
Каждый AI веб-скрейпер выглядит эффектно в рекламном демо. Но стоит направить его на реальный сайт с защитой Cloudflare, и он возвращает страницу проверки, при этом уверенно сообщает, что нашёл 47 товарных карточек.
Последние несколько месяцев я тестировал инструменты для скрейпинга для нашей команды в Thunderbit. Разрыв между качеством демо и надёжностью в продакшене — пожалуй, главный источник раздражения, который я постоянно вижу в сообществах. Один пользователь Reddit сформулировал это идеально: Если учесть , а ещё десятки расширений Chrome, API-провайдеров и маркетплейсов акторов, выбор действительно превращается в парадокс. Поэтому я протестировал 12 решений.
В этой статье 12 AI веб-скрейперов оцениваются по критериям продакшена: обход антибот-защиты, масштабируемость, качество структурированного вывода, эффективность по затратам, поддержка динамических сайтов и гибкость для разработчиков. Никаких чек-листов функций. Никаких маркетинговых скриншотов. Только то, что реально работает после окончания демо.
Почему большинство AI веб-скрейперов ломаются сразу после демо
Сценарий предсказуем. На маркетинговом сайте инструмент красиво показывает, как извлекает аккуратные столбцы с простой страницы товаров. Вы ставите его, пробуете на защищённом e-commerce-сайте и получаете одно из следующего:
- Ответ
200 OK, который вместо данных содержит страницу проверки Cloudflare - Чистые результаты для первых 5 страниц, а затем тихие сбои или выдуманные строки
- Идеальное извлечение сегодня, сломанные селекторы на следующей неделе после небольшого изменения макета
Это не редкие случаи. Это норма.
Как один практик : «Скрейпер возвращает 200 со страницей проверки Cloudflare, агент пытается это интерпретировать, начинает фантазировать, а вы даже не понимаете, почему так вышло».
Проблема — в архитектуре. Большинство демо показывают слой парсинга на чистых публичных страницах, тогда как в реальной работе всё ломается на слое получения данных. Промышленные сайты добавляют антибот-защиту, динамический рендеринг, вложенные страницы с деталями, бесконечную прокрутку, авторизацию, локализацию и постоянно меняющиеся макеты.
Инструмент может отлично выглядеть в туре по продукту и при этом развалиться уже в первом серьёзном рабочем процессе клиента.
Именно поэтому в этой статье каждый инструмент оценивается не по списку функций, а с точки зрения готовности к продакшену. Вот шесть критериев, которые я использовал:
| Критерий | Почему это важно |
|---|---|
| Обход антибот-защиты/CAPTCHA | Защищённые сайты ломаются ещё до того, как качество извлечения вообще становится важным |
| Масштабируемость за пределами демо | Пакетные задания и параллельные запуски выявляют реальные операционные ограничения |
| Качество структурированного вывода | Пользователям нужен чистый JSON/CSV, а не сырой HTML, который придётся чистить вручную |
| Эффективность по токенам/стоимости | AI-извлечение может стать дороже самого скрейпинга |
| Поддержка динамических/JS-тяжёлых сайтов | Современные страницы требуют отрисованного DOM, а не статического HTML |
| Гибкость no-code против API | У sales-команд и data-инженеров разные потребности |
Если вам нужен быстрый обзор рынка и того, как web scraping изменился за последние два года, этот доклад Browserless — хорошее введение перед сравнением инструментов один за другим.
Где AI действительно помогает в пайплайне скрейпинга, а где — нет
Устойчивый миф на этом рынке: «AI web scraper» означает, что AI делает всё от начала до конца. На самом деле консенсус в сообществе удивительно ясен: . Один из пользователей сформулировал это без обиняков: «AI можно использовать, чтобы прочитать скриншот веб-страницы. Но не для того, чтобы писать сам скрейпер».
Пайплайн скрейпинга состоит из трёх отдельных слоёв, и ценность AI на каждом из них сильно отличается:
Сбор и получение данных: инфраструктурный слой
Именно здесь происходят запросы: прокси, headless-браузеры, управление сессиями, обход CAPTCHA, повторные попытки. AI почти ничего полезного тут не делает. Вам всё равно нужны пул прокси, браузерные отпечатки и инфраструктура для разблокировки. Именно на этом уровне большинство инструментов впервые ломаются в продакшене.
Парсинг и извлечение: где AI раскрывается лучше всего
Когда у вас уже есть чистое содержимое страницы, AI отлично превращает неструктурированный HTML в структурированные поля. Извлечение по схеме, адаптивное определение полей и работа с вариациями макета без хрупких XPath-селекторов — это как раз сильная сторона AI в скрейпинге.
Постобработка: маркировка, перевод, категоризация
После извлечения AI добавляет ценность, когда нужно категоризировать товары, переводить текст, нормализовать номера телефонов или кратко пересказывать описания. Это очень удачное применение, но только если изначальные данные уже корректны.
