
Битые ссылки. Страницы-сироты. Тестовая страница из 2019-го, которую Google каким-то образом умудрился проиндексировать. Если ты управляешь сайтом — ты точно знаешь эту боль.
Хороший краулер сайта вылавливает весь этот «мусор» — и параллельно строит карту ресурса, чтобы ты мог спокойно всё починить. Но многие до сих пор путают «веб-краулер» и «веб-скрейпер». А это, по сути, разные инструменты.
Я прогнал 10 бесплатных решений на реальных сайтах. Одни реально сильны для SEO-аудита. Другие — больше про веб-скрейпинг и извлечение данных. Ниже — что зашло, а что оказалось мимо.
Что такое краулер сайта: базовые понятия
Давай сразу проясним: краулер сайта — это не то же самое, что веб-скрейпер. Эти слова часто мешают в одну кучу, но смысл у них разный. Краулер — это такой «картограф» сайта: он проходит по ссылкам, заглядывает в разделы и собирает карту страниц. Его задача — обнаружение: находить URL, понимать структуру и фиксировать контент. По похожей логике работают боты Google и многие SEO-сервисы, когда проверяют «здоровье» сайта ().
Веб-скрейпер — это уже «добытчик» конкретных данных. Ему не обязательно строить полную карту: он ищет то, что имеет ценность — цены, названия компаний, отзывы, email-адреса и т. д. Скрейперы вытаскивают нужные поля со страниц, которые краулер нашёл ().
Простая аналогия:
- Краулер: человек, который проходит по всем рядам супермаркета и составляет полный список товаров.
- Скрейпер: человек, который идёт прямо к полке с кофе и записывает цены на все органические смеси.
Почему это важно? Потому что если тебе нужно просто найти все страницы сайта (например, для SEO-аудита), нужен краулер. А если цель — собрать цены товаров у конкурента, нужен скрейпер (или, в идеале, инструмент веб-краулера, который умеет и то и другое).
Зачем нужен онлайн веб-краулер: ключевые выгоды для бизнеса
Зачем вообще возиться с краулером? Интернет точно не становится меньше. Более того, по данным отрасли, свыше 54% корпоративных брендов используют специализированные платформы для краулинга](https://martechvibe.com/article/top-10-web-crawler-platforms/#:~:text=DeepCrawl%E2%80%99s%20technical%20crawler%20platform%20helps,Disney%2C%20PayPal%2C%20twitch%2C%20and%20Adobe) для оптимизации сайтов, а некоторые SEO-инструменты ежедневно обходят до 7 миллиардов страниц](https://martechvibe.com/article/top-10-web-crawler-platforms/#:~:text=Link%20Assistant%E2%80%99s%20website%20auditor%20SEO,Audi%2C%20Microsoft%2C%20IBM%2C%20and%20MasterCard).
Вот чем веб-краулинг может быть полезен:
- SEO-аудит: поиск битых ссылок, отсутствующих title, дублей контента, страниц-сирот и т. п. ().
- Проверка ссылок и QA: находить 404 и циклы редиректов до того, как это увидят пользователи ().
- Генерация sitemap: автоматически собирать XML-карты сайта для поисковиков и планирования ().
- Инвентаризация контента: полный список страниц, их иерархии и метаданных.
- Соответствие требованиям и доступность: проверка страниц на WCAG, SEO и юридические требования ().
- Производительность и безопасность: поиск медленных страниц, слишком тяжёлых изображений или проблем безопасности ().
- Данные для AI и аналитики: передача результатов обхода в аналитические или AI-инструменты ().
Ниже — короткая таблица, какие задачи чаще всего закрывают разные роли:
| Сценарий | Кому подходит | Результат / польза |
|---|---|---|
| SEO и аудит сайта | Маркетинг, SEO, владельцы малого бизнеса | Найти технические проблемы, улучшить структуру, поднять позиции |
| Инвентаризация контента и QA | Контент-менеджеры, вебмастера | Проверить/перенести контент, найти битые ссылки/картинки |
| Лидогенерация (скрейпинг) | Продажи, Biz Dev | Автоматизировать поиск контактов, наполнять CRM свежими лидами |
| Конкурентная разведка | E-commerce, продакт-менеджеры | Отслеживать цены конкурентов, новые товары, изменения наличия |
| Sitemap и клонирование структуры | Разработчики, DevOps, консультанты | Воспроизвести структуру для редизайна или бэкапа |
| Агрегация контента | Исследователи, медиа, аналитики | Собирать данные с разных сайтов для анализа и мониторинга трендов |
| Маркет-ресёрч | Аналитики, команды обучения AI | Собирать большие датасеты для анализа или обучения моделей |
()
Как мы выбирали лучшие бесплатные инструменты для краулинга сайтов
Я провёл немало поздних вечеров (и выпил больше кофе, чем хотелось бы признавать), разбираясь в краулерах: читал документацию и гонял тестовые обходы. Вот на что я смотрел:
- Технические возможности: тянет ли современные сайты (JavaScript, логины, динамический контент)?
