

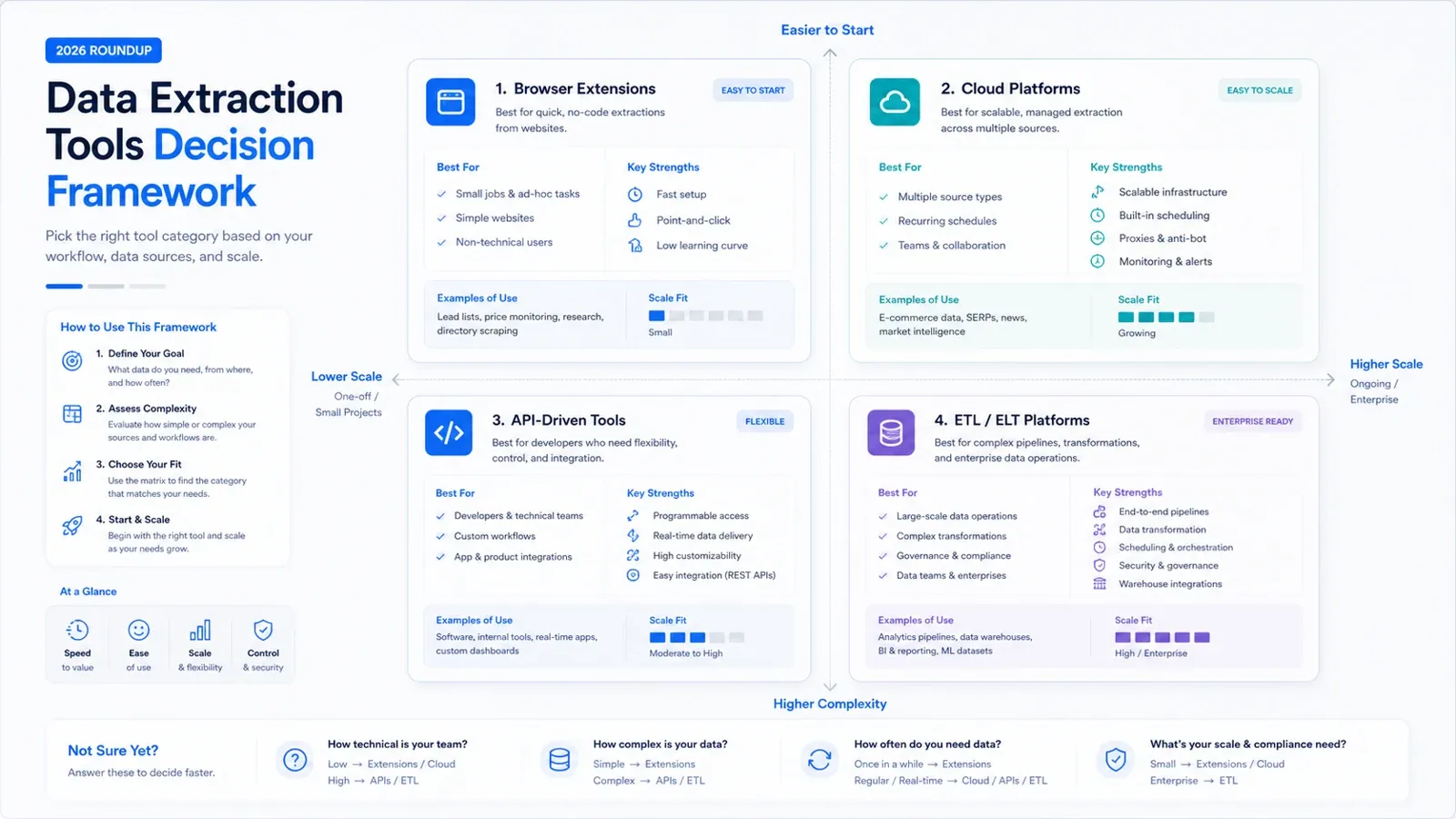
ПО для извлечения данных в 2026 году — это уже не одна категория и не один тип покупателя. Одним командам нужен browser-first инструмент, который за считаные минуты превращает сайты в таблицы. Другим — crawl API, прокси-инфраструктура или управляемый pipeline, который загружает данные в хранилище. Если свалить все эти задачи в один рейтинг без контекста, покупатели только зря потратят время и купят лишнее.
