
Открою маленький секрет: интернет — это, по сути, самая большая библиотека в мире, только у большинства «книг» страницы как будто 딱 붙어버린 느낌이야. Каждый день я общаюсь с владельцами бизнеса, маркетологами и отделами продаж, которые точно знают: на веб-страницах спрятано золото — характеристики товаров, цены конкурентов, отзывы клиентов, контакты. Но вот извлечь текст с сайта и вытащить всё это наружу — тут и начинаются сложности. Я много лет работаю в SaaS и автоматизации и видел всё: и «марафоны копипаста», и «самодельные приключения на Python». Хорошая новость в том, что сегодня извлекать текст с сайта стало заметно проще (и куда менее болезненно) — благодаря новым ai web scraper инструментам и более умным расширениям для браузера.
В этом руководстве я разберу все практичные способы, которые знаю: от простого копирования вручную до продвинутых AI-решений вроде Thunderbit (да, это продукт моей команды, но я честно расскажу и о плюсах, и о минусах). Неважно, кто вы — мастер таблиц, разработчик, который пишет код на раз-два, или человек, уставший щуриться в экран: вы найдёте пошаговый вариант под свои задачи. Давайте «расклеим» эти цифровые книги и достанем нужный текст.
Что значит «извлечь текст с сайта»?
Когда мы говорим «извлечь текст с сайта», мы имеем в виду: забрать информацию, которую вы видите (а иногда и не видите) на веб-странице, и перенести её в удобный формат — например, в таблицу, базу данных или хотя бы в аккуратный документ Word. Но текст на сайтах бывает разным:
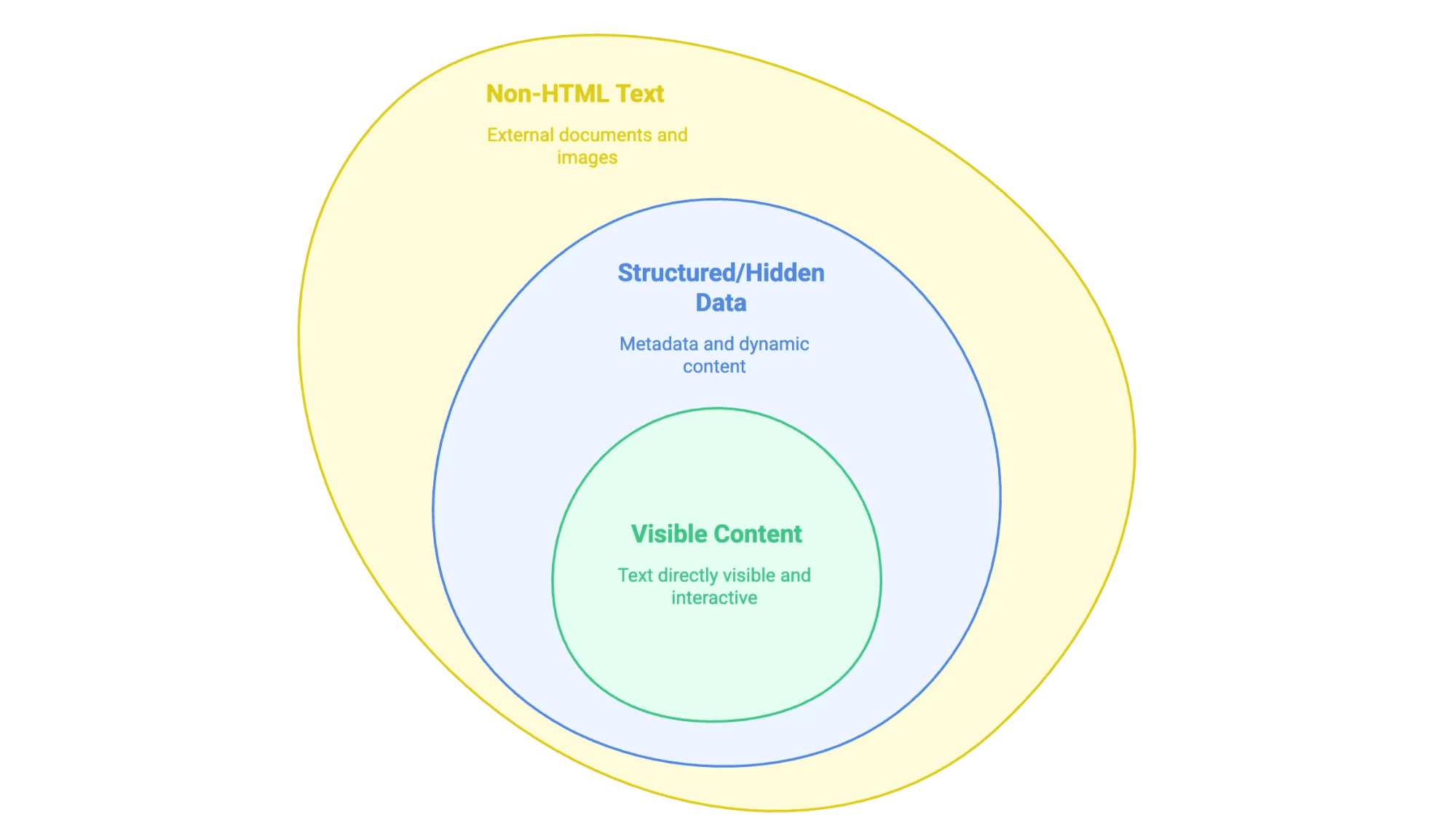
- Видимый контент: то, что можно выделить мышкой — основной текст, заголовки, списки, таблицы, описания товаров, статьи в блоге и т. д.