- Удобство: зайдёт ли нетехническим пользователям или нужен «шаман» командной строки?
- Ограничения бесплатного тарифа: это реально бесплатно или просто «попробуй и забудь»?
- Доступность: облако, десктоп или библиотека?
- Уникальные фишки: есть ли что-то особенное — AI-извлечение, визуальные карты сайта, событийный краулинг?
Я протестировал каждый инструмент, посмотрел отзывы пользователей и сравнил функции «в лоб». Если инструмент вызывал желание выбросить ноутбук в окно — он в список не попадал.
Быстрое сравнение: 10 лучших бесплатных краулеров
| Инструмент и тип | Ключевые возможности | Лучший сценарий | Технические требования | Условия бесплатного плана |
|---|---|---|---|---|
| BrightData (Cloud/API) | Корпоративный краулинг, прокси, рендеринг JS, обход CAPTCHA | Сбор данных в больших объёмах | Желательны тех. навыки | Триал: 3 скрейпера, по 100 записей (≈300 записей всего) |
| Crawlbase (Cloud/API) | API-краулинг, антибот, прокси, рендеринг JS | Разработчикам для серверной инфраструктуры обхода | Интеграция API | Бесплатно: ~5 000 API-вызовов на 7 дней, затем 1 000/мес |
| ScraperAPI (Cloud/API) | Ротация прокси, рендеринг JS, асинхронный обход, готовые эндпоинты | Разработчикам, мониторинг цен, SEO-данные | Минимальная настройка | Бесплатно: 5 000 API-вызовов на 7 дней, затем 1 000/мес |
| Diffbot Crawlbot (Cloud) | AI-обход + извлечение, knowledge graph, рендеринг JS | Структурированные данные в масштабе, AI/ML | Интеграция API | Бесплатно: 10 000 кредитов/мес (≈10k страниц) |
| Screaming Frog (Desktop) | SEO-аудит, анализ ссылок/мета, sitemap, кастомное извлечение | SEO-аудиты, владельцам сайтов | Десктоп, GUI | Бесплатно: 500 URL за обход, только базовые функции |
| SiteOne Crawler (Desktop) | SEO, производительность, доступность, безопасность, офлайн-экспорт, Markdown | Разработчикам, QA, миграции, документация | Desktop/CLI, GUI | Бесплатно и open-source, 1 000 URL в GUI-отчёте (настраивается) |
| Crawljax (Java, OpenSrc) | Событийный обход JS-сайтов, статический экспорт | Разработчикам, QA динамических веб-приложений | Java, CLI/конфиг | Бесплатно и open-source, без лимитов |
| Apache Nutch (Java, OpenSrc) | Распределённый обход, плагины, интеграция с Hadoop, кастомный поиск | Собственные поисковики, крупномасштабный обход | Java, командная строка | Бесплатно и open-source, затраты только на инфраструктуру |
| YaCy (Java, OpenSrc) | P2P-обход и поиск, приватность, индексация web/intranet | Приватный поиск, децентрализация | Java, браузерный интерфейс | Бесплатно и open-source, без лимитов |
| PowerMapper (Desktop/SaaS) | Визуальные sitemap, доступность, QA, совместимость браузеров | Агентствам, QA, визуальное картирование | GUI, просто | Триал: 30 дней, 100 страниц (desktop) или 10 страниц (online) за скан |
BrightData: облачный краулер корпоративного уровня

BrightData — это прям «тяжёлая артиллерия» в мире веб-краулинга. Облачная платформа с огромной прокси-сетью, рендерингом JavaScript, решением CAPTCHA и IDE для кастомных сценариев. Если тебе нужен сбор данных в больших объёмах — например, мониторить цены на сотнях e-commerce сайтов — инфраструктура BrightData реально впечатляет ().
