Ваш CRM ровно настолько силён, насколько сильны данные, которые ты в него заливаешь. А самые «вкусные» данные чаще всего лежат на открытых сайтах — а не в дорогущих сторонних базах.
веб-экстрактор помогает превратить разрозненные веб-данные в аккуратные таблицы. Лучшие решения делают это за считанные минуты и без программирования — просто открыл сайт, выбрал, что нужно, и получил результат.
Я гонял эти инструменты в боевых условиях: собирал лид-листы, мониторил цены конкурентов, выгружал товарные каталоги. Ниже — 12 вариантов, которые реально выдержали нагрузку, отсортированные по тому, насколько уверенно они закрывали бизнес-задачи.
Почему веб-экстракторы стали необходимостью для бизнеса
Давай по-честному: интернет — это самая большая (и самая неаккуратная) база данных на планете. И в 2026 году выигрывают те, кто умеет превращать этот бардак в понятные инсайты. По данным , компании, которые принимают решения на основе данных, на 5% продуктивнее и на 6% прибыльнее, чем конкуренты. Это уже не «шум» — это реальное преимущество.
Инструменты для извлечение данных из веба (их часто называют web page extractor или решениями для web page extracting) — тот самый скрытый ингредиент. Они позволяют отделам продаж собирать данные из публичных каталогов, соцсетей и сайтов компаний, чтобы собирать точные списки потенциальных клиентов — без покупки устаревших баз и без надежды, что стажёр не выгорит на середине бесконечного копипаста (). Маркетинг и e-commerce используют веб-экстракторы, чтобы следить за ценами конкурентов, контролировать наличие и сравнивать товары в реальном времени — например, John Lewis связывает веб-скрейпинг с ростом продаж на 4% благодаря более умному ценообразованию ().
Но дело не только в цифрах. Веб-экстракторы экономят огромное количество времени (один пользователь говорил о «сотнях часов», сэкономленных за счёт автоматизации сбора данных) и снижают риск человеческих ошибок (). Операционные команды настраивают сбор данных на постоянке — то, на что у стажёров ушли бы недели, теперь делается автоматически, возвращая часы, которые раньше сгорали на рутинном копировании (). А с экстракторами на базе ИИ даже люди без технического бэкграунда могут превращать сайты в структурированные наборы данных для анализа ().
Вывод простой: если в 2026 году ты не используешь веб-экстрактор, ты почти наверняка оставляешь инсайты (и деньги) на столе.
Как мы отобрали топ-12 веб-экстракторов
Инструментов для web page extracting сейчас реально море — как выбрать «тот самый»? Я пересмотрел десятки вариантов, но в финальный список попали только 12. Вот что было главным при отборе:
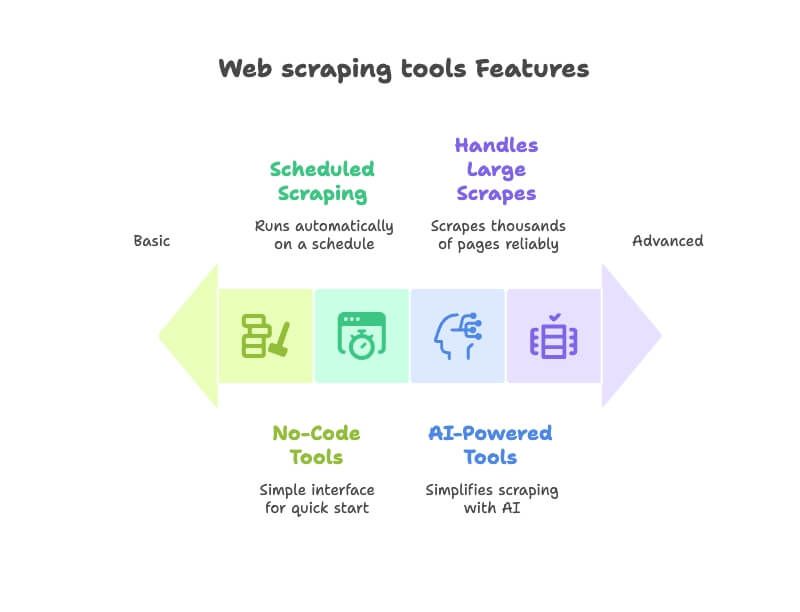
- Простота: сможет ли человек без техскиллов быстро стартовать без кода? Я делал ставку на no-code/low-code решения с понятным интерфейсом ().
