

Какой язык программирования лучше использовать для веб-скрейпинга? Это зависит от вашего проекта — и я видел, как разработчики срывались и бросали всё после выбора неподходящего инструмента.
Рынок ПО для веб-скрейпинга достиг $1,01 млрд в 2024 году и, как ожидается, более чем удвоится к 2032 году. Правильный язык может дать более быстрый результат и снизить объём поддержки. Неправильный — сломанные скрейперы и потерянные выходные.
Я уже много лет создаю инструменты автоматизации. Ниже — семь языков, которые я использовал для скрейпинга, с примерами кода, честными компромиссами и взглядом на то, когда лучше вообще не писать код и вместо этого использовать Thunderbit.
Как мы выбирали лучший язык для веб-скрейпинга
Когда речь заходит о веб-скрейпинге, не все языки программирования одинаково полезны. Я видел, как проекты взлетали — и падали — в зависимости от нескольких ключевых факторов:
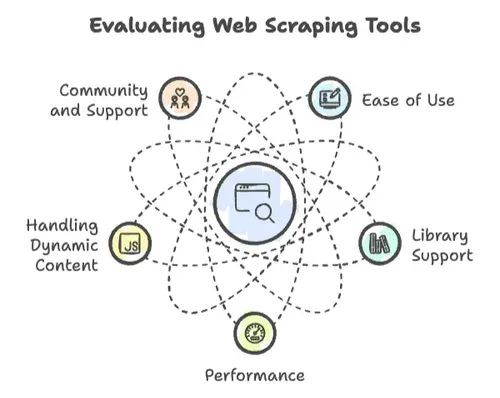
- Простота использования: Как быстро можно начать? Синтаксис дружелюбный или нужен PhD по компьютерным наукам, чтобы просто вывести «Hello, World»?
- Поддержка библиотек: Есть ли надёжные библиотеки для HTTP-запросов, разбора HTML и работы с динамическим контентом? Или вам придётся изобретать велосипед?
- Производительность: Справится ли язык с парсингом миллионов страниц или сдастся уже после нескольких сотен?
- Работа с динамическим контентом: Современные сайты обожают JavaScript. Успеет ли за ними ваш язык?
- Сообщество и поддержка: Когда вы упрётесь в стену — а вы упрётесь — найдётся ли сообщество, которое поможет?
На основе этих критериев — и множества ночных тестов — вот семь языков, о которых я расскажу:
- Python: первый выбор и для новичков, и для профессионалов.
- JavaScript и Node.js: король динамического контента.
- Ruby: чистый синтаксис, быстрые скрипты.
- PHP: простота на стороне сервера.
- C++: когда нужна чистая скорость.
- Java: готов к enterprise-задачам и масштабированию.
- Go (Golang): быстрый и параллельный.
А если вы думаете: «Шутка, я вообще не хочу писать код», — дочитайте до Thunderbit в конце.
Веб-скрейпинг на Python: мощный и дружелюбный для новичков
Начнём с фаворита большинства: Python. Если задать в комнате, полной специалистов по данным, вопрос: «Какой язык программирования лучше всего подходит для веб-скрейпинга?» — в ответ вы, скорее всего, услышите Python так же дружно, как на концерте Taylor Swift.
Почему Python?
- Синтаксис для новичков: Код на Python можно читать вслух, и он почти звучит как английский.
- Непревзойдённая поддержка библиотек: От BeautifulSoup для разбора HTML до Scrapy для крупномасштабного краулинга, Requests для HTTP и Selenium для автоматизации браузера — у Python есть всё.
- Огромное сообщество: Только по веб-скрейпингу — более 33 000 вопросов на Stack Overflow.
Пример кода на Python: извлечение заголовка страницы
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Заголовок страницы: {title}")
Сильные стороны:
- Быстрая разработка и прототипирование.
- Огромное количество туториалов и ответов на вопросы.
- Отлично подходит для анализа данных — собирайте данные на Python, анализируйте в pandas, визуализируйте в matplotlib.
