
Объём данных в интернете растёт буквально 폭발적으로 — и вместе с ним усиливается 압박 на команды, которым нужно держать темп рынка. Я не раз видел, как sales-отделы и операционные команды тратят больше времени на «укрощение» таблиц и бесконечный copy-paste данных с сайтов, чем на реальные решения. По данным Salesforce, менеджеры по продажам сегодня тратят , а Asana отмечает, что . Это десятки часов, которые улетают на ручной сбор данных — вместо того чтобы закрывать сделки или запускать кампании.
Но есть и хорошие новости: веб-скрейпинг стал по-настоящему 대중화, и чтобы пользоваться его преимуществами, не обязательно быть разработчиком. Ruby давно любят за автоматизацию извлечения данных из веба, а если добавить к нему современные ai web scraper-инструменты вроде , получается идеальная связка: гибкость для тех, кто пишет код, и простота «веб-скрейпинг без кода» для всех остальных. Ты маркетолог, e-commerce менеджер или просто устал от бесконечного copy-paste? Этот гид покажет, как уверенно работать с веб-скрейпинг с ruby и с ИИ — без необходимости писать код.
Что такое веб-скрейпинг на Ruby? Вход в мир автоматизированных данных
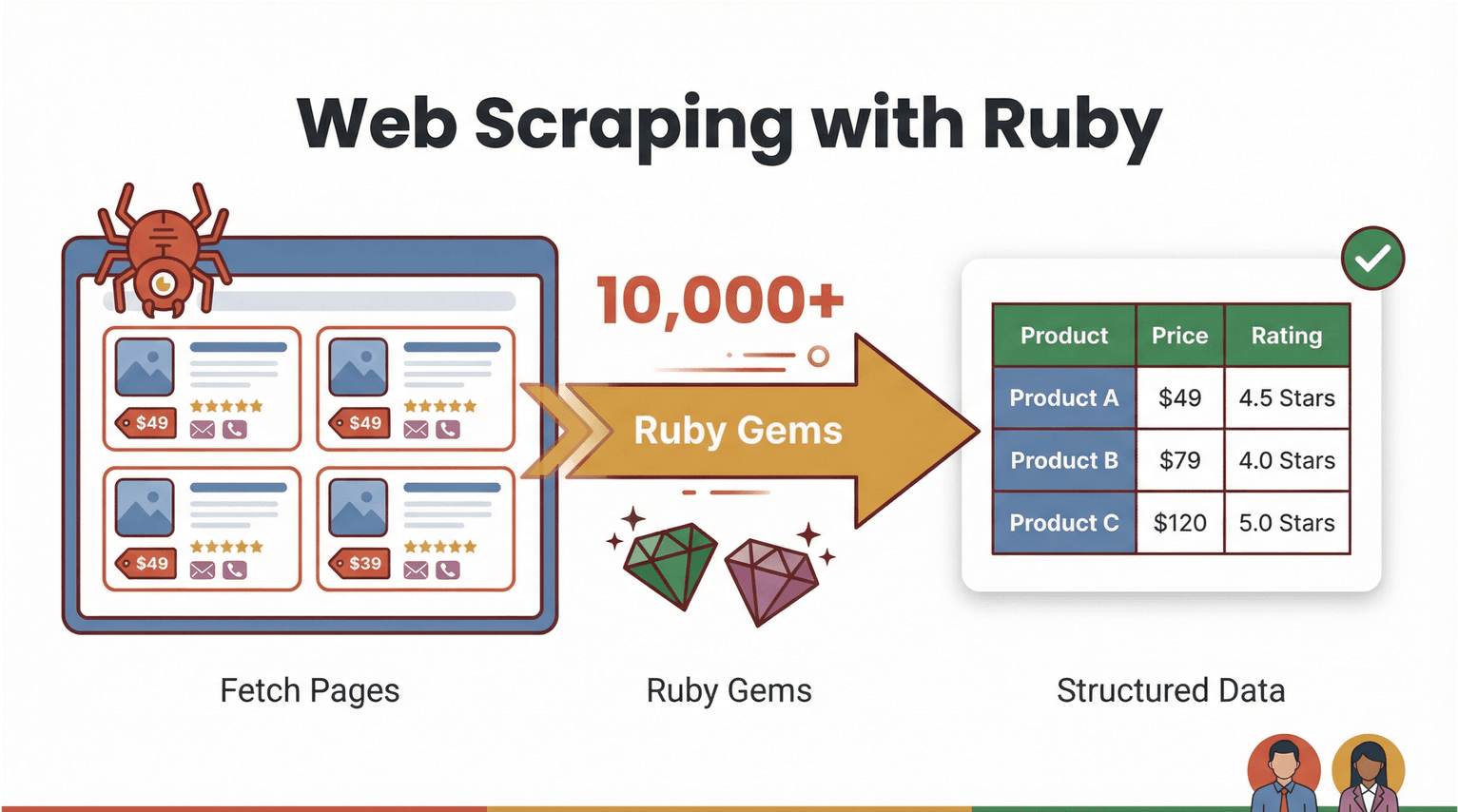
Начнём с базы. Веб-скрейпинг — это процесс, когда программа загружает веб-страницы и вытаскивает из них нужную инфу (например, цены, контакты или отзывы) в структурированный формат — вроде CSV или Excel. С Ruby это одновременно мощно и довольно просто: язык ценят за читаемый синтаксис и огромную экосистему «гемов» (라이브러리), которые делают автоматизацию максимально удобной ().
Как выглядит «веб-скрейпинг с Ruby» на практике? Представь, что тебе нужно собрать названия товаров и цены с интернет-магазина. На Ruby можно написать скрипт, который:
- Загружает страницу (например, через )
- Разбирает HTML и находит нужные элементы (с помощью )
- Выгружает результат в таблицу или базу данных