- Структурированные или скрытые данные: например, метаданные в тегах
<meta>, скрипты JSON-LD или информация, которую подгружает JavaScript и которая появляется только после клика или прокрутки. - Текст не в HTML: PDF, документы Word и даже изображения с текстом (например, сканы договоров или инфографика), которые размещены на сайте или встроены в него.
Ключевой момент — понять, какой тип данных вам нужен: от этого зависит подход к извлечению.
Зачем извлекать текст с сайта? Польза для бизнеса и сценарии применения
Скажем прямо: никто не вытаскивает текст с сайтов «просто ради удовольствия» (если только у вас не очень специфическое хобби). Компании делают это, потому что отдача ощутимая. Рынок ПО для веб-скрейпинга превысил $1 млрд в 2024 году и продолжает расти. Вот почему:
| Команда | Пример сценария | Выгода |
|---|---|---|
| Продажи | Сбор лидов и контактов из каталогов | Быстрее и качественнее поиск клиентов |
| Маркетинг | Извлечение статей конкурентов и SEO-данных | Анализ контентных пробелов, поиск трендов |
| Операции | Мониторинг цен на e-commerce площадках | Динамическое ценообразование, контроль остатков |
| Недвижимость | Агрегация объявлений и параметров объектов | Аналитика рынка, генерация лидов |
| Поддержка | Сбор отзывов и вопросов с форумов | Анализ тональности, раннее выявление проблем |
Несколько примеров из практики:

- Лидогенерация: один бизнес по поставкам для ресторанов собирал списки потенциальных клиентов за минуты вместо дней.
- Мониторинг конкурентов: ритейлеры вроде John Lewis увеличили продажи на 4% благодаря данным о ценах, собранным со страниц.
- SEO-аналитика: команды вытаскивают метатеги и ключевые слова, чтобы подкреплять стратегию данными.
А с AI-инструментами компании экономят 30–40% времени на сбор данных по сравнению с «классическими» подходами.
Ручные способы: основы копирования текста с сайта
Начнём с самого простого. Иногда нужно вытащить небольшой фрагмент — и никакие инструменты не обязательны.
Как извлечь текст вручную
- Копировать и вставить: откройте страницу, выделите текст и нажмите Ctrl+C (или правой кнопкой мыши > Copy). Затем вставьте в документ или таблицу.
- Сохранить страницу как: в браузере выберите File > Save Page As. Сохраните как “Webpage, HTML only”, чтобы получить исходный HTML, или иногда как .txt, чтобы сохранить только текст.
- Печать в PDF: в окне печати выберите “Save as PDF”. Затем откройте PDF и скопируйте текст (или используйте функцию «сохранить как текст» в PDF-ридере).
- Инструменты разработчика: правой кнопкой > Inspect или клавиша F12, чтобы открыть DevTools. Там можно посмотреть HTML-исходник, найти meta-теги или скрытый JSON и скопировать нужное.
Ограничения
Ручной способ подходит для разовых задач, но для чего-то большего превращается в кошмар. Он занимает много времени, даёт ошибки и не масштабируется. Я видел, как стажёры днями переносили таблицы построчно — такую работу не пожелаешь никому.
