

Оптимизация запросов к спискам Apollo — это не просто техническая задача, а по-настоящему важный навык для тех, кто работает с новостными данными в реальном времени, автоматическим сбором новостей или с высоконагруженными процессами продаж и операций. Я не раз видел, как медленный запрос к списку превращал удобную панель в узкое место: отдел продаж смотрит на бесконечные индикаторы загрузки, а операционные команды в спешке ищут обходные пути в таблицах. В мире, где 60% рабочего времени продавцов уже уходит на задачи, не связанные с продажами, важна буквально каждая миллисекунда.
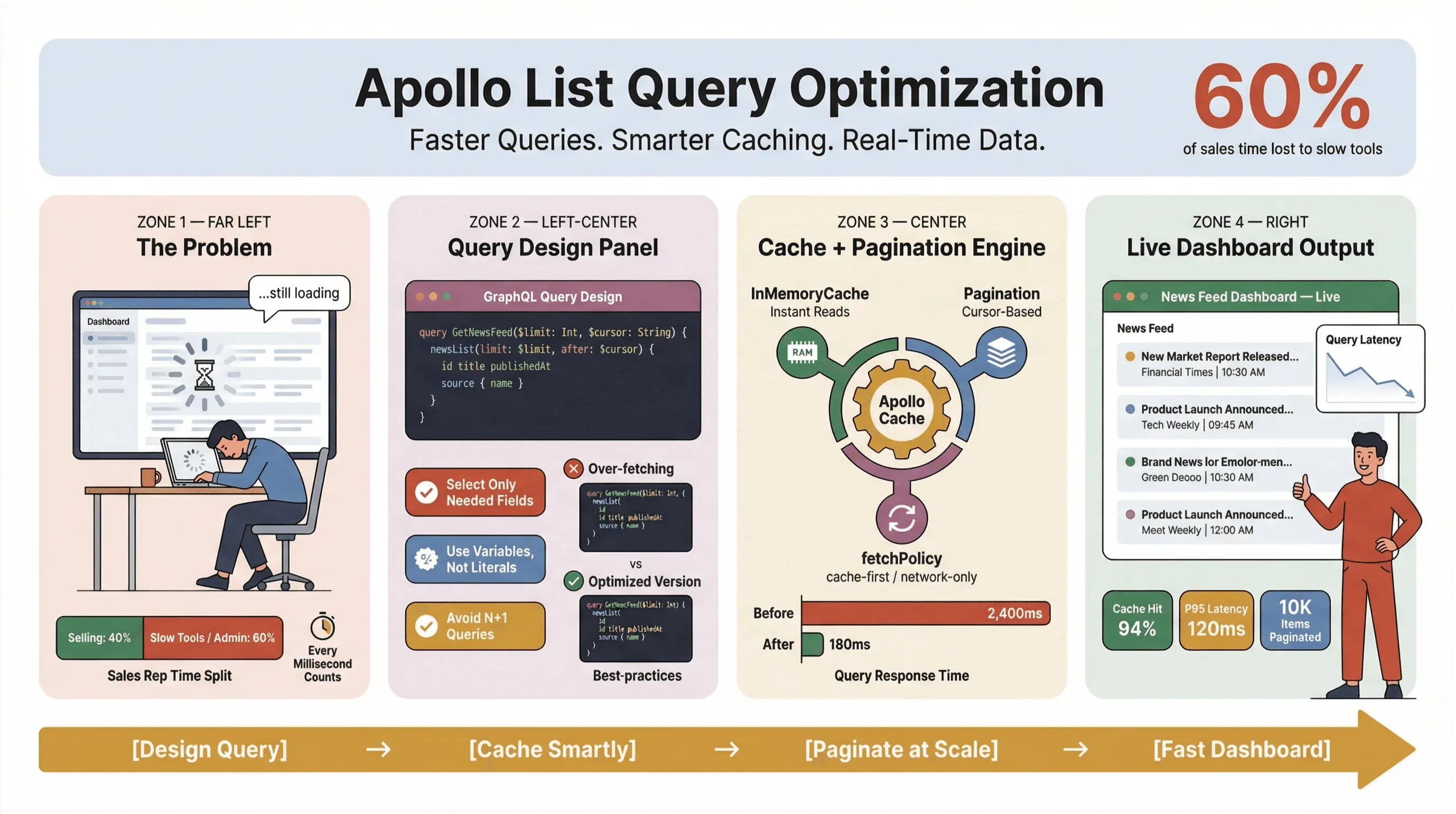
Так как же сделать так, чтобы запросы списка в Apollo Client оставались быстрыми, надежными и стабильными даже при больших объемах данных — особенно если вы собираете новости, отслеживаете лиды или поддерживаете критически важные дашборды? В этом руководстве я разберу практики, которые хорошо показывают себя в продакшене: проектирование запросов, кэширование, пагинацию и подключение no-code-инструментов вроде Thunderbit для автоматизации рутинного сбора новостей.