Но самое интересное — код нужен не всегда. AI-инструменты для веб-скрейпинга без кода, такие как , берут на себя «тяжёлую часть»: читают страницу, распознают поля и собирают аккуратные таблицы данных буквально в пару кликов. Ruby остаётся отличным «клеем» для автоматизации нестандартных процессов, а ai web scraper-решения открывают сбор данных и для бизнес-пользователей.
Почему веб-скрейпинг на Ruby важен для бизнес-команд

Давай честно: никто не мечтает проводить день за копированием и вставкой данных. Спрос на автоматизированное извлечение данных из веба растёт 엄청 быстро — и это абсолютно логично. Вот как веб-скрейпинг с ruby (и AI-инструменты) меняют бизнес-процессы:
- Лидогенерация: быстро собирать контакты из каталогов или LinkedIn для воронки продаж.
- Мониторинг цен конкурентов: отслеживать изменения цен по сотням SKU — без ручных проверок.
- Сбор товарного каталога: агрегировать характеристики и изображения для своего магазина или маркетплейса.
- Маркетинговые исследования: собирать отзывы, рейтинги или новости для анализа трендов.
Экономический эффект очевиден: автоматизация сбора данных экономит часы каждую неделю, снижает количество ошибок и даёт более свежие и надёжные данные. В производстве, например, , хотя объём данных всего за два года удвоился. Это огромный потенциал для автоматизации.
Коротко о том, какую пользу дают Ruby и ai web scraper-инструменты:
| Сценарий | Боль при ручной работе | Плюс автоматизации | Типичный результат |
|---|---|---|---|
| Лидогенерация | Сбор email по одному | Тысячи контактов за минуты | В 10 раз больше лидов, меньше рутины |
| Мониторинг цен | Ежедневные проверки сайтов | Плановые автоматические выгрузки | Актуальная ценовая аналитика |
| Сбор каталога | Ручной ввод данных | Массовое извлечение и форматирование | Быстрее запуск, меньше ошибок |
| Маркетинговые исследования | Читать отзывы вручную | Сбор и анализ в масштабе | Более глубокие и свежие инсайты |
И дело не только в скорости: автоматизация уменьшает число ошибок и делает данные более стабильными — что критично, когда .