Расширения для браузера и онлайн-инструменты для извлечения текста
Хотите быстрее и удобнее? Для большинства бизнес-пользователей расширения и онлайн-сервисы — идеальный компромисс: без кода, без лишней возни, просто «наведи и нажми» (딱 클릭 한 번 느낌).
Почему это удобно?

- Быстрее, чем ручной копипаст
- Не нужно программировать
- Умеют работать с таблицами, списками, а иногда и с файлами
- Экспорт в Excel, Google Sheets, CSV и т. д.
Разберём самые популярные варианты.
Thunderbit: AI Web Scraper для быстрого и точного извлечения текста
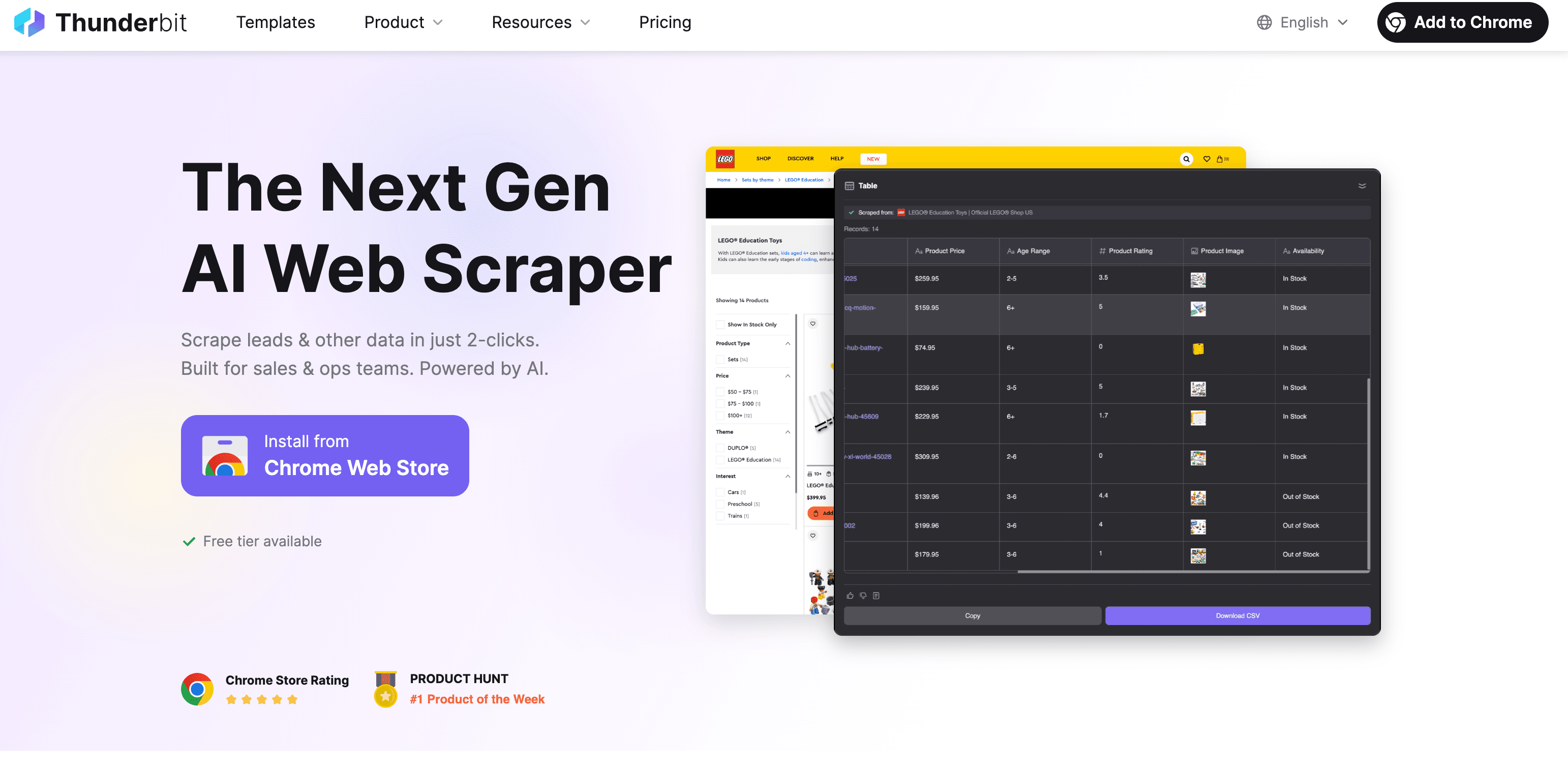
Да, я тут немного предвзят, но Thunderbit действительно сделан так, чтобы извлечение текста с сайта было таким же простым, как заказать еду на дом — 완전 간편하게. Как это работает:
Пошагово: как извлечь текст с Thunderbit
- Установите расширение для Chrome: скачайте Thunderbit в Chrome Web Store.