- Библиотеки продолжают развиваться: в релизе Scrapy 2.14 (январь 2026) появилась нативная поддержка
async/awaitпо всему фреймворку, так что история с асинхронностью больше не ограничивается только Selenium/Playwright.
Ограничения:
- Медленнее компилируемых языков на больших объёмах задач.
- С очень динамическими сайтами бывает неудобно работать (хотя Selenium и Playwright помогают).
- Не лучший выбор для скрейпинга миллионов страниц на предельной скорости.
Итог:
Если вы новичок в скрейпинге или просто хотите быстро получить результат, Python — лучший язык для веб-скрейпинга, без оговорок. Почему Python доминирует в веб-скрейпинге.
JavaScript и Node.js: лёгкий скрейпинг динамических сайтов
Если Python — это швейцарский нож, то JavaScript (и Node.js) — это дрель, особенно для современных сайтов с тяжёлым JavaScript.
Почему JavaScript/Node.js?
- Нативно подходит для динамического контента: Он работает в браузере, поэтому видит то же, что видят пользователи, даже если страница построена на React, Angular или Vue.
- Асинхронность по умолчанию: Node.js может одновременно обрабатывать сотни запросов.
- Знаком веб-разработчикам: Если вы делали сайт, вы уже знаете хотя бы часть JavaScript.
Ключевые библиотеки:
- Playwright: мультибраузерность (Chromium, Firefox, WebKit), автоожидание и прокси на уровне контекста. Если в 2026 году вы начинаете новый Node-скрейпер, это выбор по умолчанию.
- Puppeteer: Headless Chrome через Chrome DevTools Protocol. По-прежнему отличный вариант для задач только под Chrome и с меньшим числом зависимостей.
- Cheerio: HTML-парсинг в стиле jQuery для Node, когда настоящий браузер не нужен.
Пример кода на Node.js: извлечение заголовка страницы с Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Заголовок страницы: ${title}`);
await browser.close();
})();
Сильные стороны:
- Нативно работает с контентом, который рендерится JavaScript’ом.
- Отлично подходит для бесконечной прокрутки, всплывающих окон и интерактивных сайтов.
- Эффективен для массового параллельного скрейпинга.
Ограничения:
- Асинхронное программирование может быть сложным для новичков.
- Headless-браузеры съедают много памяти, если запускать слишком много одновременно.
- Инструментов для анализа данных меньше, чем у Python.
Когда JavaScript/Node.js — лучший язык для веб-скрейпинга?
Когда целевой сайт динамический или вам нужно автоматизировать действия в браузере. Подробнее о Node.js для скрейпинга динамического контента.
Ruby: чистый синтаксис для быстрых скриптов веб-скрейпинга
Ruby — это не только про Rails и элегантную поэзию кода. Это вполне надёжный выбор для веб-скрейпинга — особенно если вам нравится, когда код читается почти как хайку.
Почему Ruby?
- Читаемый, выразительный синтаксис: На Ruby можно написать скрейпер, который почти так же легко читать, как список покупок.
- Отличен для прототипирования: Быстро пишется, легко дорабатывается.
- Ключевые библиотеки: Nokogiri для разбора HTML, Mechanize для автоматизации навигации.
Пример кода на Ruby: извлечение заголовка страницы
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Заголовок страницы: #{title}"
Сильные стороны:
- Очень читаемый и лаконичный код.
- Отлично подходит для небольших проектов, одноразовых скриптов или если вы уже используете Ruby.
Ограничения:
- Медленнее Python или Node.js на больших задачах.
- Меньше библиотек для скрейпинга и слабее сообщество по этой теме.
- Не лучший вариант для сайтов с тяжёлым JavaScript (хотя можно использовать Watir или Selenium).
Лучший сценарий:
Если вы Ruby-разработчик или хотите быстро собрать скрипт, Ruby — это удовольствие. Для крупного динамического скрейпинга лучше поискать другой инструмент.