- ИИ-возможности: новое поколение инструментов, где ИИ упрощает извлечение данных из веба — сам находит поля, помогает с навигацией по сайту или позволяет описать задачу обычным языком ().
- Автоматизация и расписание: лучшие веб-экстракторы работают «на автопилоте». Я выбирал решения, где можно планировать регулярные выгрузки и мониторинг сайтов ().
- Экспорт и интеграции: легко ли выгружать в Excel, Google Sheets, Airtable или Notion? Плюс — интеграции с рабочими процессами ().
- Масштабируемость и надёжность: справится ли инструмент и с одной страницей, и с тысячами? Также смотрел на отзывы о стабильности.
- Бизнес-ориентированные сценарии: фокус был на инструментах, которые реально используют команды продаж, маркетинга, e-commerce и операций — а не только разработчики.
В подборке есть и свежие ИИ-решения, и проверенная классика. Все они помогают превратить веб в вашу собственную бизнес-базу данных — без лишней боли.
Быстрое сравнение: веб-экстракторы одним взглядом
Ниже — короткая сводка по 12 инструментам, чтобы сразу увидеть разницу:
| Инструмент | ИИ-автоматизация | Простота | Лучший сценарий |
|---|---|---|---|
| Thunderbit | Да — ИИ предлагает поля и автоматически проходит страницы | Очень просто (расширение Chrome, без кода) | Быстрый сбор лидов, цен и т. п. для нетехнических пользователей, которым нужен результат за минуты. |
| Octoparse | Ограниченно (шаблоны, без ИИ) | Удобно для большинства (визуальный drag-and-drop) | Кастомные сценарии (логины, пагинация) для аналитиков, которым нужен контроль без программирования. |
| Browse AI | Частично — «роботы» по принципу point-and-click | Просто (no-code, облако) | Плановый мониторинг данных (цены, объявления и т. п.) с уведомлениями и интеграциями. |
| WebScraper.io | Нет (ручная настройка) | Средне (расширение + настройка sitemap) | Визуальный сбор данных с многоуровневых сайтов для тех, кто готов настраивать шаги. |
| ScraperAPI | N/A (API-сервис, прокси через API) | Нужен код (интеграция по API) | Высокие объёмы для техкоманд — прокси и CAPTCHA закрыты для масштабных выгрузок. |
| Data Miner | Нет | Очень просто (расширение с шаблонами в один клик) | Быстрые разовые выгрузки со страниц (особенно таблицы/списки) прямо в CSV/Excel. |
| Simplescraper | Нет (есть отдельные функции с ИИ-поддержкой) | Просто (конструктор «рецептов» point-and-click) | No-code сбор данных с интеграциями — удобно отправлять в Google Sheets, Airtable или API. |
| Instant Data Scraper | Да — автоматически распознаёт таблицы | Очень просто (клик — и готово) | Мгновенный бесплатный сбор HTML-таблиц и списков для любых быстрых задач. |
| ScrapeStorm | Да — ИИ распознаёт элементы страницы | Просто (визуальный интерфейс; кроссплатформенное приложение) | Масштабные/сложные проекты без кода, включая запуск по расписанию. |
| Apify | Частично — есть готовые «actors» | Средне (веб-интерфейс; код по желанию) | Масштабируемый облачный сбор данных и автоматизация через готовые или кастомные сценарии. |
| ParseHub | Нет (без скриптов, но ручная настройка) | Просто для базовых задач (визуальный редактор; десктоп) | Сбор данных с динамических/сложных сайтов (AJAX) через no-code интерфейс. |
| OutWit Hub | Нет | Просто (десктопное GUI-приложение) | Простая офлайн-выгрузка данных и архивирование контента для небольших проектов. |
У большинства инструментов есть бесплатный тариф или пробный период и несколько уровней подписки. Здесь важнее возможности и сценарии, чем цена.