Сильные стороны:
- Умеет работать со «сложными» сайтами и антибот-защитой
- Нормально масштабируется под корпоративные задачи
- Есть готовые шаблоны под популярные сайты
Ограничения:
- Постоянного бесплатного тарифа нет (только триал: 3 скрейпера по 100 записей)
- Для простых аудитов может быть избыточным
- Нетехническим пользователям потребуется время на освоение
Если нужен краулинг «в промышленных масштабах», BrightData — это как арендовать болид Формулы‑1. Только не рассчитывай, что после тест-драйва это останется бесплатным ().
Crawlbase: бесплатный веб-краулер через API для разработчиков

Crawlbase (бывший ProxyCrawl) заточен под программный обход. Ты отправляешь URL в их API — и получаешь HTML, а прокси, геотаргетинг и CAPTCHA сервис берёт на себя ().
Сильные стороны:
- Высокая успешность запросов (99%+)
- Поддержка сайтов с тяжёлым JavaScript
- Удобно встраивать в свои приложения и пайплайны
Ограничения:
- Нужна интеграция через API/SDK
- Бесплатно: ~5 000 API-вызовов на 7 дней, затем 1 000/мес
Если ты разработчик и хочешь краулить (и при необходимости делать веб-скрейпинг) без управления прокси — Crawlbase выглядит очень здраво ().
ScraperAPI: проще краулить динамические сайты

ScraperAPI — это API в стиле «просто достань мне страницу». Ты передаёшь URL, а сервис сам решает вопросы с прокси, headless-браузером и антиботом, возвращая HTML (а для некоторых сайтов — сразу структурированные данные). Особенно хорошо заходит для динамических страниц и даёт довольно щедрый бесплатный лимит ().
Сильные стороны:
- Максимально просто для разработчиков (один API-запрос)
- Обходит CAPTCHA, IP-баны, поддерживает JavaScript
- Бесплатно: 5 000 API-вызовов на 7 дней, затем 1 000/мес
Ограничения:
- Нет визуальных отчётов по обходу
- Логику перехода по ссылкам придётся писать самостоятельно
Если нужно быстро встроить веб-краулинг в кодовую базу — ScraperAPI почти без альтернатив.
Diffbot Crawlbot: автоматическое обнаружение структуры сайта

Diffbot Crawlbot — это уже «умный» уровень. Он не просто обходит страницы: AI классифицирует типы страниц и извлекает структурированные данные (статьи, товары, события и т. д.) в JSON. Как будто у тебя появился робот-стажёр, который реально понимает, что читает ().
Сильные стороны:
- AI-извлечение данных, а не только обход
- Поддержка JavaScript и динамического контента
- Бесплатно: 10 000 кредитов/мес (примерно 10k страниц)
Ограничения:
- Ориентирован на разработчиков (интеграция API)
- Это не визуальный SEO-инструмент — скорее для data-задач
Если тебе нужны структурированные данные в масштабе (особенно под AI/аналитику), Diffbot — очень мощная штука.
Screaming Frog: бесплатный десктопный SEO-краулер

Screaming Frog — классика десктопного веб-краулинга для SEO-аудитов. Бесплатная версия обходит до 500 URL за запуск и показывает всё важное: битые ссылки, метатеги, дубли, sitemap и многое другое ().
Сильные стороны:
- Быстрый, подробный и суперпопулярный в SEO-среде
- Без кода: ввёл URL — и погнал
- Бесплатно до 500 URL за обход
Ограничения:
- Только десктоп (облачной версии нет)
- Продвинутые функции (рендеринг JS, расписание) — по платной лицензии
Если ты серьёзно в SEO, Screaming Frog стоит держать под рукой — просто не жди, что он бесплатно обойдёт сайт на 10 000 страниц.
SiteOne Crawler: экспорт статического сайта и документация

SiteOne Crawler — «швейцарский нож» для техпроверок. Open-source, кроссплатформенный: умеет обходить сайт, делать аудит и даже экспортировать страницы в Markdown для документации или офлайн-архива ().
Сильные стороны:
- Проверяет SEO, производительность, доступность и безопасность
- Экспорт для архивации или миграции
- Бесплатный и open-source, без лимитов использования
Ограничения:
- Технически сложнее многих GUI-инструментов
- В GUI-отчёте по умолчанию лимит 1 000 URL (можно настроить)
Если ты разработчик, QA или консультант и любишь open source — SiteOne может приятно удивить.