Вот как 12 инструментов распределяются по этим слоям:
| Инструмент | Сбор/получение | Парсинг/извлечение | Постобработка | Лучшее описание |
|---|---|---|---|---|
| Thunderbit | Сильный | Сильный | Сильный | Полноценный no-code AI-скрейпер |
| Octoparse | Сильный | Средний | Низкий | Визуальный скрейпер на правилах с облачной инфраструктурой |
| Browse AI | Средний | Средний | Средний | Облачная платформа мониторинга в первую очередь |
| Firecrawl | Средний | Сильный | Низкий-средний | API для разработчиков для извлечения данных |
| Apify | Сильный | Средний-сильный | Средний | Маркетплейс акторов и оркестрация |
| Gumloop | Средний | Средний | Сильный | Автоматизация рабочих процессов со скрейпер-узлами |
| Bright Data | Очень сильный | Средний | Низкий-средний | Корпоративный инфраструктурный стек |
| Bardeen | Средний | Средний | Сильный | Браузерная автоматизация для GTM-процессов |
| Diffbot | Низкий-средний | Очень сильный | Средний | Предобученное извлечение плюс knowledge graph |
| ScrapingBee | Сильный | Низкий-средний | Низкий | API для получения данных и обхода блокировок |
| Instant Data Scraper | Низкий | Средний (простые страницы) | Низкий | Быстрый эвристический скрейпер прямо в браузере |
| ParseHub | Средний | Средний | Низкий | Визуальный десктопный скрейпер для сложных сценариев |
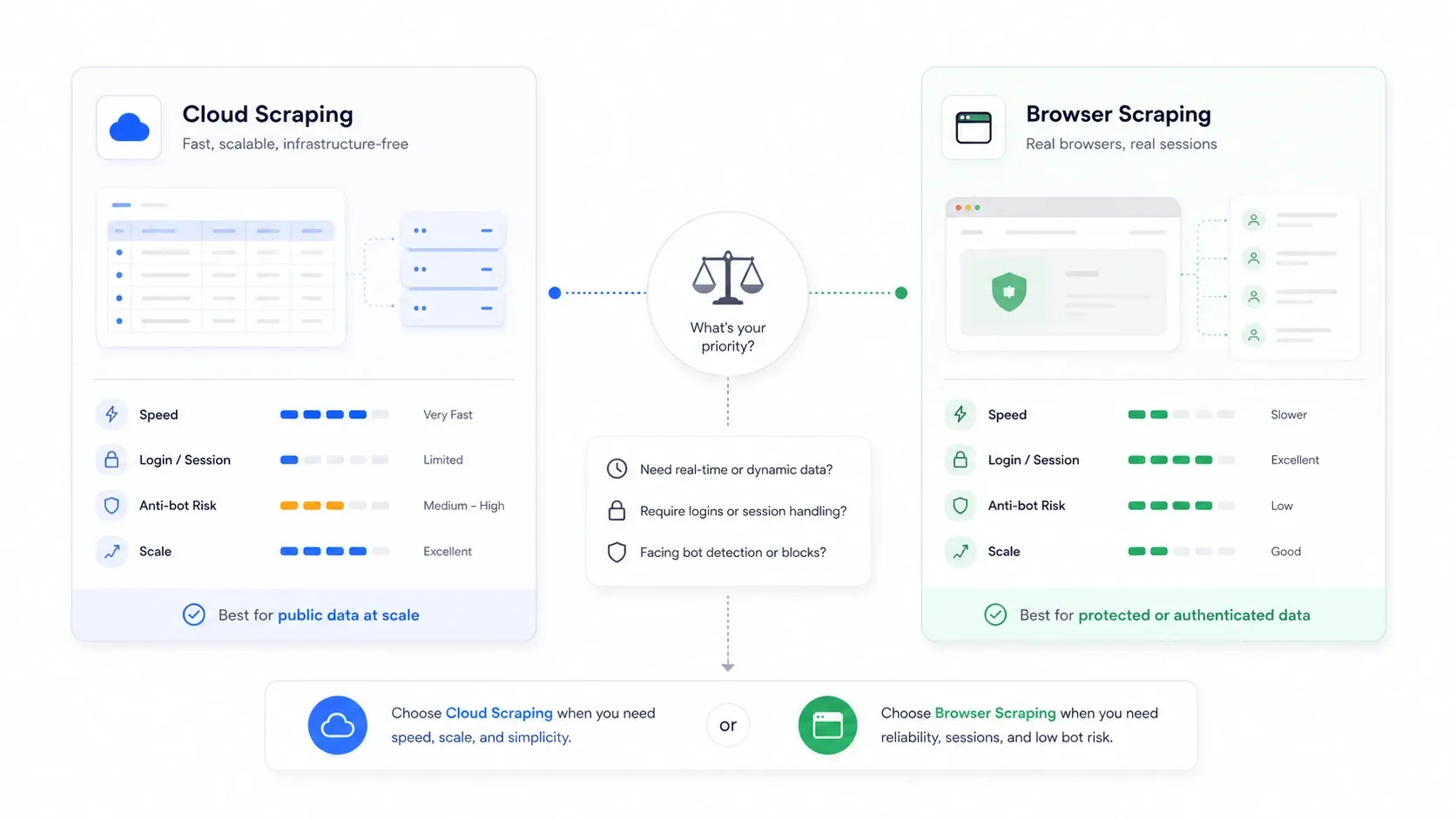
Cloud-скрейпинг против браузерного скрейпинга: выбор, который никто не объясняет
Это архитектурное решение, которое большинство обзорных статей полностью игнорирует, хотя оно часто важнее самого инструмента.