Выбираем подход: Ruby-скрипты vs. AI Web Scraper-инструменты
Так что лучше: написать свой Ruby-скрипт или использовать ai web scraper без кода? Разложим по полочкам.
Скрипты на Ruby: максимум контроля, больше поддержки
В экосистеме Ruby есть гемы почти под любую задачу скрейпинга:
- : стандарт де-факто для парсинга HTML и XML.
- : для загрузки страниц и работы с API.
- : для сайтов с cookies, формами и навигацией.
- / : автоматизация реального браузера (полезно для сайтов на JavaScript).
С Ruby-скриптами ты получаешь полную свободу: своя логика, очистка данных, интеграции с внутренними системами. Но вместе с этим приходит и поддержка: сайт поменял верстку — скрипт может 깨지다 (сломаться). А если ты не дружишь с кодом, придётся пройти порог входа.
AI Web Scraper и no-code инструменты: быстро, удобно и устойчиво к изменениям
Современные no-code решения вроде реально меняют правила игры. Вместо кода ты:
- Открываешь расширение Chrome
- Нажимаешь «AI Suggest Fields», чтобы ИИ сам определил, что извлекать
- Жмёшь «Scrape» и выгружаешь данные
ИИ Thunderbit подстраивается под изменения на сайте, умеет ходить по подстраницам (например, карточкам товара) и экспортирует данные прямо в Excel, Google Sheets, Airtable или Notion. Отличный вариант для бизнес-пользователей, которым важен результат без лишней возни.
Сравнение «лоб в лоб»:
| Подход | Плюсы | Минусы | Кому подходит |
|---|---|---|---|
| Скрипты на Ruby | Полный контроль, своя логика, гибкость | Сложнее старт, нужна поддержка | Разработчикам, продвинутым пользователям |
| AI Web Scraper | Без кода, быстрый запуск, адаптация к изменениям | Меньше тонкой настройки, есть ограничения | Бизнес-пользователям, ops-командам |
Тренд очевиден: сайты становятся сложнее (и «защитнее»), поэтому ai web scraper-инструменты всё чаще становятся основным выбором для бизнес-задач.
Старт: настраиваем окружение для веб-скрейпинга на Ruby
Если хочешь попробовать скрипты на Ruby, начнём с настройки. Хорошая новость: Ruby легко ставится и работает на Windows, macOS и Linux.
Шаг 1: Установите Ruby
- Windows: скачайте и следуйте инструкциям. Обязательно установите MSYS2 для сборки нативных расширений (это нужно, например, для Nokogiri).
- macOS/Linux: используйте для управления версиями. В терминале:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Актуальную стабильную версию смотрите на странице загрузок Ruby: .)
Шаг 2: Установите Bundler и нужные гемы
Bundler помогает управлять зависимостями:
1gem install bundlerСоздайте Gemfile для проекта:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Затем выполните:
1bundle installТак ты получишь воспроизводимое окружение, готовое к скрейпингу.
Шаг 3: Проверьте установку
Попробуй в IRB (интерактивной консоли Ruby):
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONЕсли выводится номер версии — всё ок, работает.
Пошагово: ваш первый веб-скрейпер на Ruby
Разберём реальный пример — соберём данные о книгах с , сайта, созданного специально для практики.
Ниже простой Ruby-скрипт, который извлекает названия, цены и наличие:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#{BASE_URL}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #{rows.length} rows to books.csv"Скрипт проходит по страницам, парсит HTML, вытаскивает данные и сохраняет их в CSV. Файл books.csv можно открыть в Excel или Google Sheets.
Частые проблемы:
- Если ругается на отсутствующие гемы — проверь Gemfile и выполни
bundle install. - Если сайт подгружает данные через JavaScript, понадобится автоматизация браузера (Selenium или Watir).
Ускоряем сбор данных с Thunderbit: AI Web Scraper в деле
Теперь — о том, как может прокачать процесс на новый уровень, причём в формате веб-скрейпинг без кода.
