В интернете реально море ценных данных — но большинство сайтов изначально не сделаны так, чтобы ты мог просто взять и «скачать всё». В 2025 году веб-скрейпинг из нишевой технарской фишки превратился в must-have для команд, которые мониторят цены, вакансии, недвижимость и конкурентов. Проблема в другом: GitHub буквально забит скрейпинг‑проектами. Одни сделаны по‑взрослому, другие — чистая боль, а третьи не трогали годами. Как выбрать то, что зайдёт именно тебе — особенно если ты не разработчик?
В этом гайде я разберу 15 лучших проектов для веб-скрейпинга на GitHub в 2025 году. Но это будет не просто «топчик списком»: я сравню их по сложности старта, соответствию задачам, поддержке динамических страниц, «здоровью» репозитория, вариантам экспорта данных и тому, для кого они вообще предназначены. А если тебе уже надоело воевать с кодом, покажу, почему no-code и AI‑инструменты вроде меняют правила игры для бизнес‑пользователей и людей без технического бэкграунда.
Как мы отобрали топ-15 проектов для веб-скрейпинга на GitHub
Давай честно: проекты на GitHub бывают очень разного «качества жизни». Одни обкатаны тысячами пользователей, другие — weekend‑эксперимент, который так и не стал продуктом. Для этого списка я отбирал решения, которые проходят по таким критериям:
- Звёзды GitHub и комьюнити: заметная популярность (от нескольких тысяч до 90k+ звёзд) и живые контрибьюторы.
- Свежая активность: инструменты, которые реально обновляются в 2025 году, а не превратились в «цифровые окаменелости».
- Документация и удобство: понятные шаги, примеры кода и адекватный порог входа.
- Практическое применение: используется в реальных бизнес‑ или исследовательских задачах, а не только в демо «hello world».
И поскольку веб-скрейпинг — не волшебная таблетка на все случаи, каждый проект я сравню по:
- Сложности установки и запуска: можно стартануть за пару минут или придётся страдать с драйверами и зависимостями?
- Соответствию задачам: e-commerce, новости, исследования или что-то ещё?
- Поддержке динамических страниц: потянет ли современные сайты на JavaScript?
- Состоянию проекта: активно живёт или последний коммит уже «достаточно взрослый, чтобы голосовать»?
- Экспорту данных: отдаёт бизнес‑готовые таблицы или только сырой HTML?
- Целевой аудитории: для новичков в Python, дата‑инженеров или команд без технарей?
Для каждого проекта я добавлю быстрые теги по этим критериям, чтобы ты сразу нашёл то, что подходит именно тебе — будь ты «код‑ниндзя» или просто хочешь выгрузить данные в Google Sheets.