Cloud-скрейпинг означает, что страницы за вас загружают удалённые серверы. Браузерный скрейпинг означает, что извлечение происходит в вашей собственной браузерной сессии — с вашими cookie, вашим IP и вашим авторизованным состоянием.
| Сценарий | Лучший режим | Почему |
|---|---|---|
| Публичные e-commerce и каталожные сайты в больших объёмах | Cloud | Быстрее параллелизм и нет ограничения локального компьютера |
| Сайты, где требуется вход в аккаунт или авторизация | Браузер | Используются реальные cookie сессии |
| Сайты, которые наказывают дата-центровые IP | Браузер | Выглядит как обычный пользовательский трафик |
| Крупные регулярные задачи мониторинга | Cloud | Проще планировать и поддерживать непрерывность |
| Разовые, хрупкие задачи, чувствительные к антибот-защите | Браузер | Проще увидеть, что именно отрендерил сайт |
Экономически это тоже важно. В отчёте Apify State of Web Scraping 2026 говорится, что по сравнению с прошлым годом, а сообщили о росте расходов на инфраструктуру. Антибот-защита — это не только техническая проблема. Это ещё и бюджетная проблема.
Большинство инструментов поддерживает только один режим. Вот как выглядит разбивка:
| Инструмент | Cloud | Браузер | Оба |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (локально) | ✅ |
| Browse AI | ✅ | Только настройка | — |
| Firecrawl | ✅ | API для интерактивных задач | — |
| Apify | ✅ | ✅ (через actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Ограниченно (публичные страницы) | ✅ | Частично |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (платно) | ✅ (desktop) | ✅ |
12 AI веб-скрейперов в одном обзоре
Ниже — сводное сравнение всех 12 инструментов:
| Инструмент | Лучше всего для | Бесплатный тариф | Cloud/браузер | Доступ к API | Плановый скрейпинг | Обход антибот-защиты |
|---|---|---|---|---|---|---|
| Thunderbit | Некомандных пользователей | ✅ (6 страниц) | Оба | ✅ | ✅ | Сильный |
| Octoparse | Скрейпинга на шаблонах | ✅ (ограниченно) | Оба | ✅ | ✅ | Средне-сильный |
| Browse AI | Мониторинга изменений | ✅ (ограниченно) | В основном cloud | ✅ | ✅ | Средний |
| Firecrawl | Пайплайнов извлечения для разработчиков | ✅ (1 000 кредитов/мес.) | Cloud плюс browser API | ✅ | Нет | Средний |
| Apify | Команд разработчиков и marketplace | ✅ ($5 бесплатного использования) | Оба | ✅ | ✅ | Сильный с дополнениями |
| Gumloop | Автоматизации рабочих процессов | ✅ (5 000 кредитов/мес.) | Оба | ✅ | ✅ | Средний |
| Bright Data | Корпоративного доступа к данным | Trial / credits | Оба | ✅ | Внешний | Очень сильный |
| Bardeen | Браузерной автоматизации для sales и ops | ✅ (100 кредитов) | В первую очередь браузер | Ограниченно | ✅ | Средне-низкий |
| Diffbot | Структурированных API для извлечения | ✅ (10 000 кредитов) | Cloud | ✅ | Нет | Низкий на этапе получения / высокий на этапе извлечения |
| ScrapingBee | Получения данных и разблокировки для разработчиков | ✅ (1 000 кредитов) | Cloud | ✅ | Нет | Сильный |
| Instant Data Scraper | Бесплатных разовых скрейпов | ✅ (полностью бесплатно) | Только браузер | Нет | Нет | Низкий |
| ParseHub | Сложных визуальных сценариев | ✅ (5 проектов) | Desktop плюс cloud | ✅ | ✅ (платно) | Средний |
1. Thunderbit
— это AI веб-скрейпер, который мы создали специально для некомандных пользователей, которым нужны данные продакшен-качества без написания кода и без управления инфраструктурой. Базовый процесс действительно занимает два клика: AI Suggest Fields читает страницу и предлагает столбцы, а затем Scrape запускает извлечение в cloud- или browser-режиме.
От других no-code скрейперов его отличает архитектура. Thunderbit разделяет задачи сбора данных — облачную инфраструктуру, ротацию прокси, антибот-защиту и рендеринг JavaScript — и AI-извлечение, которое читает HTML и выдаёт структурированные столбцы. Это соответствует рекомендуемому экспертами принципу «сначала скрейпер, потом LLM», но упаковано в workflow расширения Chrome, которым реально могут пользоваться sales-менеджеры и операционные команды.