- Откройте нужный сайт: перейдите на страницу, откуда хотите забрать текст.
- Нажмите “AI Suggest Fields”: AI просканирует страницу и предложит поля (колонки) для извлечения — например, название товара, цену, описание и т. п.
- Проверьте и настройте: при необходимости отредактируйте предложенные поля или добавьте свои.
- Нажмите “Scrape”: Thunderbit соберёт данные, при необходимости пройдётся по подстраницам или страницам пагинации.
- Экспортируйте: выгрузите данные в Excel, Google Sheets, Airtable, Notion или в формате CSV/JSON. За экспорт доплачивать не нужно.
Извлечь текст с сайта с Thunderbit
Чем Thunderbit отличается?
- AI-подсказка полей: не нужно возиться с селекторами или кодом — AI сам понимает, что важно на странице (눈치 빠르게 캐치).
- Подстраницы и пагинация: нужно собрать детали с каждой карточки товара в категории? Thunderbit может переходить автоматически.
- Извлечение из PDF, изображений и документов: есть PDF-инструкция или картинка с характеристиками? Встроенный OCR в Thunderbit тоже вытащит текст.
- Поддержка многих языков: работает с 34 языками (клингонского пока нет, но мы стараемся).
- Бесплатный экспорт данных: никаких «стен оплаты», чтобы забрать результат.
- Сценарии: описания товаров, контакты, контент блогов, списки лидов — что угодно.
Как собирать данные о товарах и отзывах Amazon в 2025 году с помощью AI Get Started Free
Хотите посмотреть вживую? Загляните в наш Thunderbit Blog — там есть гайды вроде How to Scrape Amazon Products and Reviews in 2025 using AI.
Другие расширения и онлайн-инструменты
Коротко о нескольких решениях, которые часто встречаются:
- Web Scraper (webscraper.io): бесплатный, с интерфейсом «укажи и нажми», но требует привыкания. Подойдёт аналитикам, которые не боятся настроек: нужно собирать «sitemaps» и селекторы. Пагинацию поддерживает, а вот PDF и изображения — нет. Подробнее здесь.
- CopyTables: максимально простой — копирует HTML-таблицы в буфер обмена или сразу в Excel. Отлично для разового «быстро забрать таблицу», но работает только с таблицами и только по одной странице за раз. Как это устроено.
- ScraperAPI (ScraperAPI Pricing): вариант для разработчиков. Вы отправляете URL — сервис возвращает HTML (берёт на себя прокси, блокировки и т. п.), но разбор текста и извлечение данных всё равно нужно делать самостоятельно. Подробнее.
Как выбрать инструмент?
- Thunderbit: когда важны скорость, помощь AI и поддержка разных форматов (включая PDF/изображения).
- Web Scraper: когда вы готовы «покрутить настройки» и хотите больше контроля.
- CopyTables: когда нужна только таблица — быстро и без лишнего.
- ScraperAPI: когда вы пишете свой скрейпер кодом.
Автоматизированный веб-скрейпинг: программные способы извлечения текста
Если вы разработчик (или он у вас под рукой), собственный скрейпер даёт максимальный контроль. Базовый процесс обычно такой:
- HTTP-запрос: используйте Python
requestsили аналог, чтобы получить страницу. - Парсинг HTML: примените
BeautifulSoup,lxmlилиScrapy, чтобы найти нужный текст. - Извлечение и экспорт: достаньте данные, очистите и сохраните в CSV, JSON или базу данных.
Пример: Python + Beautiful Soup
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
for qt in quotes:
print(qt)
Плюсы и минусы
- Плюсы: максимальная гибкость, можно адаптироваться под любой сайт и тип данных, легко интегрировать в ваши системы.
- Минусы: нужны навыки программирования, регулярная поддержка, плюс придётся разбираться с антибот-защитой.
Когда это оправдано
- Нужно собрать тысячи (или миллионы) страниц.
- Сайт сложный (логины, многошаговые формы).
- Вы хотите встроить сбор данных прямо в продукт или бизнес-процесс.