Этот обновлённый ежегодный обзор делает одну вещь особенно хорошо: помогает быстро собрать shortlist. 15 инструментов ниже по-прежнему покрывают большинство реальных сценариев покупки на рынке, но решают совершенно разные задачи. Если вам нужно быстрое извлечение данных с сайта с минимальной настройкой, ваш shortlist будет сильно отличаться от списка команды, покупающей ELT и governance.
Примечание к проверке: этот ежегодный обзор был пересмотрен 7 мая 2026 года. Следующий ответственный за проверку: редакционная команда Thunderbit.
Начните с правильного типа инструмента
Прежде чем сравнивать вендоров, определите, какую именно задачу вы хотите решить:
- Нужны данные с сайта в таблице как можно быстрее, без собственной scraping-инфраструктуры: начните с AI- или no-code browser-инструментов вроде Thunderbit, Octoparse, Data Miner или Browse AI.
- Нужны рендеринг страниц, доставка через API или anti-bot-инфраструктура для продуктовых команд: посмотрите на ScrapingBee, Diffbot, Bright Data или Captain Data.
- Нужно централизовать данные из SaaS-приложений, API и баз данных в хранилище: сосредоточьтесь на Airbyte, Hevo, Fivetran, Talend, Matillion или Integrate.io.
Посмотрите, подходит ли Thunderbit вашему рабочему процессу
Краткая таблица сравнения: лучшие инструменты для извлечения данных в 2026 году
| Инструмент | Лучше всего подходит для | Что выделяет | Модель ценообразования |
|---|---|---|---|
| Thunderbit | Бизнес-пользователи, которым нужны данные с сайта быстро | AI-подсказка полей, подстраницы, пагинация, экспорт в таблицы | Бесплатный тариф; платная подписка + кредиты |
| Diffbot | Команды, создающие структурированные веб-продукты на данных | Extraction API, Crawlbot, Knowledge Graph | Бесплатный пробный период; платные API-кредиты; enterprise по договору |
| Captain Data | Команды growth и ops, автоматизирующие outbound-процессы | No-code многошаговые workflows для сайтов и SaaS-инструментов | Оплата по использованию / через продажи |
| ScrapingBee | Разработчики, которые парсят страницы с тяжёлым JS | Headless-rendering, ротация прокси, простой API-доступ | Бесплатный пробный период; платные API-планы |
| Octoparse | Аналитики, которым нужен визуальный scraping и облачные запуски | Конструктор задач point-and-click, шаблоны, расписание в облаке | Бесплатный тариф; платные планы |
| Data Miner | Пользователи браузера, которые по запросу извлекают списки и таблицы | Браузерное извлечение на основе recipes с быстрым экспортом | Бесплатный тариф; платные планы |
| Browse AI | Команды, которым важны мониторинг и уведомления об изменениях | Обученные роботы, плановый мониторинг, доставка в Sheets/Zapier | Бесплатный тариф; платные планы |
| Bardeen | Пользователи, сочетающие scraping с автоматизацией браузерных workflows | AI playbooks, browser-автоматизация, интеграции с приложениями | Бесплатный тариф; платные планы |
| Bright Data | Корпоративный сбор данных в больших объёмах | Proxy-сеть, unlocker, datasets, scraping-платформа | Оплата по использованию / контракт |
| Airbyte | Инженерные команды, строящие warehouse pipelines | Open connectors, self-managed вариант, фокус на хранилищах | Бесплатно self-managed; cloud и enterprise уровни |
| Talend / Qlik Talend Cloud | Enterprise, которым нужна интеграция с жёстким governance | Интеграция, качество, governance, enterprise-контроль | Подписка по запросу |
| Matillion | Команды cloud data, работающие в современных хранилищах | Cloud-native ELT и трансформация внутри хранилища | Оплата по потреблению |
| Integrate.io | Mid-market команды, которым нужны управляемые pipelines | Managed-интеграции между SaaS и базами данных | Подписка через продажи |
| Hevo Data | Команды, которым нужна почти realtime-обработка под управлением | Управляемые коннекторы, фокус на real-time, быстрая настройка | Бесплатный тариф; платные планы |
| Fivetran | Команды, для которых надёжность важнее кастомизации | Управляемые коннекторы, обработка схем, простота эксплуатации | Бесплатный план; MAR-ценообразование по использованию |
Что изменилось в 2026 году
Сейчас важнее три сдвига, а не общие разговоры об «автоматизации»:
- Извлечение с AI стало массовым. Покупатели всё чаще ожидают, что инструмент сам определит поля, справится с базовыми вариациями страниц и выгрузит чистые таблицы без настройки селекторов.