Основные сильные стороны
- И cloud-, и браузерный скрейпинг в одном интерфейсе. Переключайтесь между режимами в зависимости от того, открыт ли сайт публично или требует авторизованной сессии. Cloud-режим обрабатывает до 50 страниц параллельно.
- AI перечитывает структуру страницы каждый раз. Никакой поддержки XPath. Если сайт меняет макет, Thunderbit автоматически адаптируется при следующем запуске.
- Скрейпинг подстраниц. AI посещает связанные страницы с деталями и обогащает основную таблицу данных без ручной настройки.
- Field AI Prompts. Пользовательская маркировка, перевод и категоризация прямо во время извлечения, а не отдельным этапом постобработки.
- Бесплатный экспорт в Google Sheets, Excel, Airtable и Notion.
- Мгновенные шаблоны скрейперов для популярных сайтов, таких как Amazon, Zillow и LinkedIn.
- Планирование на естественном языке. Скажите «скрейпить каждую пятницу в 9 утра», и система превратит это в повторяющееся расписание.
- Открытый API с эндпоинтами Distill и Extract, пакетной обработкой до 100 URL и опубликованной конкурентностью от 2 в бесплатном плане до 50 в Pro 1.
Что можно улучшить
- Бесплатный тариф намеренно небольшой.
- Опыт no-code завязан на расширение Chrome. Разработчикам, которым нужны только API-процессы, придётся отдельно использовать Open API.
- Это не лучший инструмент, если ваша основная задача — просто сырой proxy-инфраструктурный стек без извлечения.
Цены
Есть бесплатный тариф. No-code планы начинаются от $9/мес. при оплате за год или $15/мес. при ежемесячной оплате для Starter. Цены API выделены отдельно: бесплатные одноразовые 600 units, затем $16/мес. при годовой оплате за Starter API и $40/мес. при годовой оплате за Pro 1 API. См. и .
Лучше всего подходит для: команд sales, e-commerce и operations, которым нужны структурированные веб-данные без поддержки инженеров.
2. Octoparse
— это визуальный конструктор рабочих процессов для web scraping с большой библиотекой готовых шаблонов. Он существует достаточно давно, чтобы иметь зрелую облачную инфраструктуру, и хорошо справляется с пагинацией на структурированных, предсказуемых сайтах.
Основные сильные стороны
- Большая библиотека готовых шаблонов для популярных сайтов
- Облачное извлечение с плановыми запусками
- Ротация IP и обход CAPTCHA как платные дополнения
- Доступ к API на старших тарифах
Что можно улучшить
- AI-возможности скромнее, чем у инструментов, изначально построенных вокруг LLM. Подсказки полей по-прежнему больше опираются на шаблоны, чем на адаптивное чтение.
- Сложные или необычные макеты требуют заметной ручной настройки в визуальном редакторе.
- Порог входа становится выше, когда вам нужны условная логика или обход блокировок.
Цены
Есть бесплатный тариф навсегда. В официальном центре поддержки сейчас указано Standard от $75/мес. при годовой оплате и Professional от $208/мес. при годовой оплате, хотя на некоторых локализованных страницах и в сценариях апгрейда отображаются более высокие эквиваленты в пересчёте на месяц. Важно, что сейчас ценообразование Octoparse сочетает подписки с платными дополнениями вроде residential proxies и обхода CAPTCHA.
Лучше всего подходит для: аналитиков и операционных команд, которые скрейпят структурированные сайты, хорошо подходящие под шаблоны, в умеренном масштабе.
3. Browse AI
— это облачная no-code платформа, созданная прежде всего для мониторинга изменений на сайтах: цен конкурентов, наличия товаров и обновлений контента. Скрейпинг — часть продукта, но реальное отличие — система повторяющегося мониторинга и оповещений.
Основные сильные стороны
- Встроенное обнаружение изменений и алерты
- No-code запись робота с настройкой через point-and-click
- Готовые роботы для популярных сайтов
- Поддержка премиум-прокси на старших тарифах
Что можно улучшить
- Тарифная модель на кредитах быстро становится дорогой при мониторинге страниц деталей в масштабе
- Для больших одноразовых извлечений менее удобен, чем API-first инструменты
- Обход антибот-защиты на среднем уровне; для некоторых сайтов всё равно нужны премиум-прокси или обходные схемы
Цены
Есть бесплатный аккаунт. Платные планы начинаются примерно от $19/мес. при годовой оплате за Starter, далее идут более высокие уровни по кредитам и мониторингу.
Лучше всего подходит для: команд, которым нужен постоянный мониторинг цен конкурентов, изменений контента или остатков, а не разовое массовое извлечение.
4. Firecrawl
— это API для разработчиков, которое преобразует веб-страницы в чистый Markdown или структурированный JSON. Он в основном находится на слое извлечения и отлично подходит командам, строящим RAG-пайплайны или подающим веб-контент в LLM.