Thunderbit — это , который позволяет извлекать структурированные данные с любого сайта буквально в два клика. Как это выглядит:
- Откройте расширение Thunderbit на нужной странице.
- Нажмите “AI Suggest Fields”. ИИ просканирует страницу и предложит оптимальные колонки (например, «Название товара», «Цена», «Наличие»).
- Нажмите “Scrape”. Thunderbit соберёт данные, обработает пагинацию и при необходимости перейдёт по подстраницам.
- Экспортируйте результат прямо в Excel, Google Sheets, Airtable или Notion.
Сильная сторона Thunderbit — умение работать со сложными и динамическими страницами без хрупких селекторов и без кода. А если нужен гибридный процесс, можно сначала извлечь данные через Thunderbit, а затем дополнительно обработать или обогатить их Ruby-скриптом.
Совет: функция скрейпинга подстраниц — настоящая 꿀기능 (находка) для e-commerce и недвижимости. Сначала собери список ссылок на товары, затем пусть Thunderbit сам зайдёт в каждую карточку и вытащит характеристики, изображения или отзывы — автоматически расширяя датасет.
Практический кейс: сбор цен и карточек товаров для e-commerce с Ruby и Thunderbit
Соберём всё в один рабочий сценарий для e-commerce команды.
Ситуация: нужно мониторить цены конкурентов и детали товаров по сотням SKU.
Шаг 1: Соберите основной список товаров через Thunderbit
- Откройте страницу со списком товаров конкурента.
- Запустите Thunderbit и нажмите “AI Suggest Fields” (например, Название, Цена, URL).
- Нажмите “Scrape” и экспортируйте в CSV.
Шаг 2: Обогатите данные через скрейпинг подстраниц
- В Thunderbit включите “Scrape Subpages”, чтобы зайти на страницу каждого товара и извлечь дополнительные поля (описание, наличие, изображения и т. д.).
- Экспортируйте расширенную таблицу.
Шаг 3: Дальше обработайте или проанализируйте в Ruby
- Используйте Ruby-скрипт для очистки, трансформации или анализа. Например:
- привести цены к одной валюте
- отфильтровать товары «нет в наличии»
- посчитать сводные метрики
Пример простого Ruby-кода, который оставляет только товары в наличии:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endИтог:
Ты превращаешь «сырые» веб-страницы в чистую, пригодную для действий таблицу — для анализа цен, планирования запасов или маркетинговых кампаний. И всё это — без единой строки кода именно для скрейпинга.
Без кода — не проблема: автоматизация извлечения данных для всех
Одна из сильных сторон Thunderbit — он даёт возможность работать с данными людям без технического бэкграунда. Не нужно знать Ruby, HTML или CSS: открыл расширение, доверил работу ИИ и выгрузил результат.
Порог входа: для Ruby-скриптов нужно освоить основы программирования и понимать структуру веб-страниц. В Thunderbit настройка занимает минуты, а не дни.
Интеграции: Thunderbit экспортирует данные прямо в привычные инструменты — Excel, Google Sheets, Airtable, Notion. Также можно настроить регулярные выгрузки по расписанию для постоянного мониторинга.
По опыту команд: я видел, как маркетинг, sales ops и e-commerce менеджеры автоматизируют с Thunderbit всё — от сборки списков лидов до отслеживания цен — и при этом не обращаются к IT.
Лучшие практики: как сочетать Ruby и AI Web Scraper для масштабируемой автоматизации
Хочешь надёжный и масштабируемый процесс? Вот рекомендации:
- Учитывайте изменения на сайтах: ai web scraper-инструменты вроде Thunderbit подстраиваются автоматически, а Ruby-скрипты придётся обновлять при изменении верстки.
- Запускайте по расписанию: используйте планировщик Thunderbit для регулярных выгрузок. Для Ruby — cron или системный планировщик задач.
- Работайте пакетами: при больших объёмах делите сбор на батчи, чтобы снизить риск блокировок и не перегружать систему.