Сложность установки и настройки: как быстро вы начнёте скрейпить?
Если по‑честному, главный барьер для большинства — банально запустить скрейпер и не утонуть в настройках. Я делю сложность так:
- Plug & Play (без конфигурации): поставил — и поехали. Минимум шагов, супер для новичков.
- Средний уровень (командная строка, минимум кода): нужно чуть‑чуть кода или работы в CLI, но это ок, если ты уже писал скрипты.
- Продвинутый уровень (драйверы, антибот, глубокий код): придётся настраивать окружение, драйверы браузера и иметь уверенные навыки Python/JS.
Вот как раскладываются топ‑проекты:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (для конечных пользователей после развёртывания)
- Средний уровень: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Продвинутый уровень: Heritrix, Apache Nutch (оба требуют Java, конфигов или тяжёлых стеков)
Если ты не разработчик, «Plug & Play» или no-code — твои лучшие друзья. Для остальных «средний уровень» означает: код писать придётся, но без хоррора — если только у тебя не аллергия на фигурные скобки.
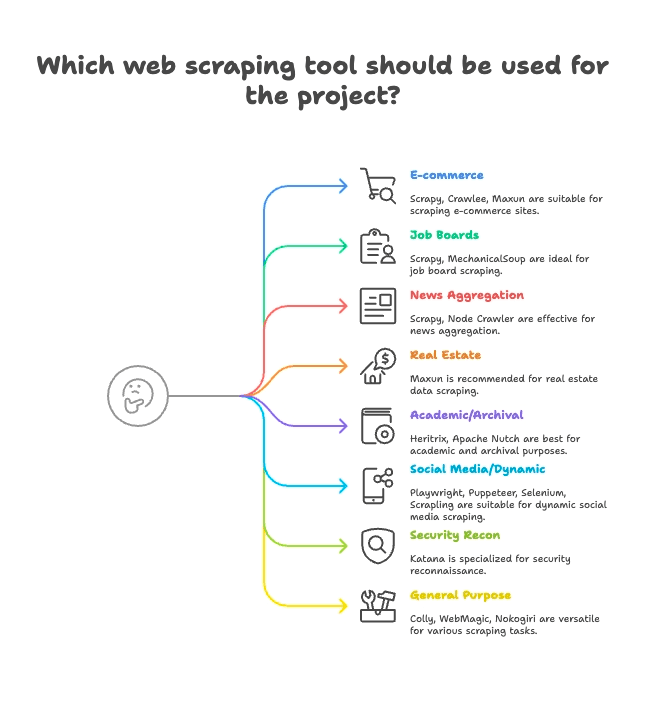
Группировка по задачам: выберите скрейпер под вашу сферу
Не все скрейперы сделаны под одну и ту же работу. Вот как я группирую топ-15 по самым подходящим сценариям:
E-commerce и мониторинг цен
- Scrapy: масштабный сбор товаров на множестве страниц
- Crawlee: универсал — и для статических, и для динамических магазинов
- Maxun: no-code, отлично для быстрого вытягивания списков товаров
Вакансии и рекрутинг
- Scrapy: хорошо тянет пагинацию и структурированные списки
- MechanicalSoup: подходит для сайтов с логином
Новости и агрегирование контента
- Scrapy: рассчитан на краулинг новостных сайтов в масштабе
- Node Crawler: быстрый вариант для статических новостных страниц
Недвижимость
- Thunderbit: AI‑скрейпинг подстраниц для объявлений + карточек объектов
- Maxun: визуальный выбор полей для данных по объектам
Академические исследования и веб-архивирование
- Heritrix: архивирование целых сайтов (WARC‑файлы)
- Apache Nutch: распределённый краулинг для исследовательских датасетов
Соцсети и динамический контент
- Playwright, Puppeteer, Selenium: сбор динамических лент, имитация логина
- Scrapling: «тихий» скрейпинг для сайтов с антибот‑защитой
Безопасность и разведка
- Katana: быстрый поиск URL, краулинг для задач безопасности
Универсальные решения
- Colly: высокопроизводительный скрейпинг на Go для любых сайтов
- WebMagic: Java‑фреймворк, гибкий для разных доменов
- Nokogiri: парсинг в Ruby для кастомных скриптов
Поддержка динамических страниц: умеют ли эти проекты скрейпить современные сайты?
Современные сайты обожают JavaScript. React, Vue, бесконечная прокрутка, AJAX — если ты хоть раз пытался скрейпить страницу и получал большое жирное «ничего», ты понимаешь эту боль.
Вот как каждый проект работает с динамическим контентом:
- Полная поддержка JS (headless‑браузер):
- Selenium: рулит реальными браузерами, выполняет весь JS
- Playwright: мультибраузерность, несколько языков, мощная поддержка JS
- Puppeteer: headless Chrome/Firefox, полноценный рендеринг JS
- Crawlee: переключается между HTTP и браузером (через Puppeteer/Playwright)
- Katana: опциональный headless‑режим для разбора JS
- Scrapling: интегрирует Playwright для «стелс»-скрейпинга с JS
- Maxun: использует браузер «под капотом» для динамики
- Без встроенной поддержки JS (только статический HTML):
- Scrapy: для JS нужен плагин Selenium/Playwright
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: по умолчанию получают только HTML и не умеют JS «из коробки»
Здесь особенно выделяется AI в Thunderbit: он сам находит и вытаскивает динамический контент — без ручной настройки, без плагинов и без мучений с селекторами. Достаточно нажать «AI Suggest Fields», и инструмент сделает тяжёлую работу даже на сайтах, перегруженных React. Подробнее — в .
Надёжность и «здоровье» проекта: будет ли этот скрейпер работать и в следующем году?
Нет ничего хуже, чем выстроить процесс вокруг инструмента и внезапно понять, что его забросили. Вот как дела у топ‑проектов:
- Активно поддерживаются (частые обновления):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Стабильные, но обновляются медленнее:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Режим поддержки (узкая специализация, медленно):
- Heritrix:
- Apache Nutch:
Thunderbit — это управляемый сервис, поэтому тебе не нужно переживать из‑за заброшенного кода. Команда держит AI, шаблоны и интеграции в актуальном состоянии — плюс есть онбординг, обучалки и поддержка, если что-то не взлетело.
Работа с данными и экспорт: от сырого HTML к данным, готовым для бизнеса
Собрать данные — это только половина истории. Важно получить их в формате, который удобен команде: CSV, Excel, Google Sheets, Airtable, Notion или даже через API.
- Встроенный структурированный экспорт:
- Scrapy: экспортеры CSV, JSON, XML
- Crawlee: гибкие datasets и хранилища
- Maxun: CSV, Excel, Google Sheets, JSON API
- Thunderbit:
- Ручная обработка данных (на стороне пользователя):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: сохранение/экспорт нужно допиливать кодом
- Специализированный экспорт:
- Heritrix: WARC (файлы веб‑архива)
- Apache Nutch: сырой контент в хранилище/индекс
Структурированный экспорт и интеграции Thunderbit — это огромная экономия времени для бизнес‑пользователей. Никаких танцев с CSV и «склеивающим» кодом — нажал кнопку, и данные готовы.
Кому подходит каждый проект для веб-скрейпинга на GitHub?
Давай без иллюзий: один инструмент не подходит всем. Вот кому я бы рекомендовал каждый вариант:
- Новичкам в Python: MechanicalSoup, Scrapling (если хочется поэкспериментировать)
- Дата-инженерам: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- Специалистам по QA и автоматизации: Selenium, Playwright, Puppeteer
- Исследователям в области безопасности: Katana
- Ruby-разработчикам: Nokogiri
- Java-разработчикам: WebMagic, Heritrix, Apache Nutch
- Пользователям без технических навыков / бизнес-командам: Maxun, Thunderbit
- Гроус-хакерам и аналитикам: Maxun, Thunderbit
Если ты не уверен в коде или просто хочешь быстро получить результат, Thunderbit и Maxun — самые приземлённые и практичные варианты. Остальным логичнее выбирать инструмент под язык и задачу.
Топ-15 проектов для веб-скрейпинга на GitHub: подробное сравнение
Переходим к каждому проекту — по группам задач, с быстрыми тегами и ключевыми фишками.
E-commerce, мониторинг цен и общий краулинг
— 57.1k stars, обновление в июне 2025