- Инфраструктура отделилась от инструментов для workflows. Одни продукты лучше покупать как API или proxy-слои, а другие — как полноценные workflows для бизнес-пользователей.
- Ежегодные покупатели внимательнее смотрят на стоимость поддержки. Инструмент, который дешевле на бумаге, может оказаться хуже, если вашей команде каждую неделю приходится вручную чинить селекторы, синхронизацию с хранилищем или обход anti-bot-защит.
Именно поэтому эта страница разделяет shortlist по операционной модели, а не делает вид, что все инструменты конкурируют один к одному.
Лучшие AI и no-code инструменты для извлечения данных
1. Thunderbit
Thunderbit по-прежнему лучше всего подходит нетехническим командам, которым нужно быстро получить данные с сайта в структурированной таблице. Его главное преимущество не только в том, что он no-code: продукт изначально создан, чтобы снижать трение при настройке. Вы открываете страницу, просите AI предложить поля, при необходимости корректируете таблицу и экспортируете данные.
- Лучше всего подходит для: sales ops, ecommerce ops, рекрутинга, ресёрча и всех, кто переходит от страницы в браузере к таблице.
- Что выделяет: AI-подсказка полей, scraping подстраниц, работа с пагинацией, экспорт в Sheets / Excel / Airtable / Notion.
- Цена: доступен бесплатный тариф; платные планы масштабируются за счёт подписки и использования кредитов.
Попробовать Thunderbit AI Web Scraper бесплатно
2. Octoparse
Octoparse по-прежнему остаётся одним из самых зрелых no-code scraping-продуктов для команд, которым нужен более явный визуальный конструктор задач. Он требует больше настройки, чем Thunderbit, но взамен даёт более сильный контроль над задачами пользователям, готовым моделировать workflow.
- Лучше всего подходит для: аналитиков, исследователей и ops-команд, которые парсят повторяющиеся наборы данных на умеренном масштабе.
- Что выделяет: визуальный дизайн задач, облачное расписание, шаблоны задач, поддержка логина и динамических страниц.
- Цена: бесплатный тариф плюс платные планы для облачной мощности и командных функций.
3. Data Miner
Data Miner по-прежнему полезен для тактического извлечения данных прямо в браузере. Особенно хорош, когда нужно быстро собрать список, каталог или таблицу и при этом удобно пользоваться готовыми recipes или адаптировать их под себя.
- Лучше всего подходит для: нативного в браузере извлечения таблиц, каталогов и повторяющихся элементов страниц.
- Что выделяет: большая библиотека recipes, быстрый browser-workflow, привычный экспорт в CSV / таблицы.
- Цена: бесплатный тариф и платные апгрейды для более интенсивного использования.
4. Browse AI
Browse AI особенно силён там, где задача — не только извлечение, но и мониторинг. Если покупателю нужен робот, который снова и снова заходит на страницу, отслеживает изменения и отправляет результаты дальше по цепочке, Browse AI остаётся актуальным.
- Лучше всего подходит для: регулярного мониторинга, уведомлений об изменениях и простого извлечения по расписанию.
- Что выделяет: обученные роботы, повторяющиеся запуски, workflow в стиле alert, доставка в Sheets и инструменты автоматизации.
- Цена: бесплатный тариф плюс платные планы, зависящие от объёма запусков.
5. Bardeen
Bardeen находится на границе между извлечением данных и автоматизацией браузерных workflows. Это скорее не чистый scraper, а browser productivity layer, который умеет собирать данные и передавать их дальше по рабочему процессу.
- Лучше всего подходит для: команд, которые автоматизируют повторяющиеся браузерные задачи вокруг scraping, enrichment и передачи данных.
- Что выделяет: AI playbooks, browser-автоматизация, глубокие интеграции с приложениями.
- Цена: бесплатный тариф плюс платные планы.