Thunderbit: веб-экстрактор на базе ИИ для всех

Начнём с Thunderbit — да, это мой продукт, но дай объясню. Рынок web page extracting быстро уходит от «собери себе скрейпер» к «просто скажи ИИ, что тебе нужно». Thunderbit — первый инструмент, который я видел (и помогал делать), и который реально ощущается как ИИ-помощник по данным, а не очередной «краулер ради краулера».
С тебе не нужно ковыряться в XPath, CSS-селекторах или регулярках. Достаточно описать задачу человеческим языком — например: «вытащи заголовок, автора и дату со страницы» — и ИИ Thunderbit сделает остальное (). Нажимаешь “AI Suggest Fields”, и Thunderbit анализирует страницу, предлагает колонки и сам разбирается с подстраницами и пагинацией ().
И это не только про «снять данные». Thunderbit умеет чистить, преобразовывать, классифицировать и даже переводить поля прямо во время извлечения данных из веба. Нужно привести телефоны к одному формату, коротко суммировать описания или перевести названия товаров? Добавь короткую инструкцию — и ИИ всё сделает. А потом выгружай результат напрямую в Excel, Google Sheets, Airtable или Notion ().
Главная фишка Thunderbit — ноль настройки и нулевой порог входа. Это расширение Chrome, поэтому старт — буквально за секунды. Никаких плагинов, конфигов и техно-словечек. Поэтому его особенно любят команды продаж, маркетинга и операций, которым нужен быстрый результат (). Бесплатный тариф позволяет пройти весь путь, а платные планы доступны (для большинства команд — «дешевле, чем месячный бюджет на кофе»).
Хочешь почувствовать, как выглядит web page extracting с ИИ? Установи и протестируй. Возможно, эпоха копипаста для тебя закончится.
Octoparse: визуальный веб-экстрактор для кастомных сценариев
Octoparse — классика визуального веб-скрейпинга. Это десктопное приложение с интерфейсом point-and-click: ты взаимодействуешь со страницей, отмечаешь нужные элементы, а Octoparse собирает сценарий «под капотом» (). Можно обрабатывать логины, настраивать пагинацию и даже автоматизировать отправку форм — без кода.
Сильная сторона Octoparse — библиотека из 500+ готовых шаблонов для популярных сайтов (Amazon, Twitter, LinkedIn и т. д.), поэтому часто достаточно выбрать шаблон и сразу запускать выгрузку (). Для сложных сайтов можно перейти в ручной режим и визуально настроить каждый шаг. Octoparse умеет собирать контент, который появляется после кликов или прокрутки, поддерживает прокси и решение CAPTCHA для «тяжёлых» задач. Есть и облачный режим — для расписаний и масштабных запусков.
Компромисс — нужно время, чтобы освоиться, особенно если сценарии продвинутые. Но для непограммистов и аналитиков, которым нужен кастомный процесс извлечения данных из веба без кода, Octoparse — очень надёжный выбор ().
Browse AI: автоматизированное извлечение данных с готовыми «роботами»
Browse AI заходит с другой стороны: ты «обучаешь робота», просто кликая по нужным данным, и он учится вытаскивать их на похожих страницах (). Всё работает в облаке и без кода — не нужно думать ни о скриптах, ни о серверах.
Browse AI особенно хорош в автоматизации и мониторинге. Можно запускать роботов по расписанию и получать уведомления об изменениях (например, конкурент снизил цену или появилась новая вакансия). Есть библиотека готовых роботов под типовые задачи — часто можно стартовать с готового и чуть подогнать под себя ().
Browse AI интегрируется с тысячами приложений через Zapier и Make и умеет выгружать данные в Google Sheets или через API/webhooks (). Отличный вариант для регулярного мониторинга и повторяющегося сбора, если тебе нужны уведомления и интеграции «без рук».
WebScraper.io: браузерный web page extractor

WebScraper.io (часто просто “Web Scraper”) — это расширение для браузера, где ты строишь “sitemaps” — визуальные схемы того, как ходить по сайту и что именно вытаскивать (). Ты задаёшь селекторы для данных и ссылки, по которым нужно пройти (например, «жать Next для пагинации» или «заходить в карточку товара за деталями»).