PHP: простота на стороне сервера для извлечения веб-данных
PHP может показаться реликтом раннего интернета, но он до сих пор жив — особенно если вам нужно собирать данные прямо на сервере.
Почему PHP?
- Работает почти везде: На большинстве веб-серверов PHP уже установлен.
- Легко интегрируется с веб-приложениями: Можно сразу и собрать данные, и показать их на сайте.
- Ключевые библиотеки: cURL для HTTP, Guzzle для запросов, Symfony Panther для автоматизации headless-браузера.
Пример кода на PHP: извлечение заголовка страницы
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Заголовок страницы: $title\n";
?>
Сильные стороны:
- Легко разворачивать на веб-серверах.
- Хорошо подходит для скрейпинга как части веб-рабочего процесса.
- Быстрый вариант для простых серверных задач по сбору данных.
Ограничения:
- Ограниченная поддержка библиотек для продвинутого скрейпинга.
- Не создан для высокой параллельности и масштабного сбора.
- Работа с сайтами, насыщенными JavaScript, может быть непростой (хотя Panther помогает).
Лучший сценарий:
Если ваш стек уже на PHP или вам нужно собирать и сразу показывать данные на сайте, PHP — практичный выбор. Подробнее о PHP и Python для скрейпинга.
C++: высокопроизводительный веб-скрейпинг для крупных проектов
C++ — это muscle car среди языков программирования. Если вам нужна максимальная скорость и полный контроль, и вы не боитесь немного ручной работы, C++ способен далеко увезти.
Почему C++?
- Молниеносная скорость: На CPU-bound задачах обгоняет большинство языков.
- Тонкий контроль: Управление памятью, потоками и оптимизациями производительности.
- Ключевые библиотеки: libcurl для HTTP, htmlcxx для разбора HTML.
Пример кода на C++: извлечение заголовка страницы
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Заголовок страницы: " << title << std::endl;
} else {
std::cout << "Тег title не найден" << std::endl;
}
return 0;
}
Сильные стороны:
- Непревзойдённая скорость для очень больших задач по скрейпингу.
- Отлично подходит для встраивания скрейпинга в высокопроизводительные системы.
Ограничения:
- Порог входа высокий, возьмите кофе.
- Ручное управление памятью.
- Мало высокоуровневых библиотек; не лучший выбор для динамического контента.
Лучший сценарий:
Когда нужно скрейпить миллионы страниц или производительность критична. Во всех остальных случаях вы можете потратить больше времени на отладку, чем на сам скрейпинг.
Java: решения для веб-скрейпинга enterprise-уровня
Java — рабочая лошадка корпоративного мира. Если вы строите что-то, что должно работать вечно, обрабатывать тонны данных и пережить зомби-апокалипсис, Java — ваш друг.
Почему Java?
- Надёжность и масштабируемость: Отлично подходит для больших, долгоживущих проектов по скрейпингу.
- Строгая типизация и обработка ошибок: Меньше сюрпризов в продакшене.
- Ключевые библиотеки: Jsoup для разбора HTML, Selenium WebDriver для автоматизации браузера, Apache HttpClient для HTTP.
Пример кода на Java: извлечение заголовка страницы
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Заголовок страницы: " + title);
}
}
Сильные стороны:
- Высокая производительность и параллелизм.
- Отлично подходит для больших, поддерживаемых кодовых баз.
- Хорошая поддержка динамического контента (через Selenium или HtmlUnit).
Ограничения:
- Многословный синтаксис; нужно больше подготовки, чем у скриптовых языков.
- Избыточен для маленьких одноразовых скриптов.
Лучший сценарий:
Корпоративный скрейпинг или случаи, когда нужна железобетонная надёжность и масштабируемость.
Go (Golang): быстрый и параллельный веб-скрейпинг
Go — новичок на сцене, но уже успел наделать шума, особенно в высокоскоростном параллельном скрейпинге.
Почему Go?
- Скорость компиляции и исполнения: Почти как у C++.
- Встроенная конкурентность: Goroutines делают параллельный скрейпинг очень простым.