--- Если вы разработчик, продакт-менеджер или просто тот человек, на которого все смотрят, когда дашборд начинает тормозить, — это ваш рабочий план по повышению производительности списков в Apollo GraphQL.
Попробуйте Thunderbit для автоматического сбора новостей
Зачем оптимизировать запросы списков Apollo? (apollo client list performance, optimize apollo list queries)
Давайте честно: никто не любит ждать загрузки заголовков новостей или списка лидов. В бизнес-среде — особенно там, где используют автоматический сбор новостей или данные в реальном времени — медленные запросы списков Apollo не просто раздражают пользователей; они стоят денег, тормозят принятие решений и возвращают людей к ручной работе. Регулярные исследования Slack Workforce Lab показывают, что офисные сотрудники стабильно тратят около трети, а в более свежих отчетах уже почти 40% рабочего дня на рутинные задачи с низкой ценностью, часто потому, что их инструменты дробят работу между медленными интерфейсами.
Вот что происходит, когда запросы списков не оптимизированы:
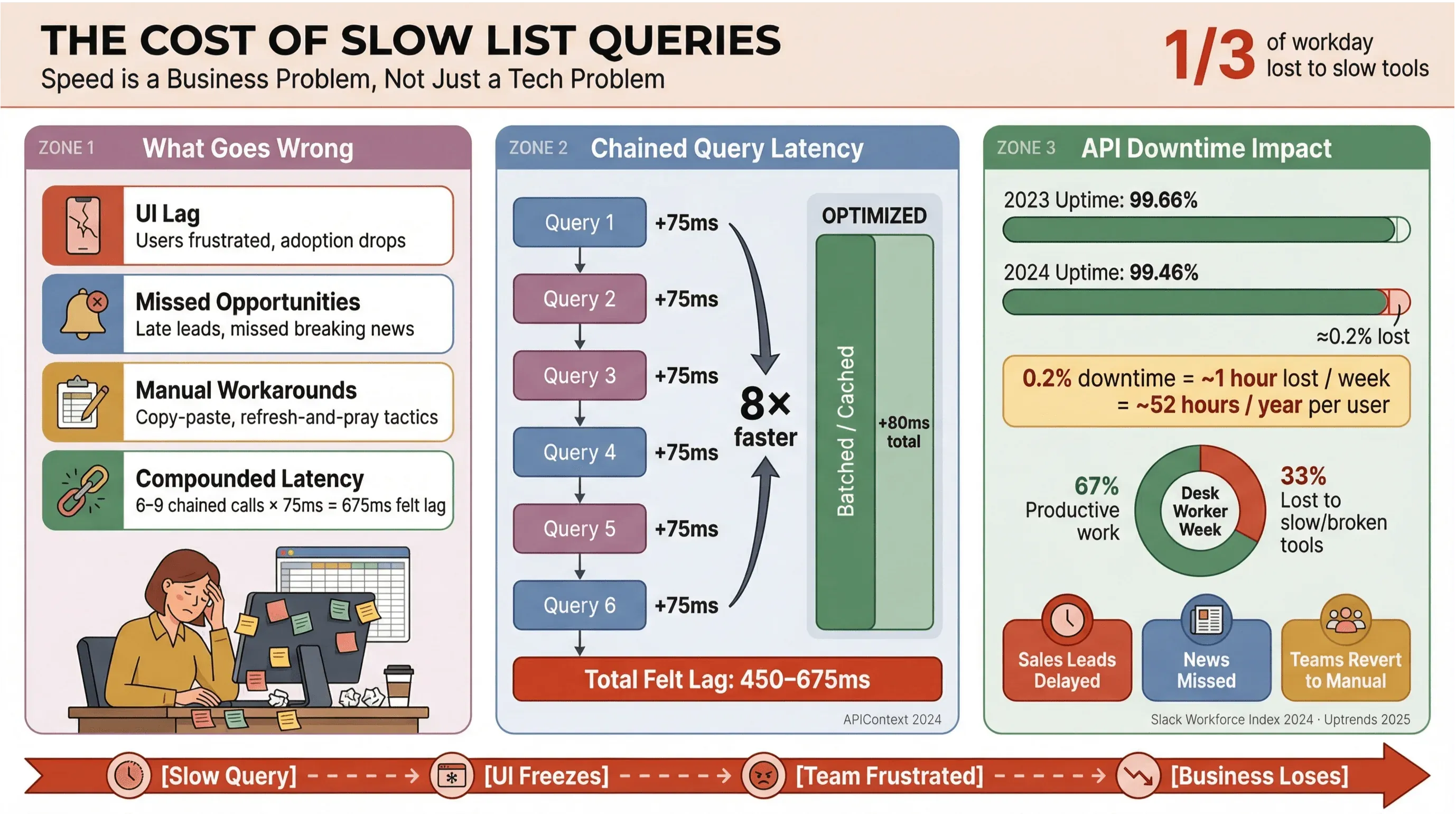
- Тормозит интерфейс: пользователи сталкиваются с задержками, что вызывает раздражение и снижает вовлеченность.
- Упущенные возможности: в продажах или мониторинге новостей даже несколько секунд задержки могут стоить горячего лида или пропущенной срочной новости.
- Ручные обходные решения: команды снова возвращаются к копированию и вставке, таблицам и тактике «обнови и молись».
- Накопление задержки: каждый медленный API-вызов суммируется — если ваш процесс запускает 6–9 зависимых запросов, умеренная задержка 75 мс на запрос может вырасти в 450–675 мс заметного лага (APIContext).
И дело не только в скорости. Простой API растет: средний uptime за год снизился с 99,66% до 99,46% — а для приложений с большим количеством списков это почти час потери продуктивности в неделю. Если ваш бизнес зависит от новостных данных в реальном времени, такой риск слишком дорог.