Основные сильные стороны
- Отличное качество Markdown для дальнейших LLM-процессов
- Чистый API со scrape, crawl, map, search, extract и browser actions
- Поддержка пакетной обработки
- Конкурентность от 2 в бесплатном плане до 100 в Growth
Что можно улучшить
- Нет no-code интерфейса, нужны навыки разработки
- Встроенная помощь с прокси и антибот-защитой есть, но Firecrawl не позиционируется как специализированный провайдер разблокировки
- Нет собственного планировщика для повторяющихся задач
- Неэкономичен для неразработчиков, которым нужен просто табличный выгруз данных
Цены
Бесплатный план включает 1 000 кредитов в месяц. Платные тарифы начинаются от $16/мес. при годовой оплате за Hobby и масштабируются за счёт большего числа кредитов, конкурентности и использования браузера. Сессии браузера тарифицируются отдельно в кредитах.
Лучше всего подходит для: разработчиков, строящих LLM-пайплайны, RAG-системы или собственные рабочие процессы извлечения, которым нужен чистый Markdown или JSON со страниц.
5. Apify
— это платформа с маркетплейсом готовых scraping actors и инструментами для создания собственных. Думайте о ней как об уровне оркестрации: вы выбираете или создаёте специализированные скрейперы под конкретные сайты, а затем планируете и управляете ими через единый API.
Основные сильные стороны
- Огромный маркетплейс акторов с сотнями скрейперов, созданных сообществом
- Сильный API и SDK для разработчиков
- Встроенное управление прокси и планирование
- Интеграции со множеством внешних инструментов
Что можно улучшить
- «No-code» отчасти заканчивается там, где вам нужна собственная логика за пределами marketplace
- Надёжность акторов зависит от поддержки сообществом
- Цена может быстро расти, потому что складываются вычисления, стоимость акторов и прокси
Цены
Бесплатный тариф включает $5 в виде ежемесячных кредитов платформы. Платные планы начинаются от $39/мес. за Starter, дальше идут тарифы для масштабирования.
Лучше всего подходит для: команд разработчиков, которым нужны переиспользуемые, планируемые скрейпинг-процессы с большой экосистемой готовых решений.
6. Gumloop
— это no-code платформа автоматизации рабочих процессов, в которой есть узел web scraping. Реальная ценность здесь не только в скрейпинге, а в том, чтобы связывать извлечение с LLM, Google Sheets, CRM и другими инструментами на одной визуальной доске.
Основные сильные стороны
- Визуальный конструктор процессов drag-and-drop
- Связывает скрейпинг с LLM и последующими бизнес-инструментами в одном потоке
- Бесплатный план сейчас заявлен как 5 000 кредитов/мес.
- Планирование по времени для повторяющихся процессов
- Базовый скрейпинг и интерактивный режим Web Agent покрывают и простые, и более богатые сценарии
Что можно улучшить
- Скрейпинг-движок менее устойчив, чем у специализированных AI веб-скрейперов
- Меньше глубина антибот-защиты и работы с прокси по сравнению со специализированными вендорами
- На бесплатных планах жёстче ограничения по конкурентности и триггерам
- Не лучший вариант, если скрейпинг — ваш основной сценарий в больших объёмах
Цены
Есть бесплатный план. В конце 2025 года Gumloop объединил старые Solo и Team в план Pro, и с тех пор публичные сообщения компании делают акцент на более щедрых бесплатных кредитах и объединённых платных тарифах, а не на классическом scraper-first ценообразовании.
Лучше всего подходит для: команд, которым скрейпинг нужен как один из шагов в более широкой автоматизации: собрать данные, проанализировать их и отправить в бизнес-инструменты.
Если хотите увидеть, как AI-нативный процесс извлечения ощущается на практике, прежде чем читать остальной список, этот walkthrough Thunderbit — наиболее релевантная демонстрация продукта для некомандных пользователей.
7. Bright Data
— это корпоративный инфраструктурный стек в этом списке. Если ваша проблема звучит как «я никак не могу пройти бот-защиту на этом сайте», Bright Data, вероятно, и есть ответ, но вместе с ним приходит корпоративная сложность и соответствующая цена.
Основные сильные стороны
- Лидирующая в отрасли прокси-сеть с residential, datacenter и mobile IP
- Web Unlocker для обхода антибот-защиты и CAPTCHA
- Scraping Browser со встроенной разблокировкой
- Готовые наборы данных для покупки
- Полный программный контроль через API и SDK
Что можно улучшить
- Не предназначен для некомандных пользователей
- Цена отражает корпоративное позиционирование
- AI-извлечение — не основная причина покупать эту платформу
Цены
Browser API стартует от $8/GB по модели pay as you go, с более низкой ценой за GB при больших ежемесячных обязательствах. Другие продукты Bright Data, такие как Unlocker, Scraper APIs, datasets и proxy pools, используют разные единицы тарификации.
Лучше всего подходит для: корпоративных data-команд, которым нужно массово скрейпить сильно защищённые сайты и у которых есть технические специалисты для управления инфраструктурой.