Порог входа есть, но код не нужен — ты просто выбираешь элементы и задаёшь действия. Web Scraper поддерживает многоуровневую навигацию, пагинацию и даже бесконечную прокрутку (правда, шаги придётся описывать руками). Инструмент гибкий и работает прямо в браузере, поэтому можно собирать данные с сайтов «за логином», просто войдя в аккаунт.
WebScraper.io отлично подходит для «гражданских аналитиков данных», которые понимают структуру страниц и хотят бесплатный, гибкий инструмент. Надёжная рабочая лошадка, если ты готов собирать sitemaps самостоятельно.
ScraperAPI: API-first веб-экстрактор для разработчиков и команд
Не всем нужен формат «кликнул — собрал». Иногда нужно серверное решение, чтобы сразу отправлять веб-данные в приложения или базы. ScraperAPI — это API-first веб-экстрактор: ты передаёшь URL, а сервис возвращает HTML или извлечённые данные, беря на себя всё сложное — прокси, георотацию IP, headless-браузеры и CAPTCHA ().
ScraperAPI поддерживает пул из 40+ миллионов прокси в 50+ странах и обрабатывает 36 миллиардов запросов в месяц (). Это топ-вариант для масштабного автоматизированного извлечение данных из веба, где важны стабильность и защита от блокировок. Да, нужны навыки разработки, но если ты строишь data pipeline или встраиваешь сбор данных в продукт, ScraperAPI — один из лидеров.
Data Miner: расширение Chrome для быстрого извлечения данных со страниц

Data Miner — расширение Chrome для бизнес-пользователей и исследователей, которым нужно быстро «снять» данные. Оно даёт point-and-click подход и библиотеку готовых «рецептов» под типовые структуры — таблицы, списки или конкретные сайты ().
Ставишь расширение, открываешь нужную страницу и жмёшь на иконку Data Miner. Выбираешь рецепт или создаёшь свой, выделяя элементы на странице. Отлично заходит для разовых задач и срочных выгрузок — например, сейлз вытаскивает список компаний из каталога, а e-commerce менеджер копирует цены конкурентов.
Data Miner простой, работает прямо в браузере и идеален для интерактивного сбора данных по запросу.
Simplescraper: no-code веб-экстрактор для быстрых результатов

Simplescraper полностью оправдывает название. Это no-code расширение Chrome (и веб-приложение), где ты визуально выбираешь данные на странице и собираешь «рецепт» извлечения (). Можно переходить по ссылкам, собирать данные с подстраниц, обрабатывать пагинацию и даже превращать сбор данных в API endpoint в один клик.
Сильнее всего Simplescraper раскрывается в интеграциях — данные можно отправлять напрямую в Google Sheets, Airtable или в инструменты вроде Zapier (). Есть облачный сбор и расписание для регулярных задач, а ещё функция “AI Enhance” для очистки/аналитики данных через GPT.
Если тебе важны быстрый старт и удобные интеграции, Simplescraper — почти швейцарский нож среди лёгких инструментов web page extracting.
Instant Data Scraper: мгновенное извлечение данных из таблиц и списков
Иногда данные нужны вот прямо сейчас — без настроек. Для этого есть Instant Data Scraper (IDS). Это бесплатное расширение Chrome, известное тем, что делает выгрузку табличных данных в один клик (). Включаешь расширение — и IDS сам находит таблицы или списки на странице. Он также умеет проходить пагинацию и бесконечную прокрутку, автоматически «прокликивая» страницы.
IDS — полностью бесплатный: без регистрации, без кода, без ожидания. Идеален для простых или срочных задач — например, быстро собрать список лидов или выгрузить таблицу из Wikipedia. Если инструмент распознал нужные данные — ты получишь их за секунды.
ScrapeStorm: облачный веб-экстрактор с поддержкой ИИ
ScrapeStorm — инструмент веб-скрейпинга с ИИ, который сочетает визуальный интерфейс и сильные алгоритмы распознавания (). Ты вводишь URL, а ИИ сам определяет поля данных — списки, таблицы, кнопки «следующая страница» и т. д.