Как выбрать правильную структуру данных и поля (apollo graphql list best practices)
Одна из самых распространенных ошибок, которую я вижу (и, да, сам ее допускал), — относиться к каждому запросу списка как к запросу деталей. В GraphQL у вас есть возможность получать ровно то, что нужно, так что используйте это преимущество. Избыточная выборка данных — главный враг производительности, особенно в инструментах для новостного скрапинга и дашбордах в реальном времени.
Подбор полей для автоматического сбора новостей
Допустим, вы строите новостную ленту. Действительно ли вам в запросе списка нужны полный текст статьи, все теги, комментарии и биография автора? Скорее всего, нет. Вот разница:
Эффективный запрос списка:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Неэффективный запрос списка (так делать не стоит):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Первый запрос — легкий и быстрый, идеально подходит для сортировки, фильтрации и рендера строк. Второй? Это замаскированный запрос деталей, который тянет большой объем данных и замедляет все вокруг (спецификация GraphQL, рекомендации Apollo).
Совет: используйте двухуровневый подход — в списке запрашивайте только легкие поля, а тяжелые данные (например, полный текст или NLP-обогащение) подгружайте только тогда, когда пользователь открывает элемент или наводит на него курсор.
Как ускорить запросы с помощью Apollo Client Cache (apollo client list performance)
Кэш Apollo Client — это, пожалуй, самый мощный рычаг для повышения производительности запросов списков. При грамотной настройке он позволяет:
- Мгновенно отдавать повторные запросы без обращения к сети
- Снижать нагрузку на сервер и расходы на API
- Обеспечивать плавную навигацию назад/вперед и смену фильтров
Но кэш — это не магия. Он требует настройки и дисциплины.