- Приводите данные в порядок: перед анализом очищайте и валидируйте данные — экспорт Thunderbit уже структурирован, а в кастомных Ruby-скриптах часто нужны дополнительные проверки.
- Соблюдайте правила: собирайте только публичные данные, уважайте
robots.txtи учитывайте законы о приватности (особенно в ЕС — ). - Имейте план Б: если сайт слишком сложный или активно блокирует скрейпинг, ищите официальные API или альтернативные источники.
Когда что выбирать?
- Ruby-скрипты — когда нужен полный контроль, сложная логика или интеграция с внутренними системами.
- Thunderbit — когда важны скорость, простота и устойчивость к изменениям, особенно для разовых или регулярных бизнес-задач.
- Комбинация — для продвинутых сценариев: Thunderbit извлекает данные, Ruby делает обогащение, контроль качества и интеграции.
Заключение и ключевые выводы
Веб-скрейпинг с ruby всегда был «суперсилой» для автоматизации сбора данных. А теперь, с ai web scraper-инструментами вроде Thunderbit, эта суперсила стала доступна всем. Ты разработчик и хочешь гибкости — или бизнес-пользователь, которому нужен быстрый результат? В любом случае ты можешь автоматизировать извлечение данных, сэкономить часы ручной работы и принимать решения быстрее и точнее.
Что важно запомнить:
- Ruby отлично подходит для веб-скрейпинга и автоматизации, особенно с Nokogiri и HTTParty.
- AI Web Scraper-инструменты вроде Thunderbit делают извлечение данных доступным без навыков программирования — благодаря “AI Suggest Fields” и скрейпингу подстраниц.
- Связка Ruby + Thunderbit даёт лучшее из двух миров: быстрый сбор в стиле веб-скрейпинг без кода и кастомная автоматизация/аналитика.
- Автоматизация сбора веб-данных — сильная стратегия для продаж, маркетинга и e-commerce: меньше рутины, выше точность, больше инсайтов.
Готов начать? , попробуй простой Ruby-скрипт и оцени, сколько времени можно сэкономить. А если хочешь углубиться, загляни в — там много гайдов, советов и практических примеров.
FAQs
1. Нужно ли уметь программировать, чтобы использовать Thunderbit для веб-скрейпинга?
Нет. Thunderbit рассчитан на пользователей без технических навыков. Достаточно открыть расширение, нажать “AI Suggest Fields” — и ИИ сделает остальное. Данные можно экспортировать в Excel, Google Sheets, Airtable или Notion — без кода.
2. В чём главные преимущества Ruby для веб-скрейпинга?
Ruby даёт мощные библиотеки вроде Nokogiri и HTTParty для гибких, кастомных сценариев. Это отличный выбор для разработчиков, которым нужен полный контроль, своя логика и интеграции с другими системами.
3. Как работает функция Thunderbit “AI Suggest Fields”?
ИИ Thunderbit анализирует веб-страницу, находит наиболее релевантные поля (например, названия товаров, цены, email) и предлагает структурированную таблицу. Перед запуском можно отредактировать колонки.
4. Можно ли сочетать Thunderbit и Ruby-скрипты для продвинутых сценариев?
Да. Многие команды извлекают данные через Thunderbit (особенно со сложных или динамических сайтов), а затем дополнительно обрабатывают или анализируют их Ruby-скриптами. Такой гибридный подход удобен для кастомной отчётности и обогащения данных.
5. Законен ли веб-скрейпинг и безопасен ли он для бизнеса?
Веб-скрейпинг законен, если ты собираешь публично доступные данные и соблюдаешь условия использования сайта и законы о приватности. Всегда проверяй robots.txt и не собирай персональные данные без законных оснований — особенно для пользователей в ЕС, где действует GDPR.
Хочешь увидеть, как веб-скрейпинг может изменить твой процесс? Попробуй бесплатный тариф Thunderbit или поэкспериментируй с Ruby-скриптом уже сегодня. А если появятся вопросы, в и на есть множество уроков и подсказок, которые помогут освоить автоматизацию веб-данных — без кода.
Узнать больше