ScrapeStorm работает на Windows, Mac и Linux и предлагает как десктопный, так и облачный режим. Можно планировать задачи, запускать несколько процессов параллельно и экспортировать в Excel, CSV, JSON или загружать в базу данных (). Особенно популярен в e-commerce и маркетинговых исследованиях, а ещё умеет извлекать данные из изображений или PDF с помощью ИИ.
Если нужен умный помощник для масштабных или сложных проектов, ScrapeStorm точно стоит посмотреть.
Apify: маркетплейс веб-экстракторов и платформа автоматизации

Apify — это не просто скрейпер, а платформа для веб-скрейпинга и автоматизации. Здесь запускаются “actors” — сценарии для извлечения данных или автоматизации браузера. Главная фишка — маркетплейс готовых actors под типовые задачи (). Нужно собрать все отзывы с интернет-магазина? Скорее всего, actor уже существует.
Разработчики могут писать свои скрейперы на Node.js или Python и разворачивать их в облаке. Платформа масштабируется, автоматизируется и интегрируется через API. Apify лучше всего подходит продвинутым пользователям и компаниям, для которых веб-данные — стратегический ресурс: регулярные крупные выгрузки или встраивание сбора данных в pipeline.
ParseHub: визуальный web page extractor для сложных сайтов

ParseHub — десктопное приложение (с облачными опциями), которое славится работой со сложными динамическими сайтами. Ты «ходишь» по сайту в интерфейсе, похожем на браузер, кликаешь по нужным данным — и ParseHub собирает скрейпер (). Поддерживаются условная логика, вложенный сбор, AJAX-контент и многое другое.
ParseHub часто спасает там, где другие инструменты сдаются. Его используют исследователи, аналитики и владельцы малого бизнеса, которым нужно «пробить» сложные сайты. Освоение потребует времени, но если у тебя динамический сайт и ты не хочешь писать код, ParseHub — один из лучших вариантов.
OutWit Hub: десктопный веб-экстрактор для архивирования контента

OutWit Hub — немного «олдскул», но это десктопное приложение, которое отлично подходит для сбора разных типов контента (ссылки, изображения, email-адреса и т. д.) и его систематизации (). По ощущениям это смесь браузера и таблицы: открываешь страницу — и OutWit Hub может вытащить таблицы, списки, картинки и многое другое.
Особенно полезен для архивирования и исследований — например, собрать все посты с форума или скачать коллекцию файлов. Это локальный инструмент, то есть ты запускаешь его на своём компьютере и сохраняешь данные у себя. OutWit Hub лучше всего подходит для небольших и средних задач, где важны простота и контроль.
Какой веб-экстрактор выбрать под ваши задачи?
12 инструментов — и тысячи сценариев. Что выбрать? Вот моя шпаргалка:
-
Для новичков и разовых быстрых задач:
Попробуй Instant Data Scraper для простых таблиц и списков (бесплатно и мгновенно). Data Miner — ещё один дружелюбный вариант, особенно если ты часто собираешь данные со схожих страниц.
-
Для нетехнических команд, которым нужен регулярный сбор и интеграции:
Thunderbit даёт самый простой процесс благодаря ИИ — идеально для бизнес-пользователей, которым нужен быстрый и повторяемый результат. Browse AI отлично подходит для постоянного мониторинга и уведомлений. Simplescraper хорош, если ты хочешь, чтобы данные автоматически улетали в Google Sheets или во внутреннее приложение через API.
-
Для сложных сайтов и кастомных сценариев без кода:
Выбирай визуальные инструменты вроде Octoparse или ParseHub. Octoparse проще и с большим количеством шаблонов. ParseHub справляется с очень сложными динамическими сайтами и даёт тонкую настройку. WebScraper.io тоже хорош, если ты готов настраивать sitemaps вручную.
-
Для разработчиков и дата-инженеров, которым нужен масштаб:
ScraperAPI создан для встраивания веб-скрейпинга в софт и для крупных проектов. Apify — отличный выбор, когда нужна масштабируемая платформа и маркетплейс готовых или кастомных сценариев.
-
Для контентных задач и офлайн-работы:
OutWit Hub — хороший вариант для системного сбора и архивирования контента, особенно если тебе важен десктопный формат ради приватности или контроля.