- Кратко: высокоуровневый асинхронный Python‑фреймворк для масштабного краулинга и скрейпинга.
- Запуск: средний уровень (Python‑код, async‑подход)
- Сценарии: e-commerce, новости, исследования, «пауки» на много страниц
- Поддержка JS: нет (нужен плагин Selenium/Playwright)
- Состояние проекта: активно поддерживается
- Экспорт данных: CSV, JSON, XML — встроено
- Кому подходит: разработчикам, дата‑инженерам
- Сильные стороны: масштабируемость, надёжность, куча плагинов. Для новичков порог входа ощутимый.
— 17.9k stars, 2025

- Кратко: мощная библиотека Node.js для скрейпинга статических и динамических сайтов.
- Запуск: средний уровень (код на Node/TS)
- Сценарии: e-commerce, соцсети, автоматизация
- Поддержка JS: да (интеграция Puppeteer/Playwright)
- Состояние проекта: очень активный
- Экспорт данных: гибко (datasets, storages)
- Кому подходит: командам разработки на JS/TS
- Сильные стороны: инструменты против блокировок, удобное переключение HTTP/браузерного режима.
— 13k stars, июнь 2025

- Кратко: open-source no-code платформа для извлечения данных с визуальным интерфейсом.
- Запуск: средний уровень (развёртывание сервера), простой (для конечных пользователей)
- Сценарии: универсально, e-commerce, бизнес‑скрейпинг
- Поддержка JS: да (браузер внутри)
- Состояние проекта: активный и растущий
- Экспорт данных: CSV, Excel, Google Sheets, JSON API
- Кому подходит: пользователям без технавыков, аналитикам, командам
- Сильные стороны: «укажи и нажми», многоуровневая навигация, можно хостить у себя.
Вакансии, рекрутинг и простые взаимодействия
— 4.8k stars, 2024