Как задать эффективные политики кэширования
Apollo поддерживает несколько политик получения данных:
| Политика | Что делает | Лучший сценарий для новостных списков |
|---|---|---|
| cache-first | Сначала читает из кэша, при отсутствии идет в сеть | Повторный просмотр списков, переключение фильтров, навигация назад/вперед |
| network-only | Всегда запрашивает данные из сети | Ручное обновление, «самые свежие заголовки» |
| cache-and-network | Сначала возвращает кэш, затем обновляет данными из сети | Быстрый первый рендер + фоновое обновление (отлично для новостных лент) |
| no-cache | Всегда делает запрос, ничего не сохраняет в кэш | Разовые чувствительные запросы (редко подходит для списков) |
Для новостных данных в реальном времени мне нравится cache-and-network — пользователь сразу видит результаты, а затем данные обновляются в фоне. Только следите за мерцанием интерфейса, если при обновлении записи меняют порядок (issue на GitHub).
Советы по настройке кэша:
- Используйте стабильные ID (
idили_id) для нормализации (документация Apollo). - Настраивайте размер кэша и сборку мусора для больших списков (управление памятью).
- Не храните огромные ненормализованные объекты в
ROOT_QUERY— это может замедлить приложение (сообщение сообщества).
Как реализовать пагинацию и ограничить количество элементов (apollo graphql list best practices)
Если вы загружаете сразу сотни или тысячи новостных материалов или лидов, вы сами создаете себе проблемы. Пагинация — это не просто UX-улучшение, а необходимое условие производительности.
Apollo поддерживает как пагинацию по offset, так и пагинацию по cursor. Сравнение такое:
| Тип пагинации | Плюсы | Минусы | Лучше всего подходит для |
|---|---|---|---|
| Offset-based | Простая, легко реализуется | При изменении данных могут появляться пропуски или дубли | Небольшие или неизменяемые списки |
| Cursor-based | Стабильная, хорошо работает при изменениях данных | Слегка сложнее в реализации | Новостные ленты, большие списки |
Для большинства списков новостей в реальном времени или списков лидов лучший выбор — cursor-based pagination. Она сохраняет целостность данных, даже когда появляются новые записи или старые удаляются (GraphQL Foundation).
Советы по пагинации в Apollo:
- Настройте
keyArgs, чтобы контролировать ключи кэша для полей с пагинацией (документация). - Реализуйте функцию
merge, чтобы объединять страницы в кэше. - Используйте
fetchMore, чтобы подгружать дополнительные страницы без перезаписи предыдущих результатов.
Практические паттерны пагинации для инструментов сбора новостей
Типичный интерфейс для новостного скрапинга будет:
- Показывать последние 20–50 заголовков (только легкие поля)
- Загружать еще по прокрутке или по клику «Следующая страница»
- Подтягивать детали только при необходимости
Так интерфейс остается быстрым, API — спокойным, а пользователи — продуктивными.
Интеграция Thunderbit для автоматического сбора новостей
Теперь поговорим о главном: откуда вообще берутся все эти структурированные новостные данные? Здесь на сцену выходит Thunderbit.
Установите расширение Thunderbit для Chrome Get Started Free
Thunderbit — это no-code AI web scraper в формате расширения для Chrome, который умеет извлекать заголовки новостей, URL, источники, авторов, даты публикации, краткие описания и изображения практически с любого сайта — без единой строки кода. Я видел, как команды используют Thunderbit, чтобы полностью автоматизировать процесс сбора новостей и превращать неструктурированные веб-страницы в чистые данные, которые можно сразу отправить в базу данных или GraphQL API.
Как сочетать Thunderbit и Apollo для новостей в реальном времени
Вот рабочий процесс, который я особенно люблю для sales- и ops-команд, которым нужны актуальные новости:
- Слой извлечения: используйте шаблон News Scraper в Thunderbit, чтобы по расписанию собирать структурированные новостные данные с целевых сайтов.
- Слой хранения: сохраняйте собранные данные в базе, оптимизированной под быстрый доступ.