На практике многие команды используют несколько инструментов под разные задачи. Можно начать с Instant Data Scraper для простого, перейти на Thunderbit или Octoparse для более серьёзного проекта, а ScraperAPI или Apify подключать, когда процесс нужно «поставить на промышленные рельсы». Хорошая новость: у большинства решений есть бесплатный тариф или пробный период — можно спокойно протестировать и выбрать своё.
Итоги: будущее web page extracting для бизнес-команд
Инструменты извлечение данных из веба сильно прокачались. В 2026 году они стали массовым стандартом. Главный тренд — веб-скрейпинг становится проще, более автоматизированным и глубже встраивается в ежедневные процессы (). Скрейперы на базе ИИ позволяют приручать даже сложные динамические сайты без узких навыков. Как сказал один дата-инженер: «Когда на рынке появились инструменты AI web scraping, я стал выполнять задачи быстрее и в большем масштабе... а с ИИ [очистка данных] автоматически встроилась в мой процесс».
Ещё один заметный сдвиг — границы между извлечением данных, мониторингом и автоматизацией размываются. Инструменты вроде Browse AI и Thunderbit не только собирают данные, но и поддерживают их актуальность, а иногда даже выполняют действия (например, заполняют формы или запускают уведомления). Рост использования — не миф: одна крупная платформа отметила рост MAU более чем на 140% за год (). Компании любого размера понимают: доступ к публичным веб-данным (этично и законно) — ключ к конкурентоспособности.
Для бизнес-команд главный вывод — самостоятельность. Не нужно ждать разработчика неделями или принимать решения «на ощущениях». Инструменты из списка дают доступ к веб-данным через интерфейсы и функции, заточенные под реальные сценарии продаж, маркетинга, операций и не только. И судя по динамике, дальше будет ещё больше удобства: более дружелюбные интерфейсы, умнее ИИ и глубже интеграции с BI и аналитическими платформами.
Важно помнить: уважайте условия использования сайтов и правила robots.txt, а также соблюдайте требования законов о персональных данных. Этичный сбор данных — основа устойчивости таких практик.
Так что, начинаешь ли ты с бесплатного расширения или разворачиваешь корпоративный «флот» скрейперов, сейчас лучшее время, чтобы превращать веб-информацию в решения. Революция веб-экстракторов уже здесь — выбери инструмент, попробуй и достань ценность, которая прячется на виду. Твоё будущее на данных — в одном клике.
FAQs
1. Что такое веб-экстрактор и почему он важен для бизнеса?
Веб-экстрактор — это инструмент, который автоматически собирает структурированные данные с сайтов. Он важен, потому что помогает превращать разрозненную онлайн-информацию в практические инсайты: повышает продуктивность, влияет на прибыль и убирает ручной сбор данных.
2. Кто может пользоваться веб-экстракторами — нужны ли технические навыки?
Во многих современных решениях технические навыки не требуются. Инструменты вроде Thunderbit, Browse AI и Instant Data Scraper рассчитаны на нетехнических пользователей: понятный интерфейс, автоматизация на базе ИИ и no-code процессы.
3. Чем веб-экстракторы полезны для продаж, маркетинга и операций?
Продажи могут собирать списки лидов из онлайн-каталогов, маркетинг — отслеживать цены конкурентов, а операционные команды — автоматизировать сбор данных. Это экономит время, снижает ошибки и даёт свежие, надёжные данные для стратегических решений.
4. На что смотреть при выборе веб-экстрактора?
Ключевые критерии: простота, ИИ-возможности, автоматизация/расписание, интеграции (например, Google Sheets или Airtable), масштабируемость и соответствие вашему сценарию (лиды, мониторинг цен, архивирование контента и т. д.).
5. Есть ли бесплатные или недорогие веб-экстракторы?
Да. Многие инструменты предлагают бесплатные тарифы или доступные планы. Instant Data Scraper полностью бесплатен для базовых задач, а Thunderbit, Simplescraper и Data Miner дают щедрые бесплатные возможности с опциями апгрейда.
Хочешь глубже разобраться в web page extracting, AI scraping или в том, как превратить сайты в конкурентное преимущество для команды? Загляни в — там больше гайдов, советов и реальных кейсов из мира автоматизации данных.