8. Bardeen
— это инструмент браузерной автоматизации, ориентированный на клики, заполнение форм и скрейпинг с AI-извлечением данных поверх. Его лучше всего понимать как GTM-инструмент для workflow, который заодно умеет скрейпить, а не как скрейпинг-инструмент, который ещё и делает GTM.
Основные сильные стороны
- Интуитивная автоматизация в стиле playbook, где скрейпинг — лишь один из шагов
- Официальные скрейперы, которые поддерживает команда Bardeen для популярных сайтов
- Сильные интеграции с CRM, Google Sheets, Slack и другими бизнес-инструментами
- Хорошо подходит для извлечения лидов, enrichment и экспорта в CRM
Что можно улучшить
- Браузер-ориентированная архитектура ограничивает высокообъёмный unattended-скрейпинг
- Cloud-скрейпинг работает только на публичных страницах, а не на защищённых
- Обход антибот-защиты в основном зависит от того, что уже даёт ваша браузерная сессия
- AI-извлечение может буксовать на сложных или нестандартных макетах страниц
Цены
Бесплатный план включает 100 кредитов в месяц. В публичной документации поддержки упоминается старый тариф $15/мес. Pro для существующих пользователей, тогда как текущая коммерческая упаковка Bardeen стала более enterprise-ориентированной и workflow-центричной, чем классическое недорогое ценообразование для скрейперов.
Лучше всего подходит для: команд sales и operations, которым скрейпинг нужен как часть более широкого процесса браузерной автоматизации.
9. Diffbot
использует компьютерное зрение и NLP, чтобы читать веб-страницы как человек и выдавать структурированные данные по статьям, товарам, обсуждениям и организациям. Это один из самых качественных API для извлечения, если ваши страницы соответствуют его предобученным моделям.
Основные сильные стороны
- Предобученные модели извлечения для статей, товаров, обсуждений и многого другого
- Knowledge Graph с миллиардами сущностей для обогащения данных
- Высокое качество структурированного вывода на поддерживаемых типах страниц
- Понятный API для разработчиков с опубликованными лимитами
Что можно улучшить
- Нет no-code интерфейса
- Нет встроенного crawling, управления прокси или антибот-защиты
- Дорогой для небольших команд
- Меньше гибкости на нестандартных типах страниц, чем у экстракторов с schema-prompt
Цены
Бесплатный план включает 10 000 кредитов. Startup стоит $299/мес. за 250 000 кредитов, а Plus — $899/мес. за 1 000 000 кредитов.
Лучше всего подходит для: команд разработчиков, которым нужно высокоточное структурированное извлечение со стандартных типов страниц и которые готовы отдельно заниматься получением данных.
10. ScrapingBee
— это API для web scraping, сосредоточенный на слоях получения данных и обхода блокировок. Вы отправляете URL, он обрабатывает прокси, headless-рендеринг браузера и антибот-защиту, а затем возвращает HTML или, при необходимости, извлечённые данные.
Основные сильные стороны
- Встроенная ротация прокси и антибот-защита
- Поддержка рендеринга JavaScript
- Простой REST API
- Эндпоинт для скрейпинга Google Search
- Опубликованная конкурентность по тарифам
Что можно улучшить
- AI-функции извлечения ограничены
- Нет no-code интерфейса
- Нет встроенного планирования или мониторинга
- Ответ
200со страницей блокировки всё равно может считаться успешным запросом
Цены
Бесплатный план включает 1 000 API-кредитов. Платные тарифы начинаются от $49/мес. и масштабируются за счёт большей конкурентности и объёма запросов.
Лучше всего подходит для: разработчиков, которым прежде всего нужно надёжно получать страницы, проходя антибот-защиту, а извлечение они будут делать своим кодом или отдельным инструментом.
11. Instant Data Scraper
— это бесплатное расширение Chrome с более чем 1 000 000 пользователей, которое автоматически определяет шаблоны данных на странице и позволяет экспортировать их в CSV или Excel. Здесь нет AI-подсказок полей в смысле LLM. Используется эвристическое распознавание шаблонов.
Основные сильные стороны
- Полностью бесплатно, без регистрации
- Обнаружение данных в один клик на многих страницах со списками и таблицами
- На некоторых сайтах умеет работать с пагинацией
- Чрезвычайно низкий порог входа
- По-прежнему поддерживается, обновления в Chrome Web Store есть и в 2026 году
Что можно улучшить
- Нет AI-подсказок полей или маркировки данных
- Нет cloud-скрейпинга, планирования или API
- Сложные макеты, динамический контент и JS-тяжёлые сайты даются плохо
- Нет антибот-защиты, кроме того, что уже способен загрузить ваш браузер
- Экспорт ограничен CSV и Excel
Цены
Бесплатно. Навсегда.
Лучше всего подходит для: любого, кому нужен быстрый разовый скрейп простой страницы со списком и кто не хочет ни регистрироваться, ни платить.
12. ParseHub
— это десктопное приложение с визуальным интерфейсом point-and-click для создания scraping-проектов. Оно справляется со сложными вложенными данными, AJAX-контентом, бесконечной прокруткой и выпадающими списками, которые более простые расширения часто пропускают.