- Слой GraphQL: публикуйте через API поле списка
newsFeedи поле деталейnewsArticle(id). - Слой клиента: используйте Apollo Client для получения списка (легкие поля, с пагинацией), а детали загружайте только по необходимости.
Этот конвейер «собрать → сохранить → запросить» означает, что ваши запросы Apollo всегда работают со свежими, структурированными данными — без ручного копипаста и хрупких скриптов.
Бонус: Thunderbit также может обогащать списки дополнительными полями, например тональностью или категорией, с помощью AI-подсказок для полей, делая вашу новостную ленту еще умнее.
Пошаговое руководство: оптимизация запросов списков Apollo
Готовы применить это на практике? Вот мой рабочий чек-лист по оптимизации запросов списков Apollo:
-
Упростите запросы
- Запрашивайте только поля, нужные для отображения списка (title, URL, timestamp и т. д.).
- Переносите тяжелые поля (полный текст, изображения, обогащение) в запросы деталей.
-
Внедрите пагинацию
- Для больших или динамичных списков используйте cursor-based pagination.
- Настройте
keyArgsиmerge, чтобы кэш работал корректно.
-
Используйте кэш Apollo
- Нормализуйте сущности с помощью стабильных ID.
- Выбирайте подходящую политику получения данных (
cache-and-networkособенно хорош для новостей). - Подбирайте размер кэша и сборку мусора под ваш объем данных.
-
Подключите автоматическое извлечение данных
- Используйте Thunderbit для автоматизации сбора новостей и поддержания актуальности данных.
- Выгружайте структурированные данные напрямую в базу данных или таблицу.
-
Контролируйте и отлаживайте
- Используйте Apollo Client Devtools, чтобы анализировать запросы, кэш и производительность.
- Следите за большими записями кэша, чрезмерным количеством отслеживаемых запросов и подтормаживанием интерфейса.
- Отслеживайте p95/p99 задержки и частоту ошибок (New Relic, Uptrends).
Мониторинг и устранение проблем с производительностью запросов
Devtools Apollo здесь незаменимы. С их помощью вы можете:
- Просматривать активные запросы и состояние кэша
- Находить дублирующиеся запросы или чрезмерное количество подписок на изменения
- Выявлять крупные объекты в кэше и проблемы с нормализацией
Если вы видите лаги интерфейса или медленные обновления, проверьте:
- Слишком большие запросы списков — их нужно сократить
- Некорректную нормализацию кэша — исправьте ID
- Проблемы с объединением страниц — проверьте
keyArgsиmerge
И не забывайте измерять tail latency, а не только средние значения. Именно там обычно и скрывается реальная боль пользователей.
Сравнение традиционного и AI-подхода к сбору новостей
Будем честны: раньше сбор новостных данных означал написание кастомных скриптов, возню с headless-браузерами и надежду, что верстка сайта не изменится за ночь. Теперь с AI-инструментами вроде Thunderbit весь процесс можно автоматизировать — без кода и без стресса.
| Подход | Сильные стороны | Ограничения для бизнес-пользователей |
|---|---|---|
| Скриптовый скрапинг | Полная гибкость, низкая стоимость при масштабе | Требует постоянной поддержки и времени инженеров |
| Управляемые платформы для скрапинга | Быстрый старт, берут на себя антибот-защиту | Все равно нужна настройка, стоимость растет с объемом |
| AI-извлечение (Thunderbit) | Хорошо справляется со сложной версткой, не требует кода | Результаты нужно проверять, нужна интеграция со схемой |
| Визуальные no-code скраперы | Доступны неразработчикам | Могут ломаться при изменениях интерфейса, ограничены в масштабе |
| Инфраструктура прокси/разблокировки | Обходит блокировки, поддерживает высокий поток | Все равно нужна логика извлечения, есть риски соблюдения правил |
Юридическое замечание: сбор общедоступных данных, как правило, законен, но всегда соблюдайте условия использования сайтов и ограничения по частоте запросов (Reuters).
Главное о лучших практиках Apollo GraphQL для списков
Подведем итоги:
- Оптимизируйте под скорость и ясность: сокращайте запросы списков, используйте пагинацию и активно применяйте кэш.