Crawljax: open-source Java-краулер для динамических страниц
Crawljax — инструмент узкой специализации: он сделан для обхода современных веб-приложений с тяжёлым JavaScript, имитируя действия пользователя (клики, заполнение форм и т. п.). Работает по событиям и может даже собрать статическую версию динамического сайта ().
Сильные стороны:
- Отлично подходит для SPA и AJAX-нагруженных сайтов
- Open-source и расширяемый
- Без лимитов
Ограничения:
- Нужны Java и навыки программирования/настройки
- Не для нетехнических пользователей
Если нужно обойти React/Angular-приложение «как живой пользователь», Crawljax — отличный вариант.
Apache Nutch: масштабируемый распределённый краулер

Apache Nutch — один из самых известных open-source краулеров «старой школы». Он рассчитан на огромные распределённые обходы — например, если ты строишь собственный поисковик или индексируешь миллионы страниц ().
Сильные стороны:
- Масштабируется до миллиардов страниц с Hadoop
- Очень гибкий и расширяемый
- Бесплатный и open-source
Ограничения:
- Сложное освоение (Java, командная строка, конфиги)
- Не для небольших сайтов и «на попробовать»
Если ты хочешь краулить интернет в больших объёмах и не боишься командной строки — Nutch для тебя.
YaCy: P2P-краулер и поисковик
YaCy — вариант не для всех, но очень любопытный: децентрализованный краулер сайта и поисковая система. Каждый экземпляр обходит и индексирует сайты, а при желании можно подключиться к P2P-сети и шарить индексы с другими участниками ().
Сильные стороны:
- Упор на приватность, нет центрального сервера
- Подходит для приватного поиска или поиска по интранету
- Бесплатный и open-source
Ограничения:
- Качество результатов зависит от покрытия сети
- Потребуется настройка (Java, браузерный интерфейс)
Если тебе близка идея децентрализации или хочется свой поисковик — YaCy точно стоит глянуть.
PowerMapper: визуальный генератор sitemap для UX и QA

PowerMapper делает ставку на визуализацию структуры сайта. Он обходит сайт и строит интерактивные карты, а также проверяет доступность, совместимость с браузерами и базовые SEO-параметры ().
Сильные стороны:
- Визуальные карты сайта удобны для агентств и дизайнеров
- Проверка доступности и соответствия требованиям
- Простой интерфейс, без технических навыков
Ограничения:
- Только триал (30 дней, 100 страниц desktop / 10 страниц online за скан)
- Полная версия платная
Если нужно показать карту сайта клиенту или проверить соответствие требованиям — PowerMapper реально удобен.
Как выбрать подходящий бесплатный веб-краулер
При таком выборе легко зависнуть. Вот мой быстрый ориентир:
- Для SEO-аудитов: Screaming Frog (небольшие сайты), PowerMapper (визуально), SiteOne (глубокие проверки)
- Для динамических веб-приложений: Crawljax
- Для крупномасштабного обхода или собственного поиска: Apache Nutch, YaCy
- Для разработчиков, которым нужен API: Crawlbase, ScraperAPI, Diffbot
- Для документации или архивации: SiteOne Crawler
- Для enterprise-уровня с триалом: BrightData, Diffbot
На что смотреть в первую очередь:
- Масштаб: насколько большой сайт или задача?
- Удобство: готов писать код или нужен «клик-и-готово»?
- Экспорт: нужен CSV/JSON или интеграции?
- Поддержка: есть ли комьюнити и документация, если застрянешь?
Когда краулинг встречается со скрейпингом: почему Thunderbit — более умный выбор
Реальность такая: большинство людей запускают веб-краулинг не ради красивой карты сайта. Обычно цель — получить структурированные данные: карточки товаров, контакты, инвентаризацию контента. И вот тут появляется .
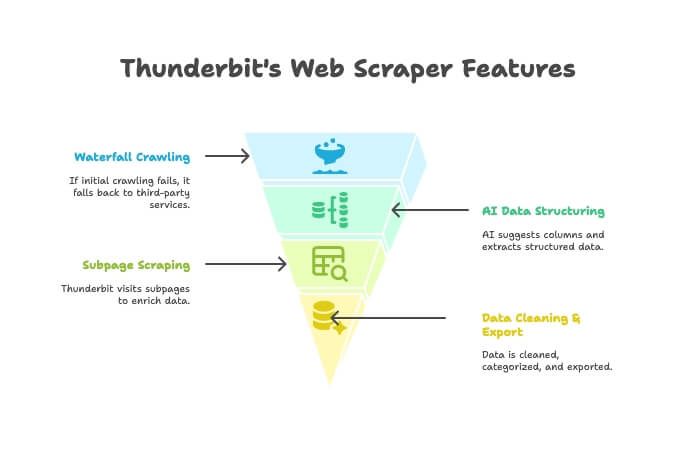
Thunderbit — это не просто краулер сайта или скрейпер. Это AI-расширение для Chrome, которое объединяет оба подхода. Как это работает:
- AI Crawler: Thunderbit исследует сайт, как классический краулер.