- Кратко: Python‑библиотека для автоматизации отправки форм и простой навигации.
- Запуск: Plug & Play (Python, минимум кода)
- Сценарии: сайты вакансий с логином, статические сайты
- Поддержка JS: нет
- Состояние проекта: зрелый, поддерживается «по минимуму»
- Экспорт данных: нет встроенного (вручную)
- Кому подходит: новичкам в Python, быстрым скриптам
- Сильные стороны: имитирует сессию браузера в несколько строк. Для динамических сайтов не годится.
Агрегация новостей и статический контент
— 6.8k stars, 2024

- Кратко: быстрый параллельный серверный краулер с парсингом через Cheerio.
- Запуск: средний уровень (callbacks/async в Node)
- Сценарии: новости, высокоскоростной скрейпинг статических страниц
- Поддержка JS: нет (только HTML)
- Состояние проекта: умеренная активность (v2 beta)
- Экспорт данных: нет встроенного (на стороне пользователя)
- Кому подходит: Node.js‑разработчикам, задачам с высокой параллельностью
- Сильные стороны: асинхронный краулинг, лимиты скорости, API в стиле jQuery.
Недвижимость, листинги и сбор данных с подстраниц

- Кратко: AI‑инструмент для no-code веб-скрейпинга, заточенный под бизнес‑задачи.
- Запуск: Plug & Play (расширение Chrome, настройка в 2 клика)
- Сценарии: недвижимость, e-commerce, продажи, маркетинг — по сути любой сайт
- Поддержка JS: да (AI автоматически распознаёт динамический контент)
- Состояние проекта: постоянно обновляется, управляемый сервис
- Экспорт данных: в один клик в Sheets, Airtable, Notion, CSV, JSON
- Кому подходит: пользователям без технавыков, бизнес‑командам, продажам и маркетингу
- Сильные стороны: AI «Suggest Fields», сбор с подстраниц, мгновенный экспорт, онбординг, шаблоны, .
Академические исследования и веб-архивирование
— 3k stars, 2023

- Кратко: архивный краулер Internet Archive масштаба «веб целиком».
- Запуск: продвинутый уровень (Java‑приложение, конфиги)
- Сценарии: веб‑архивирование, обход доменов целиком
- Поддержка JS: нет (только получение)
- Состояние проекта: поддерживается (медленно, но стабильно)
- Экспорт данных: WARC (файлы веб‑архива)
- Кому подходит: архивам, библиотекам, учреждениям
- Сильные стороны: масштабируемость, надёжность, соответствие стандартам. Не для точечного скрейпинга.
— 3k stars, 2024

- Кратко: open-source краулер для big data и поисковых систем.
- Запуск: продвинутый уровень (Java + Hadoop для масштаба)
- Сценарии: краулинг для поисковиков, большие данные
- Поддержка JS: нет (только HTTP)
- Состояние проекта: активный (Apache)
- Экспорт данных: сырой контент в хранилище/индекс
- Кому подходит: enterprise, big data, академические исследования
- Сильные стороны: плагинная архитектура, распределённый краулинг.
Соцсети, динамический контент и автоматизация
— ~30k stars, 2025

- Кратко: автоматизация браузера для скрейпинга и тестирования, поддерживает все основные браузеры.
- Запуск: средний уровень (драйверы, разные языки)
- Сценарии: JS‑насыщенные сайты, тестовые сценарии, соцсети
- Поддержка JS: да (полная автоматизация браузера)
- Состояние проекта: активный, зрелый
- Экспорт данных: нет (вручную)
- Кому подходит: QA‑инженерам, разработчикам
- Сильные стороны: несколько языков, имитация поведения реального пользователя.
— 73.5k stars, 2025

- Кратко: современная автоматизация браузера для скрейпинга и E2E‑тестов.
- Запуск: средний уровень (скрипты на разных языках)
- Сценарии: современные веб‑приложения, соцсети, автоматизация
- Поддержка JS: да (headless или реальный браузер)
- Состояние проекта: очень активный
- Экспорт данных: нет (на стороне пользователя)
- Кому подходит: разработчикам, которым нужен надёжный контроль браузера
- Сильные стороны: кросс‑браузерность, auto-wait, перехват сети.
— 90.9k stars, 2025