Основные сильные стороны
- Визуальный интерфейс селекторов для задания правил извлечения
- Обрабатывает вложенные данные, выпадающие списки, бесконечную прокрутку и AJAX-контент
- Бесплатный тариф до 5 проектов
- Экспорт в JSON, CSV и Excel
- Планирование в облаке и ротация IP на платных тарифах
Что можно улучшить
- Только десктопный workflow, без удобства браузерного расширения
- Ниже скорость выполнения по сравнению с cloud-native инструментами
- Проекты ломаются при изменении макета сайта, потому что нет AI-слоя повторного чтения
- Ограниченные AI-возможности и более «старомодное» ощущение визуального скрейпера
Цены
Есть бесплатный план с 5 проектами и 200 страницами за запуск. Платные тарифы начинаются от $189/мес. и включают планирование, ротацию IP и более высокие лимиты.
Лучше всего подходит для: некомандных пользователей, которым нужно скрейпить сложные интерактивные сайты и которые готовы потратить время на настройку визуального workflow.
Как начать работу с AI веб-скрейпером за 5 шагов
У каждого инструмента в этом списке свой сценарий онбординга. В качестве конкретного примера я возьму Thunderbit, потому что он лучше всего соответствует поисковому намерению «мне просто нужно, чтобы это работало на реальной странице».
Шаг 1: Установите и откройте нужную страницу
Установите и откройте страницу, которую хотите скрейпить: каталог товаров, директорию или портал недвижимости.
Шаг 2: Позвольте AI предложить поля данных
Нажмите AI Suggest Fields. AI прочитает текущую страницу и предложит названия столбцов и типы данных. На странице товара он может предложить название товара, цену, рейтинг, URL изображения и описание.
Шаг 3: Настройте поля с помощью AI Prompts
При необходимости скорректируйте столбцы, если значения по умолчанию не совсем подходят. Добавьте Field AI Prompts для пользовательских преобразований, например: «переведи описание на испанский», «категоризируй как Electronics, Home или Fashion» или «извлеки только числовую цену».
Шаг 4: Выберите Cloud- или Browser-режим и запустите скрейпинг
Выберите cloud-скрейпинг для публичных сайтов или browser-скрейпинг для авторизованных либо сильно защищённых целей. Затем нажмите Scrape.
Шаг 5: Экспортируйте данные куда угодно
Экспортируйте результаты в Google Sheets, Excel, Airtable или Notion. Экспорт бесплатный.
Что если макет сайта изменится?
Это ключевое преимущество AI-нативных экстракторов по сравнению с инструментами на правилах. Традиционные скрейперы вроде ParseHub и старые workflow Octoparse зависят от XPath-селекторов или CSS-путей. Когда сайт обновляет HTML-структуру, эти селекторы ломаются, и вам снова приходится вручную всё перенастраивать.
AI-экстракторы вроде Thunderbit каждый раз заново читают структуру страницы. Это означает, что не нужно поддерживать XPath и нет хрупких селекторов. AI автоматически адаптируется к изменениям макета при следующем запуске.
Плановый скрейпинг и доступ к API: функции для продвинутых пользователей, которые никто не рассматривает
Разовые скрейпы хороши для исследований. А продакшен-сценарии вроде мониторинга цен, обновления лид-листов и отслеживания наличия товаров требуют повторяющегося извлечения и программного доступа. Именно эти возможности отделяют игрушки от инструментов.
Поддержка планирования
| Инструмент | Нативное планирование | Примечания |
|---|---|---|
| Thunderbit | ✅ | Настройка на естественном языке |
| Octoparse | ✅ | Запуски по расписанию в облаке |
| Browse AI | ✅ | Ключевая функция продукта |
| Firecrawl | ❌ | Используйте внешний cron |
| Apify | ✅ | Полные cron-выражения |
| Gumloop | ✅ | Триггеры процессов по времени |
| Bright Data | Внешнее | Обычно оркестрируется через системы клиента |
| Bardeen | ✅ | Планирование playbook |
| Diffbot | ❌ | API-first, внешняя оркестрация |
| ScrapingBee | ❌ | Только API |
| Instant Data Scraper | ❌ | Ручной инструмент в браузере |
| ParseHub | ✅ (платно) | Премиум-функция |
Сравнение API для разработчиков
| Инструмент | Сигнал по конкурентности или скорости запросов | Модель ценообразования |
|---|---|---|
| Thunderbit | 2 → 50 параллельных запросов | На основе кредитов |
| Firecrawl | 2 → 100 параллельных запросов | На основе кредитов |
| Apify | Зависит от тарифа | Compute units |
| Gumloop | Ограничение конкурентности workflow по тарифу | На основе кредитов |
| Diffbot | 5 calls/min → 25 calls/sec | На основе кредитов |
| ScrapingBee | 10 → 200 параллельных запросов | API-кредиты |
| Bright Data | Browser API заявляет неограниченные параллельные запросы | По GB |
Если ваш кейс более технический и вы пытаетесь понять, сколько инфраструктуры хотите взять на себя, этот walkthrough Firecrawl — полезное практическое дополнение к сравнению продуктов выше.