- Waterfall Crawling: если собственный движок Thunderbit не может получить страницу (например, из-за жёсткой антибот-защиты), он автоматически переключается на сторонние сервисы краулинга — без ручной настройки.
- AI-структурирование данных: получив HTML, AI предлагает подходящие колонки и извлекает структурированные данные (имена, цены, email и т. д.) без написания селекторов.
- Скрейпинг подстраниц: нужны детали с каждой карточки товара? Thunderbit сам зайдёт на подстраницы и дополнит таблицу.
- Очистка и экспорт: можно суммировать, классифицировать, переводить и выгружать данные в Excel, Google Sheets, Airtable или Notion в один клик.
- No-code простота: если ты умеешь пользоваться браузером — ты справишься с Thunderbit. Без кода, прокси и головной боли.
Когда Thunderbit лучше традиционного краулера?
- Когда тебе нужен не список URL, а аккуратная таблица, готовая к работе.
- Когда хочется автоматизировать весь цикл (обход → извлечение → очистка → экспорт) в одном месте.
- Когда ты ценишь время и нервы.
Ты можешь и сам увидеть, почему всё больше бизнес-пользователей переходят на него.
Итоги: как выжать максимум из бесплатных краулеров
Краулеры для сайтов заметно прокачались. Неважно, кто ты — маркетолог, разработчик или просто человек, который хочет держать сайт в порядке — почти всегда найдётся бесплатный (или хотя бы условно бесплатный) инструмент веб-краулера. От корпоративных платформ вроде BrightData и Diffbot до open-source находок вроде SiteOne и Crawljax и визуальных «картографов» вроде PowerMapper — выбор сегодня реально широкий.
Но если тебе нужен более умный и цельный путь от «мне нужны данные» до «вот готовая таблица», попробуй Thunderbit. Он сделан для бизнес-пользователей, которым важен результат, а не просто отчёты.
Готов начать обход? Скачай инструмент, запусти сканирование и посмотри, что ты упускал. А если хочешь превращать веб-краулинг в прикладные данные буквально в пару кликов — .
Больше разборов и практических гайдов — в .
FAQ
В чём разница между краулером сайта и веб-скрейпером?
Краулер находит и «картирует» все страницы сайта (как оглавление). Скрейпер извлекает конкретные поля данных (например, цены, email или отзывы) с этих страниц. Краулеры находят, скрейперы добывают ().
Какой бесплатный веб-краулер лучше всего подойдёт нетехническим пользователям?
Для небольших сайтов и SEO-аудитов Screaming Frog довольно дружелюбен. Для визуального представления структуры хорош PowerMapper (в период триала). А Thunderbit — самый простой вариант, если цель — структурированные данные и нужен no-code опыт прямо в браузере.
Бывают ли сайты, которые блокируют веб-краулеры?
Да. Некоторые сайты ограничивают обход через robots.txt или используют антибот-защиту (CAPTCHA, IP-баны и т. п.). ScraperAPI, Crawlbase и Thunderbit (за счёт waterfall crawling) часто помогают обойти такие барьеры, но важно действовать ответственно и соблюдать правила сайта ().
Есть ли у бесплатных краулеров лимиты по страницам или функциям?
Почти всегда — да. Например, бесплатный Screaming Frog ограничен 500 URL за обход; триал PowerMapper — 100 страниц. У API-сервисов обычно есть месячные лимиты кредитов. Open-source инструменты вроде SiteOne или Crawljax чаще всего не имеют жёстких ограничений, но ты упираешься в ресурсы своего железа.
Законно ли использовать веб-краулер и соответствует ли это требованиям приватности?
В целом обход публичных страниц обычно законен, но всегда проверяй условия использования сайта и robots.txt. Не обходи приватные или защищённые паролем данные без разрешения и учитывай требования законов о персональных данных, если извлекаешь личную информацию ().