- Структура имеет значение: запрашивайте только нужное — тяжелые поля переносите в запросы деталей.
- Кэш — ваш союзник: используйте нормализацию и политики Apollo, чтобы отдавать данные мгновенно.
- Автоматизируйте сбор: инструменты вроде Thunderbit делают сбор новостей и обогащение списков доступными каждому.
- Измеряйте и улучшайте: используйте Devtools и observability-дашборды, чтобы заранее находить узкие места.
Для команд продаж, операций и новостей эти практики означают меньше ожидания, больше действий — и гораздо меньше сообщений в Slack в духе «почему это так медленно?».
Заключение: что делать дальше для оптимизации запросов списков Apollo
Если вы все еще используете тяжелые, непагинированные или плохо совместимые с кэшем запросы списков, сейчас самое время провести аудит и обновить подход. Начните с малого: сократите набор полей, добавьте пагинацию и настройте кэш. Затем перейдите на следующий уровень — подключите инструменты автоматического извлечения, такие как Thunderbit, чтобы данные всегда оставались свежими и полезными для работы.
Хотите углубиться? Изучите документацию Apollo, блог Thunderbit или присоединяйтесь к сообществу Apollo за практическими советами и разбором проблем. А если вы готовы автоматизировать сбор новостей, попробуйте шаблон News Scraper от Thunderbit — это настоящий прорыв для тех, кому нужны данные в реальном времени без лишней головной боли.
Используйте шаблон News Scraper от Thunderbit
Если после прочтения вы сделаете только одну вещь: сократите набор полей в запросе списка, добавьте cursor-based pagination и выберите разумную политику получения данных. Уже эти три изменения обычно переводят запрос из заметно медленного в практически незаметный — и освобождают вас для работы с данными, а не с экраном загрузки.
FAQ
1. Почему запросы списков Apollo тормозят в дашбордах новостей или продаж в реальном времени?
Запросы могут становиться медленными, если они тянут слишком много данных, не используют пагинацию или неправильно кэшируются. В высокочастотных сценариях, таких как мониторинг новостей, даже небольшие задержки накапливаются, вызывая лаги интерфейса и снижение продуктивности.
2. Как лучше всего структурировать запросы списков Apollo для автоматического сбора новостей?
Запрашивайте только те поля, которые нужны для отображения списка (например, title, URL, timestamp). Тяжелые поля, такие как полный текст статьи или изображения, переносите в запросы деталей, а результаты разбивайте на страницы, чтобы уменьшить объем данных и ускорить работу.
3. Как кэш Apollo Client улучшает производительность списков?
Кэш Apollo хранит ранее полученные данные, что позволяет мгновенно отвечать на повторные запросы. Правильная нормализация кэша и политики получения данных, например cache-and-network, могут заметно ускорить отображение списков и снизить нагрузку на сервер.
4. Как Thunderbit помогает с новостным скрапингом и интеграцией с Apollo?
Thunderbit — это no-code AI web scraper, который извлекает структурированные новостные данные с любого сайта. Его можно использовать для автоматизации сбора новостей, а затем передавать данные в базу или GraphQL API для работы с Apollo Client.
5. Какие инструменты использовать для мониторинга и отладки производительности запросов списков Apollo?
Apollo Client Devtools позволяют в реальном времени анализировать запросы, состояние кэша и производительность. Дополните это observability-дашбордами, такими как New Relic или Uptrends, чтобы отслеживать задержки и ошибки, и постепенно улучшайте структуру запросов для оптимального результата.
Хотите больше советов по веб-скрапингу, автоматизации и процессам с данными в реальном времени? Загляните в блог Thunderbit — там есть подробные разборы, инструкции и свежие материалы об AI-продуктивности.
Попробуйте Thunderbit AI Web Scraper Get Started Free
Узнайте больше
- Как оптимизировать списки Apollo для эффективного управления лидами
- Обогащение данных Apollo: возможности, преимущества и усиление с помощью AI
- Как освоить prospecting в Apollo: пошаговое руководство
- Как использовать пагинацию в веб-скрапере для эффективного извлечения данных
- Как использовать пагинацию в веб-скрапере для эффективного извлечения данных