- Кратко: высокоуровневый API для автоматизации Chrome/Firefox.
- Запуск: средний уровень (скрипты на Node)
- Сценарии: headless‑скрейпинг Chrome, динамический контент
- Поддержка JS: да (Chrome/Firefox)
- Состояние проекта: активный (команда Chrome)
- Экспорт данных: нет (кастомно в коде)
- Кому подходит: Node.js‑разработчикам, фронтенд‑специалистам
- Сильные стороны: богатый контроль браузера, скриншоты, PDF, перехват сети.
— 5.4k stars, июнь 2025

- Кратко: «стелс»-скрейпинг с высокой производительностью и антибот‑функциями.
- Запуск: средний уровень (Python‑код)
- Сценарии: обход антибота, динамические сайты, скрытный сбор
- Поддержка JS: да (интеграция Playwright)
- Состояние проекта: активный, на острие
- Экспорт данных: нет встроенного (вручную)
- Кому подходит: Python‑разработчикам, «хакерам», дата‑инженерам
- Сильные стороны: stealth, прокси, антиблок, async.
Разведка безопасности
— 13.8k stars, 2025

- Кратко: быстрый веб‑краулер для задач безопасности, автоматизации и поиска ссылок.
- Запуск: средний уровень (CLI‑инструмент или Go‑библиотека)
- Сценарии: security crawling, поиск эндпоинтов
- Поддержка JS: да (опциональный headless‑режим)
- Состояние проекта: активный (ProjectDiscovery)
- Экспорт данных: текстовый вывод (списки URL)
- Кому подходит: исследователям безопасности, Go‑разработчикам
- Сильные стороны: скорость, параллельность, headless‑разбор JS.
Универсальный / многоцелевой скрейпинг
— 24.3k stars, 2025

- Кратко: быстрый и аккуратный фреймворк для скрейпинга на Go.
- Запуск: средний уровень (код на Go)
- Сценарии: высокопроизводительный универсальный скрейпинг
- Поддержка JS: нет (только HTML)
- Состояние проекта: активный, свежие коммиты
- Экспорт данных: нет встроенного (на стороне пользователя)
- Кому подходит: Go‑разработчикам, тем, кому важна производительность
- Сильные стороны: async, лимиты скорости, распределённый скрейпинг.
— 11.6k stars, 2023

- Кратко: гибкий Java‑фреймворк для краулинга в стиле Scrapy.
- Запуск: средний уровень (Java, простой API)
- Сценарии: общий веб-скрейпинг на Java
- Поддержка JS: нет (можно расширить через Selenium)
- Состояние проекта: активное сообщество
- Экспорт данных: подключаемые pipelines
- Кому подходит: Java‑разработчикам
- Сильные стороны: пул потоков, планировщики, антиблок.
— 6.2k stars, 2025