Лучшие инструменты извлечения с API, workflows и инфраструктурным подходом
6. Diffbot
Diffbot по-прежнему остаётся одним из самых очевидных вариантов, когда покупателю нужно извлечение данных как API-продукт, а не как браузерный workflow. Он создан для структурированного понимания веб-данных на масштабе и по-прежнему больше ориентирован на разработчиков и data products, чем no-code-инструменты выше.
- Лучше всего подходит для: команд, создающих data products, системы enrichment или крупномасштабные структурированные web pipelines.
- Что выделяет: extraction API, Crawlbot, Knowledge Graph, data products, ориентированные на сущности.
- Цена: бесплатный пробный период и платные API-уровни с кредитами, а также enterprise-варианты.
7. Captain Data

Captain Data остаётся актуальным, потому что рассматривает извлечение данных как один из шагов более широкого go-to-market workflow. Он особенно полезен, когда реальная задача — не «спарсить страницу», а «собрать лиды, обогатить их, маршрутизировать и обновить downstream-системы».
- Лучше всего подходит для: команд growth, outbound и revenue operations.
- Что выделяет: многошаговые workflows, действия по enrichment, передача в CRM, автоматизация outbound-процессов.
- Цена: оплата по использованию и продажи через sales-канал.
8. ScrapingBee
ScrapingBee по-прежнему остаётся практичным API-выбором для разработчиков, которым нужна поддержка рендеринга страниц и абстракция инфраструктуры без необходимости строить весь scraping-стек с нуля.
- Лучше всего подходит для: продуктовых команд и разработчиков, которые встраивают scraping в приложения или внутренние инструменты.
- Что выделяет: рендеринг JavaScript, работа с прокси, простая модель запросов, API в духе developer-first.
- Цена: платные API-планы с доступом на пробный период.
9. Bright Data
Bright Data по-прежнему остаётся enterprise-решением, когда проблема — это не один workflow, а объём сбора, география, инфраструктура для разблокировки и строгие требования к соответствию и операционному контролю.
- Лучше всего подходит для: корпоративного сбора данных, задач с большим количеством прокси и продвинутых программ сбора.
- Что выделяет: proxy-сеть, инструменты unlocker, data products и инфраструктура сбора корпоративного масштаба.
- Цена: оплата по использованию и контрактная модель.
Лучшие ELT- и data pipeline-платформы с возможностями извлечения данных
10. Airbyte
Airbyte — правильный кандидат в shortlist, когда задача шире, чем извлечение данных с сайтов, и команде нужны коннекторы, перемещение данных в хранилище и контроль над архитектурой pipeline. Это не замена web scraper, но один из лучших вариантов для централизации данных из SaaS, API и баз данных.
- Лучше всего подходит для: engineering-led команд, которым нужны open connectors и контроль, ориентированный на хранилище.
- Что выделяет: открытая экосистема, self-managed вариант, cloud-версия, гибкость коннекторов.
- Цена: бесплатный self-managed путь плюс cloud и enterprise-уровни.
11. Talend / Qlik Talend Cloud

Talend по-прежнему остаётся enterprise-инструментом интеграции для организаций, которым важнее управляемое перемещение данных, качество, lineage и контроль, чем лёгкость настройки.
- Лучше всего подходит для: enterprise с требованиями к governance, качеству и межсистемной интеграции.
- Что выделяет: enterprise-governance, инструменты качества, широта интеграций, управляемое cloud-направление под Qlik.
- Цена: подписка по запросу.
12. Matillion
Matillion по-прежнему хорошо подходит cloud data-командам, которым нужен ELT, тесно связанный с современными хранилищами и паттернами трансформации прямо внутри хранилища.
- Лучше всего подходит для: Snowflake, Databricks, BigQuery и команд, работающих с современными хранилищами.
- Что выделяет: cloud-native ELT, трансформация вокруг хранилища, командные workflows для analytics engineering.
- Цена: оплата по потреблению.
13. Integrate.io
Integrate.io остаётся актуальным для команд, которым нужен управляемый слой интеграции без необходимости самостоятельно строить и поддерживать более широкий инженерный стек pipeline.
- Лучше всего подходит для: mid-market команд, которые предпочитают управляемые интеграции между SaaS-приложениями и базами данных.
