и ограничение частоты запросов. создан с учётом этих принципов — но ответственность за соблюдение закона всегда остаётся на пользователе.
- Если сомневаетесь, задокументируйте свою логику и поговорите с solicitor. Стоимость юридического заключения почти всегда ниже, чем стоимость расследования ICO.
Часто задаваемые вопросы
Законно ли собирать общедоступные данные в Великобритании?
В целом да — сбор общедоступных данных менее рискован, чем сбор данных из закрытых или частных источников. Но «публично доступно» не означает «можно использовать как угодно». UK GDPR всё ещё может применяться к публичным персональным данным, авторское право — к скопированным фрагментам выражения, права на базы данных — к тщательно собранным коллекциям, а ToS могут ограничивать автоматизированный доступ.
Могу ли я собирать email и телефоны с британских сайтов?
Если это персональные данные (а email и телефоны обычно именно они), вам нужно законное основание по UK GDPR. Законный интерес — самое распространённое основание для B2B-лидогенерации, но вы должны провести балансировку интересов, минимизировать объём собираемых данных и предусмотреть механизм отказа. Сбор личных контактных данных (мобильных номеров, личных email) несёт гораздо больший риск, чем сбор данных из деловых каталогов.
В чём разница между веб-скрейпингом и веб-краулингом по британскому праву?
С юридической точки зрения существенной разницы нет — закон смотрит на действия, а не на ярлык. Crawling обычно означает обнаружение или индексацию страниц; scraping — извлечение структурированных данных. И то и другое связано с автоматизированным доступом к сайтам и подпадает под те же правовые рамки.
Делает ли robots.txt скрейпинг незаконным?
Нет. robots.txt не имеет обязательной юридической силы. Однако игнорирование этого файла повышает риск, потому что суды и ICO рассматривают его как доказательство намерений владельца сайта. Если вы игнорируете robots.txt, а ToS сайта ещё и прямо запрещают скрейпинг, вы накапливаете факторы риска — и защищать такую позицию намного сложнее.
Могут ли в Великобритании привлечь к уголовной ответственности за веб-скрейпинг?
Только если вы обходите механизмы защиты (CAPTCHA, логины, IP-блокировки) или причиняете ущерб компьютерной системе по . Обычный сбор действительно общедоступных данных в разумных объёмах, без технического обхода, крайне маловероятно приведёт к уголовному преследованию. Риск резко растёт, когда действия начинают напоминать взлом или умышленное нарушение работы сервиса.
Узнать больше