- Ключевые библиотеки: Colly для скрейпинга, Goquery для разбора HTML.
Пример кода на Go: извлечение заголовка страницы
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Заголовок страницы:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Ошибка:", err)
}
}
Сильные стороны:
- Молниеносный и эффективный для крупномасштабного скрейпинга.
- Легко разворачивается (один бинарный файл).
- Отлично подходит для параллельного краулинга.
Ограничения:
- Сообщество меньше, чем у Python или Node.js.
- Меньше высокоуровневых библиотек для скрейпинга.
- Для сайтов с тяжёлым JavaScript нужна дополнительная настройка (Chromedp или Selenium).
Лучший сценарий:
Когда нужно скрейпить в масштабе или Python просто недостаточно быстр. Go против Python для скрейпинга: сравнение производительности.
Сравнение лучших языков программирования для веб-скрейпинга
Соберём всё вместе. Ниже — сравнение в одном списке, которое поможет выбрать лучший язык для веб-скрейпинга в 2026 году:
| Язык/инструмент | Простота использования | Производительность | Поддержка библиотек | Работа с динамическим контентом | Лучший сценарий |
|---|---|---|---|---|---|
| Python | Очень высокая | Средняя | Отличная | Хорошая (Selenium/Playwright) | Универсальные задачи, новички, анализ данных |
| JavaScript/Node.js | Средняя | Высокая | Сильная | Отличная (нативно) | Динамические сайты, асинхронный скрейпинг, веб-разработчики |
| Ruby | Высокая | Средняя | Достаточная | Ограниченная (Watir) | Быстрые скрипты, прототипирование |
| PHP | Средняя | Средняя | Неплохая | Ограниченная (Panther) | Серверная часть, интеграция с веб-приложениями |
| C++ | Низкая | Очень высокая | Ограниченная | Очень ограниченная | Критичная к производительности, огромный масштаб |
| Java | Средняя | Высокая | Хорошая | Хорошая (Selenium/HtmlUnit) | Enterprise, долгоживущие сервисы |