Извлечение текста не из HTML: PDF, Word-документы и изображения
Сайты — это не только HTML: там полно PDF, документов и картинок с ценным текстом. Вот как с этим работать:
- Текстовые PDF: используйте Adobe Acrobat или библиотеки вроде
PDFMiner/PyPDF2для извлечения текста. - Сканированные PDF: понадобится OCR (оптическое распознавание) — например, Tesseract, Google Cloud Vision API или AWS Textract.
Документы Word/Excel
- Word:
python-docxдля чтения .docx. - Excel:
openpyxlилиpandasдля .xlsx.
Изображения
- OCR-инструменты: Tesseract (open-source) или облачные сервисы для более высокой точности. Лучше всего работают изображения хорошего качества (150–300 DPI).
Подход Thunderbit
Функция “Image/Document Parser” позволяет загрузить или дать ссылку на PDF, изображение или документ — AI извлечёт текст (и даже предложит колонки, если распознает таблицу). Не нужно переключаться между разными инструментами: файлы обрабатываются почти так же, как обычные веб-страницы.
Сравнение методов: какой способ извлечения текста подходит вам?
Короткая таблица для выбора:
| Метод | Простота | Масштабируемость | Нужны тех. навыки | Поддерживаемые типы данных | Лучше всего подходит для |
|---|---|---|---|---|---|
| Вручную (копипаст) | Очень просто | Низкая | Не нужны | Только видимый текст | Разовые, небольшие задачи |
| Расширения/инструменты | Просто–средне | Средняя | Низкие–средние | HTML, некоторые таблицы | Нетеx. пользователи, малые–средние объёмы |
| AI-инструменты (Thunderbit) | Очень просто | Высокая | Не нужны | HTML, PDF, изображения и др. | Бизнес-пользователи, смешанный контент |
| Программирование (код) | Сложно | Очень высокая | Высокие | Любые (при нужных библиотеках) | Разработчики, крупные проекты |
| Не-HTML (OCR) | Средне | Низкая–средняя | Средние | PDF, изображения, документы | Когда важны файлы/картинки |
Если вам нужен самый быстрый, гибкий и наименее нервный вариант — особенно для бизнес-задач — AI-инструменты вроде Thunderbit сложно превзойти. Но если требуется полный контроль или вы собираете данные в огромных объёмах, собственный код может быть логичнее.
Главное: начните извлекать текст с сайтов уже сегодня
- В интернете море ценных текстовых данных, но достать их бывает непросто.
- Ручные методы подходят только для совсем маленьких задач и не масштабируются.
- Расширения и AI Web Scraper инструменты вроде Thunderbit делают извлечение текста быстрым, точным и доступным всем — без программирования.
- Для не-HTML контента (PDF, изображения) выбирайте решения со встроенным OCR и разбором документов.
- Подбирайте метод под навыки команды, объём проекта и типы данных, которые вам нужны.
Попробовать Thunderbit AI Web Scraper бесплатно
Удачного скрейпинга — и пусть дни, когда вы живёте на Ctrl+C, станут редкостью. С правильными инструментами извлечение данных с сайтов превращается в плавный автоматизированный процесс, который освобождает время для действительно важных задач. Никаких бесконечных часов копирования и вставки — только умные и эффективные решения под рукой. Пора уходить от ручной рутины и переходить к более продуктивному будущему.
FAQs
Q1: Можно ли собирать данные с любого сайта?
A1: Не всегда. Некоторые сайты блокируют скрейперы или прямо запрещают сбор данных в условиях использования. Всегда сначала проверьте правила сайта.
Q2: Насколько точны AI-скрейперы?
A2: AI-скрейперы вроде Thunderbit обычно дают высокую точность, но для сложных или очень динамичных страниц иногда требуется небольшая настройка.
Q3: Нужны ли навыки программирования, чтобы пользоваться инструментами веб-скрейпинга?
A3: Нет. Thunderbit и многие расширения для браузера рассчитаны на пользователей без технического бэкграунда и не требуют навыков кодинга.
Q4: Какие данные можно извлечь из PDF или изображений?
A4: OCR-инструменты умеют распознавать текст, таблицы и даже «скрытые» элементы на сканах PDF и изображениях — это делает извлечение данных гораздо универсальнее.
Read More
- The definitive guide to text scraping
- How to Scrape Any Website Using AI
- Learn How to Use AI for Web Scraping
Попробовать AI Web Scraper Get Started Free