Как выбрать подходящий AI веб-скрейпер
После тестирования всех 12 инструментов вот как бы я принимал решение:
- Некомандная команда, которой нужны данные быстро: начните с Thunderbit. Двухшаговый workflow, бесплатный экспорт и переключение между browser и cloud покрывают большинство бизнес-задач без помощи инженеров.
- Нужен постоянный мониторинг и оповещения: Browse AI создан именно для этого. Это не самый сильный инструмент для разового извлечения, но обнаружение изменений у него — функция первого класса.
- Разработчик, строящий LLM-пайплайн: Firecrawl для Markdown- или JSON-извлечения, либо Diffbot для предобученного структурированного извлечения. В обоих случаях при серьёзной антибот-защите на слое получения данных можно добавить ScrapingBee или Bright Data.
- Нужен marketplace готовых скрейперов: у Apify самая большая экосистема акторов. Просто будьте готовы к поддержке, когда акторы ломаются.
- Корпоративные объёмы и сильно защищённые цели: Bright Data. Никто не сравнится с его proxy-инфраструктурой, но и бюджет, и штат технических специалистов должны этому соответствовать.
- Скрейпинг как часть большой автоматизации: Gumloop или Bardeen, в зависимости от того, автоматизируете ли вы процессы или browser-based GTM-задачи.
- Нужен просто быстрый бесплатный скрейп: Instant Data Scraper. Ноль настройки, ноль стоимости, ноль сложности, но также ноль планирования, ноль AI и ноль cloud.
- Сложные интерактивные сайты с dropdown и AJAX: ParseHub по-прежнему справляется с ними лучше большинства расширений, хотя поддержка требует реальных усилий.
Заключение
Рынок AI веб-скрейперов в 2026 году переполнен инструментами, которые впечатляют в демо и разочаровывают в продакшене. Разрыв между «работает на маркетинговом скриншоте» и «работает на защищённом e-commerce-сайте в 3 часа ночи по расписанию» — именно то место, где большинство покупателей теряют время и деньги.
Главный вывод после оценки всех 12 инструментов прост: самым сложным по-прежнему остаётся слой получения данных. AI отлично справляется с извлечением и постобработкой, но не заменяет proxy-инфраструктуру, антибот-защиту и управление сессиями. Лучшие инструменты либо решают оба слоя, как Thunderbit и Bright Data, либо честно говорят, какой слой они покрывают, как Firecrawl для извлечения и ScrapingBee для получения данных.
Если хотите увидеть, как выглядит готовый к продакшену AI веб-скрейпер без написания кода, . Бесплатного тарифа достаточно, чтобы протестировать весь workflow на реальных страницах. Если ваши потребности больше ориентированы на разработку, соедините API для извлечения с отдельным сервисом для получения данных и избавьте себя от разочарования, когда один инструмент должен делать вообще всё.
FAQ
Почему большинство AI веб-скрейперов ломаются на реальных сайтах, хотя в демо всё работает?
Демо обычно показывают извлечение на чистых, незащищённых страницах. Реальные сайты добавляют защиту Cloudflare, динамический рендеринг JavaScript, пагинацию, требования к логину и часто меняющиеся макеты. Большинство инструментов хорошо справляются со слоем парсинга и извлечения, но у них не хватает надёжной инфраструктуры для слоя получения данных.
В чём разница между cloud-скрейпингом и браузерным скрейпингом, и когда использовать каждый из них?
Cloud-скрейпинг использует удалённые серверы для получения страниц, поэтому он быстрее, лучше параллелится и масштабируется. Браузерный скрейпинг работает в вашей собственной браузерной сессии и лучше подходит для авторизованных сайтов или сайтов с агрессивным антибот-детектом. Thunderbit — один из немногих инструментов, который предлагает оба режима в одном интерфейсе.
Можно ли использовать AI веб-скрейпер для повторяющихся задач вроде мониторинга цен?
Да, но только если инструмент поддерживает плановый скрейпинг. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen и ParseHub на платных тарифах поддерживают планирование.
Какой AI веб-скрейпер лучше всего подходит, если я не умею программировать?
Thunderbit даёт самый быстрый путь к рабочим данным для некомандных пользователей. Instant Data Scraper полностью бесплатен, но ограничен простыми страницами. Browse AI и Octoparse предлагают визуальные интерфейсы, но требуют большей настройки. ParseHub мощный для сложных интерактивных сайтов, но у него более крутая кривая обучения.
Сколько на самом деле стоит AI веб-скрейпинг продакшен-уровня?
Диапазон очень широкий. Instant Data Scraper бесплатен. Thunderbit, Firecrawl и Browse AI предлагают бесплатный вход и недорогие платные планы. Инструменты среднего уровня, такие как Octoparse, ParseHub и ScrapingBee, могут стоить от примерно $49 до $189 в месяц. Корпоративные решения вроде Bright Data и Diffbot начинаются значительно выше.