- Кратко: быстрый нативный HTML/XML‑парсер для Ruby.
- Запуск: Plug & Play (Ruby gem)
- Сценарии: парсинг HTML/XML в Ruby‑приложениях
- Поддержка JS: нет (только парсинг)
- Состояние проекта: активный, успевает за Ruby
- Экспорт данных: нет (форматируешь через Ruby)
- Кому подходит: Ruby‑разработчикам, Rails‑командам
- Сильные стороны: скорость, соответствие стандартам, безопасность по умолчанию.
Быстрый обзор: таблица сравнения функций
Ниже — таблица для быстрого просмотра (и Thunderbit для сравнения):
| Проект | Сложность запуска | Сценарии | Поддержка JS | Поддержка/обновления | Экспорт данных | Аудитория | Звёзды GitHub |
|---|---|---|---|---|---|---|---|
| Scrapy | Средняя | E-commerce, новости | Нет | Активный | CSV, JSON, XML | Разработчики, дата-инженеры | 57.1k |
| Crawlee | Средняя | Универсально, автоматизация | Да | Очень активный | Гибкие datasets | Команды JS/TS | 17.9k |
| MechanicalSoup | Plug & Play | Статика, формы | Нет | Зрелый | Нет (вручную) | Новички Python | 4.8k |
| Node Crawler | Средняя | Новости, статика | Нет | Умеренная | Нет (вручную) | Node.js-разработчики | 6.8k |
| Selenium | Средняя | JS-сайты, тестирование | Да | Активный | Нет (вручную) | QA, разработчики | ~30k |
| Heritrix | Продвинутая | Архивирование, исследования | Нет | Поддерживается | WARC | Архивы, учреждения | 3k |
| Apache Nutch | Продвинутая | Big data, поиск | Нет | Активный | Сырой контент | Enterprise, исследования | 3k |
| WebMagic | Средняя | Java, универсально | Нет | Активное сообщество | Подключаемые pipelines | Java-разработчики | 11.6k |
| Nokogiri | Plug & Play | Парсинг Ruby | Нет | Активный | Нет (вручную) | Ruby-разработчики | 6.2k |
| Playwright | Средняя | Динамика, автоматизация | Да | Очень активный | Нет (вручную) | Разработчики, QA | 73.5k |
| Katana | Средняя | Безопасность, discovery | Да | Активный | Текстовый вывод | Security, Go-разработчики | 13.8k |
| Colly | Средняя | Высокая производительность, универсально | Нет | Активный | Нет (вручную) | Go-разработчики | 24.3k |
| Puppeteer | Средняя | Динамика, автоматизация | Да | Активный | Нет (вручную) | Node.js-разработчики | 90.9k |
| Maxun | Легко (для пользователя) | No-code, бизнес | Да | Активный | CSV, Excel, Sheets, API | Нетехн., аналитики | 13k |
| Scrapling | Средняя | Stealth, антибот | Да | Активный | Нет (вручную) | Python-разработчики, «хакеры» | 5.4k |
| Thunderbit | Plug & Play | No-code, бизнес | Да | Управляемый, обновляется | Sheets, Airtable, Notion | Нетехн., бизнес-пользователи | N/A |
Почему Thunderbit — лучший выбор для бизнес-пользователей и людей без технических навыков
Большинство open-source проектов на GitHub делаются разработчиками и для разработчиков. А значит, установка, поддержка и разбор ошибок — это часть «сделки». Если ты маркетолог, sales ops, бизнес‑пользователь или просто хочешь результат, а не головную боль с регулярками, Thunderbit сделан именно под тебя.
Почему Thunderbit реально выделяется:
- No-code простота с AI: ставишь , жмёшь «AI Suggest Fields» — и можно собирать данные. Без Python, без селекторов и без драмы «pip install».
- Поддержка динамических страниц: AI Thunderbit читает и вытаскивает данные с современных JS‑сайтов (React, Vue, AJAX) без ручной настройки.
- Сбор данных с подстраниц: нужно вытащить детали по каждому товару или объявлению? AI Thunderbit сам проходит по подстраницам и склеивает всё в одну таблицу — без кастомного кода.
- Экспорт, готовый для бизнеса: выгрузка в Google Sheets, Airtable, Notion, CSV или JSON в один клик. Идеально для лидов, мониторинга цен и агрегирования контента.
- Постоянные обновления и поддержка: Thunderbit — управляемый сервис, без риска «заброшенного софта». Есть онбординг, туториалы и растущая библиотека шаблонов для популярных сайтов.
- Кому подходит: пользователям без технавыков, бизнес‑командам и всем, кто ценит скорость и надёжность больше, чем «поковыряться в коде».
И это не просто маркетинг: Thunderbit используют более 30 000 пользователей по всему миру, включая команды Accenture, Grammarly и Puma. Да, и мы были #1 Product of the Week на Product Hunt.
Хочешь увидеть, насколько простым может быть скрейпинг? .
Итоги: как выбрать правильное решение для веб-скрейпинга в 2025 году
Суть такая: на GitHub можно найти кучу мощных инструментов для скрейпинга, но большинство из них заточены под разработчиков. Если тебе нравится кодить, фреймворки вроде Scrapy, Crawlee, Playwright и Colly дадут максимум контроля. Если ты в академической среде или в безопасности, твой выбор — Heritrix, Nutch и Katana.
Но если ты бизнес‑пользователь, аналитик или просто хочешь данные — быстро, структурированно и в удобном виде — выбирай Thunderbit. Без настройки, без обслуживания, без кода. Только результат.
Что дальше? Можно взять GitHub‑проект под свой уровень и задачу. А если хочешь пропустить кривую обучения и увидеть результат за считанные минуты — и начни собирать данные уже сегодня.
А если хочется глубже нырнуть в тему, загляни в другие материалы на , например: или .
Удачного скрейпинга — и пусть твои данные всегда будут структурированными, чистыми и готовыми к работе. А если вдруг застрянешь, помни: скорее всего, под это уже есть репозиторий на GitHub… или можно просто доверить задачу AI от Thunderbit.