| Go (Golang) | Средняя | Очень высокая | Растущая | Средняя (Chromedp) | Быстрый параллельный скрейпинг |
Когда лучше не писать код: Thunderbit как no-code решение для веб-скрейпинга
Попробуйте AI Web Scraper от Thunderbit No-code веб-скрейпинг на базе ИИ для бизнес-пользователей, маркетологов и команд продаж. Get Started Free
Ладно, давайте честно: иногда вам нужны просто данные — без кода, без отладки и без головной боли в стиле «почему этот селектор не работает». Именно для этого и существует Thunderbit.
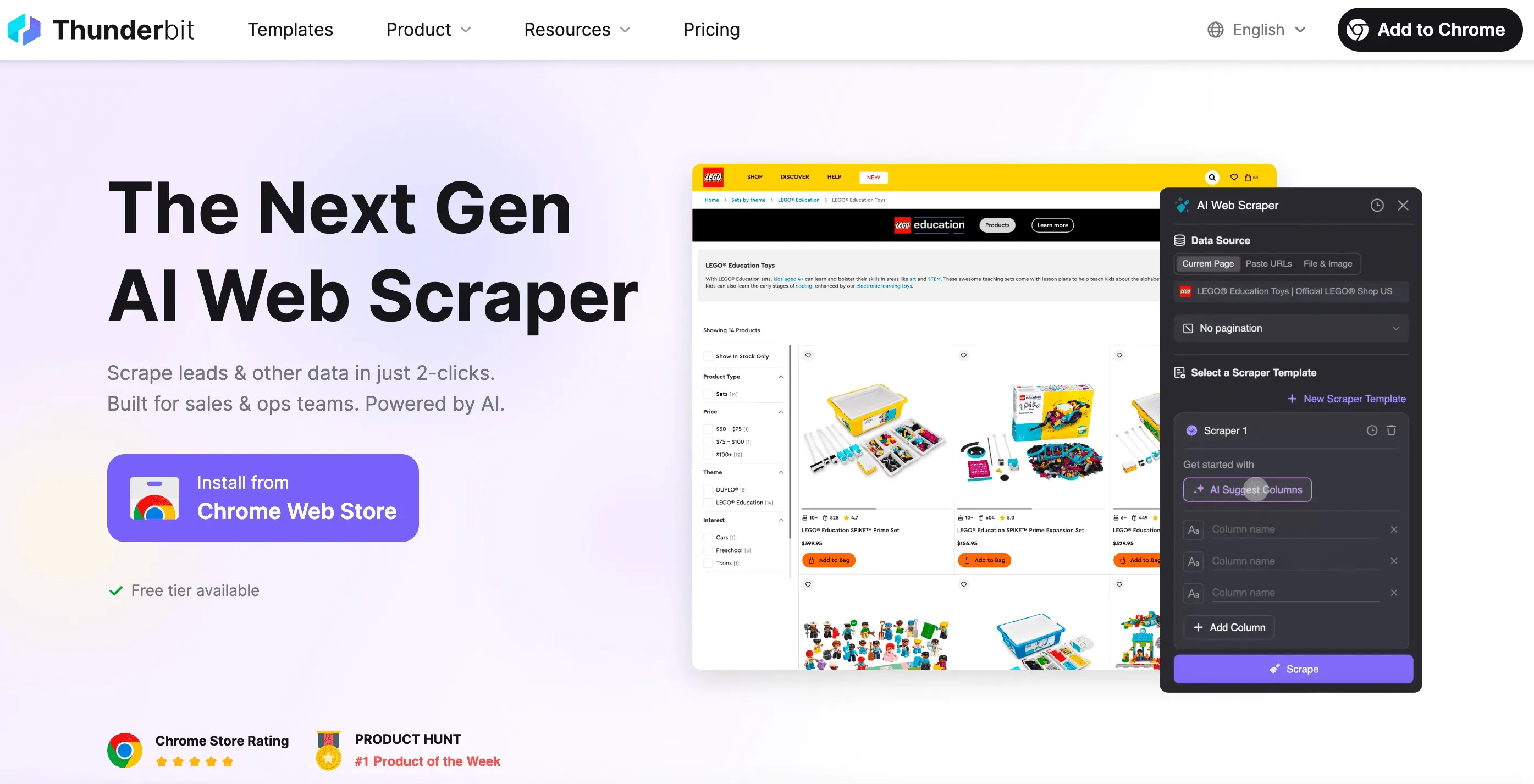
Как сооснователь Thunderbit, я хотел сделать инструмент, который делает веб-скрейпинг таким же простым, как заказ еды на вынос. Вот чем Thunderbit выделяется:
- Настройка в 2 клика: Просто нажмите «AI Suggest Fields» и «Scrape». Никакой возни с HTTP-запросами, прокси или антибот-обходами.
- Умные шаблоны: Один шаблон скрейпера может подстраиваться под разные макеты страниц. Не нужно переписывать скрейпер при каждом изменении сайта.
- Скрапинг в браузере и в облаке: Выбирайте — запускать сбор прямо в браузере (отлично для сайтов с логином) или в облаке (очень быстро для публичных данных).
- Работа с динамическим контентом: ИИ Thunderbit управляет настоящим браузером, так что справляется с бесконечной прокруткой, всплывающими окнами, входом в аккаунт и многим другим.
- Экспорт куда угодно: Скачивайте в Excel, Google Sheets, Airtable, Notion или просто копируйте в буфер обмена.
- Без обслуживания: Если сайт изменился, просто заново запустите ИИ-подсказку. Больше никаких ночных сессий отладки.
- Планирование и автоматизация: Настраивайте запуск скрейперов по расписанию — без cron-задач и настройки сервера.
- Специализированные экстракторы: Нужны email, телефоны или изображения? У Thunderbit есть и однокликовые экстракторы для этого.