- Что выделяет: managed-подход к внедрению, связность бизнес-систем, низкое трение в эксплуатации.
- Цена: подписка через продажи.
14. Hevo Data
Hevo Data продолжает привлекать команды, которым нужен простой в запуске managed pipeline с почти realtime-синхронизацией и сравнительно низкой операционной нагрузкой.
- Лучше всего подходит для: аналитических команд, которым нужно быстро перемещать данные из операционных систем в хранилище.
- Что выделяет: управляемые коннекторы, почти realtime-синхронизация, простая настройка.
- Цена: бесплатный тариф и платные планы.
15. Fivetran
Fivetran по-прежнему остаётся одним из самых безопасных вариантов shortlist, когда покупателю важнее надёжность, поддержка коннекторов и простота эксплуатации, чем экономия или свобода кастомизации.
- Лучше всего подходит для: data-команд, которым нужен стандарт управляемых коннекторов и которые готовы за это платить.
- Что выделяет: управляемые коннекторы, обработка схем, высокая операционная зрелость, низкие требования к поддержке.
- Цена: бесплатный план плюс MAR-ценообразование по использованию.
Как выбрать без переплаты за лишнее
Самый быстрый способ выбрать правильно — не решать не ту задачу.

- Если вам в основном нужны данные с сайта в таблицу, не начинайте с ELT-платформы.
- Если вам нужен governed pipeline в хранилище, не пытайтесь превратить browser scraper в свою data platform.
- Если самая сложная часть workflow — рендеринг JavaScript, блокировки или API-доставка, сначала сравнивайте инфраструктурные инструменты.
- Если самое трудное — внедрение среди коллег и скорость запуска, сначала сравнивайте AI и no-code инструменты.
Полезное правило покупки в 2026 году звучит так: выбирайте минимально сложное решение, которое действительно покрывает ваш workflow. Стоимость поддержки растёт быстрее, чем экономия на цене в прайсе.
Финальный shortlist по типу команды
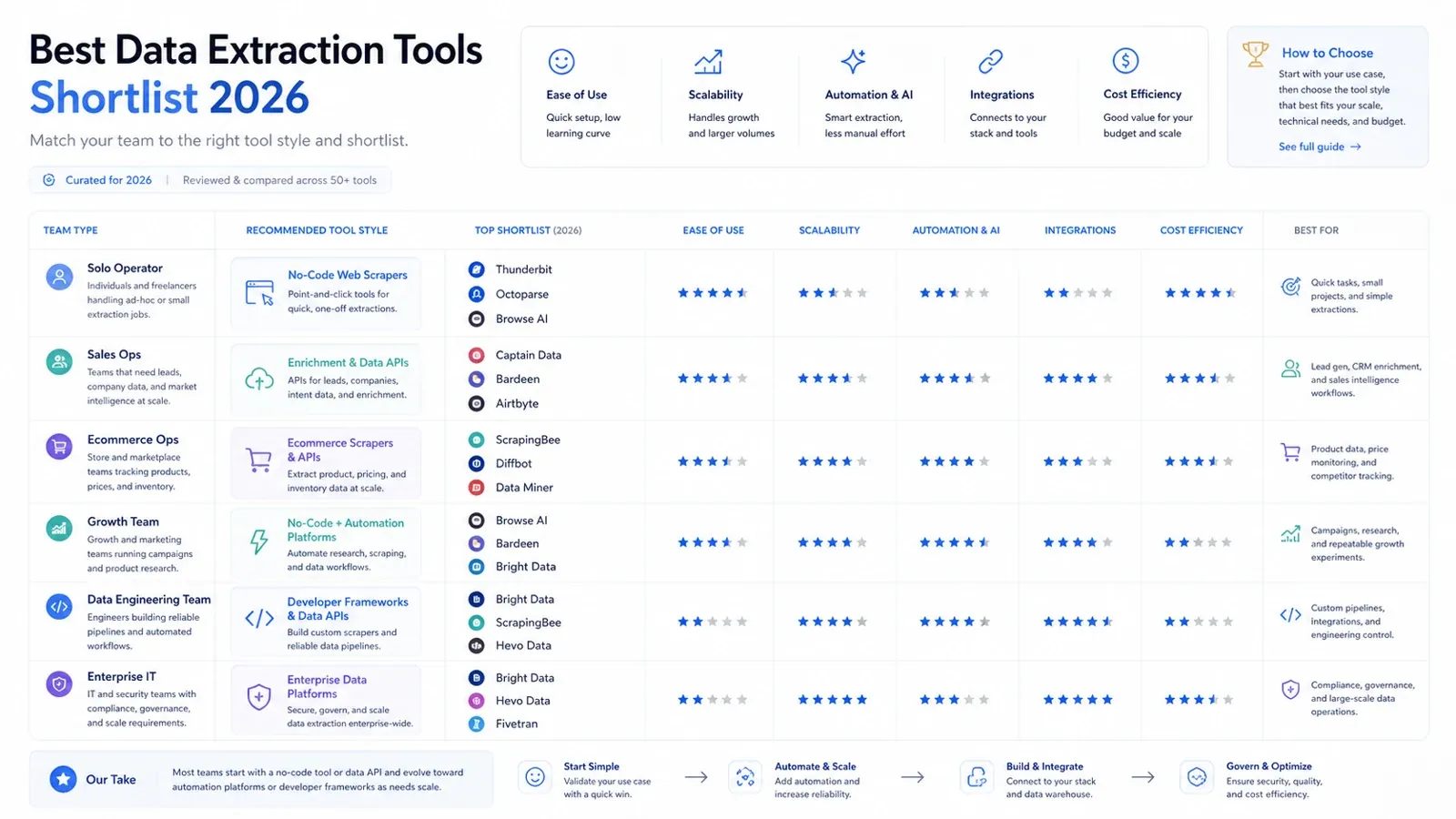
Практический shortlist выглядит так:
- Один пользователь или бизнес-пользователь: Thunderbit, Data Miner, Browse AI.
- Команда sales ops или growth workflow: Thunderbit, Captain Data, Bardeen.
- Команда ecommerce ops: Thunderbit, Octoparse, Bright Data.
- Команда data engineering: Airbyte, Fivetran, Matillion, Hevo.
- Enterprise IT / покупатель управляемой интеграции: Talend, Fivetran, Integrate.io, Bright Data.
- Разработчик, создающий data products: Diffbot, ScrapingBee, Bright Data.
Если бы мне пришлось сократить весь этот рынок до самого короткого полезного стартового списка для большинства покупателей в 2026 году, он выглядел бы так:
- Thunderbit — для быстрого AI-assisted извлечения данных с сайтов командами без технической подготовки.
- ScrapingBee — для разработчиков, которым нужна API-инфраструктура с рендерингом страниц.
- Bright Data — для сбора данных enterprise-масштаба и инфраструктуры для обхода блокировок.
- Airbyte — для инженерных warehouse pipelines с гибкостью.
- Fivetran — для надёжности управляемых коннекторов.
Начать бесплатно с Thunderbit Get Started Free
FAQ
В1: Инструменты для извлечения данных и ETL-инструменты — это одно и то же?
Нет. Инструмент для извлечения данных может быть сосредоточен на сайтах, PDF или структурированном захвате на уровне страницы, тогда как ETL- или ELT-платформа предназначена для перемещения и преобразования данных между системами в хранилище. Некоторым покупателям нужны и те и другие, но оценивать их так, будто они решают одну и ту же первоочередную задачу, не стоит.
В2: Какой выбор лучше всего подойдёт нетехнической команде в 2026 году?
Для быстрого извлечения данных с сайта с минимальной настройкой по-прежнему лучше всего подходят AI- и no-code-инструменты. Thunderbit, Octoparse, Browse AI и Data Miner — самые релевантные первые варианты shortlist в зависимости от того, что вашей команде важнее: контроль или скорость.
В3: Какие инструменты лучше всего подходят для разработчиков и enterprise-сценариев?
Для разработчиков сильными стартовыми вариантами остаются ScrapingBee и Diffbot — в зависимости от того, нужна ли вам инфраструктура рендеринга или API для структурированных веб-данных. Для сбора данных enterprise-масштаба или инфраструктуры с высокими требованиями к compliance Bright Data по-прежнему остаётся важным кандидатом shortlist. Для управляемых внутренних pipelines лучше подойдут Airbyte, Fivetran, Talend, Matillion, Hevo и Integrate.io.