И самое приятное — вам не нужно знать ни одной строчки кода. Thunderbit создан для бизнес-пользователей, маркетологов, sales-команд, специалистов по недвижимости — для всех, кому данные нужны быстро.
Хотите увидеть Thunderbit в деле? Скачайте расширение Chrome или загляните на наш YouTube-канал с демо.
Попробовать Thunderbit AI Web Scraper бесплатно
Вывод: как выбрать лучший язык для веб-скрейпинга в 2026 году
Что такое сбор данных и как это делать Get Started Free
В 2026 году веб-скрейпинг стал доступнее — и мощнее — чем когда-либо. Вот что я понял за годы в автоматизации:
- Python по-прежнему лучший язык для веб-скрейпинга, если вы хотите быстро начать и иметь под рукой море ресурсов.
- JavaScript/Node.js незаменим для динамических сайтов, насыщенных JavaScript.
- Ruby и PHP отлично подходят для быстрых скриптов и интеграции с вебом, особенно если вы уже ими пользуетесь.
- C++ и Go — ваши друзья, когда важны скорость и масштаб.
- Java — стандартный выбор для enterprise-проектов и долгосрочных задач.
- А если вы хотите вообще не писать код? Thunderbit — ваше секретное оружие.
Прежде чем начинать, задайте себе несколько вопросов:
- Насколько велик мой проект?
- Нужно ли мне работать с динамическим контентом?
- Какой у меня уровень технической подготовки?
- Я хочу строить решение или просто получить данные?
Попробуйте один из приведённых выше фрагментов кода или протестируйте Thunderbit на своём следующем проекте. А если хотите копнуть глубже, загляните в наш блог Thunderbit — там больше гайдов, советов и реальных историй о скрейпинге.
Удачного скрейпинга — и пусть ваши данные всегда будут чистыми, структурированными и в один клик от вас.
P.S. Если однажды вы застрянете в кроличьей норе веб-скрейпинга в 2 часа ночи, просто помните: Thunderbit всегда рядом. Или кофе. Или и то и другое.
Попробовать Thunderbit AI Web Scraper прямо сейчас Get Started Free
Часто задаваемые вопросы
1. Какой язык программирования лучше всего подходит для веб-скрейпинга в 2026 году?
Python остаётся лучшим выбором благодаря читаемому синтаксису, мощным библиотекам (таким как BeautifulSoup, Scrapy и Selenium) и большому сообществу. Он идеально подходит и новичкам, и профессионалам, особенно если вы совмещаете скрейпинг с анализом данных.
2. Какой язык лучше всего подходит для скрейпинга сайтов с тяжёлым JavaScript?
JavaScript (Node.js) — лучший выбор для динамических сайтов. Инструменты вроде Puppeteer и Playwright дают полный контроль над браузером и позволяют взаимодействовать с контентом, загруженным через React, Vue или Angular.
3. Есть ли no-code вариант для веб-скрейпинга?
Да — Thunderbit — это no-code AI веб-скрейпер, который берёт на себя всё: от динамического контента до расписания запусков. Просто нажмите «AI Suggest Fields» и начинайте собирать данные. Это отличный вариант для команд продаж, маркетинга и операционных команд, которым быстро нужны структурированные данные.
4. Нужно ли мне всё ещё выбирать язык, если AI-агент для кода может написать скрейпер за меня?
В 2026 году это вполне справедливый вопрос. Инструменты вроде Claude Code, Cursor и OpenAI Codex с радостью сгенерируют spider для Scrapy, скрипт для Playwright или crawler на Go + Colly из одного абзаца запроса — так что порог входа в вопрос «какой язык мне учить первым» действительно стал ниже, чем два года назад. Но агент всё равно выдаёт код на каком-то языке, а вам — или тому, кто унаследует проект — потом это читать, отлаживать и разворачивать. Поэтому выбор всё ещё важен; просто теперь он важнее для поддержки, чем для первых 30 строк. Если вы вообще не хотите трогать код, здесь и подходит Thunderbit — он полностью убирает вопрос языка.
Подробнее:




